2015 год был очень богат на события, связанные с нейросетевыми технологиями и машинным обучением. Особенно заметный прогресс показали сверточные и рекуррентные сети, подходящие для решения задач в области компьютерного зрения и распознавания речи. Многие крупные компании опубликовали на Github свои разработки, Google выпустил в свет TensorFlow, Baidu — warp-ctc. Группа ученых из Microsoft Research тоже решила присоединиться к этой инициативе, выпустив Computational Network Toolkit, набор инструментов для проектирования и тренировки сетей различного типа, которые можно использовать для распознавания образов, понимания речи, анализа текстов и многого другого. Интригующим при этом является то, что эта сеть победила в конкурсе ImageNet LSVR 2015 и является самой быстрой среди существующих конкурентов.

Computational Network Toolkit является попыткой систематизировать и обобщить основные подходы по построению различных нейронных сетей, снабдить ученых и инженеров большим набором функций и упростить многие рутинные операции. CNTK позволяет создавать сети глубокого обучения (DNN), сверточные сети (CNN), рекуррентные сети и сети с памятью (RNN, LSTM). Базой для CNTK является лаконичный способ описания нейронной сети через ряд вычислительных шагов, принятый во многих других решениях, например, Theano. Простейшая сеть с одним скрытым слоем может быть представлена следующим образом:

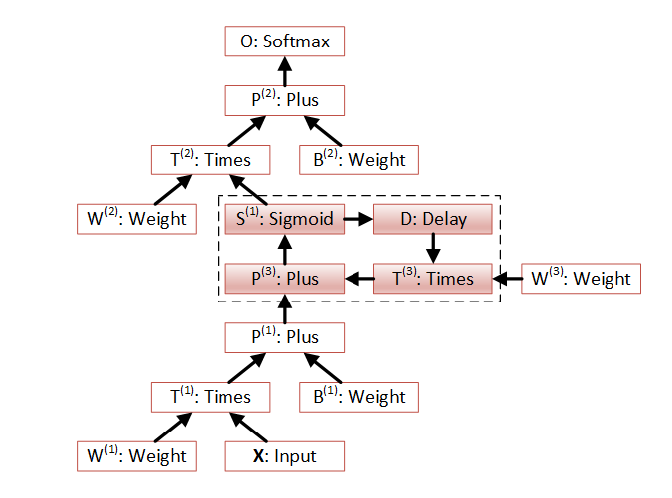
На шаге 2 входной вектор значений X (другими словами, набор чисел) умножается на вектор весов W1, затем складывается с вектором смещений B1, полученные значения весов передаются сигма функции возбуждения. Далее вычисленный вектор S1 умножается на веса скрытого слоя W2 складывается с смещением B2, и вычисляется функция softmax которая является ответом сети.
Этот же алгоритм в графическом виде можно представить так (вычисление идет снизу-вверх):
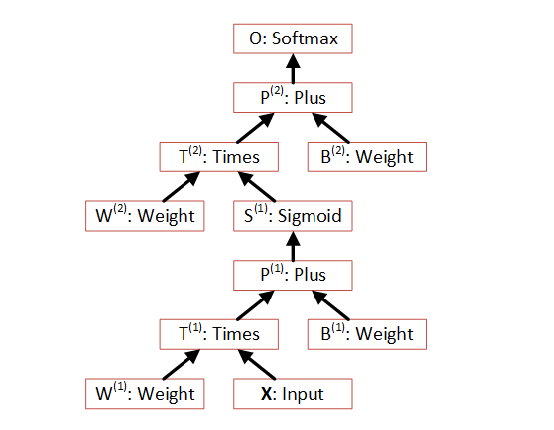
Сети такого типа могут быть описаны с помощью конфигурационного синтаксиса CNTK имеющего в простом случае следующий вид:

Обучение сети, или другими словами, подбор коэффициентов W[N], ведется с помощью стохастического градиентного спуска (SGD), и тоже описывается в конфигурационном файле, задавая параметры скорости обучения, количества эпох и момента:

CNTK помогает решить задачи инфраструктурного характера, в частности, у него уже есть подсистемы чтения данных из различных источников. Это могут быть текстовые и бинарные файлы, изображения, звуки.
Более подробно о возможностях и функциях CNTK можно прочитать в документе An Introduction to Computational Networks and the Computational Network Toolkit.
Для быстрого освоения возможностей CNTK в папке Examples есть ряд примеров, демонстрирующих наиболее распространенные подходы в решении задач применимых к нейронным сетям.
На основе искусственных данных, генерируемых скриптом Matlab, создается сеть, которая решает задачу бинарной классификации — принадлежит ли точка синему или красному кластеру:

Фактически, нейронная сеть пытается восстановить функцию label = 0.25*sin(2*pi*0.5*x) > y с помощью которой эти данные были сгенерированы. Данный пример демонстрирует всю силу и мощь нейронных сетей, так как математически доказано, что благодаря универсальной теореме аппроксимации можно подобрать любую функцию.
Технологию того как с помощью сверточных сетей классифицировать изображения обычно демонстрируют с помощью набора данных MNIST.
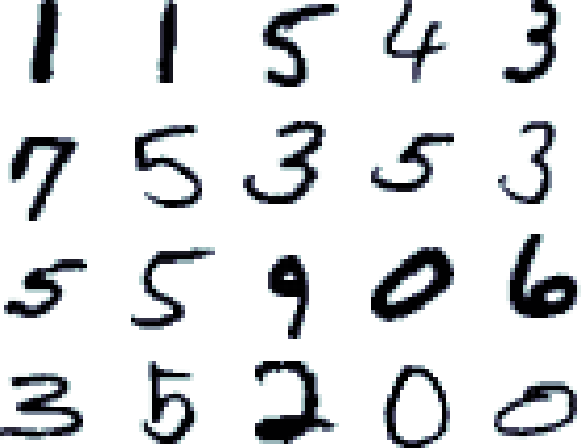
Из этого примера вам станет понятно, как данные о изображении попадают в сверточную сеть (CNN). Не будем делать тайны, все на самом деле просто. Все значения пикселей изображения, а в нашем случае это квадрат 28x28 попадают на вход сети, а ответом сети является вероятность того что поданное изображение принадлежит конкретному классу. Соответственно у сети 784 входа и 10 выходов.
Помимо этого в CNTK входят примеры работы с классическими наборами изображений, наиболее популярными у ученых которые занимаются Deep Convolution Neural Networks, это CIFAR-10 и ImageNet (AlexNet и VGG форматы).
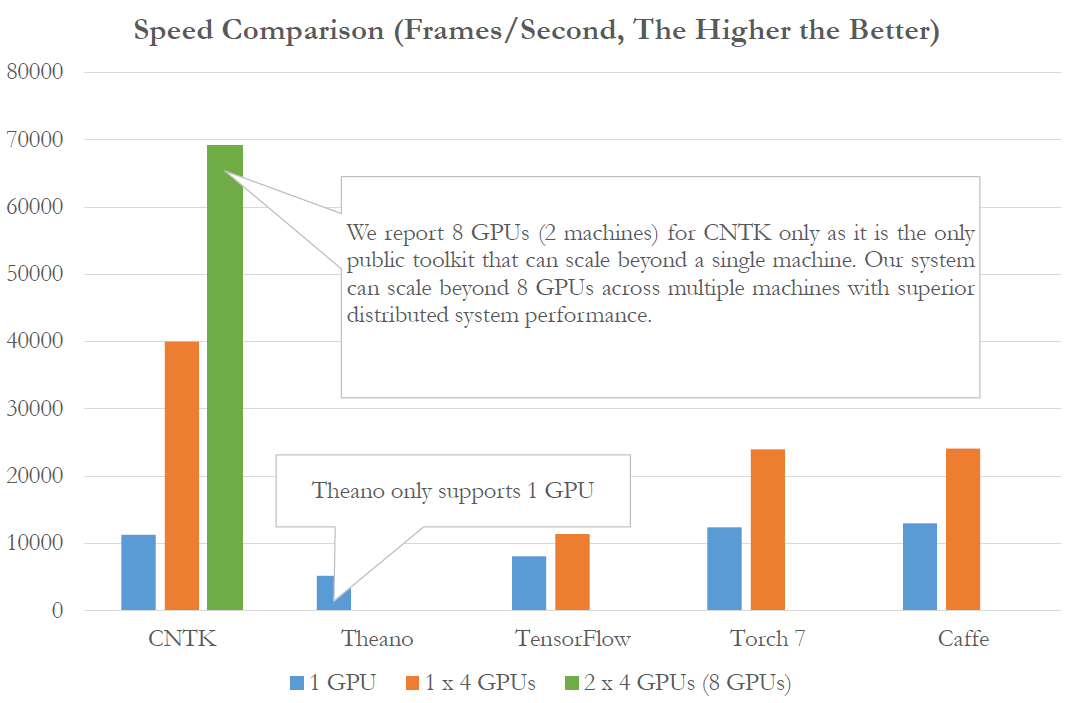
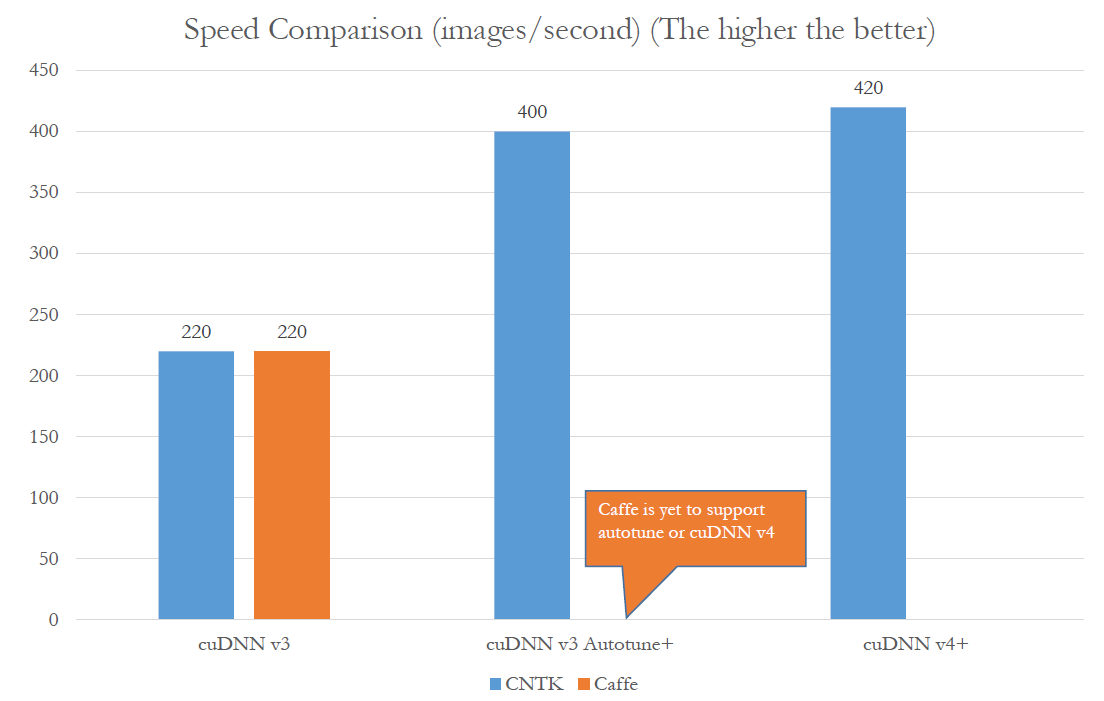
Усилия, которые приложили ученые MSR при создании CNTK могут давать надежду на создание весьма быстрых классификаторов. По некоторым тестам (насколько понимает автор, на «классическом» в мире CNN размере 224x224 пикселя), скорость распознавания может быть свыше 400 кадров в секунду, что является весьма высоким результатом. Еще более интересным является то что современные CNN сети в некоторых случаях уже превосходят возможности человека по распознаванию образов. Более подробно об этом вы можете узнать из публикации Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.

Распознавание речи и текста на естественных языках являются одной из сложных областей. С возникновением идеи рекуррентных сетей появилась надежда на то что этот научный барьер будет преодолен. Рекуррентные сети (RNN) позволяют помнить предыдущее состояние, тем самым снижая количество данных подаваемых на вход сети. Необходимость «зацикливания» и «обладания памятью» нейронных сетей обусловлена тем, что данные голоса или текста невозможно подать на вход сети в полном объёме, они возникают некоторыми порциями, разделенными во времени.

Близкими в этом контексте являются LSTM сети, для которых разработан специальный тип нейронов, переводящий себя в возбужденное состояние на основе некоторых значений и не меняющий его пока на вход не придет деактивационый вектор. LSTM сети в том числе помогают решить задачу преобразования последовательности в последовательность возникающую при переводе одного языка на другой. Возможности RNN и LSTM сетей настолько высоки что, в некоторых случаях уже превосходят человека в распознавании коротких фраз и рукописного ввода.
В CNTK входит несколько примеров анализа речи, на основе AN4 Dataset, Kaldi Project, TIMIT, и проект по трансляции на основе научной работы Sequence-to-sequence neural net models for grapheme to phoneme conversion. Анализ текста представлен несколькими проектами по анализу комментариев, новостей, и произнесенных фраз (spoken language understanding, SLU), с деталями последней технологии вы можете ознакомиться из научной работы SPOKEN LANGUAGE UNDERSTANDING USING LONG SHORT-TERM MEMORY NEURAL NETWORKS.
Ядро CNTK создано на языке C++, но разработчики обещают в будущем создать Python bindings, и C# интерфейсы.
Вы можете самостоятельно собрать CNTK для Windows или Linux, в первом случае вам понадобится Visual Studio 2013, и набор библиотек CUDA, CUB, CuDNN, Boost, ACML (или MKL) и MS-MPI. Опционально, CNTK может быть скомпилирован с поддержкой OpenCV. Детали вы можете узнать из CNTK Wiki.
Можно воспользоваться готовыми бинарными сборками с поддержкой GPU и без, которые опубликованы по адресу https://github.com/Microsoft/CNTK/wiki/CNTK-Binary-Download-and-Configuration
Краткое введение в CNTK которое было проведено учеными из MSR в рамках конференции NIPS 2015 опубликовано по адресу http://research.microsoft.com/pubs/226641/CNTK-Tutorial-NIPS2015.pdf
Совсем краткое введение в CNTK
Computational Network Toolkit является попыткой систематизировать и обобщить основные подходы по построению различных нейронных сетей, снабдить ученых и инженеров большим набором функций и упростить многие рутинные операции. CNTK позволяет создавать сети глубокого обучения (DNN), сверточные сети (CNN), рекуррентные сети и сети с памятью (RNN, LSTM). Базой для CNTK является лаконичный способ описания нейронной сети через ряд вычислительных шагов, принятый во многих других решениях, например, Theano. Простейшая сеть с одним скрытым слоем может быть представлена следующим образом:

На шаге 2 входной вектор значений X (другими словами, набор чисел) умножается на вектор весов W1, затем складывается с вектором смещений B1, полученные значения весов передаются сигма функции возбуждения. Далее вычисленный вектор S1 умножается на веса скрытого слоя W2 складывается с смещением B2, и вычисляется функция softmax которая является ответом сети.
Этот же алгоритм в графическом виде можно представить так (вычисление идет снизу-вверх):

Сети такого типа могут быть описаны с помощью конфигурационного синтаксиса CNTK имеющего в простом случае следующий вид:

Обучение сети, или другими словами, подбор коэффициентов W[N], ведется с помощью стохастического градиентного спуска (SGD), и тоже описывается в конфигурационном файле, задавая параметры скорости обучения, количества эпох и момента:

CNTK помогает решить задачи инфраструктурного характера, в частности, у него уже есть подсистемы чтения данных из различных источников. Это могут быть текстовые и бинарные файлы, изображения, звуки.
Более подробно о возможностях и функциях CNTK можно прочитать в документе An Introduction to Computational Networks and the Computational Network Toolkit.
Примеры использования CNTK
Для быстрого освоения возможностей CNTK в папке Examples есть ряд примеров, демонстрирующих наиболее распространенные подходы в решении задач применимых к нейронным сетям.
Простой пример классификации
На основе искусственных данных, генерируемых скриптом Matlab, создается сеть, которая решает задачу бинарной классификации — принадлежит ли точка синему или красному кластеру:
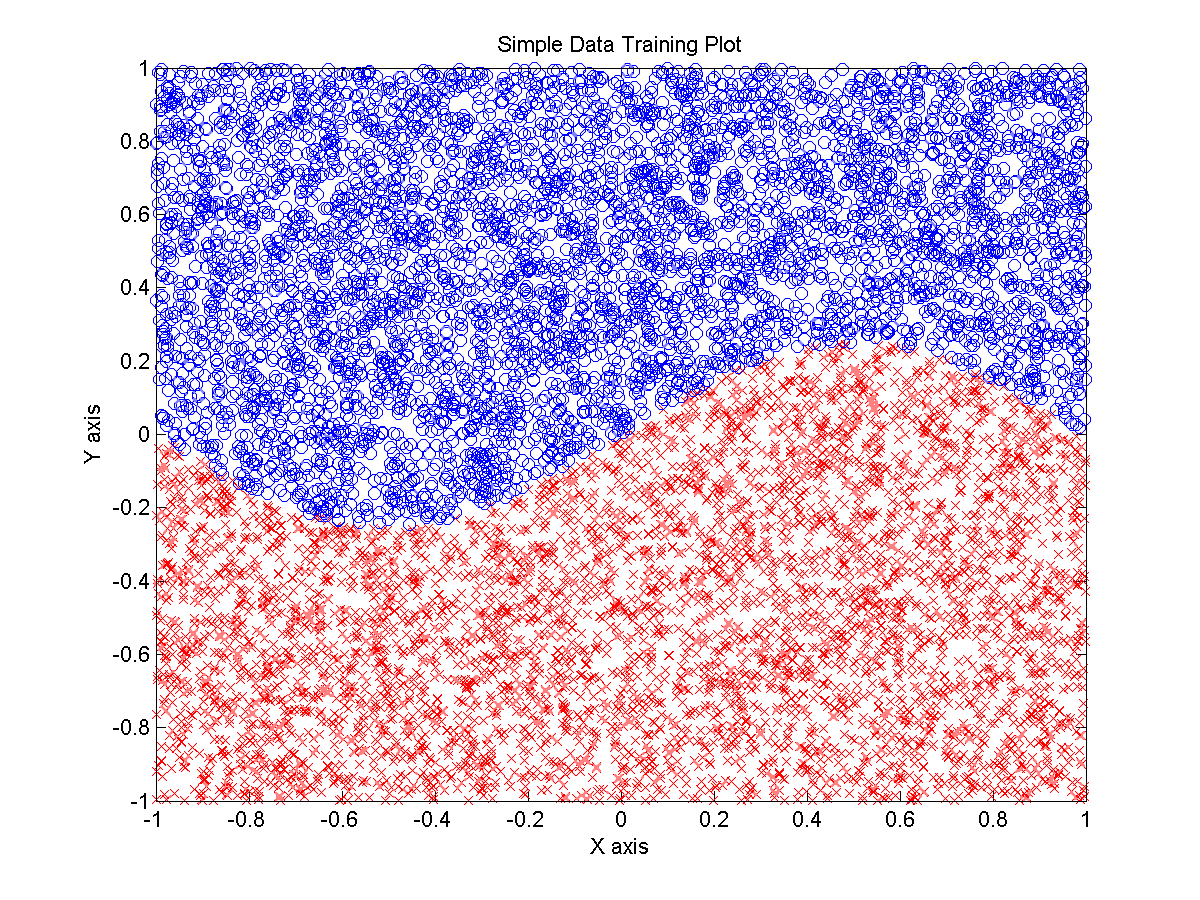
Фактически, нейронная сеть пытается восстановить функцию label = 0.25*sin(2*pi*0.5*x) > y с помощью которой эти данные были сгенерированы. Данный пример демонстрирует всю силу и мощь нейронных сетей, так как математически доказано, что благодаря универсальной теореме аппроксимации можно подобрать любую функцию.
Анализ изображений
Технологию того как с помощью сверточных сетей классифицировать изображения обычно демонстрируют с помощью набора данных MNIST.

Из этого примера вам станет понятно, как данные о изображении попадают в сверточную сеть (CNN). Не будем делать тайны, все на самом деле просто. Все значения пикселей изображения, а в нашем случае это квадрат 28x28 попадают на вход сети, а ответом сети является вероятность того что поданное изображение принадлежит конкретному классу. Соответственно у сети 784 входа и 10 выходов.
Помимо этого в CNTK входят примеры работы с классическими наборами изображений, наиболее популярными у ученых которые занимаются Deep Convolution Neural Networks, это CIFAR-10 и ImageNet (AlexNet и VGG форматы).
Усилия, которые приложили ученые MSR при создании CNTK могут давать надежду на создание весьма быстрых классификаторов. По некоторым тестам (насколько понимает автор, на «классическом» в мире CNN размере 224x224 пикселя), скорость распознавания может быть свыше 400 кадров в секунду, что является весьма высоким результатом. Еще более интересным является то что современные CNN сети в некоторых случаях уже превосходят возможности человека по распознаванию образов. Более подробно об этом вы можете узнать из публикации Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.
Анализ речи и естественных языков
Распознавание речи и текста на естественных языках являются одной из сложных областей. С возникновением идеи рекуррентных сетей появилась надежда на то что этот научный барьер будет преодолен. Рекуррентные сети (RNN) позволяют помнить предыдущее состояние, тем самым снижая количество данных подаваемых на вход сети. Необходимость «зацикливания» и «обладания памятью» нейронных сетей обусловлена тем, что данные голоса или текста невозможно подать на вход сети в полном объёме, они возникают некоторыми порциями, разделенными во времени.
Близкими в этом контексте являются LSTM сети, для которых разработан специальный тип нейронов, переводящий себя в возбужденное состояние на основе некоторых значений и не меняющий его пока на вход не придет деактивационый вектор. LSTM сети в том числе помогают решить задачу преобразования последовательности в последовательность возникающую при переводе одного языка на другой. Возможности RNN и LSTM сетей настолько высоки что, в некоторых случаях уже превосходят человека в распознавании коротких фраз и рукописного ввода.
В CNTK входит несколько примеров анализа речи, на основе AN4 Dataset, Kaldi Project, TIMIT, и проект по трансляции на основе научной работы Sequence-to-sequence neural net models for grapheme to phoneme conversion. Анализ текста представлен несколькими проектами по анализу комментариев, новостей, и произнесенных фраз (spoken language understanding, SLU), с деталями последней технологии вы можете ознакомиться из научной работы SPOKEN LANGUAGE UNDERSTANDING USING LONG SHORT-TERM MEMORY NEURAL NETWORKS.
Если вы хотите попробовать CNTK в деле
Ядро CNTK создано на языке C++, но разработчики обещают в будущем создать Python bindings, и C# интерфейсы.
Вы можете самостоятельно собрать CNTK для Windows или Linux, в первом случае вам понадобится Visual Studio 2013, и набор библиотек CUDA, CUB, CuDNN, Boost, ACML (или MKL) и MS-MPI. Опционально, CNTK может быть скомпилирован с поддержкой OpenCV. Детали вы можете узнать из CNTK Wiki.
Можно воспользоваться готовыми бинарными сборками с поддержкой GPU и без, которые опубликованы по адресу https://github.com/Microsoft/CNTK/wiki/CNTK-Binary-Download-and-Configuration
Краткое введение в CNTK которое было проведено учеными из MSR в рамках конференции NIPS 2015 опубликовано по адресу http://research.microsoft.com/pubs/226641/CNTK-Tutorial-NIPS2015.pdf
