

Мы анализируем ваши действия с тем, чтобы понимать во всех каналах контакта, что для вас актуально. Это влияет на разного рода подсказки, возможность предлагать определённые акции и условия. Но в первую очередь — на повышение лояльности, а следовательно — на уменьшение оттока клиентов.
В основе — модифицированный метод RFM-сегментации. Разница между RFM и другими методами сегментации заключается в том, что он рассматривает только поведение клиентов. Не использует демографические данные, увлечения, взгляды или что-то ещё, кроме информации, в нашем случае, о транзакционной активности.
Меня зовут Ирина Скорынина, я занимаюсь разработкой новых моделей анализа поведения клиентов в Управлении розничного моделирования Газпромбанка и запуском кампаний по таким моделям. Сейчас расскажу, как математика помогает лучше понять потребности клиентов.
RFM-сегментация — это метод маркетингового анализа, позволяющий ранжировать клиентов, а также прогнозировать их будущее поведение как покупателей, основываясь на анализе их прошлых действий. Для RFM-анализа мы рассматривали такое поведение клиентов, как их транзакционная активность.
RFM — это аббревиатура от анализируемых ключевых количественных метрик:
- Recency (давность покупки). Этот показатель отражает, сколько времени прошло с момента последнего действия или транзакции клиента.
- Frequency (частота). Метрика, показывающая, как часто клиент совершал транзакции в течение определённого периода времени.
- Monetary (общая сумма трат). Этот фактор отражает количество потраченных клиентом денег за определённый период времени.
Как мы модифицировали RFM-анализ
Мы усовершенствовали этот подход, взяв его за основу и изменив метрики. В нашем методе, получившем название FMCD (это тоже аббревиатура), четыре параметра, по которым мы определяем транзакционное поведение клиентов. Теперь это:
- Frequency, который измеряется в количестве транзакций в среднемесячном значении.
- Monetary, представляющий собой среднемесячную сумму транзакций.
- Consistency, определяющий временные периоды трат, то есть частоту совершения клиентом транзакций.
- Diversity — это фактор, определяющий широту трат или количество уникальных категорий, в которых клиент проводил транзакции.
Категории определяются с учётом стандартных MCC-кодов (Merchant Category Code), которые классифицируют вид деятельности организации в операциях оплаты по банковским картам.
Такой код обозначает, чем занимается компания, какие товары или услуги продаёт: продукты питания, развлечения, топливо, строительные материалы и т.п. Он присваивается организации, когда она начинает принимать к оплате банковские карты. В нашей модели всего 14 уникальных категорий.
Кстати, мы отслеживаем появление новых MCC-кодов, чтобы их в дальнейшем можно было учесть в модели. В частности, у Яндекса не так давно появилась своя экосистема MCC-кодов 3990–3999.
Существующая база транзакционной активности клиентов позволяет анализировать их потребности, сегментировать покупателей по группам и разрабатывать на основе такой сегментации персональные предложения.
Сегментация помогает нацелиться на определённый сектор базы данных, который с наибольшей вероятностью ответит на маркетинговые усилия.
Отмечу, что мы, естественно, можем анализировать только транзакции с помощью банковских карт, покупки за наличные мы не можем отслеживать.
Недавно мы дополнили FMCD-расчёт анализом склонности клиента к покупкам в онлайне или офлайне. То есть онлайн-покупка — это покупка через интернет-магазин, а офлайн, соответственно, просто личный поход в магазин и оплата картой на месте.
С помощью этих метрик можно позиционировать клиента по тому, как он совершает транзакции. Чтобы более точно определиться, для каждого потребителя отсортировали метрики по величине их значения и распределили их по группам, или так называемым бакетам (bucket). Каждый бакет — это 10 % от выборки. То есть в наименьших бакетах будет наименьшее значение метрики, а, соответственно, в самых больших бакетах — наибольшее.
Чтобы было понятнее, например, клиенты, которые много покупают в разных местах, попадают в один бакет, клиенты, которые тратят много денег, попадают в другой бакет и т.д.
В итоге мы для каждого клиента получили по четыре скоринговых балла. В соответствии со скорбаллом каждый клиент попадает в ту или иную выборку. А ещё можно понять, сколько клиент совершает транзакций в количественном, в суммарном значении по отношению к остальным клиентам, а также в каком количестве уникальных категорий и в какие временные периоды.
Кроме того, можно определить, насколько каждый клиент вовлечён в транзакционную активность, просуммировав эти четыре скоринговых балла. Максимальное суммарное число баллов — 40.
Мы разделили всех клиентов по группам, отличающимся степенью POS-активности, то есть использования банковских карт. В процентном отношении это соответственно 20 % (TOP), 40 % (MIDDLE) и 40 % (BOTTOM). В первую группу попадают люди, имеющие самый большой показатель такой суммы баллов, то есть отличающиеся высокой степенью POS-активности и транзакциями в различных категориях. В средней группе — клиенты, у которых транзакционная активность умеренная, а в третью группу попадают люди со слабой POS-активностью, то есть те, кто совершает покупки редко, нерегулярно и в небольшом количестве уникальных категорий.
Учитываются именно все четыре метрики. К примеру, в нижнюю категорию попадает даже клиент, который потратил много денег при какой-то транзакции. То есть человек, который совершил одну-две очень крупные покупки, но остальные метрики у него проседают, поскольку он очень редко использовал свою банковскую карту.
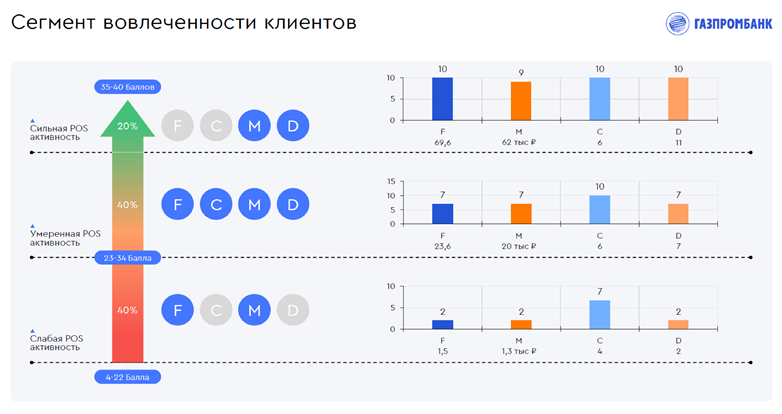
Таким образом можно понять, какие клиенты много совершают транзакций и часто, какие — редко.
Также с помощью таких метрик (скорбаллов) можно определять, что происходит с нашей клиентской базой за определённый период времени, например за полгода. Понять, какая часть клиентов улучшила свою позицию по скорбаллам, какая ухудшила или сохранила свой статус.
Анализируя скорбаллы, мы можем понять, как лучше работать с разными группами клиентов. Например, отправлять предложения со скидками или промоакцией самым давним клиентам, покупателям, совершающим транзакции лишь в одной-двух категориях, или даже клиентам, которые давно не совершали покупок (кампания по возвращению клиентов).
С помощью FMCD-анализа можно сократить объём выдаваемых скидок и бонусов. Тем, кто постоянно покупает, необязательно предлагать дополнительные скидки, а «уснувшим клиентам» они помогут вернуться к покупкам.
Такая информация может быть полезна, чтобы понять, в какую рассылку должны попасть конкретные клиенты. Если какая-то часть клиентов снижает свою POS-активность, их метрики «сползают» вниз, то их надо включать в маркетинговую кампанию и начать с ними общаться.
Для того чтобы стимулировать клиента к переходу в более высокую группу по скорбаллам (в следующий бакет), определяем значение потенциала. Он рассчитывается из дискретной разницы и линейного коэффициента, указывающего на тренд в бакетах. Очередная цель рассчитывается как:
Целевое значение = Текущее значение + Потенциал.
То есть при достижении клиентом потенциала он переходит из низкого бакета в более высокий.
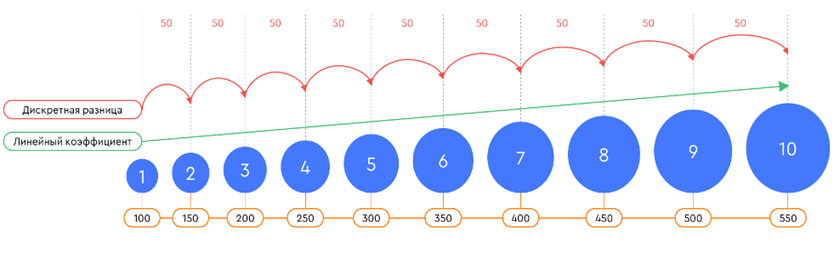
Переход в группу с более высоким скоринговым баллом означает, что в дальнейшем с таким клиентом можно будет работать по-другому, например, он будет получать рассылку определённого типа.
Для того чтобы сегментирование клиентов и FMCD-анализ были ценными для бизнеса в целом, они должны помогать принимать решения, способствующие достижению результатов. Сама по себе деятельность по группировке показателей ничего не стоит. Ценность представляют решения, принимаемые при создании кампаний.
Наша модель также позволяет рассчитать прогноз нетривиальной категории, в которой клиент с большей вероятностью совершит транзакции. Нетривиальная категория обозначает, что в ней клиент ещё не совершал транзакций за последние три месяца.
Мы используем здесь методологию Market Basket Analysis, которая широко применяется для анализа данных о транзакциях и предназначена для выявления сильных правил, обнаруженных в таких данных, с помощью показателей интересности.
Для поиска частых элементов и ассоциативных применяем алгоритм Apriori из библиотеки Arules. Алгоритм использует поуровневый поиск частых элементов. Ассоциативные правила — это правила вида «если делается это, то будет делаться и то». Например, «если клиент купил тёплую куртку, то он купит и зимние ботинки». Проанализировав все транзакции клиента с помощью такого алгоритма, можно спрогнозировать возможные POS-активности, определить категорию, в которой он с большей вероятностью совершит покупку.
Расчёт ведётся по формуле, по которой определяются ассоциативные правила:
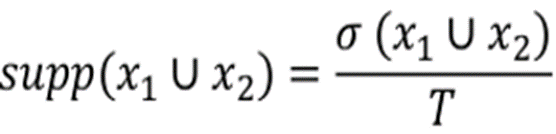
где:
Supp (поддержка) — это показатель частотности, то есть насколько часто встречается какой-то itemset (в данном случае категория) в корзине в чеках клиентов.
T — общее количество транзакций.
Когда мы оцениваем клиентские корзины, клиенты со схожим поведением попадают в одну группу. И если у какого-то клиента из такой группы ещё нет покупок в какой-то категории, а у других людей со схожим поведением они есть, то такой клиент с большой долей вероятности скоро проведёт там транзакцию.
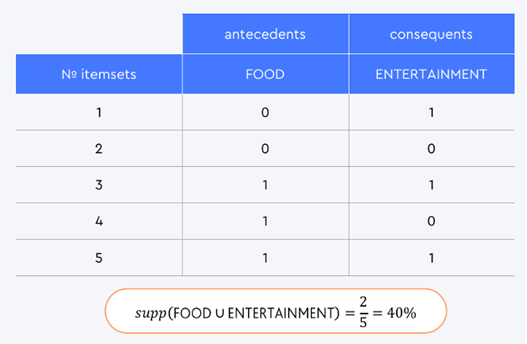
Возьмём для простого примера две уникальные категории — Food и Entertainment.
Если мы хотим определить показатель частотности, то в числитель добавляем сумму чеков, где есть обе категории. Таких чеков два (3 и 5), всего чеков — 5. В результате мы видим, в 40 % чеков эти две категории присутствуют вместе.
Имея эти данные, можно теперь рассчитать показатель Confidence (достоверность). Это показатель того, как часто это правило срабатывает для всего набора данных:
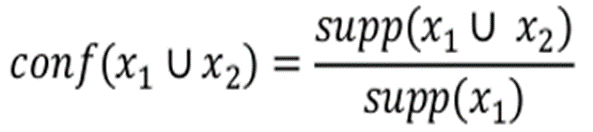
Для правила «кто тратится в категории Food, тот покупает и в категории Entertainment», чтобы узнать значение Confidence, мы в числитель помещаем 2/5, а в знаменатель — показатель Support только для категории Food. Он равен 3/5, поскольку покупки в этой категории отмечены в трёх чеках из пяти.
Поделив одно на другое, получаем:

Мы видим, что из трёх чеков, в которых клиенты совершали транзакции в категории Food, в двух чеках также клиенты совершили транзакции и в Entertainment. То есть мы говорим о том, что с большей вероятностью клиенты в категории Food также совершат транзакцию и в Entertainment. И при очередной рассылке это можно учесть.
Всего мы прогнозируем три нетривиальные категории транзакций, три уровня. И соответственно при запуске кампании учитываем все эти три уровня.
Сложности при реализации модели
За всё это время мы столкнулись с рядом сложностей и достаточно быстро с ними справились. Например, при программировании модуля, который реализует прогнозирование нетривиальных категорий, мы поняли, что написанный нами код отрабатывает задачу за трое суток. После этого код был оптимизирован, заменили строковые значения на бинарные, а вместо сравнений множеств в Python использовали более простые операции действия. В итоге теперь код отрабатывает задачу за сутки.
Были и технические проблемы с кодом на Python, поскольку обрабатывается очень большая база данных, а система позволяет распараллеливать обработку только процессами, а не потоками. Приходилось учитывать также различные нюансы — проверки, возвратные транзакции и тому подобное.
В итоге мы пришли к тому, что вычислительная мощность всего алгоритма составляет приблизительно сутки.
Были сложности, связанные с бизнесом, за счёт чего алгоритм за год претерпел ряд изменений. Это вполне понятно, поскольку коллегам со стороны бизнеса всё время хочется усовершенствовать систему, например, изменить сегментацию клиентов. При этом трудности с сегментацией были ещё связаны и с отсутствием общебанковских продуктовых словарей. Впрочем, эта задача скоро будет решена.
Уже при выводе в промышленную эксплуатацию нашей модели мы столкнулись с проблемой, что тикет, который работает для подключения к базе данных, отключался через 24 часа. Пришлось ввести поправки в код, чтобы этот тикет функционировал дольше. Кроме того, нам потребовались большие мощности для разработки и работы модели, что вызвало ряд вопросов у наших айтишников. Для запуска модели и расчёта, с тем чтобы она отрабатывала за сутки, нам потребовалось запускать 16 ядер и 150 Гбайт оперативной памяти. При этом, используя библиотеку Dask, мы распараллеливали процесс и ускоряли расчёт.
В итоге примерно в течение года алгоритм отрабатывался как MVP (минимально жизнеспособный продукт), после чего недавно был выведен в промышленную эксплуатацию. И сейчас запуск кампаний по модели FMCD поставлен на поток и каждый месяц запускаются какие-нибудь маркетинговые акции.
Результаты и ближайшее будущее
В целом можно утверждать, что разработанная нами модель уже сегодня помогает уменьшать отток клиентов и повышать их лояльность. Но мы продолжаем разрабатывать дальнейшие усовершенствования.
В дальнейшем мы также планируем ввести кластеризацию MCC-кодов для определения групп клиентов со сложными тратами и заменить алгоритм Apriori на более быстрый, в частности, на ECLAT. Этот алгоритм, в отличие от Apriori, не сканирует весь гигантский набор данных (поиск в ширину), а производит поиск в глубину.
Сейчас FMCD рассчитывается ежемесячно, но мы хотим перейти на еженедельные расчёты. Актуальная информация — актуальное прогнозирование.
Помимо группировки категорий транзакций клиентов, планируется внедрение категорий магазинов, в которых совершались транзакции, с градацией от наименее до наиболее популярных, а также расчёт среднего чека и времени с последней покупки. Кроме того, предполагается разработка механики для отслеживания задолженности по кредитным картам.
Чем лучше мы определяем, как ведёт себя клиент, тем эффективнее наше с ним взаимодействие. И несмотря на, понятное дело, коммерческий подход, можно сказать, это про взаимность — ведь выигрывают обе стороны.
