
Привет, Хабр! Меня зовут Дмитрий Химион, я руковожу отделом обеспечения качества в Avito. Cегодня я хочу рассказать про автоматизацию тестирования в рамках работы с микросервисной архитектурой. Что мы можем предложить разработке для того, чтобы облегчить контроль качества? Читайте под катом.

Чтобы мой рассказ был полным, начнем с основ. Если упростить, микросервисная архитектура — это способ организации сервера приложений. Как он работает? По сути, это просто ответ сервис-ориентированной архитектуры на появление такой практики, как DevOps. Если в SOA не регламентированы размеры сервисов и то, что именно они должны делать, то в рамках микросервисной архитектуры есть некоторые умозрительные ограничения. Микросервис — это некоторая сущность, которая заключает в себе одну небольшую функциональность, которой она заведует и предоставляет внешним сервисам какие-то данные.
Иногда приводят информацию, что микросервис — это 500 строк кода. Но это не обязательно; смысл заключается в том, что сервисы эти достаточно маленькие и образуют те же бизнес-процессы, что и монолитный бэк-энд, который работает на многих проектах. Функционально — то же самое, отличия — в организационной структуре.
В чем здесь могут возникать проблемы? Сервисов быстро становится много, повышается их связность. Это осложняет тестирование: проверка изменения одного микросервиса влечет за собой необходимость поднять довольно толстый слой инфраструктуры из множества сервисов, с которыми взаимодействует изменяемый микросервис. В определенный момент развития проекта количество связей и зависимостей сильно вырастает и выполнять быстрое и изолированное тестирование становится затруднительно. Мы начинаем работать медленнее. Разработка замедляется. Эти и некоторые другие проблемы можно решить с помощью автоматизации тестирования.
Для начала рассмотрим переход от монолита к микросервисной архитектуре. В случае с монолитом для того, чтобы заменить какой-либо кусочек в этой системе, мы не можем выкатить его отдельно. Нужно делать сборку заново и полностью обновлять бэк-энд. Это не всегда рационально и удобно. Что происходит при переходе на микросервисную архитектуру? Мы берем бэк-энд и делим его на составляющие компоненты, разделяя их по функциональности. Определяем взаимодействия между ними, и получается новая система с тем же фронт-эндом и теми же базами данных. Микросервисы взаимодействуют между собой и обеспечивают всё те же бизнес-процессы. Для пользователя и системного тестирования всё осталось таким, как и прежде, изменилась внутренняя организация.
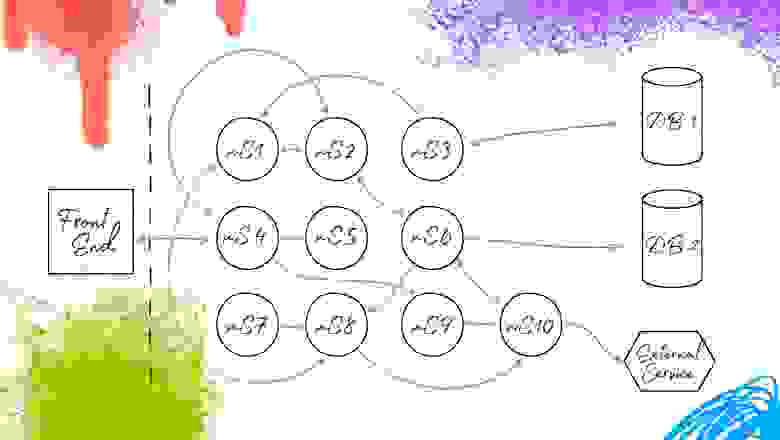
Что это дает? Можно сделать изменение в микросервисе X, которое реализует какую-то его функциональность, и сразу выкатить его в работу. Всё это звучит очень хорошо. Но, как и всегда, есть нюанс: нужно проверять то, как микросервисы взаимодействуют друг с другом.
Взаимодействия микросервисов между собой реализуются посредством контрактов. Что это значит для сервис-ориентированной архитектуры? Контракт — это некоторое соглашение, которое разработчики сервиса создают для взаимодействия между собой внешних пользователей. Разработчики сервиса сами решают, что вы можете запросить у них “X”, а они вам предоставят “Y”. Сервис может предоставлять внешним пользователям яблоки, помидоры, плутоний, продавать детскую одежду или телевизоры — ему не декларируется чёткий фокус на функционал. Внутреннее наполнение регламентируется только на уровне здравого смысла. И соответственно, это сервис диктует внешним пользователям то, что они будут получать, и как к нему необходимо обращаться.
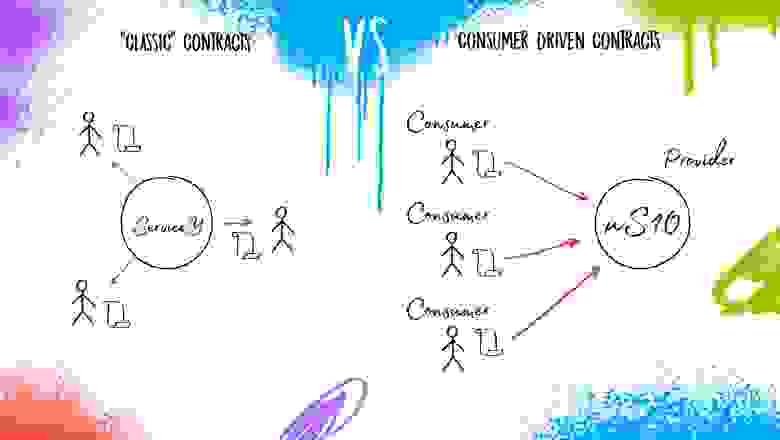
Если увеличивать комплексность этой задачи, когда сервисов будут не десятки (10-20-50), а сотни (200, 400…2000), то традиционные, “классические” контракты перестают работать в функциональном смысле. И тогда уже возникает необходимость модернизации контрактов под микросервисную архитектуру. Разработан шаблон работы для разработчиков, в котором они и “конечные пользователи” микросервиса меняются местами — этот подход называется consumer driven contacts. Теперь запросы делают внешние пользователи. Это можно представить как такого рода беседу:
Таким образом получается, что пользователи создают контракты, задают требования и направляют их к провайдеру, который их реализует. В чем плюс? Так как у каждого сервиса достаточно ограниченное количество потребителей, получить от каждого по три спецификации и реализовать их гораздо проще, чем пытаться угадать, какие именно “яблоки” нужно предоставить в каждом конкретном случае и что еще им может понадобиться к этим “фруктам” дополнительно.
Вот для этого подхода мы, как отдел обеспечения качества, должны предоставить достойный ответ в области тестирования так, чтобы не замедлить процесс быстрых выкаток микросервисов.
Без чего нельзя начать работать по принципам CDC-testing? Первое. У нас не получится помочь, если мы видим что у нас в разработке не соблюдается процесс работы по контрактам. Вторая вещь более техническая: это система post-commit (post-PR, если хотите) hook-ов, которая обрабатывает этот поток общения между девелоперами с помощью контрактов и сигнализирует нашей системе тестирования об их обновлении, удалении, появлении новых. Соответственно, заводятся соответствующие таски в Jira, чтобы автоматизаторы успели это все “переварить”. К этому базовому процессу можно добавить еще все что угодно — дополнительные проверки, процессные примочки, но без контроля изменения контрактов взаимодействия между микросервисами жить будет достаточно сложно. Выполнив в каком-то виде эти два пункта, мы можем приступить к имплементации.
В основу нашей системы автоматизации тестирования ляжет такое решение, как PACT-фреймворки. Что нужно о них знать? Это протокольное взаимодействие с API: JSON over HTTP, в этом нет ничего сложного. Эти решения взаимодействуют с нашими микросервисами и дают некоторый дополнительный функционал для изоляции и организации тестирования. Что сказать еще? Я видел, как это реализовано в том или ином виде на семи языках программирования (Java, Javascript, Ruby, Python, Go, .NET, Swift). Но если вашего нет в этом списке, не пугайтесь: можно взять базовую библиотеку и сделать свой велосипед, или написать что-то подобное тому, что уже реализовано.
Что ещё нас ждёт почти в 100% случаев? Первое — это мокирование внешних сервисов. Проблема в том, что сложно поддерживать релевантность того, как себя ведет внешний сервис, и поддерживать это во всех заглушках. Как решать эту проблему? Это зависит от вас. Скорее всего, потребуется направить на это больше ресурсов или ограничить покрытие тестами. И второе: сэмплированные базы данных. Понадобится нарезать боевые базы данных в облегченном виде так, чтобы в них были все необходимые данные для тестирования в рамках нашей системы. Тогда получится наглядный релевантный результат.

Идем далее. Первое, что я сразу захотел сделать в этом проекте — это информативное логирование. Всегда необходима репрезентативность итогов тестирования. Простая истина: если результаты невозможно прочитать и понять — их никто не будет смотреть. Надо сказать, что базовое логирование в PACT-фреймворках реализовано очень убого.
Я предпочел бы вынести его в отдельный модуль, сделать обёртку и навертеть там то, что нам нужно. В первую очередь сделать разделение ошибок по источникам их появления. Далее — всё, что вы можете реализовать, например, решения наподобие Allure (решение от компании Яндекс для повышения простоты анализа результатов тестирования). Делать можно что угодно, но необходимость информативных логов нужно учесть.
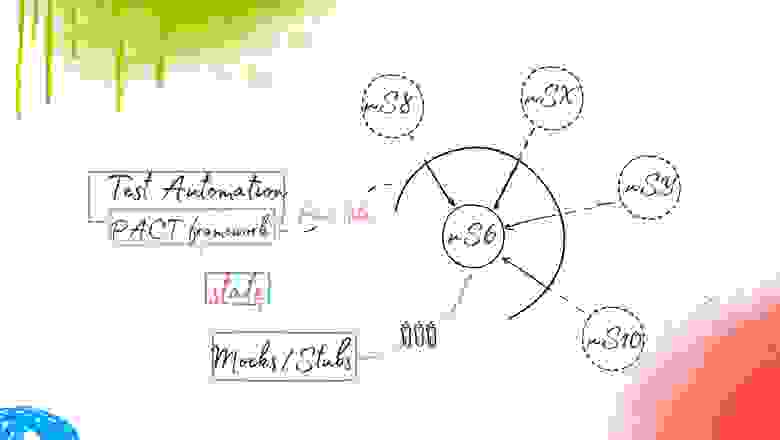
Следующий, возможно, “капитанский” момент — это Config Reader. Но в рамках тестирования микросервисной архитектуры это может быть немного заковыристой вещью. Для Config Reader у нас есть два источника. Первый — это PACT-файлы, а второй — State.
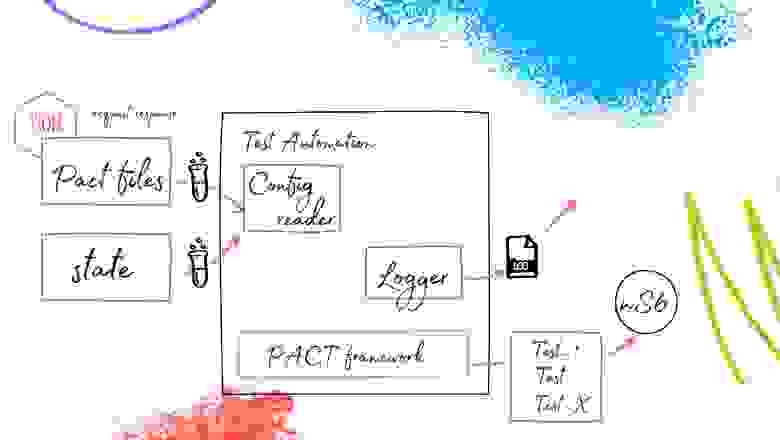
Что это такое PACT-файл? Это не какой-то шифрованный бинарник, а обычный JSON-файл, который имеет специфичную структуру. В нем выделяется consumer, provider (т.е. кто именно и с кем взаимодействует в рамках этого контракта и в какой роли). Далее описываются взаимодействия (это делают разработчики): я — consumer, и хочу от этого сервиса (provider), чтобы он отдавал мне “маленькие зеленые яблоки”; жду такой-то код ответа, статус, header, body и так далее. Есть поле description — это просто описание, повод напомнить разработчикам о чём шла речь в контракте, какой смысл в него вкладывался.
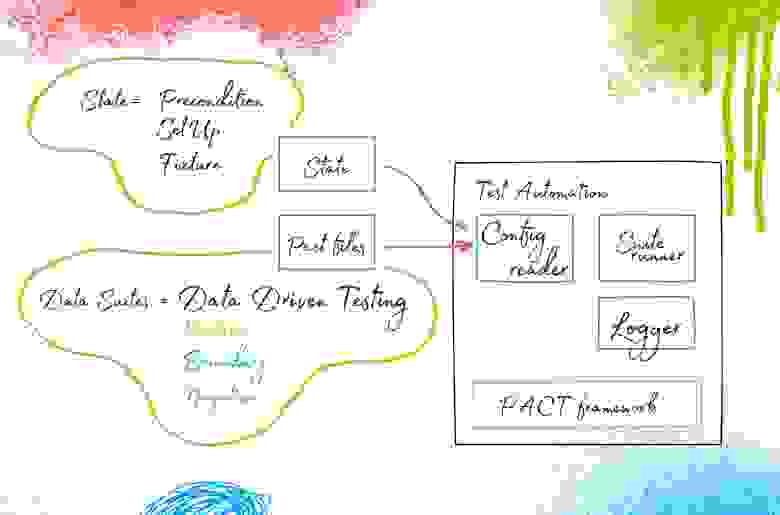
И самое интересное — это State Provider. Что это? По сути, это состояние, в котором должен пребывать тестируемый микросервис на момент обращений к нему по конкретной итерации тестирования, по конкретному запросу. В States могут описываться как SQL-запросы (или другие механизмы приведения сервиса в некоторое состояние), так и создание каких-то данных в нашей сэмплированной базе. States — это сложный модуль, который может содержать в себе всякого рода сущности, приводящие наш сервис в нужное надлежащее состояние.
Важно отметить, что здесь появляется Suite runner (см. схему ниже). Это — та сущность, которая будет отвечать за запуск и конфигурирование тестов в удобном для разработчика/тестировщика виде. Её можно и не писать, но я бы все-таки выделил этот момент, так как сложно предвидеть какие тесты необходимо будет прогонять в тот или иной момент времени на проекте. В итоге у нас получается вот такое ядро автоматизации тестирования под микросервисную архитектуру:
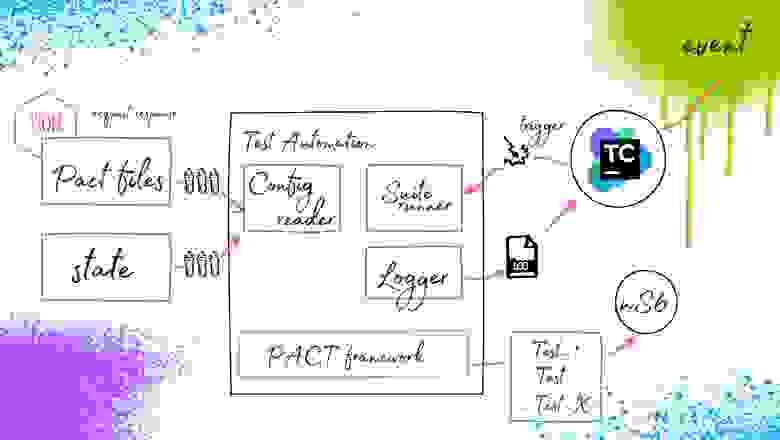
Теперь самое важное — внедрение. Мы должны предоставить эту схему с требованиями по наличию описанных контрактов разработчикам. Что мы получаем после?

У нас есть информация по каждому сервису: о том, что он выдает и то, что он запрашивает у своих “соседей”. Соответственно, с помощью нашей системы автоматизации тестирования, с помощью PACT-файлов мы изолируем наш микросервис для обеспечения изоляции его тестирования вне зависимости от внешних сервисов, с которыми он интегрирован. И предоставляем states через моки, заглушки, сэмплированные базы данных, или напрямую как-то изменяем сервис. Получаем, соответственно, изолированное тестирование. Вуаля: у нас есть ответ на вопрос, что делать с автоматизацией тестирования во время перехода от монолита к микросервисной архитектуре.
Что же нужно учесть при имплементации? Первое — это использование контейнеризации и виртуализации в процессе сборки/деплоя микросервиса. И наша система автоматизации тестирования точно так же закручивается в контейнер. Как будете обеспечивать взаимодействие микросервиса и системы автоматизации тестирования — это уже не столь важно: как удобнее, так и делайте.
Второе — актуализация файлов требований по контрактам. Есть такая проблема, что требования консьюмеров к провайдеру начинают копиться, а разработчики занимаются только тем, что им насущно необходимо сейчас. Здесь нужно на уровне тест-менеджмента или управления продуктом ставить задачу разработчикам: например, час в неделю работать с этим “хвостом”, чтобы он не разрастался. Конечно, эти тесты быстрые, они могут проходить за несколько секунд. Но если их количество будет измеряться тысячами, это будет осложнять актуализацию тестирования. А мы со своей стороны, через систему commit hook-ов будем получать информацию и убирать ненужные автотесты. По сути, CDC — это documentation-driven development, если так можно выразиться.
Третье: нужно ввести обязательно ввести в эту работу процесс актуализации states и data suites. Что такое data suites? Девелоперы в процессе разработки пишут некоторые базовые сценарии взаимодействия. К примеру: “мне нужен такой запрос и такой ответ”. А обо всем остальном — в каких рамках он должен существовать, какие значения параметров возможны, а какие — нет, забывают. Это необходимо проверять. И сюда мы должны входить с нашим data-driven подходом к тестированию, реализуя это в нашем конфигураторе: позитивные, пограничные и негативные тесты, для того, чтобы обеспечить отказоустойчивость работы нашей микросервисной архитектуры на продакшене. Без этого она вряд ли будет работать, любой шаг вправо/влево — и ошибка взаимодействия.
Соответственно при появлении новых pact-файлов, через hook мы получаем таски и наполняем новые/изменённые взаимодействия большим количеством наборов данных в interactions, что равно целому ряду проведенных тестов. Мы можем наполнять и редактировать interactions вручную, а можем делать генераторы, которые будут параметризировать их и гнать тесты.
Что касается States: если брать автоматизацию тестирования веба, то это preconditions, setUps, FixTure; для микросервисов есть проблема — готового механизма нет: надо продумать то, как вы будете сопрягать изменение названия States в PACT-файлах в этом модуле. Самый простой из механизмов — использовать Aliases, по сути KDT (keyword driven testing), говоря на языке автоматизации тестирования. Рассказать сейчас про более красивое и элегантное решение не готов: пока что его не придумал.
Если вы больше любите не читать, а смотреть видео, то эта информация доступна в формате доклада по ссылке. А в конце августа у нас в Avito пройдет тематический митап для профессионалов в области тестирования. Поговорим о векторах развития систем автоматизации в целом, обсудим применение прикладных инструментов и их влияние на изменение инфраструктуры тестирования. Если интересно — следите за обновлениями на нашей странице в FB, или напишите в комментариях: дадим знать, когда будут подробности о мероприятии.
Вместо вступления
“An implementation should be conservative in its sending behavior, and liberal in its receiving behavior”.
Jonathan Bruce Postel, computer scientist
Что такое микросервисная архитектура?
Чтобы мой рассказ был полным, начнем с основ. Если упростить, микросервисная архитектура — это способ организации сервера приложений. Как он работает? По сути, это просто ответ сервис-ориентированной архитектуры на появление такой практики, как DevOps. Если в SOA не регламентированы размеры сервисов и то, что именно они должны делать, то в рамках микросервисной архитектуры есть некоторые умозрительные ограничения. Микросервис — это некоторая сущность, которая заключает в себе одну небольшую функциональность, которой она заведует и предоставляет внешним сервисам какие-то данные.
Иногда приводят информацию, что микросервис — это 500 строк кода. Но это не обязательно; смысл заключается в том, что сервисы эти достаточно маленькие и образуют те же бизнес-процессы, что и монолитный бэк-энд, который работает на многих проектах. Функционально — то же самое, отличия — в организационной структуре.
В чем здесь могут возникать проблемы? Сервисов быстро становится много, повышается их связность. Это осложняет тестирование: проверка изменения одного микросервиса влечет за собой необходимость поднять довольно толстый слой инфраструктуры из множества сервисов, с которыми взаимодействует изменяемый микросервис. В определенный момент развития проекта количество связей и зависимостей сильно вырастает и выполнять быстрое и изолированное тестирование становится затруднительно. Мы начинаем работать медленнее. Разработка замедляется. Эти и некоторые другие проблемы можно решить с помощью автоматизации тестирования.
Переход к микросервисам
Для начала рассмотрим переход от монолита к микросервисной архитектуре. В случае с монолитом для того, чтобы заменить какой-либо кусочек в этой системе, мы не можем выкатить его отдельно. Нужно делать сборку заново и полностью обновлять бэк-энд. Это не всегда рационально и удобно. Что происходит при переходе на микросервисную архитектуру? Мы берем бэк-энд и делим его на составляющие компоненты, разделяя их по функциональности. Определяем взаимодействия между ними, и получается новая система с тем же фронт-эндом и теми же базами данных. Микросервисы взаимодействуют между собой и обеспечивают всё те же бизнес-процессы. Для пользователя и системного тестирования всё осталось таким, как и прежде, изменилась внутренняя организация.
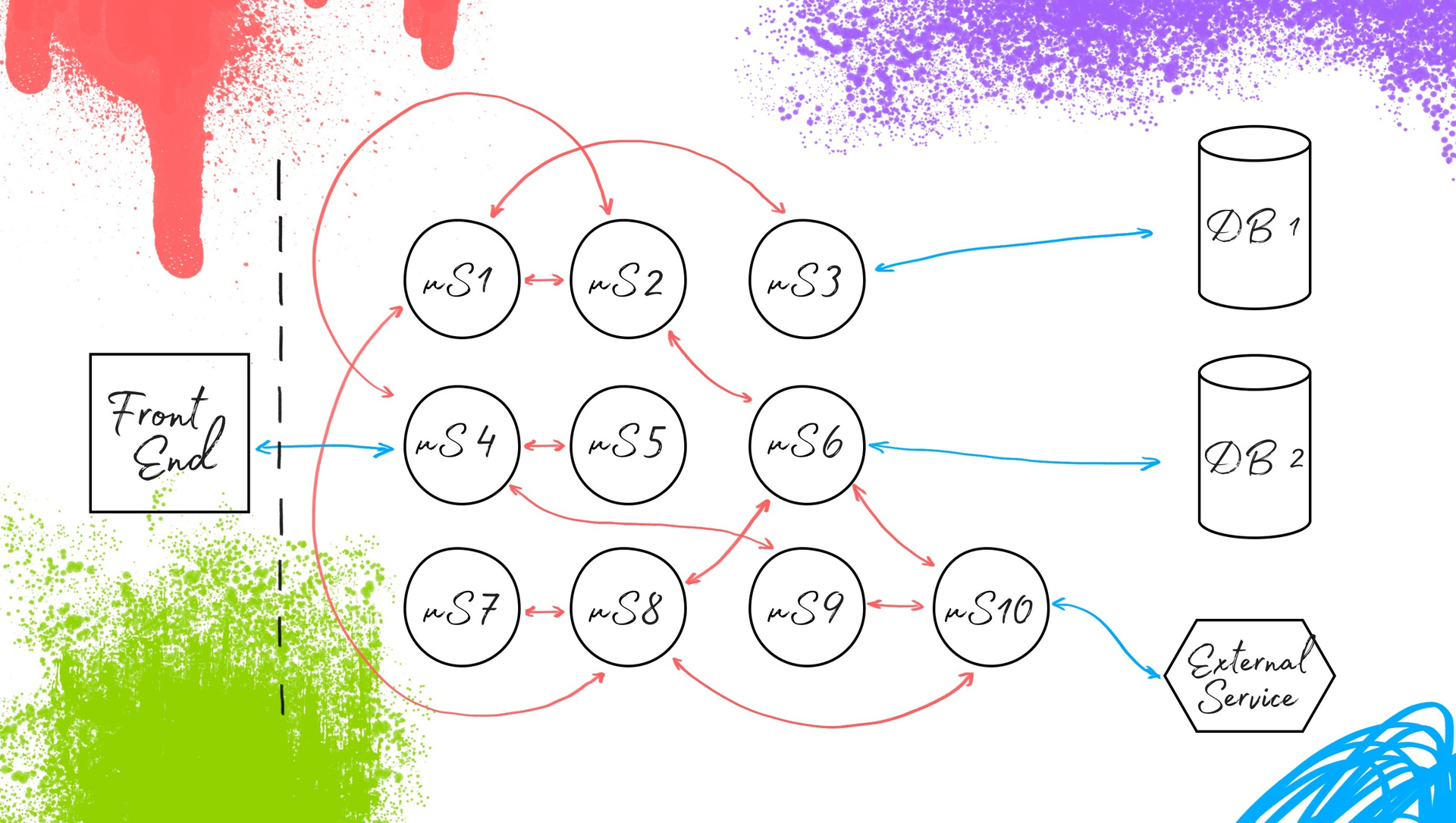
Что это дает? Можно сделать изменение в микросервисе X, которое реализует какую-то его функциональность, и сразу выкатить его в работу. Всё это звучит очень хорошо. Но, как и всегда, есть нюанс: нужно проверять то, как микросервисы взаимодействуют друг с другом.
Контракты для микросервисной архитектуры
Взаимодействия микросервисов между собой реализуются посредством контрактов. Что это значит для сервис-ориентированной архитектуры? Контракт — это некоторое соглашение, которое разработчики сервиса создают для взаимодействия между собой внешних пользователей. Разработчики сервиса сами решают, что вы можете запросить у них “X”, а они вам предоставят “Y”. Сервис может предоставлять внешним пользователям яблоки, помидоры, плутоний, продавать детскую одежду или телевизоры — ему не декларируется чёткий фокус на функционал. Внутреннее наполнение регламентируется только на уровне здравого смысла. И соответственно, это сервис диктует внешним пользователям то, что они будут получать, и как к нему необходимо обращаться.
Если увеличивать комплексность этой задачи, когда сервисов будут не десятки (10-20-50), а сотни (200, 400…2000), то традиционные, “классические” контракты перестают работать в функциональном смысле. И тогда уже возникает необходимость модернизации контрактов под микросервисную архитектуру. Разработан шаблон работы для разработчиков, в котором они и “конечные пользователи” микросервиса меняются местами — этот подход называется consumer driven contacts. Теперь запросы делают внешние пользователи. Это можно представить как такого рода беседу:
Пользователь 1: “Я слышал, вы поставляете яблоки. Мне нужны маленькие и зелёные”.
Пользователь 2: “А мне нужны огромные красные яблоки”.
Пользователь N: “А мне нужно, чтобы вы привезли три тонны яблок”.
Таким образом получается, что пользователи создают контракты, задают требования и направляют их к провайдеру, который их реализует. В чем плюс? Так как у каждого сервиса достаточно ограниченное количество потребителей, получить от каждого по три спецификации и реализовать их гораздо проще, чем пытаться угадать, какие именно “яблоки” нужно предоставить в каждом конкретном случае и что еще им может понадобиться к этим “фруктам” дополнительно.
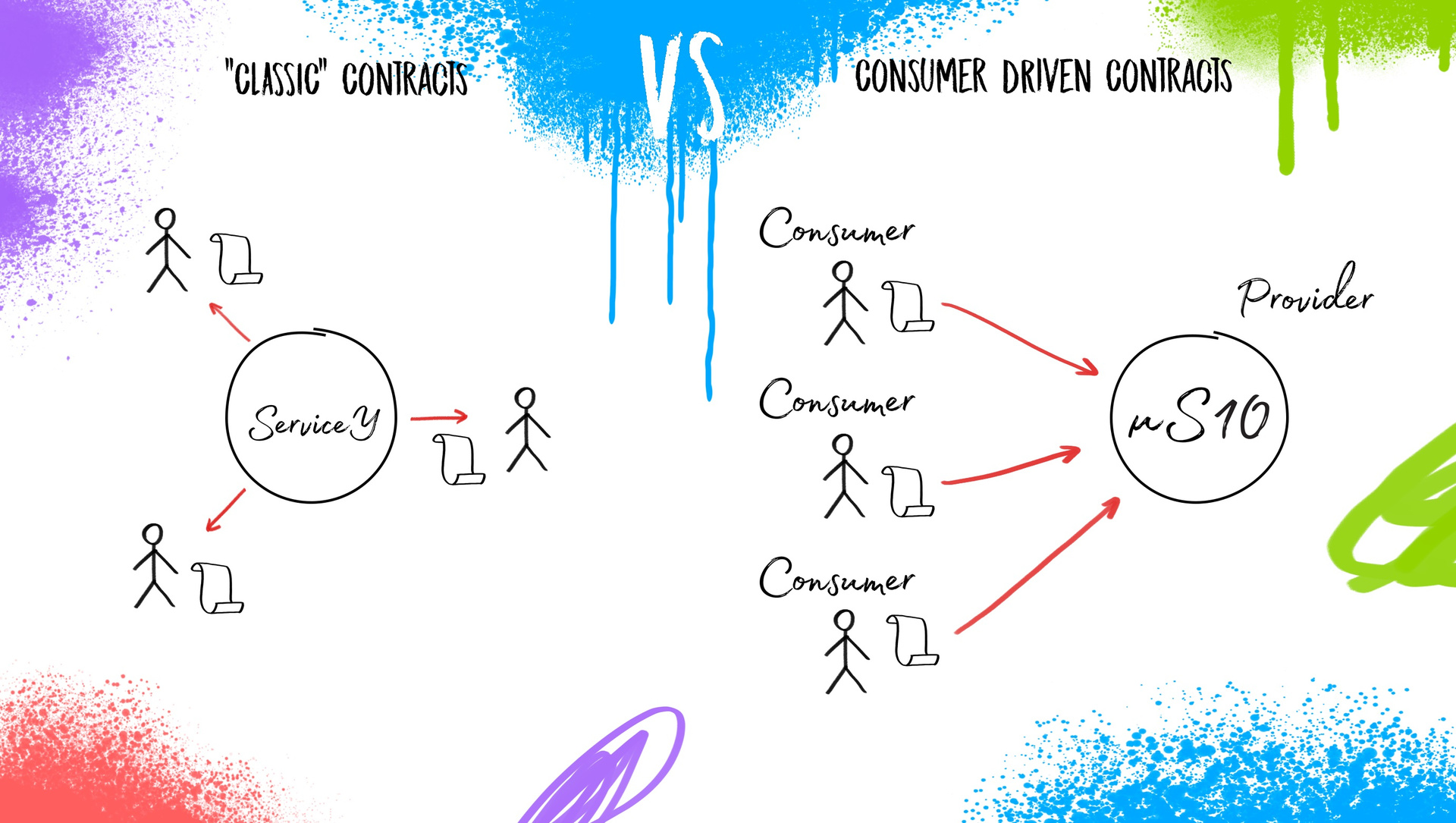
Вот для этого подхода мы, как отдел обеспечения качества, должны предоставить достойный ответ в области тестирования так, чтобы не замедлить процесс быстрых выкаток микросервисов.
Предикаты для CDC-testing (Consumer Driven Contracts)
Без чего нельзя начать работать по принципам CDC-testing? Первое. У нас не получится помочь, если мы видим что у нас в разработке не соблюдается процесс работы по контрактам. Вторая вещь более техническая: это система post-commit (post-PR, если хотите) hook-ов, которая обрабатывает этот поток общения между девелоперами с помощью контрактов и сигнализирует нашей системе тестирования об их обновлении, удалении, появлении новых. Соответственно, заводятся соответствующие таски в Jira, чтобы автоматизаторы успели это все “переварить”. К этому базовому процессу можно добавить еще все что угодно — дополнительные проверки, процессные примочки, но без контроля изменения контрактов взаимодействия между микросервисами жить будет достаточно сложно. Выполнив в каком-то виде эти два пункта, мы можем приступить к имплементации.
Имплементация автоматизации под CDC
В основу нашей системы автоматизации тестирования ляжет такое решение, как PACT-фреймворки. Что нужно о них знать? Это протокольное взаимодействие с API: JSON over HTTP, в этом нет ничего сложного. Эти решения взаимодействуют с нашими микросервисами и дают некоторый дополнительный функционал для изоляции и организации тестирования. Что сказать еще? Я видел, как это реализовано в том или ином виде на семи языках программирования (Java, Javascript, Ruby, Python, Go, .NET, Swift). Но если вашего нет в этом списке, не пугайтесь: можно взять базовую библиотеку и сделать свой велосипед, или написать что-то подобное тому, что уже реализовано.
Что ещё нас ждёт почти в 100% случаев? Первое — это мокирование внешних сервисов. Проблема в том, что сложно поддерживать релевантность того, как себя ведет внешний сервис, и поддерживать это во всех заглушках. Как решать эту проблему? Это зависит от вас. Скорее всего, потребуется направить на это больше ресурсов или ограничить покрытие тестами. И второе: сэмплированные базы данных. Понадобится нарезать боевые базы данных в облегченном виде так, чтобы в них были все необходимые данные для тестирования в рамках нашей системы. Тогда получится наглядный релевантный результат.

Идем далее. Первое, что я сразу захотел сделать в этом проекте — это информативное логирование. Всегда необходима репрезентативность итогов тестирования. Простая истина: если результаты невозможно прочитать и понять — их никто не будет смотреть. Надо сказать, что базовое логирование в PACT-фреймворках реализовано очень убого.
Я предпочел бы вынести его в отдельный модуль, сделать обёртку и навертеть там то, что нам нужно. В первую очередь сделать разделение ошибок по источникам их появления. Далее — всё, что вы можете реализовать, например, решения наподобие Allure (решение от компании Яндекс для повышения простоты анализа результатов тестирования). Делать можно что угодно, но необходимость информативных логов нужно учесть.
Следующий, возможно, “капитанский” момент — это Config Reader. Но в рамках тестирования микросервисной архитектуры это может быть немного заковыристой вещью. Для Config Reader у нас есть два источника. Первый — это PACT-файлы, а второй — State.

Что это такое PACT-файл? Это не какой-то шифрованный бинарник, а обычный JSON-файл, который имеет специфичную структуру. В нем выделяется consumer, provider (т.е. кто именно и с кем взаимодействует в рамках этого контракта и в какой роли). Далее описываются взаимодействия (это делают разработчики): я — consumer, и хочу от этого сервиса (provider), чтобы он отдавал мне “маленькие зеленые яблоки”; жду такой-то код ответа, статус, header, body и так далее. Есть поле description — это просто описание, повод напомнить разработчикам о чём шла речь в контракте, какой смысл в него вкладывался.
И самое интересное — это State Provider. Что это? По сути, это состояние, в котором должен пребывать тестируемый микросервис на момент обращений к нему по конкретной итерации тестирования, по конкретному запросу. В States могут описываться как SQL-запросы (или другие механизмы приведения сервиса в некоторое состояние), так и создание каких-то данных в нашей сэмплированной базе. States — это сложный модуль, который может содержать в себе всякого рода сущности, приводящие наш сервис в нужное надлежащее состояние.
Важно отметить, что здесь появляется Suite runner (см. схему ниже). Это — та сущность, которая будет отвечать за запуск и конфигурирование тестов в удобном для разработчика/тестировщика виде. Её можно и не писать, но я бы все-таки выделил этот момент, так как сложно предвидеть какие тесты необходимо будет прогонять в тот или иной момент времени на проекте. В итоге у нас получается вот такое ядро автоматизации тестирования под микросервисную архитектуру:

Теперь самое важное — внедрение. Мы должны предоставить эту схему с требованиями по наличию описанных контрактов разработчикам. Что мы получаем после?
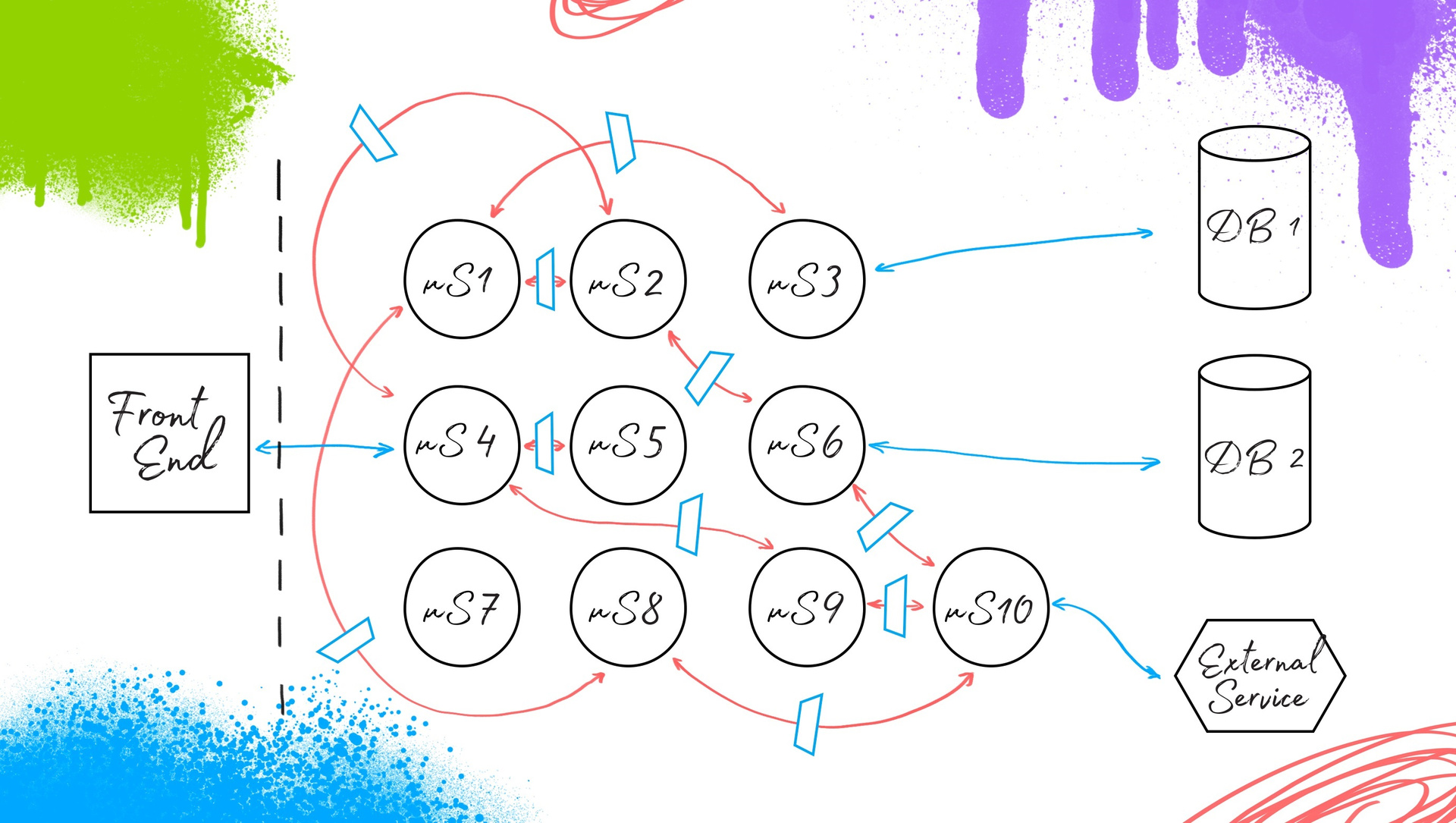
У нас есть информация по каждому сервису: о том, что он выдает и то, что он запрашивает у своих “соседей”. Соответственно, с помощью нашей системы автоматизации тестирования, с помощью PACT-файлов мы изолируем наш микросервис для обеспечения изоляции его тестирования вне зависимости от внешних сервисов, с которыми он интегрирован. И предоставляем states через моки, заглушки, сэмплированные базы данных, или напрямую как-то изменяем сервис. Получаем, соответственно, изолированное тестирование. Вуаля: у нас есть ответ на вопрос, что делать с автоматизацией тестирования во время перехода от монолита к микросервисной архитектуре.

Что учесть при имплементации?
Что же нужно учесть при имплементации? Первое — это использование контейнеризации и виртуализации в процессе сборки/деплоя микросервиса. И наша система автоматизации тестирования точно так же закручивается в контейнер. Как будете обеспечивать взаимодействие микросервиса и системы автоматизации тестирования — это уже не столь важно: как удобнее, так и делайте.
Второе — актуализация файлов требований по контрактам. Есть такая проблема, что требования консьюмеров к провайдеру начинают копиться, а разработчики занимаются только тем, что им насущно необходимо сейчас. Здесь нужно на уровне тест-менеджмента или управления продуктом ставить задачу разработчикам: например, час в неделю работать с этим “хвостом”, чтобы он не разрастался. Конечно, эти тесты быстрые, они могут проходить за несколько секунд. Но если их количество будет измеряться тысячами, это будет осложнять актуализацию тестирования. А мы со своей стороны, через систему commit hook-ов будем получать информацию и убирать ненужные автотесты. По сути, CDC — это documentation-driven development, если так можно выразиться.
Третье: нужно ввести обязательно ввести в эту работу процесс актуализации states и data suites. Что такое data suites? Девелоперы в процессе разработки пишут некоторые базовые сценарии взаимодействия. К примеру: “мне нужен такой запрос и такой ответ”. А обо всем остальном — в каких рамках он должен существовать, какие значения параметров возможны, а какие — нет, забывают. Это необходимо проверять. И сюда мы должны входить с нашим data-driven подходом к тестированию, реализуя это в нашем конфигураторе: позитивные, пограничные и негативные тесты, для того, чтобы обеспечить отказоустойчивость работы нашей микросервисной архитектуры на продакшене. Без этого она вряд ли будет работать, любой шаг вправо/влево — и ошибка взаимодействия.
Соответственно при появлении новых pact-файлов, через hook мы получаем таски и наполняем новые/изменённые взаимодействия большим количеством наборов данных в interactions, что равно целому ряду проведенных тестов. Мы можем наполнять и редактировать interactions вручную, а можем делать генераторы, которые будут параметризировать их и гнать тесты.
Что касается States: если брать автоматизацию тестирования веба, то это preconditions, setUps, FixTure; для микросервисов есть проблема — готового механизма нет: надо продумать то, как вы будете сопрягать изменение названия States в PACT-файлах в этом модуле. Самый простой из механизмов — использовать Aliases, по сути KDT (keyword driven testing), говоря на языке автоматизации тестирования. Рассказать сейчас про более красивое и элегантное решение не готов: пока что его не придумал.

Итоги
- То, что касается post-commit-hooks, автоматизации мониторинга, появления и изменения, удаления контрактов между сервисами — это все необходимо автоматизировать, это часть системы. Я бы сказал, что это кусочек ядра, который стоит на уровне репозиториев.
- CDC-паттерн для разработчиков обязателен. Это фундамент, без него ничего работать не будет.
- Вы заметите снижение склонности системы к появлению дефектов. По сути, у нас все её части окутаны изолирующим тестированием. Мы быстро локализуем дефекты, их быстро исправляют, мы располагаем высоким тестовым покрытием. Если будут появляться дефекты на уровне системного тестирования, они, скорее всего, будут связаны с фронт-эндом или какими-то внешними сервисами.
- Вы имеете возможность уйти от ручного тестирования изменений. Ключевые моменты: быстрое и изолированное тестирование. Тогда мы получим профит от того, что мы можем хорошо локализовать проблему или дефект.
P.S.
Если вы больше любите не читать, а смотреть видео, то эта информация доступна в формате доклада по ссылке. А в конце августа у нас в Avito пройдет тематический митап для профессионалов в области тестирования. Поговорим о векторах развития систем автоматизации в целом, обсудим применение прикладных инструментов и их влияние на изменение инфраструктуры тестирования. Если интересно — следите за обновлениями на нашей странице в FB, или напишите в комментариях: дадим знать, когда будут подробности о мероприятии.
