
Привет, Хабр! Легендарная команда прогнозирования промо сети магазинов «Магнит» снова в эфире. Ранее мы успели рассказать о целях и задачах, которые мы решаем: «Магнитная аномалия: как предсказать продажи промо в ритейле», а также поделиться основными трудностями, с которыми приходится сталкиваться в нашем опасном бизнесе: «Божественная комедия», или Девять кругов прогнозирования промо в «Магните». Сегодня планируем подробнее рассказать о типах и особенностях используемых нами моделей прогнозирования продаж.
Дисклеймер
Приведённый в статье перечень подходов не является исчерпывающим и оптимальным для решения любых задач прогнозирования, а лишь отражает наш практический опыт работы в рамках отдельно взятой отрасли бизнеса достаточно крупных масштабов.

На нижнем уровне результат нашей работы — ответ на вопрос: «Какое количество конкретного товара мы продадим в отдельно взятом магазине в течение периода при заданных параметрах?» В поисках ответа на этот вопрос мы успели поработать с различными моделями, которые можно условно разделить по типу:
cтатистические,
линейная регрессия,
деревья решений,
нейронные сети.
Для людей, знакомых с задачей прогнозирования временных рядов, этот список не является чем-то новым. Но, как обычно, дьявол кроется в деталях. Далее познакомимся поближе с каждым из типов и пройдём эволюционный путь становления ансамбля алгоритмов в нашей компании.
Стихия земли: статистические модели
Ключевые характеристики: надёжность, простота, интерпретируемость

«Чтоб убрать с дороги камни,
Наклоняясь-поклонись,
Может камнем чья-то память,
Может камнем чья-то жизнь»
Под статистическими моделями подразумеваем набор моделей, использующих в основе скользящие средние с рядом преобразований разной степени сложности. От простых скользящих средних и экспоненциального сглаживания до ARIMA, SARIMA, ARIMAX и более сложных комбинированных вариантов.
Первые попытки использовать статистические модели в бизнесе уходят корнями в историю. Они предшествовали бурному развитию IT и росту вычислительных мощностей в силу относительной простоты и прозрачности применения, соразмерно уровню технической оснащённости тех времён.
Если внимательно посмотреть на процессы любого бизнес-подразделения, где возникает хотя бы минимальная потребность что-либо прогнозировать, высока вероятность встретить интуитивные попытки использования скользящих средних: «закажем, как в прошлые разы», «сделай по аналогии».
Наша компания — не исключение. Более 20 лет назад был создан инструмент «Автозаказ» на базе скользящих средних.
«Автозаказ»
Автозаказ – инструмент прогнозирования, при помощи которого осуществляется пополнение товаром торговых объектов компании.
В те годы это был настоящий прорыв: администрации магазинов больше не нужно было вести ручной учёт и размещать заказы товаров в конце рабочего дня. «Автозаказ» всё делал автоматически. Это сэкономило и высвободило тысячи человеко-часов за счёт эффекта масштаба, а также минимизировало человеческий фактор ручной ошибки прогноза.
Безусловно, требования к качеству метрик и сложность решаемых задач за прошедшие годы возросли на порядок. Однако статистические модели всё ещё в стеке и могут быть актуальны для решения отдельных задач: они хорошо себя зарекомендовали и прошли проверку временем.
Для прогнозирования промо использование статистических моделей в базовом виде не подходит из-за наличия набора сильно влияющих на целевую переменную факторов. Для решения этой проблемы мы используем мультипликативную модель прогнозирования (ММП) вида:
y = x * k1 * k2 * … * kn,
Где x – очищенная от влияния факторов базовая продажа, над которой строится статистическая модель.
k1…kn – учитываемые факторы (мультипликаторы).
Таким образом, декомпозиция ряда на составляющие позволяет приблизить ряд наблюдений X к стационарному виду, после чего над ними строится статистическая модель.
Один из ключевых моментов – правильная оценка факторов и учёт их влияния. Рассмотрим для примера самые важные из них:
Коэффициент эластичности спроса – собственная разработка, аппроксимация эластичности спроса на товар в зависимости от изменения цены. Рассчитывается отдельным алгоритмом.
Коэффициенты сезонности – сезонная составляющая изменчивости спроса. Для расчёта используем адаптированный под наши цели алгоритм на базе библиотеки Prophet.
Также важный пункт в реализации подобных алгоритмов – правильный выбор детализации расчёта, исходя из целей прогнозирования и горизонта сбора статистики для расчёта базовой компоненты. В нашей версии ММП мы используем короткий тренд – около трёх месяцев: динамика продаж отдельных товаров в розничной торговле меняется достаточно быстро, а представленная модель не способна учитывать весь спектр факторов, влияющих на изменение целевой переменной.
Помимо прочего, ценная особенность алгоритма – независимая иерархическая структура расчёта каждой из компонент. Это позволяет использовать модель для прогнозирования товаров и магазинов, не имеющих собственных наблюдений.
Попробуем разобраться, почему это так важно. В таблице приведён пример наиболее часто встречающихся комбинаций наличия статистики по компонентам в упрощённом виде для одного условного магазина.
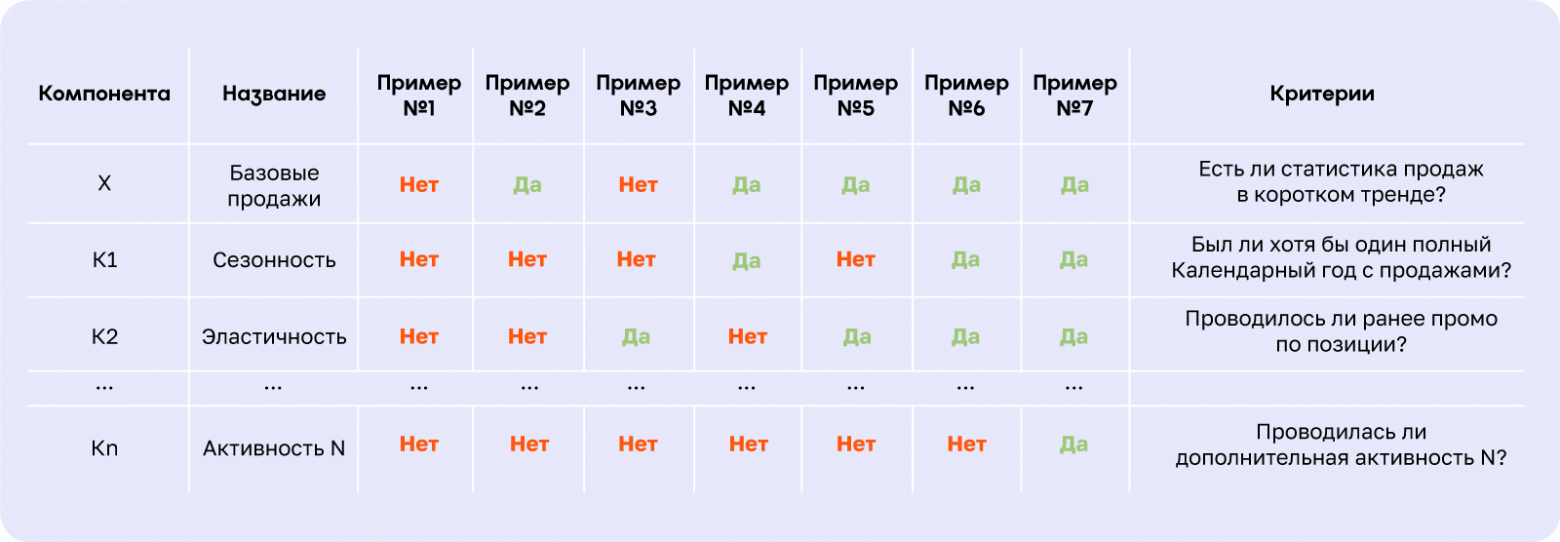
Если бы основная часть наблюдений соответствовала примеру 6–7, нам не пришлось бы разделять модель на отдельные модули расчёта компонент. В реальности значительная доля случаев скорее «окрашена в красный цвет». Поэтому ММП в рамках расчёта последовательно проверяет, есть ли статистика каждой из компонент: начинает с нижнего уровня детализации, двигается вверх при отсутствии таковой и останавливается на том уровне иерархии расчёта, где выполняется критерий по достаточному количеству наблюдений.
Целью создания модели было решение двух задач:
Быстро создать относительно простой и легко интерпретируемый для бизнеса алгоритм.
Прогнозировать все поступившие на расчёт записи, включая те, у которых полностью отсутствует история продаж.
Помимо разработки и совершенствования основных модулей (мультипликаторов и компонент), мы реализовали ряд дополнительных веток расчёта для учёта нестандартных явлений разного рода, прогнозирование которых было критичным с точки зрения бизнеса. Это необходимо для случаев, где исходная версия модели не способна выдавать прогноз в силу архитектурных ограничений либо при появлении сильного внешнего фактора, вызывающего существенную просадку ключевых метрик.
Сильные стороны мультипликативной модели
Простота применения, можно быстро адаптировать подход для разных задач.
Проще интерпретировать результаты и искать причины ошибок прогноза благодаря декомпозиции ряда на отдельные, понятные бизнесу мультипликаторы.
Применение модели на коротком тренде позволяет относительно быстро реагировать на внешние факторы, которые могут оказывать существенное влияние на спрос. Пример – ковид или резкое изменение структуры ассортимента из-за ухода старых и появления новых поставщиков.
За счёт иерархической структуры расчёта компонент модель способна прогнозировать почти 100% от всех потенциальных входящих данных, вне зависимости от наличия статистики: например, для новых товаров и не встречавшихся ранее скидок и цен.
Слабые стороны мультипликативной модели
Обратная сторона простоты – отсутствие «гибкости». В отличие от более сложных моделей нельзя просто разметить события в истории и пробросить признак в будущее.
Любое нестандартное явление в статистике продаж или реализация новой механики промо помимо явной разметки требует создания отдельной надстройки (ветки расчёта) и разработку логики для каждой уникальной ситуации (заданную последовательность действий: if…else…). Это приводит либо к бесконечному усложнению логики, утяжелению и разрастанию кода, либо к отказу от использования подхода в части случаев.
Сложности при прогнозировании товарных категорий, присутствующих в ассортименте ограниченный период времени в течение года. Например, новогодних украшений, кремов для загара, сезонных овощей и фруктов. Подобные товары могут не иметь доверительной статистики продаж в короткой истории, а периоды их появления в ассортименте и выхода на «пиковые значения» меняются от года к году.
Разработка новых признаков возможна только в виде мультипликаторов, что существенно ограничивает потенциал развития модели.
Статистические модели – это база. безусловно являются фундаментом прогнозирования в силу высокой скорости расчёта, простоты реализации и интерпретации результатов, а также могут показывать неплохой результат для задач не высокой сложности.
Следуя принципу «Бритвы Оккама», при наличии ограниченного ресурса и времени на разработку, статистические модели могут оказаться отличным стартовым (а зачастую – достаточным) решением (вспоминаем про «самокаты» и «космические корабли»). Но не стоит забывать, что качество подобных моделей напрямую зависит от глубины понимания специфики бизнеса, качества и структуры имеющихся в наличии данных и способностей команды видеть связь между сухими цифрами в источниках и реальными событиями.
Стихия огня: линейные модели
Ключевые характеристики: агрессивность, прямолинейность, комплексность, интерпретируемость

«Огонь обжечь способен неумелых,
иным он свет дарует и тепло»
Применять линейные модели для прогнозирования продаж в нашей компании стали более пяти лет назад. Реализация первой ML-модели (для задачи прогнозирования внутри компании) была отдана на откуп внешнему контрагенту. Она представляла собой «коробку», развёрнутую внутри нашего контура.
Решение было вынужденным: сказывалось накопленное на тот момент технологическое отставание от рынка и отсутствие собственной экспертизы в этом направлении.
Правда, впоследствии возникли сложности с поддержкой, адаптацией и развитием модели. Возникла острая необходимость сформировать собственную команду. Но обо всём по порядку.
Стандартная линейная модель имеет вид:
y = a0 + b1x1 + b2x2 + b3x3 + … + bnxn,
где x1…xn – признаки модели (фичи),
b1…bn – подобранный моделью вес признаков,
a0 – смещение.
В первоначальном виде приобретённое решение не отличалось оригинальностью:
Детализация обучения моделей: Товар – Формат магазинов – Географический признак торгового объекта.
Детализация
Под детализацией подразумеваем несколько понятий: гранулярность данных (час-день-неделя) и разрез (набор бизнес-сущностей), до которого они собираются.
~10 признаков в модели.
В одном недельном цикле строилось ~2 миллиона моделей.
Код был написан на нескольких языках программирования.
Масштабы и скорости изменений в ритейле в совокупности с отсутствием бизнес-экспертизы на стороне подрядчика и узкой предметной у заказчика заставили задуматься о целесообразности использования «коробки», и всё завертелось…
После формирования внутренней команды, в условиях необходимости быстро растить метрики, мы получили линейную модель в виде legacy-решения. Как в большинстве коробочных решений, проблема заключалась в закрытом исходном коде и архитектуре на уровне железа.
Оставался только вариант управления количеством фичей, но это лишь половина беды: из-за быстрого роста объёмов данных длительность обучения модели выросла с 24 часов до 140 и выше. Код был реализован на R и выполнялся в распределенном режиме по аналогии с Hadoop в виде весьма неоптимального подобия. Расчёты часто падали в процессе выполнения, механизм автоматического перезапуска отдельных этапов отсутствовал.
Тестирование даже небольших доработок (в ретро-тестах) занимало больше недели, поэтому первым делом мы решили перенести модель на всем привычный Python в виде Spark. К этому добавилась и миграция на чистый Hadoop, где в роли хранилища данных выступил HDFS, а в роли СУБД – Hive. Для запуска скриптов по расписанию и контроля их выполнения использовали Airflow.
Итог работы не заставил себя ждать: обучение моделей в распределенном режиме стало занимать ~8 часов и существенно выросла отказоустойчивость. Основной эффект дал переход с MapReduce на Spark.
Вторым шагом практически «с нуля» пересобрали решение: от исходной версии осталась схожая детализация и сам подход – линейная модель, а также одна концептуально полезная вещь – обучение не одной модели на всех данных, а обучение миллиона моделей на подгруппах, что отлично ложится на концепцию распределенных вычислений (считай много подобного очень быстро в параллели).
Перейдём к практическому опыту работы с линейной моделью.
Линейность (как бы странно это ни звучало)
Очевидно, оптимальным условием для хороших метрик линейной модели является линейная зависимость между признаками и таргетом. На практике в ритейле это условие практически никогда не соблюдается. Например, изменение спроса при переходе от скидки в 10% до 20% может быть не сопоставимо с переходом от 30% до 60%.
Безусловно, «на бумаге» существуют методы учёта нелинейных зависимостей (полиномиальное преобразование признаков и др.), но является ли это решением проблемы на практике? Путём проб и ошибок мы остановились на варианте включения в модель более гибких фичей и преобразовании таргета, позволяющих нивелировать негативное влияние подобных факторов.
Обработка таргета
Одна из особенностей применяемой нами линейной модели – отсутствие признаков, описывающих отдельные магазины. Вместо этого мы используем информацию о средних продажах каждого объекта, чтобы нормировать целевую переменную, и восстанавливаем результат прогноза модели на аналогичное значение.
Таким образом, ряд преобразований целевой переменной включает логарифмирование, нормирование и обратное восстановление прогноза. Звучит просто. И если с логарифмированием все понятно, то нормирование ставит ряд вопросов, от которых сильно зависит качество итоговой модели:
Что считать «средним» таргетом?
До какого уровня лучше считать этот показатель?
Какой объем статистики заслуживает доверия? Целесообразно ли нормировать на среднее значение, если товар имеет всего несколько недель продаж?
Что делать, если у товара были только нулевые продажи, а на ноль нормировать нельзя?
Нулевые продажи
Ещё одна особенность ритейла – распределение значений таргета, близкое к логнормальному. В отдельных категориях с низкой оборачиваемостью при отсутствии скидок доля нулевых наблюдений составляет существенную часть истории: в дневном агрегате до 80% строк имеют значение целевой переменной = 0.
Если оставить их «как есть», они могут оказывать негативное влияние на модель, в первую очередь на Bias.
Bias
Bias (англ. – смещение) демонстрирует, на сколько и в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз профицитным или дефицитным.
При этом полностью отказываться от подобных наблюдений – не лучшая идея: можно получить диаметрально противоположный (с точки зрения смещения ошибки) эффект.

Решить эту проблему можно, добавив веса наблюдений, которые позволяют сбалансировать важность нулевых значений для модели. Чтобы учесть фактор неоднородности доли подобных случаев в разных категориях, с помощью специальной функции рассчитывается коэффициент, учитывающий характер спроса. Основная идея – чем ниже частота потребления в категории, тем меньший вес получают нулевые наблюдения.
Скорость адаптации к изменениям
Для классической линейной регрессии наблюдения разных временных периодов равнозначны, если их подавать в модель «как есть». В реальности спрос может существенно меняться с течением времени: более «свежие» данные зачастую лучше отражают действительность. Для решения проблемы использовали несколько подходов:
добавлять фичу тренда,
давать больший вес «свежим» наблюдениям,
ограничивать историю обучения модели.
Каждый из подходов работает в определённых условиях. Вопрос в тонкой настройке. Насколько ограничивать историю – дилемма выбора между коротким периодом с максимально релевантными к текущим условиям данными и большим периодом наблюдений с разнообразием ситуаций, но при этом с большей долей «устаревших» данных.
Аналогичные проблемы возникают при изменении весов наблюдений в зависимости от их удалённости в прошлое. Например, в течение года целесообразно доверять ближайшим в истории к дате старта промо продажам, но в преддверии праздников наиболее точными (характеризующими будущий спрос) станут аналогичные периоды прошлых годов, которым мы успели существенно снизить вес.
Сезонность
Отдельной головной болью при работе с нашей моделью стала низкая чувствительность к сезонным колебаниям спроса.
Почему, казалось бы, одна из базовых составляющих прогнозирования становится испытанием? Мы неплохо умеем описывать сезонную компоненту на уровне типов услуг, товарных категорий и иных агрегатов, которые можем передать в модель. При этом в детализации модели, как и общей цели прогнозирования, объектом является товар-магазин.
Сезонность, посчитанная до категории, довольно стабильна и адекватно отражает циклические сезонные изменения, но на уровне отдельного товара-магазина всё «ломается». Происходит это по разным причинам: рваная или короткая история продаж, сосредоточенная в отдельном сезоне, наличие сильных случайных шумов, влияние скидок на сам товар (как признак, перетягивающий на себя вес) или на товары-субституты, каннибализирующие спрос вопреки ожидаемому сезонному поведению.
В работе над решением этой проблемы было сломано немало копий. Мы пробовали:
Подавать в модель временные признаки в разных вариантах реализации (включая кодирование через Sin/Cos).
Использовать сезонные фичи и коэффициенты.
Чистить таргет от влияния сезонности и восстанавливать обратно после получения прогноза и многое другое.
Несмотря на определённые успехи, мы всё ещё пребываем в состоянии поиска оптимального решения этой проблемы для линейной модели.
Регуляризация
В силу того, что мы имеем дело с тысячами моделей, проверять корреляцию между признаками и их важность «вручную» невозможно. В этом на помощь приходит регуляризация. Мы используем оба типа: L1 помогает избавиться от шумных для отдельной модели фичей, а L2 не позволяет весам принимать слишком большие значения или сильно отклоняться от ожидаемого интервала.
Рассмотрим кейс, когда это может помочь. Цена – важный признак при прогнозе спроса. Для большинства товаров она меняется во времени, и все работает хорошо. Но некоторые из них могут находиться в длительном промо с одинаковой, практически неизменной ценой, что делает этот признак бесполезным для модели.
Экстраполяция
Способность модели к экстраполяции в зависимости от ситуации может быть как преимуществом, так и недостатком. В рамках постобработки мы проверяем результаты расчёта на отсутствие отрицательных и аномально высоких значений, но об этом позже.
Сильные стороны линейной модели
Более гибкая в сравнении со статистическими моделями, способна учитывать большее количество признаков на длинной истории продаж.
Наиболее простая среди ML-моделей с точки зрения ресурсоёмкости и скоростей расчёта.
Результаты интерпретируются через веса признаков. Для объяснения причин отклонений прогноза достаточно достать из модели вес каждого признака и описать их физический смысл.
Комплексность: модель параллельно, а не последовательно балансирует влияние признаков на таргет. Это может быть важным преимуществом в решении определённых задач, например, если нужно оценить взаимное и разное по силе влияние друг на друга большого количества сущностей.
Способность к экстраполяции: линейная модель обладает способностью прогнозировать значения за пределами обучения, что может быть полезно для решения бизнес-задач. Например, часто требуется спрогнозировать спрос при уровнях скидок или цен, которых не было в истории.
Слабые стороны линейной модели
Падает качество прогноза, если есть сложные нелинейные зависимости между признаками и целевой переменной.
Возникают проблемы при необходимости учёта большого количества категориальных признаков.
Чувствительность к аномалиям и выбросам.
Для интерпретации на практике необходимо агрегировать влияния веса признаков огромного количества моделей в единую, понятную бизнесу сущность. Например, для прогноза одного товара на нескольких тысячах магазинов разных форматов может использоваться ~300-700 моделей. Заказчику же интересно знать, какие пять факторов больше всего влияют на прогноз. Тут и возникает сложность, как правильно «схлопнуть» коэффициенты такого количества моделей, чтобы оценить их общий вклад в ошибку прогноза.
Риски при экстраполяции: важно уметь контролировать результаты, полученные на данных, которые модель никогда не видела, так как они могут быть неадекватными.
Линейные модели в нашем стеке выполняют роль наиболее легкого в реализации ML-алгоритма прогнозирования. Они сохраняют баланс между простотой, интерпретируемостью и возможностью учёта наиболее важных признаков, влияющих на продажи. Помимо прочего, они неплохо справляются с объяснением линейных взаимосвязей, обладают способностью к экстраполяции и позволяют оперативно адаптировать модель к изменениям внешней среды.
Стихия Воздуха: градиентный бустинг
Ключевые характеристики: гибкость, стабильность, универсальность

«Ты не можешь менять направление ветра,
но всегда можешь поднять паруса,
чтобы достичь своей цели»
Градиентный бустинг над решающими деревьями (GBDT) – это метод машинного обучения, который отличается хорошей точностью «из коробки». Это один из самых популярных алгоритмов для работы с табличными данными.
Метод основан на идее о том, что обезьяны вместе – сила комбинации нескольких слабых алгоритмов, последовательно уточняющих прогноз друг друга с целью сокращения ошибки.

Внедрение собственной модели бустинга для целей прогнозирования продаж со старта стало одним из приоритетных направлений работы нашей команды в силу ряда причин:
Наметившийся тренд применения подобных моделей для прогнозирования спроса в ритейле (бенчмарк).
Усложнение задач прогнозирования продаж и появление новых механик промо: необходимость учёта большего количества признаков, включая категориальные.
Высокое качество метрик в схожих задачах на основании публикаций и статей в открытых источниках.
Появление современных библиотек с открытым исходным кодом (XGBoost, LGBM, Catboost и др.).
Бустинг удобен для работы с табличными и неоднородными данными.
В течение ~6 месяцев мы работали над запуском рабочего прототипа модели с точностью, достаточной для поставки решения на прод:
Блоки очистки, преобразования и подготовки данных были реализованы с учётом ошибок, возникавших в работе с другими алгоритмами.
Проблема малого количества статистики в нашем случае решается высоким уровнем детализации модели: Географический признак – Товарная группа – Тип магазина. Всего в модели больше 50 фичей. Отдельные товары и магазины закодированы набором признаков.
Используем длинную историю обучения: больше трех лет. В рамках многочисленных тестов пришли к выводу, что рост количества наблюдений, несмотря на их «устаревание», положительно влияет на метрики бустинга.
В нашей модели используется большое количество производных от целевой переменной в качестве признаков, что повышает стабильность алгоритма.
Дальнейшая доработка модели была сосредоточена на точечных корректировках признаков и подборе оптимальных гиперпараметров: оптимальная функция потерь, количество бинов, максимальная глубина, количество деревьев, шаг обучения, количество листьев, L1/L2 регуляризация, бэггинги и др.
Отдельно стоит упомянуть о возможности задавать ограничения на монотонность признакам. В некоторых случаях это помогает модели правильно определять однозначные зависимости при наличии шума в данных: актуальность растёт при высоком уровне детализации.
Другим полезным решением было квантование – округление значений некоторых признаков до целых чисел (например, цены до рублей). Это помогло в борьбе с переобучением и повысило стабильность модели: она не пыталась объяснить сотые и тысячные порядки значений.
Ещё одна особенность нашей реализации бустинга – применение различных функций потерь в зависимости от структуры данных: mse, mae, huber, poisson, tweedie. Это позволяет учитывать специфические особенности распределений: асимметрию, концентрацию большинства наблюдений в одной точке и другие, что положительно сказывается на метриках.
Сильные стороны бустинга
Модель поддерживает очень гибкую работу с фичами. Это позволяет минимизировать процесс обработки данных: пропуски, нормализацию, стандартизацию, кодирование категориальных переменных и так далее.
У модели хорошая обобщающая способность, в том числе при наличии нелинейных зависимостей между признаками и таргетом, характерная для GDBT-моделей.
Возможность учёта большого количества категориальных признаков позволяет прогнозировать нестандартные (в том числе не ценовые) активности.
Отсутствие экстраполяции у бустинга позволяет формировать «консервативный», или безопасный, прогноз. Результаты расчёта модели всегда лежат в пределах диапазона наблюдений, а длинная история обучения «страхует» от аномалий.
Слабые стороны бустинга
Самая тяжелая модель в нашем стеке: это создает некоторые проблемы с ее использованием. Если в случае линейных моделей нам достаточно перемножить коэффициенты с предварительной обработкой входящих на расчёт признаков, то в случае с бустингом необходимо считывать большое количество дампов моделей (больше 500 тысяч экземпляров) и присоединять их к приходящим на расчёт данным.
Большое количество моделей вызывает трудности при интерпретации результата и дебаге. Каждая группа отличается собственным поведением, и модель ищет разные подходы к прогнозированию группы, что затрудняет поиск унитарного подхода для поиска ошибок.
Для оценки общего влияния признаков на группы в разных детализациях мы разработали несколько инструментов, которые помогают определить степень важности конкретного признака в конкретной группе. Но это не решает вопрос интерпретации результата для бизнес-пользователя.
Ухудшение метрик модели при недостаточном объёме данных в группах, которые редко встают в промо, являются новинками, имеют высокую волатильность.
Чтобы максимизировать метрики для каждого экземпляра модели, необходимо тонко подбирать параметры. Это – большая вычислительная проблема.
Для нас бустинг – качественная и стабильная база. В силу особенностей и архитектуры модели она страхует прогноз от вылетов. Также она является лидером с точки зрения качества учёта нелинейных зависимостей и разреженных событий (зачастую категориальных признаков), имеющих значительное влияние на продажи.
Таким образом, модель одновременно достаточно гибкая и стабильная, но за это приходится дорого расплачиваться: ресурсоёмкость, тяжесть и требовательность к объёмам статистики бустинга превосходит упомянутые ранее подходы к прогнозированию.
Стихия Воды: Нейросети
Ключевые характеристики: аморфность, многомерность, изменчивость, хайповость

«Когда воду наливают в чашку, она становится чашкой.
Когда воду наливают в чайник, она становится чайником.
Когда воду наливают в бутылку, она становится бутылкой.
Вода может течь, а может крушить.
Будь водой, друг мой»
Имея в обойме прогнозной машины описанные выше модели, мы обратили взор в сторону нейронных сетей. Несмотря на расхожее мнение о том, что их использование для работы с табличными данными – не оптимальное решение, мы попробовали. О том, что из этого вышло, расскажем в отдельной статье: накопилось много материала.

Ансамбль

«Для достижения истинного знания и обретения
баланса необходимо освоить все пути»
Вершина эволюции в нашем стеке и фактическое промышленное решение, результат которого видит заказчик, – ансамбль алгоритмов. Идея довольно проста: использовать несколько независимых друг от друга моделей с разной архитектурой для прогнозирования одной сущности, что позволяет уменьшить неконтролируемую случайную ошибку.
Дзен Ансамбля
Много моделей лучше, чем мало.
Всегда начинай с простых моделей.
Разнообразие алгоритмов лучше, чем их сходство.
Качество моделей имеет значение.
Если моделей больше двух, отбрось явных аутсайдеров.
Ключевые требования для успешной реализации подобного подхода – независимость, разнородность моделей и сопоставимое друг с другом качество метрик. Чем сильнее модели отличаются – тем больший эффект даёт ансамблирование. В нашем случае каждая модель имеет отличную от других детализацию обучения:
ММП – «нижний уровень», товар-магазин, но мультипликаторы считаются независимо друг от друга в иерархическом порядке на агрегате более высокого уровня.
Линейная модель – товар-все магазины в географическом разрезе.
Бустинг – товарная группа-тип магазина.
Нейросеть – без ограничений; номенклатура закодирована через признаки.
Помимо этого необходимо по возможности использовать разные (неидентичные) признаки в моделях – это тоже хорошо сказывается на устойчивости ансамбля. Например, для описания сезонной компоненты спроса в линейной модели используются коэффициенты, характеризующие поведение категории товаров в прошлом в качестве признаков, а в модели градиентного бустинга это учитывается с помощью лаговых фичей в аналогичные периоды прошлых лет.
Варианты реализации ансамбля
Математические правила – при реализации этого метода мы не оцениваем качество каждой из моделей относительно истории, а используем ряд статистических показателей для фильтрации и ансамблирования итогового прогноза.
Например: отказ от использования аномального значения прогноза одной из моделей, если он существенно отличается от остальных; адаптивная логика взвешивания и др. Основное преимущество метода – простота реализации и отсутствие необходимости контроля.
Сильные и слабые стороны алгоритмов – подход является, скорее, эвристикой и схож со SWOT/SNW-анализом. Зная сильные и слабые стороны каждой из моделей, можно вручную задавать сценарии применения в разных случаях.
Например, если мы знаем, что бустинг плохо справляется с прогнозом новинок, а линейные модели недостаточно хорошо чувствуют сезонность, можем на уровне ансамбля «отключить» или существенно снизить вес прогноза модели. Подход оправдывает себя за счёт возможности быстро адаптироваться к изменениям, но требует ручного контроля (важность растёт при активном внедрении доработок в отдельные алгоритмы).
Бизнес-требования – подход повторяет предыдущий. Только во главу угла ставятся не объективные ограничения архитектуры моделей, а требования бизнеса к прогнозу в зависимости от ряда признаков: категории товаров, географии, типа акции или маркетинговой активности и так далее.
Преимущество очевидно: результаты наиболее соответствуют требованиям заказчика. Отсюда вытекает и недостаток: сложность и необходимость постоянного ручного контроля настроек ансамбля.
Надстроечная модель – использование отдельной, обученной на исторических данных модели для расчёта оптимальных весов и комбинаций прогнозов алгоритмов, применяемых в ансамбле.
С первого взгляда этот вариант реализации ансамбля кажется оптимальным: модель сама, без участия внешнего пользователя, определит параметры и выдаст наилучший результат.
Однако есть нюанс: во-первых, когда вносишь ощутимые доработки в каждый отдельно взятый алгоритм ансамбля, требуется пересчитывать исторические прогнозы за большой период времени и заново обучать надстроечную модель. Во-вторых, ритейл – живой бизнес, где ежегодно (или несколько раз в год) под давлением внешних факторов (или без таковых) меняются паттерны поведения покупателей, состав полки в различных категориях товара и так далее. Поэтому нельзя с уверенностью доверять историческим данным о точности отдельных алгоритмов.
Также этот подход сокращает устойчивость ансамбля из-за потенциального переобучения. Например, один из алгоритмов на протяжении последнего года выдавал наилучшую точность по отдельно взятому товару, вследствие чего по оценке надстроечной модели его вес в ансамбле составил 85%. Однако, после существенного изменения цены на товар, качество прогноза упало на порядок, но мы продолжили тащить за собой ошибку с большим лагом.
Сильные стороны ансамбля
Первая и основная цель использования ансамбля моделей – рост точности прогноза. В подавляющем большинстве случаев ансамбль двух, даже относительно «слабых» моделей, показывает лучшие метрики точности, чем одна «сильная».
Второе важное преимущество – высокая надёжность и отказоустойчивость подхода в сравнении с использованием одной модели:
Не существует идеальных моделей. У каждого из подходов есть ряд недостатков или архитектурных ограничений. Из-за них в отдельных случаях прогноз не может быть рассчитан, что в свою очередь недопустимо для бизнес-заказчика: «Что значит модель не способна считать прогноз при таких параметрах? Научите!» В этом случае на помощь приходит ансамбль: один или несколько алгоритмов всегда выдадут результат. Аналогичным образом «страховка» работает при случайных ошибках, сбоях, падениях моделей.
Для задач прогнозирования спроса в ритейле характерно наличие значений признаков, выходящих за пределы истории наблюдений: постоянные изменения цен, скидки и др. И тут мы возвращаемся к вопросу о способности к экстраполяции: одновременное использование разных моделей позволяет решать задачу с минимальным уровнем риска. Консервативный прогноз (ограниченный историей наблюдений) бустинга и относительно безопасная экстраполяция, собранная на агрегате за большой период времени в ММП, выступают «заземлением». Её более агрессивная версия в линейных моделях и нейросетях при необходимости дотягивают значения прогноза до ожидаемых.
Третье преимущество – возможность управлять результатом, влияя на ансамбль и его надстройки. Это позволяет независимо от текущих или временных требований к прогнозу работать над улучшением каждого отдельно взятого алгоритма, а «панель управления» вынести на уровень выше – на этап ансамблирования.
Позволяет обеспечить относительно плавный и «бесшовный» переход от старых моделей к новым, минимизируя риски ошибок, поскольку в основе остаётся несколько проверенных и надёжных решений.
Использование ансамбля позволяет формировать относительно свободную конкурентную среду параллельной разработки разных моделей прогнозирования. С появлением более эффективных решений, устаревшие безболезненно для заказчика отправляются «на склад» до востребования. Наличие разных подходов позволяет сформировать реестр моделей, из которых можно выбрать наиболее подходящую для решения конкретной задачи.
Слабые стороны ансамбля
Ресурсоёмкость. Параллельное развитие и поддержка в стеке большого количества разных по архитектуре моделей предъявляет ряд требований количественного и качественного характера к команде и вычислительным мощностям.
Сложность для аналитики и интерпретации результатов. При возникновении вопроса: «Почему прогноз составил 2000 шт.?», необходимо раскручивать всю спираль с конца. Сперва определить ряд ограничений и условий, по которым считался ансамбль, то есть разобрать его на составляющие. Затем выделить модели, имеющие наибольший вклад в ошибку. После чего проанализировать их качество и причины отклонений от факта. Аналитикам необходимо разбираться в тонкостях работы с каждой из моделей.
Усложнение процесса тестирования и внедрения доработок. Зачастую совершенствование каждой из компонент ансамбля позитивно сказывается на общем результате, но в отдельно взятых ситуациях бывает наоборот. Из-за этого необходимо отдельным этапом оценивать влияние доработок не только на саму модель, но и на ансамбль.
Таким образом, ансамблирование результатов – ключевая часть постобработки прогноза перед возвратом заказчику. Оно выполняет целый ряд важных функций: повышение качества, страховка, управление, контроль. Использование этого подхода целесообразно в рамках дорогих и ценных для бизнеса задач, связанных с прогнозированием. Однако он может быть избыточным в решении локальных проблем.
Вместо эпилога
«Практика – критерий истины»
Выбор оптимального метода и подхода к прогнозированию лучше всего определяется практическим путём. Анализируя собственный опыт, мы приходим к однозначному выводу: работа с разными моделями прогнозирования позволяет взглянуть на возникающие в процессе проблемы под разными углами, обогащает ценным опытом и существенно расширяет кругозор.
С теми же, кто только приступает к решению задач прогнозирования, хочется поделиться прописными истинами:
1. Необходимо начинать с простого и поступательно двигаться в сторону сложного. Несмотря на привлекательность сценария «быстро и качественно „ с нуля“ развернуть бустинг или нейросеть для крупного бизнеса, не обладая опытом в прогнозировании и глубоким пониманием бизнес-сущностей», вероятность успеха КРАЙНЕ МАЛА стремится к нулю. Правильно собранные простые модели могут выигрывать в качестве у более сложных подходов.
2. Не существует плохих подходов к прогнозированию, существуют плохие данные. Начните работу с оценки их качества. Эффект от работы с данными может быть выше, чем совершенствование моделей.
3. Не бойтесь экспериментировать. На практике часто срабатывают неочевидные решения или порицаемые в среде теоретиков упрощения и допущения.
Над статьёй работали
Дмитрий Строганов StrDA – тимлид DA, автор статьи
Илья Иванченко tipprim – тимлид DS, экспертиза по ML
Дмитрий Кравчук dishkakrauch – тимлид DE, экспертиза по технологиям
Андрей Ткаченко He6puToCTb – руководитель блока прогнозирования
Александр Солин rounder, Малика Лутфуллаева malika_l, Егор Игнатов Spectrens, Роман Хаитов KhRN – ответственные за развитие моделей DS
