Представьте себе: вы обслуживаете ИТ-инфраструктуру крупного торгового центра. В городе начинается ливень. Потоки дождя прорывают крышу, вода заполняет торговые помещения по щиколотку. Надеемся, что ваша серверная не в подвале, иначе проблем не избежать.
Описанная история — не фантазия, а собирательное описание пары событий 2020 года. В крупных компаниях на этот случай всегда под рукой план послеаварийного восстановления, или disaster recovery plan (DRP). В корпорациях за него отвечают специалисты по непрерывности бизнеса. Но в средних и небольших компаниях решение таких задач ложится на ИТ-службы. Нужно самому разобраться в бизнес-логике, понять, что и где может упасть, придумать защиту и внедрить.
Здорово, если ИТ-специалисту удается провести переговоры с бизнесом и обсудить необходимость защиты. Но я не раз наблюдал, как компания экономила на решении для disaster recovery (DR), так как считала его избыточным. Когда наступала авария, долгое восстановление грозило убытками, а бизнес оказывался не готов. Можно сколько угодно повторять: «А я же говорил», — восстанавливать сервисы все равно предстоит ИТ-службе.

С позиции архитектора расскажу, как избежать этой ситуации. В первой части статьи покажу подготовительную работу: как обсуждать с заказчиком три вопроса для выбора инструментов защиты:
Во второй части поговорим о вариантах ответа на вопрос: чем защищаться. Приведу примеры кейсов, как разные заказчики строят свою защиту.
Лучше начинать подготовку с обсуждения плана послеаварийных действий c бизнес-заказчиком. Тут главная сложность — найти общий язык. Заказчика обычно не волнует, как ИТ-решение работает. Его волнует, может ли сервис выполнять бизнес-функции и приносить деньги. Например: если сайт работает, а платежная система «лежит», поступлений от клиентов нет, а «крайние» — все равно ИТ-специалисты.
ИТ-специалист может испытывать сложности в таких переговорах по нескольким причинам:
Я бы построил разговор так:
Дальше выясняем у бизнес-заказчика, от каких рисков мы защищаемся в первую очередь. Все риски условно поделим на две группы:
Бизнесу страшно потерять и данные, и время — все это ведет к потере денег. Так что снова задаем вопросы по каждой группе рисков:
После обсуждения мы поймем, как расставить приоритеты для точек отказа.
Когда понятны критические точки отказа, рассчитываем показатели RTO и RPO.
Напомню, что RTO (recovery time objective) — это допустимое время с момента аварии и до полного восстановления сервиса. На языке бизнеса — это допустимое время простоя. Если мы знаем, сколько денег приносил процесс, то сможем посчитать убытки от каждой минуты простоя и вычислить допустимый убыток.
RPO (recovery point objective) — допустимая точка восстановления данных. Она определяет время, за которое мы можем потерять данные. С точки зрения бизнеса, потеря данных может грозить, например, штрафами. Такие потери тоже можно перевести в деньги.
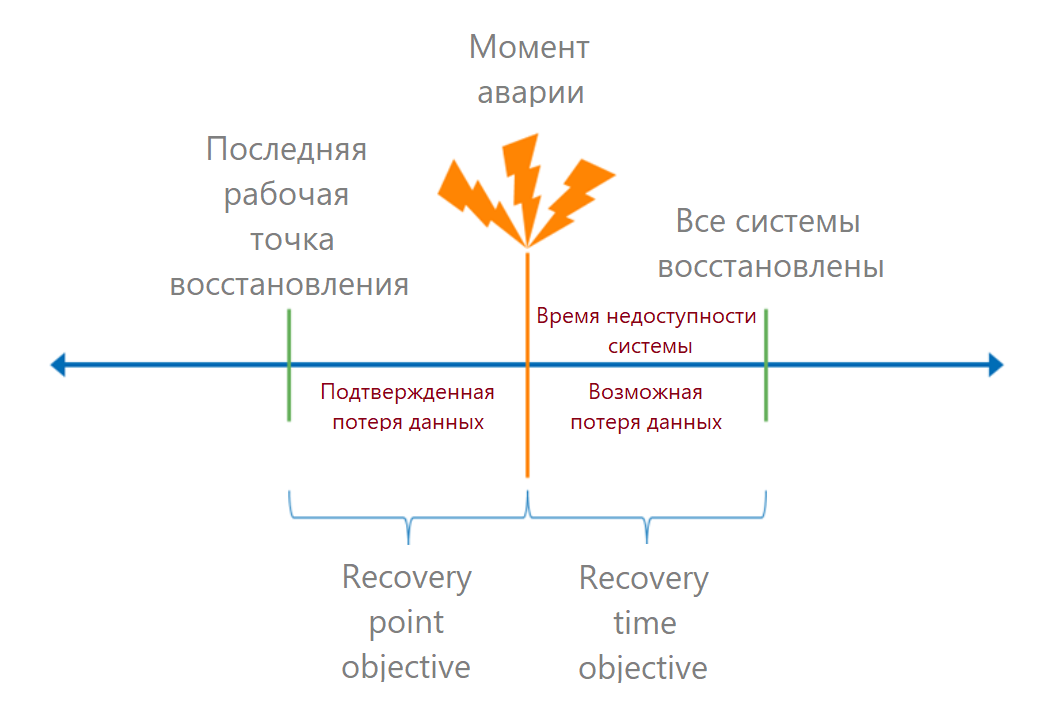
Время восстановления нужно рассчитывать для конечного пользователя: в какой срок он сможет войти в систему. Так что сначала складываем время восстановления всех звеньев цепи. Здесь часто делают ошибку: берут RTO провайдера из SLA, а про остальные слагаемые забывают.
После обсуждения всех пунктов заказчик уже понимает цену аварии для бизнеса. Теперь можно выбирать инструменты и обсуждать бюджет. Покажу на примерах клиентских кейсов, какие инструменты мы предлагаем для разных задач.
Начнем с первой группы рисков: потерь из-за простоев сервиса. Варианты решения для этой задачи должны обеспечивать хороший RTO.
Все рассмотренные решения обеспечивают высокую доступность, но не спасают от потерь данных из-за вируса-шифровальщика или случайной ошибки сотрудника. На этот случай нам понадобятся бэкапы, которые обеспечат нужный RPO.
5. Не забыть про резервное копирование
Все знают, что нужно делать бэкапы, даже если у вас самое крутое катастрофоустойчивое решение. Так что лишь коротко напомню несколько моментов.
Строго говоря, бэкап — это не DR. И вот почему:
При этом расписание резервного копирования может обеспечить нужный RPO. Для бэкапов важно предусмотреть георезервирование на случай проблем с основной площадкой. Часть резервных копий рекомендуется хранить отдельно.
В итоговом плане послеаварийного восстановления должно быть минимум 2 инструмента:
Также стоит позаботиться о резервном канале связи на случай падения основного интернет-провайдера. И — вуаля! — DR на минималках уже готов.
Описанная история — не фантазия, а собирательное описание пары событий 2020 года. В крупных компаниях на этот случай всегда под рукой план послеаварийного восстановления, или disaster recovery plan (DRP). В корпорациях за него отвечают специалисты по непрерывности бизнеса. Но в средних и небольших компаниях решение таких задач ложится на ИТ-службы. Нужно самому разобраться в бизнес-логике, понять, что и где может упасть, придумать защиту и внедрить.
Здорово, если ИТ-специалисту удается провести переговоры с бизнесом и обсудить необходимость защиты. Но я не раз наблюдал, как компания экономила на решении для disaster recovery (DR), так как считала его избыточным. Когда наступала авария, долгое восстановление грозило убытками, а бизнес оказывался не готов. Можно сколько угодно повторять: «А я же говорил», — восстанавливать сервисы все равно предстоит ИТ-службе.

С позиции архитектора расскажу, как избежать этой ситуации. В первой части статьи покажу подготовительную работу: как обсуждать с заказчиком три вопроса для выбора инструментов защиты:
- Что защищаем?
- От чего защищаем?
- Как сильно защищаем?
Во второй части поговорим о вариантах ответа на вопрос: чем защищаться. Приведу примеры кейсов, как разные заказчики строят свою защиту.
Что защищаем: выясняем критические бизнес-функции
Лучше начинать подготовку с обсуждения плана послеаварийных действий c бизнес-заказчиком. Тут главная сложность — найти общий язык. Заказчика обычно не волнует, как ИТ-решение работает. Его волнует, может ли сервис выполнять бизнес-функции и приносить деньги. Например: если сайт работает, а платежная система «лежит», поступлений от клиентов нет, а «крайние» — все равно ИТ-специалисты.
ИТ-специалист может испытывать сложности в таких переговорах по нескольким причинам:
- ИТ-службе не до конца известна роль информационной системы в бизнесе. Например, если нет доступного описания бизнес-процессов или прозрачной бизнес-модели.
- От ИТ-службы зависит не весь процесс. Например, когда часть работы выполняют подрядчики, а у ИТ-специалистов нет на них прямого влияния.
Я бы построил разговор так:
- Объясняем бизнесу, что аварии случаются со всеми, а на восстановление требуется время. Лучше всего — продемонстрировать ситуации, как это происходит и какие последствия возможны.
- Показываем, что от ИТ-службы зависит не все, но вы готовы помочь с планом действий в зоне вашей ответственности.
- Просим бизнес-заказчика ответить: если случится апокалипсис, какой процесс нужно восстановить первым? Кто и как в нем участвует?
От бизнеса необходим простой ответ, например: нужно, чтобы колл-центр продолжил регистрировать заявки 24/7.
- Просим одного-двух пользователей системы подробно описать этот процесс.
Лучше привлечь на помощь аналитика, если в вашей компании такой есть.
Для начала описание может выглядеть так: колл-центр получает заявки по телефону, по почте и через сообщения с сайта. Потом заводит их в 1С через веб-интерфейс, оттуда их забирает производство вот таким способом.
- Затем смотрим, какие аппаратные и программные решения поддерживают процесс. Для комплексной защиты учитываем три уровня:
- приложения и системы внутри площадки (программный уровень),
- саму площадку, где крутятся системы (инфраструктурный уровень),
- сеть (про нее вообще часто забывают).
- приложения и системы внутри площадки (программный уровень),
- Выясняем возможные точки отказа: узлы системы, от которых зависит работоспособность сервиса. Отдельно отмечаем узлы, которые поддерживают другие компании: операторы связи, хостинг-провайдеры, дата-центры и так далее. С этим можно возвращаться к бизнес-заказчику для следующего шага.
От чего защищаем: риски
Дальше выясняем у бизнес-заказчика, от каких рисков мы защищаемся в первую очередь. Все риски условно поделим на две группы:
- потеря времени из-за простоя сервисов;
- потеря данных из-за физических воздействий, человеческого фактора и т.д.
Бизнесу страшно потерять и данные, и время — все это ведет к потере денег. Так что снова задаем вопросы по каждой группе рисков:
- Можем ли мы оценить для этого процесса, сколько в деньгах стоит потеря данных и потеря времени?
- Какие данные мы не можем потерять?
- Где не можем допустить простоя?
- Какие события наиболее вероятны и сильнее нам угрожают?
После обсуждения мы поймем, как расставить приоритеты для точек отказа.
Как сильно защищаем: RPO и RTO
Когда понятны критические точки отказа, рассчитываем показатели RTO и RPO.
Напомню, что RTO (recovery time objective) — это допустимое время с момента аварии и до полного восстановления сервиса. На языке бизнеса — это допустимое время простоя. Если мы знаем, сколько денег приносил процесс, то сможем посчитать убытки от каждой минуты простоя и вычислить допустимый убыток.
RPO (recovery point objective) — допустимая точка восстановления данных. Она определяет время, за которое мы можем потерять данные. С точки зрения бизнеса, потеря данных может грозить, например, штрафами. Такие потери тоже можно перевести в деньги.
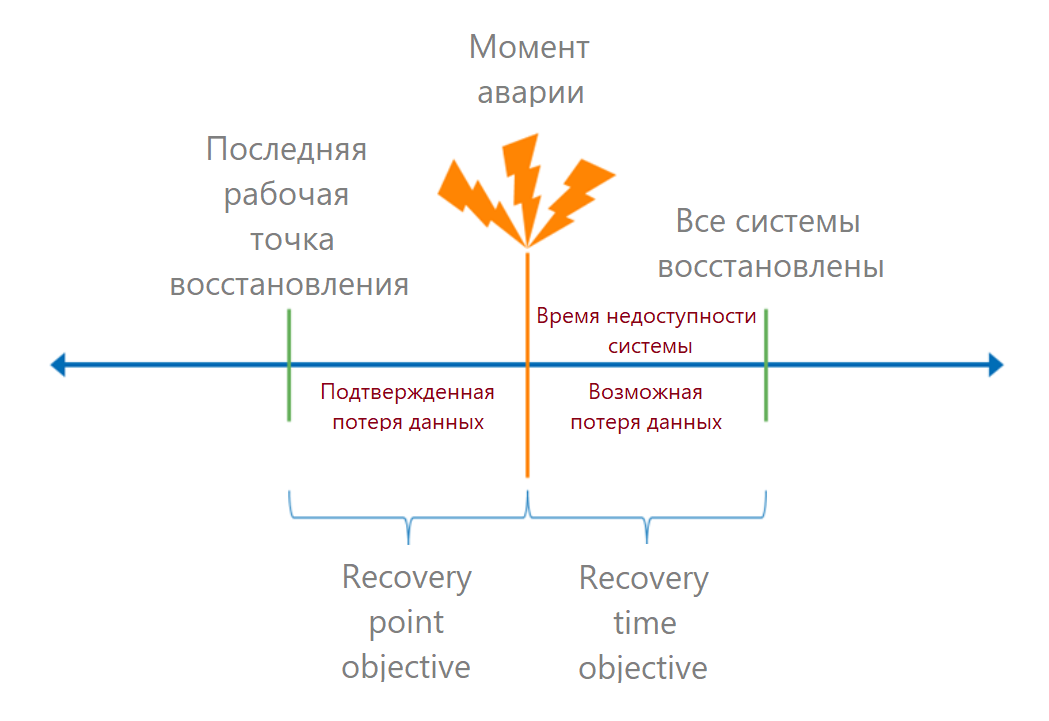
Время восстановления нужно рассчитывать для конечного пользователя: в какой срок он сможет войти в систему. Так что сначала складываем время восстановления всех звеньев цепи. Здесь часто делают ошибку: берут RTO провайдера из SLA, а про остальные слагаемые забывают.
Посмотрим на конкретном примере. Пользователь заходит в 1С, система открывается с ошибкой базы данных. Он обращается к системному администратору. База находится в облаке, сисадмин сообщает о проблеме сервис-провайдеру. Допустим, на все коммуникации уходит 15 минут. В облаке база такого объема восстановится из бэкапа за час, следовательно, RTO на стороне сервис-провайдера — час. Но это не окончательный срок, для пользователя к нему прибавились 15 минут на обнаружение проблемы.Эти расчеты покажут бизнесу, от каких внешних факторов зависит срок восстановления. Например, если офис заливают, то сначала нужно обнаружить протечку и устранить ее. Понадобится время, которое зависит не от ИТ.
Дальше системному администратору надо проверить, что база корректная, подключить ее к 1С и запустить сервисы. На это необходим еще час, значит, RTO на стороне администратора — уже 2 часа 15 минут. Пользователю нужно еще 15 минут: залогиниться, проверить, что нужные транзакции появились. 2 часа 30 минут — общее время восстановления сервис в этом примере.
Чем защищаем: выбираем инструменты для разных рисков
После обсуждения всех пунктов заказчик уже понимает цену аварии для бизнеса. Теперь можно выбирать инструменты и обсуждать бюджет. Покажу на примерах клиентских кейсов, какие инструменты мы предлагаем для разных задач.
Начнем с первой группы рисков: потерь из-за простоев сервиса. Варианты решения для этой задачи должны обеспечивать хороший RTO.
- Разместить приложение в облаке
Для начала можно просто переехать в облако — там вопросы высокой доступности уже продумал провайдер. Хосты виртуализации собраны в кластер, электропитание и сеть зарезервированы, данные хранятся на отказоустойчивых СХД, а сервис-провайдер несет финансовую ответственность за простои.
Например, можно разместить в облаке виртуальную машину с базой данных. Приложение подключится к базе данных снаружи по установленному каналу или из этого же облака. Если возникнут проблемы с одним из серверов кластера, то ВМ перезапустится на соседнем сервере меньше чем за 2 минуты. После этого в ней поднимется СУБД, и через несколько минут база данных станет доступна.
RTO: измеряется в минутах. Прописать эти сроки можно в соглашении с провайдером.
Стоимость: считаем стоимость ресурсов облака под ваше приложение.
От чего не защитит: от массовых сбоев на площадке провайдера, например, из-за аварий на уровне города.
- Кластеризовать приложение
Если хочется улучшить RTO, предыдущий вариант можно усилить и сразу разместить в облаке кластеризованное приложение.
Реализовать кластер можно в режиме active-passive или active-active. Создаем несколько ВМ, исходя из требований вендора. Для большей надежности разносим их по разным серверам и СХД. При отказе сервера с одной из БД, резервная нода принимает на себя нагрузку за несколько секунд.
RTO: измеряется в секундах.
Стоимость: чуть дороже обычного облака, потребуются дополнительные ресурсы для кластеризации.
От чего не защитит: по-прежнему не защитит от массовых сбоев на площадке. Но локальные сбои будут не такими продолжительными.
Из практики: У компании-ритейлера было несколько информационных систем и сайтов. Все базы данных располагались локально в офисе компании. Ни о каком DR не задумывались, пока офис не остался без электричества несколько раз подряд. Клиенты были недовольны сбоями на сайтах.
Проблема с доступностью сервисов решилась после переезда в облако. Плюс к этому удалось оптимизировать нагрузку на базы данных за счет балансировки трафика между узлами. - Переехать в катастрофоустойчивое облако
Если нужно, чтобы работе не помешало даже стихийное бедствие на основной площадке, можно выбрать катастрофоустойчивое облако В этом варианте провайдер разносит кластер виртуализации уже на 2 дата-центра. Между дата-центрами происходит постоянная синхронная репликация, один-в-один. Каналы между ЦОДами зарезервированы и идут по разным трассам, так что такому кластеру не страшны проблемы с сетью.
RTO: стремится к 0.
Стоимость: самый дорогой вариант в облаке.
От чего не защитит: Не поможет от порчи данных, а также от человеческого фактора, поэтому параллельно рекомендуется делать бэкапы.
Из практики: Один из наших клиентов разработал комплексный план послеаварийного восстановления. Вот какую стратегию он выбрал:
- Катастрофоустойчивое облако защищает приложение от сбоев на уровне инфраструктуры.
- Двухуровневый бэкап обеспечивает защиту на случай человеческого фактора. Резервные копии делают двух видов: «холодные» и «горячие». «Холодный» бэкап находится в выключенном состоянии, на его развертывание требуется время. «Горячий» бэкап уже готов к работе и восстанавливается быстрее. Его хранят на специально выделенной СХД. Третью копию записывают на ленту и хранят в другом помещении.
Раз в неделю клиент тестирует защиту и проверяет работоспособность всех бэкапов, в том числе с ленты. Ежегодно в компании проводят тестирование всего катастрофоустойчивого облака. - Катастрофоустойчивое облако защищает приложение от сбоев на уровне инфраструктуры.
- Организовать репликацию на другую площадку
Еще один вариант, как можно избежать глобальных проблем на основной площадке: обеспечить георезервирование. Другими словами, создать резервные виртуальные машины на площадке в другом городе. Для этого подойдут специальные решения для DR: мы в компании используем VMware vCloud Availability (vCAV). С его помощью можно настроить защиту между несколькими площадками облачного провайдера или восстановиться в облако с on-premise площадки. Подробнее о схеме работы с vCAV я уже рассказывал тут.
RPO и RTO: от 5 минут.
Стоимость: дороже первого варианта, но дешевле, чем аппаратная репликация в катастрофоустойчивом облаке. Цена складывается из стоимости лицензии vCAV, платы за администрирование, стоимости ресурсов облака и ресурсов под резерв по модели PAYG (10% от стоимости работающих ресурсов за выключенные ВМ).
Из практики: Клиент держал в нашем облаке в Москве 6 виртуальных машин с разными базами данных. Сначала защиту обеспечивал бэкап: часть резервных копий хранили в облаке в Москве, часть — на нашей петербургской площадке. Со временем базы данных выросли в объеме, и восстановление из бэкапа стало требовать больше времени.
К бэкапам добавили репликацию на базе VMware vCloud Availability. Реплики виртуальных машин хранятся на резервной площадке в Санкт-Петербурге и обновляются каждые 5 минут. Если на основной площадке происходит сбой, сотрудники самостоятельно переключаются на реплику виртуальной машины в Санкт-Петербурге и продолжают работу с ней.
Все рассмотренные решения обеспечивают высокую доступность, но не спасают от потерь данных из-за вируса-шифровальщика или случайной ошибки сотрудника. На этот случай нам понадобятся бэкапы, которые обеспечат нужный RPO.
5. Не забыть про резервное копирование
Все знают, что нужно делать бэкапы, даже если у вас самое крутое катастрофоустойчивое решение. Так что лишь коротко напомню несколько моментов.
Строго говоря, бэкап — это не DR. И вот почему:
- Это долго. Если данные измеряются в терабайтах, на восстановление потребуется не один час. Нужно восстановить, назначить сеть, проверить, что включится, посмотреть, что данные в порядке. Так что обеспечить хороший RTO можно, только если данных мало.
- Данные могут восстановиться не с первого раза, и нужно заложить время на повторное действие. Например, бывают случаи, когда мы точно не знаем время потери данных. Допустим, потерю заметили в 15.00, а копии делаются каждый час. С 15.00 мы смотрим все точки восстановления: 14:00, 13:00 и так далее. Если система важная, мы стараемся минимизировать возраст точки восстановления. Но если в свежем бэкапе не нашлось нужных данных, берем следующую точку — это дополнительное время.
При этом расписание резервного копирования может обеспечить нужный RPO. Для бэкапов важно предусмотреть георезервирование на случай проблем с основной площадкой. Часть резервных копий рекомендуется хранить отдельно.
В итоговом плане послеаварийного восстановления должно быть минимум 2 инструмента:
- Один из вариантов 1-4, который защитит системы от сбоев и падений.
- Резервное копирование для защиты данных от потерь.
Также стоит позаботиться о резервном канале связи на случай падения основного интернет-провайдера. И — вуаля! — DR на минималках уже готов.
