Комментарии 8
Интересно, а, например, бенгали сможет распознать?
Нет пока:


Эм, сразу возникает два вопроса:
1) Зачем городить огород со своей системой распознания. По поиску 文字识别 в 百度 уже есть несколько сотен проектов, как бесплатных, так и платных. Неужели есть такие сложности с получением лицензии на их использование, или это требование такое — иметь свой движок?
2) Сравнение корейского и китайского исключительно некорректное. Корейский пример — обычный рукописный текст, а китайский, такое ощущение, писал ребенок лет пяти( или студент первого месяца языковых курсов). Интересно было бы посмотреть, как ваш распознаватель справится с обычным текстом взрослого человека( айпад справляется на ура). Например( в следующем комментарии):
1) Зачем городить огород со своей системой распознания. По поиску 文字识别 в 百度 уже есть несколько сотен проектов, как бесплатных, так и платных. Неужели есть такие сложности с получением лицензии на их использование, или это требование такое — иметь свой движок?
2) Сравнение корейского и китайского исключительно некорректное. Корейский пример — обычный рукописный текст, а китайский, такое ощущение, писал ребенок лет пяти( или студент первого месяца языковых курсов). Интересно было бы посмотреть, как ваш распознаватель справится с обычным текстом взрослого человека( айпад справляется на ура). Например( в следующем комментарии):
Речь не о вводе отдельного символа, а о разборе целой фразы. Алгоритм айОСа не справится с разбором целой фразы, так как там требуется куча логики и архитектурных решений для определения границ символов слов (собственно статья об этом).
Поэтому и готовые движки «распознавания символов» не подходят, так как тут нужен движок «распознавания текста» — таких довольно мало.
Поэтому и готовые движки «распознавания символов» не подходят, так как тут нужен движок «распознавания текста» — таких довольно мало.
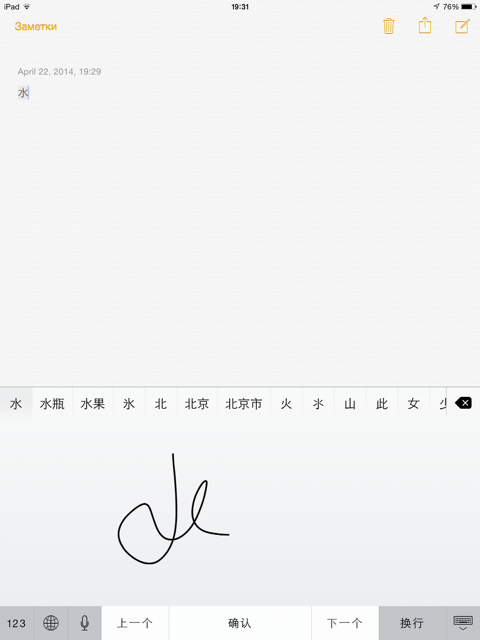
Собственно, даже сложные иероглифы вроде 警 айпад распознает без проблем( не говоря уж об элементарных вроде 水 или 兰)Хотя, правда, только по одному иероглифу. Но и то, я ведь иностранец, и пишу как ребенок лет пятнадцати.





Занятная какая формула на КДПВ.
Сравнение с системой ввода иереглифов на айОС устройствах, где известна одномерная траектория, не вполне корректно. Дело в том, что наша система позволяет также индексировать бумажные заметки по их фотографиям (так называемое оффлайн распознавание), а эта задача значительно сложнее.
Кроме того, если мы говорим про распознавание по траектории (онлайн ввод), то задача распознания целой страницы также не сводится напрямую к системе посимвольного ввода. Во-первых, есть проблемы с сегментацией, а во-вторых, практика показывает, что при посимвольном вводе, человек неявно подстраивается под систему.
Кроме того, если мы говорим про распознавание по траектории (онлайн ввод), то задача распознания целой страницы также не сводится напрямую к системе посимвольного ввода. Во-первых, есть проблемы с сегментацией, а во-вторых, практика показывает, что при посимвольном вводе, человек неявно подстраивается под систему.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Индексация рукописного текста в изображениях: от европейских языков к азиатским