В предыдущей части рассматривалась настройка зеркала — технологии высокой доступности InterSystems Database Mirroring СУБД Caché.
В этой статье будут рассмотрены сценарии перерывов (отказов) и реакция зеркала на них.
Перерывы могут быть как плановые, так и внеплановые.
Плановые — это когда нам нужно остановить сервер для обновления операционной системы, версии СУБД, версии прикладной системы и мы контролируем процесс.
Примеры плановых перерывов:
Внеплановые — когда происходит нечто, приводящее к невозможности работы сервера с клиентами информационной системы, причём без нашего ведома. Причиной этому могут быть:
Автоматическое преодоление отказа для зеркала Caché происходит только в случае отказа/перерыва на Primary-сервере, и в этой статье будут рассмотрены именно такие случаи. Безусловно, могут быть сценарии, когда на Backup-сервере происходит проблема, но в этом случае ИС продолжает работать, а зеркалирования физически нет, пока администратор вручную не восстановит Backup-сервер. Возможен другой сценарий, когда оба сервера отказали сразу — но в этом случае перерыв в работе ИС неизбежен, а его урегулирование выполняется “вручную”.
Базовый сценарий автоматического преодоления отказа:
Что может пойти не так?
Представим себе ситуацию, когда на Primary-сервере выходит из строя сетевой интерфейс, но ненадолго, однако достаточно, чтобы Backup-сервер уже успел “решить” стать Primary-сервером. В результате возникает ситуация split brain.
Split brain —рак мозга состояние полной рассинхронизации серверов кластера, когда работают оба сервера и каждый из них считает, что он Primary в данный момент.
Такая ситуация может возникнуть, например, если Backup-сервер “ошибочно” решил, что Primary-cервер находится в “дауне”, в итоге в кластере появляется сразу два Primary-сервера, которые пытаются одновременно обслуживать запросы пользователей — коллапс кластера.
Для пользователей ИС такая ситуация выражается в неопределённом перерыве работы, которая восстанавливается администратором “вручную”.
Самый быстрый способ восстановления такой ситуации — создать кластер заново, восстановив данные из бэкапа или из асинхронного “зеркала”.
Определяющим для поведения зеркала Caché при отказе/перерыве является значение параметра AgentContactRequiredForFailover=yes/no.
В случае AgentContactRequiredForFailover(ACRF)=yes (по умолчанию) при failover ISC Agent на обоих серверах должны находиться в контакте в момент перерыва. Такая ситуация возможна для случаев внепланового сбоя Cache, плановой перезагрузки Cache, плановой перезагрузки ОС. Поэтому в этом режиме для всех остальных случаев автоматический failover не произойдёт!
Этот режим работы зеркалирования позволяет выполнить failover и без наличия онлайн-контакта между агентами серверов. Такой режим может понадобиться чтобы прикрыть ситуации вида Power Off primary-сервера, выхода из строя сетевых адаптеров или самой сети между серверами и проч., когда нет связи с Primary-сервером. В этом режиме решение об автоматическом переходе Backup-сервера в состояние Primary-сервера определяется пользовательской функцией в программе ZMIRROR, расположенной в области (%SYS).
Конечно же, при построении failover-решения мы ожидаем автоматического преодоления отказа для большинства ситуаций, иначе зачем все это. В настоящее время зеркало Caché способно автоматически обработать почти все возможные сценарии.
Мы протестировали как ведёт себя зеркало для нескольких типичных сценариев при различных значениях ACRF.
Тестировалась самая свежая на данный момент версия Caché 2012.2 RC. Да — означает автоматическое преодоление отказа для этого сценария.
По итогам тестирования выяснилось — неприятным сценарием является отключение сетевого интерфейса (№4). Поэтому рекомендуется устанавливать между серверами зеркала резервный сетевой канал.
Пример конфигурации серверов:
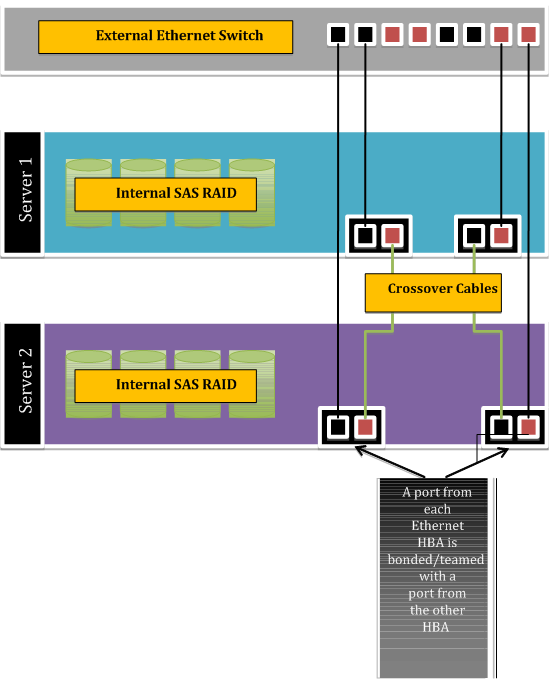
В случае одновременного выхода из строя обоих серверов — сценарии 5-6 (длительный перерыв в электропитании например), важно соблюсти очередность ввода в эксплуатацию — первым должен быть активирован Primary-сервер. В противном случае Backup-сервер становится Primary, а после старта бывшего Primary-сервера их становится два — в результате split brain.
Как видно из таблицы, синхронное зеркало Caché с ACRF=yes (значение по умолчанию) обеспечивает только те нештатные ситуации, когда сеть между серверами кластера “жива”.
Для остальных ситуаций есть режим ACRF=no, где администратор на свой страх и риск пишет пользовательскую программу ZMIRROR определения выхода из строя Primary-сервера.
Теоретически возможно построить такую аппаратно-программную систему для конечной инсталляции зеркала, когда для любого сценария можно однозначно программно определить, в каком состоянии находится Primary-сервер.
Если на вашем сервере такая ситуация имеет место быть, целесообразно устанавить режим ACRF=no. Тогда в случае перерыва, и когда уже нет связи с ISC Agent Primary-сервера, система вызывает функцию $$IsOtherNodeDown^ZMIRROR(). Функция возвращает 1 или 0. В случае, если функции нет или функция возвращает 0, процесс автоматического failover прекращается.
Задача программиста при написании пользовательской реализации функции $$IsOtherNodeDown^ZMIRROR() состоит в том, чтобы достоверно убедиться, что Primary-сервер действительно вышел из строя и вернуть 1 в этом случае.
Дисклеймер! Использование этого кода ни в коем случае не гарантирует выполнения автоматического failover в вашей продакшен конфигурации для режима ACRF=No. Для реального использования этого режима необходимо тщательное тестирование failover для каждой конфигурации в отдельности!
Несколько рекомендаций из опыта эксплуатации InterSystems Database Mirroring
“Нельзя «вручную» чистить журнал primary-сервера, если backup-сервер выключен”
Действительно, если так сделать, а backup-сервер не успел забрать нужные журналы — можно создавать backup-сервер заново.
“Нельзя долго держать backup-сервер выключеным, при работающем primary-сервере”
В этом случае может закончиться место на диске primary-сервера из-за переполнения несинхронизированными журналами.
“Время на серверах должно быть синхронизировано”
Это простое условие, но оно должно выполняться. Иначе при рассинхронизации, например, на несколько часов backup-сервер “запутается” с актуальностью журналов. В результате делаем backup-сервер заново.
“Сеть между серверами должна быть ненагруженной”
По сети постоянно идёт передача журнала с Primary-сервера на backup. Если сеть между серверами будет ещё чем-то занята, или канала не будет хватать для передачи данных, в результате начнёт “тормозить” Primary-сервер, который не будет успевать передавать данные, вносимые пользователями ИС.
«Настройки конфигурации системы, маппинги, настройки ролей и пользователей необходимо синхронизировать вручную»
Настройки маппинга глобалов, классов и пакетов а также все настройки ролей, пользователей и конфигурации системы для Primary и Backup-серверов необходимо также поддерживать в синхронизированном состоянии. Зеркало синхронизирует только базы данных, выбранные для зеркалирования. Поэтому администратору зеркала необходимо иметь идентичную конфигурацию, маппинги и политику безопасности пользователей и поддерживать это состояние для Primary- и Backup-серверов.
Среднее время выполнения автоматического failover для режима Agent Contact Required for Failover=yes — 10-20 секунд. Пауза 10-20 секунд — это время, когда приложение продолжит работать уже с новым сервером. При этом произойдёт реконнект соединения (если было прямое соединение с сервером) или просто продолжение работы, если работа велась через ECP-соединение.
В случае ACRF=no пауза составляет в среднем 35-40 секунд. При этом ECP-клиенты потеряют соединение, т.к. таймаут по умолчанию для ECP = 30 сек. Для систем, использующих ECP и зеркало с ACRF=no на серверах клиентах ECP в программе SYSTEM^%ZSTART желательно прописать код, увеличивающий таймаут ECP:
do $system.ECP.SetProperty("ECPRecoveryTimout",90)
Отвечая на этот вопрос, говорю “Да”. Даже если использовать то, что идёт “из коробки” — а именно режим ACRF=yes, есть возможность выполнять плановые работы по обновлению ОС, Caché, Hardware и проч. без остановки работы информационной системы, а также автоматическое преодоление сбоев СУБД Caché. Остальные сценарии можно прикрыть уже известными средствами с помощью аппаратных failover-кластеров и систем бесперебойного питания в необходимом количестве “девяток после запятой”.
В этой статье будут рассмотрены сценарии перерывов (отказов) и реакция зеркала на них.
Перерывы могут быть как плановые, так и внеплановые.
Плановые — это когда нам нужно остановить сервер для обновления операционной системы, версии СУБД, версии прикладной системы и мы контролируем процесс.
Примеры плановых перерывов:
- перезагрузка ОС, например для установки обновлений;
- перезагрузка СУБД;
- обновление hardware сервера.
Внеплановые — когда происходит нечто, приводящее к невозможности работы сервера с клиентами информационной системы, причём без нашего ведома. Причиной этому могут быть:
- зависание СУБД;
- зависание операционной системы;
- экстренные (Reset, Power Off);
- выход из строя оборудования сервера;
- выход из строя сетевого оборудования;
война, эпидемия, снежный буран, космоса чёрные дыры.
Преодоление отказа (failover)
Автоматическое преодоление отказа для зеркала Caché происходит только в случае отказа/перерыва на Primary-сервере, и в этой статье будут рассмотрены именно такие случаи. Безусловно, могут быть сценарии, когда на Backup-сервере происходит проблема, но в этом случае ИС продолжает работать, а зеркалирования физически нет, пока администратор вручную не восстановит Backup-сервер. Возможен другой сценарий, когда оба сервера отказали сразу — но в этом случае перерыв в работе ИС неизбежен, а его урегулирование выполняется “вручную”.
Базовый сценарий автоматического преодоления отказа:
- Primary-сервер обслуживает клиентов ИС, которые работают с одной из зеркалируемых БД, а Backup-сервер стоит “наготове” (stand by);
- Происходит отказ на Primary-сервере;
- Backup-сервер удостоверяется, что Primary-сервер находится в “дауне”, автоматически становится Primary-сервером и продолжает обслуживать клиентов информационной системы;
- Бывший Primary-сервер восстанавливается (например администратором), становится новым Backup-сервером и входит в режим “stand by” для нового Primary-сервера.
Что может пойти не так?
Представим себе ситуацию, когда на Primary-сервере выходит из строя сетевой интерфейс, но ненадолго, однако достаточно, чтобы Backup-сервер уже успел “решить” стать Primary-сервером. В результате возникает ситуация split brain.
Split brain
Split brain —
Такая ситуация может возникнуть, например, если Backup-сервер “ошибочно” решил, что Primary-cервер находится в “дауне”, в итоге в кластере появляется сразу два Primary-сервера, которые пытаются одновременно обслуживать запросы пользователей — коллапс кластера.
Для пользователей ИС такая ситуация выражается в неопределённом перерыве работы, которая восстанавливается администратором “вручную”.
Самый быстрый способ восстановления такой ситуации — создать кластер заново, восстановив данные из бэкапа или из асинхронного “зеркала”.
AgentContactRequiredForFailover
Определяющим для поведения зеркала Caché при отказе/перерыве является значение параметра AgentContactRequiredForFailover=yes/no.
AgentContactRequiredForFailover=yes
В случае AgentContactRequiredForFailover(ACRF)=yes (по умолчанию) при failover ISC Agent на обоих серверах должны находиться в контакте в момент перерыва. Такая ситуация возможна для случаев внепланового сбоя Cache, плановой перезагрузки Cache, плановой перезагрузки ОС. Поэтому в этом режиме для всех остальных случаев автоматический failover не произойдёт!
AgentContactRequiredForFailover=no
Этот режим работы зеркалирования позволяет выполнить failover и без наличия онлайн-контакта между агентами серверов. Такой режим может понадобиться чтобы прикрыть ситуации вида Power Off primary-сервера, выхода из строя сетевых адаптеров или самой сети между серверами и проч., когда нет связи с Primary-сервером. В этом режиме решение об автоматическом переходе Backup-сервера в состояние Primary-сервера определяется пользовательской функцией в программе ZMIRROR, расположенной в области (%SYS).
Результаты тестирования
Конечно же, при построении failover-решения мы ожидаем автоматического преодоления отказа для большинства ситуаций, иначе зачем все это. В настоящее время зеркало Caché способно автоматически обработать почти все возможные сценарии.
Мы протестировали как ведёт себя зеркало для нескольких типичных сценариев при различных значениях ACRF.
Тестировалась самая свежая на данный момент версия Caché 2012.2 RC. Да — означает автоматическое преодоление отказа для этого сценария.
| N | Сценарии | ACRF=Yes | ACRF=No |
|---|---|---|---|
| 1 | Плановая или аварийная перезагрузка, остановка СУБД Caché на Primary | Да | Да |
| 2 | Плановая перезагрузка OS | Да | Да |
| 3 | Аварийная остановка OS, Reset, Power Off | Нет | Да |
| 4 | Отключение сетевого интерфейса на Primary | Нет | Да |
| 5 | Power Off одновременно Primary и Backup, а затем загрузка сначала Primary | Да | Да |
| 6 | Power Off одновременно Primary и Backup, а затем загрузка сначала Backup | Нет | Нет |
По итогам тестирования выяснилось — неприятным сценарием является отключение сетевого интерфейса (№4). Поэтому рекомендуется устанавливать между серверами зеркала резервный сетевой канал.
Пример конфигурации серверов:

В случае одновременного выхода из строя обоих серверов — сценарии 5-6 (длительный перерыв в электропитании например), важно соблюсти очередность ввода в эксплуатацию — первым должен быть активирован Primary-сервер. В противном случае Backup-сервер становится Primary, а после старта бывшего Primary-сервера их становится два — в результате split brain.
Как видно из таблицы, синхронное зеркало Caché с ACRF=yes (значение по умолчанию) обеспечивает только те нештатные ситуации, когда сеть между серверами кластера “жива”.
Для остальных ситуаций есть режим ACRF=no, где администратор на свой страх и риск пишет пользовательскую программу ZMIRROR определения выхода из строя Primary-сервера.
ZMIRROR
Теоретически возможно построить такую аппаратно-программную систему для конечной инсталляции зеркала, когда для любого сценария можно однозначно программно определить, в каком состоянии находится Primary-сервер.
Если на вашем сервере такая ситуация имеет место быть, целесообразно устанавить режим ACRF=no. Тогда в случае перерыва, и когда уже нет связи с ISC Agent Primary-сервера, система вызывает функцию $$IsOtherNodeDown^ZMIRROR(). Функция возвращает 1 или 0. В случае, если функции нет или функция возвращает 0, процесс автоматического failover прекращается.
Задача программиста при написании пользовательской реализации функции $$IsOtherNodeDown^ZMIRROR() состоит в том, чтобы достоверно убедиться, что Primary-сервер действительно вышел из строя и вернуть 1 в этом случае.
Пример пользовательской функции ZMIRROR
ZMIRROR
; USE AT YOUR OWN RISK.
q
IsOtherNodeDown() public
{
d ##class(%Device).Broadcast("", "------------> IsOtherNodeDown()")
try {
s ip="192.168.169.186" ; адрес другого Failover узла
s PingSuccessful=$system.INetInfo.CheckAddressExist(ip)
d ##class(%Device).Broadcast("", "IP adress " _ip_ " is " _
$s(PingSuccessful: "available", 1: "unavailable") _ ".")
if 'PingSuccessful s returnValue=1 q ; нет пинга
s url=""_ip_":57772/csp/sys/UtilHome.csp"
s stat=$$GetStatus(url)
d ##class(%Device).Broadcast("", url_" is " _stat_ ".")
if stat["Error" s returnValue=1 q ;
s returnValue = 0
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
s returnValue = 0
}
d ##class(%Device).Broadcast("", "Returning "_returnValue_" ...")
d ##class(%Device).Broadcast("", "<------------ IsOtherNodeDown()")
q returnValue
}
CheckBecomePrimaryOK() public
{
d ##class(%Device).Broadcast("", "------------> CheckBecomePrimaryOK()")
try {
s stat=$$MemberDescription()
s returnValue=1
d ##class(%Device).Broadcast("", "This instance is " _stat)
d ##class(%Device).Broadcast("", "Returning "_returnValue_" ...")
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
s returnValue = 0
}
d ##class(%Device).Broadcast("", "<------------ CheckBecomePrimaryOK()")
q returnValue
}
NotifyBecomePrimary() public
{
d ##class(%Device).Broadcast("", "------------> NotifyBecomePrimary()")
try {
d ##class(%Device).Broadcast("", "This instance is " _$$MemberDescription())
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
}
d ##class(%Device).Broadcast("", "<------------ NotifyBecomePrimary()")
}
NotifyBecomePrimaryFailed() public
{
d ##class(%Device).Broadcast("", "------------> NotifyBecomePrimaryFailed()")
try {
d ##class(%Device).Broadcast("", "This instance is " _$$MemberDescription())
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
}
d ##class(%Device).Broadcast("", "<------------ NotifyBecomePrimaryFailed()")
}
MemberDescription() ; получить статус члена зеркала
q $s($system.Mirror.IsMember(): $s($system.Mirror.IsBackup(): "a backup",
$system.Mirror.IsPrimary(): "a primary",
$system.Mirror.IsAsyncMember(): "an async",
1: "an unknown") _ "member of " _ $system.Mirror.MirrorName(),
1: "not a member")
GetStatus(url)
;url - адрес http://localhost:57772/csp/sys/UtilHome.csp
S $ZT="HttpError"
N A,status,err,httprequest,Port,content,%objlasterror
Set httprequest=##class(%Net.HttpRequest).%New()
S A=$P($p(url,"://",2),"/",1) I A="" Q "Error! URL"
I A[":" S Port=$P(A,":",2),A=$P(A,":",1) Set httprequest.Port=Port
Set httprequest.Server=A
S A="/"_$P($p(url,"://",2),"/",2,991)
Set httprequest.Timeout=3
Do httprequest.Get(A)
S status=httprequest.HttpResponse.StatusLine
Do httprequest.%Close()
i status="",$g(%objlasterror)'="" g HttpError
q status
HttpError I $ZE["<INVALID OREF>" Q "Error! Server No Access ? "_$ZE
do DecomposeStatus^%apiOBJ(%objlasterror,.err)
Q "Error "_$G(err(err))
; USE AT YOUR OWN RISK.
q
IsOtherNodeDown() public
{
d ##class(%Device).Broadcast("", "------------> IsOtherNodeDown()")
try {
s ip="192.168.169.186" ; адрес другого Failover узла
s PingSuccessful=$system.INetInfo.CheckAddressExist(ip)
d ##class(%Device).Broadcast("", "IP adress " _ip_ " is " _
$s(PingSuccessful: "available", 1: "unavailable") _ ".")
if 'PingSuccessful s returnValue=1 q ; нет пинга
s url=""_ip_":57772/csp/sys/UtilHome.csp"
s stat=$$GetStatus(url)
d ##class(%Device).Broadcast("", url_" is " _stat_ ".")
if stat["Error" s returnValue=1 q ;
s returnValue = 0
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
s returnValue = 0
}
d ##class(%Device).Broadcast("", "Returning "_returnValue_" ...")
d ##class(%Device).Broadcast("", "<------------ IsOtherNodeDown()")
q returnValue
}
CheckBecomePrimaryOK() public
{
d ##class(%Device).Broadcast("", "------------> CheckBecomePrimaryOK()")
try {
s stat=$$MemberDescription()
s returnValue=1
d ##class(%Device).Broadcast("", "This instance is " _stat)
d ##class(%Device).Broadcast("", "Returning "_returnValue_" ...")
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
s returnValue = 0
}
d ##class(%Device).Broadcast("", "<------------ CheckBecomePrimaryOK()")
q returnValue
}
NotifyBecomePrimary() public
{
d ##class(%Device).Broadcast("", "------------> NotifyBecomePrimary()")
try {
d ##class(%Device).Broadcast("", "This instance is " _$$MemberDescription())
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
}
d ##class(%Device).Broadcast("", "<------------ NotifyBecomePrimary()")
}
NotifyBecomePrimaryFailed() public
{
d ##class(%Device).Broadcast("", "------------> NotifyBecomePrimaryFailed()")
try {
d ##class(%Device).Broadcast("", "This instance is " _$$MemberDescription())
} catch (e) {
d ##class(%Library.Device).Broadcast("", e.DisplayString())
}
d ##class(%Device).Broadcast("", "<------------ NotifyBecomePrimaryFailed()")
}
MemberDescription() ; получить статус члена зеркала
q $s($system.Mirror.IsMember(): $s($system.Mirror.IsBackup(): "a backup",
$system.Mirror.IsPrimary(): "a primary",
$system.Mirror.IsAsyncMember(): "an async",
1: "an unknown") _ "member of " _ $system.Mirror.MirrorName(),
1: "not a member")
GetStatus(url)
;url - адрес http://localhost:57772/csp/sys/UtilHome.csp
S $ZT="HttpError"
N A,status,err,httprequest,Port,content,%objlasterror
Set httprequest=##class(%Net.HttpRequest).%New()
S A=$P($p(url,"://",2),"/",1) I A="" Q "Error! URL"
I A[":" S Port=$P(A,":",2),A=$P(A,":",1) Set httprequest.Port=Port
Set httprequest.Server=A
S A="/"_$P($p(url,"://",2),"/",2,991)
Set httprequest.Timeout=3
Do httprequest.Get(A)
S status=httprequest.HttpResponse.StatusLine
Do httprequest.%Close()
i status="",$g(%objlasterror)'="" g HttpError
q status
HttpError I $ZE["<INVALID OREF>" Q "Error! Server No Access ? "_$ZE
do DecomposeStatus^%apiOBJ(%objlasterror,.err)
Q "Error "_$G(err(err))
Дисклеймер! Использование этого кода ни в коем случае не гарантирует выполнения автоматического failover в вашей продакшен конфигурации для режима ACRF=No. Для реального использования этого режима необходимо тщательное тестирование failover для каждой конфигурации в отдельности!
Советы по настройке зеркала
Несколько рекомендаций из опыта эксплуатации InterSystems Database Mirroring
“Нельзя «вручную» чистить журнал primary-сервера, если backup-сервер выключен”
Действительно, если так сделать, а backup-сервер не успел забрать нужные журналы — можно создавать backup-сервер заново.
“Нельзя долго держать backup-сервер выключеным, при работающем primary-сервере”
В этом случае может закончиться место на диске primary-сервера из-за переполнения несинхронизированными журналами.
“Время на серверах должно быть синхронизировано”
Это простое условие, но оно должно выполняться. Иначе при рассинхронизации, например, на несколько часов backup-сервер “запутается” с актуальностью журналов. В результате делаем backup-сервер заново.
“Сеть между серверами должна быть ненагруженной”
По сети постоянно идёт передача журнала с Primary-сервера на backup. Если сеть между серверами будет ещё чем-то занята, или канала не будет хватать для передачи данных, в результате начнёт “тормозить” Primary-сервер, который не будет успевать передавать данные, вносимые пользователями ИС.
«Настройки конфигурации системы, маппинги, настройки ролей и пользователей необходимо синхронизировать вручную»
Настройки маппинга глобалов, классов и пакетов а также все настройки ролей, пользователей и конфигурации системы для Primary и Backup-серверов необходимо также поддерживать в синхронизированном состоянии. Зеркало синхронизирует только базы данных, выбранные для зеркалирования. Поэтому администратору зеркала необходимо иметь идентичную конфигурацию, маппинги и политику безопасности пользователей и поддерживать это состояние для Primary- и Backup-серверов.
Эксплуатационные характеристики
Среднее время выполнения автоматического failover для режима Agent Contact Required for Failover=yes — 10-20 секунд. Пауза 10-20 секунд — это время, когда приложение продолжит работать уже с новым сервером. При этом произойдёт реконнект соединения (если было прямое соединение с сервером) или просто продолжение работы, если работа велась через ECP-соединение.
В случае ACRF=no пауза составляет в среднем 35-40 секунд. При этом ECP-клиенты потеряют соединение, т.к. таймаут по умолчанию для ECP = 30 сек. Для систем, использующих ECP и зеркало с ACRF=no на серверах клиентах ECP в программе SYSTEM^%ZSTART желательно прописать код, увеличивающий таймаут ECP:
do $system.ECP.SetProperty("ECPRecoveryTimout",90)
В сухом остатке или “оно нам надо”?
Отвечая на этот вопрос, говорю “Да”. Даже если использовать то, что идёт “из коробки” — а именно режим ACRF=yes, есть возможность выполнять плановые работы по обновлению ОС, Caché, Hardware и проч. без остановки работы информационной системы, а также автоматическое преодоление сбоев СУБД Caché. Остальные сценарии можно прикрыть уже известными средствами с помощью аппаратных failover-кластеров и систем бесперебойного питания в необходимом количестве “девяток после запятой”.
