Привет, Хабр!

В прошлой статье я рассказал о новой версии образовательного проекта Хекслет. В голосовании вы решили, что следующая статья будет о технической реализации платформы.
Напомню, Хекслет — это платформа для создания практических уроков по программированию в настоящей среде разработки. Под настоящей средой разработки мы подразумеваем полноценную машину, подключенную к сети. Эта важная деталь отличает Хекслет от других образовательных проектов (например, Codecademy или CodeSchool) — у нас нет симуляторов, все по-настоящему. Это позволяет обучать и обучаться не только программированию, но и работе с базами данных, серверами, сетью, фреймворками и так далее. В целом, если это запускается на Unix-машине — этому можно обучать на Хекслете. При этом, понимая это или нет, пользователи используют Test-Driven Development (TDD), потому что их решения проверяются юнит-тестами.
В этом посте я расскажу про архитектуру платформы Хекслет и инструменты, которые мы используем. О том, как на этой платформе создавать практически уроки — в следующей статье.

Почти весь бэкэнд написан на Rails. Все работает на Amazon Web Services (AWS). Изначально мы старались сильно не привязываться к инфраструктуре AWS, но постепенно стали использовать больше их сервисов. В RDS (Relational Database Service) крутится PostgreSQL (основная база) и Redis. Благодаря нему нам можно не волноваться о бэкапах, репликации, обновлении — все работает автоматически. Так же в RDS мы используем автоматический failover – multiAZ. В случае падения основной машины, автоматически поднимается синхронная replica в другой зоне доступности, и в течение пары минут происходит привязка DNS-записи к новому IP-адресу.
SQS (Simple Queue Service) для построения очередей. Вся почта отправляется через SES, домены живут в Route53. Amazon Simple Notification Service (SNS) шлет в нашу SQS-очередь сообщения о статусе доставки писем. Картинки и файлы хранятся в S3. С недавнего времени используем Cloudfront, CDN от Амазона.
Краеугольный камень всей платформы — Докер.
Каждый сервис у нас работает в своем контейнере. Один контейнер = один сервис. Большинство образов для контейнеров это готовые образы из tutum.co. Репозиторий для своего приложения мы храним в Docker Registry. Для стейджинга образ собирается автоматически при коммите в Dockerfile. Сам код хранится в Github. Для продакшена мы собираем образы через Ansible на отдельном сервере. Билд занимает значительное время, 20-60 минут в зависимости от условий, поэтому вариант «по-быстрому пофиксим продакшен» невозможен. Но оказалось это не проблема, наоборот – дисциплинирует. Когда что-то идет не так при деплое на продакшен, мы просто убиваем один контейнер и предыдущий. Наша база растет только горизонтально (что типично для проектов с, кхм-кхм, хорошей архитектурой), что позволяет использовать базу с разными версиями кода и не получать конфликтов. Поэтому откат это почти всегда простая замена версии кода.
В первое время для деплоя мы использования Capistrano, но в итоге отказались от нее в пользу Ansible. Немного не привычно, но Ansible просто доставляет конфиги на удаленный сервер и запускает upstart, а тот в свою очередь уже обновляет образы. В такой схеме нам не нужно устанавливать на сервера ничего специального, для Ansible нужен только ssh-доступ. Для версионирования используются теги (v64, v65 и так далее), а деплой на стейджинг всегда использует самую последнюю версию (latest) кода.
Кстати, мы так любим Ansible, что сделали по нему практический курс — «Ansible: Введение».

Большой плюс — локально при разработке мы используем почти идентичные Ansible playbooks, что и для продакшена. Так что инфрастуктура обкатывается локально, насколько это возможно, что минимизирует ошибки типа «а на локалке работало». В итоге процесс деплоя выглядит так: новый коммит в Dockerfile в гитхабе -> запуск нового билда в docker registry -> запуск плейбука Ansible -> обновленные конфиги на сервере -> запуск upstart -> получение новых образов.
Мы также используем амазоновский балансировщик, и в случае хабраэффекта за 10-20 минут можем поднять дополнительные машины. Важное условие такой схемы — конечные веб-серверы не хранят состояния (stateless), на них не сохраняется никаких данных. Это позволяет быстро масштабироваться.
Амазон мы тоже любим, про Route53 (менеджмент доменов/DNS) и про балансировщик у нас есть уроки в цикле «Распределенные системы».
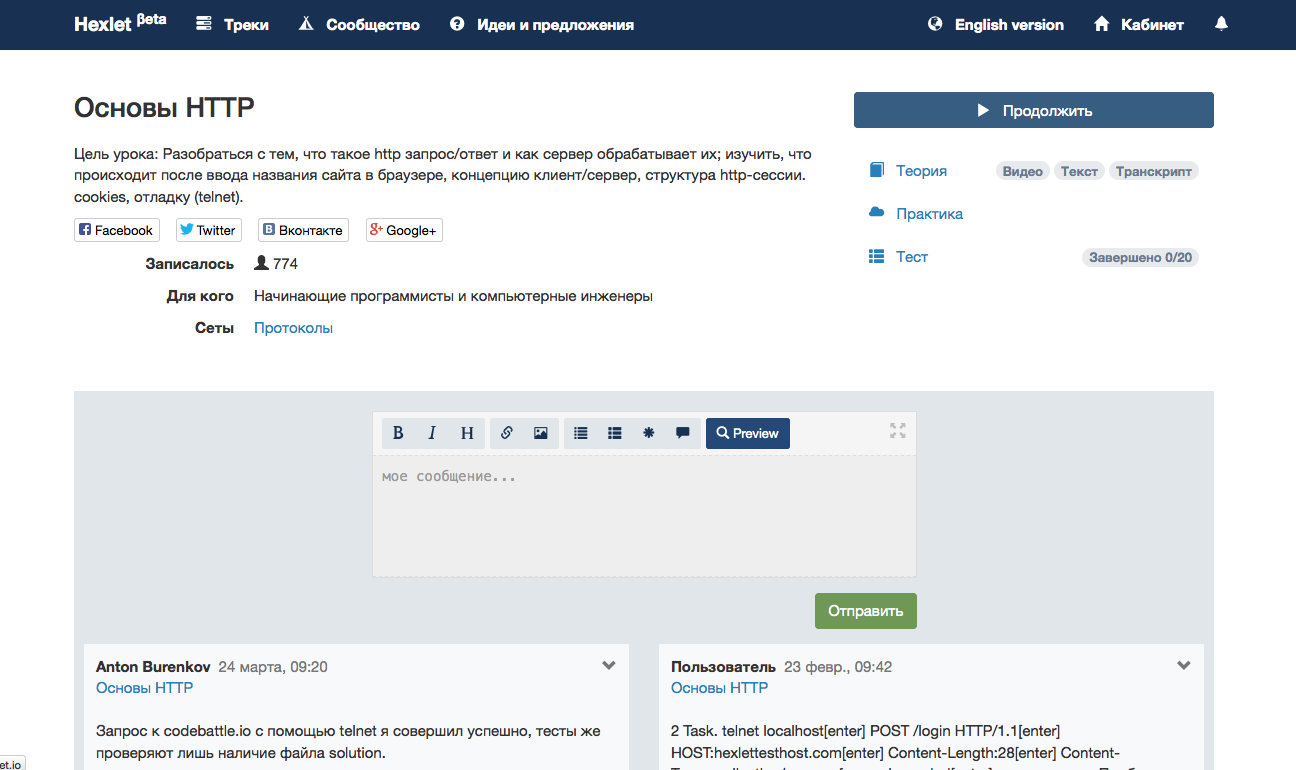
Страница популярного урока.
Суть проекта — позволять людям учиться в реальном окружении, для этого каждому юзеру мы поднимаем контейнер, в котором он выполняет практическое упражнение. Эти контейнеры поднимаются на специальном «eval»-сервере. На нем есть только Докер и обращаться к нему можно только из Shoryuken, асинхронно.
В первых прототипах Хекслета система требовала от пользователей работать над практическими заданиями на своих компьютерах, но сейчас вся работа происходит в браузере, скачивать и устанавливать ничего не нужно. Для этого нам понадобилась браузерная среда разработки, которая позволила бы юзерам редактировать файлы и запускать программы. Существует много облачных IDE, и мы, как любой уважающий себя стартап, хотели по максимуму использовать готовые решения. Нашли классный IDE с кучей функций (даже с интеграцией с Git), но потом оценили стоимость поддержания чужого кода (полного изобретенных велосипедов) и решились писать свой простой IDE. Здесь нас спасла еще одна новая технология — ReactJS и концепция Flux. Пару недель назад вышла новая версия Hexlet IDE с кучей функциональных и визуальных улучшений.
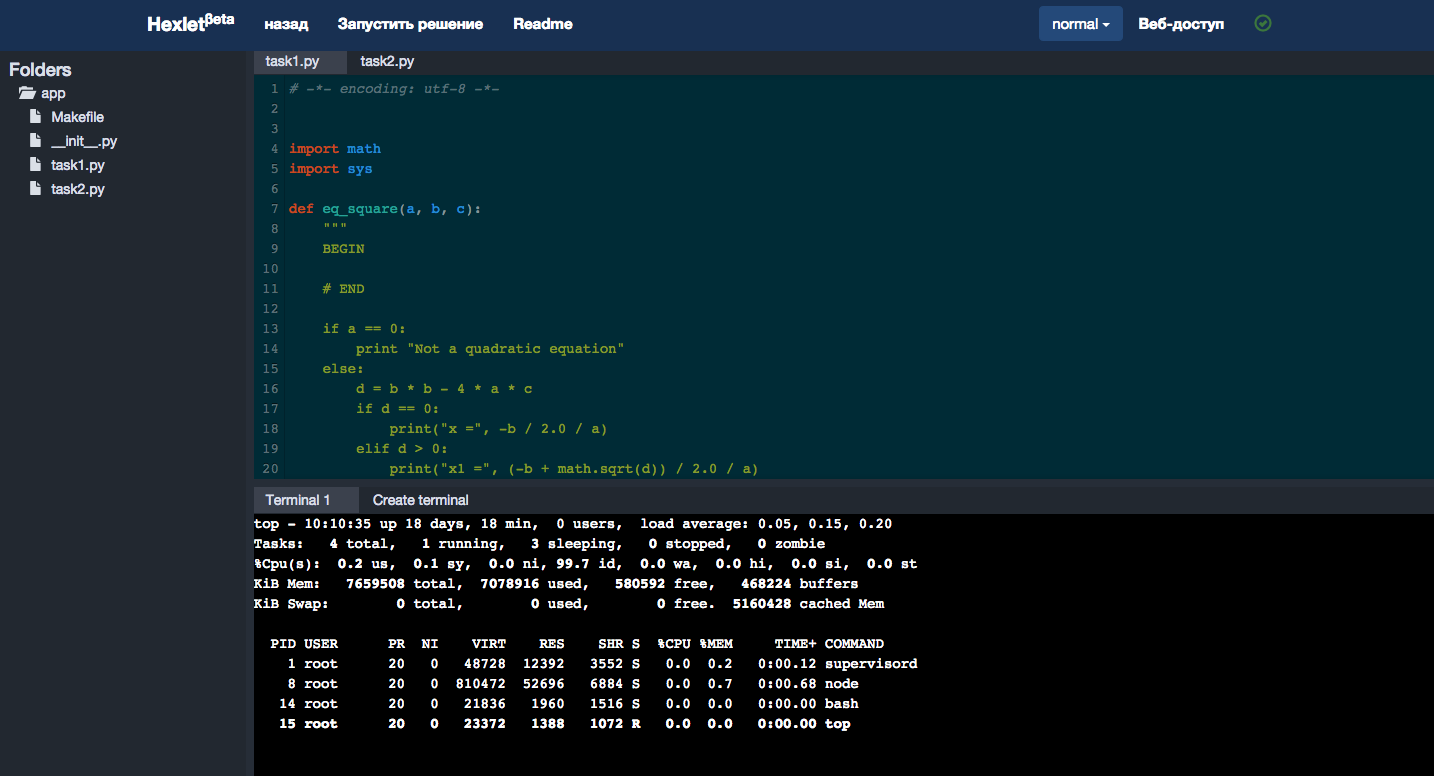
Новая версия Hexlet IDE в деле.
В первые недели все метрики (как системные, вроде нагрузки на машины, так и бизнес-метрики, такие как регистрации и оплаты) мы отправляли в свою базу InfluxDB, и рендерили графики в Grafana. Но сейчас переходим на сторонние сервисы, например, Datadog. Он умеет интегрироваться с AWS, настраивать оповещения при возникновении инцидентов.
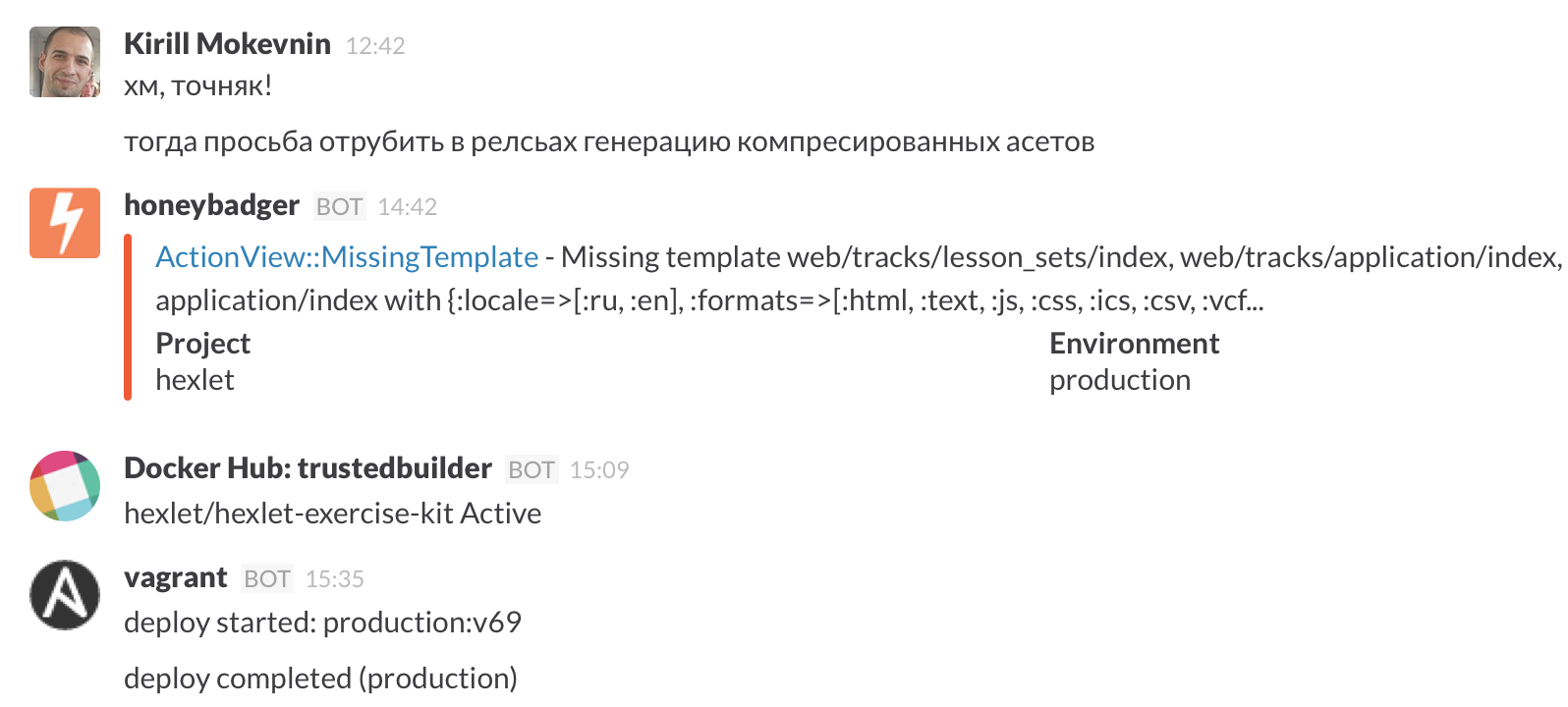
Вся команда Хекслета сидит в Slack, там в специльном чате #operations мы видим все, что происходит на проекте: деплои, ошибки, билды и пр.
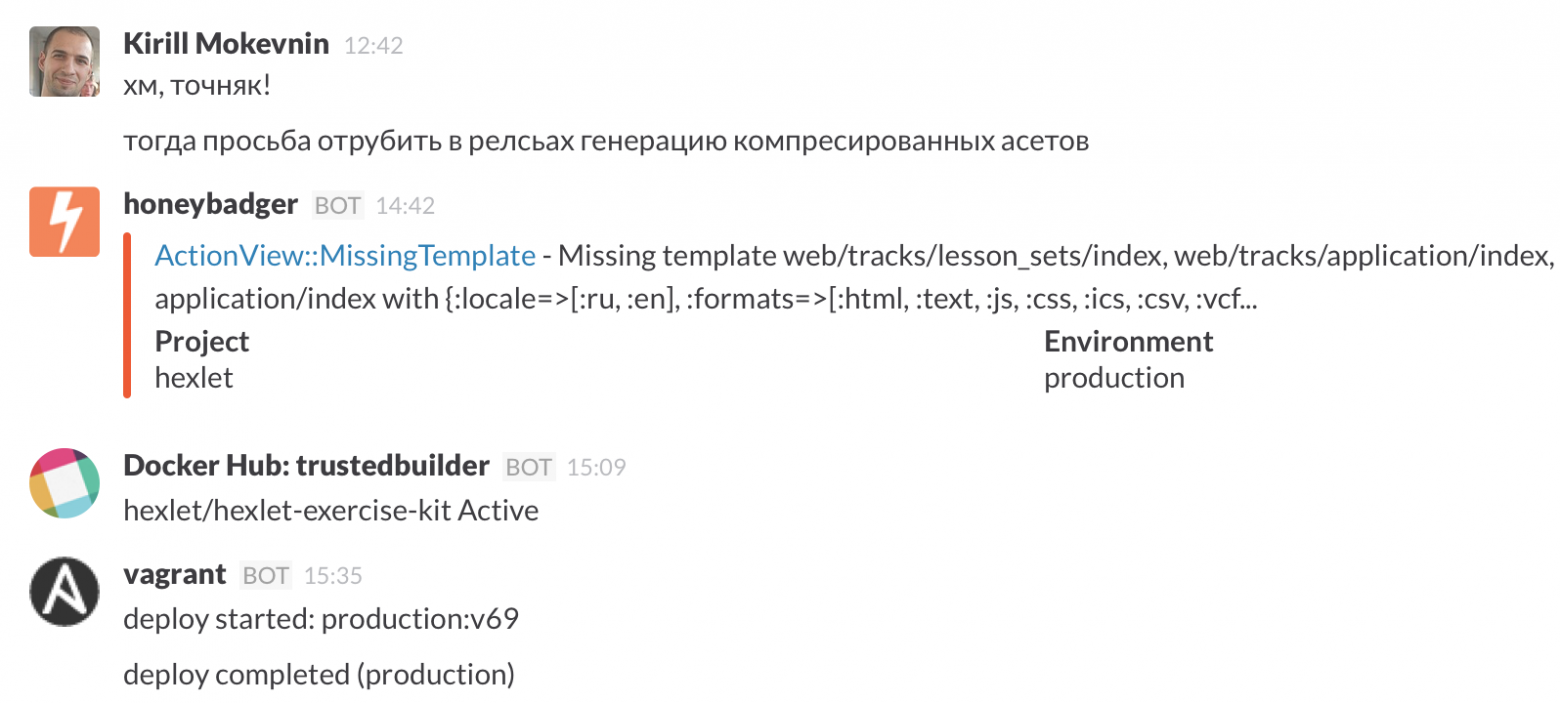
Наша команда сама создает уроки, а также приглашает авторов из числа профессиональных разработчиков. Любой человек или компания могут стать авторами уроков, как публичных, так и для внутреннего использования, например, для обучения внутри своего отдела разработки или для проведения воркшопов.
Если вам это интересно — пишите на info@hexlet.io и вступайте в нашу группу для авторов на Фейсбуке.
Спасибо!

В прошлой статье я рассказал о новой версии образовательного проекта Хекслет. В голосовании вы решили, что следующая статья будет о технической реализации платформы.
Напомню, Хекслет — это платформа для создания практических уроков по программированию в настоящей среде разработки. Под настоящей средой разработки мы подразумеваем полноценную машину, подключенную к сети. Эта важная деталь отличает Хекслет от других образовательных проектов (например, Codecademy или CodeSchool) — у нас нет симуляторов, все по-настоящему. Это позволяет обучать и обучаться не только программированию, но и работе с базами данных, серверами, сетью, фреймворками и так далее. В целом, если это запускается на Unix-машине — этому можно обучать на Хекслете. При этом, понимая это или нет, пользователи используют Test-Driven Development (TDD), потому что их решения проверяются юнит-тестами.
В этом посте я расскажу про архитектуру платформы Хекслет и инструменты, которые мы используем. О том, как на этой платформе создавать практически уроки — в следующей статье.

Почти весь бэкэнд написан на Rails. Все работает на Amazon Web Services (AWS). Изначально мы старались сильно не привязываться к инфраструктуре AWS, но постепенно стали использовать больше их сервисов. В RDS (Relational Database Service) крутится PostgreSQL (основная база) и Redis. Благодаря нему нам можно не волноваться о бэкапах, репликации, обновлении — все работает автоматически. Так же в RDS мы используем автоматический failover – multiAZ. В случае падения основной машины, автоматически поднимается синхронная replica в другой зоне доступности, и в течение пары минут происходит привязка DNS-записи к новому IP-адресу.
SQS (Simple Queue Service) для построения очередей. Вся почта отправляется через SES, домены живут в Route53. Amazon Simple Notification Service (SNS) шлет в нашу SQS-очередь сообщения о статусе доставки писем. Картинки и файлы хранятся в S3. С недавнего времени используем Cloudfront, CDN от Амазона.
Краеугольный камень всей платформы — Докер.
Каждый сервис у нас работает в своем контейнере. Один контейнер = один сервис. Большинство образов для контейнеров это готовые образы из tutum.co. Репозиторий для своего приложения мы храним в Docker Registry. Для стейджинга образ собирается автоматически при коммите в Dockerfile. Сам код хранится в Github. Для продакшена мы собираем образы через Ansible на отдельном сервере. Билд занимает значительное время, 20-60 минут в зависимости от условий, поэтому вариант «по-быстрому пофиксим продакшен» невозможен. Но оказалось это не проблема, наоборот – дисциплинирует. Когда что-то идет не так при деплое на продакшен, мы просто убиваем один контейнер и предыдущий. Наша база растет только горизонтально (что типично для проектов с, кхм-кхм, хорошей архитектурой), что позволяет использовать базу с разными версиями кода и не получать конфликтов. Поэтому откат это почти всегда простая замена версии кода.
В первое время для деплоя мы использования Capistrano, но в итоге отказались от нее в пользу Ansible. Немного не привычно, но Ansible просто доставляет конфиги на удаленный сервер и запускает upstart, а тот в свою очередь уже обновляет образы. В такой схеме нам не нужно устанавливать на сервера ничего специального, для Ansible нужен только ssh-доступ. Для версионирования используются теги (v64, v65 и так далее), а деплой на стейджинг всегда использует самую последнюю версию (latest) кода.
Кстати, мы так любим Ansible, что сделали по нему практический курс — «Ansible: Введение».

Большой плюс — локально при разработке мы используем почти идентичные Ansible playbooks, что и для продакшена. Так что инфрастуктура обкатывается локально, насколько это возможно, что минимизирует ошибки типа «а на локалке работало». В итоге процесс деплоя выглядит так: новый коммит в Dockerfile в гитхабе -> запуск нового билда в docker registry -> запуск плейбука Ansible -> обновленные конфиги на сервере -> запуск upstart -> получение новых образов.
Мы также используем амазоновский балансировщик, и в случае хабраэффекта за 10-20 минут можем поднять дополнительные машины. Важное условие такой схемы — конечные веб-серверы не хранят состояния (stateless), на них не сохраняется никаких данных. Это позволяет быстро масштабироваться.
Амазон мы тоже любим, про Route53 (менеджмент доменов/DNS) и про балансировщик у нас есть уроки в цикле «Распределенные системы».
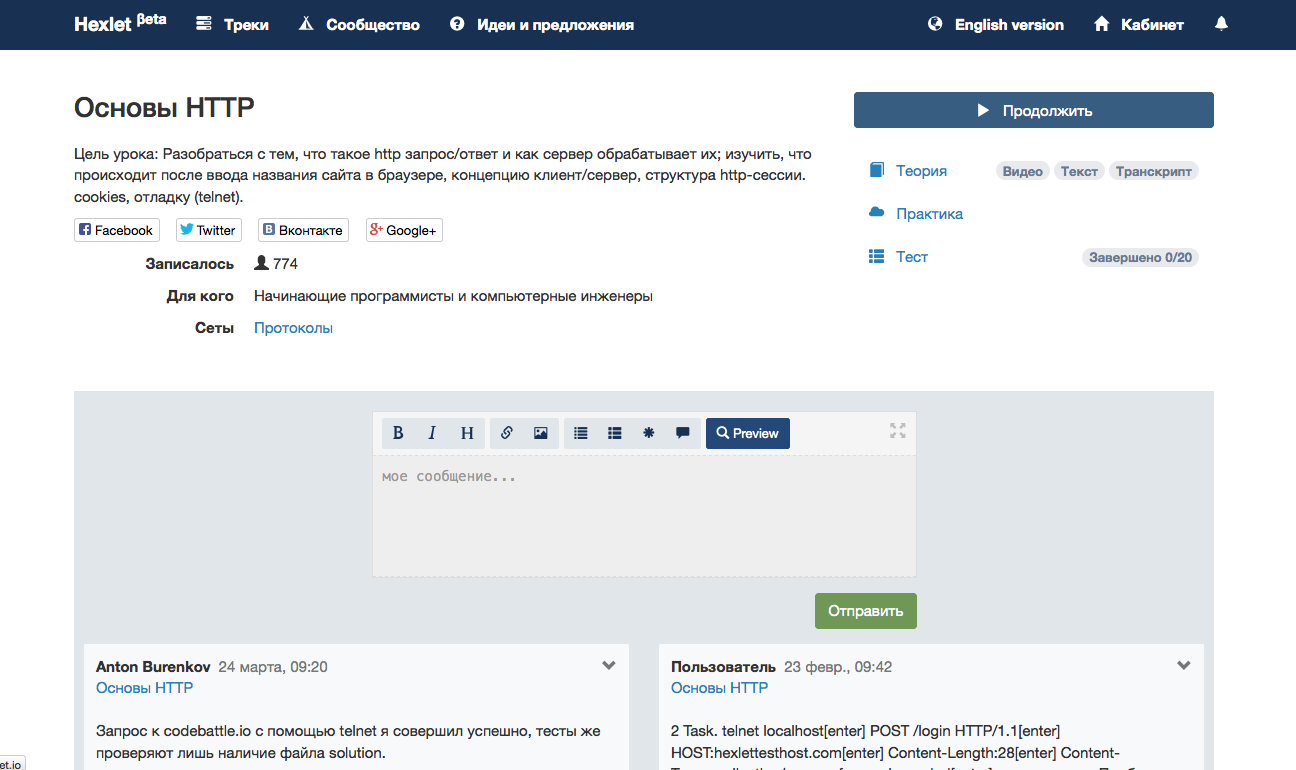
Страница популярного урока.
Суть проекта — позволять людям учиться в реальном окружении, для этого каждому юзеру мы поднимаем контейнер, в котором он выполняет практическое упражнение. Эти контейнеры поднимаются на специальном «eval»-сервере. На нем есть только Докер и обращаться к нему можно только из Shoryuken, асинхронно.
В первых прототипах Хекслета система требовала от пользователей работать над практическими заданиями на своих компьютерах, но сейчас вся работа происходит в браузере, скачивать и устанавливать ничего не нужно. Для этого нам понадобилась браузерная среда разработки, которая позволила бы юзерам редактировать файлы и запускать программы. Существует много облачных IDE, и мы, как любой уважающий себя стартап, хотели по максимуму использовать готовые решения. Нашли классный IDE с кучей функций (даже с интеграцией с Git), но потом оценили стоимость поддержания чужого кода (полного изобретенных велосипедов) и решились писать свой простой IDE. Здесь нас спасла еще одна новая технология — ReactJS и концепция Flux. Пару недель назад вышла новая версия Hexlet IDE с кучей функциональных и визуальных улучшений.
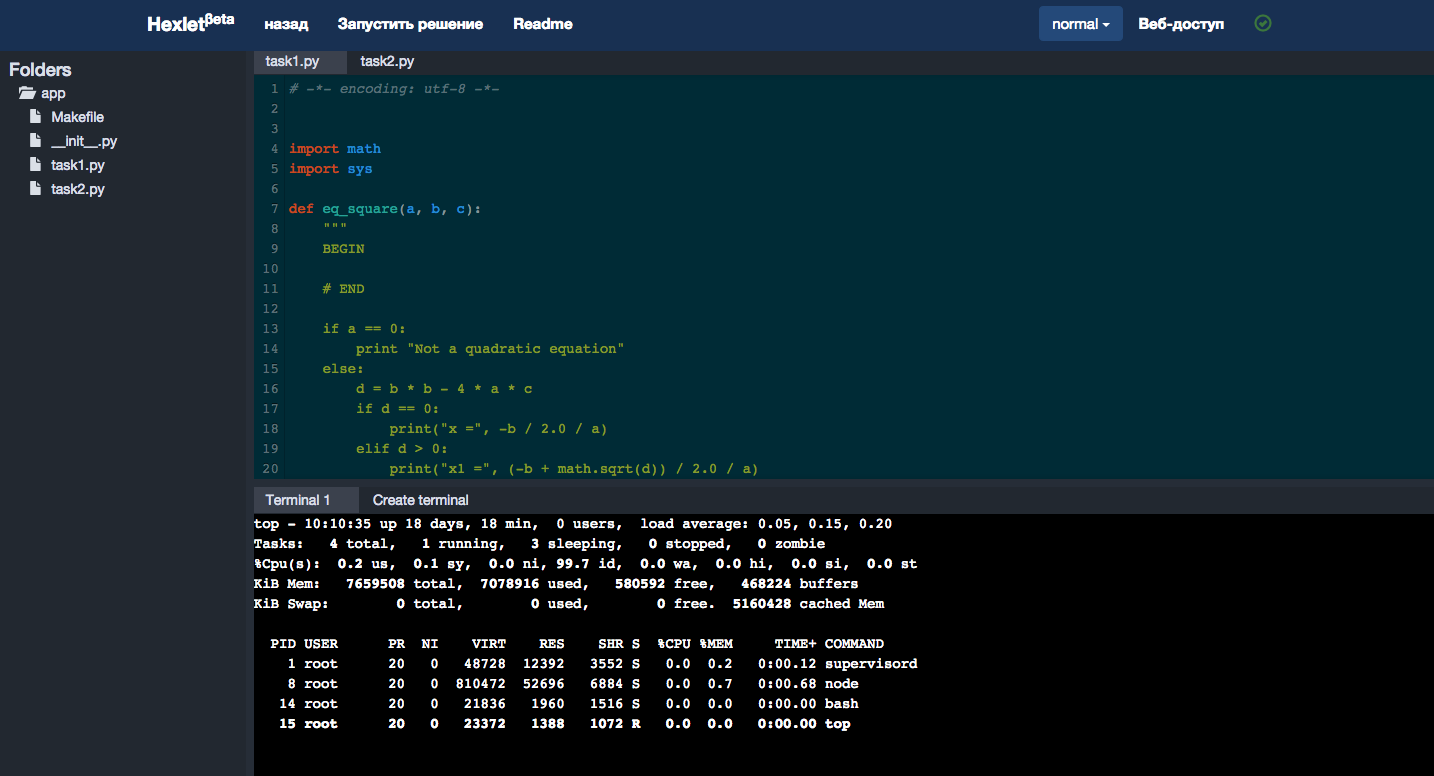
Новая версия Hexlet IDE в деле.
В первые недели все метрики (как системные, вроде нагрузки на машины, так и бизнес-метрики, такие как регистрации и оплаты) мы отправляли в свою базу InfluxDB, и рендерили графики в Grafana. Но сейчас переходим на сторонние сервисы, например, Datadog. Он умеет интегрироваться с AWS, настраивать оповещения при возникновении инцидентов.
Вся команда Хекслета сидит в Slack, там в специльном чате #operations мы видим все, что происходит на проекте: деплои, ошибки, билды и пр.
Наша команда сама создает уроки, а также приглашает авторов из числа профессиональных разработчиков. Любой человек или компания могут стать авторами уроков, как публичных, так и для внутреннего использования, например, для обучения внутри своего отдела разработки или для проведения воркшопов.
Если вам это интересно — пишите на info@hexlet.io и вступайте в нашу группу для авторов на Фейсбуке.
Спасибо!
