Комментарии 20
Как оказывается это увлекательно и интересно. Спасибо! Жду продолжения.
А как это локации «в столе» нет, а как же тумбочка в столе и т.п.?
При этом есть фраза «писАть в стол».
Да, вы правы. Есть такая локация «в столе». Имелось в виду, что в языке не закрепилась форма «в столу» или что-то подобное. У «стола» есть локативный падеж, но он совпадает с предложным.
На самом деле, в нашем языке закрепилось всего несколько десятков существительных, у которых локатив отличается от предложного падежа. По какому принципу у других слов отпала особая локативная форма — можно только догадываться.
На самом деле, в нашем языке закрепилось всего несколько десятков существительных, у которых локатив отличается от предложного падежа. По какому принципу у других слов отпала особая локативная форма — можно только догадываться.
А про нечеткие дубликаты текста можете рассказать так же увлекательно?
Кит конспирируется?
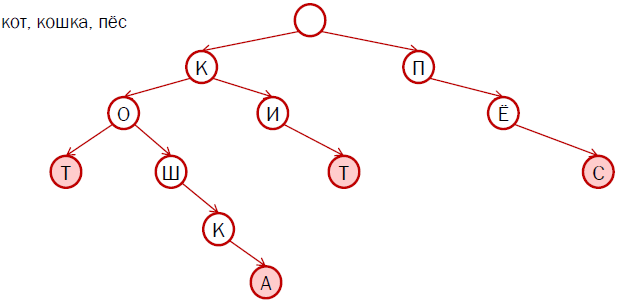
Однажды в фирме где я делал сайты, две девушки-лингвистки на соседнем проекте проверяли списки корней и гнёзда окончаний, исправляли разные исключения — теперь понял что конкретно они делали. Отлаживали подобный словарь.
И как видно из вашего объяснения для каждого языка нужна совершенно своя схема хранения словаря? Ведь есть же языки в которых меняются не окончания, а середины слов, или слова сливаются воедино? А есть и языки где нет букв. И на каждый язык требуется работа программистов совместно со специалистом по этому языку, так ведь?
И как видно из вашего объяснения для каждого языка нужна совершенно своя схема хранения словаря? Ведь есть же языки в которых меняются не окончания, а середины слов, или слова сливаются воедино? А есть и языки где нет букв. И на каждый язык требуется работа программистов совместно со специалистом по этому языку, так ведь?
Есть разные группы языков с разными свойствами. Например, Агглютинативные языки. Под каждую группу приходится несколько модифицировать структуру хранения и логику работы со словарем. Есть еще особенности написания слов, например, композиты в немецком или отсутствие пробелов в тайском, и это решается дополнительной логикой разбора слов. Как Вы правильно заметили, есть еще иероглифические языки (китайский), но там словарь просто вырождается во множество коротких цепочек. Японский, кстати, в этом смысле особенный, там часть к иероглифам приписывают окончания с помощью алфавитного письма, но это не представляет собой большую проблему с точки зрения организации словаря. Но если учесть особенности очередной группы языков, то дальше уже не нужно под каждый язык что-то специальное придумывать.
По поводу японского: запросто могут записать и все слово хираганой, и, в случае глагола/прилагательного, основу — катаканой, окончание — хираганой… Так что просто цепочкой, показанной в статье, тут уже не обойдешься. Или она вырастет в два с половиной-три раза.
В японском тогда омонимов будет очень много.
Кстати об омонимах. А как с ними будут обстоять дела в подобном словаре? Или это уже проблемы другого слоя — лексики?
Кстати об омонимах. А как с ними будут обстоять дела в подобном словаре? Или это уже проблемы другого слоя — лексики?
Омонимов много, да. Но это смотря как записывать. С речью вариантов кроме анализа смысла никаких. Вот, например, три слова, читающееся как «koumon»: "校門", "閘門", "肛門" (соответственно «школьные ворота», «шлюз» и, простите, «задний проход»). Их все можно записать как "こうもん" или "コウモン", что, при соответствующем контексте, не помешает пониманию смысла конкретного слова. А вот для машины это будут огромные проблемы.
В семитских языках типично словоизменение сменой огласовок; т.е. меняется не «середина» слова, а сразу по всей длине слова меняются звуки.
Например, мн.ч. в арабском: сафӣна «корабль» — суфун «корабли», гурфа «комната» — гураф «комнаты», раджуль «мужчина» — риджа̄ль «мужчины».
(Подробнее в Википедии)
Например, мн.ч. в арабском: сафӣна «корабль» — суфун «корабли», гурфа «комната» — гураф «комнаты», раджуль «мужчина» — риджа̄ль «мужчины».
(Подробнее в Википедии)
К примеру, для русского языка это дерево вместе с дополнительными данными занимает порядка 2 мегабайт. Во-первых, по сравнению с 75 мегабайтами это, безусловно, успех.
Хм, интересно. Для уточнения — цифры тут про одно дерево или про способ хранения, описанный далее в статье?
У меня были такие эксперименты: берем 3млн слов (весь словарь OpenCorpora), загружаем их в Trie, получаем 100-200M занятой памяти (в зависимости от реализации дерева).
Я пробовал только реализации префиксных деревьев с «полным» алфавитом; уменьшение алфавита до 33 символов может максимум раз в 7 объем памяти уменьшить (на практике меньше), так что для основанного на указателях дерева, похожего на то, что тут описано, вместо 200Мб должно около 25-30Мб получиться. Дальше, у меня была кодировка utf8; при использовании однобайтовой кодировки до 15-20Мб сжаться все может (в 2 раза не выйдет, т.к. Trie хорошо жмет utf8). Если посчитать, что «несколько сот тысяч» — это раз в десять меньше, чем 3млн, и что размер Trie линейно зависит от количества слов (опять очень грубо), то 2Мб и правда как раз получается :) Хотя выглядит цифра все равно немного странно, по прикидкам все же больше должно быть. Это точно не цифра, которая получается с двумя префиксными деревьями?
Что интересно, 3млн слов, закодированные в utf8 и загруженные «как есть» в DAFSA/DAWG (брал готовую реализацию dawgdic) с алфавитом 256 символов, тоже мегабайта 2-3 занимают (7 с грамматической информацией и информацией о парадигмах для склонения), и разбор потом проще/быстрее, т.к. не нужно с двух концов идти и сопоставлять результаты.
В русском языке есть фишка — слова, оканчивающиеся одинаково, вероятно, имеют одинаковую форму и парадигму, поэтому DAWG может и эту информацию эффективно сжимать и не «разваливается» в Trie, если ее просто приписывать в конец слов.
Локатив, партитив…
Предложный падеж всегда вызывал подозрения — покуда отвечает на вопросы и «где?» и «куда?», хотя сами вопросы, очевидно, разные. Почему-то кажется, что их можно различить чередованием «е» и «и» в конце (например, «приехал (куда?) в Залесье» или «живу (где?) в Залесьи») — однако нет такого правила! На безударном окончании всегда будет «е».
ЗЫ. А как же ещё звательный падеж? «Отче наш...» Девятый, выходит!
Предложный падеж всегда вызывал подозрения — покуда отвечает на вопросы и «где?» и «куда?», хотя сами вопросы, очевидно, разные. Почему-то кажется, что их можно различить чередованием «е» и «и» в конце (например, «приехал (куда?) в Залесье» или «живу (где?) в Залесьи») — однако нет такого правила! На безударном окончании всегда будет «е».
ЗЫ. А как же ещё звательный падеж? «Отче наш...» Девятый, выходит!
Падежей на самом деле намного больше чем указанное количество. В разное время исследователи выделяли до 16 разных вариантов.
Примеры можно посмотреть здесь: russian.stackexchange.com/questions/404/what-are-the-lesser-known-russian-cases?lq=1
Примеры можно посмотреть здесь: russian.stackexchange.com/questions/404/what-are-the-lesser-known-russian-cases?lq=1
Куда? в ... — это винительный, а не предложный.
Они различаются у большинства слов, совсем не обязательно чередованием «е» и «и».
Куда? в руку. Где? в руке.
Куда? в окно. Где? в окне.
Куда? в ящик. Где? в ящике.
Куда? в кота. Где? в коте.
Они различаются у большинства слов, совсем не обязательно чередованием «е» и «и».
Куда? в руку. Где? в руке.
Куда? в окно. Где? в окне.
Куда? в ящик. Где? в ящике.
Куда? в кота. Где? в коте.
Кстати, мымымымыться можно проверить с помощью регулярок. Кажется, повторение слога более трех раз в русском не встречается
Очень интересная статья. А можно ссылку на сам словарь? Или это Ваше ноу-хау?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Морфология. Задачи и подходы к их решению