 Привет, Хабр! Меня зовут Даня, и я работаю в группе извлечения знаний ДогадайтесьКакойКомпании. В двух постах я расскажу,
Привет, Хабр! Меня зовут Даня, и я работаю в группе извлечения знаний ДогадайтесьКакойКомпании. В двух постах я расскажу,- как мы извлекаем факты и сущности из текстов,
- кто такие онтоинженеры,
- зачем они отделяют трупы от костей,
- причём здесь Лев Толстой.
На Хабре уже было несколько публикаций, посвященных извлечению информации из неструктурированного текста (много чего ищется по тегами Text Mining, Information Extraction). Вот здесь, например, приведен краткий джентльменский набор того, что желательно сделать с текстом, прежде чем из него будет удобно что-нибудь извлечь (спойлер: мы все это тоже делаем). А вот тут коллеги из Яндекса описывают свой подход с использованием КС-грамматик (кстати, там тоже замешан Толстой). В общем, тема для Хабра не новая, но и нельзя сказать, что достаточно раскрытая. Потому мы и решили поделиться нашим опытом.
Мы в ABBYY любим подходить к проблемам фундаментально и придумывать универсальные, долгосрочные, масштабируемые решения. Вот и здесь, когда возникла задача извлекать информацию из текста, мы не стали лепить ничего на коленке из скриптов и регекспов, а применили тяжелую лингвистическую артиллерию – технологию ABBYY Compreno.
Чем дальше в лес: плохие программисты и хорошие традиции
Парсер ABBYY Compreno превращает текст в лес из деревьев, которые объединяют в себе свойства грамматики зависимости (dependency grammar, ее использует знакомый многим стэнфордский парсер) и грамматики составляющих (constituency grammar). Не буду вдаваться в подробности и уходить в дебри теории синтаксиса — здесь достаточно понимать, что узлы в деревьях примерно соответствуют словам предложения, а дуги отражают зависимости между ними. При этом узлы снабжены огромным количеством сопутствующей лингвистической информации. Вот так выглядит дерево для фразы Программист написал плохой код.

А теперь сравните его с деревом для фразы Программист ввел неправильный код

Зеленый текст капсом – это семантические классы, которые выбираются для каждого слова в нашей универсальной семантической иерархии. Семантическая иерархия — это огромное дерево понятий, организованное по принципу наследования лингвистической информации и охватывающее все части речи; кроме того, в него заложена наша синтаксическая модель. Семантические классы в иерархии традиционно называются по-английски и соответствуют одному конкретному значению слова, некоторому не завязанному на конкретный язык понятию. Таким образом, в момент выбора семантического класса разрешается лексическая неоднозначность. Пример такого выбора виден на слове код, для которого в первом предложении выбран СК “CODE_OF_PROGRAM” (код как часть компьютерной программы), а во втором – СК “CODE” (код как шифр, пароль). На решение системы в таких случаях влияет как статистика, так и ограничения лингвистической структуры, заданные внутри нашей семантической иерархии.

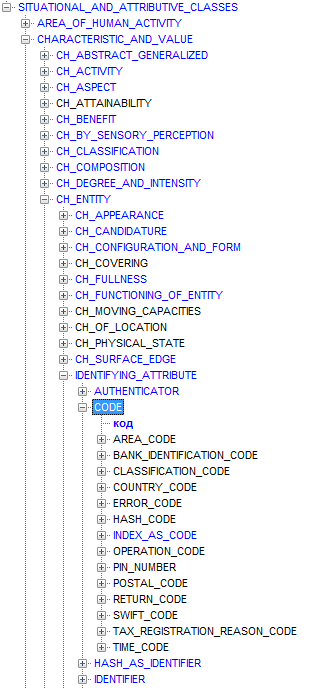
Так выглядят фрагменты иерархии, в которых находятся упомянутые классы
А вот еще один пример разрешения неоднозначности — Программист ввел традицию кодить без багов. Здесь, как мы видим, выбран совсем другой семантический класс для словоформы ввел, поскольку слово используется совсем в другом значении.

Синим в деревьях отображаются позиции узлов в поверхностном синтаксисе – это формальная структура предложения, не имеющая прямого отношения к его смыслу. Это очень близко к школьной модели с подлежащим, сказуемым, дополнением и т.п. Красным цветом указаны глубинные позиции – они уже показывают, какую роль играет элемент в описываемой ситуации. Поэтому если перевести первый пример про программиста в пассив — Программистом написан плохой код – в дереве изменится поверхностный Subject (т.к. подлежащим там становится уже не программист, а код), но не глубинный Agent (т.к. в реальности, которую описывает фраза, действие по-прежнему осуществляет программист):

Помимо семантико-синтаксических деревьев парсер ABBYY Compreno возвращает информацию о недревесных связях между их узлами. Например, для фразы Вася сидел за компьютером и кодил для глагола «кодить» будет восстановлен нулевой субъект, который будет связан недревесной связью с узлом «Вася»:

То же самое произойдет и в предложении Вася ушел писать код — с точки зрения грамматической структуры Вася активно выполняет только действие, обозначаемое глаголом «ушел», но мы-то знаем, кто пишет код:

Не удастся Васе и скрыть свои темные дела, спрятавшись за местоимением. В примерах типа "Вася ушел.", "Он пошел кодить" или "Васе нравится его код" Compreno восстановит анафорическую связь и заменит местоимения ("Он", "его") на Васю:



Сотворение мира
Подробнее о том, как работает парсер ABBYY Compreno, можно почитать здесь. Я же перейду непосредственно к теме поста и начну рассказывать, как организовано извлечение фактов и сущностей на базе этой лингвистической платформы. Здесь-то и вступают в дело онтоинженеры – специалисты по созданию формальных моделей мира (онтологий) и извлечению информации, соответствующей этим моделям. Задача онтоинженера – сначала придумать формальное представление некоторых информационных объектов, которые нужно извлекать, а потом разработать систему правил, по которым они будут извлекаться из леса Compreno-деревьев.
Первый этап работы – разработку онтологической модели – можно сравнить с созданием классов в ООП. Например, если перед онтоинженером поставлена задача извлекать из текста персон, необходимо создать соответствующий концепт (это слово в онтологическом моделировании используется как эквивалент класса), встроить его в онтологию, т.е. установить наследование с другими концептами, и создать необходимые атрибуты – имя, фамилию и т.п. Для этого мы используем язык OWL – стандарт описания онтологий, поддерживаемый консорциумом W3С. Персона в нашей онтологии будет выглядеть так:
<owl:Class rdf:about="http://www.abbyy.com/ns/BasicEntity#Person">
<rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#HumanLikeSubject"/>
<rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#BasicEntity"/>
<rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#IdentifiableThing"/>
<rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/Basic#EntityLikeSubject"/>
<Aux:LeadingParent rdf:resource="http://www.abbyy.com/ns/Basic#BasicEntity"/>
<rdfs:label xml:lang="En">Person</rdfs:label>
<rdfs:label xml:lang="Ru">Персона</rdfs:label>
<rdfs:comment xml:lang="En">For example: Mikhail Yuryevich Lermontov was born on October 15, 1814 in Moscow.</rdfs:comment>
<rdfs:comment xml:lang="Ru">Например: Михаил Юрьевич Лермонтов родился 15 октября 1814 года в Москве.</rdfs:comment>
</owl:Class>
А так – ее атрибут «Фамилия»:
<owl:DataProperty rdf:about="http://www.abbyy.com/ns/BasicEntity#surname">
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#string"/>
<rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicEntity#Person"/>
<rdfs:label xml:lang="En">Surname</rdfs:label>
<rdfs:label xml:lang="Ru">Фамилия</rdfs:label>
<rdfs:comment xml:lang="En">Mikhail Yuryevich Lermontov: Surname - Lermontov</rdfs:comment>
<rdfs:comment xml:lang="Ru">Михаил Юрьевич Лермонтов: Фамилия - Лермонтов</rdfs:comment>
</owl:DataProperty>
Концепт, для которого задается атрибут, называется областью определения (domain) этого атрибута. В данном случае область определения – объекты, принадлежащие концепту Person. Тип данных, которые могут заполнять атрибут, задается в области значения (range). В данном случае это строка.
Для удобства работы онтоинженеров создана специальная графическая среда разработки онтологий:

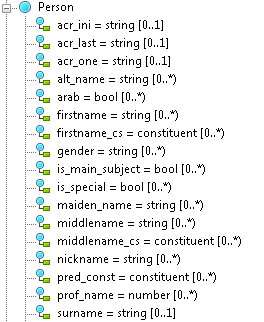
Кружки обозначают концепты; кружки, соединенные линиями – атрибуты/отношения концептов,
В зависимости от концепта заполнителями его атрибутов могут быть как простые типы данных (строка, число, булево значение), так и объекты, относящиеся к другим концептам. Особенно это актуально для фактов, в которых участниками выступают извлеченные другими правилами сущности. Почти все факты с несколькими возможными участниками мы моделируем не как отношения, записываемые внутрь сущностей, а как отдельные информационные объекты, аналогичные сущностям (кстати, это тоже рекомендация W3C). Так выглядит в OWL-записи наш факт купли-продажи (Purchase And Sale):
<owl:Class rdf:about="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale">
<rdfs:subClassOf rdf:resource="http://www.abbyy.com/ns/BasicFact#OperationWithProperty"/>
<rdfs:label xml:lang="En">Purchase And Sale</rdfs:label>
<rdfs:label xml:lang="Ru">Купля-продажа</rdfs:label>
</owl:Class>
А так – его отношения:
<owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#seller">
<rdfs:range rdf:resource="http://www.abbyy.com/ns/Basic#Subject"/>
<rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale"/>
<rdfs:label xml:lang="En">Seller</rdfs:label>
<rdfs:label xml:lang="Ru">Продавец</rdfs:label>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#customer">
<rdfs:range rdf:resource="http://www.abbyy.com/ns/Basic#Subject"/>
<rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale"/>
<rdfs:label xml:lang="En">Customer</rdfs:label>
<rdfs:label xml:lang="Ru">Покупатель</rdfs:label>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#price">
<rdfs:range rdf:resource="http://www.abbyy.com/ns/BasicEntity#Money"/>
<rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#PurchaseAndSale"/>
<rdfs:label xml:lang="En">Price</rdfs:label>
<rdfs:label xml:lang="Ru">Цена</rdfs:label>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="http://www.abbyy.com/ns/BasicFact#property">
<rdfs:range rdf:resource="http://www.abbyy.com/ns/Basic#ExtendedProfit"/>
<rdfs:domain rdf:resource="http://www.abbyy.com/ns/BasicFact#OperationWithProperty"/>
<rdfs:label xml:lang="En">Property</rdfs:label>
<rdfs:label xml:lang="Ru">Имущество</rdfs:label>
</owl:ObjectProperty>
Как видно по области значения (range), все эти отношения заполняются не простыми типами данных, а ссылками на объекты других концептов. Например, отношение price может заполняться только «денежными» сущностями, т.е. объектами концепта BasicEntity#Money или его потомков.
О том, как это работает и каким образом одни объекты попадают в отношения к другим, читайте в следующей статье.
