Появляется всё больше решений, которые уходят от традиционного подхода унифицированных хранилищ. Это специализированные хранилища, которые заточены под задачи определённого направления бизнеса. Ранее я уже рассказывал о системе Infinidat InfiniBox F2230. Сегодня в центре моего обзора SolidFire.
 «Who f*cking hate storage» @ Дэйв Хитс, основатель компании NetApp
«Who f*cking hate storage» @ Дэйв Хитс, основатель компании NetApp
В конце 2015 года компания NetApp объявила о покупке стартапа SolidFire, который был основан в 2010 году. Интерес к этим системам вызван их иным подходом к управлению хранилищами данных и предсказуемой производительностью.
Решения SolidFire дополнили линейку продуктов NetApp, которые включали в себя All Flash FAS (AFF), EF и E серии. Также это позволило спустя полтора года выпустить на рынок и новый продукт — NetApp HCI (Hyper Converged Infrastructure), который в качестве подсистемы хранения использует SolidFire.
Не так давно я уже рассказывал о системе Infinidat InfiniBox F2230, которая прекрасно подходит для задач сервис- провайдеров. Сегодняшнего участника нашего обзора SolidFire также можно отнести к этому классу устройств. Основатель SolidFire Дейв Райт со своей командой — выходцы из RackSpace, где они занимались разработкой эффективной системы хранения, которая обеспечивала бы линейную производительность в среде со множеством пользователей, при этом была простой, легко масштабируемой и обладающей гибкими возможностями автоматизации. В попытке решить эту задачу и родился SolidFire.
На сегодняшний день линейка SolidFire состоит из четырех моделей с разным соотношением IOPS/TB.

Для хранения данных используются 10 (MLC) SSD, а в качестве NVRAM — Radian RMS-200. Правда, уже есть планы по переходу к модулям NVDIMM.

Здесь интерес представляет то, как SolidFire получает и хранит данные. Все мы знаем про ограниченный ресурс SSD накопителей, поэтому логично, что для их наибольшей сохранности компрессия и дедупликация должны происходить на лету, до записи на SSD. Когда SolidFire получает данные от хоста, он разбивает их на блоки 4КБ, после чего этот блок сжимается и сохраняет в NVRAM. Затем происходит синхронная репликация этого блока в NVRAM на «соседнюю» ноду кластера. После этого SolidFire получает хэш данного сжатого блока и ищет этот хеш- значение в своем индексе сохраненных данных в рамках всего кластера. Если блок с таким хэшем уже существует, SolidFire обновляет только свои метаданные со ссылкой на данный блок, если же блок содержит уникальные данные, он записывается на SSD, и также для него записываются метаданные. Этот механизм хранения данных и метаданных очень похож на механизм работы объектного хранилища.
 Наш тестовый кластер из четырех нод
Наш тестовый кластер из четырех нод
Уже появились слухи, что в скором времени произойдёт обновление этой линейки. Стоит отметить одну очень важную вещь — кластер SolidFire способен работать с нодами как с разной «плотностью IOPs/TB», так и объединять в рамках одного кластера ноды разных поколений. Во-первых, это делает использование данной системы более предсказуемой в плане поддержки оборудования, а также облегчает процесс перехода со старых нод на новые, когда вы просто добавляете новые и удаляете старые из кластера в режиме реального времени (дожидаясь только перестроения кластера) без простоев, т.к. имеется поддержка как Scale Out, так и Scale Back.
SolidFire может поставляться в виде трех решений:
Как вы могли заметить из таблицы характеристики, ноды поддерживают только подключение по iSCSI, а для соединения по FC есть отдельный тип нод — Fabric Interconnect, который в свою очередь содержит четыре порта для данных по FC и четыре порта iSCSI для подключения к нодам, а также 64GB собственной системной памяти/кэша на чтение.

В таблице характеристик указана и производительность каждой из нод. Это один из тех случаев, когда вы знаете производительность свой системы хранения данных ещё на этапе покупки. Данная производительность является гарантированной (при профиле нагрузки 4Kb, 80/20) на каждую ноду.
Соответственно, покупая кластер из X нод или расширяя существующее решение, вы понимаете, какой объём и какую производительность вы получите в конечном итоге. Конечно, вы можете выжать из каждой ноды и большую производительность при определённых условиях, но это не то, для чего данное решение разрабатывалось. Если вы хотите получить миллионы IOPS в 2U на единственном томе, вам лучше обратить своё внимание на другие продукты, к примеру на AFF. Наибольшую производительность на SolidFire можно получить при большом количестве томов и сессий.
 Главная страница интерфейса
Главная страница интерфейса
Управление хранилищем довольно просто. Фактически у нас есть два пула ресурсов: объём и IOPS’ы. Выделяя один из типов ресурсов и зная их конечное количество, мы чётко понимаем другие возможности нашей системы. Это опять-таки делает расширение системы крайне простым занятием. Нужна дополнительная производительность? Рассматриваем SF4805 или SF19210 с «менее плотным» соотношением IOPS/TB. Нужен объём? Смотрим в сторону SF9605 и SF38410, которые предоставляют меньше IOPS на Gb.
С точки зрения администратора СХД, система смотрится довольно скучно. Такие вещи, как дедупликация и компрессия, работают по умолчанию.
Репликация и снепшоты также имеются, причём репликация может быть организована для всей линейки продуктов NetApp (кроме E-серии). Именно эта простота, на мой взгляд, и раскрывается за цитатой Дэйва Хитса из заголовка статьи. Учитывая, что данная система предполагает интеграцию с различными системами динамического выделения ресурсов, без участия администратора и без дополнительных трудозатрат, в скором времени вы вообще забудете, как выглядит интерфейс SolidFire. Но об интеграции мы ещё поговорим.
Мы в «Онланте» провели нагрузочное тестирование, дабы удостовериться в обещанных 200k IOPS. Не то, чтобы мы не верили вендору, но привыкли всё пробовать самостоятельно. Мы не ставили перед собой целью выжать из системы больше, чем было заявлено. Также мы смогли убедиться на собственном опыте, что система даёт хороший результат именно при большом количестве потоков. Для этого мы организовали на SolidFire 10 томов по 1ТБ, на котором разместили по одной тестовой виртуальной машине. Уже на этапе подготовки тестовой среды мы были приятно удивлены работой дедупликации. Несмотря на то, что схема его работы довольно стандартна, качество работы в рамках кластера оказалось крайне эффективным. Диски перед тестами заполнялись случайными данными.
Чтобы это было быстрей, генерировали блок в 10 мб, потом им заполняли. Причём на каждой виртуальной машине этот блок генерировался отдельно, т.е. во всех машинах паттерн разный. Из 10ТБ заполненных данными — реально занятого пространства на массиве было 4ТБ. Эффективность дедупликации — 1:2.5, на FAS при таком подходе эффективность инлайн дедупликации стремилась к 0. Мы смогли получить 190k IOPS при отклике ~1 мс на нашем тестовом стенде.


Хочется отметить, что архитектурные особенности решения не позволяют получить высокий уровень производительности на небольшом количестве потоков. Один небольшой лун или всего одна тестовая виртуальная машина не смогут показать высоких результатов. Получить данное количество IOPS мы смогли при использовании всей ёмкости системы и при постепенном увеличении количества виртуальных машин, создающих нагрузку при помощи fio. Увеличивали мы их количество до того момента, как задержки не стали превышать 1,5 мс, после чего остановились и сняли показатели производительности.
На производительности сказывается и заполненность дисковой подсистемы. Как я уже говорил ранее, перед запуском тестов мы заполняли диски рандомными данными. Если же запустить тест без предварительного заполнения дисков, производительность будет намного выше при том же уровне задержек.

Мы также провели и наш любимый тест на отказоустойчивость путём выключения одной из нод. Чтобы получить наилучший эффект, для отключения была выбрана Master-нода. Ввиду того, что каждый сервер-клиент устанавливает собственную сессию с нодой кластера, а не через какую-то единую точку, то при отключении одной из нод деградируют не все виртуальные машины, а только те, которые работали с данной нодой. Соответственно со стороны СХД мы видим лишь частичное падение производительности.

Конечно, со стороны хостов виртуализации на некоторых дата-сторах падение производительности было до 0. Но уже в течение 30 секунд работоспособность была восстановлена без потери в производительности (стоит учитывать, что нагрузка в момент падения была на уровне 120k iops, которую потенциально способны выдать три ноды из четырех, соответственно потери в производительности мы и не должны были увидеть).
 Со стороны SolidFire при этом началось перестроение массива. Таймер немного врёт, и процесс занял около 55 минут, что укладывается в обещанный вендором час. При этом нагрузку с СХД никто не убирал, и она оставалась на том же уровне в 120k IOPS.
Со стороны SolidFire при этом началось перестроение массива. Таймер немного врёт, и процесс занял около 55 минут, что укладывается в обещанный вендором час. При этом нагрузку с СХД никто не убирал, и она оставалась на том же уровне в 120k IOPS.
Отказоустойчивость обеспечивается не только на уровне диска, но и на уровне ноды. Кластер поддерживает одномоментный выход из строя одной ноды, после чего запускается процесс ребилда кластера. Учитывая использование SSD и что в ребилде участвуют все ноды, восстановление кластера происходит в течение часа (ребил при отказе диска занимает около 10 минут). При этом стоит учитывать, что при выходе из строя ноды вы теряете как в производительности, так и в объёме полезного пространства. Соответственно вам всегда нужно иметь в запасе свободное пространство в размере одной ноды. Минимальный размер кластера — четыре ноды. Данная конфигурация позволит вам избежать неприятностей при выходе из строя одной из ноды до того момента, как вы ждёте приезда замены.
Как и на большинстве СХД, мониторинг производительности здесь отображается только в реальном времени. Для того, чтобы иметь доступ к историческим данным, вам необходимо развернуть так называемую Management Node, которая занимается тем, что берёт данные по API с SolidFire и заливает их в Active IQ. Если вы уже работали с системами NetApp, то наверняка уже могли сталкиваться с этим порталом. Вы имеете возможность работать с данными о производительности, эффективности, в том числе и с прогнозами роста. При чём вы можете получить доступ к этим данным даже со своего мобильного устройства, находясь где угодно в мире.



Раз уж я упомянул работу инлайн дедупликации, скажу и про эффективность хранения в целом. Как и в случае с AFF серией, компания NetApp даёт гарантированный коэффициент эффективности хранения в зависимости от типа хранимых данных.

Как можно видеть, типы данных и гарантированный коэффициенты у них немного отличаются. К примеру, у SolidFire есть именно наш случай — Virtual Infrastructure с коэффициентом 4:1. И это без учёта использования снепшотов.
В основе архитектуры решения стоит Quality of Service (QoS), который собственно и позволяет добиться гарантированной производительности для каждого из томов.

QoS — одна из критически важных функций для сервис-провайдеров и иных предприятий, которым необходимо обеспечить гарантированный уровень производительность хранилища. Кто-то скажет, что QoS не является чем-то новым и реализован у многих других вендоров. Другой вопрос — как это работает. Если в традиционных хранилищах это скорее приоритизация и ограничение скорости, то SolidFire в свою очередь использует комплексный подход для достижения гарантированной производительности.
Помимо возможности задания максимальной и минимальной производительности, есть возможность предоставить тому производительность за рамками максимального ограничения (Burst). Каждый том имеет некую условную систему кредитов. Когда его производительность находится ниже максимальной отметки, ему начисляются эти кредиты, благодаря которым, на некоторое количество времени он может преодолеть максимальную отметку производительности. Такой подход позволяет размещать в хранилище большое количество приложений, требующих высокой производительности, и при этом уберечь их от негативного влияния друг на друга. Самое интересное, что QoS поддерживают не только на уровне томов массива, но и на уровне VVol’ов VMware, что позволяет гранулярно выделять ресурсы под каждую виртуальную машину. Полная поддержка VAAI и VASA API обеспечивает тесную интеграцию массива с виртуализатором.
Говоря об интеграции, решением от VMware всё далеко не заканчивается.

SolidFire, пожалуй, можно назвать наиболее автоматизируемой СХД, которая способна интегрироваться с любыми современными системами, системами виртуализации/контейнеризации, поддерживает системы управления конфигурациями, SDK есть для различных языков.
Я, как всегда, смотрю первым делом SDK для Python, при помощи которого я автоматизирую собственные рабочие процессы. И так нам нужно создать 15 томов объёмом 1Тб, а на выходе получить их iqn, который мы передадим администраторам VMware для добавления датасторов. У нас уже есть созданные предварительно аксес группы, в которых прописаны наши хосты VMware и заранее созданная политика QoS.
Или вот более подробное видео «Python SDK Demo» от самой SolidFire:
Такой подход к автоматизации делает SolidFire удобным не только для облачных провайдеров и аналогичных задач, но в соответствии с концепцией непрерывной интеграции и доставки (CI/CD) позволяет оптимизировать процесс разработки.
 Как я упоминал — WebUI работает через API, и вы можете посмотреть все запросы и ответы через API Log.
Как я упоминал — WebUI работает через API, и вы можете посмотреть все запросы и ответы через API Log.
Если вам интересно узнать больше о SolidFire, о его сравнении с конкурентами, о работе с системой и т.д., из полезного хочу порекомендовать их YouTube канал, на котором довольно большое количество полезного видео. К примеру, цикл «Comparing Modern All-Flash Architectures».
Из приятных возможностей системы можно назвать встроенный механизм резервного копирования снепшотов во внешнее S3 совместимое хранилище. Это позволяет использовать снепшоты в качестве резервных копий и хранить их на внешних хранилищах как на вашей площадке, так и на внешних ресурсах, например, в Amazon. Конечно, такой подход сложно назвать гибким, с точки зрения восстановления данных, но для некоторых случаев такое решение может быть полезно и вполне применимо. Есть ещё один интересный момент — вы можете заливать данные в S3 хранилище в двух вариантах:


В целом, мы остались более чем довольны нашим общением с SolidFire. Мы получили обещанную производительность, работа инлайн-дедупликации выше всяческих похвал, возможности интеграции и автоматизации также оставили крайне положительное впечатление. Влияние выхода из строя ноды, точнее его минимальное влияние на производительность системы в целом, распределение нагрузки и отсутствие единой точки отказа, которая бы могла сильно влиять на производительность делают эту систему крайне привлекательной. Несмотря на то, что кластер может работать только по iSCSI, наличие FC-ноды транспорта, делает эту систему более универсальной.
Отдельную благодарность в проведении тестирования хочу выразить Евгению Красикову из NetApp и Артуру Аликулову из «Мерлиона». Кстати, Артур, ведёт прекрасный Telegram-канал для всех, кто хочет быть в курсе новостей storage- направления и NetApp в частности. В нём можно найти огромное количество полезных материалов, а кому мало просто почитать, а хочется ещё и пообщаться, есть ещё и чат storagediscussions.
Если у вас остались вопросы или вдруг появились новые, приглашаю вас посетить NetApp Directions 2018, которая пройдет 17 июля 2018 г. в Hyatt Regency Petrovsky Park, где мы с Артуром будем говорить о SolidFire на одной из сессий. Регистрация на мероприятие и все подробности.
В конце 2015 года компания NetApp объявила о покупке стартапа SolidFire, который был основан в 2010 году. Интерес к этим системам вызван их иным подходом к управлению хранилищами данных и предсказуемой производительностью.
Решения SolidFire дополнили линейку продуктов NetApp, которые включали в себя All Flash FAS (AFF), EF и E серии. Также это позволило спустя полтора года выпустить на рынок и новый продукт — NetApp HCI (Hyper Converged Infrastructure), который в качестве подсистемы хранения использует SolidFire.
«Мы разрабатываем новую систему хранения, предназначенную для очень больших центров обработки данных облачных вычислений. В основном идея состоит в том, что многие компании переносят вычисления из своих офисов или своих собственных центров обработки данных в эти крупные вычислительные облачные центры обработки данных, где у них десятки тысяч клиентов со всей их информацией, объединенной в одном месте. Поэтому мы создаем новую систему хранения, предназначенную для обслуживания этих крупных вычислительных центров».В последнее время появляется всё больше решений, которые уходят от традиционного подхода унифицированных хранилищ, способных решать любые задачи, к специализированным хранилищам, призванным решать задачи определённого направления бизнеса.
Дейв Райт, CEO of SolidFire, 2012
Не так давно я уже рассказывал о системе Infinidat InfiniBox F2230, которая прекрасно подходит для задач сервис- провайдеров. Сегодняшнего участника нашего обзора SolidFire также можно отнести к этому классу устройств. Основатель SolidFire Дейв Райт со своей командой — выходцы из RackSpace, где они занимались разработкой эффективной системы хранения, которая обеспечивала бы линейную производительность в среде со множеством пользователей, при этом была простой, легко масштабируемой и обладающей гибкими возможностями автоматизации. В попытке решить эту задачу и родился SolidFire.
На сегодняшний день линейка SolidFire состоит из четырех моделей с разным соотношением IOPS/TB.
Для хранения данных используются 10 (MLC) SSD, а в качестве NVRAM — Radian RMS-200. Правда, уже есть планы по переходу к модулям NVDIMM.
Здесь интерес представляет то, как SolidFire получает и хранит данные. Все мы знаем про ограниченный ресурс SSD накопителей, поэтому логично, что для их наибольшей сохранности компрессия и дедупликация должны происходить на лету, до записи на SSD. Когда SolidFire получает данные от хоста, он разбивает их на блоки 4КБ, после чего этот блок сжимается и сохраняет в NVRAM. Затем происходит синхронная репликация этого блока в NVRAM на «соседнюю» ноду кластера. После этого SolidFire получает хэш данного сжатого блока и ищет этот хеш- значение в своем индексе сохраненных данных в рамках всего кластера. Если блок с таким хэшем уже существует, SolidFire обновляет только свои метаданные со ссылкой на данный блок, если же блок содержит уникальные данные, он записывается на SSD, и также для него записываются метаданные. Этот механизм хранения данных и метаданных очень похож на механизм работы объектного хранилища.
Уже появились слухи, что в скором времени произойдёт обновление этой линейки. Стоит отметить одну очень важную вещь — кластер SolidFire способен работать с нодами как с разной «плотностью IOPs/TB», так и объединять в рамках одного кластера ноды разных поколений. Во-первых, это делает использование данной системы более предсказуемой в плане поддержки оборудования, а также облегчает процесс перехода со старых нод на новые, когда вы просто добавляете новые и удаляете старые из кластера в режиме реального времени (дожидаясь только перестроения кластера) без простоев, т.к. имеется поддержка как Scale Out, так и Scale Back.
SolidFire может поставляться в виде трех решений:
- SolidFire в качестве самостоятельного продукта, на базе серверов Dell/EMC,
- как часть FlexPod SF на серверах Cisco,
- как часть NetApp HCI на его платформе.
Как вы могли заметить из таблицы характеристики, ноды поддерживают только подключение по iSCSI, а для соединения по FC есть отдельный тип нод — Fabric Interconnect, который в свою очередь содержит четыре порта для данных по FC и четыре порта iSCSI для подключения к нодам, а также 64GB собственной системной памяти/кэша на чтение.
В таблице характеристик указана и производительность каждой из нод. Это один из тех случаев, когда вы знаете производительность свой системы хранения данных ещё на этапе покупки. Данная производительность является гарантированной (при профиле нагрузки 4Kb, 80/20) на каждую ноду.
Соответственно, покупая кластер из X нод или расширяя существующее решение, вы понимаете, какой объём и какую производительность вы получите в конечном итоге. Конечно, вы можете выжать из каждой ноды и большую производительность при определённых условиях, но это не то, для чего данное решение разрабатывалось. Если вы хотите получить миллионы IOPS в 2U на единственном томе, вам лучше обратить своё внимание на другие продукты, к примеру на AFF. Наибольшую производительность на SolidFire можно получить при большом количестве томов и сессий.
Управление хранилищем довольно просто. Фактически у нас есть два пула ресурсов: объём и IOPS’ы. Выделяя один из типов ресурсов и зная их конечное количество, мы чётко понимаем другие возможности нашей системы. Это опять-таки делает расширение системы крайне простым занятием. Нужна дополнительная производительность? Рассматриваем SF4805 или SF19210 с «менее плотным» соотношением IOPS/TB. Нужен объём? Смотрим в сторону SF9605 и SF38410, которые предоставляют меньше IOPS на Gb.
С точки зрения администратора СХД, система смотрится довольно скучно. Такие вещи, как дедупликация и компрессия, работают по умолчанию.
Репликация и снепшоты также имеются, причём репликация может быть организована для всей линейки продуктов NetApp (кроме E-серии). Именно эта простота, на мой взгляд, и раскрывается за цитатой Дэйва Хитса из заголовка статьи. Учитывая, что данная система предполагает интеграцию с различными системами динамического выделения ресурсов, без участия администратора и без дополнительных трудозатрат, в скором времени вы вообще забудете, как выглядит интерфейс SolidFire. Но об интеграции мы ещё поговорим.
Мы в «Онланте» провели нагрузочное тестирование, дабы удостовериться в обещанных 200k IOPS. Не то, чтобы мы не верили вендору, но привыкли всё пробовать самостоятельно. Мы не ставили перед собой целью выжать из системы больше, чем было заявлено. Также мы смогли убедиться на собственном опыте, что система даёт хороший результат именно при большом количестве потоков. Для этого мы организовали на SolidFire 10 томов по 1ТБ, на котором разместили по одной тестовой виртуальной машине. Уже на этапе подготовки тестовой среды мы были приятно удивлены работой дедупликации. Несмотря на то, что схема его работы довольно стандартна, качество работы в рамках кластера оказалось крайне эффективным. Диски перед тестами заполнялись случайными данными.
Чтобы это было быстрей, генерировали блок в 10 мб, потом им заполняли. Причём на каждой виртуальной машине этот блок генерировался отдельно, т.е. во всех машинах паттерн разный. Из 10ТБ заполненных данными — реально занятого пространства на массиве было 4ТБ. Эффективность дедупликации — 1:2.5, на FAS при таком подходе эффективность инлайн дедупликации стремилась к 0. Мы смогли получить 190k IOPS при отклике ~1 мс на нашем тестовом стенде.
Хочется отметить, что архитектурные особенности решения не позволяют получить высокий уровень производительности на небольшом количестве потоков. Один небольшой лун или всего одна тестовая виртуальная машина не смогут показать высоких результатов. Получить данное количество IOPS мы смогли при использовании всей ёмкости системы и при постепенном увеличении количества виртуальных машин, создающих нагрузку при помощи fio. Увеличивали мы их количество до того момента, как задержки не стали превышать 1,5 мс, после чего остановились и сняли показатели производительности.
На производительности сказывается и заполненность дисковой подсистемы. Как я уже говорил ранее, перед запуском тестов мы заполняли диски рандомными данными. Если же запустить тест без предварительного заполнения дисков, производительность будет намного выше при том же уровне задержек.
Мы также провели и наш любимый тест на отказоустойчивость путём выключения одной из нод. Чтобы получить наилучший эффект, для отключения была выбрана Master-нода. Ввиду того, что каждый сервер-клиент устанавливает собственную сессию с нодой кластера, а не через какую-то единую точку, то при отключении одной из нод деградируют не все виртуальные машины, а только те, которые работали с данной нодой. Соответственно со стороны СХД мы видим лишь частичное падение производительности.
Конечно, со стороны хостов виртуализации на некоторых дата-сторах падение производительности было до 0. Но уже в течение 30 секунд работоспособность была восстановлена без потери в производительности (стоит учитывать, что нагрузка в момент падения была на уровне 120k iops, которую потенциально способны выдать три ноды из четырех, соответственно потери в производительности мы и не должны были увидеть).
Отказоустойчивость обеспечивается не только на уровне диска, но и на уровне ноды. Кластер поддерживает одномоментный выход из строя одной ноды, после чего запускается процесс ребилда кластера. Учитывая использование SSD и что в ребилде участвуют все ноды, восстановление кластера происходит в течение часа (ребил при отказе диска занимает около 10 минут). При этом стоит учитывать, что при выходе из строя ноды вы теряете как в производительности, так и в объёме полезного пространства. Соответственно вам всегда нужно иметь в запасе свободное пространство в размере одной ноды. Минимальный размер кластера — четыре ноды. Данная конфигурация позволит вам избежать неприятностей при выходе из строя одной из ноды до того момента, как вы ждёте приезда замены.
Как и на большинстве СХД, мониторинг производительности здесь отображается только в реальном времени. Для того, чтобы иметь доступ к историческим данным, вам необходимо развернуть так называемую Management Node, которая занимается тем, что берёт данные по API с SolidFire и заливает их в Active IQ. Если вы уже работали с системами NetApp, то наверняка уже могли сталкиваться с этим порталом. Вы имеете возможность работать с данными о производительности, эффективности, в том числе и с прогнозами роста. При чём вы можете получить доступ к этим данным даже со своего мобильного устройства, находясь где угодно в мире.
Раз уж я упомянул работу инлайн дедупликации, скажу и про эффективность хранения в целом. Как и в случае с AFF серией, компания NetApp даёт гарантированный коэффициент эффективности хранения в зависимости от типа хранимых данных.
Как можно видеть, типы данных и гарантированный коэффициенты у них немного отличаются. К примеру, у SolidFire есть именно наш случай — Virtual Infrastructure с коэффициентом 4:1. И это без учёта использования снепшотов.
В основе архитектуры решения стоит Quality of Service (QoS), который собственно и позволяет добиться гарантированной производительности для каждого из томов.
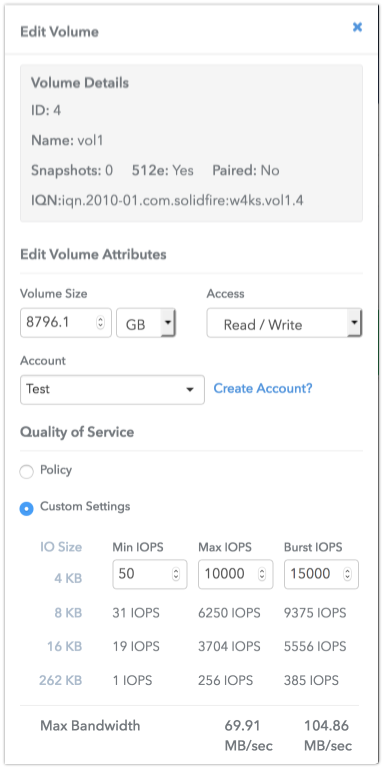
QoS — одна из критически важных функций для сервис-провайдеров и иных предприятий, которым необходимо обеспечить гарантированный уровень производительность хранилища. Кто-то скажет, что QoS не является чем-то новым и реализован у многих других вендоров. Другой вопрос — как это работает. Если в традиционных хранилищах это скорее приоритизация и ограничение скорости, то SolidFire в свою очередь использует комплексный подход для достижения гарантированной производительности.
- Использование All-SSD позволяет добиться низких показателей задержки для I/O.
- Scale-out легко прогнозирует показатели производительности.
- Отсутствие классического RAID — предсказуемая производительность при
- сбоях оборудования
- Сбалансированное распределение нагрузки исключает появление узких мест в системе.
- QoS помогает избегать «шумных соседей».
Помимо возможности задания максимальной и минимальной производительности, есть возможность предоставить тому производительность за рамками максимального ограничения (Burst). Каждый том имеет некую условную систему кредитов. Когда его производительность находится ниже максимальной отметки, ему начисляются эти кредиты, благодаря которым, на некоторое количество времени он может преодолеть максимальную отметку производительности. Такой подход позволяет размещать в хранилище большое количество приложений, требующих высокой производительности, и при этом уберечь их от негативного влияния друг на друга. Самое интересное, что QoS поддерживают не только на уровне томов массива, но и на уровне VVol’ов VMware, что позволяет гранулярно выделять ресурсы под каждую виртуальную машину. Полная поддержка VAAI и VASA API обеспечивает тесную интеграцию массива с виртуализатором.
Говоря об интеграции, решением от VMware всё далеко не заканчивается.
SolidFire, пожалуй, можно назвать наиболее автоматизируемой СХД, которая способна интегрироваться с любыми современными системами, системами виртуализации/контейнеризации, поддерживает системы управления конфигурациями, SDK есть для различных языков.
Я, как всегда, смотрю первым делом SDK для Python, при помощи которого я автоматизирую собственные рабочие процессы. И так нам нужно создать 15 томов объёмом 1Тб, а на выходе получить их iqn, который мы передадим администраторам VMware для добавления датасторов. У нас уже есть созданные предварительно аксес группы, в которых прописаны наши хосты VMware и заранее созданная политика QoS.
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from solidfire.factory import ElementFactory
sfe = ElementFactory.create('ip', 'log', 'pass')
for i in range(1,51):
create_volume_result = sfe.create_volume(name='vol'+str(i), account_id=2, total_size=1099511627776, enable512e=True, qos_policy_id=1)
id = create_volume_result.volume_id
sfe.add_volumes_to_volume_access_group(volume_access_group_id=2, volumes=[id])
volumes = sfe.list_volumes(accounts=[2], limit=100).volumes
for volume in volumes:
print volume.iqn
Или вот более подробное видео «Python SDK Demo» от самой SolidFire:
Такой подход к автоматизации делает SolidFire удобным не только для облачных провайдеров и аналогичных задач, но в соответствии с концепцией непрерывной интеграции и доставки (CI/CD) позволяет оптимизировать процесс разработки.
Если вам интересно узнать больше о SolidFire, о его сравнении с конкурентами, о работе с системой и т.д., из полезного хочу порекомендовать их YouTube канал, на котором довольно большое количество полезного видео. К примеру, цикл «Comparing Modern All-Flash Architectures».
Из приятных возможностей системы можно назвать встроенный механизм резервного копирования снепшотов во внешнее S3 совместимое хранилище. Это позволяет использовать снепшоты в качестве резервных копий и хранить их на внешних хранилищах как на вашей площадке, так и на внешних ресурсах, например, в Amazon. Конечно, такой подход сложно назвать гибким, с точки зрения восстановления данных, но для некоторых случаев такое решение может быть полезно и вполне применимо. Есть ещё один интересный момент — вы можете заливать данные в S3 хранилище в двух вариантах:
- Native — в данном случае будут заливаться уже дедуплицированные данные, но при этом восстановить этот том можно будет только на ту же систему, с которой он залит.
- Uncompressed — здесь уже заливается полный набор блоков, что позволяет восстановить данный лун на любом другом кластере SolidFire.
В целом, мы остались более чем довольны нашим общением с SolidFire. Мы получили обещанную производительность, работа инлайн-дедупликации выше всяческих похвал, возможности интеграции и автоматизации также оставили крайне положительное впечатление. Влияние выхода из строя ноды, точнее его минимальное влияние на производительность системы в целом, распределение нагрузки и отсутствие единой точки отказа, которая бы могла сильно влиять на производительность делают эту систему крайне привлекательной. Несмотря на то, что кластер может работать только по iSCSI, наличие FC-ноды транспорта, делает эту систему более универсальной.
Отдельную благодарность в проведении тестирования хочу выразить Евгению Красикову из NetApp и Артуру Аликулову из «Мерлиона». Кстати, Артур, ведёт прекрасный Telegram-канал для всех, кто хочет быть в курсе новостей storage- направления и NetApp в частности. В нём можно найти огромное количество полезных материалов, а кому мало просто почитать, а хочется ещё и пообщаться, есть ещё и чат storagediscussions.
Если у вас остались вопросы или вдруг появились новые, приглашаю вас посетить NetApp Directions 2018, которая пройдет 17 июля 2018 г. в Hyatt Regency Petrovsky Park, где мы с Артуром будем говорить о SolidFire на одной из сессий. Регистрация на мероприятие и все подробности.
А ещё в нашей компании есть вакансия.
