
От переводчика: Для этой статьи, вероятно, подошел бы заголовок "Незнание значений по умолчанию не освобождает от ответственности". Перед нами классический пример "эффекта швейцарского сыра", когда несколько мелочей приводят к сбоям, интересным и долгим расследованиям и героическому преодолению трудностей.
Сайт мониторинга ситуации по коронавирусу Соединенного Королевства - основной сервис отчетности во время пандемии COVID-19 для всей страны. Он испытывает нагрузку порядка 45–50 миллионов запросов в день и относится к национальным сервисам критической важности.
Мы работаем в соответствии с архитектурой active-active, что значит, у нас есть минимум две, часто - три экземпляра каждого сервиса, которые запущены в разных географических локациях.
Есть только одно исключение - наша база данных. Сервис работает с использованием специальной версии PostgreSQL: Hyperscale Citus. Тот факт, что наша база данных не соответствует архитектуре active-active — это не следствие того, что мы не знаем, как делать реплики для чтения, скорее - результат логистических проблем, обсуждение которых выходит за рамки этой статьи.
Тем не менее, база данных работает в высокодоступной экосистеме, где сбойный экземпляр может быть заменен в течение пары минут.
Замечательное обновление
СУБД PostgreSQL 14 была официально выпущена 30 сентября 2021 года. Помимо всего остального, новая версия предлагала расширенную модель безопасности и прирост производительности запросов к сегментированным таблицам.
Мы очень радовались этому факту, хотя, в силу того, что у нас был полностью облачный сервис СУБД, мы думали, что мы не сможем обновить нашу БД до весны 2022 года, самое раннее.
Но благодаря отличной работе команды Azure Postgres, наши ощущения оказались ложными и новое обновление стало доступным для облачных СУБД в Azure в течение 24 часов.
Это было огромное достижение команды Azure Postgres - новая веха в поддержке облачных сервисов баз данных. И это обновление оказалось даже лучше, чем мы ожидали, потому что оно также предлагало новую версию модуля Citus 10. В этой версии было исправлено несколько багов, которые мы нашли в предыдущем релизе.
Вместе с командой Azure Postgres (Citus), мы развернули новую версию нашего окружения для разработки вечером в среду, 13 октября 2021. Все прошло очень гладко, мы наблюдали за всем в течение 48 часов и сделали несколько нагрузочных тестов перед тем, как запустить развертывание на промышленное окружение в полночь субботы, 16 октября, 2021. Процесс развертывания закончился около 11 утра в субботу без проблем.
Все было прекрасно и пахло розами.
Что ещё произошло?
На следующей после обновления неделе мы сделали несколько изменений в сервисе:
Выпустили сводку по данным о бустерных вакцинах.
Выпустили новую версию страницы с итогами, сделанную на F#.
Второе обновление было нацелено на:
уменьшение зависимости от БД;
уменьшение времени ответа во время пиковой нагрузки;
использование Redis для дорогостоящих запросов;
использование решения из нашего ETL для предварительного заполнения кэша
Неделя перед судной ночью
До конца недели мне в Твиттере написали несколько человек и сообщили, о росте количества ошибок в запросах ко второй версии API (APIv2).
Самое странное, что они говорили, это то, что было невозможно скачать новые данные через API после релиза, т. е. в 4 вечера.
Первое, что я делаю в таких случаях - проверяю сервис API и наши экземпляры PGBouncer, чтобы убедится, что с ними все в порядке. Затем я обычно очищаю кэш данных для APIv2, и это обычно решает проблему.
Количество жалоб ко мне в Твиттере увеличилось. Люди теперь жаловались на увеличивающиеся задержки при использовании нашего GenericAPI. Это беспокоило меня, потому что, в отличие от APIv2, который мы активно замедляем и который предназначен для загрузок очень больших объемов данных, Generic API был написан на Go и использует сильно оптимизированные запросы для быстрого ответа. В то время, как загрузка данных через APIv2 может занять 3 или 4 минуты, средняя задержка ответа для GenericAPI – 30–50 миллисекунд.
Я ещё раз проверил инфраструктуру и даже откатил несколько изменений Generic API, чтобы убедиться, что это ошибка не из-за этих недавних, хотя и небольших, изменений. Но нет.
Катастрофический выходной
В воскресенье, 31 октября 2021 года, у нас случился критический отказ: все наши ETL процессы завершались с ошибкой, мы не могли загрузить новые данные в базу. Причина? Ошибка соединения или невозможность поддержки соединения с базой данных.
Я подчеркивал ранее, что все соединения с БД происходят через пул соединений (PGBouncer), который развернут на двух мощных виртуальных машинах с 64 Гб памяти и 16 процессорными ядрами (Standard D16 v4), которые управлялись с использованием Azure VM Scale Set.
Почему мы используем PGBouncer?
По сути, база данных предоставляет ограниченное число одновременных соединений. Можно поменять или увеличить это число, но тут есть издержки. Чем больше соединений, тем больше памяти расходуется. В Postgres каждое соединение использует примерно 10 Мб памяти. Это также означает, что можно запустить больше одновременно работающих процессов, что, в свою очередь, требует ещё больше ресурсов для выполнения.
В большинстве случаев соединения с БД не нужно поддерживать, они нужны только на время выборки данных и ожидания ответа. Однако, приложения стремятся забирать соединения навсегда.
PGBouncer, да и в целом пулы соединений, смягчают ситуацию тем, что они постоянно поддерживают фиксированное число соединений к БД (986 в нашем случае) и предоставляют короткоживущие соединения их клиентским приложениям, а затем возвращают результат запроса клиенту. Короче говоря, 986 соединений превращаются в 5000.
Как долго поддерживается соединение между клиентом и PGBouncer? Это зависит от настроек, но в нашем случае оно поддерживается для одной транзакции.
Я только недавно включил ускоренное сетевое соединение для экземпляров PGBouncer, так что у них не было причины падать, но, тем не менее они показывались как “сбойные”
Проверка состояния для PGBouncer сделана в виде пинга Postgres. Это означает, что (помимо исчерпания ресурсов процессора или памяти), есть только одна причина для того, чтобы они сбоили: проблема с СУБД.
Естественно, следующий шаг, который я сделал - проверка базы данных. И вот что я увидел:
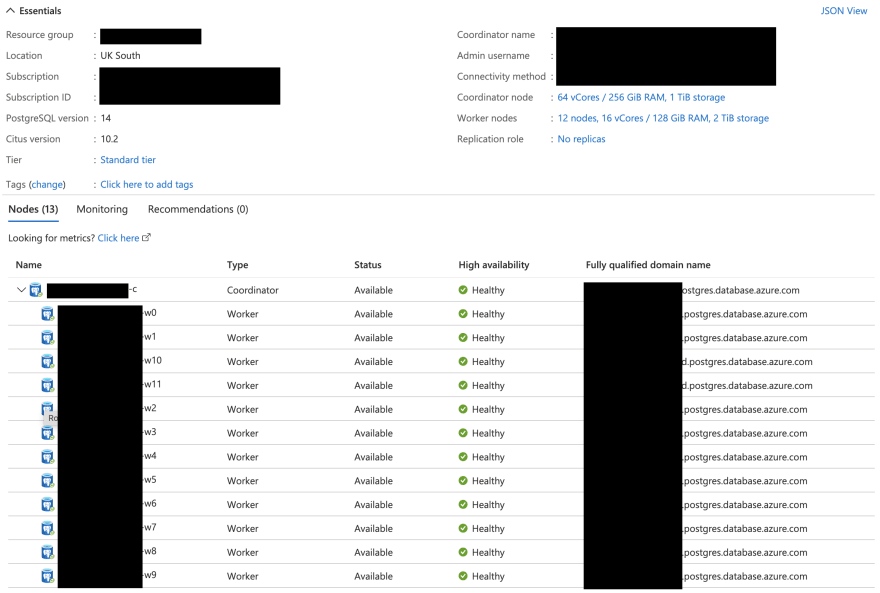
Все было в порядке 🤯 !
Но так не могло быть, и нужно было копать глубже. Единственной проблемой было то, что сейчас 12:45, середина дня, а мы ещё не загрузили данные. Время было на исходе...
Затем я проверил количество соединений:
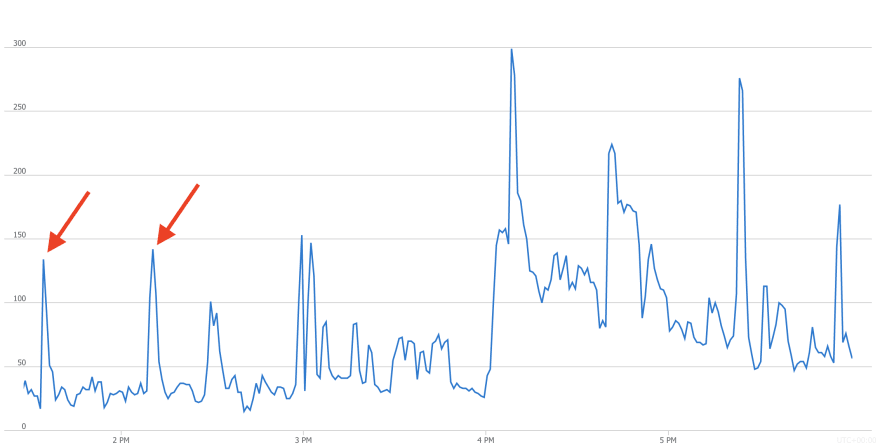
ОК, тут все было нормально... за исключением пиков, отмеченных красными стрелками. Они коррелировали с нашими попытками загрузки данных. Это было странно, потому что нам никогда не требовалось 150 соединений для загрузки. Обычно было достаточно 30 или 40.
Затем я проверил процессор... и вот тогда я понял настоящий смысл Хэллоуина 👻 :
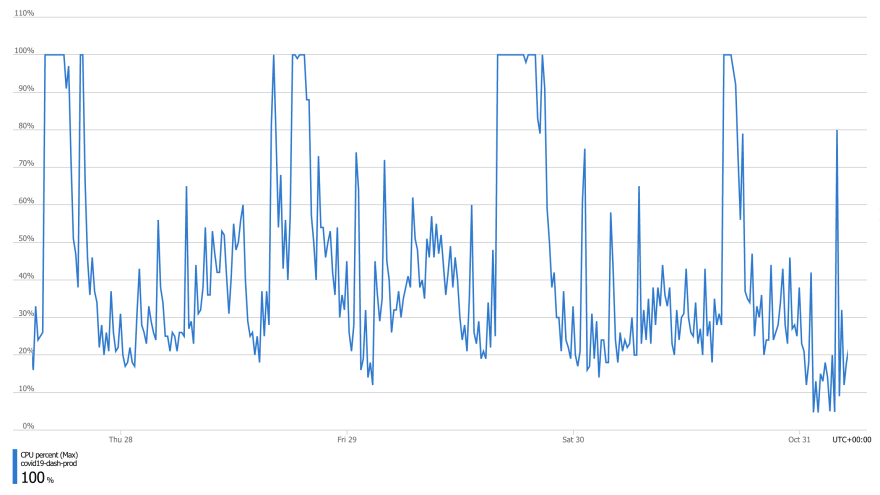
Это не могло произойти. Не на этом сервере. Но это произошло!
Я оповестил команду Azure Postgres, но они, в основном, находились в США и это все происходило в воскресенье. И не просто в воскресенье, а в Хэллоуин 🎃 . Напоминаю, что это не служба поддержки Azure, это команда разработчиков этого сервиса, и ребята, которых я знаю, не должны быть на связи 24/7.
У меня не было времени что-то предпринять в тот момент, было уже 14:50, все что я знал - нужно было, очевидно, уменьшить нагрузку на БД, чтобы иметь возможность загрузить данные. Всё, о чем я мог думать - принудительно уменьшить количество соединений к БД, так что я выключил 70% наших серверов. Это сработало, и мы смогли завершить загрузку первой порции данных в 15:08. Мы еле-еле успели загрузить все к 15:58, я включил все серверы, и мы опубликовали данные в 16:01.
Но всё было далеко от завершения
А потом мы испытали значительное ухудшение работы APIv1. Эта проблема стала очень критичной. APIv1 это наш интерфейс Open Data. Это то, с помощью чего мы показываем данные на нашем вебсайте и этот API интенсивно используется разными организациями от местных служб до министерства здравоохранения, кабинета премьер-министра, ВОЗ и университета Хопкинса. Проблемы с API стали заметными к 16:30, в воскресенье, 31 октября 2021 года.
Важно рассмотреть это в перспективе. Большинство сообщений, которые я получал, были о проблемах во время публикации данных. Затем, после публикации мы испытали моментальный взлет количества запросов. Вот как выглядел трафик во время релиза:

Это означает, что возможны редкие ошибки то тут, то там, но не для 50% запросов, как это было 31 октября:

Была ещё одна интересная закономерность. Посмотрите на участок графика, отмеченный серой стрелкой. Это тот момент, когда 70% серверов было выключено и количество необслуженных запросов уменьшилось! Но этого не может быть. У нас большое количество доступных соединений, у нас они просто не могли закончиться. Хорошо, это не было пиковой загрузкой, и мы все равно не использовали все серверы. Но все равно, как могло упасть количество ошибок, если мы уменьшили вычислительные мощности на 70%?
Почему уменьшилось количество ошибок?
И тут все стало ещё сложнее.
После напряженного расследования и замеров производительности оказалось, что наши запросы стали выполняться гораздо медленнее.
Пример: хорошо оптимизированный, протестированный запрос из нашего Generic API, который при нормальных условиях должен выполняться 1.5 миллисекунды:
SELECT
area_code AS "areaCode",
area_name AS "areaName",
ar.area_type AS "areaType"
FROM covid19.area_reference AS ar
WHERE LOWER(area_type) = LOWER('region')
AND area_name ILIKE 'London'
LIMIT 1 OFFSET 0;Я запустил анализ запроса:
EXPLAIN (ANALYZE, BUFFERS)
SELECT
area_code AS "areaCode",
area_name AS "areaName",
ar.area_type AS "areaType"
FROM covid19.area_reference AS ar
WHERE LOWER(area_type) = LOWER('region')
AND area_name ILIKE 'London'
LIMIT 1 OFFSET 0;И результат был:
...
Buffers: shared hit=5
Planning Time: 0.119 ms
Execution Time: 57.190 msЭто заняло ~57 миллисекунд! Как это возможно? Падение производительности примерно в 40 раз.
Затем я проверил активности в БД и посмотрел, какие запросы выполняются и как долго:
SELECT usename,
state,
query,
state_change - query_start AS time_lapsed
FROM pg_stat_activity;Нашлось 140 запросов, но больше половины из них содержали это:
WITH RECURSIVE typeinfo_tree(
oid, ns, name, kind, basetype, elemtype, elemdelim,
range_subtype, attrtypoids, attrnames, depth)
AS (
SELECT
ti.oid, ti.ns, ti.name, ti.kind, ti.basetype,
ti.elemtype, ti.elemdelim, ti.range_subtype,
ti.attrtypoids, ti.attrnames, 0
FROM
(...Эти запросы показывались как IDLE, и величина параметра time_lapsed между запуском запроса и изменением состояния была достаточно значительной.
Последующее расследование показало, что этот запрос выполнялся asyncpg, API драйвера, который мы используем в нашем Python коде для выполнения асинхронных операций с Postgres.
В ходе дальнейших исследований выяснилось, что эта проблема уже была замечена в сообществе:
В процессе обсуждении тикета оказалось, что проблема связана с настройкой, которая включала JIT (Just-In-Time compilation) и она была включена по умолчанию для Postgres 14, когда СУБД была скомпилирована с использованием LLVM.
Я нашел это примерно в 23:40 в понедельник, 1 ноября после обсуждений, которые у меня были ранее, примерно в 21:30 с командой Azure Postgres (Citus), где JIT упоминался как возможная причина.
Я все ещё не верил в то, что причина найдена, но затем получил сообщение команды Citus, в котором говорилось, что после тщательного расследования было установлено, что проблема именно во включенном JIT. Самое интересное, что мне прислали ссылку на то же обсуждение в GitHub.
У нас была гипотеза и, очевидно, нужно было ее проверить. Они выслали мне довольно объемный запрос, который нужно было запустить и проверить результат:
Planning Time: 3.283 ms
JIT:
Functions: 147
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 17.460 ms, Inlining 15.796 ms, Optimization 525.188 ms, Emission 350.897 ms, Total 909.340 ms
Execution Time: 911.799 ms
Отлично, теперь у нас есть тест производительности. Но посмотрите ещё раз, у нас также была проблема, которая показала себя:
JIT:
Functions: 147
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 17.460 ms, Inlining 15.796 ms, Optimization 525.188 ms, Emission 350.897ms, Total 909.340 ms
JIT оптимизация выполнялась 909.340 миллисекунд !
Время выключить JIT - сейчас 00:20, это отличное время для эксперимента:

В 00:22 мы запустили запрос снова и вот что увидели:
Planning Time: 3.159 ms
Execution Time: 0.409 msИ вот так вот просто время выполнения уменьшилось в 2,229 раз?
На следующий день мы увидели значительное уменьшение потребления процессора в Postgres. Вертикальная линия на графике отмечает время 00:22, точку, когда мы выключили JIT.
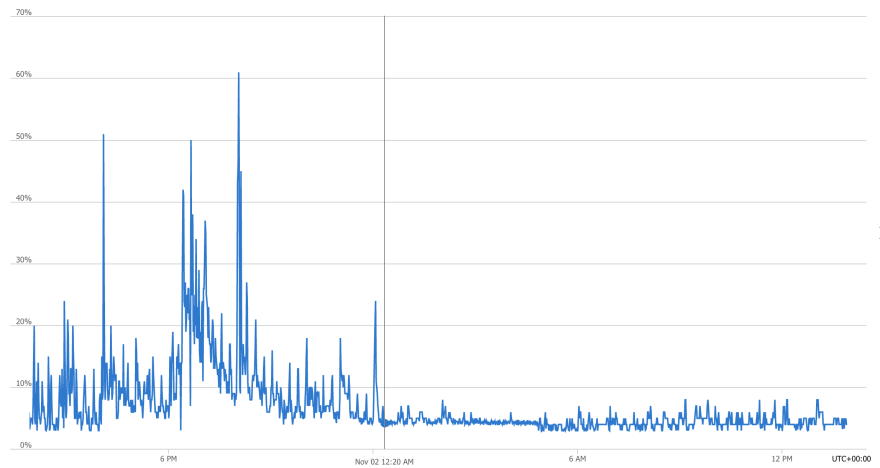
Проблема решена! 🎉
Итоговые соображения
Проблемы вроде этой достаточно сложно идентифицировать, потому что они проявляются как каскад ошибок, по следам которых надо пройти. И даже тогда необходимо поработать детективом и исследователем, чтобы дойти до сути.
JIT в Postgres
JIT компиляция - полезная вещь, вопросов нет. Однако, это не та функциональность, которая должна быть включена по умолчанию. JIT компиляция должна использоваться только в сценариях, подобных этим:
Процессы, которые выполняют аналитические вычисления или работают по столбцам таблицы - и для всей таблицы.
Запросы, которые долго выполняются без JIT, и:
Запросы, которые не вызываются постоянно
Это работает так же, как и JIT компиляторы в Python или .NET, которые оптимизируют код для более быстрого исполнения. Они исключительно полезны для приложений, которые работают в течение продолжительного времени. Компиляторы уменьшают стоимость исполнения приложений, а пользователи ждут ответа меньше.
В этом случае преимущества значительны, потому что дополнительные накладные расходы незаметны после фазы старта приложения, во время которой JIT процесс выполняет компиляцию.
Однако, это не годится для случая, когда мы выполняем короткие, хорошо оптимизированные запросы к БД десятки, если не сотни раз в секунду - особенно, если мы делаем компиляцию каждый раз, когда нам приходит этот запрос. Это не создало бы никаких проблем, если бы скомпилированные запросы кэшировались, но на текущий момент это не так.
Кэш таких запросов мог бы хранить бинарные данные и в качестве ключа использовать хэш от строки запроса. Время жизни (TTL) кэша можно было бы сделать настраиваемым с длительностью по умолчанию что-то вроде 5 минут. Однако, нужно признать, что в команде разработчиков ядра PostgreSQL работают весьма умные и компетентные инженеры, которые знают, что они делают и которые наверняка подумали о кэшировании скомпилированных запросов. Так что я остаюсь с верой в то, что этот подход не был реализован по каким-то причинам, о которых мы не догадываемся.
Пороги срабатывания
Игра с порогами срабатывания JIT на основе стоимости транзакций, по-моему, окажет не слишком большое воздействие - не в том случае, когда у вас есть огромная, но адекватно индексированная БД.
Обратное давление
Ещё одна проблема здесь - давление событий. Когда оптимизированный запрос, который должен выполняться 1 миллисекунду, выполняется 5 секунд - возможно из-за того, что в нем есть рекурсивное выражение общей таблицы (common table expression, CTE) - процессор БД остается загруженным. JIT компиляция потребляет много процессорного времени, и процессор не может обработать большое количество таких запросов.
Это значит, что другие запросы, возможно, даже идентичные этим (счет которых может идти на сотни), остановлены и ожидают своей очереди на выполнение, пополняя список отложенных задач.
Это запускает цепь событий, или, как я это называю - роковой каскад. В итоге мы получаем много мелких процессов, выжирающих процессор или ожидающих JIT компиляции:
Что приводит к увеличению времени ответа
Что может привести к срабатыванию порога таймаута в клиентском приложении
Что приводит к ошибкам в запросах
Что приводит к тому, что экземпляр приложения рапортует, что он сломан
Что приводит к созданию нового экземпляра и запуску процесса масштабирования
Что приводит к увеличению количества соединений к БД
Что добавляет давления на БД
...и дальше вы уже все видели.
Как мы узнаем, что JIT полезен?
Нет эталонного процесса, которому надо следовать, это сильно зависит от приложения. Хороший способ определения полезности, тем не менее, остается включение JIT для определенных транзакций и проведение тестов производительности:
BEGIN;
SET LOCAL jit = ON;
EXPLAIN (BUFFERS, ANALYSE)
-- The query
;
COMMIT;Нужно заметить, что наш запрос слишком простой и попадает в категорию ниже порога срабатывания `jit_above_cost` и процесс может не запуститься. Можно временно уменьшить порог, чтобы это предотвратить.
Давайте потестируем запрос к нашей БД в качестве примера.
Без JIT:
EXPLAIN (BUFFERS, ANALYSE)
SELECT metric,
area_code,
MAX(area_name) AS area_name,
percentile_cont(.25) WITHIN GROUP (ORDER BY (ts.payload ->> 'value')::FLOAT) AS first_quantile,
percentile_cont(.5) WITHIN GROUP (ORDER BY (ts.payload ->> 'value')::FLOAT) AS median,
percentile_cont(.75) WITHIN GROUP (ORDER BY (ts.payload ->> 'value')::FLOAT) AS third_quantile
FROM covid19.time_series AS ts
JOIN covid19.area_reference AS ar ON ar.id = ts.area_id
JOIN covid19.metric_reference AS mr ON mr.id = ts.metric_id
WHERE ts.date BETWEEN '2021-08-05' AND '2021-11-05'
AND ts.partition_id = '2021_11_10|ltla'
AND NOT (metric ILIKE '%direction%' OR metric ILIKE '%demog%')
GROUP BY metric, area_code
ORDER BY median DESC;
QUERY PLAN
Planning:
Buffers: shared hit=29
Planning Time: 2.163 ms
Execution Time: 13024.737 msА теперь с JIT:
BEGIN;
SET LOCAL jit = ON;
SET LOCAL jit_above_cost = 10;
EXPLAIN (BUFFERS, ANALYSE)
SELECT metric,
area_code,
MAX(area_name) AS area_name,
percentile_cont(.25) WITHIN GROUP (ORDER BY (ts.payload ->> 'value')::FLOAT) AS first_quantile,
percentile_cont(.5) WITHIN GROUP (ORDER BY (ts.payload ->> 'value')::FLOAT) AS median,
percentile_cont(.75) WITHIN GROUP (ORDER BY (ts.payload ->> 'value')::FLOAT) AS third_quantile
FROM covid19.time_series AS ts
JOIN covid19.area_reference AS ar ON ar.id = ts.area_id
JOIN covid19.metric_reference AS mr ON mr.id = ts.metric_id
WHERE ts.date BETWEEN '2021-08-05' AND '2021-11-05'
AND ts.partition_id = '2021_11_10|ltla'
AND NOT (metric ILIKE '%direction%' OR metric ILIKE '%demog%')
GROUP BY metric, area_code
ORDER BY median DESC;
COMMIT;
QUERY PLAN
Planning:
Buffers: shared hit=29
Planning Time: 2.090 ms
JIT:
Functions: 8
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 1.471 ms, Inlining 0.000 ms, Optimization 0.485 ms, Emission 6.421 ms, Total 8.377 ms
Execution Time: 12750.490 ms
Как можно видеть, несмотря на накладные расходы, время выполнения меньше, хотя и ненамного.
Простого ответа нет
Мы все с радостью используем универсальные решения, но, к несчастью, таких вещей в области высокопроизводительных решений не существует.
Глядя со стороны, кажется, что легко предложить общее решение для любой проблемы; тем не менее, доказать, было ли это решение полезным, можно только через детальное тестирование конкретного продукта.
В результате вышеописанного инцидента команда Postgres из Microsoft Azure приняла решение изменить настройки по умолчанию для Posgtres 14 и выключить JIT для новых экземпляров сервиса.
Благодарности
В конце я хочу поблагодарить команду Azure Postgres (Hyperscale) за их вовлеченность, самоотдачу и поддержку днем, ночью и глубокой ночью!
(От переводчика) P.S. Когда речь идет о разработке программного обеспечения для создания корпоративного ПО, значения по умолчанию - важная часть продукта. Парадокс: пользователь ничего не делает и даже может не знать о существовании настройки, ее может не быть в конфигурационных файлах, а она внезапно меняется в новой версии и все перестает работать. Поэтому упоминание изменения значения параметра по умолчанию в новой версии - важная часть release notes, а миграция на новую версию должна это учитывать и создавать явные конфигурации с предыдущим значением параметра. В Jmix всегда так делаем :-)
