

Быстрая и эффективная разработка ПО сегодня немыслима без отточенных рабочих процессов: каждый компонент передается на сборку к моменту установки, изделие не простаивает в ожидании. Еще два года назад мы совместно с «М.Видео» начали внедрять такой подход в процесс разработки у ритейлера и сегодня продолжаем его развивать. Каковы промежуточные итоги? Результат полностью себя оправдал: благодаря реализованным изменениям удалось ускорить выпуск релизов на 20–30 %. Хотите подробностей? Вэлком в наше закулисье.
Со Scrum на Kanban
В первую очередь была реализована смена методологии — переход со Scrum, то есть спринтовой модели, на Kanban. Раньше процесс разработки выглядел так:

Есть ветка разработки, есть спринты для пяти команд. Они кодят в своих собственных ветках разработки, спринты заканчиваются в один день, и все команды в тот же день объединяют результаты своей работы с мастер-веткой. После этого в течение пяти дней прогоняются регрессионные тесты, затем ветка отдается в пилотную среду и после неё — в продуктивную. Но, прежде чем запустить регрессионные тесты, приходилось 2–3 дня хоть как-то стабилизировать мастер-ветку, убирая конфликты после объединения с командными ветками.
В чем преимущество Kanban? Команды не ждут конца спринта, а объединяют свои локальные изменения с мастер-веткой по факту окончания реализации задачи, каждый раз проверяя, нет ли конфликтов объединения. В назначенный день все объединения с мастером блокируются и запускаются регрессионные тесты.
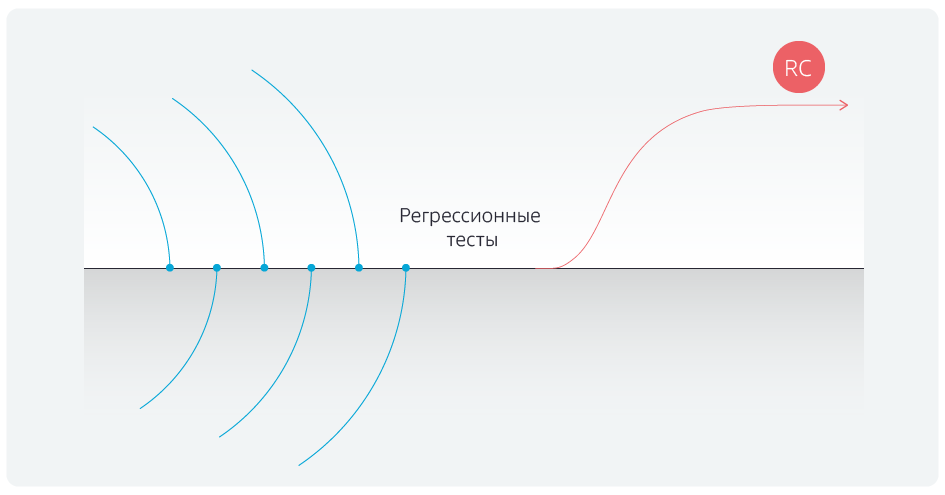
В результате удалось избавиться от постоянных сдвигов сроков вправо, регрессы
не задерживаются, release candidate отгружается вовремя.
Вездесущая автоматизация
Конечно, одной лишь смены методологии было недостаточно. Вторым этапом мы совместно с ритейлером автоматизировали тестирование. Всего проверяется около 900 сценариев, разбитых на группы по приоритетам.
Около 100 сценариев — так называемые блокеры. Они должны работать на сайте —интернет-магазине «М.Видео» — даже во время атомной войны. Если какой-то из блокеров не работает, значит на сайте большие проблемы. Например, к блокерам относятся механизм покупки товаров, применение скидок, авторизация, регистрация пользователей, оформление кредитного заказа и т.д.
Ещё примерно 300 сценариев — критически важные. К ним относится, к примеру, возможность выбирать товары с помощью фильтров. Если эта фича сломается, то вряд ли пользователи будут покупать товары, даже если будут работать механизмы покупки и прямого поиска по каталогу.
Остальные сценарии — major и minor. Если они не будут работать, люди приобретут негативный опыт использования сайта. Сюда относится множество неполадок разной важности и заметности для пользователя. Например, поехала верстка (major), не отображается описание акции (minor), не работает автоподсказка по паролям в личном кабинете (minor), не работает восстановление (major).
Вместе с «М.Видео» мы автоматизировали тестирование блокеров на 95 %, остальных сценариев — примерно на 50 %. Почему около половины не автоматизированы? Причин много, и разных. Есть сценарии, априори не поддающиеся автоматизации. Есть сложные интеграционные кейсы, подготовка к которым требует ручной работы, например, позвонить в банк и отменить заявку на кредит, связаться с отделом продаж и отменить заказы в продуктивной среде.
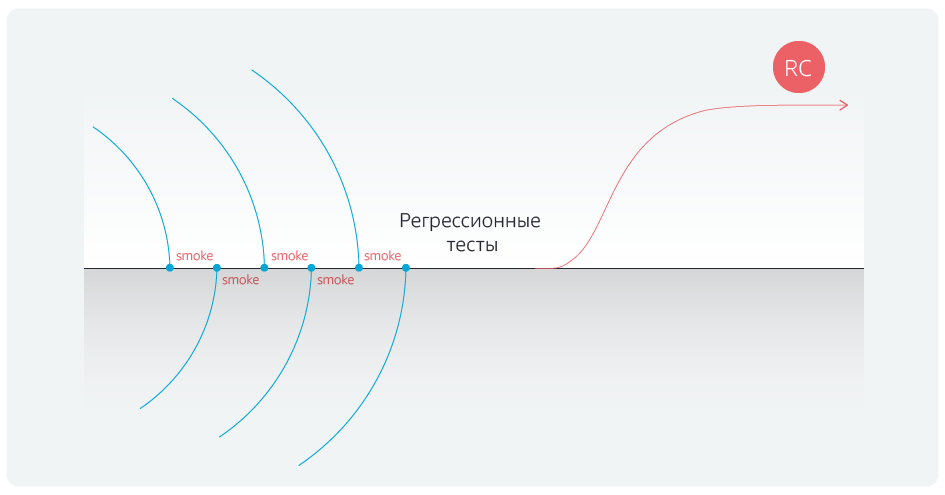
Автоматизация регрессионных тестов сократила их длительность. Но мы пошли дальше и автоматизировали еще и smoke-тесты для блокеров после каждого объединения веток команд с мастер-веткой.
После автоматизации тестов мы окончательно избавились от задержек после завершения объединений с мастер-веткой.
Gherkin в помощь
Чтобы закрепить успех, наша команда переработала сами тесты. Раньше это были таблицы: действие → ожидаемый результат → фактический результат. Например, я с таким-то логином и паролем авторизовался на сайте; ожидаемый результат: всё в порядке; фактический результат — тоже всё в порядке, перехожу по другим страницам. Это были громоздкие сценарии.
Мы перевели их в нотацию Gherkin и автоматизировали некоторые шаги. Возьмём ту же авторизацию на сайте, сценарий теперь формулируется так: «как пользователь сайта я авторизовался с авторизационными данными, и процедура прошла успешно». При этом «пользователь сайта» и «авторизовался с авторизационными данными» вынесены в отдельные таблицы. Теперь мы можем быстро прогонять тестовые сценарии вне зависимости от данных.
В чём ценность этого этапа? Допустим, тестированием проекта занимается один тестировщик. Ему плевать, как он пишет тесты, он может делать проверки хоть в виде чек-листа: «авторизация проверена, регистрация проверена, покупка картой проверена, покупка Яндекс.Деньгами проверена — я красавчик». Приходит новый человек и спрашивает: а ты авторизовался по e-mail или через Facebook? В результате чек-лист превращается в сценарий.
В проекте работают пять команд, и в каждой минимум по два тестировщика. Раньше каждый из них писал тесты, как ему заблагорассудится, и в результате тесты могли поддерживать только их авторы. С автоматизацией всё было глухо: либо нужно набирать отдельных автоматизаторов, которые весь зоопарк тестов переведут на скриптовый язык, либо забыть об автоматизации как о явлении. Gherkin помог всё изменить: с помощью этого скриптового языка мы создали «кубики» — авторизация, корзина, оплата и т. д. — из которых тестировщики теперь собирают различные сценарии. Когда нужно создать новый сценарий, человек не пишет его с нуля, а просто подтягивает нужные блоки в виде автотестов. Нотации Gherkin обучили всех функциональных тестировщиков, и теперь они могут самостоятельно взаимодействовать с автоматизаторами, поддерживать сценарии и разбирать результаты.
На этом мы не остановились.
Функциональные блоки
Допустим, релиз 1 — это функциональность, которая уже есть на сайте. В релизе 2 мы захотели внести какие-нибудь изменения в пользовательские и бизнес-сценарии, и в результате часть тестов перестала работать, потому что функциональность изменилась.
Мы структурировали систему хранения тестов: разбили её на функциональные блоки, например, «личный кабинет», «покупка» и т. д. Теперь, когда вводится новый пользовательский сценарий, в нём уже галочками отмечены необходимые функциональные блоки.
Благодаря этому после объединения с мастер-веткой разработчики могут проверять работу не только блокеров, но и сценарии, относящиеся к предметной области, которую затрагивают сделанные изменения.
Второе следствие — стало гораздо легче поддерживать сами тесты. Например, если что-то поменялось в личном кабинете, оформлении заказа и доставке, нам не нужно перетряхивать всю регрессионную модель, потому что сразу видны функциональные блоки, в которые внесены изменения. То есть поддерживать тестовый набор в актуальном состоянии стало быстрее, а значит, и дешевле.
Проблема со стендами
Раньше никто не проверял работоспособность стендов до приемочного тестирования. Например, передают нам какой-нибудь стенд на тестирование, мы гоняем на нём несколько часов регрессионные тесты. Они падают, разбираемся, исправляем, снова запускаем тесты. То есть теряем время на отладку и повторные прогоны.
Проблема решилась просто: написали всего 15 API-тестов, проверяющих конфигурацию стендов, которые никак не связаны с функциональностью. Тесты не зависят от версии сборки, они лишь проверяют все интеграционные точки, критичные для прохождения сценариев.
Это помогло сэкономить очень много времени. Ведь до автоматизации у нас было 14 тестировщиков, проверки были громоздкие и длительные, были сценарии практически на весь день работы, состоящие из 150 шагов. И вот ты тестируешь, и где-нибудь на 30–40–110-ом шаге понимаешь, что стенд не работает. Умножаем потерянное рабочее время на 14 человек и ужасаемся. А после внедрения автоматизации и проверки стендов удалось сократить количество тестировщиков вдвое и избавиться от простоев, что принесло много радости главбуху.
Вишенки на торте
Первая вишенка — bugflow. Формально, это жизненный цикл любого бага, а на самом деле любой сущности. К примеру, мы оперируем этим понятием в Jira. Один дополнительный статус позволил нам ускорить релизы.
В целом процесс выглядит так: нашли инцидент, взяли его в работу, завершили над ним работу, передали в тестирование, протестировали, закрыли.

Мы понимаем, что дефект закрылся, проблема решена. И добавили еще один статус: «для регрессионного тестирования». Это значит, что после анализа, сценарии, обнаруживающие критичные баги, добавляются в регрессионный набор из 900 сценариев. Если их там не было, или если у них была недостаточная детализация, значит, у нас происходит моментальная обратная связь по состоянию продуктива или пилота.

То есть мы понимаем, что есть проблема, и мы её по какой-то причине не учли. И теперь добавление сценария проверки бага сильно экономит время.
Также мы на уровне тестирования внедрили ретроспективу. Выглядит это так: составили табличку «номер релиза, количество багов в нём, количество блокеров и других сценариев, и количество резолюций». При этом мы оценивали количество невалидных резолюций. К примеру, если из 40 багов получается 15 невалидных, то это очень плохой показатель, тестировщики впустую тратят не только своё время, но и время разработчиков, которые работают над этими багами. Ребята начали рефлексировать, разбираться с этим, внедрили процедуру ревизии багов более опытными тестерами перед отправкой в разработку. И они очень хорошо с этим справились.
Таким образом, происходит постоянная рефлексия и работа по улучшению качества. Все баги с продуктива анализируются: на каждый баг создается тест, который сразу включается в регрессионный набор. По возможности данный тест автоматизируется и запускается на регулярной основе.
Результаты
Изначально планировалось увеличить частоту релизов и снизить количество ошибок, но итог несколько превзошел ожидания. Разумно построенный процесс автоматизации дал возможность нарастить количество автоматизированных тестов за короткое время, а проводимый анализ пропущенных багов позволил команде разработки и тестирования оптимально выстроить приоритеты в сценариях и фокусироваться на самом важном.
Итоги автоматизации:
- до 4 дней (вместо прежних 10) сократилась длительность регрессионных тестов;
- на 50 % уменьшилась команда ручного тестирования;
- с 30–35 до 25 дней сократилась продолжительность time to market — с момента поступления фичи в бэклог команды до её выхода на пилот.
Команда автоматизации тестирования, «Инфосистемы Джет»
