Сегодня только и разговоров, что о ChatGPT, Midjourney и прочих DALL-E. Почему именно сейчас нейросети стали такими крутыми и развиваются семимильными шагами? Прорыв стал возможен благодаря новому классу невероятно мощных моделей искусственного интеллекта. Рассказываем, с чего всё началось и как мы здесь оказались.

Когда мы видим, как ИИ калечит руки, то ощущаем свое превосходство над машинами... пока. — Аурих

Прогресс в системах искусственного интеллекта часто кажется цикличным. Каждые несколько лет компьютеры внезапно обучаются делать то, на что раньше не были способны. В этот момент истинно верующие в ИИ провозглашают:
“Вот! Век всеобщего искусственного интеллекта близок!”
"Да ну, бред какой то!" — отвечают скептики. — “Помните беспилотные автомобили?”
Истина обычно где-то посередине.
Сейчас мы находимся в другом цикле, на этот раз с генеративным ИИ. Стоит зайти в интернет, как на тебя отовсюду напрыгивают заголовки про GPT-3, Midjourney, SD, DALL-E 2. И помимо искусственного интеллекта, который активно конкурирует с творческими людьми, также наблюдается беспрецедентный прогресс во многих других областях (в биологии, программировании, переводе и др.).
Почему всё это происходит сейчас?
Скорее всего вы знакомы с последними событиями в мире ИИ. Видели новости о том, как картины, созданные нейросетью, выигрывают в конкурсах, как люди общаются с умершими родственниками, и о том, как ИИ помог с проблемой сворачивания белков. Причём искусственный интеллект не просто показывает эффектные фокусы, он реально становится практическим инструментом, которым может пользоваться каждый.
Есть причина, по которой всё это произошло сразу. Последние достижения основаны на новом классе моделей ИИ, более гибких и мощных, чем всё, что было раньше. Поскольку они изначально использовались для языковых задач, таких как ответы на вопросы или написание эссе, их часто называют большими языковыми моделями (LLM). GPT3 от OpenAI, BERT от Google и т. д. — всё это LLM.
Но на самом деле эти модели чрезвычайно гибкие и адаптируемые. Одни и те же математические структуры оказались настолько полезными в компьютерном зрении, биологии и многом другом, что некоторые исследователи стали называть их “базовыми моделями”. Это гораздо лучше соответствует их роли в современном мире.
Откуда взялись эти базовые модели и как они вырвались за пределы работы с языком?
Как появились базовые модели
В машинном обучении есть святая троица: модели, данные и вычисления. Модели — это алгоритмы, которые принимают входные данные и производят выходные данные. Данные — это примеры, на которых обучаются алгоритмы. Чтобы алгоритмы могли выдавать полезный результат, должно быть достаточно данных и они должны быть достаточно полными. Модели, в свою очередь, должны быть гибкими, чтобы охватить сложные данные во всей их полноте. И, наконец, необходима достаточная вычислительная мощность для запуска алгоритмов.
Первая современная революция ИИ произошла в 2012 году, когда с помощью сверточных нейронных сетей (CNN) начали решать задачи компьютерного зрения. По своей структуре CNN похожи на зрительную кору головного мозга. Они существуют с 1990-х годов, но тогда их не получалось применить на практике из-за высоких требований к вычислительной мощности.
Однако в 2006 году Nvidia выпустила CUDA, язык программирования, который позволял использовать графические процессоры в качестве суперкомпьютеров общего назначения. В 2009 году исследователи искусственного интеллекта из Стэнфорда представили Imagenet — коллекцию помеченных изображений, используемых для обучения алгоритмов компьютерного зрения. В 2012 году AlexNet объединила CNN, обученные на графических процессорах, с данными Imagenet, чтобы создать лучший визуальный классификатор, который когда-либо видел мир. Именно отсюда растут ноги у глубокого обучения и искусственного интеллекта.
CNN, набор данных ImageNet и графические процессоры были волшебной комбинацией, которая запустила мощный прогресс в области компьютерного зрения. В 2012 году начался бум интереса к глубокому обучению и породил целые отрасли, такие как автономное вождение. Но исследователи быстро поняли, что у нового поколения глубокого обучения есть свои пределы. CNN были хороши для компьютерного зрения, но не могли привести к прорыву в других сферах. Например, огромный пробел был в обработке естественного языка (NLP), то есть не получалось заставить компьютеры понимать и работать с нормальным человеческим языком, а не с кодом.
Проблема понимания и взаимодействия с языком принципиально отличается от проблемы восприятия образов. Здесь требуется работа с последовательностями слов, где важен порядок. Кошка остается кошкой независимо от того, где она находится на изображении, но есть большая разница между фразами “читатель узнает об ИИ” и “ИИ узнает о читателе”.
До недавнего времени для своевременной обработки и анализа данных исследователи полагались на так называемые рекуррентные нейронные сети (RNN) и долгую кратковременную память (LSTM). Эти модели были эффективны при распознавании коротких последовательностей, например, при распознавании произносимых слов в коротких фразах. Но они с трудом справлялись с более длинными предложениями и абзацами. Дело в том, что память этих моделей была недостаточно развита, чтобы уловить сложность и богатство идей, а также понятий, возникающих при объединении предложений в абзацы и эссе. Модели отлично подходили для простых голосовых помощников, таких, как Siri и Alexa, но не более того.
Получение правильных данных для обучения было еще одной проблемой. ImageNet представлял собой набор из ста тысяч помеченных изображений, для создания которых потребовались значительные человеческие усилия, в основном этой работой занимались аспиранты и работники Amazon Mechanical Turk. К тому же ImageNet был вдохновлен и смоделирован на основе более старого проекта под названием WordNet, в рамках которого пытались создать размеченный набор данных для английской лексики. Конечно, в Интернете нет недостатка в тексте, но, помимо отдельных слов, для создания значимого набора данных для обучения компьютера работе с человеческим языком требуется ещё и невероятно много времени. Ярлыки, которые вы создаете для одного приложения, могут быть не применимы для другого, хотя они оба основаны на одних и тех же данных.

Нам бы хотелось делать две вещи. Во-первых, тренироваться на неразмеченных данных, т.е. на тексте, который не требует от человека пометок с пояснениями к каждому элементу. Во-вторых, работать с действительно огромными объемами данных и использовать преимущества продвинутых графических процессоров и параллельных вычислений, так же, как это делали модели сверточных сетей. Только тогда можно выйти за рамки обработки на уровне предложений, которой ограничивались модели RNN и LSTM.
Другими словами, большой прорыв в компьютерном зрении состоял в том, что данные и вычисления догнали уже существовавшую модель. ИИ для работы с естественном языком ждал новой модели, которая могла бы использовать преимущества уже существующих вычислений и данных.
Перевод — это все, что вам нужно
Большим прорывом стала модель от Google под названием “the transformer” (преобразователь). Исследователи из Google работали над очень специфической проблемой естественного языка: переводом. Перевод сложен. Порядок слов, как и всегда, имеет значение, но он меняется в разных языках. Например, в японском языке глаголы стоят после объектов, на которые они воздействуют. По-английски правильно будет сказать “сэмпай замечает тебя”, а по-японски это будет “сэмпай тебя замечает”. И, конечно же, именно благодаря французскому языку Международная футбольная федерация называется ФИФА, а не IAFF.
Модель ИИ, которая может учиться и работать с такими проблемами, должна очень гибко обрабатывать порядок элементов. В старых моделях — LSTM и RNN — порядок слов был неявно встроен в модель. Обработка входной последовательности слов означала подачу их в модель по порядку. Модель знала, какое слово идет первым, потому что это слово она увидела первым. Преобразователи вместо этого обрабатывали порядок следования численно, при этом каждому слову присваивался номер. Это называется «позиционным кодированием». Для модели предложение «Я люблю ИИ; я хочу, чтобы ИИ любил меня» выглядит примерно так: (Я 1) (люблю 2) (ИИ 3) (; 4) (я 5) (хочу 6) (, 7) (чтобы 8) (ИИ 9) (любил 10) (меня 11).
Использование позиционного кодирования стало первым прорывом. Вторым было то, что называлось «Multi-Head Attention» (многоголовое внимание). Когда дело доходит до выдачи последовательности выходных слов после подачи последовательности входящих слов, модель не ограничивается только следованием строгому порядку ввода. Вместо этого она может смотреть вперед или назад на входную последовательность (отсюда в названии слово “внимание”) и на разные части входной последовательности (поэтому “многоголовое”) и выяснять, что наиболее важно для вывода.
Модель преобразователя использует векторное представление слов — последовательный ввод слова и выход слов одно за другим — и сделала его более похожим на матричное представление, где модель может рассматривать всю последовательность входных данных и определять, что относится к той или иной части вывода.

Преобразователи совершили прорыв в решении проблем перевода, более того, они могли стать идеальной моделью для решения многих других языковых задач.
Они прекрасно подходили для работы с графическими процессорами, поскольку могли обрабатывать большие куски текста параллельно, а не по одному слову. Более того, преобразователь — это модель, которая принимает одну упорядоченную последовательность символов (в данном случае слов, а точнее фрагментов слов, называемых «токенами») и затем выдает другую упорядоченную последовательность: слова на другом языке.
А ещё перевод не требует сложной маркировки данных. Вы просто позволяете компьютеру вводить текст на одном языке и выводить текст на другом. Вы даже можете научить модель заполнять пробелы, угадывать, что будет дальше, если ей передана определенная последовательность текста. Это позволяет модели изучать любые виды шаблонов без явной маркировки.
Конечно, не обязательно использовать на входе только английский язык, а на выходе — японский. Можно даже выполнять перевод между английским и английским! Это можно использовать для пересказа длинного эссе в нескольких коротких абзацах, для анализа отзыва клиента о продукте и определение, был ли он положительным или отрицательным. Более того, можно превратить небольшую подсказку в убедительное эссе.
Другими словами, большим прорывом в языковых моделях стало открытие удивительной модели перевода, а затем понимание того, как с её помощью решать другие языковые задачи.
Итак, теперь у нас есть модель ИИ, которая позволяет делать две важные вещи. Во-первых, тренироваться, самостоятельно заполняя пробелы, то есть больше не нужно маркировать все обучающие данные. Во-вторых, можно брать целые отрывки текста — даже целые книги — и запускать их в модели.
Больше не нужно сообщать компьютеру, какие строки текста относятся к Гарри Поттеру, а какие — к Гермионе. Не нужно объяснять, что Гарри — мальчик, а Гермиона — девочка, и помечать текст соответствующе. Достаточно просто случайным образом пропускать строки типа «Гарри» и «Гермиона», «он» и «она» и обучать компьютер заполнять пропуски. В процессе заполнения пропусков ИИ не просто узнает, какой текст относится к определённому персонажу, но и понимает, как сопоставлять существительные и подлежащие в целом. А поскольку мы запускаем процессы на GPU, можно начать масштабировать модели до гораздо больших размеров, чем раньше, и работать с большими отрывками текста.
Наконец-то у нас есть революционная модель, которая позволяет использовать преимущества огромного количества неструктурированных текстовых данных в Интернете и всех имеющихся у нас графических процессоров. OpenAI применил этот подход с GPT2, а затем с GPT3. GPT означает «генеративный предварительно обученный преобразователь». «Генеративная» часть очевидна — модели предназначены для того, чтобы в ответ на ввод слов выдавать новые слова. А «предварительно обученный» означает, что они обучены этому методу заполнения пробелов на большом количестве текста.
В 2019 году OpenAI выпустила GPT2. Он мог генерировать удивительно реалистичный человекоподобный текст целыми абзацами, причём они были внутренне непротиворечивы, чего никогда раньше не случалось с текстами, написанными ИИ. GPT2 был чем-то вроде безумной машины. Аккуратно передавая ему текстовые подсказки, можно было получить в ответ связанные последовательности текста. Это уже было очень хорошо, но чем длиннее становился текст, тем больше нарушалась структура и внутренняя логика. Да и сами подсказки были немного похожи на ввод поисковых запросов во времена Alta Vista — они были не очень гибкими.
Самый большой прорыв произошел при переходе с GPT2 на GPT3 в 2020 году. GPT2 имел около 1,5 миллиарда параметров, которые легко поместились бы в памяти потребительской видеокарты. GPT3 был в 100 раз больше, он содержал 175 миллиардов параметров в самом широком их проявлении. GPT3 намного лучше GPT2. Он может писать целые эссе, которые внутренне непротиворечивы и почти неотличимы от человеческого письма.
Но не обошлось и без сюрпризов. Исследователи OpenAI обнаружили, что усиление моделей позволило не только лучше создавать текст. Модели смогли научиться совершенно новому поведению, достаточно было предоставить им новые обучающие данные. В частности, исследователи обнаружили, что GPT3 можно научить следовать инструкциям на простом английском языке, и для этого не нужно разрабатывать какие-то специальные, заточенные именно под это модели.
Вместо того, чтобы обучать специальные модели выдавать сжатое содержание абзаца или переписывать текст в определенном стиле, вы можете использовать GPT-3. Достаточно просто сделать соответствующий запрос. Вы можете попросить GPT3: «кратко перескажи следующий абзац», и он сделает это. Вы можете сказать ему: «Перепиши этот абзац в стиле Эрнеста Хемингуэя», и он превратит длинный, многословный блок текста в лаконичную и сухую выжимку сути.
Таким образом, вместо создания одноцелевых языковых инструментов, можно брать многоцелевой языковой инструмент GPT3 и использовать его разными способами. И, что не менее важно, способность изучать команды является эмерджентной (возникшей случайно), а не запрограммированной в коде. Модель была сформирована путем обучения, а это позволяет использовать её для не только для работы с языком.
Выход за пределы работы с языком: Dall-E, Stable Diffusion и многое другое
Совсем недавно, в 2014 году, в веб-комиксе XKCD появилось следующее:

Менее, чем десять лет спустя мы перешли от компьютеров, не умеющих распознавать птиц, к... ну, этому:

Как мы оказались здесь так быстро?
Мы уже говорили об отправных точках — ImageNet, AlexNet, графических процессорах и революции глубокого обучения. Эта комбинация моделей, данных и вычислений дала невероятный набор инструментов для работы с изображениями.
Компьютерное зрение до появления глубокого обучения было утомительной задачей. Достаточно подумать о том, как мы, люди, определяем, что перед нами лицо. Целое состоит из частей; наш разум ищет формы, похожие на глаза и рот, определяет, как комбинации этих форм сочетаются друг с другом на лице.
Раньше исследования компьютерного зрения пытались вручную воспроизвести этот процесс. Исследователи усердно искали правильные детали конструктора (называемые «функциями»), а затем пытались выяснить, как объединить их в шаблоны. Хороший пример — детектор лиц Виолы-Джонса, который работал на том принципе, что в основном лица соответствуют образцу с ярким лбом и носом в форме буквы Т, а также двумя тёмными областями под ними.
Глубокое обучение начало всё это менять. Исследователям больше не нужно было выделять детальки изображения и работать с ними вручную, модели ИИ должны были сами изучать эти детали и то, как отдельные части соединяются в такие объекты, как лица, автомобили и животные. Если провести аналогию с языком, модели как будто изучают "язык" зрения; "словарь" линий, форм и узоров, являющихся основными “деталями конструктора”, узнают правила, “грамматику”, по которым эти части связываются вместе. При этом модели справляются со всем этим лучше человека, ведь они могут работать с огромными объемами данных.
Это было мощным прорывом, потому что давало компьютерам масштабируемый способ изучения правил работы с изображениями. Но и этого было мало. Модели двигались в одном направлении — они могли научиться сопоставлять пиксели с категориями объектов и говорить: «Эти пиксели показывают кошку; эти пиксели показывают собаку», но другие направления были для них закрыты. Эти модели походили на туриста, который запоминает некоторые стандартные фразы и имеет некоторый словарный запас, но на самом деле не может по-настоящему переводить с одного языка на другой.
Понимаете, к чему мы идём?
Модели-преобразователи были придуманы как переводчики, переходящие с одного языка на другой. Вы можете переводить с английского на французский, с английского на английский, с латыни на английский и т. д. Но на самом деле языки — это просто упорядоченные последовательности символов, а перевод — это просто отображение одного набора упорядоченных последовательностей в виде другого. Преобразователи — это инструменты общего назначения для определения правил одного языка и их последующего сопоставления с другим. Поэтому, если вы сможете понять, как провести параллели между языком и чем-то другим (например, изображением), вы можете обучить модели-преобразователи выполнять перевод между ними.
Именно это и произошло с изображениями. Помните, как модель представляет себе “язык” изображений? Она может изучать то, что называется представлением “скрытого пространства” изображений. Модель учится извлекать важные детали из изображений и сжимать их в представление меньшего размера, называемое скрытым пространством.
Скрытое пространство берет все доступные изображения с заданным разрешением и уменьшает их размер. Модель сначала изучает невероятно большой набор основных форм, линий и узоров, а затем правила того, как последовательно соединять их в объекты.
Скрытые пространства названы так потому, что они функционируют как координатная сетка, представляющая аспекты изображений. Например, представление автомобиля, похожего на лицо, означает перемещение в точку скрытого пространства, расположенную высоко на оси «похоже на машину», а также на оси «похоже на лицо». По сути, рисование изображения (или вообще работа с изображениями) является перемещением в этом пространстве. А математически представление координат в пространстве означает просто предоставление последовательности чисел. Итак, мы превратили работу с изображениями в задачу по созданию последовательности… А как её решать, мы знаем. На самом деле, если мы представим каждую «ось» скрытого пространства как символ или слово, то превратим «рисование картинки» в нечто похожее на «написание предложения».

Теперь у нас есть язык изображений для работы и инструмент (преобразователь), который позволяет выполнять перевод. Не хватает только набора данных. И, конечно же, в Интернете полно помеченных изображений — Alt-текст описывает, что изображено на картинке. OpenAI поскрёб по сусекам Интернета, чтобы создать огромный набор данных, который можно использовать для перевода между языком изображений и языком текста. При этом модели, данные и вычисления объединились для преобразования изображений в текст, и так родился Dall-E.
 -> Текстовый преобразователь, основанный на большой языковой модели -> Скрытый преобразователь (вектор) -> дешифратор изображений, основанный на модели изображений -> изображение")
Dall-E на самом деле представляет собой комбинацию нескольких разных моделей ИИ. Преобразователь выполняет перевод между скрытым языком представления и английским языком. Он берёт английские фразы и создаёт «картинки» в скрытом пространстве. Затем скрытая модель представления осуществляет перевод между низкомерным «языком» в скрытом пространстве и реальными изображениями. Наконец, есть модель под названием CLIP, которая работает в обратном направлении; она берёт изображения и ранжирует их в зависимости от того, насколько они близки к английской фразе.
Последние модели изображений, такие как Stable Diffusion, используют процесс, называемый скрытой диффузией. Вместо прямого создания скрытого представления используется текстовая подсказка для постепенного изменения исходных изображений. Идея проста: если вы возьмете изображение и добавите к нему шум, оно в конечном итоге превратится в шумное размытое изображение. Однако, если вы начинаете с шумного размытого изображения, то можете «вычесть» из него шум, чтобы вернуть чистое изображение. «Устранять шум» нужно разумно, то есть таким образом, чтобы приблизиться к желаемому изображению.
В этом случае вместо преобразователя, генерирующего изображения, есть модель преобразователя, которая принимает скрытые кодировки изображения и текстовые строки, а потом изменяет изображение таким образом, чтобы оно лучше соответствовало тексту. После запуска нескольких десятков итераций вы можете перейти от шумной и размытой к четкой картинке, созданной ИИ.
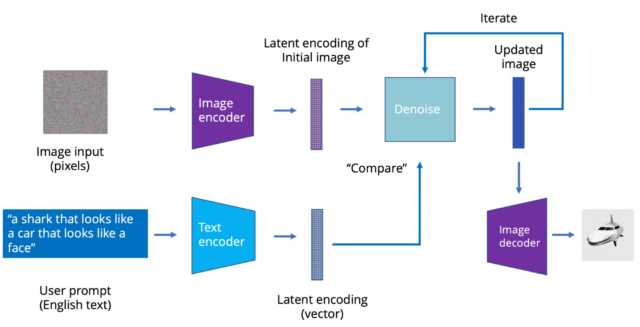
Но вам не обязательно начинать с шумного размытого изображения. Вы можете начать с другого изображения, а преобразователь просто подстроит это изображение к тому, что, по его мнению, лучше соответствует текстовой подсказке. Это ведёт к получению модели ИИ, которая берет грубые наброски и превращает их в фотореалистичные изображения.

Итак, мы приходим к тому, что прорыв в генеративных моделях изображений стал возможен благодаря сочетанию двух преимуществ ИИ. Во-первых, способности глубокого обучения выучить «язык» для представления изображений через скрытые представления. Во-вторых, способности модели использовать навык «перевода» через базовую модель для переключения между миром текста и миром изображений (посредством этого скрытого представления).
Это мощная технология выходит далеко за рамки изображений. Преобразователи могут изучать правила, а затем осуществлять перевод между любыми сущностями, которые по структуре хоть как-то напоминают язык. Copilot от Github научился переводить с английского на различные языки программирования, а Alphafold от Google умеет переводить с языка последовательностей ДНК и белков. Другие компании и исследователи работают над автоматизацией выполнения простых задач на компьютере, таких как создание электронных таблиц, каждая из которых является обычной упорядоченной последовательностью.
Создавать, оценивать, повторять
Эти модели ИИ невероятно мощны и гибки, поэтому стоит немного больше углубиться в их свойства. А именно, поговорить о зависимости от данных, непредсказуемости, эмерджентном поведение и универсальности.
Итак, обучение ИИ зависит от данных. Текста и изображений много, поэтому модели изображений, такие как Stable Diffusion и Google Imagen, смогли быстро догнать Dall-E. Stability.ai связан с несколькими проектами ИИ с открытым исходным кодом, в первую очередь с Eulethera и LAION. Eleuthera создал массивный набор данных текста под названием «The Pile» (Куча), а LAION создал набор LAION-5B из 5 миллиардов изображений с соответствующими текстовыми метками. Этот набор данных позволил другим исследователям быстро догнать OpenAI как по части текста, так и в сфере изображений.
Это означает, что инструменты ИИ будут развиваться неравномерно, в зависимости от сферы деятельности и доступных типов данных. Например, в робототехнике пока нет аналога ImageNet или LAION для обучения моделей планирования движения роботов. На самом деле, нет даже хороших общедоступных форматов для обмена данными в 3D-движении, формах и касаниях — мы словно живем в мире не только до LAION-5B, но и до JPEG.
Посмотрим на мир фармацевтики, где биотехнологические компании обучают ИИ созданию новых лекарств. Этот процесс часто связан с исследованием новых областей биологии — например, белков, которые не похожи на образцы, полученные естественным путем. Разработка ИИ должна идти рука об руку с огромным количеством физических экспериментов в лабораториях, потому что данных, необходимых для обучения этих моделей, просто не существует.
Кроме того, эти модели ИИ в своей основе являются стохастическими. Их обучают с помощью метода, называемого градиентным спуском. Алгоритм обучения сравнивает данные обучения с выходными данными модели ИИ и вычисляет «направление», чтобы приблизиться к правильному ответу. Нет явного понятия правильного или неправильного ответа — только то, насколько он близок к правильному.
Основной рабочий процесс этих моделей таков: создавать, оценивать, повторять. Обычно приходится создавать множество образцов, чтобы получить то, что вам нравится. При работе с ИИ приходится помнить, что это скорее игровые автоматы, чем калькуляторы. Каждый раз, когда вы задаете вопрос и дергаете за ручку, вы получаете ответ, который может быть чудесным… а может и не быть. Проблема в том, что сбои бывают крайне непредсказуемыми.
Сила этих моделей определяется тем, насколько легко проверить ответы, которые они дают. Например, у GPT-3 довольно хорошие математические способности. Он может не только выполнять простые арифметические действия, а способен даже интерпретировать текстовые задачи на уровне средней школы или выше. Я попросил chatGPT решить простую математическую задачу, с которой он справился хорошо:

И когда я усложнил задачу до больших чисел, он продолжал работать:

Но на самом деле он не обучился умножению, а просто симулирует знание. Если у меня есть N коробок с X мелками в каждой и N * X = Y, то у меня есть Y мелков. И если у меня есть X коробок с N мелками в каждой, любой ребенок скажет, что у меня все еще есть Y мелков!
Посмотрим, что думает chatGPT:

Этот ответ на самом деле лучше, чем у предыдущей версии GPT3. Она просто уверенно объявила бы совершенно неверный ответ:

По крайней мере, теперь ИИ знает, что не может дать правильный ответ! Я выбрал этот пример, потому что на нём легко увидеть, насколько неверен ответ. А как насчет более сложных ситуаций? Когда мы смотрим на картинку, созданную ИИ, достаточно легко оценить, хороша она или плоха. Если же речь идёт о кандидате в лекарства, разработанном ИИ, то для оценки его качества придётся сначала синтезировать его и протестировать в реальном мире. Это не означает, что «ИИ плохие и ненадежные»; это лишь означает, что при работе с ними необходимо помнить об этой непредсказуемости и учитывать ее.
Причём иногда непредсказуемость может быть и хорошей. Помните, что многие возможности, которые продемонстрировали новые модели, являются эмерджентными, то есть они не программировались специально. GPT2 был в основном машиной словесных ассоциаций. Но когда OpenAI создал GPT3, сделав его мощнее предшественника в сто раз, исследователи обнаружили, что его можно обучить ответам на такие вопросы, как «когда вымерли динозавры?» без необходимости специально затачивать модель под вопросы и ответы. То же самое относится и к его способности выполнять команды — у этих моделей есть огромный запас возможностей.
И эти модели (почти) универсальны. Тот факт, что их можно использовать для привязки языка к разным предметным областям или для непосредственного сопоставления разных предметных областей, делает их гибкими и простыми в использовании, чего раньше не было с моделями ИИ. Круто было бы взять обученную модель и масштабировать ее на множество различных вариантов использования, и сейчас мы к этому приблизились.
Появляются стартапы, предлагающие инструменты на основе ИИ для создания контента, и некоторые из них добиваются большого коммерческого успеха. Модели, подобные Alphafold, позволяют сократить огромные объемы исследований в области вычислительной биологии. Помощники для программистов переходят от привычных инструментов автозаполнения к чему-то, что может помочь разработчикам быстро создать код из простой спецификации. Предыдущие крупные прорывы в области искусственного интеллекта, будь то в беспилотные автомобили или игры, в основном не уходили дальше исследовательских центров. Сейчас же любой может использовать приложения для создания текста с помощью GPT3 или загрузить Stable Diffusion.
Делать прогнозы сложно. Пожалуй, единственное, что мы можем сказать, это то, что эти инструменты искусственного интеллекта будут становиться всё мощнее, проще в использовании и дешевле. Мы находимся на ранних стадиях революции, которая может стать такой же значимой, как открытие закона Мура.
