
Работать с данными — муторно, но есть кое-что похуже — проверять их качество. Больше данных — больше изматывающих ручных проверок и меньше уверенности, что с массивом всё в порядке.

Я разрабатываю ML-модели для розничного бизнеса, провожу A/B-тесты и оцениваю бизнес-эффекты в Газпромбанке. Год назад мы разработали систему, которая показывает, где и насколько данные плохи, а инженерам остаётся только разобраться почему. Раньше они сначала вручную выясняли, что в данных пошло не так, а теперь есть система, которая даёт подсказки. Расскажу об алгоритме, лежащем в основе системы, и о том, что она сейчас собой представляет и как используется в наших бизнес-процессах.
Проблема: стандартные проверки пропускают нетривиальные аномалии
Наши данные используются для обучения сложных моделей — бустингов и нейронок — на очень больших массивах, и какой-нибудь несработавший join на выходе может всё поломать. Crap in — crap out. А ещё могут возникнуть проблемы на стороне источника, может поменяться бизнес-логика…
Вот размерность одной из наших витрин, где применяются модели, с помощью которых мы даём рекомендации:

Мы долго использовали стандартные методы проверки качества данных: проверки на уровне ETL, ручную проверку распределений, бины и индекс стабильности популяции (PSI), а также другие статистические проверки. Но данных становилось всё больше, а в нашем случае проверки осложняются тем, что они агрегированы по миллионам клиентов. К тому же мы получаем тысячи переменных на каждый временной срез.
Иногда после успешно проведённой рекламной кампании приходит много клиентов с подозрением на аномальность, объединённых каким-то общим признаком, и стандартная проверка считывает это как ошибку в данных, хотя это не так. Как с этим работать вручную, уже непонятно.
Стандартные проверки могут запросто пропустить нетривиальные аномалии в данных. А ручные происходят постфактум, когда что-то уже сломалось.
Для понимания масштаба проблемы рассмотрим DAG сборки одной из наших витрин:

Настроить мониторинги на все эти этапы несложно, но как за всем этим следить? Гораздо проще мониторить финальный набор атрибутов во времени.
Решение: ML-модель для проверок больших данных
Мы начали с выбора алгоритма поиска аномалий. Перебрали самые известные методы: правило трёх сигм, LocalOutlierFactor, OneClass SVM и другие. Эти алгоритмы либо давали много ложных срабатываний, либо не справлялись с таким объёмом данных. Остановились на методе Isolation Forest (IF) — этот алгоритм впервые был предложен в 2008 году и опубликован в статье в 2009 году. В 2016 году его включили в библиотеку Python Scikit-Learn.
Это древовидный алгоритм, построенный на теории деревьев решений и случайных лесов. Он итеративно разбивает данные на две части на основе случайного порогового значения. Процесс продолжается, пока каждая точка данных не будет изолирована. Когда алгоритм проходит через все данные, он фильтрует точки, для выделения которых потребовалось меньше шагов, чем для других. То есть аномалии определяются как выбросы, которые легко изолируются. Их можно понимать как точки, которые редко распределены и находятся далеко от групп высокой плотности. Просто, понятно, интерпретируемо.


Основные плюсы IF:
модель без учителя — не нужно размечать данные;
не требует дополнительного шкалирования;
не требует «чистой» выборки, чтобы распределения были одинаковыми от месяца к месяцу.
Конечно, как и у любого алгоритма, есть и минусы:
надо много данных: сейчас это 40 месяцев, но планируем перейти на 2 года;
гиперпараметры настраиваются вручную;
ложные срабатывания при резком изменении бизнес-логики;
для нашего случая необходима ранжирующая функция на выходе.
Что получилось
Ноу-хау в том, что алгоритм работает не с самими данными, а с их описательными характеристиками.
Разберёмся, как мы его используем. Чтобы уменьшить шум и объём данных, схлопнем измерение «клиенты» с помощью вычисления описательных характеристик распределения переменных. Тем самым мы прячем от модели наибольшую компоненту размерности данных:

Это позволит увидеть общую картину по конкретной переменной и не перегружать модель.
Итак, этапы работы с моделью:
На стороне Hadoop средствами SQL считаем в разрезе месяца-переменной статистики, описывающие распределение:
count
count_unique
count_nulls
min
max
mean
median
stdev

Схлопнутые по клиентам статистики данных проходят через fit Isolation Forest. После обучения модели на конкретной переменной мы применяем метод класса decision_function(X), а не просто predict(X).
Применяем ранжирующую функцию к выводу Isolation Forest по каждой переменной в отдельности.
На выходе получаем score аномальности, ориентируясь на который, а также на значимость статистик переменных, дата-стюарт может обратить внимание на конкретную переменную и выяснять, почему она аномальна.
Повторить все предыдущие пункты отдельно на подвыборках конкретных ключевых для бизнеса сегментах (активные, новые, монопродуктовые, отточные и т. д. клиенты).
PROFIT!!!
Важно подробнее остановиться на ранжирующей функции. Если заглянуть в документацию sklearn, параметр contamination в Isolation Forest определяет, какую долю выбросов модель будет считать аномальной. Если оставлять его в позиции auto, понятное дело, будем иметь дело с ложноположительными срабатываниями. Нас это не устраивает, мы хотим не отбросить аномальные переменные, а ранжировать их по уровню нормальности. Поэтому применим одну из следующих незамысловатых ранжирующих функций:
lambda x: np.sqrt(np.abs(x)) if x < 0 else x**2
lambda x: np.cbrt(np.abs(x)) if x < 0 else x**3
Если у нас есть ранжирующая функция, мы можем оценить ошибки первого и второго рода, что уже хорошо.

Оценка качества позволяет определить отсечку: на каком значении скора аномальности мы перестаём считать, что качество фичи приемлемо, и отдаём её на проверку.
Большой буст нам дала библиотека diffi (Depth-based Isolation Forest Feature Importance) — она умеет показывать значимость переменных в iForest. С её помощью мы подсвечиваем, какие описательные статистики привели к тому, чтобы искомое значение признака стало аномальным. Это выглядит примерно так:
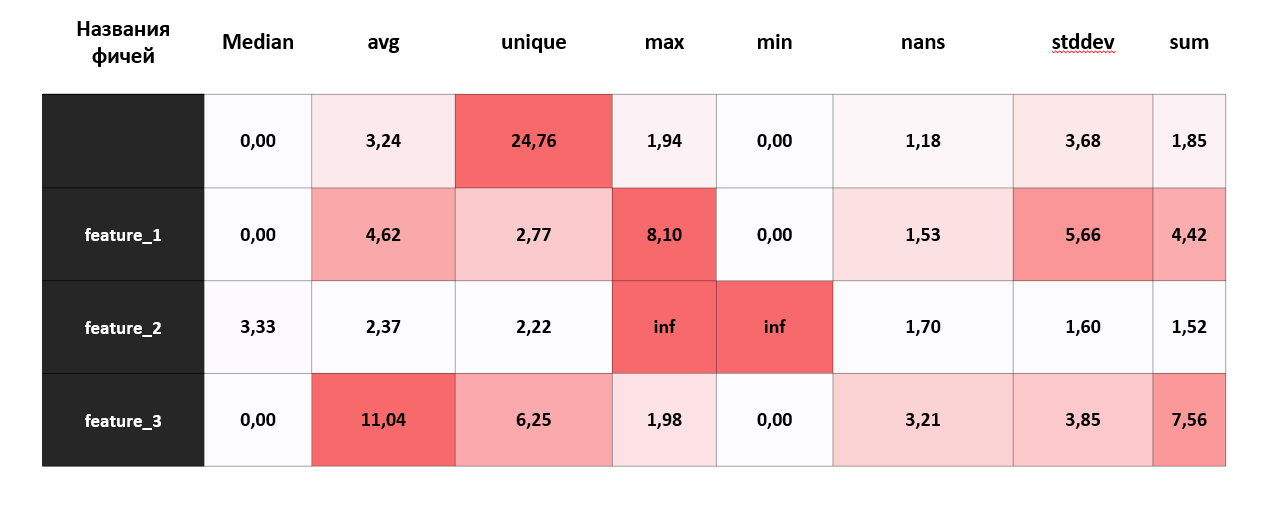
Итак, на выходе мы получаем ранжированный по скор-баллу список переменных с указанием временного среза. Далее дата-стюарт может анализировать, что пошло не так и на что обратить внимание, опираясь на этот список и на значимость статистик.
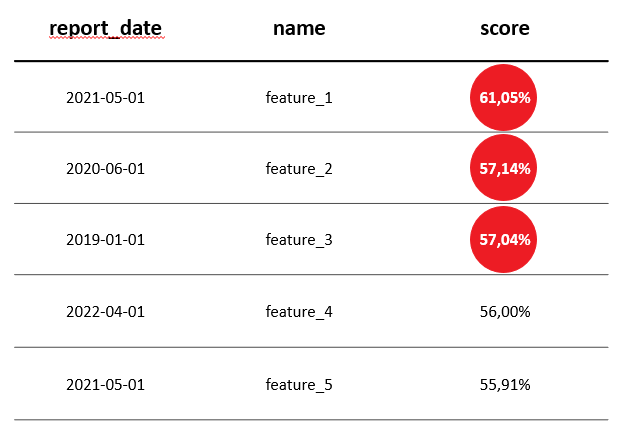
Конечно, мы сталкивались со сложностями. Сначала на этапе выбора алгоритма поиска аномалий мы поняли, что нам далеко не всё подойдёт. Данные разнородные: чтобы их сопоставить, нам пришлось бы пропускать тысячи переменных через какие-то подготовительные функции — слишком много работы.
Был случай, когда пришло большое количество клиентов в одном конкретном месте, и это подсветилось как аномалия. Понадобилось три месяца, чтобы система привыкла к этим клиентам. В течение этого времени данные по ним не учитывались.
Деплой: здесь никаких ноу-хау. Деплоим стандартно, в Docker-контейнере. Сами модельки iForest маленькие (менее 100 Кб для каждой фичи). Далее запускаем контейнер сразу после сборки витрины.
У нас есть модели, данные которых крутятся в баче, и есть данные, которые крутятся в онлайне. С данными в бачах мы справляемся отлично, так как получается их накопить для обучения. С онлайном пока думаем над реализацией, есть идея накапливать мини-бачи и пропускать через модельку.
PROFIT
На практике мы убедились, что система позволяет выявлять следующие аномалии:
массово пропущенные значения;
дубликаты;
резкая смена бизнес-логики;
аномальные значения и выбросы;
отсутствие полноты данных;
нарушение целостности (зависит от массовости);
некорректное представление данных (например, арифметические действия с текстовыми полями);
фиктивные значения.
Можно улучшить нахождение:
шум — может быть обусловлен неясно очерченной сезонностью;
нарушение структуры.
Это основные проблемы, снижающие качество данных.
Нельзя найти:
ошибки ввода данных оператором.
Теперь самое интересное: посмотрим на конкретные кейсы, которые отранжировала нам модель, и что именно там случилось:
Кейс 1. Неверный join, отпала связка договоров по части клиентов:

Кейс 2. Задвоения, затроения и т. д.:

Кейс 3. Вообще ничего не рассчиталось, какая-то глобальная ошибка:

Что дальше
Так задачка, которая решалась в фоновом режиме с привлечением малых ресурсов, выросла в полноценный проект. У нас в планах следующие улучшения модели:
добавить больше простых проверок описательных статистик на заданных правилах;
расширить список описательных статистик для работы алгоритма;
предоставлять более конкретные подсказки дата-стюартам;
протестировать подход на эмбеддингах;
делать автоматические рассылки (например, при приёмке новых данных);
перейти с ежемесячного на ежедневные пересчёты моделек;
разработать алгоритм для определения качества среза целиком, а не по фичам;
объединить всё в дашборд качества данных для ML-систем.
В итоге платформа будет предлагать различные методы проверки качества данных, давать дата-стюарту подсказки и делать рассылки.
Если у вас есть идеи, что в платформе можно сделать иначе или как её улучшить, будем рады комментариям!
