
Все побежали, и я побежал… Строго говоря, историю о том, как мы научили наше приложение работать с СУБД PostgreSQL и провели первую миграцию боевой системы одного из наших заказчиков, можно было рассказать ещё три года назад. Именно тогда мы это сделали впервые. Сейчас за нашими плечами уже 11 внедрений «Единого клиента» на PostgreSQL. Две миграции на эту СУБД с Oracle пройдут в этом году.
В статье поделюсь нашими наработками. Будет полезно тем, кто только собирается пойти по такому пути. Если тема интересна, можете посмотреть и выступление моего коллеги Вадима Зайцева на CDI Tech Conf.
Итак, «Единый клиент» (ЕК) — классическое энтерпрайз-приложение на Spring, сидящее на базе данных. В 2019-м году, когда мы переводили систему на PostgreSQL, у заказчика были такие вводные:
Действующая СУБД — Oracle.
База данных «весом» около 3 Тб, в нее активно шли запись и чтение.
Опыт работы с PostgreSQL, пусть и в намного более скромных по масштабу системах.
Напомню, что к тому времени на PostgreSQL уже были коммерческие энтерпрайз-решения. СУБД хорошо показывала себя в работе с большими объёмами данных. Для нашего заказчика выбор PostgreSQL был продиктован и тем, что базы на этой СУБД легче масштабировать: цена продукта не привязана к мощности серверов, как это принято для проприетарного ПО.

В принципе тут всё, как для какой-нибудь большой доработки: подготовка, железо, тренировка на тесте с реальным объёмом данных, работы на проде. Дальше я пройдусь по основным шагам.
Подготовка релиза
Начали мы с того, что проверили, насколько наш продукт готов к работе на PostgreSQL. У приложения нет бизнес-логики на «хранимках», самописный ORM умеет в PostgreSQL, а сформированный им SQL подчиняется стандарту и должен работать в любой СУБД.
Звучит обнадеживающе, но дьявол кроется в деталях. И на них было потрачено достаточно времени. Вот некоторые:
DDL выражения (ALTER TABLE, CREATE INDEX…) транзакционные, и их надо коммитить. Непривычно после Oracle.
По умолчанию любая SQL-ошибка инвалидирует всю транзакцию. Если вы из тех, кто ловит ошибку, проглатывает её и продолжает работу, используйте параметр autosave (Документация JDBC драйвера)
Другой принцип организации БД (WAL) накладывает свои ограничения, и иногда СУБД работают по-разному. Например, при использовании SELECT ... FOR UPDATE в Oracle и в PostgreSQL есть отличия: по нашим наблюдениям, Oracle обновляет свой курсор после выхода из ожидания, а PostgreSQL нет.
С другой стороны сильно порадовал богатый DDL и DML синтаксис. У любого CREATE INDEX и ADD COLUMN есть опция IF NOT EXISTS. Это после Oracle, где для безопасного создания индекса, надо писать солидный блок кода.
Или как вам INSERT INTO, который принимает сразу несколько VALUES за один раз, да еще и имеет опцию ON CONFLICT DO NOTHING?
insert into reference (created, author, ref_type, code, ordinal,
party_type, short_label)
values (localtimestamp, 'HFLabs-CDI', 'PASSPORT_TYPE',
'ACT_OF_GUARDIANSHIP', 72, 'PHYSICAL', 'Акт органа опеки и попечительства'),
(localtimestamp, 'HFLabs-CDI', 'PASSPORT_TYPE',
'ADOPTION_CERTIFICATE', 73, 'PHYSICAL', 'Св-во об усыновлении')
on conflict do nothing;
commit;Следующим шагом было научить работать на PostgreSQL наши автотесты. Мы просто допилили наш тестовый фреймворк, а все тесты (их несколько тысяч) отработали.
Затем сделали нагрузочное тестирование. У нас есть внутренний стресс-стенд с сотнями миллионов исходных записей и искусственно генерируемой нагрузкой всех типов (онлайн, загрузка данных через буферные таблицы, различные переобработки). Сделали аналогичный для PostgreSQL, запустили нагрузку и стали с замиранием сердца следить, что получится.
Вот, например, один из графиков. На нём время отклика нашего веб-сервиса на идентичные запросы (это получение данных клиента по идентификатору) к одинаковым данным для Oracle и PostgreSQL. Как видим, на чтении PostgreSQL справлялся лучше на 5%. Графики для остальных методов были примерно такими же.
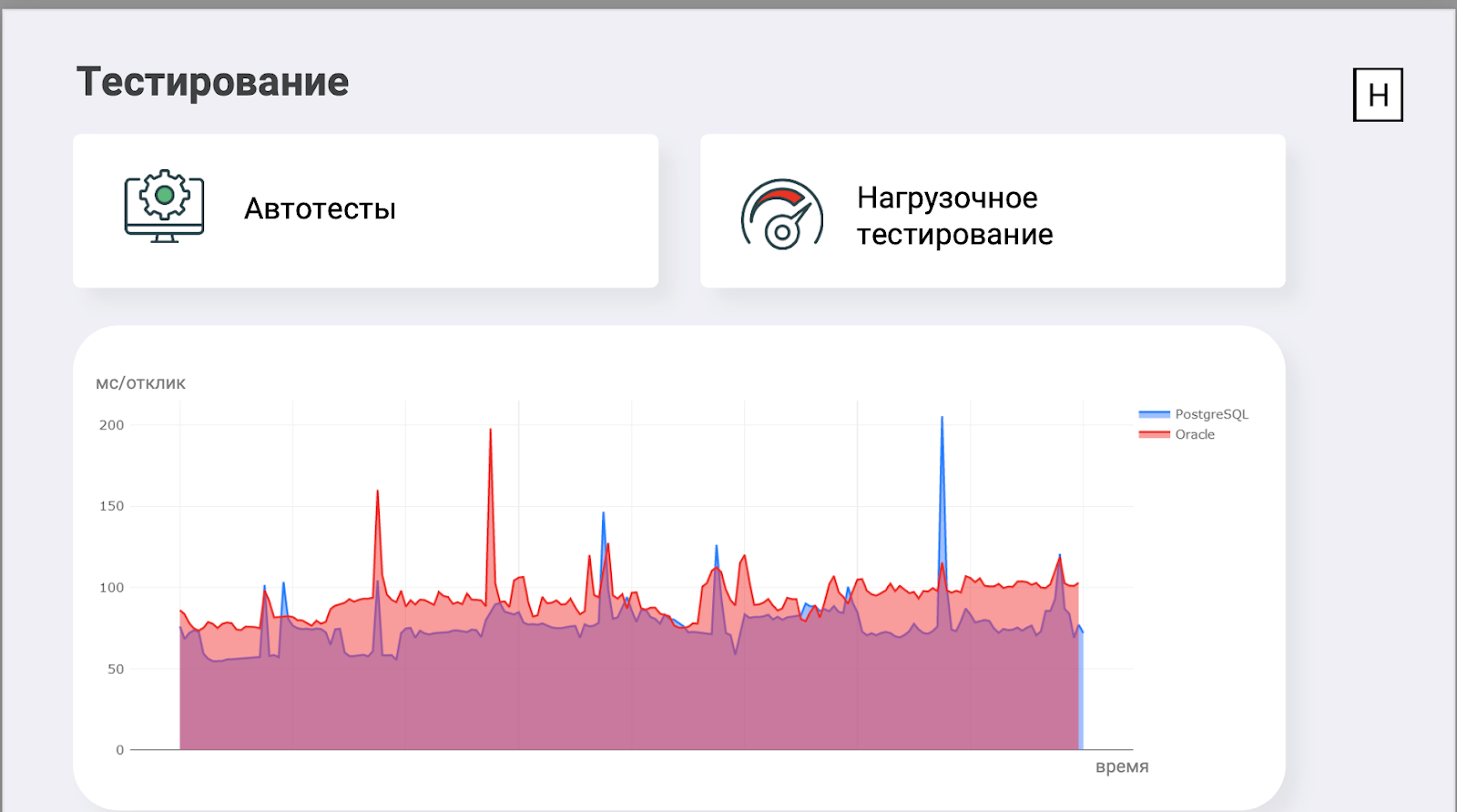
БД работали на идентичных серверах: 32 CPU AMD EPYC 7502P, 512 GB RAM, 5 TB SSD. Все ресурсы были доступны им монопольно, настройка Oracle идентична нашим боевым контурам, Postgres сконфигурирован исходя из нашего представления о прекрасном на тот момент.
Выбор механизма миграции
Следующей задачей было придумать механизм миграции отполировать его до блеска и провести миграцию сред заказчика.
Тут мы сели изучать варианты — от простой выгрузки-загрузки через CSV до миграции с использованием специализированных утилит. Ни один вариант не подошёл. Где-то не устраивала производительность, где-то трудоёмкость, где-то ограничения. Тогда мы обратились за помощью к коллегам из Postgres Professional. Показали им нашу схему, и они дали нам утилиту для миграции Pentaho Kettle (Pentaho BI Suite) и другие полезные рекомендации.

После нескольких экспериментов Pentaho вполне устроила нас в плане скорости и лёгкости в использовании. Мы написали сценарии и успешно мигрировали пару тестовых баз. Начали с нашего dev-стенда объёмом примерно в 5% данных заказчика и закончили стресс-стендом (с сотнями миллионов записей). При тестировании мы наполняли его данными с нуля, а теперь провели полноценную миграцию.
Правда, возник вопрос, как выполнять сверку. Качественно считать контрольные суммы для каждой записи каждой таблицы в Oracle и PostgreSQL или ограничиться количественной сверкой? На наших стендах мы провели качественную сверку, а при миграции боевой системы ограничились количественной — так вышло быстрее.
Следующим вызовом (в итоге он стал, пожалуй, главным) для нас было минимизировать время простоя нашей системы. С одной стороны, на тот момент «Единый клиент» не был mission/business critical приложением в инфраструктуре заказчика. С другой стороны, на него было завязано довольно много процессов. Ежедневно в приложение приходили десятки тысяч карточек клиентов в рамках пакетных интеграций, а каждую секунду оно обрабатывало до 100 поисковых запросов. По всем таблицам это давало нам более миллиона новых строк ежедневно.
Так что остановить систему на несколько дней мы не могли. Максимум, который удалось согласовать, — техническое окно в четыре часа.
Миграция
Миграция базы размером 3 Тб, по предварительной оценке, должна была занять около четырех суток. Поэтому мы стали перебирать варианты. Вот основные из них.
Остановка системы, миграция, переключение. Минус — не проходим по времени. При всей многопоточности и на мощном железе мигрировать базу такого объёма за 4 часа нереально.
Разделение данных на исторические и актуальные, миграция исторических данных, остановка системы, миграция актуальных данных, переключение. Внимательно посчитали, и соотношение исторических данных к актуальным оказалось 3:1. Мигрировать почти 1 Тб данных за четыре часа снова не получается.
Предварительная миграция среза данных, а затем дополнительная миграция свежих изменений. Миграция слепка БД, остановка системы, миграция дельты.
Работа одновременно с двумя СУБД или настройка репликации Oracle-PostgreSQL. От этого отказались сразу из-за трудоёмкости.
В итоге мы остановились на третьем варианте. Предварительный план выглядел так: создаём пустую схему, переносим слепок базы, затем считаем дельту, переносим её без остановки системы (повторяем, если надо), то есть держим базу PostgreSQL в состоянии, максимально приближенном к базе Oracle. Затем останавливаем систему, считаем «финальную» дельту, сверяем количество записей по всем таблицам, переключаемся.

После нескольких экспериментов мы внесли в план два изменения.
Индексы и констрейнты в PostgreSQL решили создавать не вместе с таблицами, а после загрузки предпоследней дельты. Это должно было ускорить миграцию.
Поняли, что необязательно останавливать систему на все четыре часа — достаточно отключить все процессы, которые меняют данные. А если кто хочет читать у нас данные, то пожалуйста. Мы добавили в «Единый клиент» режим read-only, в котором в самом приложении невозможно запустить ни одну задачу, а на любую попытку что-то нам записать обратившийся получает ошибку типа Service Unavailable. Читать при этом можно без ограничений.
В итоге планировали, что первоначальная миграция займёт сутки-двое (вместо расчётных четырёх), а финальную дельту мы успеем мигрировать за выделенные нам четыре часа.
Задача в Pentaho и для первоначальной миграции, и для загрузки дельты выглядела так:
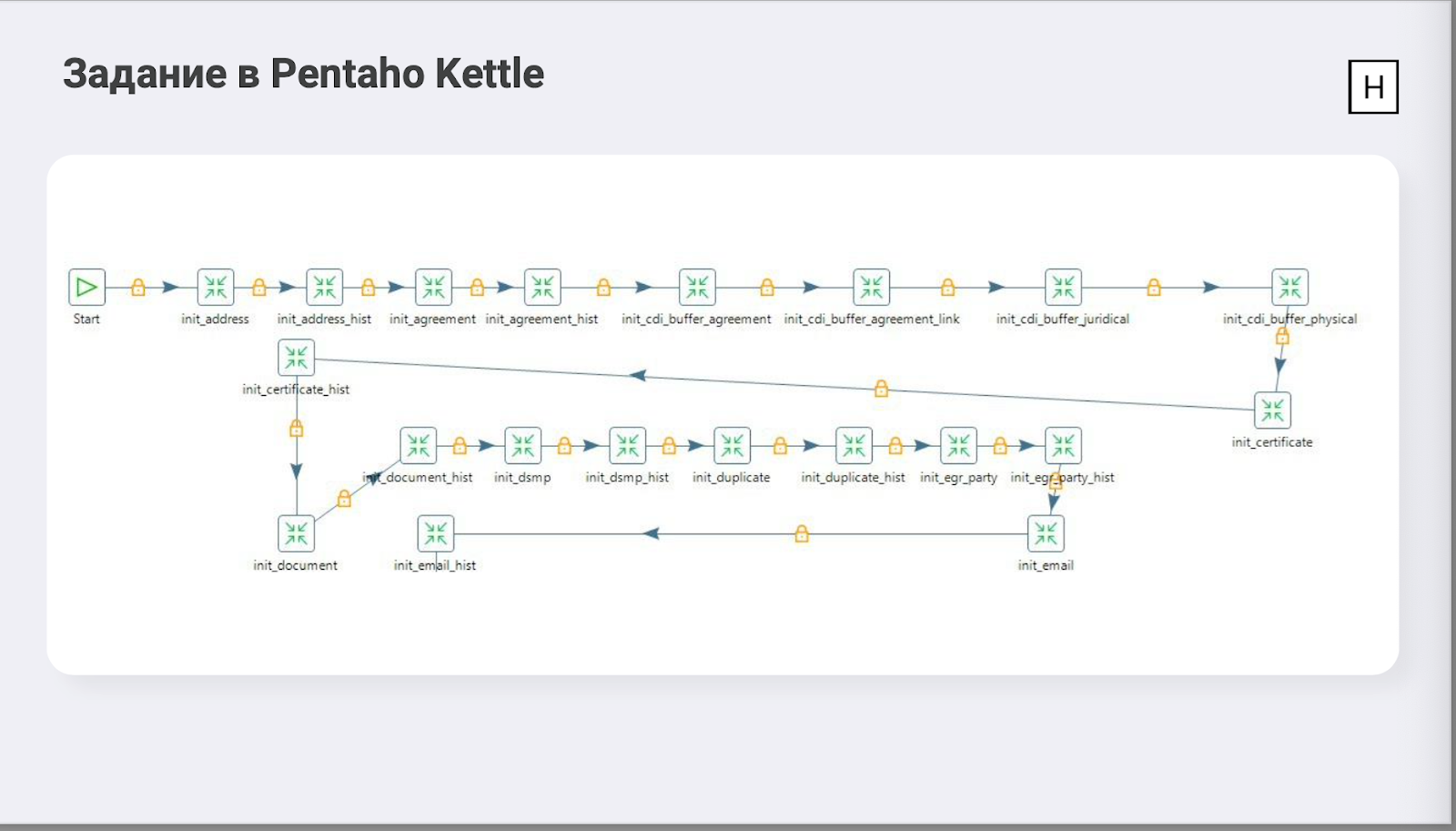
Может показаться, что здесь что-то сложное, но на самом деле всё просто: последовательно копируем таблицы с минимальным трансформом, каждый кубик — копирование таблицы в 32 потока.
На проде всё прошло по плану. Чуть больше суток мигрировали основной объём, потом неделю стояли на паузе, согласовывали дату ночных работ. По четыре часа на «догоняющие» дельты, 2,5 часа — последняя дельта, 1,5 часа — верификация.
В итоге мы уложились в четыре часа, из них 3:45 read-only и 15 минут полная недоступность. Успех :)

Что необходимо учесть, чтобы миграция прошла максимально быстро и без проблем?
До начала работ необходимо максимально уменьшить количество изменений в БД. В нашем случае мы перед началом работ отключили пакетную загрузку данных.
Перед переводом в режим read-only необходимо отключить интеграции, которые могут менять данные. Если какие-то отключить нельзя, нужно убедиться, что сообщения накапливаются где-то в очереди (например, на шине).
После миграции теста обязательно нужно проверить все интеграции, работающие с БД. Например, пишущие в таблицы или получающие данные для хранилища.
Не создавайте индексы сразу, это ускорит миграцию.
Внимательно посмотрите, какие таблицы поддерживают вычисление дельт, какие нет. У нас была одна большая таблица, которая не поддерживала, и мы мигрировали ее в самом конце, вместе с дельтами всех остальных таблиц.
Итоги
Всего, как я упоминал, у нас уже 11 инсталляций приложения на PostgreSQL — от среднего до большого объёма. Подготовка к миграции с нашей стороны теперь занимает 2-3 дня. Производительность приложения сохранилась. Так что, можно сказать, мы подружились с PostgreSQL. Потребовалось, конечно, больше тестовых ресурсов (теперь автотесты прогоняются для каждой СУБД). Да и нагрузочный стенд решено было полностью повторить, но с новой СУБД.
Добавлю и ложку дёгтя. Что хромает у PostgreSQL, так это культура сопровождения в целом. Вспомним про огромную базу Oracle DBA, обучающие курсы и то, что в каждой организации сидел сертифицированный специалист по этой СУБД. Он мог снять отчёт, по которому даже слепой бы понял, в чём проблема.
У PostgreSQL, с одной стороны, нет встроенных средств диагностики такого уровня, с другой — нет такого количества обученных администраторов. Поэтому сейчас мы находимся в заложниках у СУБД, так как часто никто кроме нас самих ответить на наши вопросы не может. Но видно, что ситуация меняется, на рынке появляются администраторы с опытом сопровождения PostgreSQL.
Есть вопросы и к надежности СУБД. Ничего аналогичного Oracle RAC, что было бы не страшно использовать в продуктивной среде, мы не нашли, лучшей практикой в части резервирования считается схема с failover. Зато заведённые дефекты могут быть исправлены очень быстро — например, поставив баг в гитхабе JDBC-драйвера, мы получили фикс в тот же день.
Чтобы больше знать о нашем приложении, проектах и работе с данными, подписывайтесь на телеграм-канал @hflabs_official. Мы пишем о персданных, качестве данных, об MDM и CDI.
