Один мой приятель, учитель латинского языка, в начале урока спрашивал своих студентов, выполнили ли они домашнее задание. Как правило, если не первый, то второй или третий ученик сознавался: простите, господин Учитель, я ничего не сделал. «Фак!» — говорил учитель. «Фак!» — повторял он, вводя в еще большее недоумение своих чад. «Сегодня мы будем проходить глагол третьего спряжения facio – делать», который в повелительном наклонении единственного числа так и произносится: fac! – делай!
Нет, мы не собираемся витийствовать о том, что не бывает хороших и плохих слов, а есть наша оценка оных. Также мы не будем говорить об истоках и функциях русской брани, не будем обсуждать моральную сторону вопроса, как и искать причинно-следственные связи ее употребления. Мы проведем небольшое исследование обсценной лексики на материалах русскоязычных соц. медиа, сделаем ряд замеров и расчетов на большой выборке из интернет-источников.
В качестве материала был обработан двухмесячный поток русскоязычного сегмента соц. медиа, собранный системой Brand-Analytics в период с начала ноября 2014 года по начало января 2015 (почему был выбран этот период, станет понятно в конце статьи). Было обработано около 45 миллиардов слов (ставим тег Big Data). Обработка заключалась в построении частотных словарей (униграммы и биграммы) за каждый день и построении языковых моделей — инструмент SRILM (ставим тег Text Mining).
Таким образом, можно было посмотреть динамику любого слова или словосочетания за этот период. Посмотрели разное и многое. Что-то понравилось, что-то нет. Например, на рисунке 1 показаны частотности личных местоимений и предлогов:
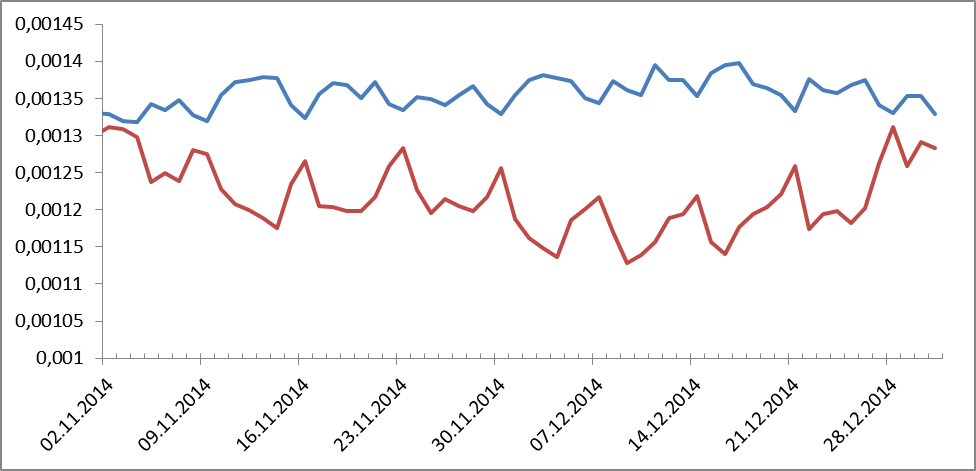
Рисунок 1. Динамика частотных распределений для предлогов (сини цвет) и личных местоимений (красный цвет).
Оказались в противофазе. Неожиданно, правда? А пики – как вы догадываетесь – выходные. А что говорили о деньгах? Смотрим:
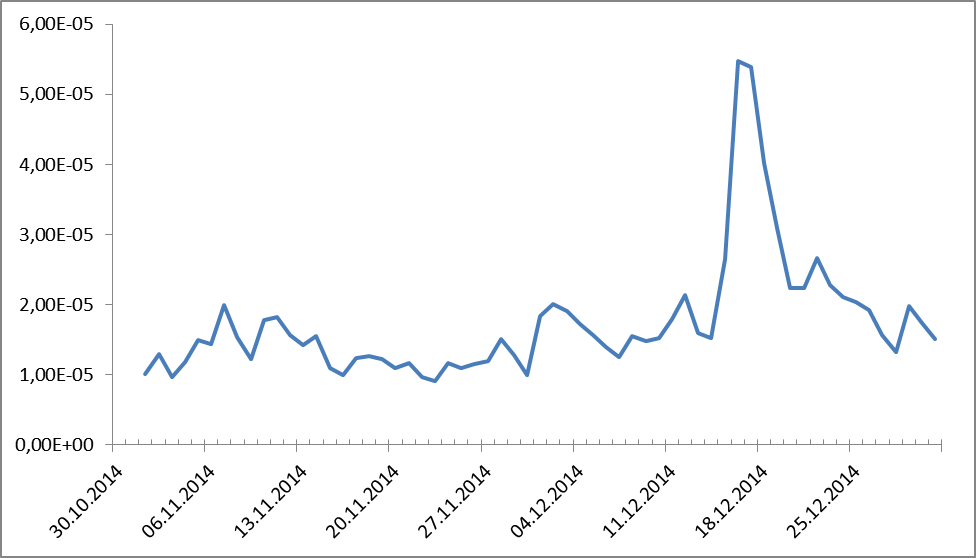
Рисунок 2. Динамика частотных распределений для названий денежных единиц.
Тут вроде бы вопросов не должно быть, все помнят 18 декабря 2014-го. Но если кто-то подзабыл, то напомним:

Но это тема отдельной публикации. Ну и как же не посмотреть то, что нельзя произносить при дамах, а уж тем более писать на уважаемом хабре! Да, их — наши, русские, четырезаветных известных слова.
Ок, сказано – сделано. Взяли наш фильтр русской обсценной лексики. А там аж более пятисот уникальных слов с морфотипами. Нагенерили всех словоформ. Получилось что-то около 8650. Ого, однако, не хилое словообразование….
Чтобы нас не забанили за нецензурщину, да и плюс, как говориться, «при дамах попрошу не выражаться», сделаем так: условно объединим их (к слову о местоименной анафоре: лексику, не дам) по морфологическому признаку и обзовем группами из неизменяемых составляющих их букв (ну, все же эти слова знают, пояснять не надо?):
Дополним еще двумя:
Примечание. Мы учитывали все словоформы, в том числе неграмотно написанные (замена букв: пля), удлинение ударных гласных (*ляяя) и наиболее частотные ошибки, сами знаете какие. Эвфемизмы не учитывали, т.е. всякие блин, хрен, трах – нормальные себе слова.
Сразу скажем, что нашлось из этих 8650 слов по всему частотному распределению около тысячи. Во-первых, частотные словари обрезались: учитывались 95% от суммы частотного распределения (т.е. хвост обрезался — чего с собой весь хлам тащить), что позволяло сократить до 30-50% объема словаря, но при этом только 5% объема исходного материала), а во вторых, многие словоформы и правда получились экзотичны.
Примечание (если кому-то интересно). Частотность исследуемой нами лексики начинается с конца второй тысячи ранжированной по частоте выдачи (из почти 12 млн. токенов).
Итак, строим и смотрим графики. График первый – абсолютное количество найденных слов по группам:
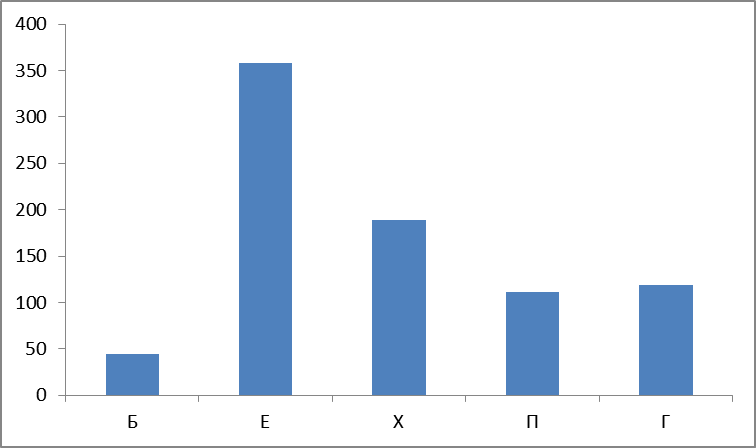
Рисунок 4. Абсолютное количество найденных слов по группам.
А в частотном выражении (точнее, мы оперируем обратными или нормированными частотами)? А вот график два:
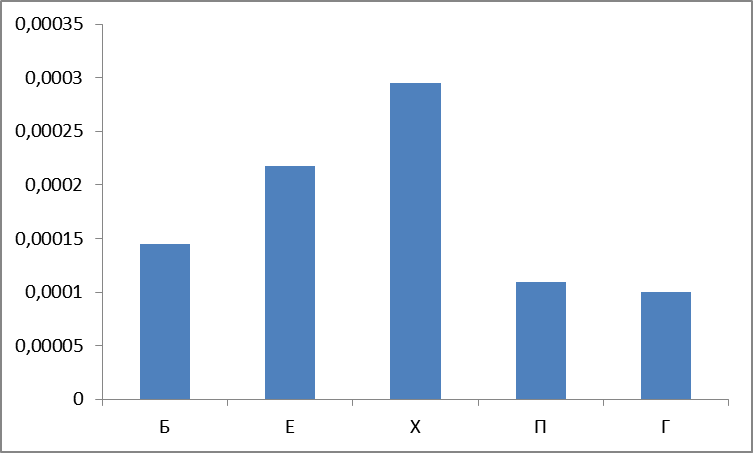
Рисунок 5. Сумма нормированных частот найденных слов по группам.
А теперь среднее: сумма частот нормированная на абсолютное количество:
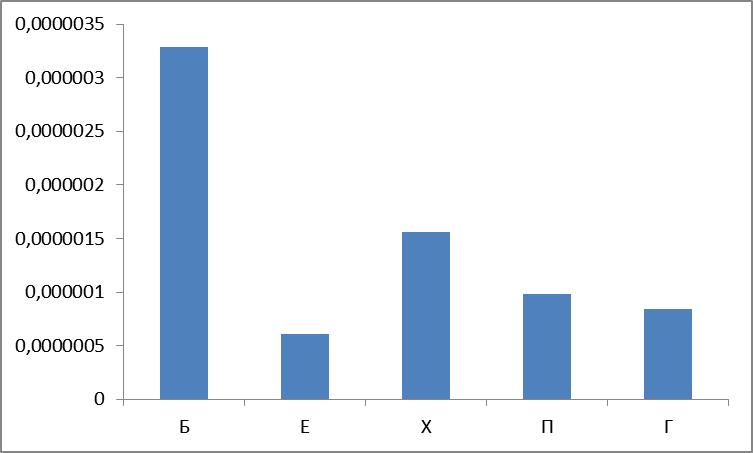
Рисунок 6. Среднее нормированных частот найденных слов по группам.
Вот и первый сюрприз: считается, что наиболее частотные группы П,Х,Е («очень частотная «сексуальная» триада» ) — ан нет, группа Б лидирует, причем с большим отрывом.
А зачем мы везде группу Г за собой тащим? А вот зачем: на всех графиках видно, что сумма П+Х+Б+Е и в абсолютном, и в относительном значениях однозначно больше группы Г. То есть, как и ожидалось, наш матсамый матерный мат в мире относится к сексуальному типу (Sex-культура), в пику немцам, чехам и «прочим шведам» с их Scheiss-культурой – вот и пригодилась группа Г.
Что еще можно посмотреть? А давайте посчитаем дисперсию?
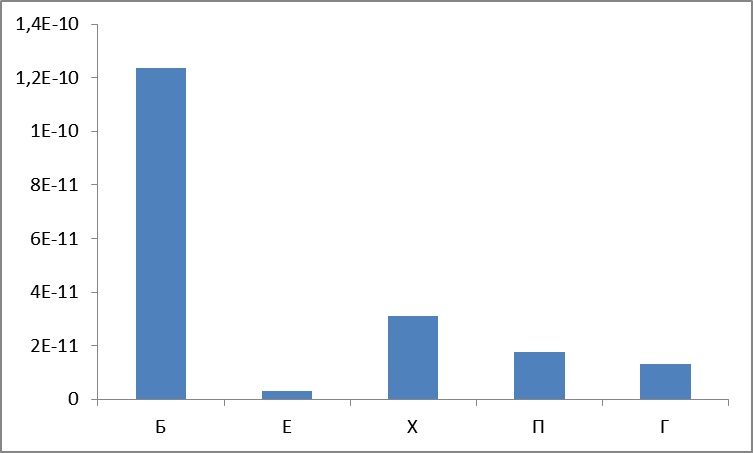
Рисунок 7. Дисперсия по группам.
В общем, не удивительно, что наиболее частотная группа имеет наибольшую дисперсию (следствие пресловутого закона Ципфа). Группа Е оказалась наиболее стабильна, ибо ее распределение наиболее равномерно и сосредоточено не в крайних областях.
Хорошо. Смотрим дальше. Интересно, а каково распределение по частям речи. Тут вопрос не простой. Потому что вне контекста не всегда возможно однозначно определить часть речи обсценной лексики. Зачастую существительное употребляется как междометие, наречие или даже частица (отрицание в группе Х, например). Поэтому строим круговые диаграммы с некоторой долей ошибки. Тем не менее:
Рисунок 8. Распределение слов каждой группы по частям речи. Сокращения: adj -прилагательные, verb — глаголы, noun — существительные, inter — междометия, part — частицы, adv -наречия.
Какие мы можем сделать выводы, глядя на все это? Группа Б существенно отстает в вариативности от групп Х,Е и П. И по непонятным нам причинам почти не образует глаголов. Зато группа Х просто пестрит. Но анализ сего явления оставим профессионалам в этой области…
Ну а теперь самое интересное: а какова же динамика употреблений исследуемого объекта в указанный период, т.е. в период кризиса конца 2014, перешедшего в перманентный? А тут становится еще интереснее:
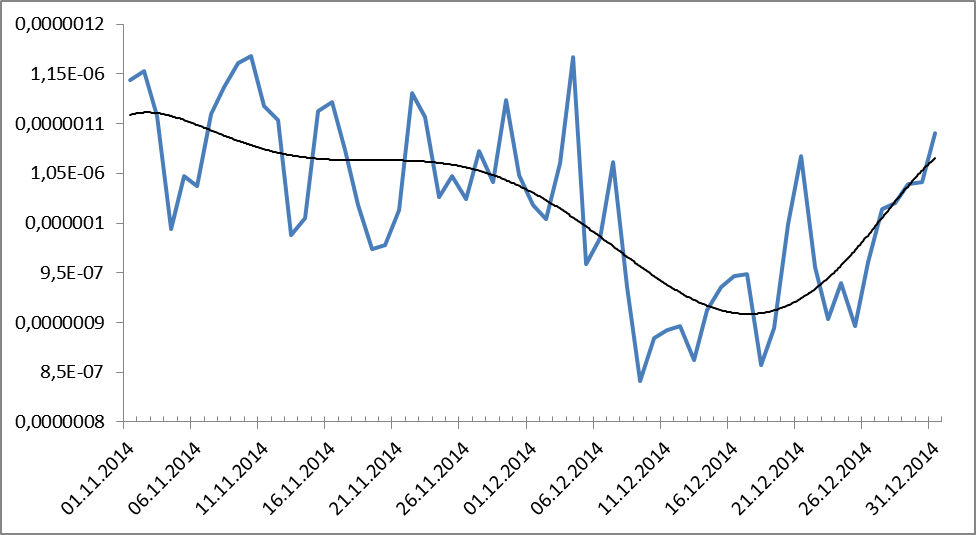
Рисунок 9. Динамика частотного распределения обсценной лексики за период с 1.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Что же это получается? В кризис употребление обсценной лексики падает? Получается, да.
Сделаем промежуточные выводы:
Может, где-то ошибка? Как бы проверить? А давайте посмотрим динамику сложности текста, его perplexity? Тяжко, конечно, с такими объемами работать, но что делать. Посчитали, получили:
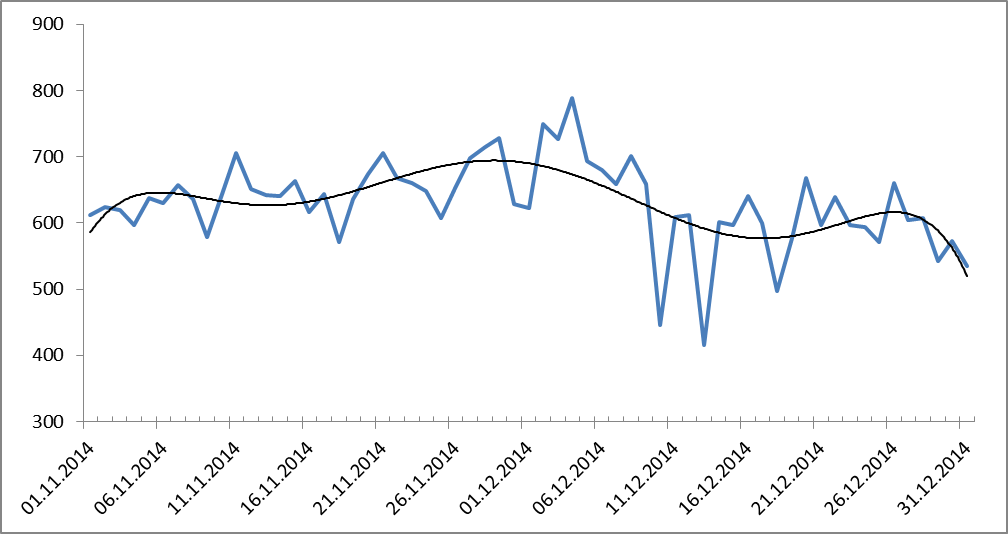
Рисунок 10. Динамика распределения перплексити за период с 01.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Примечание. Большое значение перплексити возникает вследствие того, что из-за больших объемов мы использовали сильное сглаживание и накладывали частотные ограничения. Считали на униграммах и биграммах.
Опять сюрприз: а сложность-то тоже падает. Получается, думали-то мы верно: эмоциональность связана со сложностью. Но ошиблись на «пи пополам» в предположении, что в кризис эмоции должны «зашкаливать» — ровно наоборот.
Может быть, это связно с изменением количества публикаций в кризис? Тогда вот еще один график количества словоупотреблений:
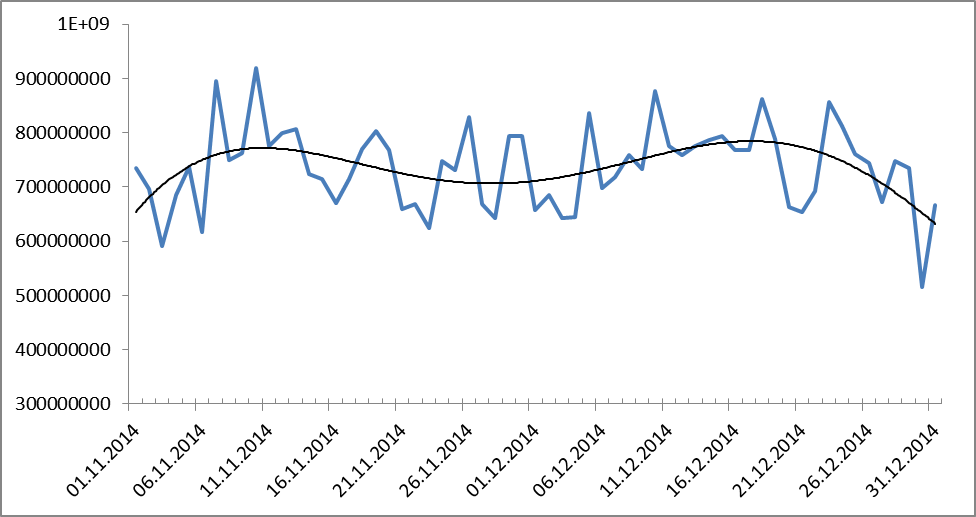
Рисунок 10. Динамика словоупотребления за период с 1.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Остается, наверно, посчитать корреляцию (perplexity vs обсценная лексика):
— коэффициент корреляции ~ 0,51, что, вроде бы, не ах как много.
Но все относительно: корреляция перплексити с предлогами ~ -0,04, а с личными местоимениями -0,06.
Даже не знаем, что и вывести. Для серьезного анализа данных мало (всего один кризис), а померить что-то еще – это отдельная статья. Может быть так: делайте выводы сами — употреблять или не употреблять. Возможно, это как-то повлияет на экономический кризис…
Спасибо за прочтение!
Нет, мы не собираемся витийствовать о том, что не бывает хороших и плохих слов, а есть наша оценка оных. Также мы не будем говорить об истоках и функциях русской брани, не будем обсуждать моральную сторону вопроса, как и искать причинно-следственные связи ее употребления. Мы проведем небольшое исследование обсценной лексики на материалах русскоязычных соц. медиа, сделаем ряд замеров и расчетов на большой выборке из интернет-источников.
Мат. часть
В качестве материала был обработан двухмесячный поток русскоязычного сегмента соц. медиа, собранный системой Brand-Analytics в период с начала ноября 2014 года по начало января 2015 (почему был выбран этот период, станет понятно в конце статьи). Было обработано около 45 миллиардов слов (ставим тег Big Data). Обработка заключалась в построении частотных словарей (униграммы и биграммы) за каждый день и построении языковых моделей — инструмент SRILM (ставим тег Text Mining).
Таким образом, можно было посмотреть динамику любого слова или словосочетания за этот период. Посмотрели разное и многое. Что-то понравилось, что-то нет. Например, на рисунке 1 показаны частотности личных местоимений и предлогов:
Рисунок 1. Динамика частотных распределений для предлогов (сини цвет) и личных местоимений (красный цвет).
Оказались в противофазе. Неожиданно, правда? А пики – как вы догадываетесь – выходные. А что говорили о деньгах? Смотрим:
Рисунок 2. Динамика частотных распределений для названий денежных единиц.
Тут вроде бы вопросов не должно быть, все помнят 18 декабря 2014-го. Но если кто-то подзабыл, то напомним:
Но это тема отдельной публикации. Ну и как же не посмотреть то, что нельзя произносить при дамах, а уж тем более писать на уважаемом хабре! Да, их — наши, русские, четыре
Ок, сказано – сделано. Взяли наш фильтр русской обсценной лексики. А там аж более пятисот уникальных слов с морфотипами. Нагенерили всех словоформ. Получилось что-то около 8650. Ого, однако, не хилое словообразование….
Теперь эксперимент и картинки
Чтобы нас не забанили за нецензурщину, да и плюс, как говориться, «при дамах попрошу не выражаться», сделаем так: условно объединим их (к слову о местоименной анафоре: лексику, не дам) по морфологическому признаку и обзовем группами из неизменяемых составляющих их букв (ну, все же эти слова знают, пояснять не надо?):
- Группа Б
- Группа Х
- Группа Е
- И группа П
Дополним еще двумя:
- Группа Г (да-да, однокоренное с говядиной), потом будет ясно зачем.
- И группа О, в смысле остальное на буквы Му*, Пид*, и пр.
Примечание. Мы учитывали все словоформы, в том числе неграмотно написанные (замена букв: пля), удлинение ударных гласных (*ляяя) и наиболее частотные ошибки, сами знаете какие. Эвфемизмы не учитывали, т.е. всякие блин, хрен, трах – нормальные себе слова.
Сразу скажем, что нашлось из этих 8650 слов по всему частотному распределению около тысячи. Во-первых, частотные словари обрезались: учитывались 95% от суммы частотного распределения (т.е. хвост обрезался — чего с собой весь хлам тащить), что позволяло сократить до 30-50% объема словаря, но при этом только 5% объема исходного материала), а во вторых, многие словоформы и правда получились экзотичны.
Примечание (если кому-то интересно). Частотность исследуемой нами лексики начинается с конца второй тысячи ранжированной по частоте выдачи (из почти 12 млн. токенов).
Итак, строим и смотрим графики. График первый – абсолютное количество найденных слов по группам:
Рисунок 4. Абсолютное количество найденных слов по группам.
А в частотном выражении (точнее, мы оперируем обратными или нормированными частотами)? А вот график два:
Рисунок 5. Сумма нормированных частот найденных слов по группам.
А теперь среднее: сумма частот нормированная на абсолютное количество:
Рисунок 6. Среднее нормированных частот найденных слов по группам.
Вот и первый сюрприз: считается, что наиболее частотные группы П,Х,Е («очень частотная «сексуальная» триада» ) — ан нет, группа Б лидирует, причем с большим отрывом.
А зачем мы везде группу Г за собой тащим? А вот зачем: на всех графиках видно, что сумма П+Х+Б+Е и в абсолютном, и в относительном значениях однозначно больше группы Г. То есть, как и ожидалось, наш мат
Что еще можно посмотреть? А давайте посчитаем дисперсию?
Рисунок 7. Дисперсия по группам.
В общем, не удивительно, что наиболее частотная группа имеет наибольшую дисперсию (следствие пресловутого закона Ципфа). Группа Е оказалась наиболее стабильна, ибо ее распределение наиболее равномерно и сосредоточено не в крайних областях.
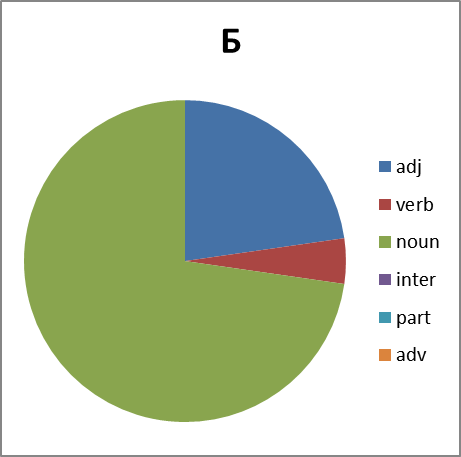
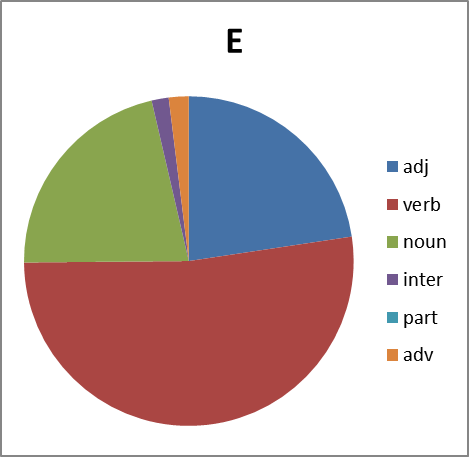
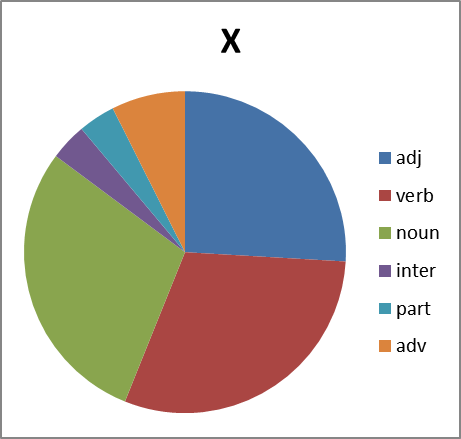
Хорошо. Смотрим дальше. Интересно, а каково распределение по частям речи. Тут вопрос не простой. Потому что вне контекста не всегда возможно однозначно определить часть речи обсценной лексики. Зачастую существительное употребляется как междометие, наречие или даже частица (отрицание в группе Х, например). Поэтому строим круговые диаграммы с некоторой долей ошибки. Тем не менее:
 |
 |
 |
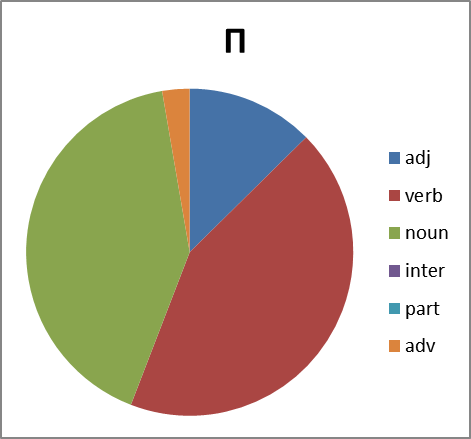 |
Рисунок 8. Распределение слов каждой группы по частям речи. Сокращения: adj -прилагательные, verb — глаголы, noun — существительные, inter — междометия, part — частицы, adv -наречия.
Какие мы можем сделать выводы, глядя на все это? Группа Б существенно отстает в вариативности от групп Х,Е и П. И по непонятным нам причинам почти не образует глаголов. Зато группа Х просто пестрит. Но анализ сего явления оставим профессионалам в этой области…
Ну а теперь самое интересное: а какова же динамика употреблений исследуемого объекта в указанный период, т.е. в период кризиса конца 2014, перешедшего в перманентный? А тут становится еще интереснее:
Рисунок 9. Динамика частотного распределения обсценной лексики за период с 1.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Что же это получается? В кризис употребление обсценной лексики падает? Получается, да.
Сделаем промежуточные выводы:
- обсценная лексика имеет сильное словообразование (у некоторых лексем может быть по нескольку морфотипов). Это говорит о том, что при ее употреблении должна повышаться энтропия текста, его сложность;
- в период кризиса, вроде бы, эмоциональность должна расти, употребление эмотивных слов увеличиваться, но мы наблюдаем обратную картину.
Может, где-то ошибка? Как бы проверить? А давайте посмотрим динамику сложности текста, его perplexity? Тяжко, конечно, с такими объемами работать, но что делать. Посчитали, получили:
Рисунок 10. Динамика распределения перплексити за период с 01.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Примечание. Большое значение перплексити возникает вследствие того, что из-за больших объемов мы использовали сильное сглаживание и накладывали частотные ограничения. Считали на униграммах и биграммах.
Опять сюрприз: а сложность-то тоже падает. Получается, думали-то мы верно: эмоциональность связана со сложностью. Но ошиблись на «пи пополам» в предположении, что в кризис эмоции должны «зашкаливать» — ровно наоборот.
Может быть, это связно с изменением количества публикаций в кризис? Тогда вот еще один график количества словоупотреблений:
Рисунок 10. Динамика словоупотребления за период с 1.11.2014 по 31.12.2014. Черным показана линия тренда (полиномиальная, 9-ой степени).
Остается, наверно, посчитать корреляцию (perplexity vs обсценная лексика):
— коэффициент корреляции ~ 0,51, что, вроде бы, не ах как много.
Но все относительно: корреляция перплексити с предлогами ~ -0,04, а с личными местоимениями -0,06.
Выводы
Даже не знаем, что и вывести. Для серьезного анализа данных мало (всего один кризис), а померить что-то еще – это отдельная статья. Может быть так: делайте выводы сами — употреблять или не употреблять. Возможно, это как-то повлияет на экономический кризис…
Спасибо за прочтение!
