
Всем привет! Меня зовут Александр Афенов, и я тимлид команды Order Processing в Lamoda. Сегодня хочу рассказать вам о том, как мы разгребаем саппорт.
Сначала поговорим про то, как он встраивается в наши процессы и как в целом мы планируем свою работу, спринты и итерации.
Затем расскажу, откуда вообще саппорт может прилетать и на какие виды он подразделяется.
Поделюсь опытом того, как мы внутри команды справляемся с каждым из видов саппорта.
В конце рассмотрим плюсы и минусы используемых нами практик и подведем итоги.
В ведении моей команды сейчас находится две системы. Первая – большая и страшная штука под названием Order Processing. Это система, которая автоматизирует жизненный цикл заказа от процесса создания до доставки (или возврата).
Сервис крутится на РНР 7, завернут в Docker и оркестрируется Kubernetes, но при этом реализован на фреймворке Zend1 и кусках Symfony 2. Те, кто программируют на РНР, сейчас, возможно, содрогнулись. Для остальных я поясню, что Zend1 – это фреймворк, у которого случился end of life полтора года назад. Он больше не поддерживается и не имеет даже патчей по безопасности.
Проект большой (более 150 тысяч строк кода), и он делает кучу не своей работы. Например, не только процессит заказы, но почему-то отправляет почту, sms, пуши, передает данные в другие системы. Поэтому мы его распиливаем на отдельные микросервисы.
Первое, что мы вынесли из монолита – это так называемый Refund tool. Он является вторым сервисом в ведении моей команды и отвечает за автоматическое возвращение денег клиенту (подробнее в докладе моего коллеги).
Несмотря на то, что у Refund tool современный технологический стек, он все равно порождает кучу саппорта из-за наследия Order processing.
Происходит это из-за того, что мы взяли некий бизнес-процесс, который раньше строился на множестве excel-файлов, и перенесли его в новую систему, которая работает через Kafka, а также взаимодействует еще с парой систем. Разумеется, что при внесении новой системы и изменении бизнес-процесса, у нас появился саппорт. И за долгие годы работы с этим мы накопили некоторый опыт.
Я верю в то, что люди делятся на две категории: те, у кого продакшн-система порождает саппорт, и чёртовы лжецы. Поэтому я поделюсь опытом, который может быть полезен в оптимизации ваших процессов. Если предложенные решения (в комплексе или по отдельности) подойдут вам, то появится больше времени на развитие функциональности своей системы, разбор технического бэклога, а не на работу с саппортом.
Для рассказа об используемых инструментах потребуется контекст, поэтому сначала речь пойдет о самом основном.

Как мы работаем с саппортом и какое место он занимает в наших спринтах?

10% мы берем из технического бэклога на то, чтобы он не застаивался и бесконечно не накапливался.
Примерно 20% спринта берем на то, чтобы заложиться на какие-то риски. Например, кто-то делал задачу, но этого человека “сбил автобус”. Следующему придется заново вникать в контекст. В итоге мы не попадем в оценку, и все будет плохо.
Далее мы закладываем запланированный саппорт. То есть мы уже знаем, что что-то не так. Это что-то не сильно горит, и мы будем его чинить.
Но самая интересная вещь – это незапланированный саппорт. То есть мы предполагаем, что за период итерации что-то может сломаться, и мы потратим время на ремонт.
Оставшиеся 30% — это проекты.
Наверное, вы заметили, что здесь получается больше 100%. Связано это с тем, что мы стараемся всегда сделать больше, чем реально можем. Иногда нам это удаётся, иногда не очень.
Каждому саппортному тикету мы даем оценку по следующим параметрам:
Если у пользователей наших систем что-то пошло не так, то они сообщают об этом в службу поддержки и уточняют, что некий инцидент блокирует частично или полностью бизнес-процесс. Поддержка сразу же заводит новый тикет в ответственную систему и ставит ей приоритет.
Blocker – что-то сломало абсолютно все, остановило бизнес. Не создаются заказы, не уходят в доставку, не принимаются платежи и так далее.
Major — это что-то менее важное и можно починить в течение более длительного времени, так как есть обходные процессы, альтернативные пути.
Trivial. Например, кто-то пишет, что у нас кнопки неприятного цвета и их стоит перекрасить. Существует большая вероятность, что такой тикет никогда не будет сделан.
Есть еще такая вещь как service level agreement, который устанавливается службой поддержки совместно с командой и бизнес-владельцем системы. Они смотрят на то, какое направление бизнеса сломалось в рамках конкретной жалобы. Если, например, перестали создаваться заказы (основной хлеб интернет-магазина), то у этой проблемы будет высокий приоритет, который мы называем Р1. Р — priority, единичка — самое важное.
Р1 — это тип SLA, который означает, что мы должны взять проблему в работу в течение получаса и решить ее за пару часов максимум.
Р2 — это что-то менее значимое, что мы должны взять в работу в течение пары часов и решить в течение дня.
Р3-Р4 — это то, что сломалось и не требует срочного ремонта. Можно когда-нибудь сделать, взять в следующую итерацию.
И тут мы подходим к приоритетности, которая устанавливается командой. Это может быть техлид, senior, саппорт-инженер — любой, кто занимается проблемой.
Допустим, у нас есть в данный момент 4 задачи с бизнес-приоритетом Major. Человек из команды за счет своей экспертизы ставит некое числовое значение, которое мы называем detailed priority. На его основе в дальнейшем будут отсортирована борда саппорта. То есть наверху окажутся самые приоритетные для бизнеса задачи, которые внутри еще отсортированы по пониманию команды о том, насколько это в действительности важно и насколько быстро можно это сделать.
Кажется, что среди основных параметров не хватает одного наиболее важного – нормального описания. Довольно часто у нас появляются саппортные задачи, заведенные из системы Sentry, куда падают ошибки, exception’ы и т.д. Человек видит, что появилась какая-то небольшая проблема, и создает задачку в Jira. Так как у нас системы интегрированы друг с другом, то в таск-трекере появляется задача, в описании которой есть только ссылка на Sentry, а в названии – текст ошибки. Все.
Как с этим должен работать тот, кто эту задачу получит? Не очень понятно. Если бы вы добавили в эту задачу хорошее описание, то это значительно бы помогло и сэкономило время.
И вот когда все это сделано, возникает вопрос: кто будет этот красиво отсортированный бэклог разгребать? Ответ такой: саппорт-инженер.
Что он делает еще?
1. Старается выделить и устранить root cause, то есть первопричину возникновения саппорта. Когда к вам прилетают регулярно однотипные тикеты, то стоит задуматься, почему так происходит. Скорее всего, где-то есть проблема, которую можно устранить, и тем самым остановить поток похожих задач.
2. Ставит задачи на исправление и заведение мониторингов.
Если саппорт-инженер не может решить проблему за день или два максимум, то он заводит на нее отдельную задачу, которая переходит в бэклог по разработке. Далее она оценивается командой и попадает в итерацию как запланированный саппорт.
Немаловажную роль для нас играют мониторинги. Мы навешиваем мониторинги не только на метрики, за которыми привыкли следить на постоянной основе, но и добавляем их для локализации самых долгоиграющих проблем. На мой взгляд, лучше пусть у нас будет ненужный мониторинг, который мы потом выпилим, чем проблема будет постоянно повторяться в виде всё новых и новых тикетов.
3. Ищет поводы для автоматизации.
Пример: мы передаем данные в нашу систему, которая автоматизирует работу службы доставки. Иногда получается так, что даже с использованием dead letter channel и переотправок, мы не можем доставить туда информацию. В итоге такие заказы где-то зависают, и их нужно переотправить.
Это типичный саппорт, который возникает каждую неделю по несколько раз. Для решения этой проблемы мы решили сделать отдельную страничку с кнопкой “переотправить список заказов”. Больше у нас этого саппорта нет. То есть задумались, автоматизировали, отдали службе поддержки.
Кажется, что очевидно, но об этом все равно часто забывают. Для того, чтобы все работало, необходимо, чтобы наши процессы были поставлены на поток и регулярно соблюдались.
Осмотр бэклога
Откуда у нас возьмется красиво отсортированный саппортный бэклог, если туда никто не смотрит?
По-хорошему, в него нужно забегать раз в месяц и закрывать задачки со статусом trivial (до которых вы, скорее всего, никогда не дойдете). Будьте честны перед собой и заказчиком. Если бэклог из-за таких задач будет бесконечно разрастаться, то впоследствии вам придется в панике пытаться их закрыть. Это не очень хорошо.
Проставление detailed priority
Это тот самый процесс, в рамках которого мы оцениваем, насколько та или иная задача действительно критична. Именно тогда будет корректная сортировка, а саппорт-инженер возьмет сверху правильную задачу.
Сражение за приоритет
Например, вам поставили задачу и говорят: “Ребят, не выгружается ежемесячный отчет. Нам его через неделю надо уже иметь, а он не работает. Пожалуйста, почините. Приоритет Р1. Нужно в течение 2-3 часов решить.”
И вы спрашиваете: “Серьезно? О чем речь, ребят? Ведь есть неделя, чтобы это зафиксить. Давайте снизим до Р2, и у нас будет пара дней.”
Порою люди думают, что мы не будем браться за задачу, поэтому ставят специально высокий приоритет. Но бывает и наоборот. Например, нам пишут, что не создаются заказы и ставят приоритет P2. Эта проблема намного серьезнее, поэтому тут стоит поднять приоритетность до P1. Полезно уметь осознанно торговаться в обе стороны.
Заведение новых задач
Ранее я упоминал систему Sentry, в которую попадают задачи, которые уже полыхают у клиентов. Однако мы сами предвосхищаем возникающие проблемы и накидываем в этот бэклог задачи самостоятельно.
Контроль выполнения SLA
Для этого у нас есть графики, по которым видно, что у нас есть задачи, время на выполнение которых уже скоро истечет. Кажется, что эти задачки имеет смысл брать в работу в первую очередь.
Быть саппорт-инженером — это довольно депрессивный процесс, поэтому человеку стоит помогать. Как же мы можем облегчить ему жизнь?
Передача роли следующему из команды
Нужно вести график того, кто на следующей неделе будет этим заниматься. Однако случаются граничные моменты. Например, человек взял задачу в пятницу и не успел доделать. Он может потратить время на следующей неделе, но лучше передать задачу новому саппорт-инженеру. Если затянуть на две недели разгребание бэклога, человек, скорее всего, будет изрядно демотивирован. Вы это увидите уже на ближайшей личной встрече :)
Помочь в поиске первоисточника проблемы
Люди любят просто разгребать задачи, но при этом не фокусируются на поиске той самой первопричины. Стоит задать вопрос: “Если ты закрыл задачу, то почему проблема изначально возникла?”. Эта практика позволит найти причину, устранить ее, и, возможно, избавиться от потока такого саппорта в будущем.
Потребность в “свежем взгляде”
Если человек за определенный промежуток времени не смог добиться видимого результата, то эту задачу стоит передать другому. Кто-то еще сможет посмотреть на задачу с другой стороны, что может привести к решению проблемы иным путем.
Но такой подход может скрывать в себе некоторые интересные психологические моменты. То есть забирая задачу у одного человека и отдавая другому, вы рискуете сказать, что тот знает лучше, поэтому он справится. Такие вещи лучше преподносить другим образом. Делайте акцент на том, что нам всем вместе нужно решить проблемы с системой, а не доказывать друг другу, кто из нас круче.
Разработка инструментов для автоматизации
Те, кто часто бывают саппорт-инженерами, понимают, что у них уже “печет” от выполнения одних и тех же типичных задач. Недавно у одного из наших разработчиков появился целый свой мини фреймворк на Go. Он ходит в разные базы, собирает данные, что-то пушит в Kafka. Таким образом, ему удалось максимально автоматизировать эту задачу и облегчить жизнь другим.

Саппорта бывает так много, что мы порой не задумываемся о том, а откуда он вообще так часто прилетает?
Стабилизация новых систем и процессов
Если вы что-то привнесли новое, то, скорее всего, оно будет использовано некорректно. Вы нарветесь на новые для себя проблемы, а ваш саппортный бэклог сразу же пополнится тикетом или тикетами.
Поддержка развития старых систем
Например, наш монолит. Он не может стоять на месте, так как мы все время в него что-то добавляем, переписываем. Безусловно, это приводит к порождению нового саппорта.
Технический сбой
Например, отключилась сеть. Вы вроде бы не виноваты, но к вам обязательно придут и спросят, почему не создались заказы. Нужно будет что-то починить, исправить, доработать. Потребуется ручное вмешательство, а, значит, и новые тикеты в бэклоге обеспечены.
Человеческий фактор
У нас был случай, когда кто-то смог запродюсить в RabbitMQ сообщение, которое повесило наш консьюмер, и все перестало работать. Такого никогда не происходило на протяжении предыдущих 7 лет, а тут вот как-то удалось :)
Человеческий фактор, который привел к сбою
Кто-то со словами «я сейчас все починю» выдернул жесткий диск из сервера, на котором крутился биллинг. В итоге получили то, что получили. Это не опыт Lаmoda, но реальный случай из моей практики.

Запрос на аналитику
Когда регулярно спрашивают статус чего-либо в базе данных, просят сделать выгрузку, собрать отчет за определенный период и так далее. Это немного раздражает, поэтому у вас есть хороший повод подумать об автоматизации и о том, чтобы просто предоставить пользовательский интерфейс или изучить структуру компании.
Например, я не сразу узнал, что большинство данных о заказе у нас хранятся в Oracle базе департамента D&A, и все можно достать оттуда. Такой саппорт либо автоматизируется через интерфейсы, либо передается в отдел аналитики.
Запросы на изменение данных
Ситуации бывают разные и непредсказуемые. Допустим, наш клиент собирался оплачивать свой заказ картой. Когда приехал курьер, он передумал и решил это сделать наличными. Или, например, где-то возникла неавтоматизированная проблема, которую надо изменить руками.Нам необходимо эти данные подправить.
Для этого мы стараемся делать новые ручки API, делать интерфейсы и по максимуму сбрасывать эти задачи с разработки и с нашей команды Operations. Это опасная практика, и от этого мы избавляемся именно через интерфейс и доработки API.
Ремонт бизнес-процессов
Если в базе напрямую возникает потребность что-то править, значит есть глючный бизнес-процесс. Это могло произойти либо по причине, связанной с IT, либо в бизнесе что-то идет не так. И там, и там требуются корректировки. В таком случае нужно идти к бизнес-заказчику и обсуждать, можно ли сделать это по-другому, или запросить разработку для ремонта бизнес-процесса.
Фича Х перестала работать
Это мой любимый тип саппорта, потому что он самый понятный. То есть у нас была какая-то штука в проде, но она поломалась и ее нужно пофиксить. Выясняете, в каком релизе сдохло и по какой причине. Чините и закрываете тикет. Все просто.
Но есть другой саппорт — фича X не работает. Может выглядеть как то же самое, но сказанное другими словами. Однако это не так.
В такой ситуации к вам приходят и говорят, что вот эта штука не работает. Вы тратите день-два на то, чтобы разобраться. Только потом запоздало понимаете, что это тут не работало никогда. Ее просто не было в вашей системе.
По-другому я называю этот тип саппорта «лиса», когда кто-то хитрый хочет вам под видом саппортной задачи подсунуть фича-реквест. Это регулярная история, которая очень болезненная. Если не пресекать такие моменты, то получится, что ваш саппорт-инженер или вы сами занимаетесь привнесением нового функционала, а реальные проблемы из саппортного бэклога остаются нерешенными.

Это как раз история про гроб и торфяной пожар, когда что-то сломалось в IT-системах настолько сильно, что встал конкретный бизнес-процесс.
Кейс из нашей практики: мы из-за ошибки в коде и неидеальных автотестов начали отдавать во внешнюю курьерскую службу определенную пометку о статусе заказа, из-за которой люди не могли на пункте выдачи забрать свой заказ. Это затронуло тысячи клиентов. Нам пришлось все заказы везти обратно, тратить на это деньги. Продать мы их не смогли, а лояльность клиентов была потеряна. Это большой инцидент, который нанес ущерб бизнесу.
С такими вещами стоит работать особенным образом, и я расскажу как это делаем мы.
Как узнать, что что-то происходит?
Самый распространенный в индустрии вариант — это узнать от пользователей. Он, разумеется, худший, потому что это значит, что у них уже “печет”. Они видят, что у вас ничего не работает, и нужно срочно чинить.
Возможно, вы это узнаете от службы поддержки, которая следит за мониторингами и нотифицирует дежурного по системе.
Но самое приятное — узнавать самостоятельно по наличию мониторингов. То есть у вас может использоваться система, которая отслеживает динамику по метрикам. Например, если на подвешенном телевизоре что-то загорелось красным, то, допустим, умер Rabbit.
Это прикольно, но, кажется, что этого мало. Многие проблемы можно отловить еще на подходе, если мониторить определенные тренды. У нас был такой кейс, когда мы заметили на мониторе, что с утра начал расти расход памяти на кластере Rabbit MQ. Мы понимали, что у нас там всего 16 гигабайт, и с такой динамикой через несколько часов память кончится, и все упадет.
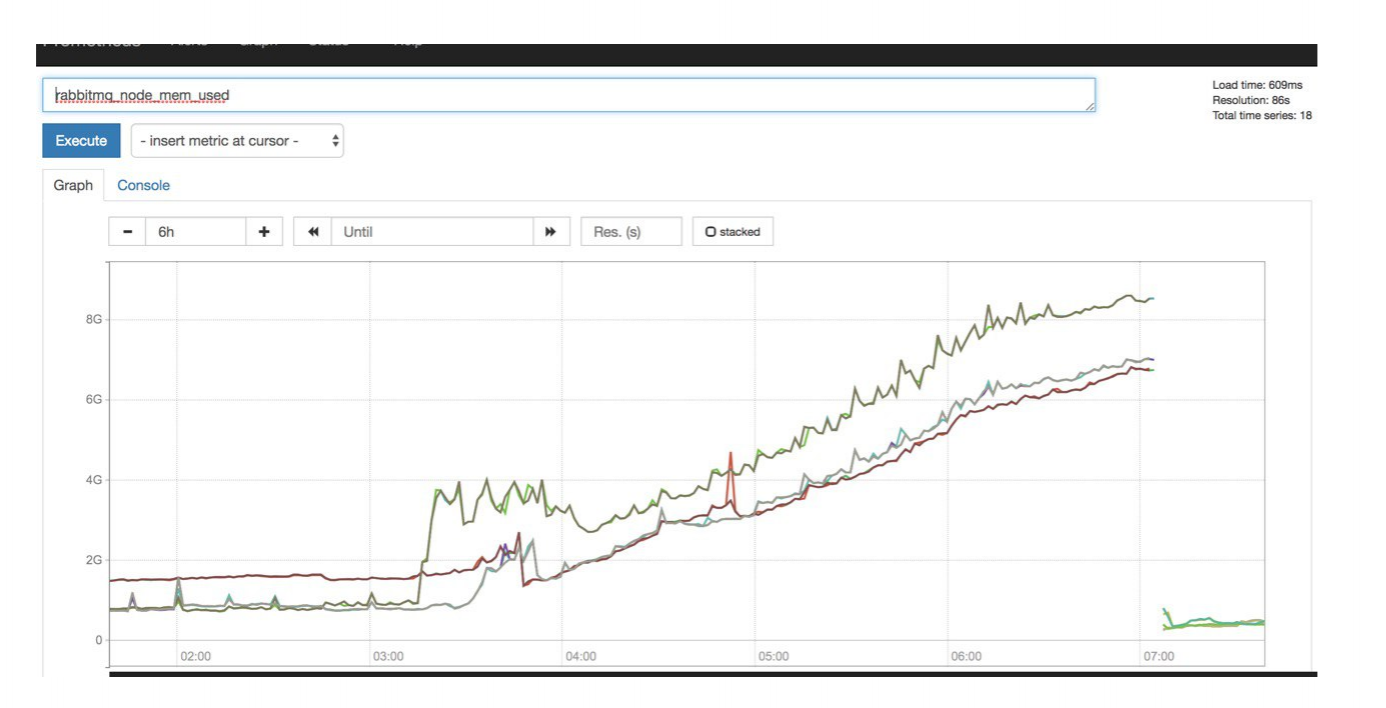
Так как мы увидели такую тенденцию, то вовремя всполошились. Оказалось, что у нас завис shovel-plugin, и течет память. Проблема была решена, а major предотвращен.
Если что-то уже произошло, и вы об этом узнали, надо как-то локализовать и потушить. Конечно, в зависимости от размера команды и того, чем она занята, вы можете поступать по-разному. Но я верю в то, что очень важна мобилизация.
Предположим, что у вас в команде 5 человек. Один из них занялся разбором, почему сейчас ничего не работает, в то время как оставшиеся четверо продолжают пилить свои фичи. В итоге у вас есть неработающие системы и куча новых фич. Это прикольно, но иногда стоит все-таки мобилизоваться и устроить brainstorm. Экспертиза каждого участника команды может сократить время, в течение которого ничего не работает.
И после того, как удалось все потушить, наступает этап ретроспективы.

У нас в Lamoda на этой встрече есть ответственный за каждую систему, вовлеченную в инцидент. Если необходимо, то присутствует кто-то от бизнеса, иногда даже приходит CTO. И на этой встрече мы составляем описание того, что конкретно произошло, и в какой системе это полыхнуло.
Дальше наступает самый веселый момент — анализ последовательности действий. То есть, что мы делали между обнаружением и тушением с точностью до минуты, если это возможно.

Мы видим, что в 13.05 поступила жалоба в колл-центр. Приблизительно к 13.13 стало понятно, что она массовая. И лишь только в 14.50 команда взяла задачу в работу. Перед этим почему-то 1,5 часа был простой, хотя задача была поставлена, а команда оповещена. Кажется, что этот гэп в 1,5 часа можно было бы сократить и тем самым сэкономить на этом инциденте миллионы рублей.
Почему эта проблема возникла?
Просто ребята встали и пошли обедать, не взяв ноутбуки и телефоны, поэтому они были недоступны. Кажется, в этом моменте стоит что-то поправить. Например, брать с собой ноутбуки, оставлять дежурного в случае, если был крупный релиз.
Также видно, что фикс оказался в продакшене в 16.55, что тоже странно, так как до этого прошло уже 40 с лишним минут. Когда вроде все проверено, можно катить, но мы этого не делали.
Почему так происходит?
У нас очень долго гоняются интеграционные тесты, примерно полчаса. И в этой ситуации выходит, что нужно принимать решение. Либо вы выкатываете поправленную систему и тушите проблему, а может быть создаете новую. Либо вы ждете, когда прокрутятся супер-долгие CI/CD процессы, и релиз уедет в бой. Очевидно, что в нашем случае надо сокращать время, которое уходит на прогон всех тестов, чтобы мы могли с момента, когда все проверено, быстрее прогнать тесты, быстрее покатить.
Следующий момент — это оценка импакта. Импакт — это влияние этого инцидента на бизнес. А именно, сколько компания потеряла в заказах, в рублях, в попугаях – неважно. Это та цифра, с которой потом можно будет прийти к бизнесу и показать, что происходит, если IT не дают время на стабилизацию, автоматизацию тестирования и тому подобные вещи.
Затем формулировка preventive actions. Это важно, потому что вам нужно как-то гарантировать себе, руководству и кому угодно, что эта же штука не выстрелит сегодня же вечером, завтра и так далее. То есть вам нужно не повторить этот же инцидент. Для этого мы формулируем preventive actions. То есть, как вы этого добьетесь, как от этого защититься или предвосхитить.
Также необходимо проставить дедлайны/fix versions.
А затем проконтролировать выполнение. Планы — это хорошо, но избежание проблемы — намного важнее.
На мой взгляд, важно также помнить, что обычный саппорт ничем не хуже Major Incident. Вы можете взять серьезную багу, с которой возились день или больше, пройтись по тем же самым степам и понять, почему она произошла, почему ее так долго решали, каким образом избежать в будущем. Применяя этот же паттерн, можно эффективнее разгребать рядовой саппорт, который не относится к Major Incident.
Наличие саппорта вполне понятным образом влияет на рабочий процесс. Он отвлекает и бесит, потому что, как правило, все хотят пилить новые фичи. Однако вместо этого приходится разгребать бесконечные тонны саппорта, эти авгиевы конюшни.
С другой стороны, когда человек занимается регулярным саппортом, он умудряется пощупать самые разные части системы, потому что саппорт структурирован по критичности, но не по бизнес-процессам. Это позволяет быстрее наращивать экспертизу по системе.
Где же взять на это все время?
Первоначальный ответ такой — непонятно где. И это правда, потому что это очень сильно зависит от каждого конкретного бизнеса.
Lamoda была организована несколькими управляющими директорами, один из которых курировал IT. Он смог объяснить другим управляющим директорам, отвечающим за другие части бизнеса, что если мы создаем сервис-провайдер и интернет-магазин со своей автоматизацией и внутренней разработкой, то важно научиться договариваться намного заранее о том, как бизнес взаимодействует с IT-департаментом. А также ему удалось донести, что не стоит пытаться на 80% заполнить спринты новыми фичами, не оставив времени ни на стабилизацию, ни на саппорт, ни на разгребание проблем. Он смог это сделать и добиться результата.
Однако я понимаю, что так далеко не у всех. Именно поэтому я верю, что если применять подход с ретроспективой к серьезному саппорту, то можно будет показать бизнесу, какие деньги вылетают в трубу просто из-за того, что IT не дается достаточно ресурсов и времени на решение внутренних проблем и разгребание саппорта.

Я верю в то, что если вы будете применять эти методики, станет легче предвосхищать появление проблем и устранять их первопричины, да и в целом перестанете наступать на одни и те же грабли, то достигните очень интересного состояния. Это состояние, в котором каждый новый вид саппорта будет для вас новым. Может звучать иронично, забавно или как угодно еще, но в действительности это дорогого стоит, потому что вы будете понимать, что не решаете раз за разом одну и ту же проблему. И я надеюсь, что вам это удастся.
Сначала поговорим про то, как он встраивается в наши процессы и как в целом мы планируем свою работу, спринты и итерации.
Затем расскажу, откуда вообще саппорт может прилетать и на какие виды он подразделяется.
Поделюсь опытом того, как мы внутри команды справляемся с каждым из видов саппорта.
В конце рассмотрим плюсы и минусы используемых нами практик и подведем итоги.
В ведении моей команды сейчас находится две системы. Первая – большая и страшная штука под названием Order Processing. Это система, которая автоматизирует жизненный цикл заказа от процесса создания до доставки (или возврата).
Сервис крутится на РНР 7, завернут в Docker и оркестрируется Kubernetes, но при этом реализован на фреймворке Zend1 и кусках Symfony 2. Те, кто программируют на РНР, сейчас, возможно, содрогнулись. Для остальных я поясню, что Zend1 – это фреймворк, у которого случился end of life полтора года назад. Он больше не поддерживается и не имеет даже патчей по безопасности.
Проект большой (более 150 тысяч строк кода), и он делает кучу не своей работы. Например, не только процессит заказы, но почему-то отправляет почту, sms, пуши, передает данные в другие системы. Поэтому мы его распиливаем на отдельные микросервисы.
Первое, что мы вынесли из монолита – это так называемый Refund tool. Он является вторым сервисом в ведении моей команды и отвечает за автоматическое возвращение денег клиенту (подробнее в докладе моего коллеги).
Несмотря на то, что у Refund tool современный технологический стек, он все равно порождает кучу саппорта из-за наследия Order processing.
Происходит это из-за того, что мы взяли некий бизнес-процесс, который раньше строился на множестве excel-файлов, и перенесли его в новую систему, которая работает через Kafka, а также взаимодействует еще с парой систем. Разумеется, что при внесении новой системы и изменении бизнес-процесса, у нас появился саппорт. И за долгие годы работы с этим мы накопили некоторый опыт.
Я верю в то, что люди делятся на две категории: те, у кого продакшн-система порождает саппорт, и чёртовы лжецы. Поэтому я поделюсь опытом, который может быть полезен в оптимизации ваших процессов. Если предложенные решения (в комплексе или по отдельности) подойдут вам, то появится больше времени на развитие функциональности своей системы, разбор технического бэклога, а не на работу с саппортом.
Для рассказа об используемых инструментах потребуется контекст, поэтому сначала речь пойдет о самом основном.
Процессы и роли
Как мы работаем с саппортом и какое место он занимает в наших спринтах?
Пропорциональные ведра — это то, как я называю наши бакеты.
10% мы берем из технического бэклога на то, чтобы он не застаивался и бесконечно не накапливался.
Примерно 20% спринта берем на то, чтобы заложиться на какие-то риски. Например, кто-то делал задачу, но этого человека “сбил автобус”. Следующему придется заново вникать в контекст. В итоге мы не попадем в оценку, и все будет плохо.
Далее мы закладываем запланированный саппорт. То есть мы уже знаем, что что-то не так. Это что-то не сильно горит, и мы будем его чинить.
Но самая интересная вещь – это незапланированный саппорт. То есть мы предполагаем, что за период итерации что-то может сломаться, и мы потратим время на ремонт.
Оставшиеся 30% — это проекты.
Наверное, вы заметили, что здесь получается больше 100%. Связано это с тем, что мы стараемся всегда сделать больше, чем реально можем. Иногда нам это удаётся, иногда не очень.
Основные параметры саппорта
Каждому саппортному тикету мы даем оценку по следующим параметрам:
- Критичность для бизнеса. Насколько им это важно и насколько это ломает бизнес-процесс?
- SLA. В течение какого времени мы должны взять проблему в работу и решить ее ?
- Приоритетность.
Если у пользователей наших систем что-то пошло не так, то они сообщают об этом в службу поддержки и уточняют, что некий инцидент блокирует частично или полностью бизнес-процесс. Поддержка сразу же заводит новый тикет в ответственную систему и ставит ей приоритет.
Критичность и приоритетность — это разные терминыВиды приоритетов
Blocker – что-то сломало абсолютно все, остановило бизнес. Не создаются заказы, не уходят в доставку, не принимаются платежи и так далее.
Major — это что-то менее важное и можно починить в течение более длительного времени, так как есть обходные процессы, альтернативные пути.
Trivial. Например, кто-то пишет, что у нас кнопки неприятного цвета и их стоит перекрасить. Существует большая вероятность, что такой тикет никогда не будет сделан.
Есть еще такая вещь как service level agreement, который устанавливается службой поддержки совместно с командой и бизнес-владельцем системы. Они смотрят на то, какое направление бизнеса сломалось в рамках конкретной жалобы. Если, например, перестали создаваться заказы (основной хлеб интернет-магазина), то у этой проблемы будет высокий приоритет, который мы называем Р1. Р — priority, единичка — самое важное.
Р1 — это тип SLA, который означает, что мы должны взять проблему в работу в течение получаса и решить ее за пару часов максимум.
Р2 — это что-то менее значимое, что мы должны взять в работу в течение пары часов и решить в течение дня.
Р3-Р4 — это то, что сломалось и не требует срочного ремонта. Можно когда-нибудь сделать, взять в следующую итерацию.
И тут мы подходим к приоритетности, которая устанавливается командой. Это может быть техлид, senior, саппорт-инженер — любой, кто занимается проблемой.
Допустим, у нас есть в данный момент 4 задачи с бизнес-приоритетом Major. Человек из команды за счет своей экспертизы ставит некое числовое значение, которое мы называем detailed priority. На его основе в дальнейшем будут отсортирована борда саппорта. То есть наверху окажутся самые приоритетные для бизнеса задачи, которые внутри еще отсортированы по пониманию команды о том, насколько это в действительности важно и насколько быстро можно это сделать.
Кажется, что среди основных параметров не хватает одного наиболее важного – нормального описания. Довольно часто у нас появляются саппортные задачи, заведенные из системы Sentry, куда падают ошибки, exception’ы и т.д. Человек видит, что появилась какая-то небольшая проблема, и создает задачку в Jira. Так как у нас системы интегрированы друг с другом, то в таск-трекере появляется задача, в описании которой есть только ссылка на Sentry, а в названии – текст ошибки. Все.
Как с этим должен работать тот, кто эту задачу получит? Не очень понятно. Если бы вы добавили в эту задачу хорошее описание, то это значительно бы помогло и сэкономило время.
Кто же все разгребет?
И вот когда все это сделано, возникает вопрос: кто будет этот красиво отсортированный бэклог разгребать? Ответ такой: саппорт-инженер.
Более подробно о том, кто такой саппорт-инженер и чем он занимается, вы можете послушать в моем докладе «Техническая ипотека: что и кому должен тимлид» с TeamLeadConf 2018.Саппорт-инженер – это парень, который из саппортного бэклога берет и чинит наиболее приоритетные задачки. Так как у нас все красиво отсортировано, мы считаем, что наверху находится самое важное, срочное и “запекающее”. Если задач никаких нет, то он может заняться техническим бэклогом.
Что он делает еще?
1. Старается выделить и устранить root cause, то есть первопричину возникновения саппорта. Когда к вам прилетают регулярно однотипные тикеты, то стоит задуматься, почему так происходит. Скорее всего, где-то есть проблема, которую можно устранить, и тем самым остановить поток похожих задач.
2. Ставит задачи на исправление и заведение мониторингов.
Если саппорт-инженер не может решить проблему за день или два максимум, то он заводит на нее отдельную задачу, которая переходит в бэклог по разработке. Далее она оценивается командой и попадает в итерацию как запланированный саппорт.
Немаловажную роль для нас играют мониторинги. Мы навешиваем мониторинги не только на метрики, за которыми привыкли следить на постоянной основе, но и добавляем их для локализации самых долгоиграющих проблем. На мой взгляд, лучше пусть у нас будет ненужный мониторинг, который мы потом выпилим, чем проблема будет постоянно повторяться в виде всё новых и новых тикетов.
3. Ищет поводы для автоматизации.
Пример: мы передаем данные в нашу систему, которая автоматизирует работу службы доставки. Иногда получается так, что даже с использованием dead letter channel и переотправок, мы не можем доставить туда информацию. В итоге такие заказы где-то зависают, и их нужно переотправить.
Это типичный саппорт, который возникает каждую неделю по несколько раз. Для решения этой проблемы мы решили сделать отдельную страничку с кнопкой “переотправить список заказов”. Больше у нас этого саппорта нет. То есть задумались, автоматизировали, отдали службе поддержки.
Роль саппорт-инженера передается каждую неделю другому человеку – это обязательное условие. Заниматься такой работой дольше — это стресс, демотивация и тлен, потому что вы все время что-то ремонтируете и не привносите в систему ничего нового.
Регулярность как источник благодати
Кажется, что очевидно, но об этом все равно часто забывают. Для того, чтобы все работало, необходимо, чтобы наши процессы были поставлены на поток и регулярно соблюдались.
Осмотр бэклога
Откуда у нас возьмется красиво отсортированный саппортный бэклог, если туда никто не смотрит?
По-хорошему, в него нужно забегать раз в месяц и закрывать задачки со статусом trivial (до которых вы, скорее всего, никогда не дойдете). Будьте честны перед собой и заказчиком. Если бэклог из-за таких задач будет бесконечно разрастаться, то впоследствии вам придется в панике пытаться их закрыть. Это не очень хорошо.
Проставление detailed priority
Это тот самый процесс, в рамках которого мы оцениваем, насколько та или иная задача действительно критична. Именно тогда будет корректная сортировка, а саппорт-инженер возьмет сверху правильную задачу.
Сражение за приоритет
Например, вам поставили задачу и говорят: “Ребят, не выгружается ежемесячный отчет. Нам его через неделю надо уже иметь, а он не работает. Пожалуйста, почините. Приоритет Р1. Нужно в течение 2-3 часов решить.”
И вы спрашиваете: “Серьезно? О чем речь, ребят? Ведь есть неделя, чтобы это зафиксить. Давайте снизим до Р2, и у нас будет пара дней.”
Порою люди думают, что мы не будем браться за задачу, поэтому ставят специально высокий приоритет. Но бывает и наоборот. Например, нам пишут, что не создаются заказы и ставят приоритет P2. Эта проблема намного серьезнее, поэтому тут стоит поднять приоритетность до P1. Полезно уметь осознанно торговаться в обе стороны.
Заведение новых задач
Ранее я упоминал систему Sentry, в которую попадают задачи, которые уже полыхают у клиентов. Однако мы сами предвосхищаем возникающие проблемы и накидываем в этот бэклог задачи самостоятельно.
Контроль выполнения SLA
Для этого у нас есть графики, по которым видно, что у нас есть задачи, время на выполнение которых уже скоро истечет. Кажется, что эти задачки имеет смысл брать в работу в первую очередь.
Поддержка инженера поддержки
Быть саппорт-инженером — это довольно депрессивный процесс, поэтому человеку стоит помогать. Как же мы можем облегчить ему жизнь?
Передача роли следующему из команды
Нужно вести график того, кто на следующей неделе будет этим заниматься. Однако случаются граничные моменты. Например, человек взял задачу в пятницу и не успел доделать. Он может потратить время на следующей неделе, но лучше передать задачу новому саппорт-инженеру. Если затянуть на две недели разгребание бэклога, человек, скорее всего, будет изрядно демотивирован. Вы это увидите уже на ближайшей личной встрече :)
Помочь в поиске первоисточника проблемы
Люди любят просто разгребать задачи, но при этом не фокусируются на поиске той самой первопричины. Стоит задать вопрос: “Если ты закрыл задачу, то почему проблема изначально возникла?”. Эта практика позволит найти причину, устранить ее, и, возможно, избавиться от потока такого саппорта в будущем.
Потребность в “свежем взгляде”
Если человек за определенный промежуток времени не смог добиться видимого результата, то эту задачу стоит передать другому. Кто-то еще сможет посмотреть на задачу с другой стороны, что может привести к решению проблемы иным путем.
Но такой подход может скрывать в себе некоторые интересные психологические моменты. То есть забирая задачу у одного человека и отдавая другому, вы рискуете сказать, что тот знает лучше, поэтому он справится. Такие вещи лучше преподносить другим образом. Делайте акцент на том, что нам всем вместе нужно решить проблемы с системой, а не доказывать друг другу, кто из нас круче.
Разработка инструментов для автоматизации
Те, кто часто бывают саппорт-инженерами, понимают, что у них уже “печет” от выполнения одних и тех же типичных задач. Недавно у одного из наших разработчиков появился целый свой мини фреймворк на Go. Он ходит в разные базы, собирает данные, что-то пушит в Kafka. Таким образом, ему удалось максимально автоматизировать эту задачу и облегчить жизнь другим.
Источники саппорта
Саппорта бывает так много, что мы порой не задумываемся о том, а откуда он вообще так часто прилетает?
Стабилизация новых систем и процессов
Если вы что-то привнесли новое, то, скорее всего, оно будет использовано некорректно. Вы нарветесь на новые для себя проблемы, а ваш саппортный бэклог сразу же пополнится тикетом или тикетами.
Поддержка развития старых систем
Например, наш монолит. Он не может стоять на месте, так как мы все время в него что-то добавляем, переписываем. Безусловно, это приводит к порождению нового саппорта.
Технический сбой
Например, отключилась сеть. Вы вроде бы не виноваты, но к вам обязательно придут и спросят, почему не создались заказы. Нужно будет что-то починить, исправить, доработать. Потребуется ручное вмешательство, а, значит, и новые тикеты в бэклоге обеспечены.
Человеческий фактор
У нас был случай, когда кто-то смог запродюсить в RabbitMQ сообщение, которое повесило наш консьюмер, и все перестало работать. Такого никогда не происходило на протяжении предыдущих 7 лет, а тут вот как-то удалось :)
Человеческий фактор, который привел к сбою
Кто-то со словами «я сейчас все починю» выдернул жесткий диск из сервера, на котором крутился биллинг. В итоге получили то, что получили. Это не опыт Lаmoda, но реальный случай из моей практики.
Виды саппорта
Запрос на аналитику
Когда регулярно спрашивают статус чего-либо в базе данных, просят сделать выгрузку, собрать отчет за определенный период и так далее. Это немного раздражает, поэтому у вас есть хороший повод подумать об автоматизации и о том, чтобы просто предоставить пользовательский интерфейс или изучить структуру компании.
Например, я не сразу узнал, что большинство данных о заказе у нас хранятся в Oracle базе департамента D&A, и все можно достать оттуда. Такой саппорт либо автоматизируется через интерфейсы, либо передается в отдел аналитики.
Запросы на изменение данных
Ситуации бывают разные и непредсказуемые. Допустим, наш клиент собирался оплачивать свой заказ картой. Когда приехал курьер, он передумал и решил это сделать наличными. Или, например, где-то возникла неавтоматизированная проблема, которую надо изменить руками.Нам необходимо эти данные подправить.
Для этого мы стараемся делать новые ручки API, делать интерфейсы и по максимуму сбрасывать эти задачи с разработки и с нашей команды Operations. Это опасная практика, и от этого мы избавляемся именно через интерфейс и доработки API.
Ремонт бизнес-процессов
Если в базе напрямую возникает потребность что-то править, значит есть глючный бизнес-процесс. Это могло произойти либо по причине, связанной с IT, либо в бизнесе что-то идет не так. И там, и там требуются корректировки. В таком случае нужно идти к бизнес-заказчику и обсуждать, можно ли сделать это по-другому, или запросить разработку для ремонта бизнес-процесса.
Фича Х перестала работать
Это мой любимый тип саппорта, потому что он самый понятный. То есть у нас была какая-то штука в проде, но она поломалась и ее нужно пофиксить. Выясняете, в каком релизе сдохло и по какой причине. Чините и закрываете тикет. Все просто.
Но есть другой саппорт — фича X не работает. Может выглядеть как то же самое, но сказанное другими словами. Однако это не так.
В такой ситуации к вам приходят и говорят, что вот эта штука не работает. Вы тратите день-два на то, чтобы разобраться. Только потом запоздало понимаете, что это тут не работало никогда. Ее просто не было в вашей системе.
По-другому я называю этот тип саппорта «лиса», когда кто-то хитрый хочет вам под видом саппортной задачи подсунуть фича-реквест. Это регулярная история, которая очень болезненная. Если не пресекать такие моменты, то получится, что ваш саппорт-инженер или вы сами занимаетесь привнесением нового функционала, а реальные проблемы из саппортного бэклога остаются нерешенными.
Major Incident
Это как раз история про гроб и торфяной пожар, когда что-то сломалось в IT-системах настолько сильно, что встал конкретный бизнес-процесс.
Кейс из нашей практики: мы из-за ошибки в коде и неидеальных автотестов начали отдавать во внешнюю курьерскую службу определенную пометку о статусе заказа, из-за которой люди не могли на пункте выдачи забрать свой заказ. Это затронуло тысячи клиентов. Нам пришлось все заказы везти обратно, тратить на это деньги. Продать мы их не смогли, а лояльность клиентов была потеряна. Это большой инцидент, который нанес ущерб бизнесу.
С такими вещами стоит работать особенным образом, и я расскажу как это делаем мы.
Как узнать, что что-то происходит?
Самый распространенный в индустрии вариант — это узнать от пользователей. Он, разумеется, худший, потому что это значит, что у них уже “печет”. Они видят, что у вас ничего не работает, и нужно срочно чинить.
Возможно, вы это узнаете от службы поддержки, которая следит за мониторингами и нотифицирует дежурного по системе.
Но самое приятное — узнавать самостоятельно по наличию мониторингов. То есть у вас может использоваться система, которая отслеживает динамику по метрикам. Например, если на подвешенном телевизоре что-то загорелось красным, то, допустим, умер Rabbit.
Это прикольно, но, кажется, что этого мало. Многие проблемы можно отловить еще на подходе, если мониторить определенные тренды. У нас был такой кейс, когда мы заметили на мониторе, что с утра начал расти расход памяти на кластере Rabbit MQ. Мы понимали, что у нас там всего 16 гигабайт, и с такой динамикой через несколько часов память кончится, и все упадет.
Так как мы увидели такую тенденцию, то вовремя всполошились. Оказалось, что у нас завис shovel-plugin, и течет память. Проблема была решена, а major предотвращен.
Если что-то уже произошло, и вы об этом узнали, надо как-то локализовать и потушить. Конечно, в зависимости от размера команды и того, чем она занята, вы можете поступать по-разному. Но я верю в то, что очень важна мобилизация.
Предположим, что у вас в команде 5 человек. Один из них занялся разбором, почему сейчас ничего не работает, в то время как оставшиеся четверо продолжают пилить свои фичи. В итоге у вас есть неработающие системы и куча новых фич. Это прикольно, но иногда стоит все-таки мобилизоваться и устроить brainstorm. Экспертиза каждого участника команды может сократить время, в течение которого ничего не работает.
И после того, как удалось все потушить, наступает этап ретроспективы.
Ретроспектива
У нас в Lamoda на этой встрече есть ответственный за каждую систему, вовлеченную в инцидент. Если необходимо, то присутствует кто-то от бизнеса, иногда даже приходит CTO. И на этой встрече мы составляем описание того, что конкретно произошло, и в какой системе это полыхнуло.
Дальше наступает самый веселый момент — анализ последовательности действий. То есть, что мы делали между обнаружением и тушением с точностью до минуты, если это возможно.
Мы видим, что в 13.05 поступила жалоба в колл-центр. Приблизительно к 13.13 стало понятно, что она массовая. И лишь только в 14.50 команда взяла задачу в работу. Перед этим почему-то 1,5 часа был простой, хотя задача была поставлена, а команда оповещена. Кажется, что этот гэп в 1,5 часа можно было бы сократить и тем самым сэкономить на этом инциденте миллионы рублей.
Почему эта проблема возникла?
Просто ребята встали и пошли обедать, не взяв ноутбуки и телефоны, поэтому они были недоступны. Кажется, в этом моменте стоит что-то поправить. Например, брать с собой ноутбуки, оставлять дежурного в случае, если был крупный релиз.
Также видно, что фикс оказался в продакшене в 16.55, что тоже странно, так как до этого прошло уже 40 с лишним минут. Когда вроде все проверено, можно катить, но мы этого не делали.
Почему так происходит?
У нас очень долго гоняются интеграционные тесты, примерно полчаса. И в этой ситуации выходит, что нужно принимать решение. Либо вы выкатываете поправленную систему и тушите проблему, а может быть создаете новую. Либо вы ждете, когда прокрутятся супер-долгие CI/CD процессы, и релиз уедет в бой. Очевидно, что в нашем случае надо сокращать время, которое уходит на прогон всех тестов, чтобы мы могли с момента, когда все проверено, быстрее прогнать тесты, быстрее покатить.
Следующий момент — это оценка импакта. Импакт — это влияние этого инцидента на бизнес. А именно, сколько компания потеряла в заказах, в рублях, в попугаях – неважно. Это та цифра, с которой потом можно будет прийти к бизнесу и показать, что происходит, если IT не дают время на стабилизацию, автоматизацию тестирования и тому подобные вещи.
Затем формулировка preventive actions. Это важно, потому что вам нужно как-то гарантировать себе, руководству и кому угодно, что эта же штука не выстрелит сегодня же вечером, завтра и так далее. То есть вам нужно не повторить этот же инцидент. Для этого мы формулируем preventive actions. То есть, как вы этого добьетесь, как от этого защититься или предвосхитить.
Также необходимо проставить дедлайны/fix versions.
А затем проконтролировать выполнение. Планы — это хорошо, но избежание проблемы — намного важнее.
На мой взгляд, важно также помнить, что обычный саппорт ничем не хуже Major Incident. Вы можете взять серьезную багу, с которой возились день или больше, пройтись по тем же самым степам и понять, почему она произошла, почему ее так долго решали, каким образом избежать в будущем. Применяя этот же паттерн, можно эффективнее разгребать рядовой саппорт, который не относится к Major Incident.
Подводные плюсы и минусы
Наличие саппорта вполне понятным образом влияет на рабочий процесс. Он отвлекает и бесит, потому что, как правило, все хотят пилить новые фичи. Однако вместо этого приходится разгребать бесконечные тонны саппорта, эти авгиевы конюшни.
С другой стороны, когда человек занимается регулярным саппортом, он умудряется пощупать самые разные части системы, потому что саппорт структурирован по критичности, но не по бизнес-процессам. Это позволяет быстрее наращивать экспертизу по системе.
Где же взять на это все время?
Первоначальный ответ такой — непонятно где. И это правда, потому что это очень сильно зависит от каждого конкретного бизнеса.
Lamoda была организована несколькими управляющими директорами, один из которых курировал IT. Он смог объяснить другим управляющим директорам, отвечающим за другие части бизнеса, что если мы создаем сервис-провайдер и интернет-магазин со своей автоматизацией и внутренней разработкой, то важно научиться договариваться намного заранее о том, как бизнес взаимодействует с IT-департаментом. А также ему удалось донести, что не стоит пытаться на 80% заполнить спринты новыми фичами, не оставив времени ни на стабилизацию, ни на саппорт, ни на разгребание проблем. Он смог это сделать и добиться результата.
Однако я понимаю, что так далеко не у всех. Именно поэтому я верю, что если применять подход с ретроспективой к серьезному саппорту, то можно будет показать бизнесу, какие деньги вылетают в трубу просто из-за того, что IT не дается достаточно ресурсов и времени на решение внутренних проблем и разгребание саппорта.
Sweet spot
Я верю в то, что если вы будете применять эти методики, станет легче предвосхищать появление проблем и устранять их первопричины, да и в целом перестанете наступать на одни и те же грабли, то достигните очень интересного состояния. Это состояние, в котором каждый новый вид саппорта будет для вас новым. Может звучать иронично, забавно или как угодно еще, но в действительности это дорогого стоит, потому что вы будете понимать, что не решаете раз за разом одну и ту же проблему. И я надеюсь, что вам это удастся.
