
Представьте, что у вас есть всего один тест с использованием Selenium. Что может сделать его нестабильным? Как его ускорить? Теперь представьте, что тестов стало два. Теперь представьте сотню. Как заставить быстро отработать такую кучу тестов? Что произойдет, если количество тестов продолжит расти?
В этой статье Саймон Стюарт проведет нас по нелегкому пути масштабирования, от одного теста до параллельно исполняющихся сотен тестов. Мы познакомимся и с проблемами, которые при этом появляются, и с практическими методами решения этих проблем. Будет код на Java и некоторые мысли о развитии тестовой инфраструктуры.
Прототипом этой статьи является доклад Саймона Стюарта на Heisenbug 2017 Moscow. Саймон — создатель WebDriver, технологии, которой сейчас почти 11 лет. Он стал руководителем проекта Selenium около 9 лет назад. В Google занимался масштабированием Selenium, от нескольких десятков тысяч до нескольких миллионов тестов каждый день, на их инфраструктуре. Затем перешел в Facebook. В данный момент занимается разработкой спецификации WebDriver для W3C, которая входит в группу тестирования и тулинга в W3C. Можно сказать, что на основе WebDriver и создается стандарт.
В ходе статьи я хочу рассмотреть простой тест и показать, как его можно масштабировать. Вначале мы его запустим личном ноутбуке, а под конец он будет работать в облаке и поражать воображение всех вокруг, в т.ч. вашего начальника, который почешет подбородок и скажет: «Я вам явно недостаточно плачу». Для этого мы и пишем софт, не правда ли?
Для начала давайте определимся — зачем вообще нужны тесты? Мы пишем их не потому, что нам нравится зеленый (или красный) цвет, и не потому, что нам нравится наша работа. Их единственная функция — обеспечить уверенность в том, что софт работает так, как задумано. Сквозные тесты (например, Selenium) должны быть частью сбалансированной диеты тестов. Если кроме них ничего не употреблять — ничего хорошего не выйдет. Но об этом мы поговорим позже.

Начнем с простого примера, который открыт у меня в IDE. Называется он longAndWrong(), таким ведь тест и должен быть, правда? Мы создаем новый FirefoxDriver, чтобы выполнение осуществлялось локально. Затем создаем явное ожидание WebDriverWait. После этого заходим на http://localhost:8080, предоставляем адрес электронной почты и пароль, ждем, пока элемент «create a todo» не будет создан, и, наконец, нажимаем на него. Все видели запуск Selenium, и в данном конкретном коде нет ничего необычного.
Этот тест ужасен. Давайте разберемся, почему. В первую очередь, он работает на удачу. Получив страницу, мы не дожидаемся, пока появится элемент, через который осуществляется вход. Таким образом, мы рассчитываем на то, что WebDriver правильно угадает время загрузки страницы. В приведенном примере происходит просто отображение HTML, поэтому такой подход срабатывает, но в других случаях возникнут проблемы.
Еще важнее — то сумасшествие, которое мы видим в другом участке кода: driver.findElements(By.tagName("button")).stream() и т.п. Происходит фильтрация, а если ничего не найдено, то зачем-то бросается AssertionError. Лишь после всех этих операций совершается клик, поскольку только тогда понятно, что у нас есть все необходимое. Все согласны, что это выглядит весьма жутко?
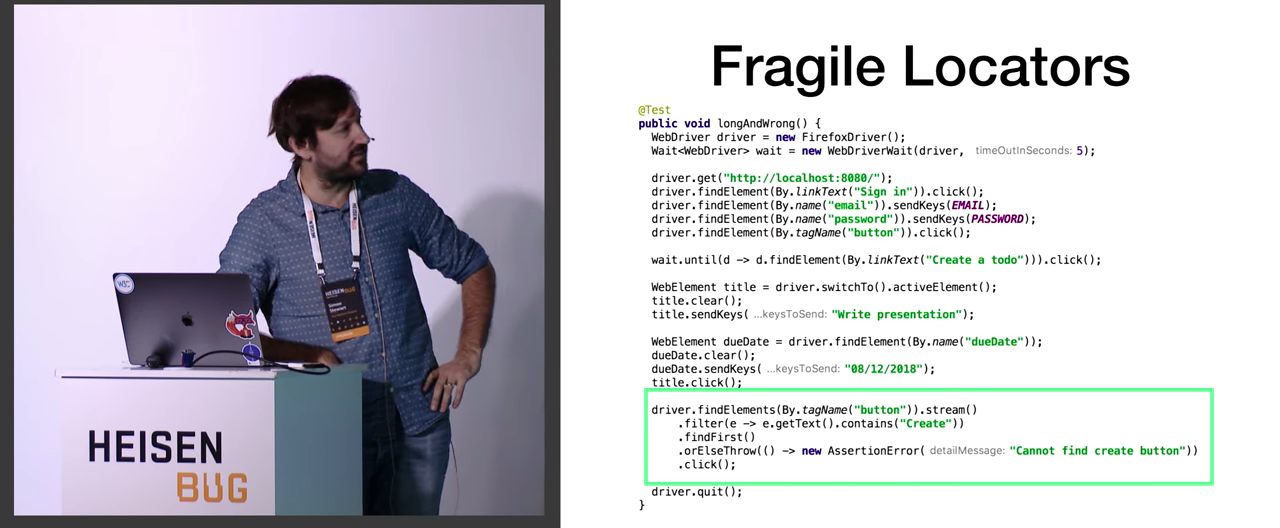

Вот это, выделенное зелёным цветом — это что вообще? Проблема всей этой конструкции в ее хрупкости. И не только этой. Например, использует ли кто-либо из вас чрезмерно длинные XPath? Длинные — значит, длиннее одной строки. Хрупкие локаторы — одна из главных причин, по которой тесты становятся жуткими. О решении этой проблемы много можно узнать в докладе о Selenide.
Есть несколько способов исправить ситуацию. Во-первых, можно правильно переписать само тестируемое приложение, если у вас есть доступ к исходному коду и права на его редактирование. Он есть не всегда. Иногда бывает, что команда разработчиков в Великобритании общается с командой тестировщиков в Румынии через тикеты в джире, и одни говорят, что приложение работает «нормально», а у других оно не проходит тесты. Если есть доступ к коду, то к элементам можно добавить осмысленные идентификаторы: классы, определенные атрибуты.
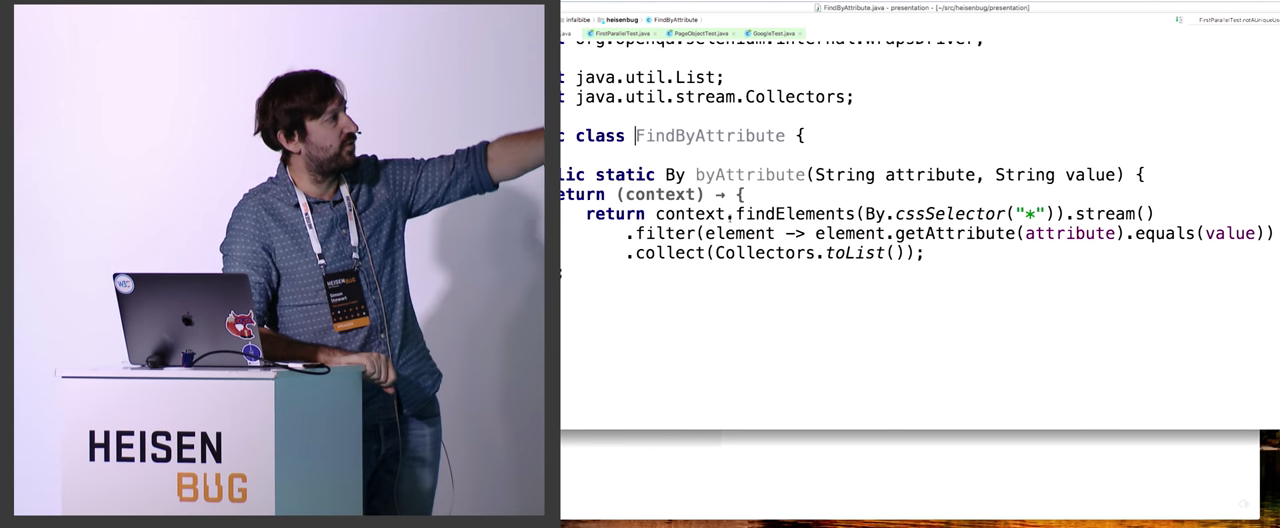
Скорей всего, есть какой-то WebDriver.findElement, который принимает на вход единственный By. Можно вручную от него отнаследоваться. Ищем все элементы по селектору *, ищем все дочерние элементы по дереву, и потом фильтруем по значению аттрибута. Однако это крайне неэффективно. Каждый вызов к WebDriver или Selenium API — это вызов удалённой процедуры, так или иначе он осуществляется через сеть.
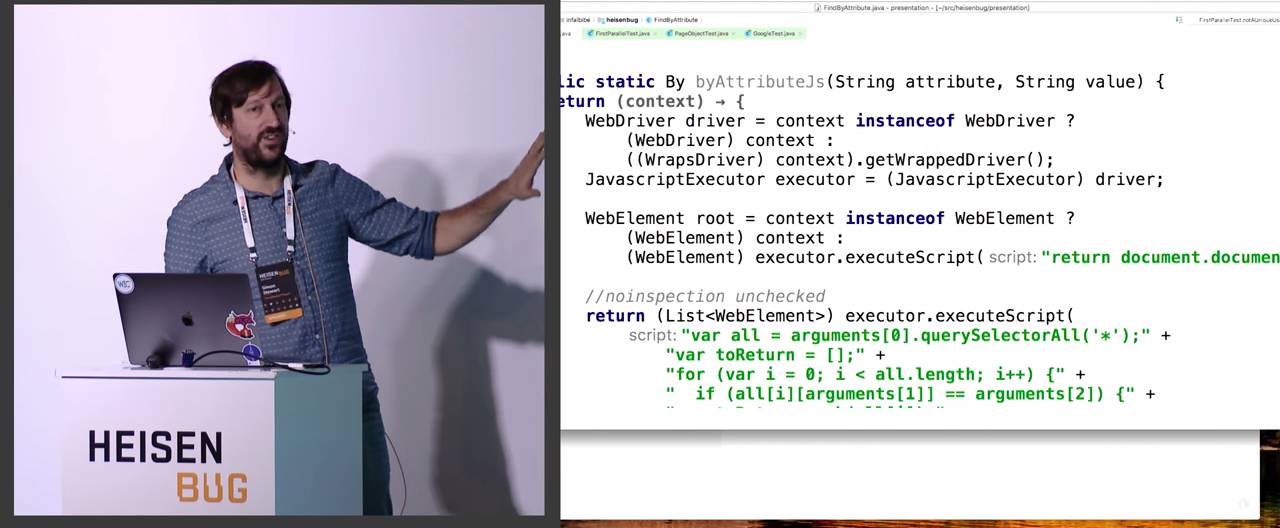
Вместо этого, всё это можно записать на JavaScript, и оно будет делать в точности то же самое. Если посмотрите на слайд, оно выглядит значительно более сложно и страшно, но по сути дела, мы берем контекст и спрашиваем — а ты действительно WebDriver?.. Если да, то смотрим — может, он является одиночным WrapsDriver? Тогда мы можем из него извлечь завёрнутый WebDriver. И так как мы хотим выполнять JavaScript, дальше кастуем его к JavascriptExecutor. Ну и так далее по мелочи. Может кто-то не знает, но executeScript() может возвращать элементы и разные другие штуки. Оно пойдёт в браузер, сделает там какую-то работу, вернёт результат назад, и результат правильно скастуется в джавовые типы. То что вы видите на экране — действительно работает.
Некоторые разработчики мечтают о такой фиче, не зная, что она уже реализована. Допустим, имеется JS-фреймворк, в который уже встроен механизм поиска элементов. Даже если это что-то простое, типа генерации рандомных id :-) Можно не реализовывать этот механизм повторно. Не стесняйтесь попросить сам фреймворк найти нужные элементы! Это существенно упрощает жизнь.
Еще добавлю, зачем Selenium пользуется JavaScript. Кто из читателей пользуется JavaScript-фреймворками в своем приложении? JQuery, React, Angular, или каким-нибудь доморощенным кошмаром? Вот для взаимодействия с ними вам и придется использовать JavaScript. В примере, который я приводил, JQuery отслеживал количество запросов. Другого способа получить от системы однозначную информацию о том, что в ней происходит, нет. Иногда это необходимо. Кроме того, WebDriver пытается смоделировать поведение пользователя. Что делает пользователь? Он щелкает браузер, печатает, нажимает на элементы. Есть вещи, которые WebDriver и Selenium делать не умеют. Если вы хотите отслеживать коды состояния HTTP или сетевой трафик, возможно, вам нужен прокси. Если что-то происходит на странице, лучшим вариантом может быть спросить у самой страницы. Например, достаточно часто идентификаторы создаются случайным образом, хоть и используются упорядоченно. Так что вы не можете всегда рассчитывать на их доступность. Вы можете просто обратиться к странице, чтобы узнать, какой именно идентификатор у элемента, и затем использовать его в обычном указателе. Весь этот механизм позволяет вам делать тестирование по принципу «серого ящика». «Белый ящик» — это когда при тестировании вам полностью доступны внутренности системы, в ситуации «черного ящика» система герметично закрыта, как будто она попала к нам из космоса. А при тестировании «серого ящика» вы вначале хватаетесь за голову от того, как все внутри сложно, а потом начинаете то тут что-то менять, то там вставлять обработчик, и все это делается для того, чтобы тестирование было более стабильным и простым. Кто-то смотрит на это, как на хак. Ларри Уолл считает, что у первоклассного разработчика должно быть три качества: нетерпеливость, высокомерие и лень. Нетерпеливость требует, чтобы все происходило сейчас же. Благодаря этому ваши программы будут быстрыми. Если вас просят что-то делать снова и снова, вы этого делать не будете, для этого есть машины. Ленивый человек готов поработать очень много один раз, чтобы не работать больше никогда. Так что я в описанном подходе вижу не хак, а лень. Я мог бы попытаться разобраться, как оно устроено — или я могу об этом у кого-то спросить. Моя жизнь станет проще. Ну, а высокомерие — это просто желание пустить пыль в глаза.
Еще одна тема — это ожидание события. Есть в Selenium такая штука — Wait<?>.

Надеюсь, все знакомы с ней. В Selenium есть два способа подождать чего-то: явный и неявный. В неявном мы ждём какое-то непонятное время, в явном — используем то, что вы сейчас видите на иллюстрации. Совет от команды Selenium: не используйте неявные ожидания, используйте Wait.until!.. Почему? Проблема в том, что люди, как правило, не знают, сколько времени нужно ждать, и поэтому выставляют время неявного ожидания вплоть до минуты. Если всё в порядке — это не проблема, всё отлично. Но если тест упал, он займёт лишнюю минуту перед остановкой. Благодаря этому запуск тестов, обычно занимающий 5-15 минут, может растянуться на несколько часов.
Если время у явного ожидания короче, чем у неявного, мы по сути будем работать только с результатами неявного ожидания. Это очень сильно сбивает с толку, поддерживать такие тесты невозможно. Но всё-таки так делать можно.
Да, явные ожидания очень странно взаимодействуют с неявными. Странно — не значит «непредсказуемо». На самом деле, все абсолютно предсказуемо. Если выполняется команда, которая задает время неявного ожидания, она не закончит выполнение, пока время не истечет. Предположим, время неявного ожидания — 10 секунд, а явного — 15. Вы выполняете запрос, который через 10 секунд сообщает, что он не удался. Явное ожидание затем сравнивает 10 и 15, решает, что 15 больше, и выполняет новое ожидание, снова 10 секунд. Вы же ломаете голову, почему оно ждет 20 секунд, если я задал 15? Не всегда ясно, когда будут запущены неявные ожидания. Так что все происходит совершенно предсказуемо, но если эту внутреннюю механику не знать, со стороны это поведение может казаться крайне странным, и жизнь ваша будет крайне сложной. Мой совет — не пользуйтесь неявными ожиданиями вообще. Явные ожидания несут определенные сведения. Ваш набор тестов не только проверяет работу кода, он описывает то, как функционирует система для людей, с ней незнакомых. К примеру, явные ожидания могут сообщать: в данный момент должно произойти подключение к интернету, должен быть совершен вызов AJAX, нечто должно обновиться и т. п. Человек, читающий ваш тест, может спросить: а система действительно этим занимается в данный момент? Должна ли она этим заниматься? Зачем она это делает? Это позволяет вам вести диалог, невозможный при другом подходе. В общем, явные и неявные ожидания взаимодействуют, не всегда очевидным образом, но неявные всегда оказываются приоритетнее.
Вернёмся к изначальному тесту.

Он нигде не спит. Наивный подход в том, что если в какой-то момент надо подождать — просто запустим Thread.sleep(). Проблема с таким подходом в том, что тест будет ждать слишком долго. Так делать не надо.
Вместо этого следует использовать класс Wait. Его преимущество в том, что он использует дженерики, поэтому тип, который вы закинете на вход, будет проброшен в until(). Например, можно написать Wait.until(d -> driver.findElement(...)), оно найдет элемент, until его пробросит дальше, и из него очень удобно прямо там же вызвать .isDisplayed().
Кроме того, бывает удобно хранить ссылку на WebElement, чего люди почему-то избегают. Я достаточно много общаюсь с клиентами, посещаю их сайты и замечаю, что для каждого взаимодействия с элементом они ищут его заново. Таким образом, для каждого вызова действия осуществляется два удалённых вызова. Предположим, вам нужно получить значение и отправить ключи. В этом случае люди зачастую пишут вначале driver.switchTo().activeElement().clear(), а затем driver.switchTo().activeElement().sendKeys().
Но элемент при этом один и тот же. Единственная ситуация, в которой он может поменяться — если он полностью удалён или отключен от DOM, и в этом случае вы получите StaleElementReferenceException. Не правда ли, вы все без ума от этого исключения? Оно сообщает, что нечто обновило DOM, и там уже нет искомого элемента. Это значит, возможность выставить ожидание пропущена — не получится дождаться появления нужного элемента.
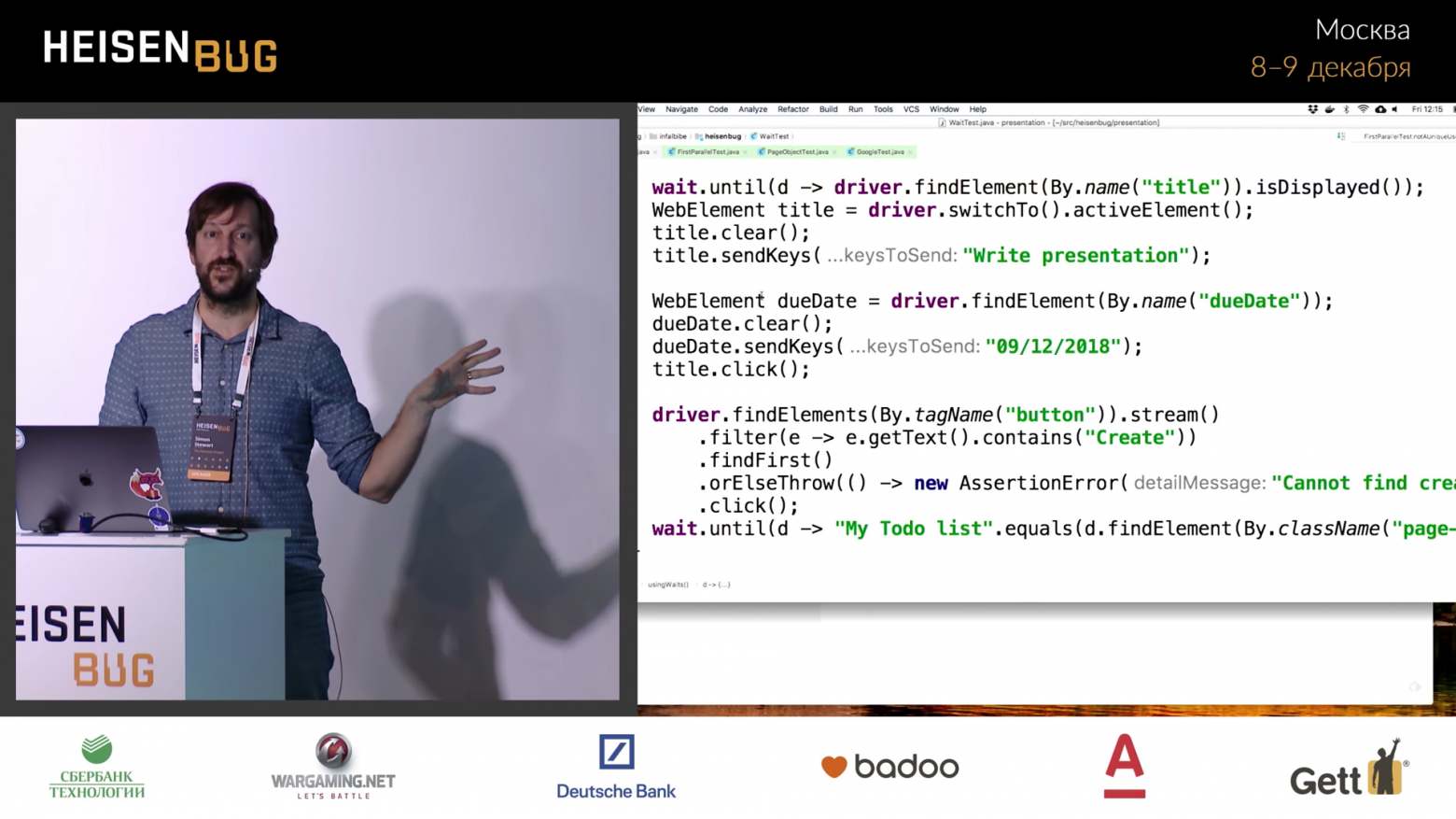
Показанный на экране код будет выполняться оптимальное количество времени, поскольку ожидание будет сведено к необходимому минимуму. Если перезапустить тест с этим кодом, результат не изменится вообще.
Вы всё ещё читаете? Надеюсь, пока что я не сказал ничего нового :-)
Итак, тестирование по принципу «серого ящика».

Есть способы сделать ожидания более эффективными. Посмотрите на метод isJqueryDone() на слайде выше. Он ведет учет активных операций. Если jQuery.active становется равен 0, становится ясно, что ничего больше не происходит.
С другой стороны, зачем постоянно дергать страницу, чтобы узнать эту статистику? Ведь похожий механизм есть в JS-фреймворках. В AngularJS, например. Почему нельзя ограничиться только этим? Возможно, библиотеки — просто не тот уровень.
А ещё, проблему можно решить при помощи вашего приложения. Предположим, вы осуществляете вызов AJAX и хотите знать, завершен он или нет. Иногда обновление DOM не происходит, и в него просто вбрасывается новый контент. Становится непонятно, можно ли продолжать тест. Может быть, всё осталось по-прежнему, и тест можно продолжать? В такой ситуации это стоит отслеживать на уровне приложения — при совершении осмысленной операции нужно создать переменную, а по завершении операции её значение можно обнулить. Тогда можно будет проверять эту переменную, и когда она примет правильное значение — это будет значить, что можно спокойно продолжать тестирование дальше.
Наконец, можно обратиться за помощью к Selenium. Ссылки на устаревшие элементы могут оказаться полезной информацией. Если ожидается, что в результате ваших действий элемент DOM будет обновлен и удален из DOM, можно получить ссылку на элемент прежде, чем это действие выполнять. Тогда возможно будет дождаться исключения StaleElementReference, найти новый элемент и вернуть его. В Wait можно игнорировать некоторые виды исключений, так что этот код будет чистым, опрятным и простым в использовании. Selenium возьмёт часть работы на себя. Сигналы, говорящие об изменении DOM, о том что под капотом что-то передвинулось — отличная возможность сделать тестирование более стабильным.
Перейдем к Page Objects. Слышали о боге Янусе из древнеримской мифологии?

Янус — двухголовый бог, смотрящий в прошлое и в будущее. Именно поэтому Январь назвали его именем.
Page Objects часто становятся жертвой непонимания. В выступлениях на SeleniumConf была куча презентаций про автоматическую генерацию PageObjects, про автоматическое определение положения элементов. Так делать нельзя. Это только выглядит красиво, потому что кажется, что «напишешь фреймворк» и будешь молодцом, в реальности всё будет куда хуже.
В изначальном определении Page Object — одно из лиц Януса. Это службы, обращенные к пользователю. Если у тестируемого приложения есть страница входа, то вам захочется залогиниться на неё, и описать всё это на языке предметной области. Если вы покажете такой тест бизнес-аналитику, владельцу проекта, вашим родителям — им сразу станет ясно, правильно ли ведет себя приложение. Но у Page Object есть и другое лицо Януса, требующее глубоких знаний кода и структуры страницы. Это нужно для DRY («don’t repeat yourself»), для абстрагирования. Для облегчения задачи, Selenium предоставляет класс LoadableComponent. Мне кажется, название Page Object не совсем отражает суть, поскольку здесь можно моделировать более мелкими кусками, намеренно уменьшать их размер.
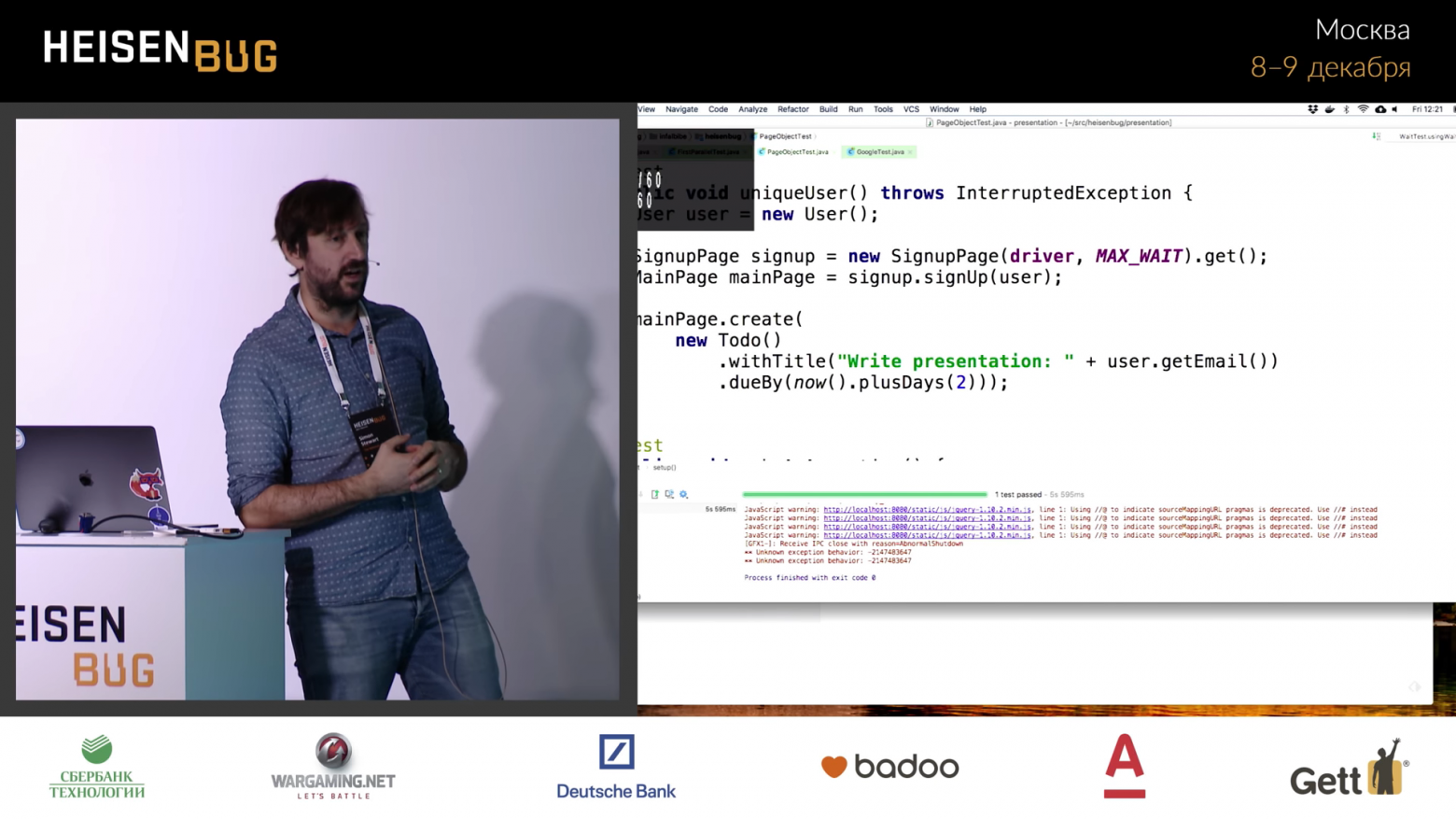
У меня здесь есть тест, использующий Page Objects. Он делает абсолютно то же, что и предыдущий тест. Мы создаем объект User, переходим на страницу входа и передаем ей driver и максимальное время ожидания, после чего выполняем на ней get(). Это происходит по нашей модели LoadableComponent. Если залогиниться, то назад вернётся главная страница. Преимущество того, как шаблон Page Object реализован в этом тесте — он осуществляет навигацию. Если страница входа больше не перебрасывает MainPage, вы меняете сигнатуру функции и возвращете из метода signUp что-нибудь другое. Такой тест даже запускать не нужно, он попросту не скомпилируется.
Давайте посмотрим на демку:

Это простенький TODO-список. Не поражает воображение, зато хорошо иллюстрирует идею.
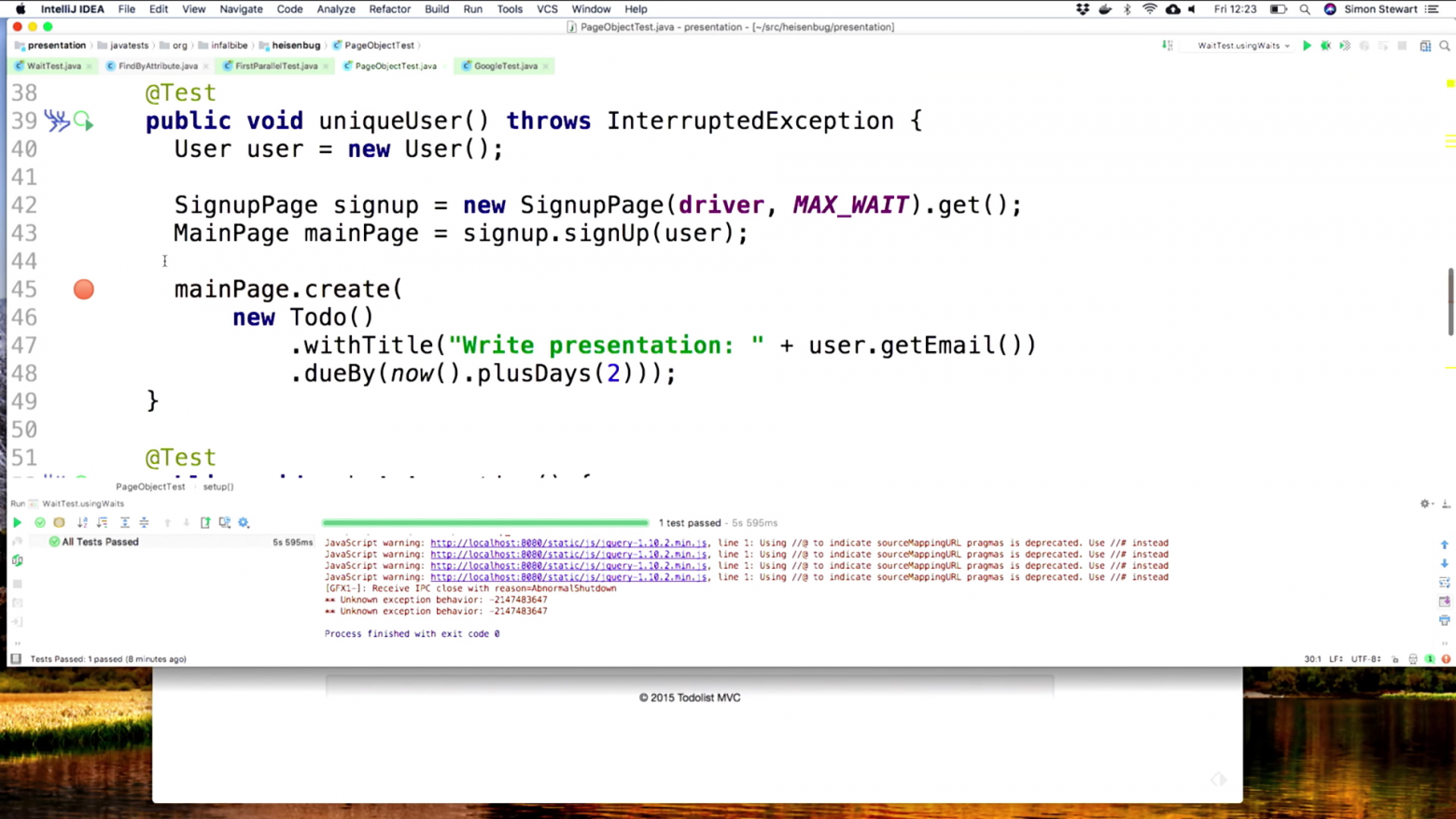
В коде функции SignupPage.signUp() не происходит ничего, кроме поиска элементов.

Всё абстрагировано и помещено в одну эту функцию. Если поменяется код страницы входа, эта функция — единственное место, где нужно будет делать поправки. Если ваши разработчики поменяли UI workflow или переименовали какой-то элемент, то все изменения будут здесь. Альтернатива — бегать по миллионам тестов и исправлять их.
На этом закончим с основами. У нас есть тест, поддержку которого легко осуществлять. Один из способов масштабировать Selenium — это просто писать хорошо работающие и легко поддерживаемые тесты. Однажды я встретился с клиентами, которым сказали, что их задача — делать так, чтобы набор тестов был зеленым. Они решили эту задачу, убрав все проверки, а в случае выпадения исключений — завершали тест успешно. Тестирование в целом завершалось успешно, но это ни о чем не говорило.
Ещё, крайне важны используемые данные. Вряд ли ваше приложение абсолютно stateless. Скорее всего, у вас есть пользователи, постоянные данные и многое другое. Данные — это одна из проблем, с которой вы столкнетесь при масштабировании тестов. Есть несколько рекомендаций о том, как параллелить тесты.

Во-первых, static в Java и паттерн проектирования Singleton — это зло, их надо избегать. Причина в том, что статические поля общие для всех тредов. Если поменять это поле из двух тестов одновременно, результат будет непредсказуемым. Общаясь с клиентами, часто вижу использование статической переменной для хранения ссылки на WebDriver. Возникают жалобы на сумасшедшее поведение тестов, когда они запускаются параллельно: иногда работают, а иногда — нет. Это называется «состояние гонки» («race condition»).
Пытаясь избежать static, кое-кто переключается на использование ThreadLocal. Однако он — также зло. Он заставляет полагаться на thread affinity. Если постоянно быть уверенным, что тест исполняется в одном и том же треде, можете безопасно телепортировать данные с уровня на уровень. Сам факт того, что вам приходится телепортировать данные (экземпляр WebDriver, имя пользователя) — это уже дурной знак, это code smell. Значит, они плохо структурированы. В них сложно разобраться, сложно поддерживать. Тест, в котором сложно разобраться, — источник огромных неприятностей. Один коллега сказал, что для отладки теста нужно в два раза больше ума, чем для его написания. Если для написания теста вам пришлось задействовать все ваши способности, то во время отладки вы упретесь в тупик, выбираться из которого будет крайне мучительно. Одна из вещей, которым нас научило функциональное программирование, в том числе, в Java: идеальный код должен быть неизменяемым (immutable) и не должен сохранять состояния (stateless). Если вы создаете объект Todo (как на предыдущих иллюстрациях), чтобы в нём что-то поменять, нужно создать новый объект. Если же есть два треда, одновременно работающих с изменяемым состоянием, это приводят к жутким последствиям.
Представьте такой тест: пользователь Fred заходит на example.com и регистрируется, регистрация должна быть успешной. В первый раз тест проходит успешно. Однако при повторном запуске теста, он падает, потому что пользователь с именем Fred уже зарегистрирован. Неприятно, не правда ли? Уверен, что вы встречаетесь с таким постоянно. Правильный подход — для каждого теста иметь данные, подготовленные специально для него.

Эта проблема встречается нечасто, поскольку вы воссоздаёте окружение между запусками тестов. Однако она обязательно возникнет, если вы попытаетесь организовать CI/CD (непрерывную интеграцию и сборку). Тест запускается во все большем и большем количестве мест (что тоже является масштабированием, горизонтальным), вероятность конфликта данных растет, начинают возникать необъяснимые ошибки.
Чтобы избежать таких проблем, нужно готовить данные внутри самого теста. Но здесь есть трудность — «окостенение» данных.

Окостенение означает затвердевание чего-либо пластичного и податливого, к примеру, кода или данных. Изменить их становится всё сложнее и сложнее. В dev среде, скорей всего, можно подкладывать данные прямо в базу. Но в продакшне подкладывать случайные данные уже не стоит. Но как было бы здорово, если б тесты можно было запускать и в продакшне тоже! Не обязательно делать полный прогон, достаточно happy path.
В dev окружении можно использовать генераторы данных. Это работает так: когда мы пишем какой-то ассерт (должен существовать пользователь с таким-то именем или с таким-то паролем, у некоторого пользователя должно быть три элемента todo), генератор данных автоматически подсовывает в базу такие данные, чтобы утверждения начали выполняться. Когда то же самое запущено в продакшне, происходит отбор из списка существующих вариантов, область поиска уменьшается до тех пор, пока в базе не найдётся нечто, соответствующее критериям поиска. Благодаря этому можно масштабировать тест, начиная от локального запуска на одной машине, и вплоть до продакшна. Как именно это сделать — ваш выбор. Просто имейте в виду, что по мере приближения к продакшну данные «окостеневают».
Пример классического веб-приложения.

Сервер осуществляет сбор пользовательских данных, которые затем хранятся в базе данных. Также он использует службу аутентификации, которая проверяет имена пользователей и пароли при помощи LDAP. Ничего необычного здесь нет. Но предположим, что служба аутентификации не запущена — возможно, у вас нет LDAP, а собственная версия службы написана ужасно. Если запустить тесты, то они упадут. Но ошибки будут вызваны не той проблемой, которую вы пытаетесь решить, а тем, что одна из служб не запущена. Вы заранее знаете, что эти тесты не пройдут. По мере того, как тесты растут, нужно вводить проверки предварительных условий для запуска тестов. Предположим, перестала работать база данных — это всегда неприятно, многое перестает работать. Но, скорее всего, тесты службы аутентификации по-прежнему могут быть успешно пройдены. В большинстве инструментов тестирования есть механизмы для маркировки тестов или фильтрации их результатов. Можно пометить тесты в соответствии с теми системами бэкенда, которые им требуются. Перед запуском теста можно осуществлять подобную проверку, в JUnit для этого есть класс Assume. Или можно фильтровать результаты уже выполненных тестов.
Возвращаясь к вопросу, зачем вообще заниматься тестированием. Чтобы знать, что софт работает, когда он выпущен в продакшн. Если мы знаем, что одна из систем бэкенда не запущена, результаты тестов этой системы не должны влиять на наше решение о том, можно ли делать релиз. Тесты ценны постольку, поскольку люди им доверяют и могут на них положиться. Если доверия нет, тесты можно попросту стереть. Бывает так, вы запускаете тест, он завершается с ошибкой, вы спрашиваете автора — «Это нормально?», и вам отвечают — «Не переживай, он всегда выдает ошибку». Сотрите этот тест. Он уничтожает доверие, от него больше вреда, чем пользы. Ни ошибки, ни успешные завершения такого теста вам ничего не говорят.
Итак, на данном этапе мы уже разобрались, как организовать пользовательские данные для тестирования, а сами тесты можно запускать параллельно по всей организации, в различных средах. Наш код легко поддерживается благодаря использованию Page Objects и, возможно, шаблона Screenplay, о котором говорит Энтони Марконо. Но можно масштабироваться и другим способом, запуская колоссальное количество тестов одновременно.
Как именно работает Selenium?

Под WebDriver находится протокол Wire. В сущности, это передача определенным образом отформатированных JSON-данных на URL. Существует два основных диалекта: Json Wire Protocol и W3C Dialect. Первый иногда называют OSS Dialect. Он обеспечивает привычную нам функциональность, которая реализована в ChromeDriver, старом FirefoxDriver, его использует Selenium Server, PhantomJS. Диалект W3C — это версия протокола Wire, прошедшая процесс стандартизации. Есть два принципиальных отличия. Первое — это то, как создается новая сессия, второе — это Actions. Если вы пользовались старой версией Selenium Grid и FirefoxDriver, у вас могли быть проблемы вроде неработающего drag-n-drop. Причина как раз в различиях между протоколами. Имейте это в виду.
Перед вами обычная архитектура Selenium: тесты взаимодействуют с отдельным сервером.

Но дальше вам скорее всего захочется иметь дополнительные узлы для запуска ваших тестов. Здесь может помочь Selenium Grid. Запустим в режиме хаба:

Selenium будет получать входящие запросы и распределять их. Посмотрим на консоль:

Если сейчас запустить тест, он не заработает вообще. Нужно запустить ещё одну ноду. Для упрощения жизни, если нода запускается на той же машине, что и хаб, она регистрируется автоматически. Теперь в браузере мы видим стандартную конфигурацию: Firefox, Chrome и, поскольку он знает, что у меня macOS — Safari:

Проблема в том, что здесь требуется обязательно иметь установленный ChromeDriver, GeckoDriver, правильно указать пути и вообще, проделать много работы. Я буду с вами откровенен: это попросту уже не модно? потому что не используется Docker. Вот если бы был докер — это ого-го!
Мода в нашей отрасли имеет большое значение, не правда ли? Да, большинство здесь в джинсах и футболке, в относительно удобной одежде. Но у нас острейший нюх на моду. Если не используется Docker, если нет микросервисов, и ещё ряда вещей — попросту нет смысла в это вкладываться.
К счастью, Selenium знает, что вы любите модные вещи. Поэтому существует подпроект — Selenium Docker. Это набор совместимых образов браузеров, которые используются для тестирования. Становится не важно, установлен ли у вас GeckoDriver или ChromeDriver, какая версия Firefox у вас работает с какой версией GeckoDriver и т. п. В результате в вашей архитектуре Selenium-тесты взаимодействуют с хабом, а ноды запущены в Docker-контейнерах.

Если запустить простую сеть с хабом и двумя нодами (одна для Chrome, другая — для Firefox).

Теперь в браузере мы видим два этих узла.

Когда в них будут запущены тесты, они будут использовать Docker, и он позволит нам масштабировать эту систему. Очевидно, как сюда добавить дополнительные узлы. На одном жалком ноутбуке всего четыре ядра, поэтому на нём быстро перестанет хватать мощности. Думаю, если запустить больше 8 тредов, он начнет загибаться. Но преимущество в том, что эти узлы можно запускать в разных местах, а регистрировать — в одном.

Зачастую вам не нужно запускать все узлы одновременно, и вы не знаете заранее, какая ситуация может возникнуть. Вам нужно, чтобы на хабе можно было запускать экземпляры Docker по мере необходимости. Этого можно достичь благодаря проекту Zalenium. Он достаточно прост в использовании.

Если запустить его в Docker, то в браузере будет предлагаться выбор между двумя браузерами:

На достаточно сильной машине хаб может запускать ноды по необходимости. Или можно сочетать эти подходы, пусть часть узлов продолжит работать постоянно. Но есть нюанс. Мало у кого есть легкодоступное реальное реально железо с Windows, на котором можно запускать, например, тесты для браузера Edge.

Отсюда появляется третий тип архитектуры. Нам необходимо доставать эти машины из облака. К счастью, в Zalenium есть очень простой механизм для этого.

При запуске Zalenium в консоли выставляется опция --sauceLabsEnabled true, происходит вход в Sauce Labs по логину и паролю. Теперь в браузере видно, можно запускать тесты, используя инфраструктуру Sauce Labs, если вдруг локально их запустить не получается.

Помимо этого *Zalenium*** может демонстрировать вам все происходящее в реальном времени.

В Zalenium есть панель мониторинга, на урле /dashboard. Когда тест завершен, там появляется видеозапись всего происшедшего с журналом и проч. Благодаря всей этой системе, внутри своей компании вы можете поддерживать собственную сеть с хабом и нодами. И когда вам перестает хватать мощности, возникнет необходимость в масштабировании, или когда у вас просто нет машины с Windows или macOS, можно прибегнуть к помощи Sauce Labs, BrowserStack или какого-то другого облачного провайдера.
Можно сразу идти к в облачный провайдер. Проблема с таким подходом в том, что между каждым запуском теста и получением результатов ваши данные дважды будут передаваться через интернет. Получив запрос, облако передает его на сервер Selenium, который затем обращается к вашему браузеру, тот передает на сервер запросы HTTP, и затем сервер возвращает результаты. Все это происходит жутко медленно, но по этому пути можно пойти, если хочется самостоятельно заниматься поддержкой.
При масштабировании тестов есть несколько ловушек. Первая — случайный DDoS, когда вы запускаете так много тестов, что несчастный сервер не выдерживает. Если вы начинаете сталкиваться со случайными ошибками, проведите анализ первопричин. Достаточно часто проблема кроется в том, что какой-то части вашей инфраструктуры перестало хватать ресурсов. Пользователи Selenium часто пытаются исправлять ошибки, не понимая их причин. Поскольку ошибки никуда не уходят, в коде возникают все более сложные структуры, люди начинают пользоваться жуткими хаками.

Другая проблема, которая возникает с тестами — так называемый «рожок мороженого». Это ситуация, когда большая часть тестов — сквозные (верхняя часть «рожка»), а юнит-тестов совсем небольшое количество (низ «рожка»). Вид радостного мелькания браузеров, вероятно, вселяет уверенность в себе и повышает самооценку. Однако такой подход абсолютно бесполезен, поскольку сквозные тесты не дают никаких точных данных. Единственное, что от них можно узнать — это что где-то в стеке произошла ошибка, но чем именно она вызвана — неясно.
В идеале структура тестов должна выглядеть, как пирамида: много юнит-тестов и небольшое количество сквозных.

Если нужно преобразовать рожок мороженого в пирамиду, надо проводить анализ первопричин при ошибках в сквозных тестах и затем писать как можно более маленькие тесты специально для этих ошибок. В идеале, это должны быть юнит-тесты. Мой обычный совет: перестаньте писать Selenium-тесты. Если вы пытаетесь масштабировать Selenium — это похоже на проблему.
Иногда люди для каждого изменения в коде запускают все свои тесты. Так поступать не следует. Если вы ничего не меняли на сервере аутентификации, вам не надо запускать тест этого сервера. Благодаря современным средствам сборки вроде Buck или Bazel, выполняющим анализ графов, вам не обязательно запускать все тесты одновременно. Но тут может помочь даже маркирование тестов.
Наконец, пытайтесь избегать запуска каждого теста в каждом браузере на каждой платформе. С одной стороны, это дает чувство безопасности, с другой, это — явный перебор. Большая часть браузеров сегодня соответствуют общим стандартам, так что если вы все протестировали в одном браузере, скорее всего это будет работать во всех остальных. В них можно ограничиться набором тестов на общую работоспособность, чтобы убедиться, что ничего сущностного не было поломано. В идеале у вас также будут тесты JavaScript, которые как раз можно запускать в каждом браузере при каждом изменении. Как выбрать, в каком браузере запускать тест? Взгляните на пользовательские данные, на логи, и вам станет ясно, что же люди используют больше всего. На этом и стоит сфокусировать тестирование. Это не распространяется на ситуацию, когда вы собираетесь поменять способ использования сайта.
Минутка рекламы. Как вы, наверное, знаете, мы делаем конференции. Ближайшая конференция про тестирование — Heisenbug 2018 Piter, которая пройдет 17-18 мая 2018 года в Санкт-Петербурге. Можно туда прийти, послушать доклады (какие доклады там бывают — вы уже увидели в этой статье), вживую пообщаться с практикующими экспертами в тестировании и разработчиками разных моднейших технологий. Короче, заходите, мы вас ждём!
