Введение
За последние годы современные компании, в том числе отечественные, сделали большой шаг вперед в части модернизации IT-инфраструктур и расширения используемых программных средств и компонентов, СЗИ, а также корпоративных систем. Вместе с повышением качества внутренних сервисов, защищенности инфраструктуры и других улучшений, неизбежно увеличивается и объем данных, генерируемых новыми системами. Разумеется, для сопровождения, развития и, что самое главное, получения ожидаемых прикладных результатов от соответствующих систем, необходимо эти данные как-то обрабатывать.
В сфере информационной безопасности особняком стоят SIEM системы, отвечающие за сбор, обработку, хранение и анализ данных . В то же время на сегодняшний день сложно кого-то удивить настроенной и корректно функционирующей SIEM системой. А вот стоимостью на лицензирование SIEM, особенно учитывая ежегодный рост объемов данных и существенно подскочивший курс иностранных валют, удивить можно практически каждого. Кроме этого, современные объемы данных часто нагружают SIEM системы настолько сильно, что они становятся неспособными переваривать такой поток информации, от чего страдает основной функционал SIEM – возможность корреляции событий и выявление инцидентов ИБ. В таких условиях многие компании присматриваются или уже внедрили в свою инфраструктуру, так называемые, CLM (Central Log Management) решения. Или, проще говоря, Logger – приложения, отвечающие за долгосрочное хранение данных больших объемов и фильтрацию событий, попадающих в SIEM.
В этой статье постараемся рассказать, как на базе всем доступного open-source можно построить эффективный Logger, поддерживающий интеграцию со всеми SIEM системами, а также как возможно модернизировать уже существующий Logger с помощью алгоритмов машинного обучения, сделав его умнее и эффективнее.
Как мы собирали Logger: Logstash + Clickhouse + Grafana
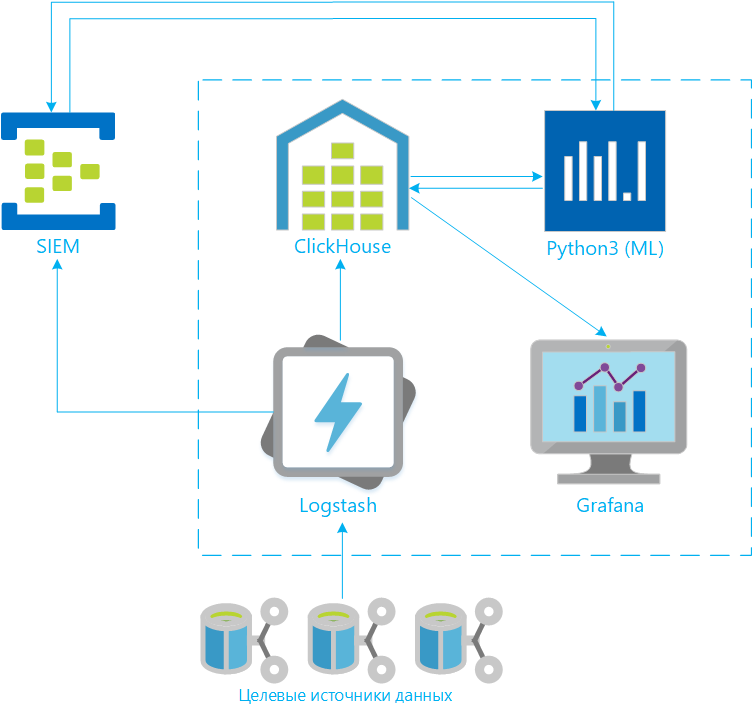
ETL (Logstash)
В качестве ETL-инструмента, отвечающего за сбор, обработку и загрузку данных в хранилище, используется компонент из стека ELK – Logstash. Кроме этого, в связке с Logstash используются и соответствующие агенты семейства Beats, наиболее часто используемые из которых Winlogbeat и Filebeat. Они используются для сбора аудит-лога с Windows машин и лог-файлов соответственно. Большое количество поддерживаемых источников из коробки, гибкие механизмы обработки данных, поддержка языка Ruby для написания парсеров и обработчиков любой сложности, отличная документация и большое комьюнити – все это повлияло на выбор именно этого решения.
Предлагаю опустить процесс развертывания Logstash в рамках данной статьи и сконцентрироваться на нюансах, связанных непосредственно с построением рассматриваемой Системы.
Первое, что нам необходимо сделать после развертывания Logstash – это установить плагин logstash-output-clickhouse, позволяющий вставлять обработанные данные в ClickHouse. Репозиторий на гитхабе на текущий момент в архиве, но сам плагин актуален и доступен по ссылке (https://github.com/funcmike/logstash-output-clickhouse). Установка плагина, при наличии интернета, происходит стандартно с помощью общедоступного репозитория:
bin/logstash-plugin install logstash-output-clickhouseПроверка успешности установки плагина проверяется с помощью следующей команды:
/usr/share/logstash/bin/logstash-plugin list --verbose 'logstash-output-clickhouse'Структура конфигурационных файлов Logstash
Логика ETL-процесса описывается в конфигурационных файлах .conf, который состоит из трех логических блоков.
input {...}
filter {...}
output {...}1. Input – отвечает за непосредственную интеграцию с целевым источником, определение методов и протоколов сбора, а также параметров подключения. Разделяют основные 3 типа интеграций с целевыми источниками:
Push – перенаправление данных инициируется со стороны источника (syslog, udp/tcp);
Pull – сбор данных инициируется со стороны Logstash (odbc/jdbc, rest api);
Agent – для сбора логов используется агент, устанавливаемый на удаленной рабочей станции и отвечающей за сбор, предобработку и отправку данных на Logstash.
2. Filter – отвечает за обработку и парсинг данных. Содержит множество предустановленных и готовых к использованию плагинов, например, csv, mutate, kv, grok и другие. Также позволяет писать обработчики любой сложности на языке Ruby. Отдельно стоит упомянуть плагин clone. Clone является обязательным плагином для построения Logger и отвечает за разделение потока на два независимы друг от друга. Один из потоков, который является основным, поступает в хранилище данных ClickHouse, а второй, на который накладываются необходимые фильтры, поступает в SIEM.
3. Output – отвечает за настройку параметров отправки событий в хранилища данных, либо форвардинга в сторонние системы.
Логика разделения пайплайнов для потоков данных с различных целевых источников описывается в конфигурационном файле pipelines.yml, который состоит из двух параметров, передающихся для каждого из целевых источников в соответствии с настроенными конфигурационными файлами .conf.
- pipeline.id: id_1
path.config: "/etc/logstash/conf.d/config_1.conf"
...
- pipeline.id: id_N
path.config: "/etc/logstash/conf.d/config_N.conf"pipeline.id– отвечает за определение уникального id пайплайна.path.config– отвечает за определение пути к конфигурационному файлу целевого источника для соответствующего id.
Используемые типы источников назначения (блок Output)
В собираемом нами Logger используются два типа источников назначения: clickhouse – хранилище данных Системы, в которое поступают все обработанные события и tcp и output, отвечающий за перенаправление отфильтрованных данных в SIEM.
Помимо этих двух типов, Logstash поддерживает и другие. Подробнее про типы output можно ознакомиться в официальной документации Logstash (https://www.elastic.co/guide/en/logstash/current/output-plugins.html).
ClickHouse
Для сохранения данных в ClickHouse отвечает плагин logstash-output-clickhouse. Плагин позволяет перенаправлять поток «clone_for_CH» в ClickHouse и осуществляет маппинг полей с источника той структуре данных, которая предусмотрена в хранилище.
Ниже представлен пример output, в котором реализуется загрузка данных в ClickHouse. Загрузка происходит пачками по 1000 событий.
Пример ClickHouse Output
if [type] == "clone_for_CH" {
clickhouse {
http_hosts => ["http://127.0.0.1:8123"]
user => "default"
password => "******"
table => "logger.DATA_asa_F"
mutations => {
"deviceReceiptTime" => "Timestamp"
"deviceVendor" => "vendor"
"deviceProduct" => "product"
"deviceVersion" => "version"
"deviceHostName" => "deviceHostName"
"deviceEventCategory" => "eventtype"
"eventId" => "message_id"
...
}
automatic_retries => 3
request_tolerance => 8
backoff_time => 5
flush_size => 1000
idle_flush_time => 5
}
}
SIEM
За форвардинг отфильтрованных данных на SIEM отвечает плагин tcp. Плагин позволяет перенаправлять поток «clone_for_SIEM» в SIEM в поддерживаемом формате.
Ниже представлен пример output, в котором реализуется форвардинг данных в SIEM Qradar.
Пример SIEM Qradar Output
tcp {
host => ["10.20.6.239"]
port => 514
mode => "client"
codec => "json_lines"
}host – отвечает за определение ip-адреса SIEM Qradar;
port – отвечает за определение порта SIEM Qradar;
mode – отвечает за определение типа соединения;
codec – отвечает за определение формата отправляемых данных.
Пример готового .conf файла Logstash
Ниже представлен пример .conf файла Logstash, отвечающий за сбор и обработку событий с источника, подключенного по UDP, который использует различные обработчики и плагины, после чего разделяет события на два потока – для Logger и SIEM Qradar. В Logger поступает весь массив данных, а в SIEM - события необходимые и достаточные для отработки логики правил корреляций.
Пример подключения и обработки источника данных
input {
udp {
port => 5080
}
}
filter {
csv {
separator => ";"
columns => ["datetime", "User", "src_ip", "account", "category", "field", "old_time", "action", "app", "event_id", "body", "bytes", "bytes_from_client",
"bytes_from_server", "bytes_in", "bytes_out", "bytes_to_client", "bytes_to_server", "cfids58", "clen", "connect_protocol", "date", "dest", "dest_port",
"dhost", "docid", "dvc", "error", "eventtype", "expire", "host", "http_content_type", "http_method", "http_user_agent", "http_user_agent_length", "index",
"lat", "linecount", "mt", "mtd", "proto", "rep", "response_time", "rule", "severity", "severity_id", "signature", "source", "sourcetype", "src", "srcip",
"status", "status_code", "status_description", "status_type", "subject", "tag"]
add_field => {
'isForwarding' => '1'
'version' => '7.6'
'receiverType' => 'Syslog'
}
clone {
clones => ["clone_for_CH", "clone_for_QRADAR"]
}
if [severity] == 1 or [severity] == 2 {
mutate {
replace => {'severity' => 'Low'}
}
}
if [severity] == 3 or [severity] == 4 {
mutate {
replace => {'severity' => 'Medium'}
}
}
if [severity] == 5 {
mutate {
replace => {'severity' => 'Critical'}
}
}
#Фильтр для CH
if [type] == "clone_for_CH" {
if [event_id] == 105 {
mutate {
replace => {
'isForwarding' => '0'
}
}
}
}
#Фильтр для QRADAR
if [type] == "clone_for_QRADAR" {
if [event_id] == 105 {
drop {}
}
}
if [type] == "clone_for_QRADAR" {
prune {
whitelist_names => ["Timestamp", "vendor", "product", "version", "category", "field", "severity", "dvc", "host",
"datetime_event", "src_ip", "User", "user", "dest_port", "dhost", "rule", "status_description",
"body", "http_user_agent", "http_method", "http_content_type", "connect_protocol", "event_id", "bytes", "bytes_from_client", "bytes_to_client", "status_code",
"action", "eventtype", "http_user_agent_length", "bytes_from_server", "bytes_to_server", "status_type"]
}
mutate {
add_field => { "[@metadata][type]" => "only_QRADAR" }
}
}
}
output {
if [type] == "clone_for_CH" {
clickhouse {
http_hosts => ["http://127.0.0.1:8123"] user => "<user>" password => "<password>"
table => "<table name>"
mutations => {
"deviceReceiptTime" => "Timestamp"
"deviceVendor" => "vendor"
"deviceProduct" => "product"
"deviceVersion" => "version"
"deviceEventCategory" => "category"
"eventId" => "event_id"
...
}
automatic_retries => 3
request_tolerance => 8
backoff_time => 5
flush_size => 1000
idle_flush_time => 5
}
}
if [@metadata][type] == "only_QRADAR" {
tcp {
host => ["<ip server>"]
port => 514
mode => "client"
codec => "json_lines"
}
}
}
Хранилище данных (ClickHouse)
В качестве инструмента для долгосрочного хранения данных используется колоночная СУБД ClickHouse. На этом этапе у многих может возникнуть вопрос: почему не нативный ElasticSearch из ELK стека? Ведь он, казалось бы, как нельзя лучше подходит для Logstash. Причин, на самом деле, достаточно много, при этом в некоторых случаях действительно ElasticSearch будет более предпочтительным выбором. Но рассмотрение +/- и особенностей архитектур этих решений выходит за рамки этой статьи. Отметим лишь, что на выбор ClickHouse повлияла простота установки и эксплуатации, гибкие возможности масштабирования, крайне приятные показатели в части производительности, низких затрат на эксплуатацию, отличных показателей в части дедупликации данных (для однотипных логов показатели компрессии данных могут доходить до 100), а также, потенциальные возможности использования этого хранилища для задач аналитики и IT-мониторинга.
Структура хранения данных в ClickHouse
Данные в ClickHouse хранятся в соответствии с жестко заданной структурой данных, в которой фиксированное количество полей и типов данных, хранящихся в них. На этапе определения структуры хранения нужно быть предельно внимательным, ведь вольности того же ElasticSearch здесь недопустимы и при малейших несоответствиях названий, структуры и типов полей в конфигурационном файле Logstash структуре данных в ClickHouse вы увидите ошибки и исключения.
Определение структуры хранения данных в ClickHouse необходимо произвести предварительно до заполнения блока Output в Logstash. Хоть и выбор структуры хранения данных произвольный, рекомендуем сразу же его унифицировать, то есть сделать единым для любого источника данных. Это упростит подключение новых источников, откроет дополнительные возможности для аналитики и смежных интеграций. В частности, можно, например, использовать CEF-подобный формат хранения. Ниже пример запроса на создание таблицы для соответствующего источника.
Пример создания таблицы под источник данных
CREATE TABLE seo.DATA_<source_name>
(
`deviceReceiptTime` DateTime,
`deviceVendor` Nullable(String),
`deviceProduct` Nullable(String),
`deviceVersion` Nullable(String),
`deviceEventCategory` Nullable(String),
`eventId` Nullable(UInt32),
...
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(deviceReceiptTime)
ORDER BY deviceReceiptTime
SETTINGS index_granularity = 8192В таком примере, для любого нового источника, создание таблицы будет идентично, за исключением изменения названия таблицы в соответствии с источником данных.
Визуализация и мониторинг (Grafana)
В качестве инструмента, отвечающего за визуализацию и мониторинг ключевых метрик по собираемым данным, отвечает Grafana. Гибких возможностей по построению дашбордов и визуализации, а также поддержки ClickHouse в качестве источника данных из коробки хватило для выбора этого решения.
Для возможности работы Grafana с ClickHouse необходимо установить соответствующий плагин vertamedia-clickhouse-datasource. Установка плагина, при наличии интернета, происходит с помощью общедоступного репозитория:
grafana-cli plugins install vertamedia-clickhouse-datasourceПроверка успешности установки плагина проверяется с помощью следующей команды:
grafana-cli plugins ls | grep vertamedia-clickhouse-datasourceПосле установки плагина в блоке Data Sources появится возможность настройки подключения к ClickHouse.
Примеры возможных панелей мониторинга
Логика построения визуализаций в Grafana подразумевает отдельный запрос к ClickHouse под каждой визуализацией. Возможности формирования некой витрины данных, как, например, в BI, на основе которой в дальнейшем формируются визуализации, в Grafana нет. На данном этапе сформируем рекомендации по тому, какие из БД и таблиц будут полезны и информативны в качестве источников для визуализаций, расположенных на панелях мониторинга.
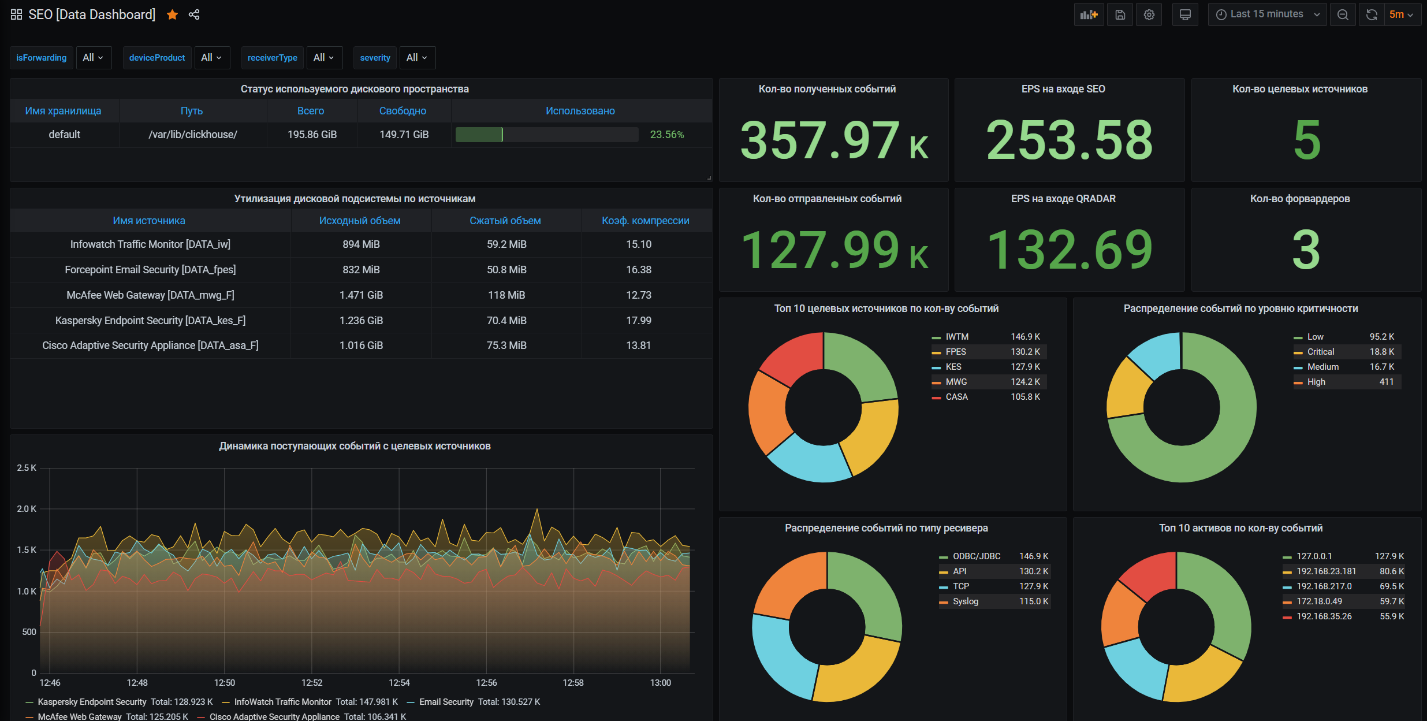
Data Dashboard
Для основной панели мониторинга, на которой представлена общая динамика по собираемым в Logger и отправляемым на SIEM событиям, в первую очередь, стоит обратить внимание на те таблицы, в которых хранятся собираемые данные. Данные из этих таблиц позволят отслеживать общую динамику обрабатываемых событий.
Что касается информации об утилизации дисковой подсистемы, подсчета коэффициентов компрессии данных по каждому из источников, состояния сервера и иной системной информации, то здесь необходимо упомянуть БД ClickHouse system, в которой хранится множество внутренней информации по хранилищу данных. Для основной панели мониторинга важнейшими являются таблицы parts и disks.
Говоря об информации о EPS на входе и выходе Logger, следует отметить, что здесь может быть несколько решений: отслеживать трафик на Logstash, подсчитывать уже по факту проиндексированные данные в Logger и SIEM. Тем не менее для хранения этой информации, в любом случае, будут нужны некие внутренние таблицы, создаваемые самостоятельно. В нашем случае, это таблицы с префиксом EPS_. EPS мы считаем на основе уже проиндексированных данных. В ClickHouse подсчет EPS осуществляется элементарно, для сбора информации о EPS на SIEM мы подключаемся по API к соответствующему SIEM и собираем нужную информацию.
Разумеется, для каждого, основная панель мониторинга будет своя. В качестве примера, ниже иллюстрация того, как может выглядеть такой дашборд.
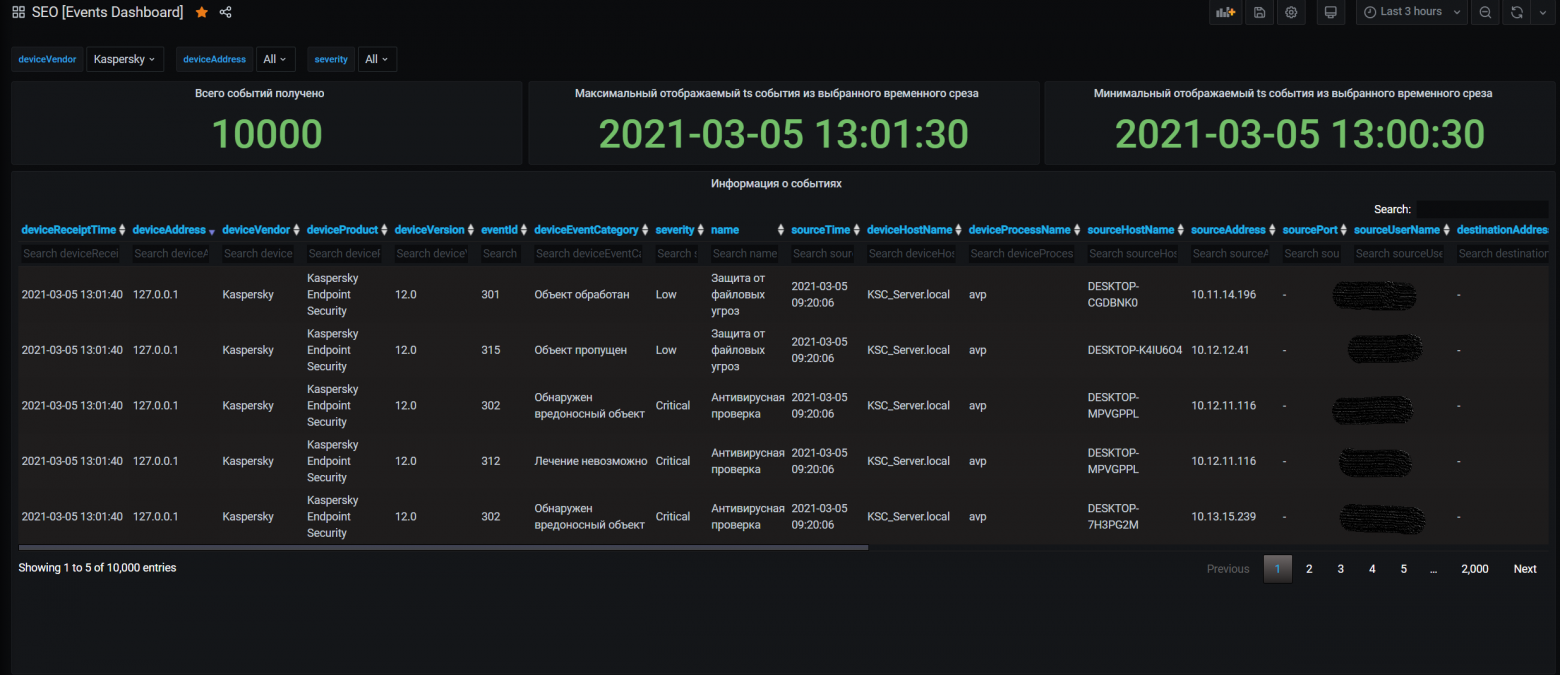
Events Dashboard
Для панели мониторинга, на которой представлена общая витрина собранных и проиндексированных событий, достаточно соответствующих таблиц с данными. Дашборд отвечает за возможность ретроспективного поиска событий по всем источникам и поиска как по отдельно взятому столбцу, так и по всей витрине в целом.
Иные дашборды
Выше представлены, пожалуй, обязательные дашборды для любого Logger. Помимо этого, могут быть и другие дашборды – по каждому из источников, по утилизации аппаратных ресурсов сервера, по динамике и эффективности запросов в хранилище данных. Для таких дашбордов могут потребоваться дополнительные инструменты – кастомные внутренние таблицы, в том числе, использующие различные движки (например, GraphiteMergeTree). Ниже парочка примеров.


Предварительные результаты
По итогам собранного стека мы уже сейчас покрываем весь функционал CLM решений, при этом, наш Logger является мультивендорным решением и поддерживает, по сути, любой SIEM. В частности, в нашей компании есть разработанные двусторонние интеграции с Qradar, ArcSight и MaxPatrol.
Но что если мы хотим от построенной системы большего? В частности, некой рекомендательной системы по формированию оптимальных фильтров для SIEM или способность детектировать аномалии во входящем потоке данных в Logger. Давайте разбираться дальше.
Делаем фильтры Logger умнее
Как обычно настраиваются фильтры при внедрении CLM решений в инфраструктуру с уже работающим SIEM? Инженеры из отдела мониторинга, основываясь на своем опыте работы, выкатывают требования по тем источникам, которые в SIEM должны быть обязательно. По особо тяжелым источникам вроде Cisco ASA, просят настроить фильтры по типам событий низкой критичности, что-то наподобие DEBUG и INFO и исключить не особо интересные подсети, а ряд источников не отправлять в SIEM вовсе – то, что необходимо хранить только для покрытия требований регуляторов и оставлять только в Logger. Вот, собственно, и весь процесс настройки фильтров CLM решений.
Но что если мы хотим фильтры максимально объективные и оптимальные, позволяющие снизить поток входящих данных в SIEM по максимуму, при этом не потеряв ни одного события, используемого в логике того или иного правила корреляции?
В продукте, разработанным нашей компанией, данная задача решается с помощью, так называемого, компонента анализа корреляционных правил – функционального компонента, написанного на Python3 и отвечающего за двустороннюю интеграцию с SIEM решениями. Дабы не нарушить права на интеллектуальную собственность, сам код останется за рамками данной статьи, при этом, ниже я вкратце постараюсь описать сам подход, позволяющий осуществлять более умную фильтрацию, отслеживать неактуальные правила корреляции и избыточные события.
Основная идея подхода заключается в вытягивании информации о логике правил корреляции и ее дальнейшем анализе. При наличии информации о логике, используемой в правиле корреляции и маппинге полей событий в SIEM и Logger, можно автоматизировано формировать фильтры, необходимые и достаточные для сработки соответствующих правил. Обработав таким образом все правила на SIEM, можно сформировать наиболее оптимальные фильтры в автоматизированном режиме, после чего применить их на Logstash для SIEM потока и оптимизировать таким образом входящий трафик. Помимо этого, мы отслеживаем информацию по каждому из типу событий, которые поступают в SIEM, в частности, это количество событий в час и EPS в разрезе определенного типа события, то в каких правилах соответствующий тип события используется. Также отслеживается информация о дате создания и модификации правил корреляции, количестве событий, поступающих в рамках логики правила и его статус. В заключении реализован функционал управления правилами корреляции из Logger. Так, например, можно выключить неактуальное правило после того, как были сформированы и применены соответствующие фильтры.
Выявляем аномалии во входящем потоке данных
Нередки случаи, когда интенсивность и объем потока данных возрастают или, напротив, падают. Иногда это случается в рамках неких технических работ и является нормой, а иногда свидетельствует о неработоспособности источника данных или же включенных избыточных политик аудита. Но как отличить приемлемые изменения в динамике потока событий от аномальных всплесков или провалов? Многие инженеры SIEM настраивают соответствующие сигнатурные правила, отслеживающие объем данных, поступающих с соответствующего источника. Однако, в условиях динамично меняющейся инфраструктуры, такие правила достаточно быстро становятся неактуальным и требуют регулярной поддержки.
На помощь здесь приходит машинное обучение и статистический анализ, позволяющие строить baseline активности не только в разрезе самих источников, но и в разрезе более мелких сущностей, таких как ip-адрес, подсеть, актив, пользователь и т.д. Такой подход позволяет отслеживать неочевидные отклонения в части работоспособности или же выявлять избыточные политики аудита у одного из десяти серверов в рамках одного источника, например, Kaspersky Endpoint Security.
Ниже рассмотрим один из алгоритмов по анализу временных рядов применяемых в CLM решении, разработанный нашей компанией.
При наличии непрерывного потока данных, где отсутствует счетчик событий, создадим материализованное представление в ClickHouse, которое будет обновляться автоматически с поступлением новых событий и автоматически их агрегировать в выбранный нами пятиминутный диапазон.
Создаем MATERIALIZED VIEW
CREATE MATERIALIZED VIEW CURRENT_events
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(ts)
ORDER BY ts
AS
SELECT
toStartOfFiveMinute(ts) AS ts,
count() AS numbers
FROM events
GROUP BY tsДальнейший анализ данных и приведенный ниже код будет представлен на Python3. Прежде всего взглянем на основные статистики ряда.

Построим на основе имеющейся статистики график динамики поступающих событий.
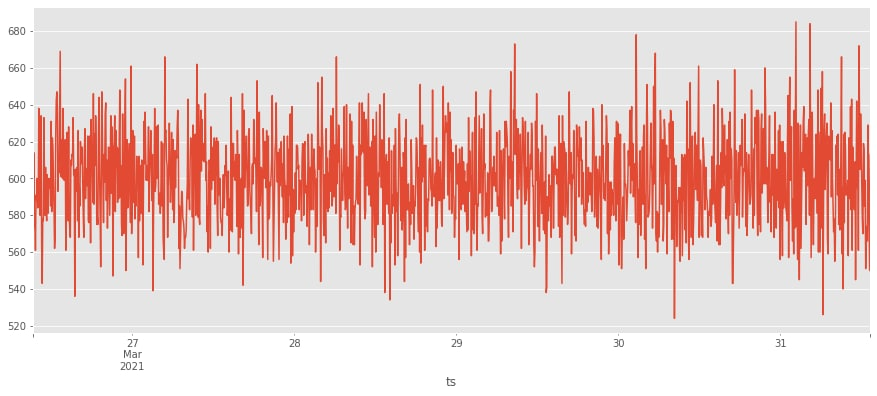
На текущем этапе стоит четко сформулировать цель проводимого анализа. В нашем случае мы не ставим целью предсказание будущего объема поступающих данных. Наша цель – отслеживать текущий поток здесь и сейчас, при этом иметь простую и быструю возможность переобучения ранее построенного baseline. Поэтому одним из наиболее простых и в то же время эффективных решений (конкретно в этом кейсе) является применение обычного статистического анализа.
Построим гистограмму распределения данных.

В представленном примере мы видим, что данные очень похожи на нормальное распределение. Проверим наше предположение с помощью критерия Шапиро-Уилка.
from scipy.stats import shapiro
def test_shapiro(data):
stat, p = shapiro(data)
print('Статистика=%.3f, p=%.3f' % (stat, p))
alpha = 0.05
if p > alpha:
print('Принять H0 гипотезу. Распределение нормальное.')
else:
print('Отклонить H0 гипотезу')
test_shapiro(data['events'])
--------------
Статистика=0.998, p=0.052
Принять H0 гипотезу. Распределение нормальное.Так как наше распределение выглядит нормальным, то можно воспользоваться правилом 3-х сигм для отслеживания динамики потока событий и поиска выбросов.

Посчитаем верхнюю и нижнюю границу при условии 3-х сигм и обновим ранее представленный график с динамикой событий.
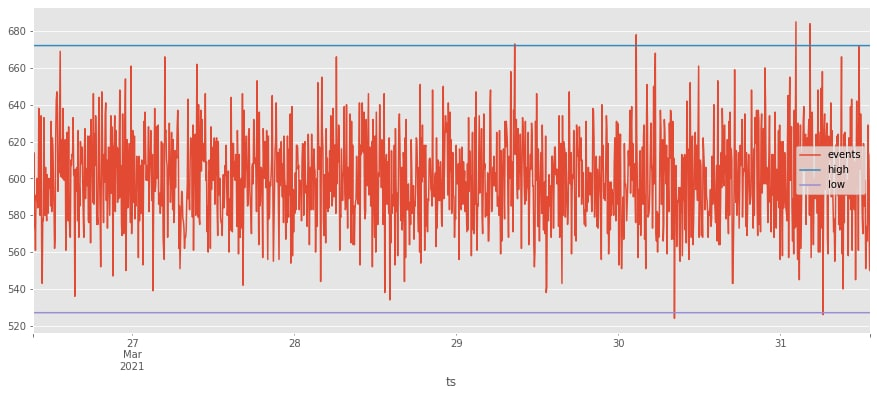
Далее выявляем аномалии и фиксируем их на графике.
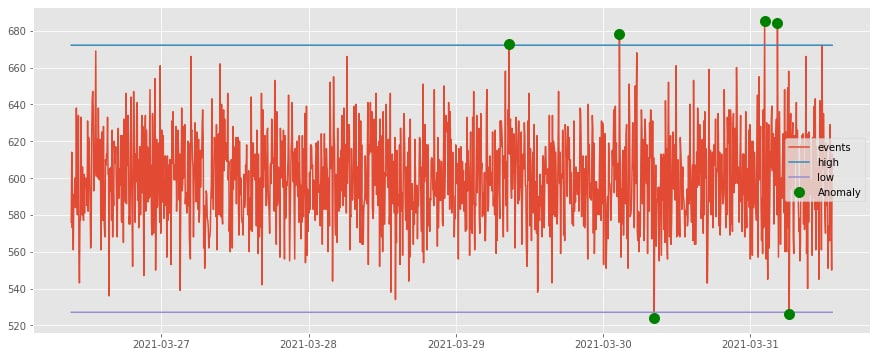
Исходная задача решена в том объеме, в котором была нам необходима. Далее, соответствующая логика интегрируется непосредственно в ClickHouse, внутри которого настраивается расчет аномалий и уведомлений об их фиксации ответственным лицам.
Однако, такой подход может показаться несколько ограниченным, поэтому мы решили пойти немного дальше и строить верхнюю и нижнюю границу для каждого временного диапазона (5 минут). Для этого посмотрим на распределение значений в каждую минуту времени и повторим тест Шапиро-Уилка.
grouped = data.groupby('minute')['events']
ncols=2
nrows = grouped.ngroups // ncols
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(16,12), sharey=True)
for (key, ax) in zip(grouped.groups.keys(), axes.flatten()):
grouped.get_group(key).hist(ax=ax)
print('Минута', key)
test_shapiro(grouped.get_group(key))
print('-'*50)
ax.set_xticks([])
ax.set_title(key)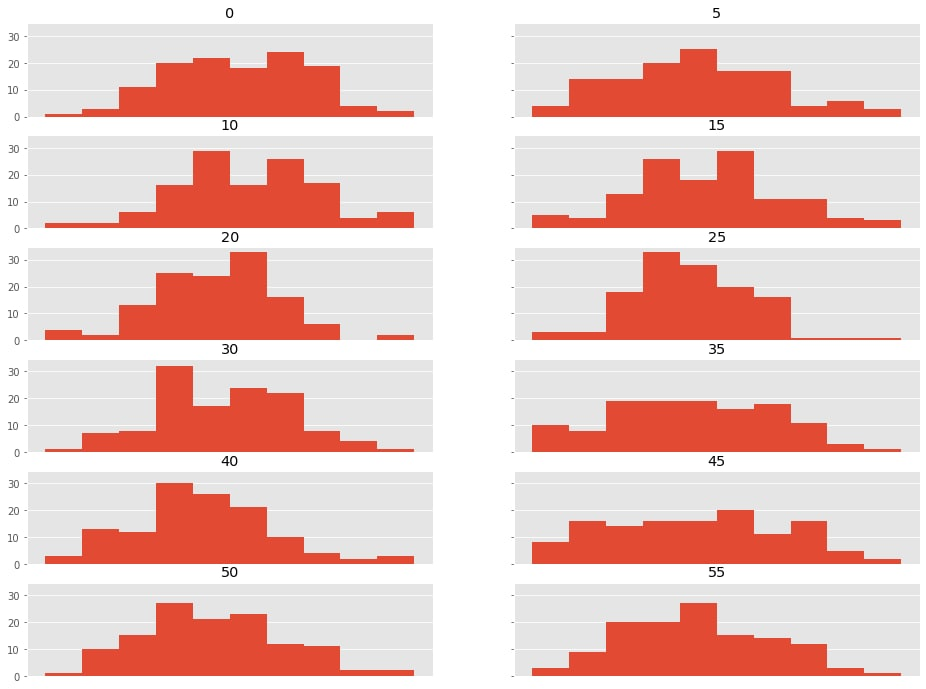
Повторяем тест Шапиро-Уилка
Минута 0
Статистика=0.992, p=0.690
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 5
Статистика=0.986, p=0.250
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 10
Статистика=0.992, p=0.712
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 15
Статистика=0.993, p=0.780
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 20
Статистика=0.988, p=0.380
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 25
Статистика=0.987, p=0.277
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 30
Статистика=0.991, p=0.592
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 35
Статистика=0.985, p=0.208
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 40
Статистика=0.982, p=0.092
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 45
Статистика=0.977, p=0.031
Отклонить H0 гипотезу
--------------------------------------------------
Минута 50
Статистика=0.985, p=0.174
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------
Минута 55
Статистика=0.991, p=0.573
Принять H0 гипотезу. Распределение нормальное.
--------------------------------------------------Из полученных результатов можно сделать вывод, что в каждую минуту времени распределение значений является нормальным. Исключение составляет только 45 минута. Так как в конкретном примере у нас событий не так много, а значение p не такое маленькое, то мы опустим разбор конкретного примера. Построим верхнюю и нижнюю границу для каждого временного отрезка и зафиксируем выявленные аномалии.
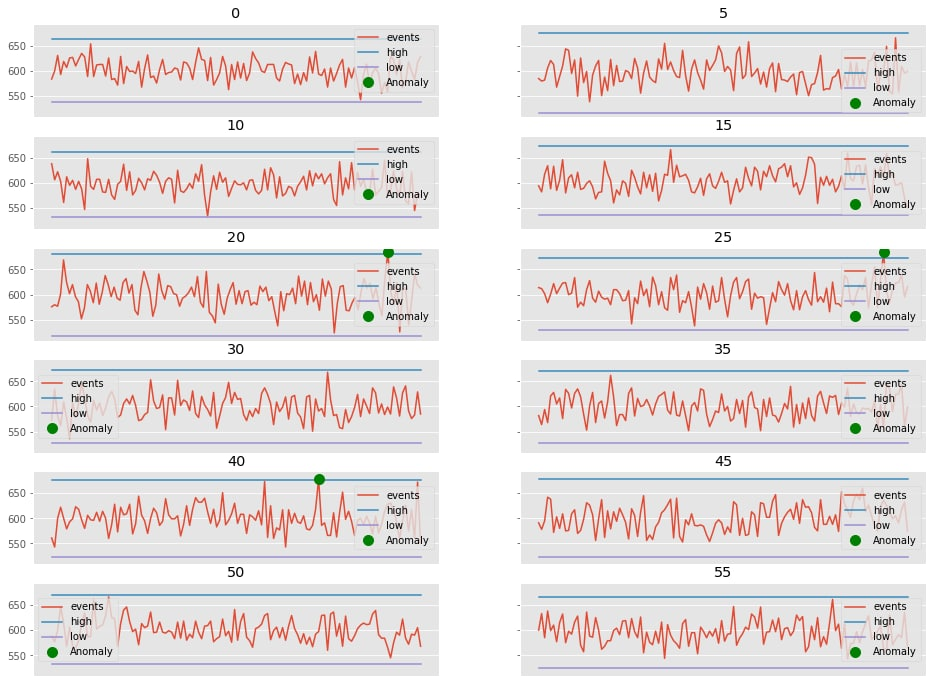
Далее соберем это вместе и отобразим на итоговом графике.
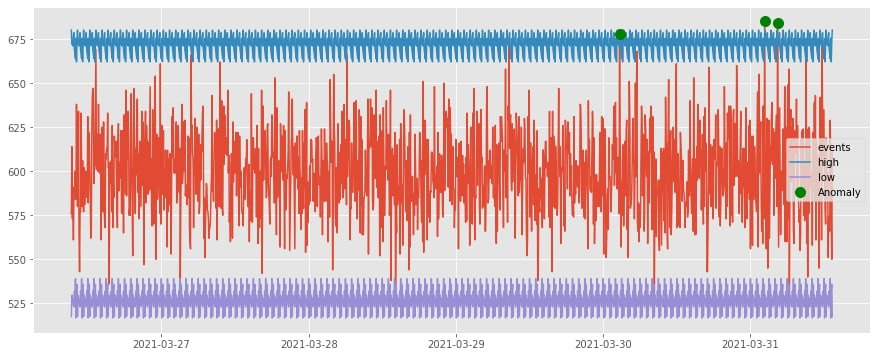
Таким образом, мы построили верхнюю и нижнюю границу для каждого временного диапазона. Как можно заметить, зафиксированных аномалий стало меньше в силу более детальной аналитики. Однако стоит понимать, что любая инфраструктура индивидуальна и подбор оптимальных временных диапазонов и верхних/нижних границ является основополагающей задачей, определяющей точность и достоверность анализа.
Небольшие промежуточные выводы и заметки:
В данном случае можно использовать медиану, так как она менее чувствительна к выбросам, чем среднее значение;
Можно воспользоваться моделями машинного обучения для прогнозирования следующего значения, например линейная регрессия и catboost. Данные модели можно легко внедрить непосредственно в ClickHouse;
Можно экспериментировать с другими временными промежутками и строить в разрезе их поиск аномалий и выбросов;
Выбирать алгоритм стоит, исходя из поставленной цели и задач. Далеко не всегда монструозные модели на проде дают лучшие результаты, иногда достаточно простой статистики, либо взятых с потолка значений (шутка).
P. S. За подготовку данного раздела выражаю огромную благодарность своему коллеге по цеху - Роману Титову (@titovr).
Результаты
Подводя итоги, пару слов об итоговой системе и тому, какие задачи получилось решить. В результате построенный Logger:
Решает необходимый пул задач, возлагаемый на коммерческие CLM решения;
Является мультивендорным решением, работающим с любым SIEM, а, значит, при сценарии, когда условный Splunk уйдет с рынка, вы безболезненно сможете переключиться на новый SIEM;
Автоматизированно формирует фильтры, полагаясь не только на экспертизу инженеров из отдела мониторинга, но и при этом учитывает логику используемых правил корреляции. В дополнение определяет необходимые и достаточные типы событий, необходимые к форвардингу в SIEM;
Выявляет аномалии во входном потоке данных, основываясь на baseline не только самих источников, но и различных более мелких сущностей - активов, пользователей, подсетей.
Говоря о результатах внедрения подобной системы для бизнеса:
Оптимизирован объем входного потока событий в SIEM систему;
Реализовано долгосрочное хранение ретроспективных данных в сжатом формате;
Снижены финансовые затраты на лицензирование SIEM-системы;
Повышена эффективность и скорость работы SIEM-системы;
Снижены эксплуатационные затраты на SIEM систему и минимизированы ошибки аналитиков на ручную обработку данных.
