Совсем недавно мы выпустили в свет первую бета-версию нашей онлайн-читалки, с которой можно ознакомиться, почитав книгу Михаила Лермонтова «Герой нашего времени». Эта читалка — результат почти семимесячной работы, пять из которых ушло только на разработку движка. Казалось бы, в интернете уже есть бесплатные и открытые JavaScript-движки для чтения электронных книг и такой долгий срок может вызвать сомнения в профпригодности разработчика (то есть меня). Но есть одно большое и жирное «НО». Мы поставили перед собой слишком амбициозную и трудновыполнимую задачу: мы хотели использовать один и тот же движок на разных устройствах, в том числе маломощных, таких как айфон или электронная читалка.
В чём же заключается трудновыполнимость задачи? В первую очередь — в очень низкой скорости работы веб-приложений на айфоне. Например, мобильный Сафари по моим прикидкам работает раз в 100 медленнее своего десктопного собрата. Если на декстопе одна и та же операция выполняется 10 мс и совершенно незаметна для пользователя, то на айфоне она может выполняться больше секунды. Для сравнения: первая версия движка разбивала небольшую главу на страницы примерно за 15 секунд. Сейчас, спустя полгода, он делает то же самое менее, чем за секунду и вполне сносно работает в нашем приложении booq.
В этой статье я не буду заострять внимание на том, как сделать свою читалку, но поделюсь опытом оптимизации веб-приложения под айфон. Статья будет интересна не только разработчикам под мобильные устройства, но и обычным веб-технологам. Ведь если ваше приложение/сайт будет быстро работать на мобильном устройстве, то представьте, с какой скоростью оно будет работать на десктопе.
Для начала стоит объяснить, почему мы выбрали именно веб-технологии в качестве основы для читалки. Во-первых, это их распространённость. Сейчас довольно сложно найти устройство, которое не имеет встроенного браузера. Телефоны, компьютеры, нетбуки, планшеты, электронные книги – все они способны прочитать HTML, украсить его с помощью CSS и оживить через JavaScript. Имея один и тот же движок, мы можем легко создавать приложения для различных платформ и устройств. Во-вторых, ни один «классический» движок читалки не способен отобразить то, что может веб-браузер. Таблицы, векторная графика, аудио/видео контент, интерактивные элементы – всё это давно и успешно работает в браузерах. Представьте, что вы читаете научную книгу и тут же видите видеоролик, демонстрирующий описываемый процесс. Ну или читаете детектив, в котором нужно пройти паззл, чтобы открыть следующую главу :). Возможности ограничены только фантазией и умениями разработчика.
Всё это красивая маркетинговая обёртка, но спустимся с небес на землю и посмотрим, каким должен быть движок с технической точки зрения:
В качестве тестовой площадки использовался айфон 2G с прошивкой 3.1 и глава из книги Ивана Миронова «Замурованные» весом 500 КБ. Такая большая глава скорее исключение, чем правило, однако задаёт хорошую планку по производительности, ниже которой не стоит опускаться.
Итак, приступим к оптимизации.
Сразу хочу огорчить любителей наставить кучу фрэймворков на страницу и обвешать их плагинами, чтобы решить простые задачи вроде перетаскивания блоков или выбора элементов по CSS-селектору: объём JS-кода на странице имеет огромное значение, по крайней мере для мобильного Safari. Например, парсинг и инициализация популярного jQuery занимает 1400 мс для оригинальной, не сжатой версии (155 КБ) и 1200 мс для сжатой (76 КБ). Несмотря на то, что сжатая версия в 2 раза меньше оригинала, по функциональности они идентичны: отсюда такая «небольшая» разница в скорости парсинга. То есть на скорость влияет не длина названий переменных, а количество функций, объектов, методов и так далее. Для сравнения: на десктопе парсинг занимает порядка 30 мс.
Идеальный вариант: держать весь JS-код в самом низу страницы и вообще отказаться от фрэймворков. Так как сам по себе WebKit поддерживает много чего, я вынес стандартные DOM-операции (добавление событий, поиск элементов по селектору и т.д.) в виде отдельного дополнительного модуля, а для десктоп-версии переопределил этот слой, чтобы вызовы транслировались в jQuery.
Сама читалка ориентирована на формат ePub, в котором каждая глава книги представлена отдельным документом в формате XHTML. Главу нужно каким-то образом передать в JavaScript, чтобы он её распарсил, разбил на страницы и начал показывать.
Тут стоит сказать пару слов о принципе вывода контента на экран. Напомню, что движок должен поддерживать два режима чтения: постраничный и «портянкой». Поэтому я решил весь контент обрамить в две обёртки: первая является своеобразным «окном», а вторая смещает контент вверх-вниз. Подобрав правильные размеры окна и смещения контента, можно создать иллюзию разбитой на страницы главы:
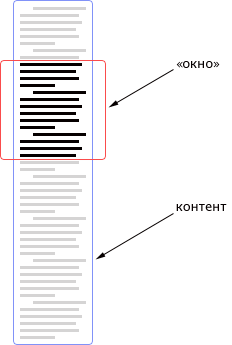
Так как мне в любом случае нужно всё содержимое главы, а для расчётов размеров страниц мне нужны полноценные DOM-элементы, я решил вывести главу прямо в HTML:
И тут же столкнулся с серьёзной проблемой: парсинг и сопутствующее отображение главы длилось аж 7 секунд. Я предположил, что основное время занимает именно отрисовка контента, поэтому в качестве эксперимента скрыл контент с помощью
На этот раз парсинг страницы занимал 800 мс, что очень даже неплохо: ускорил почти в 10 раз. А так как у айфона довольно маленький экран, достаточно было достать из дерева несколько первых элементов и показать их, чтобы пользователь мог начать читать, пока на фоне идёт обсчёт главы.
В принципе, это уже довольно большая победа в плане производительности и можно было бы заняться другими вещами, но интуиция мне подсказывала, что можно ещё немного снизить время парсинга.
Я предположил, что когда HTML разбирается прямо в теле документа, браузер делает какие-то дополнительные действия, чтобы элементы могли в нужный момент показаться на странице. Например, поиск и применение соответствующих CSS-правил. Лично мне эти действия на данный момент не нужны: мне нужно как можно быстрее передать содержимое главы в виде DOM-дерева прямо в JavaScript. Как заставить браузер не парсить определённый фрагмент документа? Правильно, закомментировать его:
Смех смехом, но время парсинга страницы сократилось до 350 мс. А комментарий — это ведь полноценный DOM-элемент, к которому можно обратиться через JavaScript и получить его содержимое:
Суммарное время парсинга страницы и разбора кода в дерево составило примерно 550 мс (против 800 мс в предыдущем варианте), что, на мой взгляд, очень даже неплохо.
Итак, содержимое главы я получил и распарсил, теперь нужно разбить главу на страницы. Во время оптимизации парсинга я понял, что мой первоначальный вариант вывода главы в постраничном режиме в виде окна и движущегося контента имел ряд недостатков. Во-первых, нужно выводить (отрисовывать) всю главу целиком, что, как вы уже поняли, занимает очень много времени. Во-вторых, при таком раскладе я не мог вывести больше одной страницы на экран: для второй страницы пришлось бы полностью дублировать всю главу, что, опять же, медленно и вызовет неминуемый крэш приложения из-за нехватки памяти на больших главах.
После примерно двух месяцев безуспешных попыток написать постраничную разбивку с приемлемым временем исполнения было найдено довольно неплохое решение. Вкратце, что оно из себя представляет.
По сути глава книги — это набор параграфов. Параграфы можно представить как элементы первого уровня. С учётом скорости отрисовки HTML-контента в айфоне, для максимально быстрого отображения одной страницы нужно определить минимальный набор элементов первого уровня, который необходим для её представления. У меня есть вся глава в виде списка элементов первого уровня, а также список страниц. Страница представляет из себя объект, в котором хранятся порядковые номера начального и конечного элемента первого уровня, размер окна и смещения. Получилась довольно компактная и быстрая конструкция: для отображения одной страницы достаточно клонировать набор элементов первого уровня и вывести их на экран, указав правильное смещение и размер окна.
Для того, чтобы просчитать все страницы, нужно знать габариты каждого элемента первого уровня, их внутренние и внешние отступы, бордюры, размер шрифта и так далее. Чтобы получить все эти данные, элементы должны быть на странице и к ним должы быть применены стили. Для этих целей я создал специальный скрытый контейнер, который наследует все стилевые описания самой страницы, добавлял в него параграфы и проводил расчёты.
Для получения необходимых характеристик элемента нужно обратиться к его CSS-свойствам. За основу я взял функцию
Так как мне нужно было получить сразу довольно много свойств, это функция, судя по профайлеру из Web Inspector (имеется в виду десктопный браузер, на айфоне таких инструментов отладки нет, что сильно усложняет работу), была самой медленной. Как оказалось, обращение к
После такой оптимизации функция
Следующий шаг: правильно «размазать» расчёт страниц во времени. Дело в том, что пока выполняется JS, интерфейс браузера полностью блокируется, а также вступают в действия ограничения на время выполнения скрипта. Могла сложиться ситуация, что экран «застынет» секунд на 20—30, а потом и вовсе вывалится с ошибкой о превышении таймаута на выполнение. Современный способ избавления от таких проблем — Web Workers, но мобильный Сафари их не поддерживает. Поэтому будем использовать проверенный «дедовский» метод, работающий во всех браузерах: вызывать каждую итерацию обсчёта страниц через
Функция работает следующим образом. Например, нам нужно обсчитать 30 элементов первого уровня. Отдаём массив этих элементов в функцию
У такого подхода есть один важный аспект — это нагрузка на одну итерацию. В данном случае — это сколько элементов нужно обсчитать за один вызов функции
Поэтому нужно найти некую золотую середину, чтобы и время расчёта не сильно увеличивать, и не снижать отзывчивость интерфейса. Я решил ориентироваться не на количество элементов первого уровня, а на их объём, который можно получить через свойство
После того, как посчиталась одна группа, нужно очистить скрытый контейнер и освободить ресурсы для следующей группы элементов. Самый простой способ очистить содержимое контейнера — это обнулить свойство
Однако «самый простой» не всегда означает «самый быстрый» — как показали замеры, вот такой способ работает намного быстрее:
Пожалуй, пока всё. В этой статье были рассмотрены некоторые особенности парсинга и обсчёта больших объёмов данных на маломощных устройствах. На практике все описанные трюки оказались очень эффективными. Например, я протестировал главу объёмом более 1 МБ: наша читалка смогла её переварить где-то за 30—40 секунд, в то время как другие (причём довольно популярные) читалки из AppStore, написанные на Objective C/C++, попросту падали.
В следующей статье рассмотрим некоторые факторы, влияющие на время отрисовки одной страницы в айфоне, а также некоторые трюки, позволяющие это время заметно снизить.
Сергей Чикуёнок
В чём же заключается трудновыполнимость задачи? В первую очередь — в очень низкой скорости работы веб-приложений на айфоне. Например, мобильный Сафари по моим прикидкам работает раз в 100 медленнее своего десктопного собрата. Если на декстопе одна и та же операция выполняется 10 мс и совершенно незаметна для пользователя, то на айфоне она может выполняться больше секунды. Для сравнения: первая версия движка разбивала небольшую главу на страницы примерно за 15 секунд. Сейчас, спустя полгода, он делает то же самое менее, чем за секунду и вполне сносно работает в нашем приложении booq.
В этой статье я не буду заострять внимание на том, как сделать свою читалку, но поделюсь опытом оптимизации веб-приложения под айфон. Статья будет интересна не только разработчикам под мобильные устройства, но и обычным веб-технологам. Ведь если ваше приложение/сайт будет быстро работать на мобильном устройстве, то представьте, с какой скоростью оно будет работать на десктопе.
Задача
Для начала стоит объяснить, почему мы выбрали именно веб-технологии в качестве основы для читалки. Во-первых, это их распространённость. Сейчас довольно сложно найти устройство, которое не имеет встроенного браузера. Телефоны, компьютеры, нетбуки, планшеты, электронные книги – все они способны прочитать HTML, украсить его с помощью CSS и оживить через JavaScript. Имея один и тот же движок, мы можем легко создавать приложения для различных платформ и устройств. Во-вторых, ни один «классический» движок читалки не способен отобразить то, что может веб-браузер. Таблицы, векторная графика, аудио/видео контент, интерактивные элементы – всё это давно и успешно работает в браузерах. Представьте, что вы читаете научную книгу и тут же видите видеоролик, демонстрирующий описываемый процесс. Ну или читаете детектив, в котором нужно пройти паззл, чтобы открыть следующую главу :). Возможности ограничены только фантазией и умениями разработчика.
Всё это красивая маркетинговая обёртка, но спустимся с небес на землю и посмотрим, каким должен быть движок с технической точки зрения:
- быть кроссбраузерным и кроссплатформенным;
- иметь модульную структуру, чтобы легче было создавать версии под различные устройства;
- поддерживать два режима чтения: постраничный и с прокруткой (как обычная веб-страница), а также быстро переключаться между ними;
- обрабатывать главы объёмом 1 МБ+ (для сравнения: первый том «Войны и мира» Толстого весит 1,2 МБ);
- иметь гибкие настройки внешнего вида (по сути, ограничены возможностями CSS).
В качестве тестовой площадки использовался айфон 2G с прошивкой 3.1 и глава из книги Ивана Миронова «Замурованные» весом 500 КБ. Такая большая глава скорее исключение, чем правило, однако задаёт хорошую планку по производительности, ниже которой не стоит опускаться.
Итак, приступим к оптимизации.
Объём JS-кода
Сразу хочу огорчить любителей наставить кучу фрэймворков на страницу и обвешать их плагинами, чтобы решить простые задачи вроде перетаскивания блоков или выбора элементов по CSS-селектору: объём JS-кода на странице имеет огромное значение, по крайней мере для мобильного Safari. Например, парсинг и инициализация популярного jQuery занимает 1400 мс для оригинальной, не сжатой версии (155 КБ) и 1200 мс для сжатой (76 КБ). Несмотря на то, что сжатая версия в 2 раза меньше оригинала, по функциональности они идентичны: отсюда такая «небольшая» разница в скорости парсинга. То есть на скорость влияет не длина названий переменных, а количество функций, объектов, методов и так далее. Для сравнения: на десктопе парсинг занимает порядка 30 мс.
Идеальный вариант: держать весь JS-код в самом низу страницы и вообще отказаться от фрэймворков. Так как сам по себе WebKit поддерживает много чего, я вынес стандартные DOM-операции (добавление событий, поиск элементов по селектору и т.д.) в виде отдельного дополнительного модуля, а для десктоп-версии переопределил этот слой, чтобы вызовы транслировались в jQuery.
Парсинг HTML
Сама читалка ориентирована на формат ePub, в котором каждая глава книги представлена отдельным документом в формате XHTML. Главу нужно каким-то образом передать в JavaScript, чтобы он её распарсил, разбил на страницы и начал показывать.
Тут стоит сказать пару слов о принципе вывода контента на экран. Напомню, что движок должен поддерживать два режима чтения: постраничный и «портянкой». Поэтому я решил весь контент обрамить в две обёртки: первая является своеобразным «окном», а вторая смещает контент вверх-вниз. Подобрав правильные размеры окна и смещения контента, можно создать иллюзию разбитой на страницы главы:
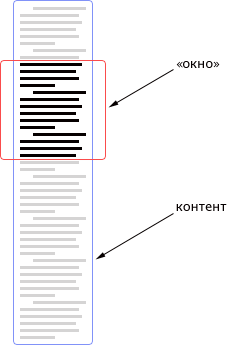
Так как мне в любом случае нужно всё содержимое главы, а для расчётов размеров страниц мне нужны полноценные DOM-элементы, я решил вывести главу прямо в HTML:
<div id="window">
<div id="content">
<p>В департаменте… но лучше не называть, в каком департаменте…</p>
</div>
</div>И тут же столкнулся с серьёзной проблемой: парсинг и сопутствующее отображение главы длилось аж 7 секунд. Я предположил, что основное время занимает именно отрисовка контента, поэтому в качестве эксперимента скрыл контент с помощью
display: none:<div id="window">
<div id="content" style="display:none">
<p>В департаменте… но лучше не называть, в каком департаменте…</p>
</div>
</div>На этот раз парсинг страницы занимал 800 мс, что очень даже неплохо: ускорил почти в 10 раз. А так как у айфона довольно маленький экран, достаточно было достать из дерева несколько первых элементов и показать их, чтобы пользователь мог начать читать, пока на фоне идёт обсчёт главы.
В принципе, это уже довольно большая победа в плане производительности и можно было бы заняться другими вещами, но интуиция мне подсказывала, что можно ещё немного снизить время парсинга.
Я предположил, что когда HTML разбирается прямо в теле документа, браузер делает какие-то дополнительные действия, чтобы элементы могли в нужный момент показаться на странице. Например, поиск и применение соответствующих CSS-правил. Лично мне эти действия на данный момент не нужны: мне нужно как можно быстрее передать содержимое главы в виде DOM-дерева прямо в JavaScript. Как заставить браузер не парсить определённый фрагмент документа? Правильно, закомментировать его:
<div id="window">
<div id="content">
<!--
<p>В департаменте… но лучше не называть, в каком департаменте…</p>
-->
</div>
</div>Смех смехом, но время парсинга страницы сократилось до 350 мс. А комментарий — это ведь полноценный DOM-элемент, к которому можно обратиться через JavaScript и получить его содержимое:
var elems = document.getElementById('content').childNodes;
for (var i = 0, il = elems.length; i < il; i++) {
var el = elems[i];
if (el.nodeType == 8) { //comment
var div = document.createElement('div');
div.innerHTML = el.nodeValue;
// внутри div теперь полноценное DOM-дерево, с которым можно работать
break;
}
}Суммарное время парсинга страницы и разбора кода в дерево составило примерно 550 мс (против 800 мс в предыдущем варианте), что, на мой взгляд, очень даже неплохо.
Расчёт размеров страниц
Итак, содержимое главы я получил и распарсил, теперь нужно разбить главу на страницы. Во время оптимизации парсинга я понял, что мой первоначальный вариант вывода главы в постраничном режиме в виде окна и движущегося контента имел ряд недостатков. Во-первых, нужно выводить (отрисовывать) всю главу целиком, что, как вы уже поняли, занимает очень много времени. Во-вторых, при таком раскладе я не мог вывести больше одной страницы на экран: для второй страницы пришлось бы полностью дублировать всю главу, что, опять же, медленно и вызовет неминуемый крэш приложения из-за нехватки памяти на больших главах.
После примерно двух месяцев безуспешных попыток написать постраничную разбивку с приемлемым временем исполнения было найдено довольно неплохое решение. Вкратце, что оно из себя представляет.
По сути глава книги — это набор параграфов. Параграфы можно представить как элементы первого уровня. С учётом скорости отрисовки HTML-контента в айфоне, для максимально быстрого отображения одной страницы нужно определить минимальный набор элементов первого уровня, который необходим для её представления. У меня есть вся глава в виде списка элементов первого уровня, а также список страниц. Страница представляет из себя объект, в котором хранятся порядковые номера начального и конечного элемента первого уровня, размер окна и смещения. Получилась довольно компактная и быстрая конструкция: для отображения одной страницы достаточно клонировать набор элементов первого уровня и вывести их на экран, указав правильное смещение и размер окна.
Для того, чтобы просчитать все страницы, нужно знать габариты каждого элемента первого уровня, их внутренние и внешние отступы, бордюры, размер шрифта и так далее. Чтобы получить все эти данные, элементы должны быть на странице и к ним должы быть применены стили. Для этих целей я создал специальный скрытый контейнер, который наследует все стилевые описания самой страницы, добавлял в него параграфы и проводил расчёты.
Для получения необходимых характеристик элемента нужно обратиться к его CSS-свойствам. За основу я взял функцию
css() из jQuery:function getCSS(elem, name) {
if (elem.style[name]) {
return elem.style[name];
} else {
var cs = window.getComputedStyle(elem, "");
return cs && cs.getPropertyValue(name);
}
}
Так как мне нужно было получить сразу довольно много свойств, это функция, судя по профайлеру из Web Inspector (имеется в виду десктопный браузер, на айфоне таких инструментов отладки нет, что сильно усложняет работу), была самой медленной. Как оказалось, обращение к
getComputedStyle() — очень дорогое в плане производительности. Поэтому я модифицировал эту функцию, чтобы можно было отдать массив свойств, которые нужно получить, а также убрал проверку elem.style[name], так как в 99% случаев элементам не выставлялись CSS-свойства через объект style и эта оптимизация скорее вредила, чем помогала:function getCSS(elem, name) {
var names = (typeof name == 'string') ? [name] : name,
cs = window.getComputedStyle(elem, ""),
result = {};
for (var i = 0, il = names.length; i < il; i++) {
var n = names[i];
result[n] = cs && cs.getPropertyValue(n);
}
return (typeof name == 'string') ? result[name] : result;
}После такой оптимизации функция
getCSS() не попадала даже в первую тройку самых медленных функций :).Следующий шаг: правильно «размазать» расчёт страниц во времени. Дело в том, что пока выполняется JS, интерфейс браузера полностью блокируется, а также вступают в действия ограничения на время выполнения скрипта. Могла сложиться ситуация, что экран «застынет» секунд на 20—30, а потом и вовсе вывалится с ошибкой о превышении таймаута на выполнение. Современный способ избавления от таких проблем — Web Workers, но мобильный Сафари их не поддерживает. Поэтому будем использовать проверенный «дедовский» метод, работающий во всех браузерах: вызывать каждую итерацию обсчёта страниц через
setTimeout(). Примерный код этого решения:function calculatePages(elems, callback) {
// elems — массив элементов, которые нужно обсчитать
var cur_elem = 0;
var run = function() {
createPage(elems[cur_elem]); // делаем обсчёт страницы
cur_elem++;
if (cur_elem < elems.length)
setTimeout(run, 1);
else
callback(); // обсчёт окончен
};
run();
}Функция работает следующим образом. Например, нам нужно обсчитать 30 элементов первого уровня. Отдаём массив этих элементов в функцию
calculatePages(), внутри которой создано замыкание в виде функции run(), которая является одной итерацией обсчёта. Когда закончили считать проверяем, остались ли ещё элементы в массиве. Если да, то через setTimeout() вызываем новую итерацию, иначе вызываем callback-функцию, сообщая, что расчёт окончен и можно двигаться дальше.У такого подхода есть один важный аспект — это нагрузка на одну итерацию. В данном случае — это сколько элементов нужно обсчитать за один вызов функции
run(). Если, например, считать один элемент за одну итерацию, то интерфейс для пользователя будет максимально отзывчивым, но общее время расчёта всей главы может увеличиться в 2—3 раза из-за накладных расходов, возникающих при запуске функции через setTimeout(). Если будем считать 10 элементов за один проход, то общее время обсчёта главы снизится, но также снизится отзывчивость интерфейса и повысится риск не пройти по таймауту, если параграфы будут очень большими.Поэтому нужно найти некую золотую середину, чтобы и время расчёта не сильно увеличивать, и не снижать отзывчивость интерфейса. Я решил ориентироваться не на количество элементов первого уровня, а на их объём, который можно получить через свойство
innerHTML или textContent. В качестве порогового объёма методом проб и ошибок было выбрано значение в 5 КБ. Перед вызовом calculatePages() я делил все объекты на группы: как только суммарный объем одной группы становился больше 5 КБ, она закрывалась и создавалась новая. Соответственно, расчёт размеров страниц вёлся не по отдельным элементам, а по группам.Удаление элементов
После того, как посчиталась одна группа, нужно очистить скрытый контейнер и освободить ресурсы для следующей группы элементов. Самый простой способ очистить содержимое контейнера — это обнулить свойство
innerHTML:function emptyElement(elem) {
elem.innerHTML = '';
}Однако «самый простой» не всегда означает «самый быстрый» — как показали замеры, вот такой способ работает намного быстрее:
function emptyElement(elem) {
while (elem.firstChild)
elem.removeChild(elem.firstChild);
}Пожалуй, пока всё. В этой статье были рассмотрены некоторые особенности парсинга и обсчёта больших объёмов данных на маломощных устройствах. На практике все описанные трюки оказались очень эффективными. Например, я протестировал главу объёмом более 1 МБ: наша читалка смогла её переварить где-то за 30—40 секунд, в то время как другие (причём довольно популярные) читалки из AppStore, написанные на Objective C/C++, попросту падали.
В следующей статье рассмотрим некоторые факторы, влияющие на время отрисовки одной страницы в айфоне, а также некоторые трюки, позволяющие это время заметно снизить.
Сергей Чикуёнок

