
Одной из возможностей повышения качества выпускаемого продукта является соответствие окружений на боевых серверах и в среде тестирования. Мы постарались минимизировать количество ошибок, связанных с различием конфигураций, путем перехода от нашего старого тестового окружения, где настройки сервисов сильно отличались от боевых, к новому окружению, где конфигурация практически соответствует боевой. Сделали мы это с помощью docker и ansible, получили много профита, но и не избежали различных проблем. Об этом переходе и интересных подробностях я постараюсь рассказать в данной статье.
В HeadHunter около 20 инженеров вовлечены в процесс тестирования: специалисты по ручному тестированию, тестировщики-автоматизаторы и небольшая команда QA, которая развивает его процесс и инфраструктуру. Инфраструктура достаточно обширная — около 100 тестовых стендов со своим инструментом для их развертывания, более 5000 автотестов с возможностью запустить их любым сотрудником технического департамента.
С другой стороны продакшен, где еще больше серверов и где цена ошибки намного выше.
Чего хотят наши тестировщики? Выпустить продукт без багов и простоев в боевой среде. И они этого добиваются на текущем тестовом окружении. Правда, иногда проскакивают проблемы, которые отловить на этом окружении невозможно. Такие как изменение конфигурации.
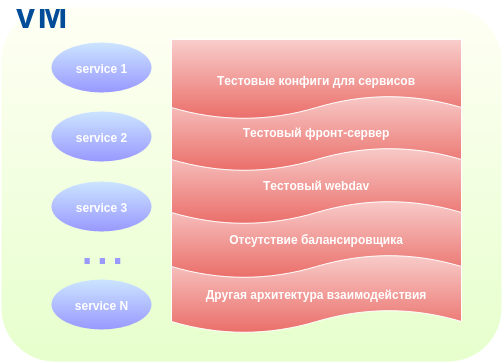
Старое тестовое окружение имело ряд особенностей:
- Свои конфигурационные файлы для приложений, отличающиеся от production и требующие постоянной поддержки.
- Отсутствие тестирования развертывания приложений.
- Отсутствие некоторых приложений, которые есть и работают в боевой среде.
- Полностью свои тестовые конфиги веб-сервера и webdav.
Все эти пункты приводили к различным багам, самый неприятный из которых был почти часовой простой сайта из-за неправильного конфига nginx.
Что хотелось от нового окружения:
- использования конфигурации, максимально приближенной к боевой среде (те же nginx locations, балансировщики и т.п.);
- возможности делать все то же, что мы могли делать на старом окружении, и даже чуть больше — тестировать деплой приложений и их взаимодействие;
- актуальности конфигурации в тестовом окружении относительно боевой среды;
- легкости в поддержке изменений.
Начало пути
Идея использовать конфигурацию с продакшена в тестовом окружении появилась довольно давно (года 3 назад), но были другие более важные задачи, и мы не брались за реализацию этой идеи.
А взялись мы за нее случайно, решив попробовать новое технологическое веяние в виде docker’a в момент, когда вышла версия 0.8.
Чтобы понять, что такого особенного в нашем тестовом окружении, надо немножко представлять из чего состоит продакшен hh.ru.
Продакшен hh.ru предстваляет собой парк серверов, на которых запущены отдельные части сайта — приложения, каждое из которых отвечает за свою функцию. Приложения общаются между собой посредством http.
Идея была воссоздать такую же структуру, заменив парк серверов на lxc-контейнеры. А чтобы всем этим хозяйством было удобно управлять, использовать надстройку под названием docker.
Не совсем docker-way
Мы не пошли по истинному docker-way, когда в одном контейнере запущен один сервис. Задача была сделать тестовые стенды похожими на инфраструктуру продакшена и службы эксплуатации.
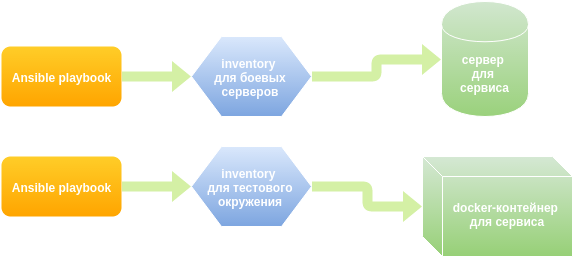
Служба эксплуатации использует ansible для деплоя приложений и конфигурирования серверов. Порядок выкладки и шаблоны конфигов для каждого сервиса описан в yaml файле, в терминологии ansible — playbook. Было решено использовать те же самые плейбуки и в тестовом окружении. Гибкость тут в возможности заменять значения и иметь полностью свой, тестовый, набор значений переменных.
В итоге у нас образовалось несколько docker images — базовый образ в виде ubuntu с init & ssh, с тестовой базой данных, с cassandra, с deb-репозиторием и maven-репозиторием, которые доступны во внутреннем docker registry. Из этих образов мы создаем необходимое нам количество контейнеров. Затем ansible раскатывает нужные плейбуки, на указанные в inventory (список групп серверов, с которыми будет работать ansible) контейнеры-хосты.
Все запущенные контейнеры находятся в одной (внутренней для каждой машины-хоста) сети, и каждый контейнер имеет постоянный IP адрес и DNS-имя — и тут тоже не docker-way. Для полного воссоздания инфраструктуры продакшена некоторые контейнеры имеют даже IP-адреса боевых серверов.
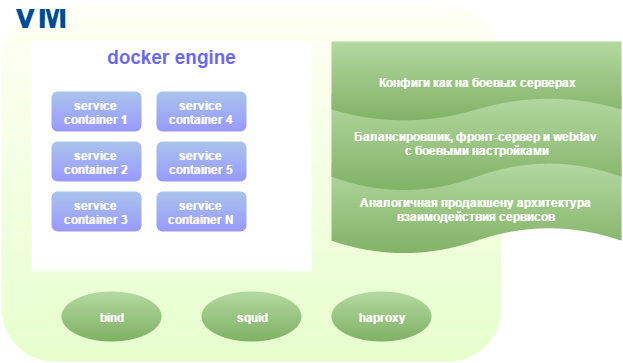
Заходить на контейнеры можно по ssh прямо с машины-хоста. Внутри у контейнера то же расположение файлов, что и на продакшен серверах, те же версии приложений и зависимостей.
Для удобного поиска ошибок на хост-машине агрегируются директории с логами с каждого контейнера с помощью механизма символических ссылок. Каждый запрос на продакшене имеет уникальный номер, и теперь эта же система доступна в тестовом окружении, что позволяет, имея id запроса, найти его упоминание в логах всех сервисов.
Саму хост-машину под контейнеры мы создаем и настраиваем из нашей системы управления тестовыми стендами при помощи vmbuilder & ansible. Новым машинам потребовалось больше оперативной памяти из-за дополнительных сервисов, которых раньше не было в тестовом окружении.
Для облегчения работы было написано множество скриптов (python, shell) — для запуска плейбуков (чтобы тестировщики не запоминали различные теги и параметры запуска ansible), для работы с контейнерами, для создания с нуля всего окружения и его обновления, обновления и восстановления тестовых баз и т.п.
Сборка сервисов из кода для тестирования у нас также автоматизирована, и в новом окружении используется точно та же программа сборки, что и при выпуске релизов на продакшен. Сборка производится в специальном контейнере, где установлены все необходимые build dependencies.
Какие проблемы были и как мы их решали
IP адреса контейнеров и их постоянный список.
Докер по-умолчанию выдает IP-адреса из подсети в случайном порядке и контейнер может получить любой адрес. Чтобы как-то завязываться в DNS зоне мы решили прокидывать каждому контейнеру свой уникальный, закрепленный за ним адрес, указанный в конфиг-файле.
Параллельный запуск ansible.
Служба эксплуатации никогда не сталкивается с задачей создать продакшен с чистого листа, поэтому они никогда не запускают все ansible-плейбуки разом. Мы попробовали, и последовательный запуск плейбуков для разворачивания всех сервисов занял примерно 3 часа. Такое время полностью нас не устроило при развертывании тестового окружения. Было решено запускать плейбуки в параллели. И тут нас опять ждала засада: если запустить все в параллели, то некоторые сервисы не стартуют из-за того, что они пытаются установить соединение с другими сервисами, которые еще не успели стартовать.
Обозначив примерную карту этих зависимостей, мы выделили группы сервисов и запускаем плейбуки в параллели внутри этих групп.
Задачи, которые отсутствуют в процессе выпуска приложений службой эксплуатации.
Служба эксплуатации занимается развертыванием уже собранных приложений в deb-пакетах, тестировщику, как и разработчику, приходится собирать приложения из исходного кода, при сборке есть другие зависимости относительно тех, что необходимы при установке. Для решения задачи сборки добавили еще один контейнер, в который ставим все необходимые зависимости. Отдельный скрипт собирает пакет внутри этого контейнера из исходников нужного в данный момент приложения. Затем пакет заливается в локальный репозиторий и раскатывается на те контейнеры, где он необходим.
Проблемы с возросшими требованиями по железу.
В виду большего количества сервисов (балансировщики) и других настроек приложений относительно старого тестового окружения, для новых стендов потребовалось больше оперативной памяти.
Проблемы с таймаутами.
На продакшене каждый сервис стоит на своем сервере, достаточно мощном. В тестовом окружении сервисы в контейнерах делят общие ресурсы. Установленные таймауты в продакшене оказались неработающими в тестовом окружении. Они были вынесены в переменные ansible и изменены для тестового окружения.
Проблемы с ретраями и алиасы для контейнеров.
Некоторые ошибки, происходящие в сервисах, обходятся на продакшене с помощью повторных запросов на другую копию сервиса (ретраи). В старом окружении ретраи вообще не использовались. В новом окружении, хотя мы и подняли по одному контейнеру с сервисом, были сделаны dns-алиасы для некоторых сервисов, чтобы работали ретраи. Ретраи делают систему чуть более стабильной.
pgbouncer и количество соединений.
В старом тестовом окружении все сервисы ходили прямо в postgres, в продакшене перед каждым постгресом стоит pgbouncer, менеджер соединений к базе. Если менеджера нет, то каждое соединение к базе — это отдельный процесс postgres, отъедающий дополнительный объем памяти. После установки pgbouncer количество процессов postgres сократилось с 300 до 35 на работающем тестовом стенде.
Мониторинг сервисов.
Для удобства использования и запуска автотестов был сделан легкий мониторинг, который с задержкой меньше минуты показывает состояние сервисов внутри контейнеров. Сделали на основе haproxy, который делает http check по сервисам из конфига. Конфигурационный файл для haproxy генерируется автоматически на основе ansible inventory и данных по адресам и портам из ansible playbooks. Мониторинг имеет user-friendly view для людей и json-view для автотестов, которые проверяют состояние стенда перед запуском.
Было еще множество других проблем: с контейнерами, с ansible, с нашими приложениями, с их настройками и т.п. Мы решили большинство из них и продолжаем решать то, что осталось.
Как всем этим пользоваться для тестирования?
Каждый тестовый стенд имеет свое dns-имя в сети. Раньше, чтобы получить доступ к тестовому стенду, тестировщик вводил hh.ru.standname и получал копию сайта hh.ru. Это было достаточно просто, но не позволяло тестировать многие вещи и вносило сложности в тестирование мобильных приложений.
Теперь, благодаря использованию продакшен конфигов для nginx, которые не очень хотят принимать на вход URI, заканчивающиеся на standname, тестировщик прописывает у себя в браузере прокси (на каждой хост-машине поднят squid) и открывает в браузере hh.ru или любой другой сайт из нашего пула (career.ru, jobs.tut.by, etc) и любой из доменов третьего уровня, например, nn.hh.ru.
Использование прокси позволяет без проблем тестировать мобильные приложения, просто включив прокси в настройках wifi.
Если тестировщик или разработчик захотел получить доступ к сервису и его порту напрямую снаружи, то делается проброс портов при помощи haproxy — например, для дебага или других целей.
Profit
В данный момент мы все еще находимся в процессе перехода на новое окружение и реализуем всевозможные пожелания, которые появились в процессе работы. Уже перевели ручное тестирование на новые стенды и основной релизный стенд. В ближайших планах — перевести на новое окружение инфрастуктуру автотестирования.

На текущий момент уже имеем profit в следующих случаях:
- для выпуска нового сервиса сам разработчик может написать и протестировать ansible playbook и только после этого передать его в службу эксплуатации. Это позволяет протестировать конфиги и процесс выкладки максимально приближенно к production;
- можно без проблем поднять несколько экземпляров одного сервиса в разных контейнерах и проверить совместимость версий или работу балансировщика при отключении одного из них, или как сайт будет работать, если два инстанса из трех одного сервиса вдруг перестанут отвечать;
- можно проверить какие-то сложные изменения в конфигах nginx или изменить схему работы webdav;
- для отладки можно без проблем подключить тестовый сервер к нашему мониторингу и с удобством исследовать проблемы;
- во время работы над новым окружением было обнаружено и исправлено множество багов в конфигурации продакшена и в ansible playbooks.
Как и со всеми нововведениями есть и те, кто доволен, и те, кто принимает новое в штыки. Основным камнем преткновения является использование прокси — кому-то это не очень удобно, что вполне понятно. Общими усилиями постараемся решить и эту проблему.
В следующих планах полная автоматизация создания стендов под каждый релиз и исключение человека из процесса сборки и автотестирования релизов.
