Комментарии 41
Вопрос с фотографией остается открытым. Она режется довольно грубо. А ведь найти прямоугольник не такая проблема.
Фотография с загранника идет на бейджи, потому ее нужно вырезать хорошо.
Плюс были проблемы у меня с разной контрастностью фотографий со сканера. Поддержка сказала, покрути контраст и все распознается — но это как то глупо. Я делал скан на дефолтных настройках сканера. Примеры уже не найду.
Кстати, жалко что .net — портировать на linux лично нам бы хотелось.
Имеет ли клиент права поставить локальную версию на сервер и использовать ее всем пользователям, пусть с ограниченями?
Смотрел продукт от когнитива, ваших конкурентов. Я просто выпал в осадок от их программы для дестопа, мало что там документация поразбросана по папкам на диске, так там жесть какая то в плане интерфейса с 2005 года. Диск отпечатан на принтере, видно что админ и сам диск подготавливал… Вы тут монополисты по удобству. Даже просто говорит неочем.
У вас дистрибутив — примеры, api, ядро. Все просто и понятно.
Фотография с загранника идет на бейджи, потому ее нужно вырезать хорошо.
Плюс были проблемы у меня с разной контрастностью фотографий со сканера. Поддержка сказала, покрути контраст и все распознается — но это как то глупо. Я делал скан на дефолтных настройках сканера. Примеры уже не найду.
Кстати, жалко что .net — портировать на linux лично нам бы хотелось.
Имеет ли клиент права поставить локальную версию на сервер и использовать ее всем пользователям, пусть с ограниченями?
Смотрел продукт от когнитива, ваших конкурентов. Я просто выпал в осадок от их программы для дестопа, мало что там документация поразбросана по папкам на диске, так там жесть какая то в плане интерфейса с 2005 года. Диск отпечатан на принтере, видно что админ и сам диск подготавливал… Вы тут монополисты по удобству. Даже просто говорит неочем.
У вас дистрибутив — примеры, api, ядро. Все просто и понятно.
Про фотографию — учтём. Спасибо, что обратили внимание на важный сценарий с бейджом! Прежде всего делали акцент на качестве распознавания текста и недосмотрели.
С контрастностью не очень понятно — хорошо бы примеры. Изображения перед обработкой нормализуются и не очень зависят от контраста. Возможно, при сканировании терялась информация в светах и тенях.
Для портирования у нас есть FlexiCapture Engine — и мы уже подумываем об этом. Как написано в статье, всё что может PassportReader может и большое SDK. Потребуеться немного лишних телодвижений для настройки и доработки, но пользователей линукса этим, думаю, не напугать ).
Про установку на сервер локальной версии — мне кажется, что не должно быть никиких ограничений на этот счёт. Уточню и напишу позже, если это не так
С контрастностью не очень понятно — хорошо бы примеры. Изображения перед обработкой нормализуются и не очень зависят от контраста. Возможно, при сканировании терялась информация в светах и тенях.
Для портирования у нас есть FlexiCapture Engine — и мы уже подумываем об этом. Как написано в статье, всё что может PassportReader может и большое SDK. Потребуеться немного лишних телодвижений для настройки и доработки, но пользователей линукса этим, думаю, не напугать ).
Про установку на сервер локальной версии — мне кажется, что не должно быть никиких ограничений на этот счёт. Уточню и напишу позже, если это не так
Спасибо. Кстати, я бы хотел иметь возможность распозновать паспорт не только всего разворота, а только той половины, где есть фото. Потому что не очень бы хотелось хранить в базе избыточную информацию. (сканы сохраняем) А там получается что 20-40% jpg размера уходит на половину с подписью. Подпись, к примеру, нас не интересует, потому что сами понимаете, та каркуля не обязана быть чем то что от нее требуется. В итоге при большой базе размер ее мог быть не 1 гб (300-500kb на половинку в хор качестве) а 500-700mb.
Конечно, мы можем сами отрезать половину, так как вы возвращаете скан по контору, но все же не кашерно)
Более того, вынуждены пользоваться сканерами формата А5 а не A6 — к примеру этот Fujitsu FI-60f. С последнего сканера не получится сегодня скармливать сканы паспорта, ибо половинки не находятся как файлы для распознованя. Преимущетсва Fujitsu FI-60f в его скорости (цена правда пипец, но скан за 2 секунды это здорово)
Конечно, мы можем сами отрезать половину, так как вы возвращаете скан по контору, но все же не кашерно)
Более того, вынуждены пользоваться сканерами формата А5 а не A6 — к примеру этот Fujitsu FI-60f. С последнего сканера не получится сегодня скармливать сканы паспорта, ибо половинки не находятся как файлы для распознованя. Преимущетсва Fujitsu FI-60f в его скорости (цена правда пипец, но скан за 2 секунды это здорово)
Всё таки я был не прав. Текущая EULA запрещает использование локальной версии на сервере.
Да, у вас политика такая, что чуть ли не цвет мочи сотрудников спрашивают, кто будет сидеть за аппаратом, ну то есть не проверяемая в принципе информация, все со слов: спрашивают как что сколько и зачем. Я ни чуть не сомневаюсь что кроме маркетологов знать никто не знает у вас как это там, с лицензиями)
Почему не могут поставить такую штуку на почте и в прочих госслужбах? Иногда приходится заполнять по нескольку бланков за раз, где только паспортные данные.
Работал с аналогом от конкурентов (разработчик ныне опенсорсной CuneiForm)
Демку в своё время присылали очень оперативно, качество работы на внутренних паспортах РФ очень понравилось.
Будет интересно попробовать и этот продукт.
Демку в своё время присылали очень оперативно, качество работы на внутренних паспортах РФ очень понравилось.
Будет интересно попробовать и этот продукт.
А ещё у нас в России регулярно вот такое попадается.
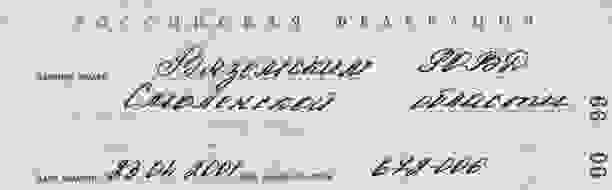
До сих пор такие паспорта вполне себе действительны и никто их не меняет без крайней на то нужды.
И это не смотря на все новшества и наличие машиночитаемой полосы на новых внутренних паспортах:
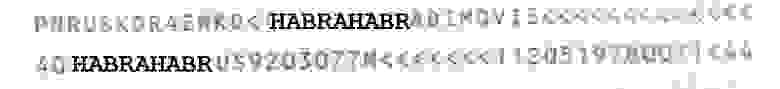
Кстати, почему бы не распознать и её?
В Украине же это вообще стандарт для внутреннего паспорта:

Печатать текст в этих полях стали совсем недавно:

P.S. все примеры найдены в Google и дополнительно обезличены.

До сих пор такие паспорта вполне себе действительны и никто их не меняет без крайней на то нужды.
И это не смотря на все новшества и наличие машиночитаемой полосы на новых внутренних паспортах:

Кстати, почему бы не распознать и её?
В Украине же это вообще стандарт для внутреннего паспорта:

Печатать текст в этих полях стали совсем недавно:

P.S. все примеры найдены в Google и дополнительно обезличены.
Да, с рукописными документами мы вряд ли справимся в полной мере, хотя номер и фотографию, думаю, найдём без проблем. Хорошо, что таких документов не так много осталось.
Машиночитаемую область мы распознаём, где находим и специально обрабатываем. Это фишка PassportReader-а, которую упустил в основной статье, спасибо, что обратили на это внимание )
Машиночитаемую область мы распознаём, где находим и специально обрабатываем. Это фишка PassportReader-а, которую упустил в основной статье, спасибо, что обратили на это внимание )
Вопрос с галёрки: планируется ли расширение списка стран, и если да, то как скоро и какие приоритеты?
Да, планируется, но, в рамках данного продукта, только для ближайших соседей (стран СНГ). Приоритет будет определяться потребностями пользователей — вы на него можете повлиять.
Поддержку отдельных стран и типов документов мы можем при необходимости делать достаточно оперативно — без глубокого тестирования несколько дней. В разработке данного продукта у нас очень короткие циклы и мелкие правки и доработки можем делать в течении дня.
Если интересует что-то конкретное, можете спрашивать прямо здесь
Поддержку отдельных стран и типов документов мы можем при необходимости делать достаточно оперативно — без глубокого тестирования несколько дней. В разработке данного продукта у нас очень короткие циклы и мелкие правки и доработки можем делать в течении дня.
Если интересует что-то конкретное, можете спрашивать прямо здесь
Меня интересуют удостоверние личности и паспорт Республика Молдова (также в этом могут быть заинтересованы тысячи российских работодателей)
В ближайших планах пока не стоит, но мы с удовольствием это обсудим.
А какие документы для этих стран вы обрабатываете? Только паспорта?
РФ, а в данный момент делают уже для стран СНГ.
Какиеименно документы я думаю не лень будет перейти по ссылке встатье на оф сайт)
Какиеименно документы я думаю не лень будет перейти по ссылке встатье на оф сайт)
Полный список типов документов, включённых в текущий дистрибутив:
RU: Паспорт, Водительское удостоверение, Загранпаспорт, Свидетельство о рождении
AZ: Удостоверение личности, Загранпаспорт
BY: Паспорт, Загранпаспорт
KZ: Удостоверение личности, Водительское удостоверение, Загранпаспорт,
KG: Удостоверение личности, Водительское удостоверение
TJ: Паспорт, Загранпаспорт
UZ: Водительское удостоверение, Загранпаспорт
Для любых локалей: Загранпаспорт (машиночитаемая зона)
Ситуация меняеться и эта информация быстро устареет
RU: Паспорт, Водительское удостоверение, Загранпаспорт, Свидетельство о рождении
AZ: Удостоверение личности, Загранпаспорт
BY: Паспорт, Загранпаспорт
KZ: Удостоверение личности, Водительское удостоверение, Загранпаспорт,
KG: Удостоверение личности, Водительское удостоверение
TJ: Паспорт, Загранпаспорт
UZ: Водительское удостоверение, Загранпаспорт
Для любых локалей: Загранпаспорт (машиночитаемая зона)
Ситуация меняеться и эта информация быстро устареет
А есть HTTP/REST/JSON интерфейс? Т.е. некий сервис который можно запустить и система будет доступна из систем на разных языках, Java, PHP, etc…
Сам такой хочу, потому что файн ридер у них работает через API на azure. Вариант сейчас только такой — хостинг windows, вебсервер, обертка к SDK для работы с вебсервером. И общаться через https. Они говорят, что такое не сделали, потому что не все доверятся сливать доки кому то налево. От того решения только на руки. Плюс у них ключ железный, сейчас веду разговор чтобы дали только серийник ибо на сервер я tuj не могу физически воткнуть. С нашим штатом еще админить свои серваки не хватало…
Но если ребята реализуют! Мы просто с экономим деньги.
Но если ребята реализуют! Мы просто с экономим деньги.
Мы об этом думаем. В нашем облачном API сейчас есть возможность распознавать машиночитаемую зону документов
Вот здесь подробности. На сайте оказалось не так просто найти
Кстати, а вас не смущает передача картинок документов по сети на сторонний сервер? Нам кажется, что это может быть серьёзной проблемой для подобной архитектуры
У нас интернет 1 mbit стоит 2200р в месяц. (Угу!) То есть чтобы обеспечить нормальную скорость к серверу и нам на просмотр котиков хватало, нужно как минимум брать тариф больше… за 8тр 5 mbit. И платить за сервера и администратирование!
А случаем 8тр в месяц некуда больше потратить? Да проще на Azure что взять! Хотя я у нас нашел решение. Аренда: windows, анлим по трафику, гарант полосы в 10 mbit, 2x3ггц, 50 gb места. Не дороже 16-18тр в год! Бекапа хватит одного ибо это не база данных.
По безопасностти… ну https + хостингу доверяю. Да и у нас в стране кому надо, и так базы найдут где купить.
Елинственное что — пинги и задержки вебсервиса, чуть медленный https. А так удобнее всего аренда лично нам.
А случаем 8тр в месяц некуда больше потратить? Да проще на Azure что взять! Хотя я у нас нашел решение. Аренда: windows, анлим по трафику, гарант полосы в 10 mbit, 2x3ггц, 50 gb места. Не дороже 16-18тр в год! Бекапа хватит одного ибо это не база данных.
По безопасностти… ну https + хостингу доверяю. Да и у нас в стране кому надо, и так базы найдут где купить.
Елинственное что — пинги и задержки вебсервиса, чуть медленный https. А так удобнее всего аренда лично нам.
И ещё вопрос. Если бы мы в дистрибутив включили в качестве примера простую реализацию web-сервисв — прислал POST-ом картинку, получил в ответ XML-ку — это бы покрыло ваши потребности?
удостоверяющих личность граждан России и стран СНГ.
Правильно ли я понимаю, что украинские паспорта не распознаются, поскольку Украина — не член СНГ?
Правильно ли я понимаю, что украинские паспорта не распознаются, поскольку Украина — не член СНГ?
как не член?
На самом деле про страны СНГ там имелось в виду в широком смысле без привязки к политике. Следует читать скорее как «близкие соседи» :)
Украинских документов сейчас нет, но обязательно будут. Чтобы это произошло быстрее вы можете высказать своё горячее пожелание.
Украинских документов сейчас нет, но обязательно будут. Чтобы это произошло быстрее вы можете высказать своё горячее пожелание.
Интересная вещь.
Если это .Net, то будет работать в Windows Phone 7/8, в Mono для Android и iOS (Xamarin)?
Если это .Net, то будет работать в Windows Phone 7/8, в Mono для Android и iOS (Xamarin)?
.Net здесь только обёртка. Поэтому, к сожалению на мобильных платформах работать не будет.
Для мобильных платформ у нас есть:
1) ABBYY Cloud OCR SDK — дешёвый старт при этом легко масштабируется; есть распознавание машиночитаемой области документов (MRZ); примеры клиентов под разные платформы
2) ABBYY Mobile Data Capture Solution — создание собственного сервера распознавания на базе FlexiCapture Engine или FineReader Engine с участием наших Professianal Services, на мобильном устройстве клиентская часть
3) ABBYY Mobile OCR Engine — это будет работать непосредственно на устройстве, но всю data capture часть придёться ваять самим
Для мобильных платформ у нас есть:
1) ABBYY Cloud OCR SDK — дешёвый старт при этом легко масштабируется; есть распознавание машиночитаемой области документов (MRZ); примеры клиентов под разные платформы
2) ABBYY Mobile Data Capture Solution — создание собственного сервера распознавания на базе FlexiCapture Engine или FineReader Engine с участием наших Professianal Services, на мобильном устройстве клиентская часть
3) ABBYY Mobile OCR Engine — это будет работать непосредственно на устройстве, но всю data capture часть придёться ваять самим
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
ABBYY PassportReader SDK – когда вообще ничего не нужно настраивать