Зачем я это читаю?
TL;DR:
- Переложив секции кода и данных программы на большие страницы можно существенно ускорить приложение (у нас получилось до +10%) не трогая исходный код.
- Можно быстро проверить ничего не перекомпилируя, детали здесь.
- Финальное решение оперирует "классическими" большими страницами (не transparent huge pages), поэтому в какой-то степени его можно назвать дальнейшим развитием
libhugetlbfs.
Вступление
Если вы спросите у инженера как ускорить вашу программу, то ответ будет зависеть от того, в какой области он специализируется:
- системный архитектор откроет документацию на ваш продукт и будет искать самое слабое звено (компонент — бутылочное горлышко, заменив который система должна получить второе дыхание)
- SDE сразу попросит доступ к исходному коду, пропадет из поля зрения на пару месяцев, анализируя асимптотики используемых алгоритмов — может быть ребята где-то пропустили "квадрат" или того похуже?
- SRE станет профилировать ключевые процессы системы и как они взаимодействуют с ядром ОС, как используется память, где и сколько потребляется: perf top / perf stat / perf record / perf report / jemalloc profiler. А может быть pidstat, vmstat, sar? strace/gdb? Если есть новое Linux ядро под рукой, то набирает бешеную популярность eBPF: bcc в руки, и вперед! На выходе список наиболее тяжелых функций, узкие места ОС (сеть, диски, память?).
- разработчик компиляторов откроет для вас дивный новый мир генерации кода с использованием профиля выполнения: PGO / AutoFDO / BOLT. Предложит LTO для усиления эффектов этих технологий. И, о чудо, оно действительно генерирует значительно более быстрые программы, особенно сильно видно на архитектурах не x86. Применив все это добро правильно, можно серьезно улучшить производительность, не трогая исходный код вообще. Привлекательно, не правда ли?
- hardware специалист приоткроет двери NUMA-aware архитектур. Что греха таить — мы уже очень давно используем сервера с NUMA, а все наивно верим что все процессоры одинаковые, а RAM общая. Мммм, "Random access memory" — термин остался с прошлого века, сейчас это, прямо скажем, обман. Набор L1/L2/L3 + NUMA + RAM — чем дальше от процессора, выполняющего Ваш код, тем все дольше доступ, тем сложнее синхронизация. Забудьте о гигабайтах памяти, если Вам нужна производительность, представьте, что ваша память простая, предсказуемая, с последовательным доступом, эксклюзивная для потока, и её не так уж и много (пара мегабайт?). Вряд ли сходу вы сможете все это применить для своего продукта, но попытаться все же стоит.
- разработчик операционных систем, глубоко вздохнув, расскажет о бремени обратной совместимости и петабайтах уже написанных, отлаженных и работающих как часы приложений, а потом Вашему взору откроются новые API асинхронного доступа к современным дискам (libaio, io-uring), ориентированные на облака планировщики задач (linux kernel >= 4) и оптимизации технологии виртуального адресного пространства.
Спектр доступных инструментов и технологий довольно велик, сегодня я расскажу про опыт применения больших страничек в лаборатории баз данных Huawei на примере MySQL сервера: здесь описывается попытка оптимизировать доступ к виртуальному адресному пространству и как с её помощью улучшить утилизацию процессорного времени.
Рассказа про технологию виртуальной памяти, как это сделано внутри Linux, и что такое MMU и TLB, здесь не будет. Есть огромное количество официальных статей, а также зарекомендовавших себя полезных книжных изданий, где это детально описывается. Что-то подзабыли — освежите в Вашей любимой настольной книге по операционным системам.
Разумеется, технология больших страниц не нова (сколько десятилетий прошло с момента выхода Linux 2.6.16?), но почему-то есть не так много программных продуктов, которые дейтвительно используют большие странички хоть как-то. Например, в MySQL большие страницы можно подключить только для внутреннего кеша страниц B-дерева ("innodb_buffer_pool"), причем Oracle предлагает это делать через довольно устаревший SystemV shared memory механизм, а ОС требуется дополнительная специфическая конфигурация.
А где же используют большие странички для собственно кода и данных приложения? .text/.data/.bss располагаются в стандартном маппинге в адресном пространстве процесса, его тоже можно положить на большие страницы. Если кода сгенерировано много, обращение к сегменту кода выполняется довольно часто, производительность также страдает от iTLB/dTLB кеш-промахов. Думаю, можно пересчитать по пальцам, где такой подход применяется, хотя попытки появляются с завидной регулярностью (что несомненно радует):
- libhugetlbfs: 'remap_segments' function
- Google: 'RemapHugetlbText*' functions
- Facebook: 'HugifyText' function
- Intel: 'MoveRegionToLargePages' function
И тем не менее, все вендоры едины в своих отчетах: приложения становятся быстрее, если код и данные положить на большие страницы. Наша команда решила детально изучить сей вопрос и убедиться в правильности данного суждения.
Теория гласит: чем больше страница виртуального адресного пространства, тем большее адресное пространство может быть адресовано с помощью фиксированного набора записей, помещающихся в TLB буфер процессора. Как только количество записей превышает TLB буфер, появляются дополнительные накладные расходы на трансляцию виртуального адреса в физический. Кстати, TLB буферов может быть несколько, например, L1 и L2. В этой статье презентован бенчмарк, показывающий влияние первого и второго уровня TLB с привязкой к спецификации испытуемого процессора. Кроме того, разные архитектуры поддерживают разный набор больших страниц (например, x86_64: 2M, 1G; ppc64: 16М; AArch64: 64K, 2M, 512M, 16G (зависит от модели, а иногда и конфигурации ядра ОС)), поэтому выбор в каждом случае зависит от конкретных целей и задач. Для MySQL 8.0 размер сегментов кода и данных, запакованных в ELF формат, составляет около 120-140М, кроме того в Huawei Cloud мы поддерживаем только 2 архитектуры: x86_64 и AArch64, поэтому выбор пал на стандартные 2М большие страницы.
Теперь какую технологию больших страниц выбрать? Есть 2 основных типа больших страниц в Linux:
- classic hugepages
- transparent hugepages
Здесь на ум приходит старый добрый Морфеус, и его синяя и красная таблетки:

- Синяя таблетка (transparent huge pages) — вы включаете технологию прозрачных больших страниц, сообщаете Linux ядру, какой маппинг выровнен корректно по границе большой странички ( в нашем случае 2М ) и рекомендуете его использовать. Всё. После "вы просыпаетесь в своей постели с твердой уверенностью, что все это был сон".
- Красная таблетка (classic huge pages) — вы "копаете" дальше и "узнаете, насколько глубока кроличья нора".
"Cъесть ли синюю таблетку"? Опыт коллег по использованию THP в типовых базах данных нас сильно обеспокоил. В чем же подвох?
- Дефрагментация физической памяти. Не замечали такой интересный процесс "khugepaged"? Да-да, именно он может притормозить вдруг ваше приложение, даже если вы никогда не планировали использовать какие-то там другие страницы, но ваш процесс останавливается, потому что его кодовый сегмент переносится в другое место физической памяти, чтобы создать побольше больших страниц для своего потребителя. Да и потребитель (к примеру, MySQL сервер) может испытывать случайные скачки TPS/latency в эти моменты времени.
- Непредсказуемость поведения. Какова светлая мечта любого DBA? Правильно, чтобы система работала предсказуемо, понятно, быстро и просто. THP — это оптимизация работы ядра, она может работать и давать результаты, а может не работать или временно не работать, и только ядро конкретной версии знает, почему так происходит. Оценить изменение производительности — уже достаточно сложно решаемая задача. Оценить прирост от оптимизации ядра, которая срабатывает по своему заложенному алгоритму — на порядок сложнее, разве только вы специалист ядра Linux и регулярно "комитите" в ядро, но тогда вряд ли вы это читаете :)
- Свопинг. На старых Linux ядрах, когда большая страница выгружается в файл подкачки, то она разбивается на множество стандартных страниц, когда загружается обратно — снова сливается воедино. Разумеется, этот процесс бьет по производительности системы. Классические страницы выделяются в RAM перманентно, и в
swapне выгружаются. На момент написания статьи я видел патчи в ядро, которые решают этот вопрос. - Рост потребления памяти. Случается при неудачном динамическом выделении в коде конечного приложения, когда отдельно нужно хранить данных пару килобайт, но выделяется каждый раз для этого одна полная страничка памяти (например, 2М). Знаю, что данный симптом присущ и классическим большим страничкам, но прямого контроля над THP программист не имеет. Согласен, пунктик спорный, однако в статьях упоминается регулярно, поэтому решил его также добавить.
Надо все же признать, что разработчики ядра Linux активно улучшают эту технологию, и в ближайшем будущем ситуация может кардинальным образом измениться (возможно, будущее уже наступило). Недаром такие техно-гиганты как Google/Facebook/Intel в своих решениях предлагают использовать THP и отдать ядру решающий голос. Увы, для нас был важен результат здесь и сейчас, и, кроме того, процесс принятия на вооружение новых Linux ядер в Huawei достаточно сложный, ответственный и занимает много времени.
Итак, мы "проглотили красную таблетку".
С чего начать?
Думаю, каждая команда, которая пробовала перемапливать сегменты кода и данных на большие страницы, начинала свой путь с боевого крещения огнем, а именно с библиотеки libhugetlbfs. Сей комбайн создавался на заре внедрения технологии больших страниц в народные массы, поддерживает очень старые ядра (2.6.16) и toolchain'ы (да-да, вот эти линкерные скрипты создавались для них: libhugetlbfs/ldscripts), а также умеет работать не только под Linux, а после прочтения имплементации создается стойкое ощущение, что библиотека активно используется (или использовалась) во встраиваемых системах малой мощности с очень небольшим количеством памяти на борту. В общем, что воду лить? Прикоснуться к истории и почерпнуть мудрости можно на сайте проекта.
Разумеется, это решение взлетело не сразу, однако эффект ускорения был очевидным. MySQL сервер смог устойчиво выдавать на 10% больше TPS (transactions per second) в OLTP PS (point select) на 1vCPU инстансе (эмулятор виртуальной машины на 1 CPU с использованием Linux cgroups, x86_64). iTLB-misses упал в разы. На AArch64 платформе прирост производительности был ещё больше. Наша команда более детально изучила эффект перемапливания .text/data/bss сегментов по отдельности и всех вместе, результат можно представить одной картинкой (процессор AArch64: Huawei Kunpeng 920):
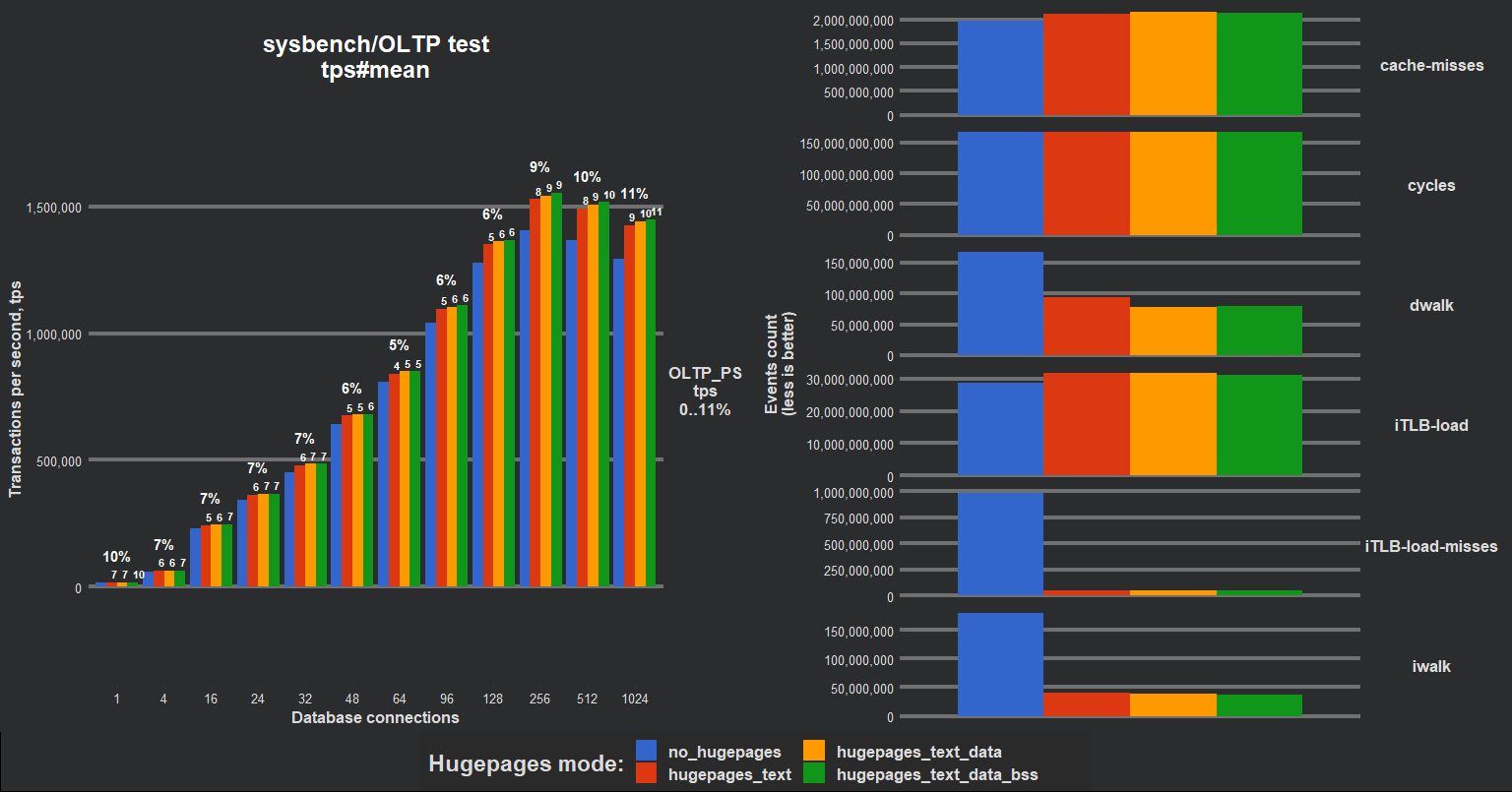
Конечно же, это был "усиленный" CPU-bound бенчмарк (острая нехватка ресурсов процессора), но +10% определенно стоили того, чтобы продолжать исследование. A походу проведения тестов стали отчетливо видны следующие ограничения:
- Включение ASLR на сервере, где работал MySQL (дефолтная сборка с PIE), приводило к SIGSEGV. Анализ выявил явный баг со стороны libhugetlbfs, и ваш покорный слуга с превеликим удовольствием сей баг зарепортил (сразу с фиксом): https://github.com/libhugetlbfs/libhugetlbfs/issues/49. Спустя год мне так же радостно ответили: "не воспроизводится", даже не взглянув на патч. Я в печали ...
- Ограничение на количество сегментов, которые можно перемапить — 3. Думаю, дело опять же в истории, раньше GNU BFD линкер генерировал только 2 ELF сегмента для загрузки динамическим линковщиком: код (r-x: чтение/выполнение) и данные (rw-: чтение/запись). Потом требование безопасности сделало его немного умнее (выделение сегмента для констант: r--), а разработчики, от греха подальше, выставили такую конфигурацию дефолтной. В итоге новый линкер создает 4 сегмента (r-x, r--, r-x, rw-: он все же недостаточно умный, чтобы сделать 3 сегмента, поэтому получаем 4), в итоге библиотека не перемапливает 1 финальный RW сегмент, который обычно является самым объемным.
- Перемапливание финального сегмента автоматически отмапливает HEAP сегмент. Происходит это втихую, без каких-либо внешних проявлений, системный вызов
brkпросто перестает работать. Влияет только на стандартный аллокатор изglibc, который используетbrkдля аллокаций до 128К, а для всего остального —mmap; после сего несчастьяglibcпереключается наmmapдля любых аллокаций. Доподлинно неизвестно, как это влияет на производительность приложения и системы в целом: если у вас есть идеи — делитесь в комментариях. Не влияет наjemalloc, который всю свою память выделяет черезmmap. - Нет как таковой интеграции в целевое приложение — вся работа выполняется в конструкторе динамической библиотеки без каких-либо сообщений об ошибках. Если все плохо, приложение не стартует, а разбор полетов занимает много времени.
- Используется специализированная файловая система
hugetlbfsядра Linux, что означает, что, как минимум, нужно примонтировать её с правильными параметрами, плюс обеспечить приложению корректные права доступа. В облаках, на виртуальных машинах, эта зависимость создает дополнительные проблемы, особенно учитывая тот факт, что начиная с Linux 2.6.32 можно сразу создать анонимный маппинг на больших страницах (системный вызовmmap). Ярмо обратной совместимости с Linux 2.6.16. - Приложение должно быть по-особому слинковано (конкретные флаги линкера:
common-page-size=2M max-page-size=2M). Это сделано для обеспечения безопасности, поэтому не скажу, что это "ограничение" в прямом смысле слова, скорее обязательная рекомендация для финального деплоя в production, однако для тестового запуска для первоначальной оценки изменения производительности в любом случае требуется пересобрать целевое приложение — это не удобно.
Часть проблем критичные, иными словами не production-ready. Ох...

Засучив повыше рукава и набрав побольше воздуха в легкие, я начал медленное и основательное погружение в libhugetlbfs, дабы сделать серверный аналог для нашего MySQL, лишенный всех перечисленных недостатков, а также интегрировав в дальнейшем это решение в код проекта.
А как вообще загружается программа?
Сразу оговорюсь, рассматривается вариант Linux 64-bit / программа в ELF формате / установлена glibc.
Чтобы расставить все точки над "и", стоит затронуть алгоритм запуска типового приложения в ОС Linux. Например, что скрывается за конкретным системным вызовом execve? Опять же, стоит отметить уже существующие шикарные статьи с повышенной детализацией конкретных функций и вызовов в glibc / Linux kernel. Далеко ходить не будем, здесь отслеживается каждый шаг запуска GNU утилиты ls в интерпретаторе bash.
Из этого обилия технической информации нас сейчас интересует несколько моментов:
- Вызов
execveдля исполняемого ELF файла приводит к вызовуload_elf_binaryвfs/binfmt_elf.cв ядре Linux load_elf_binary:
- разбирает ELF файл, достает из него сегменты данных и кода
- создает маппинг для кода и данных приложения, потом инициализирует heap сегмент сразу за этими маппингами
- примапливает VDSO сегмент
- вычитывает текущий интерпретатор для ELF файла (обычно это динамический линковщик
glibc), и загружает его в память (код и данные DSO объекта)
- Linux ядро выполняет еще некоторые служебные функции, потом всю информацию о созданных маппингах сохраняет на стеке, после передает управление динамическому линковщику
glibc(или напрямую программе, если интерпретатор не указан, а программа слинкована статически) - Динамический линковщик:
- инициализирует список текущих маппингов (регистрирует те, что уже созданы ядром)
- вычитывает список DSO, от которых зависит приложение
- выполняет поиск по системе и загрузку всех необходимых DSO (результат подключается к списку текущих маппингов)
- выполняет конструкторы в каждом DSO, а также в основной программе
- передает выполнение функции
mainосновного приложения
Итого, получаем, что список маппингов нашей программы можно получить у:
- ядра Linux,
- библиотеки выполнения
glibc,
a описание этих маппингов лежит в ELF файле.
Ядро Linux публикует маппинги приложения в /proc/$pid/smaps (детальный список) и /proc/$pid/maps (короткий список). Пример короткого списка с Ubuntu 20.04 (kernel 5.4):
$ cat /proc/self/maps
555555554000-555555556000 r--p 00000000 08:02 24117778 /usr/bin/cat
555555556000-55555555b000 r-xp 00002000 08:02 24117778 /usr/bin/cat
55555555b000-55555555e000 r--p 00007000 08:02 24117778 /usr/bin/cat
55555555e000-55555555f000 r--p 00009000 08:02 24117778 /usr/bin/cat
55555555f000-555555560000 rw-p 0000a000 08:02 24117778 /usr/bin/cat
555555560000-555555581000 rw-p 00000000 00:00 0 [heap]
7ffff7abc000-7ffff7ade000 rw-p 00000000 00:00 0
7ffff7ade000-7ffff7dc4000 r--p 00000000 08:02 24125924 /usr/lib/locale/locale-archive
7ffff7dc4000-7ffff7dc6000 rw-p 00000000 00:00 0
7ffff7dc6000-7ffff7deb000 r--p 00000000 08:02 24123961 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7ffff7deb000-7ffff7f63000 r-xp 00025000 08:02 24123961 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7ffff7f63000-7ffff7fad000 r--p 0019d000 08:02 24123961 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7ffff7fad000-7ffff7fae000 ---p 001e7000 08:02 24123961 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7ffff7fae000-7ffff7fb1000 r--p 001e7000 08:02 24123961 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7ffff7fb1000-7ffff7fb4000 rw-p 001ea000 08:02 24123961 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7ffff7fb4000-7ffff7fb8000 rw-p 00000000 00:00 0
7ffff7fc9000-7ffff7fcb000 rw-p 00000000 00:00 0
7ffff7fcb000-7ffff7fce000 r--p 00000000 00:00 0 [vvar]
7ffff7fce000-7ffff7fcf000 r-xp 00000000 00:00 0 [vdso]
7ffff7fcf000-7ffff7fd0000 r--p 00000000 08:02 24123953 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7ffff7fd0000-7ffff7ff3000 r-xp 00001000 08:02 24123953 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7ffff7ff3000-7ffff7ffb000 r--p 00024000 08:02 24123953 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7ffff7ffc000-7ffff7ffd000 r--p 0002c000 08:02 24123953 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7ffff7ffd000-7ffff7ffe000 rw-p 0002d000 08:02 24123953 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7ffff7ffe000-7ffff7fff000 rw-p 00000000 00:00 0
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]Смотрим список программных сегментов в ELF заголовке:
$ readelf -Wl /bin/cat
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000040 0x0000000000000040 0x0000000000000040 0x0002d8 0x0002d8 R 0x8
INTERP 0x000318 0x0000000000000318 0x0000000000000318 0x00001c 0x00001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x000000 0x0000000000000000 0x0000000000000000 0x0016e0 0x0016e0 R 0x1000
LOAD 0x002000 0x0000000000002000 0x0000000000002000 0x004431 0x004431 R E 0x1000
LOAD 0x007000 0x0000000000007000 0x0000000000007000 0x0021d0 0x0021d0 R 0x1000
LOAD 0x009a90 0x000000000000aa90 0x000000000000aa90 0x000630 0x0007c8 RW 0x1000
DYNAMIC 0x009c38 0x000000000000ac38 0x000000000000ac38 0x0001f0 0x0001f0 RW 0x8
NOTE 0x000338 0x0000000000000338 0x0000000000000338 0x000020 0x000020 R 0x8
NOTE 0x000358 0x0000000000000358 0x0000000000000358 0x000044 0x000044 R 0x4
GNU_PROPERTY 0x000338 0x0000000000000338 0x0000000000000338 0x000020 0x000020 R 0x8
GNU_EH_FRAME 0x00822c 0x000000000000822c 0x000000000000822c 0x0002bc 0x0002bc R 0x4
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
GNU_RELRO 0x009a90 0x000000000000aa90 0x000000000000aa90 0x000570 0x000570 R 0x1DSO зависимости:
$ ldd /bin/cat
linux-vdso.so.1 (0x00007ffff7fce000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffff7dba000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7fcf000)Анализ /proc/$pid/maps:
- libc.so.6 — это libc-2.31.so
- ld-linux-x86-64.so.2 — это ld-2.31.so
- linux-vdso.so.1 — это [vdso], виртуальная DSO поставляемая ядром для ускорения работы четырех (для x86_64) системных вызовов, подробнее здесь
- [vvar] и [vsyscall] — устаревшая имплементация [vdso] (ядро держит обратную совместимость)
- [heap] и [stack] — здесь все понятно
/usr/bin/cat— это как разLOADсегменты из результатовreadelf, сдвинутые на0x555555554000ядром.
Кстати, можно заметить, что LOAD сегментов у нас 4, а маппингов 5. Все дело в GNU_RELRO технологии (и снова безопасность!): по этим адресам располагается PLT таблица (1 страница, 4К). Её заполняет динамический линковщик, а когда дело сделано, сбрасывает на ней право записи. Теперь, если приложение пытаются взломать путем подмены PLТ адреса какой-нибудь широко известной функции (например, printf@plt), переписать ничего не получится, ибо ядро пришлёт SIGSEGV. Проверяем адреса GNU_RELRO сегмента:
- 0x55555555e000 — 0x55555555f000: 4K (начало/конец маппинга, одна системная 4К страница)
- 0x555555554000 + 0xaa90 = 0x55555555ea90 ("ядерный" сдвиг плюс адрес начала
GNU_RELROсегмента) - 0x55555555ea90 & (~(0x1000 — 1)) = 0x55555555e000 (выравниваем предыдущий результат по границе 4К страницы => получаем начало маппинга)
- 0x55555555f000 — 0x570 = 0x55555555ea90 (от конца маппинга отнимаем размер
GNU_RELROсегмента, получаем, с поправкой на выравнивание 4К, начало маппинга) - Цифры сходятся, и это хорошо!
Беглая справка по выводу readelf:
- Offset = offset in ELF file
- VirtAddr = virtual address in application address space
- PhysAddr = physical address (не использовал это поле, интересно когда это нужно?)
- FileSiz = размер данных внутри ELF файла
- MemSiz = FileSiz + (область памяти, которую нужно занулить, используется для
.bss)
С точки зрения glibc получить все маппинги приложения по ходу его выполнения можно с помощью функции dl_iterate_phdr: справка и небольшая заметка — через этот интерфейс вы получите честные 4 LOAD сегмента, ровно как и в выводе readelf.
Итого, вооружившись всем вышеперечисленным, приступаем к достижению своей цели — перемапить LOAD сегменты.
Первый подход к снаряду
Нацеливаемся на большие страницы размером 2М (не THP), используем AArch64 или X86_64.
В основу первой версии elfremapper (так я решил наречь своё создание) положим функцию remap_segments из libhugetlbfs и чтобы сделать жизнь проще, сделаем нашу библиотечку статической. Смотрим в libhugetlbfs и делаем аналогично:
- Загрузка текущих LOAD сегментов используя
dl_iterate_phdr(спасибо тебе,glibc, за точность, пунктуальность и беспристрастность в представлении данных: никакой дополнительной магии сGNU_RELRO) - Проверка: сегменты не пересекаются с поправкой на выравнивание в 2М
- Дополнительно выравниваем сегменты в случае, если включен ASLR (в этом случае, сегменты имеют сдвиг 0x555555554000 и дополнительный рандомный сдвиг, который генерируется ядром каждый раз при запуске приложения — и эти сдвиги, разумеется, выравниваются ядром по границе 4К)
- Выделяем большие странички, используя специальную файловую систему
hugetlbfs(для каждого нашего маппинга кода и данных — свою копию, доступ MAP_PRIVATE) - Копируем туда все наши маппинги по очереди: открыли файл на
hugetlbfs, сделалиmmap, получили виртуальный базовый адрес от ядра, скопировали, сделалиmunmap. - Оставляем файловые дескрипторы открытыми для последующих операций.
- Проверочка — данные действительно скопировались? Мапим первый же файловый дескриптор от
hugetlbfs, куда только что переносили данные — и — там пусто!
Что ж, читаем более детально реализацию libhugetlbfs, смотрим в документацию ядра, и приходим к выводу, что MAP_PRIVATE маппинг, созданный с помощью hugetlbfs, теряется после вызова munmap (он же PRIVATE!), при этом неважно, в каком состоянии остался соответствующий файловый дескриптор. Выдержка из man mmap:
MAP_PRIVATE Create a private copy-on-write mapping. Updates to the mapping are not visible to other processes mapping the same file, and are not carried through to the underlying file. It is unspecified whether changes made to the file after the mmap() call are visible in the mapped region.А libhugetlbfs использует MAP_SHARED! Хорошо, скрепя сердце, делаем маппинги MAP_SHARED, открытые файлы тут же удаляем при помощи unlink из файловой системы. Продолжаем:
- Проверка: данные действительно скопировались, держим открытыми файловые дескрипторы (файлы-то мы удалили!)
- Отмапливаем наши текущие маппинги кода и данных — и — получаем
SIGSEGVна следующей заmunmapстрочке кода.
Как так??? libhugetlbfs делает munmap и не падает, а у нас так же не работает… Думаем. Думаем. Ещё раз думаем.
Когда выполняется код, он зачитывается CPU из ровно такого же маппинга, как и все остальные. Единственное отличие — этот маппинг имеет флаг права выполнения. Получается, как только мы отмапили сегмент кода, который выполняем, чтение следующей ассемблерной инструкции привело к обращению к адресному пространству, которое не принадлежит нашему процессу, и вполне резонно мы получаем SIGSEGV. Почему же не падает libhugetlbfs? Дело в том, что это DSO и, естественно, имеет свой отдельный маппинг, который остается нетронутым — мы перемапливаем только LOAD сегменты основного процесса.
Что делать? Ещё раз думаем… Читаем man mmap:
MAP_FIXED Don't interpret addr as a hint: place the mapping at exactly that address. addr must be suitably aligned: for most architectures a multiple of the page size is sufficient; however, some architectures may impose additional restrictions. If the memory region specified by addr and len overlaps pages of any existing mapping(s), then the overlapped part of the existing mapping(s) will be discarded. If the specified address cannot be used, mmap() will fail.Так-так, значит, если мы сделаем MAP_FIXED на существующий маппинг, то ядро само его отмапит. Интересно! Что если зайти в системный вызов mmap со старого маппинга, а выйти на новом маппинге? Если виртуальные адреса останутся прежними, тогда ничего не должно измениться. Проверяем:
- Не отмапливаем текущие маппинги кода и данных, берем открытые файловые дескрипторы (указывают на
hugetlbfs) и делаемMAP_SHARED+MAP_FIXEDмаппинг поверх существующих. Работает! - Проверяем
/proc/$pid/maps— вместо имени нашего приложения напротивLOADсегментов мы видим наши файлики, созданные вhugetlbfs, например,/dev/hugepages/g4PcpN (deleted)(точка монтирования/dev/hugepages, файлики создавались с помощьюmktemp)
Справочка: монтирование hugetlbfs (если не подмонтировано) и выделение страничек статически:
$ mkdir /dev/hugepages
$ mount -t hugetlbfs -o pagesize=2M none /dev/hugepages
$ sudo bash -c "echo 100 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages"Суммируем:
- Это подход, при котором перемапливающий код слинкован статически (перемапливает сам себя)
- Мы использовали
MAP_SHAREDдля сегментов кода и данных. "Будут последствия" — вероятно, подумали вы, и вы правы! - Проверяем сколько страниц реально потребляется — оказывается, что цифры здесь сходятся один в один, сколько нужно было страниц (например, 67), ровно столько страниц будет задействовано системой (
nr_hugepages—free_hugepages). Это очень важный пункт, так как в случае, если нам не хватит больших страниц, нужно аккуратно сообщить об ошибке, и в общем случае переключиться на использование обычных — т.е. вернуть все как было на место.
Прописываем алгоритм с учётом обработки out of memory (нехватки больших страниц):
- открываем файловый дескриптор на
hugetlbfs; - выделяем "большую" память с помощью
mmap(передаем файловый дескриптор); - здесь проверяем успешен ли
mmap, если нет, сообщаем об ошибке, возвращаем все на место; - копируем наш рабочий сегмент в выделенную память;
- отмапливаем "большую" память, оставляем открытым файловый дескриптор;
- делаем финальный
mmap(fixed|shared) поверх существующего рабочего маппинга; - этот системный вызов никогда не падает из-за нехватки памяти, так как маппинг shared (нет необходимости делать резервирование страниц в ядре), а вся "большая" память уже выделена на шаге 2 и проверена на корректность на шаге 3.
Чем чревато MAP_SHARED под маппингом кода/данных?
- Перестаёт работать
fork. Нет, он работает корректно, но не копирует shared маппинги между потомком и родителем (что логично), это в свою очередь приводит к хаотичным непредсказуемым ошибкам в связи с гонками при доступе к одной и той же памяти из потомка и родителя. - Перестают работать новые версии
gdb:gdb attach, корректная загрузкаcoreфайлов. При этом старые версии работают штатно, что интересно, но дальше наша команда в эту сторону не копала.
Есть ещё одна глобальная проблема, на которой стоит остановиться отдельно: perf перестает резолвить символы. В итоге perf top/perf record отображают россыпь неагрегированных друг с другом адресов. Увы и ах, perf использует для загрузки символов ELF файлы, указанные в том же самом файлике /proc/$pid/maps, который изменился. К счастью, с этой напастью можно бороться штатными средствами утилиты perf. В своё время, когда на свет появились JIT-компиляторы ( например, в таких популярных языках как Java или Python), в perf появился интерфейс для JIT кода: если утилита не может загрузить символы, она пытается загрузить их из файла /tmp/perf-$pid.map, который имеет предельно простой сsv формат (3 колонки: адрес начала, длина, имя символа). Итого, данная проблема закрывается так:
- компилируем наше приложение с дебаг-символами
- генерируем файлик с символами, используя утилиту
nm:
$ nm --numeric-sort --print-size --demangle $app | awk '$4{print $1" "$2" "$4}' | grep -Ee"^0" > /tmp/perf-$pid.map
Второй подход к снаряду
Как сделать текущее решение лучше? Заглядываем в libhugetlbfs, там финальный mmap выполняется с флажком MAP_PRIVATE|MAP_FIXED (пункт 6 алгоритма). Хорошо, пробуем, радуемся (fork/gdb в строю!), выкладываем в среду предрелизного нагрузочного тестирования, и спустя 3 недели работы продукт падает с SIGSEGV и нечитаемой полупустой "коркой".
Детальный анализ:
MAP_PRIVATEприводит к двойному потреблению больших страниц. В момент финальногоmmapядро копирует все shared страницы: это логично, срабатывает copy-on-write + reservation. Как минимум, есть пик двойного потребления памяти в процессе работы алгоритма, хотя в моём случае память не вернулась в систему даже после закрытия всех файловых дескрипторов наhugetlbfs.- Вторая волна выделения памяти приходится на финальный
mmap, и если в этот момент большие страницы заканчиваются,mmapпадает, и не просто падает, а с крайне неприятным сайд-эффектом: ядро отмапливает все перекрывающиеся сегменты, и если случается ошибка (нет памяти), то на место маппинги не возвращаются. Наблюдаем аналогичнуюmunmapситуацию — секция с кодом покидает адресное пространство процесса — и здравствуй,SIGSEGV!
Думаем! Думаем! Усиленно думаем!
libhugetlbfs данную ситуацию никак не обрабатывает — если все плохо, приложение завершается сигналом SIGABORT. Продукты Google/Facebook/Intel используют THP, но при этом активно пользуют mremap. Что если использовать его для больших страниц? Выделить private маппинг, но не отмапливать его, а просто перенести в адресном пространстве в другую область памяти, как раз на рабочие виртуальные адреса кода и данных.
Интересно, пробуем — и — получаем ошибку MAP_FAILED (EINVAL). Почему?
Оказалось, если проследить системный вызов mremap в исходном коде ядра Linux, то окажется, что Linux до сих пор не поддерживает перемещение адресных блоков на больших страницах (https://github.com/torvalds/linux/blob/master/mm/mremap.c):
if (is_vm_hugetlb_page(vma))
return ERR_PTR(-EINVAL);Багфикс — откатываемся на shared маппинг. Грусть-тоска меня съедает...
Третий подход к снаряду
И все же я хочу сделать решение лучше! Как? Вероятно, исходный постулат в виде "статическая линковка делает жизнь лучше" в данном конкретном случае не работает от слова совсем, скорее наоборот. Хорошо, создаем свою DSO!
Можно сбросить оковы, вздохнуть полной грудью и расправить крылья — теперь можно делать несколько системных вызовов и корректно обрабатывать коды возврата, а ещё можно отказаться от hugetlbfs. Если вы заметили, в первом подходе нужно было за один системный вызов подменить маппинг под кодом, который выполняется, иначе — SIGSEGV. И чтобы этого достичь с использованием mmap нужно передать и новые адреса, и указать на уже подготовленный блок памяти на больших страницах, т.е нужен файловый дескриптор на hugetlbfs (ну или сделать себе новый syscall, перекомпилить ядро, разлить по продакшн машинам, пройти security review… в общем, вы поняли).
Алгоритм меняем на следующий:
- Делаем анонимный 4K маппинг ровно с одной целью — заставить ядро найти в адресном пространстве процесса место для текущих рабочих маппингов кода и данных.
- Переносим (
mremap) текущие рабочие маппинги в только что выделенное адресное пространство (случается перекрытие адресов => только что выделенный маппинг теряется без единого page fault). Так как код, который это делает, находится в DSO и имеет свой выделенный маппинг (который мы не трогаем), тоSIGSEGVне случается. - Выделяем на старых рабочих виртуальных адресах новый маппинг на больших страницах (
mmapprivate + fixed + huge2m), по факту, это место сейчас вакантно. - Если на этом этапе заканчивается память — возвращаем старые маппинги (которые мы утащили в пункте 2 в сторону) на старое место, если все хорошо — продолжаем.
- Копируем все бинарные данные из старых маппингов в новые.
- Отмапливаем старые маппинги — возвращаем 4К память системе.
Как видно, DSO явно меняет мир к лучшему. Какие же подводные камни ожидают нас в этом светлом и радужном месте?
- Нужно заранее заполнить GOT/PLT таблицы, иначе вернется старый, добрый и всеми крайне любимый
SIGSEGV. Дело в том, что по умолчанию динамический линковщик работает в ленивом режиме, а именно резолвит имена внешних DSO функций в адреса только по мере их использования. Эти таблицы хранятся в LOAD сегментах (помните историю сGNU_RELRO?). Наша DSO также использует спектрlibcфункций (mmap/mremap/memcpy), таблицы PLT/GOT этих функций лежат в LOAD сегменте нашего DSO, если резолвинг еще не выполнялся, запускается динамический линковщик. Если LOAD сегментов основного приложения нет на фиксированных виртуальных адресах, линковщик в ходе своей работы получает "access violation". Честно говоря, не копал, чего конкретно не хватило: heap живет отдельно (где хранится метаинформация линковщика), LOAD сегмент моего DSO живет также отдельно (не перемапливается), однако, как говорится, факт остается фактом. Данная проблема решается достаточно просто: добавляем флаг компиляции-Wl,-znow, что заставляет динамический линковщик быть более расторопным и сделать все необходимые расчеты на старте приложения (до входа вmain). - Если в ходе работы
forkпамять заканчивается, процесс получаетSIGBUS. Да, мы сделали честный private маппинг, иforkего корректно копирует, дальше происходит copy-on-write, ядро пытается найти свободную большую страницу, и если этого сделать не получается, посылаетSIGBUS. Что ж, это лучше, чем получить неопределенное поведение и повреждение данных, но все же хочется плавно переключиться на обычные страницы. Признаюсь, мы не писали обработчик дляSIGBUS, чтобы в нем выполнить обратное перемапливание на 4К в потомке, скопировав данные родителя. На этом месте запал иссяк, и я просто сдвинул код перемапливания после вызоваfork. ПрипомнилсяTHP— у этой технологии есть положительные стороны, в частности, данный кейс, согласно беглому поиску, должен обрабатываться корректно, хотя как он реально обрабатывается на практике — ни разу не видел. Если знаете, расскажите.
Что с NUMA?
Как известно, для каждой NUMA ноды большие страницы выделяются отдельно. Не верите?
$ echo /sys/devices/system/node/node*/hugepages/hugepages-2048kBНаше Linux ядро в случае с NUMA и виртуальными машинами ведет себя хитро и жестоко. Виртуальная машина обычно ограничена внутри одной NUMA ноды (/sys/fs/cgroup/cpuset/$vm/cpuset.mems). Когда выполняется системный вызов mmap, то он анализирует доступные страницы на всех NUMA нодах, если памяти суммарно хватает, вызов завершается успешно. Потом случается page fault, ядро начинает искать большие странички на текущей NUMA ноде, не находит свободных и посылает процессу SIGBUS. В сумме, память как бы есть, но на самом деле её нет!
Чтобы побороть подобные всплески потребления больших страниц, мы пришли к следующей схеме:
- Прикидываем, сколько может быть виртуальных машин в среднем на NUMA ноде и сколько страниц можно безболезненно выделить — выделяем статически
- Остальное оформляем через
overcommitс большим запасом (скажем, 10Гб):
echo 5120 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_overcommit_hugepages
overcommit-страницы выделяются на лету, и, конечно же, существует ненулевая вероятность, что ядро не сможет выделить странички мгновенно, будет дефрагментация, и т.д. Однако для таких приложений как БД, когда процесс стартует один раз за месяц, и потом резидентно живет в памяти сервера — приемлемо (требуется лишь один раз перемапить код и данные при старте).
Битва за HEAP
Помните, когда я перечислял недостатки libhugetlbfs, я рассказал, что библиотека отмапливает HEAP сегмент от адресного пространства приложения. Сейчас расскажу, почему это происходит.
Когда мы инструктируем линковщик выровнять LOAD сегменты внутри ELF файла по границе 2M, то этот процесс никак не затрагивает HEAP. Все корректно, HEAP создается ядром при старте приложения, и выравнивается по границе в 4К. Получается, что "куча" вплотную "приклеена" к последнему LOAD сегменту. Когда мы перемапливаем последний LOAD сегмент, мы выравниваем его конец по 2М, и, разумеется, это перекрывается с "кучей". Дальше мы копируем только данные LOAD сегмента, а про "кучу" никто не вспоминает. Кроме того, перемапливание обычно делается в начале работы приложения, то есть "куча" ещё маленькая, поэтому часто случается, что вся она умещается в "хвосте" последнего LOAD сегмента. Итог печальный:
- потеря данных, которые были сохранены на куче;
- потеря самого HEAP сегмента — так как он часто целиком перекрывается LOAD сегментом, то полностью отмапливается, после этого
brkперестает выделять память.
Почему ядро Linux радикально отмапливает HEAP сегмент, если на него сверху кладется большая страница, покрывающая "кучу" целиком — вопрос открытый. Если знаете, просветите!
Решить эту проблему получилось достаточно просто:
- адреса "кучи" зачитываются из
/proc/$pid/maps, далее, если она перекрывается с последним LOAD сегментом, её данные также копируются в новый маппинг по старым виртуальным адресам; - если "куча" целиком попадает в "хвост" последнего сегмента, она искусственно увеличивается на размер 2М, то есть после перекрытия адресов часть HEAP'a все же остается нетронутой, экспериментально доказано, что в этом случае
brkпродолжает работу корректно, системный аллокатор изglibcтоже. Что будет, если системный аллокатор освободит всю выделенную память (включая ту, которая была перемаплена на большие страницы) — неизвестно. Предполагаю, чтоbrkвозвращает ошибку, когда аллокатор пробует это сделать, и эта ошибка обрабатывается корректно, ибо "крашей", связанных с этой проблемой, я пока не видел.
Если вы используете аллокатор памяти, получающий память через mmap (anonymous), например, jemalloc, то эта проблема вас не коснется.
Также, если включить ASLR, то ядро генерирует рандомно сдвинутый стартовый адрес для "кучи", обычно достаточно далеко от LOAD сегментов (>2M), поэтому это как раз тот редкий случай, когда ASLR не добавляет, а, наоборот, устраняет проблемы.
perf
Много слов уже сказано о том, как и что мы делали, чтобы получить стабильно работающее приложение, а также упомянуто увеличение TPS в OLTP тестах. Однако увидеть воочию на реальном железе эффект применения больших страниц лучше всего с использованием perf. Дело в том, что узких мест в конкретной программе может быть много, и применение нашего опыта для вашего проекта может не дать вообще никаких результатов. Тем не менее, perf обязательно покажет, как изменилась картина для процессора.
Для анализа используем эту статью, в частности, табличку с выдержкой из официальной документации Intel на события, которые можно посчитать и снять с помощью perf.
| Mnemonic | Desctiption | Event Num. | Umask Value |
|---|---|---|---|
| DTLB_LOAD_MISSES.MISS_CAUSES_A_WALK | Misses in all TLB levels that cause a page walk of any page size. | 08H | 01H |
| DTLB_STORE_MISSES.MISS_CAUSES_A_WALK | Miss in all TLB levels causes a page walk of any page size. | 49H | 01H |
| DTLB_LOAD_MISSES.WALK_DURATION | This event counts cycles when the page miss handler (PMH) is servicing page walks caused by DTLB load misses. | 08H | 10H |
| ITLB_MISSES.MISS_CAUSES_A_WALK | Misses in ITLB that causes a page walk of any page size. | 85H | 01H |
| ITLB_MISSES.WALK_DURATION | This event counts cycles when the page miss handler (PMH) is servicing page walks caused by ITLB misses. | 85H | 10H |
| PAGE_WALKER_LOADS.DTLB_MEMORY | Number of DTLB page walker loads from memory. | BCH | 18H |
| PAGE_WALKER_LOADS.ITLB_MEMORY | Number of ITLB page walker loads from memory. | BCH | 28H |
Конструируем из таблички запрос на снятие метрик (скажем, за 30 секунд):
$ perf stat -e cycles -e cpu/event=0x08,umask=0x10,name=dwalkcycles/ -e cpu/event=0x85,umask=0x10,name=iwalkcycles/ -e cpu/event=0x08,umask=0x01,name=dwalkmiss/ -e cpu/event=0x85,umask=0x01,name=iwalkmiss/ -e cpu/event=0xbc,umask=0x18,name=dmemloads/ -e cpu/event=0xbc,umask=0x28,name=imemloads/ -p $app_pid sleep 30Берем sysbench для генерации синтетической OTLP нагрузки здесь. Далее, компилируем MySQL 8.0 (в нашем случае, это 8.0.21).
Запускаем сервер на NUMA0:
- разворачиваем БД в /dev/shm (InnoDB / UTF8);
- загружаем 10 таблиц по 1М записей (2.4 GB)
- CPU: Intel® Xeon® Gold 6151 CPU @ 3.00GHz, no boost/turbo
- No ASLR
- innodb_buffer_pool = 88G
- innodb_buffer_pool_instances = 64
- innodb_data_file_path=ibdata1:128M:autoextend
- threadpool_size = 64
- performance_schema=ON
- performance_schema_instrument='wait/synch/%=ON'
- innodb_adaptive_hash_index=0
- log-bin=mysql-bin
Далее, запускаем sysbench (OLTP PS / 128 threads) на NUMA1:
$ sysbench --threads=128 --report-interval=1 --thread-init-timeout=180 --db-driver=mysql --mysql-socket=/tmp/mysql.sock --mysql-db=sbtest --mysql-user=root --tables=10 --table-size=1000000 --rand-type=uniform --time=3600 --histogram --db-ps-mode=disable oltp_point_select runНагрузка CPU-bound / read-only.
Снимаем perf stats с оригинала (TPS=581K):
3,213,429,932,057 cycles (57.15%)
194,753,410,016 dwalkcycles (57.14%)
139,241,762,335 iwalkcycles (57.14%)
3,977,146,385 dwalkmiss (57.14%)
4,969,951,701 iwalkmiss (57.14%)
15,102,884 dmemloads (57.14%)
30,794 imemloads (57.14%)
30.005683086 seconds time elapsedТеперь перемапливаем на большие страницы код и данные (TPS=641K):
3,213,038,157,768 cycles (57.15%)
78,822,186,791 dwalkcycles (57.15%)
18,042,959,892 iwalkcycles (57.15%)
1,306,771,287 dwalkmiss (57.15%)
695,958,356 iwalkmiss (57.14%)
18,090,550 dmemloads (57.15%)
4,574 imemloads (57.15%)
30.005697688 seconds time elapsedСравниваем:
iwalkcyclesупал в 7.7 раза,dwalkcyclesв 2.4 разаiwalkmiss— 7.1 раза,dwalkmiss— 3 раза- TPS: +10.3%
Следует признать тот факт, что применение компиляторных технологий, серьезно улучшающих производительность, снижает эффект, однако он все же остается стабильно положительным. Причина проста — эти технологии направлены на концентрацию горячего кода в одном месте, что крайне положительно сказывается на всем кэшировании внутри CPU, включая TLB.
Применяем PGO/LTO/BOLT к тому же коду (обучающая нагрузка — OLTP RW), запускаем те же тесты.
perf stats без больших страниц (TPS=915K):
3,212,892,465,135 cycles (57.14%)
175,161,815,648 dwalkcycles (57.15%)
64,908,489,131 iwalkcycles (57.15%)
3,579,819,559 dwalkmiss (57.15%)
2,108,905,920 iwalkmiss (57.15%)
21,031,821 dmemloads (57.15%)
85,002 imemloads (57.14%)
30.004624838 seconds time elapsedС большими страницами под кодом и данными (TPS=952K):
3,213,313,736,349 cycles (57.15%)
92,547,731,364 dwalkcycles (57.15%)
22,334,822,336 iwalkcycles (57.15%)
1,611,692,765 dwalkmiss (57.15%)
804,414,164 iwalkmiss (57.14%)
25,627,581 dmemloads (57.12%)
15,717 imemloads (57.12%)
30.006456928 seconds time elapsedСравниваем:
iwalkcyclesупал в 2.9 раза,dwalkcyclesв 1.9 разаiwalkmiss— 2.6 раза,dwalkmiss— 2.2 раза- TPS: +4%
Резюмируем: диспетчер, взлет прошел успешно, полет нормальный:

Что дальше?
Что ж, технология перемапливания кода и данных на большие страницы имеет право на жизнь, учитывая текущее состояние API ядра и библиотеки glibc. Однако, обмозговав всё, что здесь написано, приходишь к одной простой мысли: почему не создать маппинги сразу на больших страницах? Во всех подходах мы имели дело с уже созданным маппингом (дефолтные системные страницы), который потом, приседая и ударяя в бубен, перекладывался на другой маппинг (2M страницы).
Daniel Black из MariaDB предложил простое и элегантное решение — сделать всю эту работу сразу в динамическом загрузчике glibc. Единственная проблема — способ запуска приложения. Если запускать по-старинке, то LOAD сегменты загружаются в память ядром, а изменять ядро очень не хочется. Однако, динамический загрузчик умеет запускать приложения самостоятельно! Пробовали запускать динамический загрузчик? Да-да, по факту, это DSO, но на самом деле — универсальный солдат:
$ /lib64/ld-linux-x86-64.so.2
Usage: ld.so [OPTION]... EXECUTABLE-FILE [ARGS-FOR-PROGRAM...]
You have invoked `ld.so', the helper program for shared library executables.
This program usually lives in the file `/lib/ld.so', and special directives
in executable files using ELF shared libraries tell the system's program
loader to load the helper program from this file. This helper program loads
the shared libraries needed by the program executable, prepares the program
to run, and runs it. You may invoke this helper program directly from the
command line to load and run an ELF executable file; this is like executing
that file itself, but always uses this helper program from the file you
specified, instead of the helper program file specified in the executable
file you run. This is mostly of use for maintainers to test new versions
of this helper program; chances are you did not intend to run this program.
...
$ /lib64/ld-linux-x86-64.so.2 /bin/echo "HELLO, WORLD"
HELLO, WORLDПоложительные моменты этого решения.
- Не требуется писать дополнительный код в приложение.
- Можно загружать на большие страницы не только LOAD сегменты исполняемого бинаря, но также и DSO, от которых оно зависит.
- Загрузка на большие страницы становится динамической: один и тот же код вызывается как при старте приложения, так и при вызове
dlopen.
Попытка сделать "грязный" патч на наш локальный форк glibc выявило лишь одну неприятную особенность — серьезный перерасход памяти. Дело в том, что типовые системные DSO имеют крайне маленькие LOAD сегменты. Порой, даже 4К страница для них является избыточной. Кроме того, каждая системная DSO содержит внутри себя несколько маленьких LOAD сегментов (вспоминаем про безопасность). И, честно говоря, для таких маленьких библиотек большие страницы не требуется вовсе — стандартный TLB буфер и системные 4К страницы справляются со своей задачей на ура. Поэтому для подхода с динамическим загрузчиком нужно сделать фильтр: класть на большие страницы только основную программу и, скажем, список наиболее тяжелых и активно используемых DSO.
Что ж, если вдруг появится свободное время, я обязательно опишу свои приключения в мире glibc, поговаривают, добиться включения своего патча в эту библиотеку сродни попытке пробежать марафон: без длительной кропотливой подготовки не получится.
Благодарности
Я хотел бы лично поблагодарить команду облачных СУБД в Российском исследовательском институте Huawei, которая принимала активное участие в проектировании, исследованиях и ревью.
К читателю
Если у вас есть замечания к написанному, вы видите явную ошибку или опечатку, пропущена ссылка или нарушен копирайт, милости просим в комментарии, я постараюсь исправить, уточнить, исследовать и дополнить.
Исходный код, выкованный кровью и потом, выложен в открытый доступ здесь.
Использованные материалы
- https://wiki.debian.org/Hugepages
- https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt
- https://www.1024cores.net/home/in-russian/ram---ne-ram-ili-cache-conscious-data-structures
- https://medium.com/applied/applied-c-memory-latency-d05a42fe354e
- https://yandex.ru/images
- https://e7.pngegg.com/pngimages/908/632/png-clipart-man-wearing-black-jacket-illustration-morpheus-the-matrix-neo-red-pill-and-blue-pill-youtube-good-pills-will-play-fictional-character-film.png
- https://alexandrnikitin.github.io/blog/transparent-hugepages-measuring-the-performance-impact/
- https://www.percona.com/blog/2019/03/06/settling-the-myth-of-transparent-hugepages-for-databases/
- https://bugs.mysql.com/bug.php?id=101369
- https://jira.mariadb.org/browse/MDEV-24051
- https://0xax.gitbooks.io/linux-insides/content/SysCall/linux-syscall-4.html
- https://man7.org/linux/man-pages/man7/vdso.7.html
- https://man7.org/linux/man-pages/man3/dl_iterate_phdr.3.html
- https://github.com/dmitriy-philimonov/elfremapper
- https://github.com/akopytov/sysbench
- https://i1.wp.com/freethoughtblogs.com/affinity/files/2016/06/facepalm_estatua.jpg
- https://pbs.twimg.com/media/EroZF0DXYAIDYI4.jpg

{kind=link}
{kind=link}
{kind=link}