
Продолжаем знакомиться с инструментом pg_probackup.
В первой части мы установили pg_probackup, создали и настроили экземпляр, сняли два бэкапа — полный и инкрементный в режиме DELTA, научились просматривать и изменять конфигурацию экземпляра. Получили список бэкапов, написали скрипт (bkp_base.sh), производящий резервное копирование кластера и отправку результатов последней операции по снятию бэкапа в систему мониторинга. Сегодня будем решать не менее интересные задачи.
Задача 2
Дано: У нас есть два сервера, на первом у нас располагается наша база данных (имя хоста srv_db1, пользователь postgres), а на втором мы будем хранить бэкапы (имя хоста srv_bkp, пользователь backup_user). Но помимо бэкапов на этом же сервере мы будем хранить копии журналов предварительной записи, чтобы иметь возможность восстановления на произвольный момент времени (Point-in-time recovery) в течение последних 3х дней.
Решение:
Для того, чтобы появилась возможность восстановления на выбранный момент времени (точку восстановления), мы должны иметь резервную копию, сделанную до точки восстановления, а также все WAL файлы от момента начала резервной копии и до точки восстановления.
Резервные копии у нас уже есть, осталось настроить архивирование WAL на srv_bkp.
Подключаемся к srv_db1 пользователем postgres и выполняем следующие команды:
ssh-keygen -t rsa ssh-copy-id backup_user@srv_bkp
Модифицируем файл ~/.ssh/autorized_keys на srv_bkp:
command="pg_probackup-12 agent" ssh-rsa AAAA....
Возвращаемся на srv_db1, необходимо включить режим архивирования (archive_mode) и настроить параметр archive_command. Он содержит команду, с помощью которой производится архивация заполненного сегмента WAL.
psql -c 'show archive_mode'
если вернулось off, то меняем на on
psql -c 'alter system set archive_mode = on'
Для того, чтобы изменение применилось, необходимо перезагрузить PostgreSQL, но пока отложим это действие и настроем еще один параметр.
Если поток WAL файлов достаточно большой, то скоро на сервере резервных может закончиться место, поэтому мы можем вставить опцию --compress в строку archive_command, тогда файлы журналов будут сжиматься перед отправкой на srv_bkp. И нам не нужно будет беспокоиться о том, что эти файлы нужно будет отдельно распаковывать при восстановлении — pg_probackup умеет работать со сжатыми файлами.
alter system set archive_command = 'pg_probackup-12 archive-push -B /home/backup_user/backup_db --instance=db1 --wal-file-path=%p --wal-file-name=%f --remote-host=srv_bkp --remote-user=backup_user --compress';
Вот теперь можно и рестартовать.
То, что мы делали в первой задаче называется автономной резервной копией. Называется оно так потому, что такая копия содержит в себе все необходимые для её восстановления WAL файлы. В текущей же задаче мы переходим от автономных копий к архивным, такие копии не содержат внутри себя необходимых журналов, но это не беда, ведь мы собираемся сохранять все нужные нам WAL файлы в архив. При восстановлении из архивных копий WAL файлы будут копироваться из архива.
Поскольку в рассматриваемой ситуации мы переходим от автономных резервных копий (сделанных в режиме stream) к архивным (в режиме archive), то может возникнуть ситуация, в которой мы сделали копию, когда архивный режим ещё не был включён, после чего часть сегментов WAL уже оказалась удалена. Это означает, что первая резервная копия после перехода на архивный режим не может быть сделана в режиме PAGE, т.к. отрезок WAL в архиве между прошлой и текущей копией может не является целостным.
Сделаем это, воспользовавшись скриптом созданным в первой задаче:
./bkp_base.sh DELTA
После чего создадим свой первый бэкап в режиме PAGE
./bkp_base.sh PAGE
Напомню, что доступно три инкрементальных режима: PAGE, DELTA и PTRACK. Они отличаются друг от друга способами получения необходимой информации об изменившихся страницах:
- DELTA — перечитывает файлы данных и те страницы, которые были изменены с момента последнего бэкапа попадают в новый бэкап
- PAGE — перечитывает все WAL сегменты, накопленные с момента предыдущего бэкапа, создает карту изменившихся блоков и копирует их в новый бэкап
- PTRACK — что-то типа механизма Block Change Tracking в Oracle — создается специальная карта, в котором отслеживается какие именно блоки были изменены в базе данных. Этот режим требует дополнительных настроек (установки дополнительного расширения и т.д.). Достаточно подробно этот механизм рассмотрен в документации, поэтому не будем на нём останавливаться.
А теперь давайте подумаем, резервной копии для того, чтобы с нее можно было восстановиться необходимы WAL файлы, созданные за время создания бэкапа. Т.е. если инкрементальный бэкап делается у нас 30 минут и за эти 30 минут было создано 10 ГБ WAL, то только эти 10 ГБ и нужны для того, чтобы мы могли консистентно восстановиться из него. Все остальные WAL файлы нужны только для целей восстановления на выбранную точку по времени (Point-in-time recovery).
В задаче было указано, что мы хотим иметь возможность восстановиться на любой момент времени за последние 3 дня. То есть все WAL за этот период необходимо сохранить, помимо этого необходимо сохранить все WAL которые нужны для восстановления из предыдущих бэкапов, но все остальные WAL файлы нам хранить не нужно!
И, если для удаления устаревших WAL мы можем использовать команду find, дополнив её mtime и -exec rm {}, то определение, какой именно WAL сегмент нужен для консистентного восстановления той или иной резервной копии, становится не совсем простой задачей. Хорошо, что разработчики подумали об этом и добавили параметр --wal-depth, с помощью которого можно задать глубину хранения WAL, исчисляемую в резервных копиях.
Схематично это можно описать так:
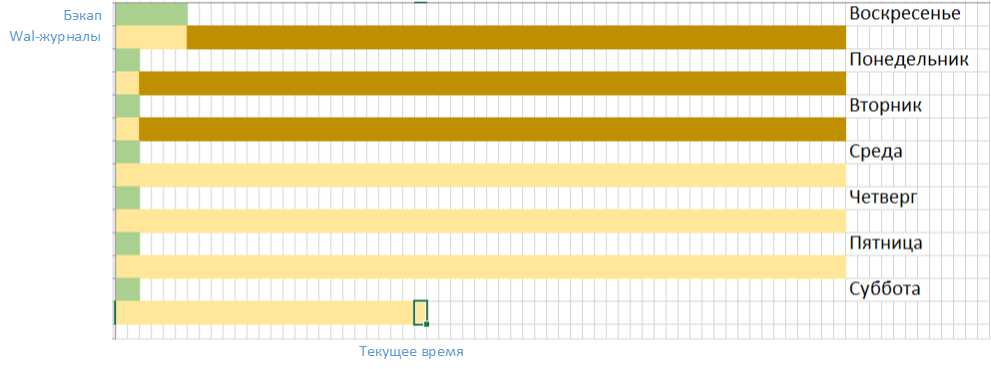
Обратите внимание — сейчас где-то середина субботы, это значит, что все WAL файлы, не нужные для восстановления бэкапов старше трёх дней, мы можем удалить (коричневый цвет на графике). Желтым отмечены те WAL, которые ещё нужны. Тут может возникнуть закономерный вопрос — но ведь уже середина субботы, значит часть утренних логов созданных в среду уже тоже не нужна, и её можно удалить. Да, это так, и вы можете настроить удаление лишнего WAL хоть каждую минуту, но в нашей статье мы будем удалять логи вместе с созданием бэкапов, поэтому несмотря на то, что они уже не попадают в политику удержания, они будут удалены при создании следующего бэкапа.
Поменяем настройки инстанса db1 — добавим время жизни WAL файлов
pg_probackup set-config --instance db1 --wal-depth=3
Проверим, что настройки применились:
pg_probackup show-config --instance=db1 | grep wal-depth
Добавим флаг --delete-wal в команду создания резервной копии в скрипте bkp_base.sh, а также уберём ключ --stream, ведь мы переходим от автономных резервных копий к архивным
pg_probackup backup --instance=db1 -j 2 --progress -b $1 --compress --delete-expired --delete-wal
На текущий момент у нас настроено создание архивных резервных копий на отдельный сервер. Также сюда складываются журнальные файлы, что даёт нам возможность воспользоваться восстановлением не только на определённый бэкап, но и осуществить Point-in-time recovery — восстановление на определённую точку времени.
Поскольку теперь у нас есть архив WAL файлов, то мы можем использовать режим PAGE для создания инкрементальных бэкапов, напомню, что в этом режиме изменения относительно предыдущего бэкапа вычисляются не по файлам данных, а по WAL, накопленным с момента предыдущего бэкапа.
P.S. Только для учебных целей! Давайте создадим табличку в базе данных на сервере srv_db1:
psql -c 'create table timing(time_now timestamp with time zone)'
После чего запишем в crontab следующую строчку:
* * * * * psql -c 'insert into timing(select now())'
Каждую минуту в базу будет записываться информация о текущем времени, эта информация пригодится нам, когда мы будем производить восстановление на момент времени.
Задача 3
Дано:
У нас есть два сервера, на первом у нас располагается наша база данных (имя хоста srv_db1, пользователь postgres), на втором хранятся архивные резервные копии и WAL файлы (имя хоста srv_bkp, пользователь backup_user). В нашей среде появляется ещё один сервер srv_db2 (пользователь postgres), на нём мы должны будем развернуть реплику нашего кластера и перенастроить pg_probackup таким образом, чтобы он снимал резервные копии с реплики.
Решение:
В интернете полно описаний того, как создавать реплики на PostgreSQL, достаточно вбить в поисковик «создание реплики в PostgreSQL» — выбирай, не хочу! Тут и документация, и статьи, и даже видеоуроки. И все эти способы хороши, но они как правило не учитывают, что у нас уже есть резервные копии. Мы же хотим создать реплику, используя бэкап, таким образом мы снимем с мастера читающую нагрузку. То есть наш боевой сервер будет не в курсе, что где-то рядом с ним создают реплику (это, конечно, с оговорками — тут и слот репликации надо будет создать и права доступа прописать, но пока мы создаём реплику, никакой дополнительной нагрузки на мастере не будет).
Настраиваем доступ по ключам между серверами srv_bkp и srv_db2, устанавливаем PostgreSQL и pg_probackup на srv_db2 (всё, кроме установки PostgreSQL, мы делали во время решения первой задачи, но если у вас возникли вопросы по установке СУБД, загляните сюда).
Переходим на srv_db2
ssh-keygen -t rsa ssh-copy-id backup_user@srv_bkp
Переходим на srv_bkp
ssh-copy-id postgres@srv_db2
Включим нашего внутреннего параноика и внесём правки в ~/.ssh/autorized_keys — вставим
command="pg_probackup-12 agent"
перед новыми ключами.
Применение WAL файлов происходит намного медленнее, чем восстановление из резервной копии, поэтому создадим ещё один инкрементный бэкап — подключимся к серверу srv_bkp пользователем backup_user и запустим команду:
pg_probackup backup --instance=db1 -j 2 --progress -b PAGE --compress
Почему мы не воспользовались созданным нами скриптом? Дело в том, что раннее в скрипт мы добавили опцию --delete-wal, то есть после создания этого бэкапа мы бы не могли выполнить восстановление на точку времени, которая была три дня тому назад. Но если мы оставим этот бэкап, то следующий бэкап, сделанный путём запуска нашего скрипта, всё равно оставит WAL только за последние два дня, то есть после того, как мы восстановимся из этого бэкапа есть смысл удалить его.
Производим восстановление:
time pg_probackup restore --instance=db1 -D /var/lib/pgsql/12/data -j 2 --restore-as-replica --progress --remote-proto=ssh --remote-host=srv_db2 --archive-host=srv_bkp --archive-user=backup_user --log-level-console=log --log-level-file=verbose --log-filename=restore_rep.log
Каталог /var/lib/pgsql/12/data должен быть пуст, помимо этого на сервере srv_db1 необходимо внести правки в pg_hba.conf — разрешить доступ с сервера srv_db2 по протоколу репликации.
host replication all srv_db2 md5
Перечитываем конфигурацию:
psql -c 'select pg_reload_conf()'
Проверяем, не было ли опечаток:
psql -c 'select * from pg_hba_file_rules'
создаём на srv_db2 файл ~/.pgpass, в котором указываем разрешения на коннект в srv_db1 но на этот раз с базой replication и запускаем PostgreSQL.
srv_db1:5432:replication:backup:Strong_PWD
И изменим его права на 600:
chmod 600 ~/.pgpass
Стартуем кластер на srv_db2.
Давайте проверим, что всё хорошо работает. Воспользуемся для этого следующими возможностями.
Заглядываем в лог-файл реплики в нём где-то ближе к концу должна появиться строка:
Database system is ready to accept read only connections
psql -c 'select pg_is_in_recovery()'
должно вернуть t
Теперь давайте на мастере создадим табличку t1:
srv_db1: psql -c 'create table t1()'
Проверим — появилась ли она на реплике.
srv_db2: psql -c '\d'
Табличка на месте, значит репликация работает. Удаляем табличку на мастере.
srv_db1: psql -c 'drop table t1'
Конечно, на настоящей базе данных сейчас следовало бы создать слот репликации на мастере и настроить реплику таким образом, чтобы она ходила в мастер через этот слот, но тема нашей статьи не реплики, а бэкапы, поэтому продолжим.
Итак, реплика у нас работает, при необходимости мы сможем выполнить переключение на реплику, но давайте зададимся вопросом — а можно ли сделать лучше?
Конечно, можно. Зачем нам снимать бэкапы с мастера, когда можно снять читающую нагрузку с мастера и переложить её на реплику?
ОСТОРОЖНО! ДОЛЖЕН БЫТЬ МОНИТОРИНГ ОТСТАВАНИЯ РЕПЛИКИ, ИНАЧЕ МОЖЕТ ТАК ПОЛУЧИТЬСЯ, ЧТО ВЫ НЕ БУДЕТЕ ЗНАТЬ О ТОМ, ЧТО РЕПЛИКА ОТСТАЛА И БУДЕТЕ ПРОДОЛЖАТЬ СНИМАТЬ БЭКАПЫ С ОТСТАВШЕЙ РЕПЛИКИ.
Давайте сделаем это!
Производим изменения в настройках кластера на серверах srv_db1 и srv_db2:
alter system set archive_timeout=180; select pg_reload_conf();
Переходим на srv_bkp и изменяем значение параметра remote-host:
pg_probackup set-config --instance db1 --remote-host=srv_db2
Вносим изменения в .pgpass на сервере srv_bkp — добавляем строки соединения с сервером srv_db2:
srv_db2:5432:replication:backup:Strong_PWD srv_db2:5432:backupdb:backup:Strong_PWD
И попробуем снять ещё один бэкап.
srv_bkp: ./bkp_base.sh PAGE
Видим, что бэкап отработал.
Задача решена!
Следующая часть будет посвящена восстановлению из бэкапов: мы рассмотрим различные варианты восстановления, научимся восстанавливаться на определённый бэкап, на точку во времени, познакомимся с частичным и инкрементным восстановлениями.

