 Что хорошего можно извлечь из социальных сетей? Можно найти себе футбольную команду, басиста в группу, братьев по разуму, жену, сдать/снять квартиру/комнату/виллу на берегу океана. А если подключить анализ данных? Можно найти свое место в обществе. Например, если я слушаю XXX, читаю YYY и пью ZZZ, то нас таких всего 100 на этом шаре. А если я еще буду красить ногти в зеленый, то точно буду единственным и неповторимым?
Что хорошего можно извлечь из социальных сетей? Можно найти себе футбольную команду, басиста в группу, братьев по разуму, жену, сдать/снять квартиру/комнату/виллу на берегу океана. А если подключить анализ данных? Можно найти свое место в обществе. Например, если я слушаю XXX, читаю YYY и пью ZZZ, то нас таких всего 100 на этом шаре. А если я еще буду красить ногти в зеленый, то точно буду единственным и неповторимым? Можно понять, что нравится людям, что им можно продать, можно делать прогнозы и в сотый раз проверять теорию шести рукопожатий. В области Social Network Analysis существует множество задач, одну из которых мы предлагаем решить на онлайн этапе SNA Hackathon 2014.
Задачи в социальных сетях
Социальные сети сегодня — это неиссякаемый источник информации о людях, их увлечениях и мыслях. Каждый день пользователи генерируют около 8 терабайт фотографий, текста, видео, которые могут стать ресурсом для создания новых программных продуктов или мощным инструментом предсказания.

Мы решили сосредоточиться на задаче анализа текстовых данных, генерируемых пользователями, и попросили участников хакатона проанализировать зависимость между содержимым поста и его рейтингом.
О хакатоне и задаче онлайн этапа
Чтобы принять участие в офлайн-этапе, участникам необходимо до 10 апреля предсказать количество лайков, которые наберет пост через определенное время после публикации. Или, говоря терминами Одноклассников, чьи данные мы анализируем, количество отметок “Класс!” у определенной темы.

На сегодняшний момент сформировался вот такой лидерборд. Участники, чьи модели окажутся самыми точными, будут приглашены на офлайн-этап, который пройдет в Петербурге, и шанс выиграть Macbook pro. Там за 24 часа нужно будет проанализировать реальные публикации около 44 миллионов пользователей и создать на их основе прототип продукта. Помогать советом и выступать с небольшими докладами будут эксперты из компаний EMC, JetBrains, Data Mining Labs и университетов НИУ ВШЭ и РЭШ.
Исходные данные первого этапа
Данные о постах хранятся в двух файлах: train_content.csv и test_content.csv со следующими полями:
group_id — Анонимизированный идентификатор группы, в которой размещен пост
post_id — Анонимизированный идентификатор поста
timestamp — Время публикации поста, представляющее собой количество миллисекунд, прошедшее с полночи 1-го января 1970 года (UTC).
content — Содержание поста. Внимание: в этом поле могут содержаться пробелы, специальные символы, а также http-ссылки, изображения и опросы. Авторская орфография и пунктуация сохранены.
Пример:

Данные о «Классах!» тренировочного множества хранятся в файле train_likes.csv со следующими полями:
user_id — Анонимизированный идентификатор пользователя, поставившего «Класс!»
post_id — Анонимизированный идентификатор поста
timestamp — Время «Класс!», представляющее собой количество миллисекунд, прошедшее с полночи 1-го января 1970 года (UTC).
Пример:

Оценка прогноза производится с использованием метрики R2 (на 1000 умножаем для удобства отображения):
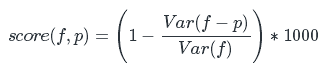
Где:
f — фактическое значение количества «Классов!»
p — прогноз количества «Классов!»
Var(x) — выборочная дисперсия величины x
Получается, что 1000 — это максимальный балл для прогноза. Чтобы пройти во второй этап хакатона, необходимо преодолеть бейзлайн, точность алгоритма, который написали мы.
Дефолтный алгоритм
Исходный код на R с предварительной обработкой данных и построением базового прогноза можно найти в нашем репозитарии на github.
Там вы найдете три скрипта на R:
prepare.R — Препроцессинг данных
features.R — Нахождение базовых признаков (кол-во символов, кол-во слов, средняя длина слова)
baseline.R — Построение модели (мы используем линейную регрессию)
Как запустить?
Распакуйте входные данные (test_content.csv, train_content.csv, train_likes.csv) в папку ./data/src/. Наберите в командной строке:
git clone https://github.com/snahackathon/sh2014.git
cd ./sh2014
#<unzip data to ./data>
cd R
R --vanilla < prepare.R
R --vanilla < features.R
R --vanilla < baseline.R
Предсказанное количество лайков для тестового множества лежит в data/submit. Конечно, это всего лишь базовый алгоритм, он не преодолевает граничного значения score.
Если ты смелый, ловкий, умелый...

Участвуй в хакатоне! Наша задача — собрать увлеченных и креативных людей, чтобы соревноваться было интересно, а в итоге конкурса получались точные модели и изящные алгоритмы. Тех, кто еще учится и хочет попробовать свои силы, мы приглашаем поучаствовать — загружайте тренировочные и тестовые данные и выжимайте из них все, что только возможно. Тех, кто уже научился приглашаем не только поучаствовать, но и выступить в качестве эксперта или судьи. Для этого напишите нам по адресу contact@sh2014.org.
