И снова здравствуйте!
Надеюсь, вас заинтересовал наш вчерашний пост про систему извлечения информации ABBYY Compreno, в котором мы рассказали про архитектуру системы, семантико-синтаксический парсер и его роль и, самое главное, про информационные объекты.
Теперь настало время поговорить о самом интересном – как устроен сам движок извлечения информации.

Итак, целью нашей системы является построить RDF-граф с извлеченной информацией.
Однако генерация RDF-графа происходит только в самом конце работы системы. В процессе работы для хранения извлекаемой информации используется более сложный объект, который мы называем «мешком утверждений». Он представляет собой множество не противоречащих друг другу логических утверждений об информационных объектах и их свойствах.
Вся работа системы извлечения информации может быть описана как процесс наполнения мешка утверждений.
Важные свойства мешка утверждений:
Основное отличие RDF-графа от мешка утверждений в том, что последний допускает наличие функциональных зависимостей.
Например, можно утверждать, что множество значений некоторого свойства одного объекта всегда включает множество значений какого-то другого свойства другого объекта. Такие зависимости являются динамическими, их пересчет система осуществляет сама.
В данной статье нет возможности разбирать утверждения подробно. Основные типы утверждений приведены на рисунке ниже.

Подробнее об утверждениях мы рассказывали в статье на конференции Диалог.
Кто же заполняет мешок утверждений?
Мешок утверждений заполняется в процессе применения правил. Существует два типа правил:
Но как происходит срабатывание правил?
Ключевым понятием для понимания алгоритма является сопоставление. Под сопоставлением мы понимаем следующее:
Работа алгоритма начинается с того, что система обрабатывает правила, содержащие только шаблоны на деревья разборов (без объектных условий). Ни одного объекта в «мешке утверждений» пока нет, поэтому правила с объектными условиями пока не участвуют в генерации сопоставлений.
Все найденные сопоставления помещаются в специальную отсортированную очередь сопоставлений. Эта очередь является важной структурой, процесс извлечения продолжается, пока эта очередь содержит хотя бы одно сопоставление. Очередь динамически пополняется новыми сопоставлениями в процессе работы, но не будем забегать вперед.
Итак, первые сопоставления были сгенерированы и помещены в очередь. Теперь система начинает обращаться к очереди и на каждом шаге извлекает самое приоритетное сопоставление. На приоритет, с одной стороны, могут влиять онтоинженеры (на множестве правил задано отношение частичного порядка), с другой стороны и сама система может вычислять наиболее удачное сопоставление.
После того, как выбрано самое приоритетное сопоставление, по правой части того правила, из которого оно было получено, формируется набор утверждений. Система пытается сделать так, чтобы эти утверждения вступили в силу, т.е. пытается поместить этот набор в общий мешок утверждений. Тут возможны нюансы – утверждения могут вступить в противоречие с утверждениями, добавленными в мешок ранее.
Противоречия могут быть разных типов:
Если вставка не удалась (нашлось противоречие), то сопоставление отбрасывается и из очереди выбирается следующее. В случае успешной вставки перед выбором следующего сопоставления запускается механизм поиска новых сопоставлений, и очередь сопоставлений может быть пополнена. Обратите внимание – в результате помещения новых утверждений в мешок могут начать срабатывать новые правила, поскольку меняется общий контекст. Возможны следующие изменения – появление новых объектов и «якорей», заполнение новых атрибутов объекта, появление новых концептов у объекта. Из-за этих изменений и могут начать срабатывать те правила, шаблонная часть которых прежде не могла сопоставиться, и очередь сопоставлений будет пополнена.
Описанный процесс хорошо иллюстрирует следующая диаграмма
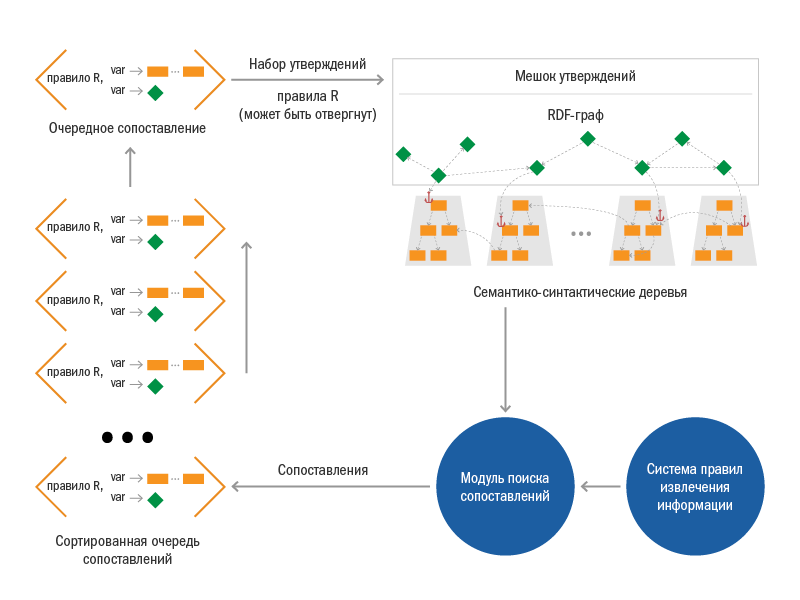
Для того чтобы реализовать все это, нам пришлось потрудиться. Одной из самых сложных компонент системы получился механизм поиска сопоставлений. В него встроен интерпретатор байт-кода скомпилированных правил, система специальных индексов над семантико-синтаксическими деревьями, модуль отслеживания изменений в мешке утверждений и некоторые другие механизмы. Отметим некоторые базовые особенности механизма поиска сопоставлений:
В результате работы у нас получился алгоритм, который обладает следующими особенностями:
Если вам захочется изучить более формальное описание алгоритма – советуем обратиться к упомянутой статье с конференции Диалог.
Эта технология предоставляет широкий круг возможностей, позволяющих нам решать различные задачи, ориентированные на актуальные потребности рынка. О том, с какими реальными бизнес-задачами мы сталкиваемся, и как с ними справляется Compreno, мы скоро расскажем в своем блоге.
Надеюсь, вас заинтересовал наш вчерашний пост про систему извлечения информации ABBYY Compreno, в котором мы рассказали про архитектуру системы, семантико-синтаксический парсер и его роль и, самое главное, про информационные объекты.
Теперь настало время поговорить о самом интересном – как устроен сам движок извлечения информации.

RDF и мешок утверждений
Итак, целью нашей системы является построить RDF-граф с извлеченной информацией.
Однако генерация RDF-графа происходит только в самом конце работы системы. В процессе работы для хранения извлекаемой информации используется более сложный объект, который мы называем «мешком утверждений». Он представляет собой множество не противоречащих друг другу логических утверждений об информационных объектах и их свойствах.
Вся работа системы извлечения информации может быть описана как процесс наполнения мешка утверждений.
Важные свойства мешка утверждений:
- Утверждения можно только добавлять. Удалять – нельзя.
- Все утверждения в мешке не противоречат друг другу.
- По мешку утверждений в любой момент можно построить аннотированный RDF-граф, согласованный с онтологией.
Основное отличие RDF-графа от мешка утверждений в том, что последний допускает наличие функциональных зависимостей.
Например, можно утверждать, что множество значений некоторого свойства одного объекта всегда включает множество значений какого-то другого свойства другого объекта. Такие зависимости являются динамическими, их пересчет система осуществляет сама.
В данной статье нет возможности разбирать утверждения подробно. Основные типы утверждений приведены на рисунке ниже.
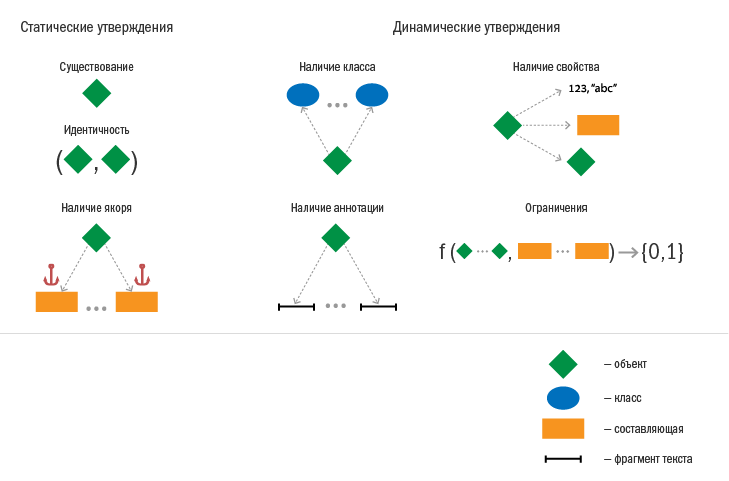
Подробнее об утверждениях мы рассказывали в статье на конференции Диалог.
Логический вывод на основе данных
Кто же заполняет мешок утверждений?
Мешок утверждений заполняется в процессе применения правил. Существует два типа правил:
- Правила извлечения информации.
Мы их уже обсуждали в прошлой статье, они позволяют описывать фрагменты семантико-синтаксических деревьев, при обнаружении которых вступают в силу определенные наборы логических утверждений. Схематично правило может быть представлено так:
[Шаблон на дерево разбора] => [набор утверждений]
Правила извлечения бывают двух типов: без объектных условий (опираются только на древесный шаблон) и с объектными условиями (опираются и на древесный шаблон, и на ранее выделенные объекты)
- Правила идентификации.
Применяются в тех ситуациях, когда требуется объединить несколько информационных объектов. Схематично может быть представлено так:
<% Условие на объект 1 %> <% Условие на объект 2 %> [Условие на объекты] => [утверждение об идентичности объектов]
Если правилу удается сработать, то мешок пополняется новыми утверждениями: в правилах извлечения информации – за счет явно выписанных утверждений в правой части правила; в правилах идентификации – за счет утверждения об идентичности.
Алгоритм извлечения информации
Но как происходит срабатывание правил?
Ключевым понятием для понимания алгоритма является сопоставление. Под сопоставлением мы понимаем следующее:
- Для правил извлечения информации – наложение древесного шаблона, описанного в правиле, на фрагмент семантико-синтаксического дерева.
- Для правил идентификации – соотнесение ограничений правила идентификации с конкретными информационными объектами.
Работа алгоритма начинается с того, что система обрабатывает правила, содержащие только шаблоны на деревья разборов (без объектных условий). Ни одного объекта в «мешке утверждений» пока нет, поэтому правила с объектными условиями пока не участвуют в генерации сопоставлений.
Все найденные сопоставления помещаются в специальную отсортированную очередь сопоставлений. Эта очередь является важной структурой, процесс извлечения продолжается, пока эта очередь содержит хотя бы одно сопоставление. Очередь динамически пополняется новыми сопоставлениями в процессе работы, но не будем забегать вперед.
Итак, первые сопоставления были сгенерированы и помещены в очередь. Теперь система начинает обращаться к очереди и на каждом шаге извлекает самое приоритетное сопоставление. На приоритет, с одной стороны, могут влиять онтоинженеры (на множестве правил задано отношение частичного порядка), с другой стороны и сама система может вычислять наиболее удачное сопоставление.
После того, как выбрано самое приоритетное сопоставление, по правой части того правила, из которого оно было получено, формируется набор утверждений. Система пытается сделать так, чтобы эти утверждения вступили в силу, т.е. пытается поместить этот набор в общий мешок утверждений. Тут возможны нюансы – утверждения могут вступить в противоречие с утверждениями, добавленными в мешок ранее.
Противоречия могут быть разных типов:
- Онтологические противоречия (нарушена кардинальность свойств, совместимость концептов одного объекта друг с другом)
- Конфликт с уже добавленным в мешок утверждением-ограничением. Такие условия могут задавать сами онтоинженеры в правилах, как правило, они представляют собой произвольные условия на граф.
Если вставка не удалась (нашлось противоречие), то сопоставление отбрасывается и из очереди выбирается следующее. В случае успешной вставки перед выбором следующего сопоставления запускается механизм поиска новых сопоставлений, и очередь сопоставлений может быть пополнена. Обратите внимание – в результате помещения новых утверждений в мешок могут начать срабатывать новые правила, поскольку меняется общий контекст. Возможны следующие изменения – появление новых объектов и «якорей», заполнение новых атрибутов объекта, появление новых концептов у объекта. Из-за этих изменений и могут начать срабатывать те правила, шаблонная часть которых прежде не могла сопоставиться, и очередь сопоставлений будет пополнена.
Описанный процесс хорошо иллюстрирует следующая диаграмма
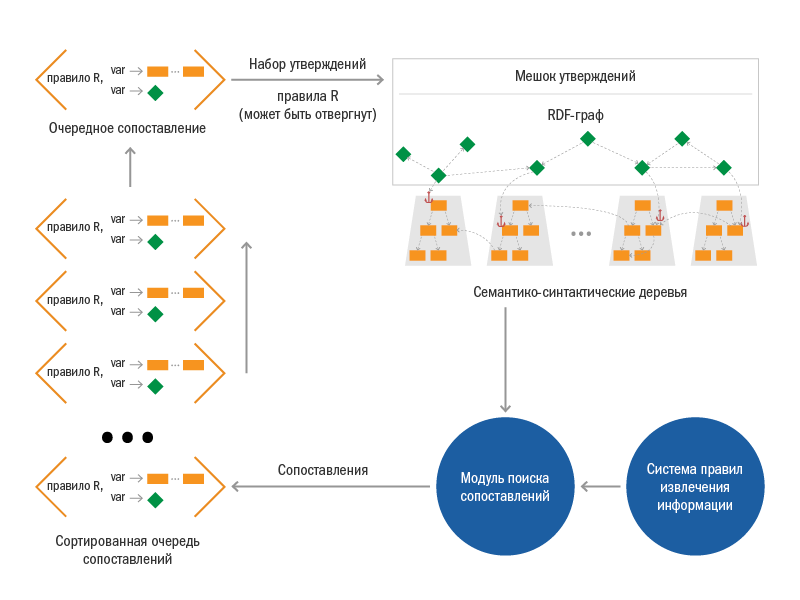
Для того чтобы реализовать все это, нам пришлось потрудиться. Одной из самых сложных компонент системы получился механизм поиска сопоставлений. В него встроен интерпретатор байт-кода скомпилированных правил, система специальных индексов над семантико-синтаксическими деревьями, модуль отслеживания изменений в мешке утверждений и некоторые другие механизмы. Отметим некоторые базовые особенности механизма поиска сопоставлений:
- Умеет находить все сопоставления для правил извлечения информации без объектных условий
- Постоянно следит за содержимым мешка утверждений и каждый раз при появлении в нем новых утверждений пытается генерировать новые сопоставления (уже с объектными условиями)
- На каждом шаге работы возможна генерация как сопоставления для новых правил извлечения информации и идентификации, так и сопоставления для правил, для которых до этого уже генерировались другие сопоставления.
Так происходит в тех случаях, когда некоторому объектному условию того или иного правила удовлетворяет более одного информационного объекта – каждый вариант рассматривается в рамках отдельного сопоставления.
В результате работы у нас получился алгоритм, который обладает следующими особенностями:
- Не рассматривает альтернативы. Если какое-то сопоставление вошло в противоречие с текущим состоянием мешка утверждений, оно просто отбрасывается.
Использование такого жадного принципа оказалось возможным в первую очередь за счет того, что языковая омонимия уже снята семантико-синтаксическим парсером – нам почти не приходится строить гипотезы о том, чем является тот или иной узел дерева.
- У онтоинженера есть возможность влиять на порядок срабатывания правил. На множестве правил введено отношение частичного порядка. Если оба срабатывания возможны и между ними задан порядок, то система гарантирует, что срабатывание одного из правил должно происходить раньше срабатывания другого. Для удобства поддержана так же возможность упорядочивать группы правил. Отношение частичного порядка транзитивно. При компиляции системы правил проверяется, что частичный порядок введен корректно, система умеет обнаруживать циклы. В то же время описанный подход существенно отличается от последовательного применения всех правил, т.к. частичный порядок, заданный на правилах, влияет лишь на выбор между очередными срабатываниями, но не блокирует повторное применение одних и тех же правил.
Если вам захочется изучить более формальное описание алгоритма – советуем обратиться к упомянутой статье с конференции Диалог.
Эта технология предоставляет широкий круг возможностей, позволяющих нам решать различные задачи, ориентированные на актуальные потребности рынка. О том, с какими реальными бизнес-задачами мы сталкиваемся, и как с ними справляется Compreno, мы скоро расскажем в своем блоге.
