
Привет, Хабр!
Не секрет, что в работе современных приложений задействованы огромные объемы данных, и их поток постоянно растет. Эти данные нужно хранить и обрабатывать, зачастую с большого числа машин, и это непростая задача. Для ее решения существуют облачные объектные хранилища. Обычно они представляют из себя реализацию технологии Software Defined Storage.
В начале 2018 года мы запускали (и запустили!) собственное 100% S3-совместимое хранилище на основе Cloudian HyperStore. Как оказалось, в сети очень мало русскоязычных публикаций о самом Cloudian, и еще меньше — о реальном применении этого решения.
Сегодня я, основываясь на опыте DataLine, расскажу вам об архитектуре и внутреннем устройстве ПО Cloudian, в том числе, и о реализации SDS от Cloudian, базирующейся на ряде архитектурных решений Apache Cassandra. Отдельно рассмотрим самое интересное в любом SDS хранилище — логику обеспечения отказоустойчивости и распределения объектов.
Если вы строите свое S3 хранилище или заняты в его обслуживании, эта статья придется вам очень кстати.
В первую очередь, я объясню, почему наш выбор пал на Cloudian. Всё просто: достойных вариантов в этой нише крайне мало. Например, пару лет назад, когда мы только задумывали строительство, опций было всего три:
- CEHP + RADOS Gateway;
- Minio;
- Cloudian HyperStore.
Для нас, как для сервис-провайдера, решающее значение имели: высокий уровень соответствия API хранилища и оригинального Amazon S3, наличие встроенного биллинга, масштабируемость с поддержкой мультирегиональности и наличие 3-ей линии вендорской поддержки. Всё это есть у Cloudian.
И да, самое (безусловно!) главное — у DataLine и Cloudian похожие корпоративные цвета. Согласитесь, перед такой красотой мы не могли устоять.

К сожалению, Cloudian — не самое распространенное ПО, и в рунете информации о нём практически нет. Сегодня мы исправим эту несправедливость и поговорим с вами об особенностях архитектуры HyperStore, изучим его наиболее важные компоненты и разберемся с основными архитектурными нюансами. Начнем с самого основного, а именно — что же находится у Cloudian под капотом?
Как устроено хранилище Cloudian HyperStore
Давайте взглянем на схему и посмотрим, как устроено решение от Cloudian.

Основная компонентная схема хранилища.
Как мы видим, система состоит из нескольких основных компонентов:
- Cloudian Management Control — консоль управления;
- Admin Service — внутренний модуль администрирования;
- S3 Service — модуль, отвечающий за поддержку протокола S3;
- HyperStore Service — собственно сервис хранения;
- Apache Cassandra — централизованное хранилище служебных данных;
- Redis — для наиболее часто читаемых данных.
Наибольший интерес для нас будет представлять работа основных сервисов, S3 Service и HyperStore Service, далее мы внимательно рассмотрим их работу. Но сначала имеет смысл узнать, как устроено распределение сервисов в кластере и какова отказоустойчивость и надежность хранения данных этого решения в целом.

Под common services в схеме выше имеются в виду сервисы S3, HyperStore, CMC и Apache Cassandra. На первый взгляд, все красиво и аккуратно. Но при более детальном рассмотрении выясняется, что эффективно отрабатывается только одиночный отказ ноды. А одновременная потеря сразу двух нод может стать фатальной для доступности кластера — у Redis QoS (на node 2) есть только 1 slave (на node 3). Такая же картина с риском потери управления кластером — Puppet Server есть только на двух нодах (1 и 2). Впрочем, вероятность отказа сразу двух узлов очень невысока, и с этим вполне можно жить.
Тем не менее, для повышения надежности хранилища мы в DataLine используем 4 ноды вместо минимальных трёх. Получается следующее распределение ресурсов:
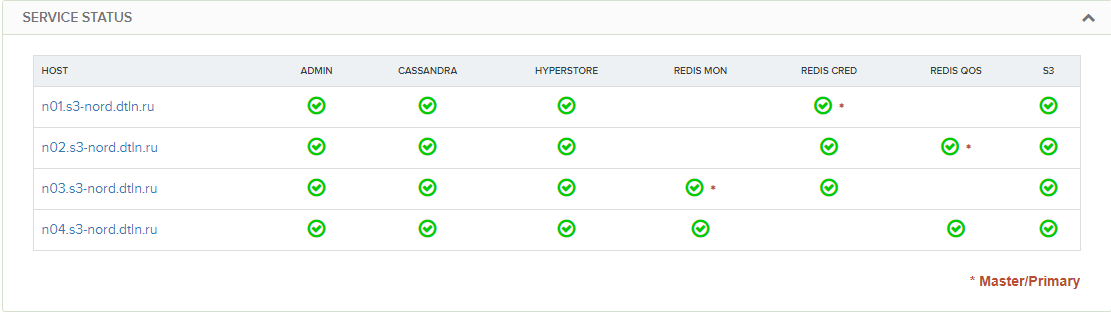
Сразу бросается в глаза еще один нюанс — Redis Credentials ставится не на каждую ноду (как можно было предположить из официальной схемы выше), а только на 3 из них. При этом Redis Credentials используется при каждом входящем запросе. Получается, из-за необходимости ходить в чужой Redis есть некоторый перекос в производительности четвертой ноды.
Для нас это пока несущественно. При нагрузочном тестировании значительных отклонений в скорости отклика ноды замечено не было, но на больших кластерах в десятки рабочих нод есть смысл поправить этот нюанс.
Вот так выглядит схема миграции на 6 нодах:

Из схемы видно, как реализована миграция сервиса при отказе ноды. Учитывается только случай отказа одного сервера каждой роли. Если упадут оба сервера, потребуется ручное вмешательство.
Здесь дело тоже не обошлось без некоторых тонкостей. Для миграции ролей используется Puppet. Поэтому, если вы потеряете его или случайно сломаете, automatic failover может не сработать. По этой же причине не стоит вручную править манифесты встроенного Puppet. Это не совсем безопасно, изменения могут быть внезапно перетерты, так как манифесты редактируются с помощью админки кластера.
С точки зрения сохранности данных всё значительно интереснее. Метаданные объектов хранятся в Apache Cassandra, и каждая запись реплицирована на 3 ноды из 4-х. Для хранения данных также используется фактор репликации 3, но можно настроить и больший. Это гарантирует сохранность данных даже при одномоментном отказе 2-х нод из 4-х. А при наличии времени на перебалансировку кластера можно и с одной оставшейся нодой ничего не потерять. Главное, чтобы хватило места.

Вот что происходит при отказе двух нод. На схеме хорошо видно, что даже в этой ситуации данные остаются сохранными
При этом доступность данных и хранилища будет зависеть от стратегии обеспечения консистентности. Для данных, метаданных, чтения и записи она настраивается отдельно.
Допустимые варианты — хотя бы одна нода, кворум или все ноды.
Эта настройка определяет, сколько нод должны подтвердить запись/чтение, чтобы запрос считался успешным. Мы используем кворум как разумный компромисс между временем на обработку запроса и надежностью записи/противоречивостью чтения. То есть из трех нод, задействованных в операции, для безошибочной работы достаточно получить непротиворечивый ответ от 2-х. Соответственно, чтобы остаться на плаву при отказе более чем одной ноды, понадобится перейти в стратегию единичной записи/чтения.
Отработка запросов в Cloudian
Ниже мы рассмотрим две схемы отработки входящих запросов в Cloudian HyperStore, PUT и GET. Это основная задача для S3 Service и HyperStore.
Начнем с того, как обрабатывается запрос на запись:

Наверняка вы отметили, что каждый запрос генерирует очень много проверок и извлечений данных, минимум 6 обращений от компонента к компоненту. Именно отсюда появляются задержки записи и высокий расход времени CPU при работе с маленькими файлами.
Крупные файлы передаются чанками. Отдельные чанки не рассматриваются как отдельные запросы и часть проверок не проводится.
Нода, получившая исходный запрос, дальше самостоятельно определяет, куда и что писать, даже если непосредственно на нее запись не производится. Это позволяет скрыть от конечного клиента внутреннюю организацию кластера и использовать внешние балансировщики нагрузки. Всё это положительно сказывается на удобстве обслуживания и отказоустойчивости хранилища.

Как видите, логика чтения не слишком отличается от записи. В ней наблюдается такая же высокая чувствительность производительности к размеру обрабатываемых объектов. Следовательно, из-за существенной экономии на работе с метаданными извлекать один мелко нарезанный объект значительно проще, чем множество отдельных объектов того же общего объема.
Хранение и дублирование данных
Как видно из приведенных выше схем, Cloudian поддерживает различные схемы хранения и дублирования данных:
Репликация — с помощью репликации возможно поддерживать в системе настраиваемое количество копий каждого объекта данных и хранить каждую копию на разных узлах. Например, с помощью 3X репликации создается 3 копии каждого объекта, и каждая копия «лежит» на своей ноде.
Erasure Coding — с помощью erasure coding каждый объект кодируется в настраиваемое количество (известное как число K) фрагментов данных плюс настраиваемое количество кода избыточности (число M). Каждые K + M фрагменты объекта уникальны, и каждый фрагмент хранится на своем узле. Декодирован объект может быть с помощью любых K фрагментов. Другими словами, объект остается читаемым, даже если M узлов недоступны.
Например, в erasure coding по формуле 4+2 (4 фрагмента данных плюс 2 фрагмента кода избыточности) каждый объект расщепляется на 6 уникальных фрагментов, хранящихся на шести различных узлах, и этот объект может быть восстановлен и прочтен, если любые 4 из 6 фрагментов доступны.
Плюс Erasure Coding по сравнению с репликацией состоит в экономии места, пусть и ценой значительного роста нагрузки на процессор, ухудшения скорости отклика и необходимости работы фоновых процедур по контролю консистентности объектов. В любом случае, метаданные хранятся отдельно от данных (в Apache Cassandra), что повышает гибкость и надежность работы решения.
Кратко о прочих функциях HyperStore
Как я уже писал в начале статьи, в HyperStore встроено несколько полезных инструментов. Среди них:
- Гибкий биллинг с поддержкой изменения цены ресурса в зависимости от объема и тарифного плана;
- Встроенный мониторинг;
- Возможность лимитировать использование ресурсов для пользователей и групп пользователей;
- Настройки QoS и встроенные процедуры балансировки использования ресурсов между нодами, а также штатные процедуры по перебалансировке между нодами и дисками на нодах или при вводе новых нод в кластере.
Тем не менее, Cloudian HyperStore всё равно не идеален. Например, почему-то нельзя переносить существующую учетную запись в другую группу или назначить несколько групп одной записи. Невозможно сформировать промежуточные отчеты биллинга — все отчеты вы получите только после закрытия отчетного периода. Поэтому узнать, насколько вырос счет, в реальном времени не смогут ни клиенты, ни мы.
Логика работы Cloudian HyperStore
Теперь мы погрузимся еще глубже и посмотрим на самое интересное в любом SDS хранилище — логику распределения объектов по нодам. В случае с хранилищем Cloudian, метаданные хранятся отдельно от самих данных. Для метаданных используется Cassandra, для данных — проприетарное решение HyperStore.
К сожалению, пока что в интернете отсутствует официальный перевод документации Cloudian на русский язык, поэтому ниже я помещу свой перевод наиболее интересных частей этой документации.
Роль Apache Cassandra в HyperStore
В HyperStore Cassandra используется для хранения метаданных объекта, данных учетной записи пользователя и данных об использовании сервиса. При типичном развертывании на каждом узле HyperStore данные Cassandra хранятся на том же диске, что и ОС. Система также поддерживает данные Cassandra на выделенном диске на каждом узле. Данные Cassandra не хранятся на дисках данных HyperStore. Когда vNodes назначаются хост-машине, они распределяются только по узлам хранения данных HyperStore. vNodes не выделяются на диск, где хранятся данные Cassandra.
Внутри кластера метаданные в Cassandra реплицируются в соответствии с политикой (стратегией) вашего хранилища. Репликация данных Cassandra использует vNodes таким образом:
- При создании нового объекта Cassandra (первичный ключ и его соответствующие значения) он хешируется, а хэш используется для того, чтобы связать объект с определенным vNode. Система проверяет, какому хосту назначен этот vNode, а затем первая реплика объекта Cassandra хранится на диске Cassandra на этом хосте.
- Например, представим, что хост-машине назначено 96 vNodes, распределенных по нескольким дискам данных HyperStore. Объекты Cassandra, чьи значения хэша попадают в диапазоны токенов любого из этих 96 vNodes, будут записаны на диск Cassandra на этом хосте.
- Дополнительные реплики объекта Cassandra (количество реплик зависит от вашей конфигурации) связываются с vNodes со следующим порядковым номером и сохраняются на том узле, которому назначены эти vNodes, при условии, что при необходимости vNodes будут «пропущены», чтобы каждая реплика объекта Cassandra хранилась на другой хост-машине.
Как работает хранилище HyperStore
Размещение и репликация объектов S3 в кластере HyperStore основаны на схеме консистентного кэширования, которая использует пространство целочисленных токенов в диапазоне от 0 до 2127 -1. Целочисленные токены назначаются узлам (nodes) HyperStore. Для каждого объекта S3 по мере его загрузки в хранилище рассчитывается хэш. Объект сохраняется в узле, которому было присвоено наименьшее значение токена, большее или равное значению хэша объекта. Репликация реализуется также путем хранения объекта на узлах, которым были назначены токены, имеющие минимально большее значение.
В «классическом» хранилище, основанном на консистентном хэшировании, один токен присваивается одному физическому узлу. Система Cloudian HyperStore использует и расширяет функциональность «виртуального узла» (vNode), введенную в Cassandra в версии 1.2, — каждому физическому хосту присваивается большое количество токенов (максимум 256). По сути, кластер хранилища состоит из очень большого количества «виртуальных узлов» с большим количеством виртуальных узлов (токенов) на каждом физическом хосте.
Система HyperStore назначает отдельный набор токенов (виртуальных узлов) каждому диску на каждом физическом хосте. Каждый диск на хосте отвечает за свой набор реплик объектов. Сбой на диске затрагивает только те реплики объектов, которые находятся на нем. Другие диски на хосте продолжат работать и выполнять свои обязанности по хранению данных.
Приведем пример и рассмотрим кластер из 6 хостов HyperStore, на каждом из которых находится по 4 диска S3-хранилища. Предположим, что каждому физическому хосту назначено 32 токена и существует упрощенное пространство токенов от 0 до 960, а значения 192 токенов в этой системе (6 хостов по 32 токена) — это 0, 5, 10, 15, 20 и так далее до 955.
На приведенной ниже схеме приводится одно возможное распределение токенов по всему кластеру. 32 токена каждого хоста распределены равномерно по 4 дискам (8 токенов на диск), а сами токены случайным образом распределены по кластеру.

Теперь предположим, что вы настроили HyperStore на 3X репликацию объектов S3. Условимся, что объект S3 загружается в систему, и алгоритм хеширования, примененный к его имени, дает нам хеш-значение 322 (в этом упрощенном хэш-пространстве). На приведенной ниже схеме показано, как три экземпляра или реплики объекта будут храниться в кластере:
- С его хэш-значением имени 322 первая реплика объекта хранится на 325 токене, т.к. это наименьшее значение токена, которое больше или равно значению хеша объекта. 325 токен (выделен красным цветом на схеме) назначен hyperstore2:Disk2. Соответственно, там и хранится первая реплика объекта.
- Вторая реплика хранится на диске, которому назначен следующий токен (330, выделен оранжевым цветом), то есть на hyperstore4:Disk2.
- Третья реплика сохраняется на диск, которому присваивается следующий после 330 токен — 335 (желтый), на hyperstore3:Disk3.

Добавлю комментарий: с практической точки зрения эта оптимизация (распределение токенов не только по физическим нодам, но и по отдельным дискам) нужна не только для обеспечения доступности, но и для равномерности распределения данных между дисками. При этом RAID-массив не используется, всей логикой размещения данных на дисках управляет сам HyperStore. С одной стороны, это удобно и контролируемо, при потере диска всё самостоятельно перебалансируется. С другой стороны, лично я хорошим RAID-контроллерам доверяю больше — всё-таки их логика работы оптимизируется уже много лет. Но это всё лично мои предпочтения, на реальных косяках и проблемах мы HyperStore ни разу не ловили, если соблюдать рекомендации вендора при установке ПО на физические сервера. А вот попытка использовать виртуализацию и виртуальные диски поверх одного и того же луна на СХД окончилась неудачей, при перегрузке СХД во время нагрузочного тестирования HyperStore сходил с ума и раскидывал данные совершенно неравномерно, забивая одни диски и не трогая другие.
Устройство диска внутри кластера
Напомним, что у каждого хоста по 32 токена, а токены каждого хоста равномерно распределены между его дисками. Давайте детально рассмотрим hyperstore2:Disk2 (на схеме ниже). Мы видим, что этому диску присвоены токены 325, 425, 370 и так далее.
Так как кластер сконфигурирован для 3X-репликации, на hyperstore2:Disk2 будет храниться следующее:
В соответствии с 325 токеном диска:
- Первые реплики объектов со значением хэша от 320 (исключительно) до 325 (включительно);
- Вторые реплики объектов со значением хэша от 315 (исключительно) до 320 (включительно);
- Третьи реплики объектов со значением хэша от 310 (исключительно) до 315 (включительно).
В соответствии с 425 токеном диска:
- Первые реплики объектов со значением хэша от 420 (исключительно) до 425 (включительно);
- Вторые реплики объектов со значением хэша от 415 (исключительно) до 420 (включительно);
- Третьи реплики объектов со значением хэша от 410 (исключительно) до 415 (включительно).
И так далее.
Как было замечено ранее, при размещении вторых и третьих реплик HyperStore может в некоторых случаях пропускать токены, чтобы не хранить больше одной копии объекта на одном физическом узле. Это исключает использование hyperstore2:disk2 как хранилища для вторых или третьих реплик одного и того же объекта.

При сбое Диска 2 на Дисках 1, 3 и 4 продолжат храниться данные, и объекты на Диске 2 сохранятся в кластере, т.к. были реплицированы на другие хосты.
Комментарий: в итоге, распределение реплик и/или фрагментов объектов в кластере HyperStore строится на доработанном под нужды файлового хранилища дизайне Cassandra. Чтобы понять, куда поместить объект физически, берется некий хэш от его имени и, в зависимости от его значения, выбираются пронумерованные «токены» для размещения. Токены заранее случайно распределены по кластеру с целью балансировки нагрузки. При выборе номера токена для размещения учитываются ограничения на размещение реплик и частей объекта на одни и те же физические ноды. К сожалению, у такого дизайна возникает побочный эффект: если нужно добавить или убрать ноду в кластере, придется заново перетасовывать данные, а это достаточно ресурсоемкий процесс.
Единое хранилище в нескольких ЦОД
Теперь давайте посмотрим, как у HyperStore работает геораспределенность в нескольких ЦОДах и регионах. В нашем случае мультиЦОД-режим от мультирегионального отличается использованием одного или нескольких пространств токенов. В первом случае пространство токенов едино. Во втором каждый регион будет иметь независимое пространство токенов с (потенциально) своими собственными настройками уровня консистентности, емкости и конфигурациями хранилища.
Чтобы понять, как это работает, снова обратимся к переводу документации, раздел «Multi-Data Center Deployments».
Рассмотрим развертывание HyperStore в двух дата-центрах. Назовем их DC1 и DC2. В каждом дата-центре расположено по 3 физических узла. Как и в наших предыдущих примерах, каждый физический узел имеет четыре диска, каждому хосту назначаются 32 токена (vNodes), и мы предполагаем упрощенное пространство токенов от 0 до 960. Согласно такому сценарию с несколькими дата-центрами, пространство токенов делится на 192 токена — по 32 токена на каждый из 6 физических хостов. По хостам токены распределены абсолютно случайно.
Также предположим, что репликация объектов S3 в данном случае настроена на двух репликах в каждом дата-центре.
Давайте рассмотри, как гипотетический объект S3 со значением хэша 942 будет реплицироваться в 2 дата-центрах:
- Первая реплика хранится в vNode 945 (обозначено красным цветом на схеме ниже), которая находится в DC2, на hyperstore5:Disk3.
- Вторая реплика хранится в vNode 950 (обозначено оранжевым цветом) DC2, на hyperstore6:Disk4.
- Следующий vNode 955 расположен в DC2, где уже достигнут заданный уровень репликации, поэтому этот vNode пропускаем.
- Третья реплика расположена в vNode 0 (желтый) — в DC1, hyperstore2:Disk3. Обратите внимание, что после токена с наивысшим номером (955) следует токен с самым низшим номером (0).
- Следующий vNode (5) расположен в DC2, где уже достигнут заданный уровень репликации, поэтому этот vNode пропускаем.
- Четвертая и последняя реплика хранится в vNode 10 (зеленый) — в DC1, hyperstore3:Disk3.
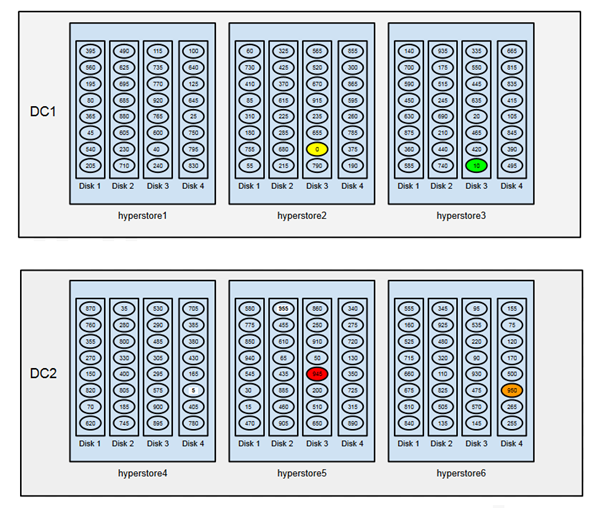
Комментарий: еще одно свойство приведенной выше схемы в том, что для нормальной работы политик хранения, затрагивающих оба ЦОДа, объем места, количество нод и дисков на ноде должно совпадать в обоих ЦОДах. Как я уже говорил выше, мультирегиональная схема такого ограничения не имеет.На этом мы закончим обзор особенностей архитектуры и основных возможностей Cloudian. В любом случае, эта тема слишком серьезна и велика, чтобы можно было уместить исчерпывающий мануал по ней в статью на Хабре. Поэтому, если вам интересны детали, которые я опустил, у вас возникли вопросы или пожелания к изложению материала в дальнейших статьях, с удовольствием пообщаюсь с вами в комментариях.
В следующей статье мы рассмотрим реализацию S3 хранилища в DataLine, подробно поговорим об использующейся инфраструктуре и технологиях сетевой отказоустойчивости, а в качестве бонуса я расскажу вам историю его строительства!
