 Badoo — крупнейшая в мире социальная сеть для знакомств с новыми людьми, насчитывающая 190 миллионов пользователей.
Badoo — крупнейшая в мире социальная сеть для знакомств с новыми людьми, насчитывающая 190 миллионов пользователей. Все данные хранятся в двух дата-центрах — европейском и американском. Некоторое время назад мы исследовали качество интернет-соединения у наших пользователей из Азии и обнаружили, что для 7 миллионов пользователей наш сайт будет загружаться в 2 раза быстрее, если мы переместим их из европейского дата-центра в американский. Перед нами впервые встала задача крупномасштабной миграции данных пользователей между дата-центрами, с которой мы успешно справились: мы научились перемещать 1,5 миллиона пользователей за один рабочий день! Мы смогли перемещать целые страны! В первой части мы подробно расскажем о поставленной перед нами задаче и о том, какого результата мы достигли.
Архитектура Badoo
Об архитектуре Badoo было много рассказано на различных конференциях и на самом Хабре, но мы всё же повторим основные моменты, которые важны для понимания нашей задачи. В Badoo для отдачи веб-страничек используется стандартный стек технологий: Linux, nginx, PHP-FPM (разработка Badoo), memcached, MySQL.
Почти все данные пользователей находятся на паре сотен MySQL-серверов и распределены («расшардены») по ним с использованием «самописного» сервиса под названием authorizer. Он хранит в себе большую таблицу соответствий id пользователя и id сервера, на котором находится пользователь. У нас не используются «остатки от деления» и другие похожие способы распределения пользователей по серверам, поэтому мы можем без особых проблем перемещать пользователей между серверами баз данных: это изначально заложено в архитектуре Badoo.

Помимо MySQL, у нас есть множество C/C++ сервисов, которые хранят различные данные: сессии, даты последнего захода на сайт, фотографии пользователей для голосования, основные данные всех пользователей для осуществления поиска.
У нас также есть сервис, который обслуживает раздел «Знакомства». Он отличается от других тем, что существует в одном экземпляре для каждой страны. Просто он потребляет так много оперативной памяти, что все его данные не могут физически поместиться на один сервер, даже если поставить туда 384 Гб. При этом он «живет» только в «своем» дата-центре.
Плюс ко всему у нас есть ряд «центральных» баз данных MySQL, которые хранят общую информацию обо всех пользователях, и отдельные базы для биллинга, которые тоже хранят информацию сразу по всем пользователям Badoo. Помимо этого, у нас имеются отдельные хранилища для загруженных фотографий и видео, о которых будет отдельная статья. Эти данные тоже должны быть перемещены.
Постановка задачи
Задача формулируется очень просто: перенести за один рабочий день данные пользователей из целой страны, и чтобы во время миграции эти пользователи могли пользоваться сайтом. Самая большая страна из тех, что мы «мигрировали» — это Таиланд, в котором у нас зарегистрировано порядка 1,5 млн пользователей. Если поделить это число на 8 рабочих часов (плюс обед), то получим требуемую скорость миграции, которая составляет около 170 тысяч пользователей в час.
Требование мигрировать страну за один рабочий день продиктовано тем, что в это время может случиться всё что угодно. Например, могут «лечь» или начать тормозить какие-то сервера или сервисы, и тогда надо будет «на живую» править код, чтобы уменьшить создаваемую на них нагрузку. Также возможны ошибки в коде миграции, которые приведут к проблемам у пользователей, и тогда должна быть возможность быстро увидеть это и приостановить (или даже откатить) процесс. Одним словом, при осуществлении такой масштабной операции по переносу пользователей обязательно требуется присутствие «оператора», который будет контролировать происходящее и вносить нужные коррективы во время работы.
Технически для каждого пользователя нужно сделать выборки из всех таблиц всех инстансов MySQL, на которых могут находиться данные об этом пользователе, а также перенести данные, которые хранятся в C/C++-сервисах. Причём для одного из сервисов нужно перенести сам демон, а не данные между запущенными инстансами демона в обоих дата-центрах.
Задержка передачи данных между дата-центрами составляет около 100 мс, поэтому операции должны быть оптимизированы таким образом, чтобы данные загружались потоком, а не большим количеством мелких запросов. Во время миграции время недоступности сайта для каждого пользователя должно быть минимальным, поэтому процесс должен осуществляться для каждого пользователя по отдельности, а не большой пачкой. Время, на которое мы ориентировались — это не более 5 минут недоступности сайта для конкретного пользователя (желательно 1-2 минуты).
План работы
Исходя из того, что нам нужно было мигрировать 170 000 пользователей в час, и время миграции каждого пользователя должно составлять около 2-3 минут, мы рассчитали количество параллельно исполняемых потоков, которые потребуются для выполнения этих условий. Каждый поток может перенести в среднем 25 пользователей за час, поэтому общее число потоков получилось 6 800 (т.е. 170 000 / 25). На деле мы смогли ограничиться «всего лишь» 2 000 потоков, т.к. бóльшую часть времени пользователь просто «ожидает» наступления различных событий (например, MySQL-репликации между дата-центрами). Таким образом, каждый поток брал в обработку трёх пользователей одновременно и переключался между ними, когда кто-то из них переходил в состояние ожидания чего-либо.
Миграция каждого пользователя состояла из множества последовательных шагов. Выполнение каждого шага начиналось строго после окончания предыдущего и при условии, что последний был выполнен успешно.
Также каждый шаг должен быть повторяемым, или, «говоря по-русски», идемпотентным. Т.е. выполнение каждого шага может быть прервано в любой момент в виду различных причин, и он должен уметь определить, какие операции ему осталось доделать, и выполнить эти операции корректно.
Это требуется для того, чтобы не терять информацию пользователей в случае аварийной остановки миграции и при временных сбоях внутренних сервисов или серверов баз данных.
Структура и последовательность наших действий
Подготовительные шаги
Помечаем пользователя как «мигрируемого» в данный момент и дожидаемся окончания его обработки фоновыми скриптами, если такие есть. Этот шаг у нас занимал около минуты, в течение которой можно мигрировать другого пользователя в том же потоке.
Миграция данных биллинга
Во время миграции страны мы полностью отключали в ней биллинг, поэтому никаких особых действий и блокировок для этого не требовалось — данные просто переносились из одной центральной MySQL-базы в другую. К этой базе устанавливалось MySQL-подключение от каждого потока, поэтому суммарное количество подключений к базе биллинга у нас составляло более 2 000.
Миграция фотографий
Здесь мы немного «считерили», потому что нашли способ относительно легко перенести фотографии заранее и отдельно. Поэтому для большинства пользователей этот шаг просто проверял, что у них не появилось новых фотографий с момента переноса.
Заливка основных данных пользователя
В этом шаге мы формировали SQL-дамп данных каждого пользователя и применяли его на удаленной стороне. При этом старые данные в этом шаге не удалялись.
Обновление данных в сервисе authorizer
Сервис authorizer хранит соответствия между id пользователя и id сервера, и пока мы не обновим данные в этом сервисе, скрипты будут ходить за данными пользователя в старое место.
Удаление данных пользователя со старого места
Очищаем с помощью запросов DELETE FROM данные пользователя на исходном MySQL-сервере.
Шаги по переносу данных из центральных баз
Одна из центральных баз под красноречивым названием Misc (от англ. miscellaneous ― разное) содержит очень много различных таблиц, и для каждой из них мы делали по одному SELECT и DELETE на пользователя. Мы «выжимали» из бедной базы 40 000 SQL-запросов в секунду и держали открытыми к ней более 2 000 соединений.
Шаги по переносу данных из сервисов
Как правило, все данные итак содержатся в базе данных, а сервисы лишь позволяют быстро получать доступ к ним. Поэтому для большинства сервисов мы просто удаляли данные из одного места и заново наполняли их информацией из базы данных, которые уже находились в новом месте. Однако один сервис мы просто переносили целиком, а не по пользователям, потому что данные в нём хранились в единственном экземпляре.
Ожидание репликации
Наши базы данных реплицируются между дата-центрами, и пока репликация не «доедет», данные пользователя находятся в несогласованном состоянии в разных дата-центрах. Поэтому нам приходилось ждать окончания репликации для каждого пользователя, чтобы все работало корректно и данные были согласованы между собой. А чтобы не терять время на этом шаге (от 20 секунд до минуты), он использовался для миграции других пользователей в этот момент.
Завершающие шаги
Помечаем пользователя как закончившего миграцию и разрешаем ему логиниться на сайте, уже в новом дата-центре.
Перенос данных MySQL

Как уже говорилось ранее, мы храним данные пользователей на MySQL-серверах, которых примерно по полторы сотни на каждый дата-центр. На каждом сервере находится несколько баз данных, в каждой из которых находятся тысячи таблиц (в среднем мы стараемся иметь по одной таблице на 1000 пользователей). Данные устроены таким образом, чтобы либо вообще не использовать автоинкрементные поля, или хотя бы не ссылаться на их в других таблицах. Вместо этого в качестве первичного ключа используется комбинация user_id и sequence_id, где user_id — это идентификатор пользователя, а sequence_id — это счетчик, который автоматически увеличивается и является уникальным в пределах одного сервера. Таким образом, записи про каждого пользователя могут быть свободно перемещены на другой сервер без потери ссылочной целостности и необходимости строить соответствия между значениями старых и новых автоинкрементных полей.
Перемещение данных сделано по одной и той же схеме для большинства MySQL-серверов (заметим, что в случае любых ошибок весь шаг аварийно завершается и стартует заново через небольшой интервал времени):
- Идем на «сторону-приемник» и проверяем, нет ли там уже данных пользователя. Если есть, значит, заливка данных прошла успешно, но выполнение шага не было завершено корректно.
- Если данных на удаленной стороне нет, делаем SELECT из всех нужных таблиц с фильтрацией по пользователю и формируем SQL-дамп, содержащий BEGIN в начале и COMMIT в конце.
- Заливаем дамп через SSH на «прокси» на удаленной стороне и применяем его с помощью консольной утилиты mysql. Может так случиться, что запрос COMMIT пройдет, но ответ мы не сможем получить, например, из-за сетевых проблем. Для этого мы сперва проверяем, не залился ли дамп в предыдущей попытке. Причём в некоторых базах данных отсутствие данных для пользователя является нормальной ситуацией, и чтобы иметь возможность проверить, выполнялся ли перенос данных, мы в таких случаях добавляли INSERT в специальную таблицу, по которой при необходимости делали проверку.
- Удаляем исходные данные с помощью DELETE FROM с теми же WHERE, которые были в SELECT-запросах. Как правило, условия WHERE содержали в себе user_id, а на части таблиц это поле не являлось частью первичного ключа в силу разнообразных причин. Там, где было возможно, индекс был добавлен. Там, где это оказалось затруднительно или нецелесообразно, при удалении данных сначала делалась выборка по user_id, а потом удаление по первичному ключу, что позволило избежать блокировок на чтение и существенно ускорить процесс.
Если мы точно знаем, что никогда до этого не приступали к соответствующему шагу, то мы пропускаем проверку наличия данных на удаленной стороне. Это позволяет выиграть нам около секунды для каждого сервера, на который мы переносим данные (что происходит из-за задержки в 100 мс для каждого отправляемого пакета).
Во время миграции мы столкнулись с рядом проблем, о которых хотим рассказать.
Автоикрементные поля (auto_increment)
В базе данных биллинга активно используются автоинкрементные поля, поэтому для них пришлось писать сложную логику «маппинга» старых id в новые.
Сложность заключалась в том, что данные из таблиц, где в первичный ключ входит только описанный выше sequence_id, нельзя просто перенести, так как sequence_id уникален только в пределах сервера. Заменить sequence_id на NULL, вызвав тем самым генерацию нового значения автоинкремента, тоже нельзя, поскольку, во-первых, генерация sequence_id производидтся вставкой данных в одну таблицу, а полученное значение используется в другой. А во-вторых, на таблицу, использующую sequence_id, ссылаются другие таблицы. То есть необходимо получить нужное количество значений автоинкрементного поля на сервере, куда переносятся данные, заменить старые sequence_id на новые в данных пользователя и записать готовые INSERT’ы в файл, который впоследствии будет применён консольной утилитой mysql.
Для этого мы на принимающем сервере открывали транзакцию, делали необходимое количество вставок, вызывали mysql_insert_id(), который в случае вставки нескольких строк в одной транзакции возвращает значение автоинкремента для первой строки, после чего откатывали транзакцию. При этом после отката транзакции автоинкремент будет оставаться увеличенным на число вставленных нами строк, если только не произойдёт перезагрузки сервера базы данных. Получив необходимые нам значения автоинкремента, мы формировали соответствующие запросы на вставку, в том числе в таблицу, отвечающую за генерацию автоинкремента. Но в этих запросах уже явно были указаны значения автоинкремента, чтобы заполнить дыры, образовавшиеся в нем после отката транзакции.
Max_connections и нагрузка на MySQL
Каждый поток создавал по одному MySQL-соединению на сервер, с которым ему приходилось иметь дело. Поэтому на всех центральных MySQL-серверах мы держали по 2 000 соединений. При большем количестве соединений MySQL начинал вести себя неадекватно, вплоть до падения (мы используем версии 5.1 и 5.5).
Однажды во время миграции упал один из центральных MySQL-серверов (один из тех, на которые приходилась очень большая нагрузка). Миграция была немедленно аварийно остановлена, и мы стали выяснять причину падения. Оказалось, что на ней просто «вылетел» RAID-контроллер. И хоть администраторы сказали, что это не связано с нагрузкой, которую мы дали на этот сервер, но «осадочек остался».
InnoDB, MVCC и DELETE FROM: подводные камни
Поскольку мы храним все данные в InnoDB и все перенесенные данные сразу удалялись, у нас сильно начали тормозить все скрипты, которые разгребают очереди, находящиеся в таблицах на некоторых серверах. Мы с удивлением наблюдали, как SELECT из пустой таблицы занимал минуты. MySQL purge thread не успевал очищать удаленные записи, и несмотря на то, что таблицы с очередями были пусты, в них было очень много удаленных записей, которые физически еще не были удалены и просто пропускались MySQL при выборке. Количественную характеристику длины очереди на очистку записей можно получить, набрав SHOW ENGINE INNODB STATUS и посмотрев на строчку History list length. Самое большое значение, которое мы наблюдали — несколько миллионов записей. Рекомендуем с большой осторожностью удалять много записей из InnoDB-таблиц с помощью DELETE FROM. Намного лучше этого избегать и использовать, например, TRUNCATE TABLE, если это возможно. Запросы вида TRUNCATE TABLE полностью очищают таблицу, и эти операции являются DDL, поэтому удаленные записи не складываются в undo/redo log (InnoDB не поддерживает транзакции для DDL-операций).
Если же вам нужно после удаления всех данных с помощью DELETE FROM делать выборку из таблицы, то постарайтесь наложить на первичный ключ условие BETWEEN. Например, если вы используете auto_increment, выберите из таблицы MIN(id) и MAX(id), после чего выбирайте все записи между ними — это существенно быстрее, чем выбирать записи с каким-то лимитом или только с одним из условий вида id > N или id < N. Запросы, которые получают MIN(id) и MAX(id), будут выполняться очень долго, потому что InnoDB будет пропускать удаленные записи. Но зато запросы по диапазонам ключей будут выполнены с такой же скоростью, как и обычно — удаленные записи при таких запросах в выборку попадать не будут.
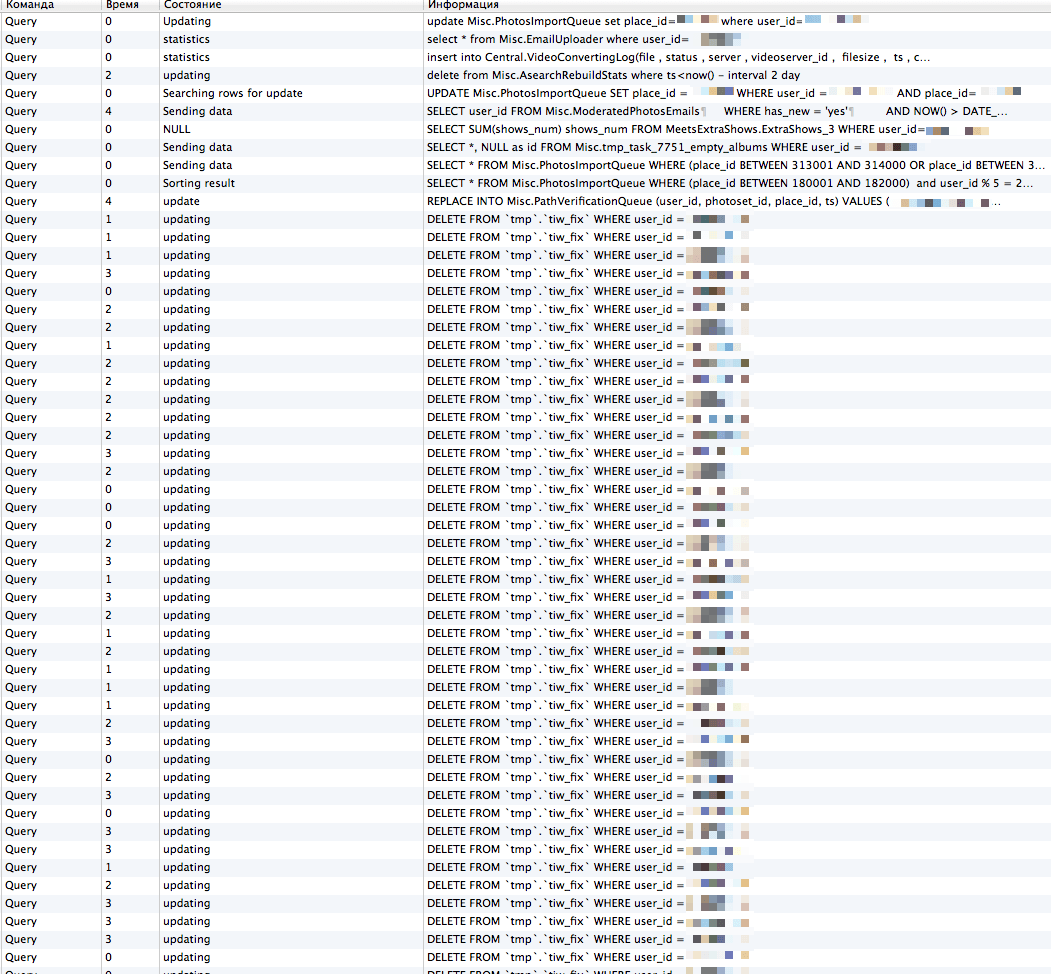
Также мы с удивлением наблюдали много «висящих» запросов вида DELETE FROM WHERE user_id = , где у всех запросов одна и та же, и при этом в этой таблице нет индекса по user_id. Как оказалось, MySQL версии 5.1 (и в меньшей степени 5.5) обладает очень плохой масштабируемостью таких запросов, если делается FULL SCAN таблицы при удалении записей и уровне изоляции REPEATABLE READ (по умолчанию). Происходит очень высокая конкуренция блокировок за одни и те же записи, что приводит к лавинообразному росту времени обработки запроса.
Одно из возможных решений проблемы — поставить уровень изоляции READ COMMITED для транзакции, которая удаляет данные, и тогда InnoDB не будет ставить блокировки на те строки, которые не подходят под условие WHERE. Чтобы проиллюстрировать, насколько это была серьёзная проблема, приведем скриншот, снятый во время миграции. Таблица tmp.tiw_fix на скриншоте содержит всего около 60 записей (!) и не содержит индекса по user_id.
Распределение пользователей по потокам
Изначально мы распределяли пользователей по потокам равномерно, без учета того, на каком сервере находится конкретный пользователь. Также в каждом потоке мы оставляем открытые подключения ко всем MySQL-серверам, с которыми нам пришлось встретиться для миграции пользователей, выделенных соответствующему потоку. В итоге мы получили еще две проблемы:
- Когда какой-то MySQL-сервер начинал тормозить, то миграция пользователей, живущих на этом сервере, замедлялась. Поскольку все остальные потоки продолжали исполнение, они постепенно тоже доходили до пользователя, живущего на проблемном сервере. Постепенно все большее число потоков скапливалось на этом сервере, и он начинал тормозить еще сильнее. Чтобы сервер при этом не упал, мы вносили временные патчи в код прямо во время работы, с помощью различных «костылей» ограничивая нагрузку на этот сервер.
- Поскольку мы держали открытыми MySQL-соединения в каждом из потоков ко всем нужным MySQL-серверам, мы постепенно приходили к тому, что каждый поток имел большое количество открытых подключений ко всем MySQL-серверам, и мы начинали упираться в max_connections.
В конце концов мы изменили алгоритм распределения пользователей по потокам и каждому потоку выделяли пользователей, которые живут только на одном MySQL-сервере. Таким образом, мы решили сразу и проблему лавинообразного роста нагрузки в случае «тормозов» этого сервера, а также проблему со слишком большим количеством одновременных подключений на некоторых слабых хостах.
Продолжение следует…
В следующих частях мы расскажем про то, каким образом мы осуществляли предварительную миграцию фотографий пользователей и какие структуры данных использовали для ограничения создаваемой нагрузки на сервера с фотографиями. После этого мы более подробно опишем, как нам удалось скоординировать работу 2 000 одновременно исполняющихся потоков миграции на 16 серверах в двух дата-центрах и какие технические решения использовались, чтобы заставить всё это работать.
Юрий youROCK Насретдинов, PHP-разработчик
Антон antonstepanenko Степаненко, Team Lead, PHP-разработчик
