Комментарии 11
Прикольный у вас фреймворк) напоминает initial commit какой-нибудь библиотеки.
Честно, все эти плагинные системы с подгрузкой типов из dll, смотрятся в наше время не очень.
Все будет жутко тормозить и возвращать на 10 лет назад с медленной загрузкой страниц и тому подобными вещами.
У вас, как я понял CMS и без этого сложно, но у вас слишком шаблонный и стандартный путь, пройденный тысячами людей, зачем его идти в 1001 раз и зачем миру очередная CMS? Первая CMS на .NET, запускаемая в Linux?
Раз уж вы работаете в этой области, то хотелось бы увидеть какой-то свежий взгляд на стандартные вещи, а не банальные репозитории к RDBMS и MVC-контроллеры: что-то типа масштабируемой NoSQL базы, которая в JSON хранит какие-то элементы и данные, а какой-нибудь изоморфный JS-фреймворк это рендерит (можно и на клиенте) и показывает и все это запускается одим файлом, тем более, что у вас на начальном этапе такой маневр есть, а у многих CMS он уже слишком далеко позади. Понятно, что ваша компания зарабатывает на разработке ПО, а не пишет для души, но… может быть…
Я, конечно, CMS не занимаюсь, и могу ошибаться в возможности таких манипуляций, но реально хочется чего-то свеженького!
Сайты ваши понравились.
Честно, все эти плагинные системы с подгрузкой типов из dll, смотрятся в наше время не очень.
Все будет жутко тормозить и возвращать на 10 лет назад с медленной загрузкой страниц и тому подобными вещами.
У вас, как я понял CMS и без этого сложно, но у вас слишком шаблонный и стандартный путь, пройденный тысячами людей, зачем его идти в 1001 раз и зачем миру очередная CMS? Первая CMS на .NET, запускаемая в Linux?
Раз уж вы работаете в этой области, то хотелось бы увидеть какой-то свежий взгляд на стандартные вещи, а не банальные репозитории к RDBMS и MVC-контроллеры: что-то типа масштабируемой NoSQL базы, которая в JSON хранит какие-то элементы и данные, а какой-нибудь изоморфный JS-фреймворк это рендерит (можно и на клиенте) и показывает и все это запускается одим файлом, тем более, что у вас на начальном этапе такой маневр есть, а у многих CMS он уже слишком далеко позади. Понятно, что ваша компания зарабатывает на разработке ПО, а не пишет для души, но… может быть…
Я, конечно, CMS не занимаюсь, и могу ошибаться в возможности таких манипуляций, но реально хочется чего-то свеженького!
Сайты ваши понравились.
Спасибо за комментарий! CMS делал не исходя из желания сделать "что-то свеженькое", а из-за необходимости именно в таком инструменте для работы. На предыдущей версии есть множество проектов, сейчас решил переписать, сделать модульно и кроссплатформенно, раз уж такая возможность (я имею в виду кроссплатформенность) появилась на моей любимой платформе .NET. Может быть это старомодно, но да, мне нравится, что ASP.NET-приложение работает на Linux и Mac. Даже без стороннего веб-сервера.
Что касается фреймворка — он, кстати, позволяет загружать не только dll, но и другие штуки, вроде NuGet-пакетов или просто проектов в исходниках. Было бы интересно взглянуть, как можно было бы решить задачу иначе. Не видел пока что ничего подходящего. На счет скорости — "жуткого торможения" не наблюдаю, но без сомнения, некое падение производительности у модульного проекта по отношению к "цельному" конечно же будет. Но это цена, которую придется заплатить за гибкость и удобство. В общем, буду благодарен, если приведете больше конкретики. Спасибо!
Что касается фреймворка — он, кстати, позволяет загружать не только dll, но и другие штуки, вроде NuGet-пакетов или просто проектов в исходниках. Было бы интересно взглянуть, как можно было бы решить задачу иначе. Не видел пока что ничего подходящего. На счет скорости — "жуткого торможения" не наблюдаю, но без сомнения, некое падение производительности у модульного проекта по отношению к "цельному" конечно же будет. Но это цена, которую придется заплатить за гибкость и удобство. В общем, буду благодарен, если приведете больше конкретики. Спасибо!
Что-то я ничего не понял. Зачем нужен ExtCore.WebApplication.Startup когда и так есть Startup класс?
Зачем представления оформлять в виде расширений ExtensionA и ExtensionB?
Хотель бы прочитать какое-то обоснование такой структуре.
Из предыдущей статьи тоже непонятно. Там только как-то фрагментарно описано что надо делать вот так и так. А почему — непонятно.
Зачем представления оформлять в виде расширений ExtensionA и ExtensionB?
Хотель бы прочитать какое-то обоснование такой структуре.
Из предыдущей статьи тоже непонятно. Там только как-то фрагментарно описано что надо делать вот так и так. А почему — непонятно.
На счет ExtCore.WebApplication.Startup. Этот класс необходим, чтобы отнаследовавшись от него получить весь необходимый функционал (поиск, подготовка расширений и прочее). Имена одинаковые для удобства (т. к. своим классом вы дополняете базовый). В своем классе вы можете не переопределять функции ConfigureServices и Configure, если добавить туда нечего. Т. е. это просто базовый класс.
На счет структуры расширений. Да, как-то я упустил этот момент. Исхожу из следующих идей. Чтобы проекты одного расширения не выглядели разрознено, логично, чтобы названия проектов начинались названием расширения. Если расширение большое (как в случае с CMS), такие куски, как фронтенд и бекенд, лучше разделять на отдельные проекты. Так с ними удобнее работать, особенно в команде. Также, при необходимости можно подключить только фронтенд и не подключать бекенд. Что касается данных. Модели удобно выносить в отдельный проект, т. к. в больших расширениях (да и вообще, приложениях) ссылки на них могут быть нужны в различных проектах. Кроме того, иногда проекту нужны только описания моделей и не нужна работа с базой. Мне больше нравится, когда добавив ссылку на проект с моделями я не получу ничего лишнего (вроде реализации работы с БД). Абстракции репозиториев лежат также в отдельном проекте, т. к. именно через них производится вся работа с данными, без знания о конкретных реализациях для конкретных хранилищ. Ну и, соответственно, конкретные реализации лежат каждая в своем проекте, чтобы можно было использовать независимо ту или иную реализацию для того или иного хранилища. Также можно в любой момент добавить проек-реализацию нового хранилища и ничего не придется переделывать благодаря такой структуре.
Т. е. если вам необходимо подключить расширение, вы подключаете основной проект и выбранную конкретную реализацию репозиториев (например, для SQLite, если расширение вообще работает с хранилищем). Возможно, эту идею хорошо проиллюстрирует эта ссылка.
Буду рад идеям по улучшению этой структуры.
На счет структуры расширений. Да, как-то я упустил этот момент. Исхожу из следующих идей. Чтобы проекты одного расширения не выглядели разрознено, логично, чтобы названия проектов начинались названием расширения. Если расширение большое (как в случае с CMS), такие куски, как фронтенд и бекенд, лучше разделять на отдельные проекты. Так с ними удобнее работать, особенно в команде. Также, при необходимости можно подключить только фронтенд и не подключать бекенд. Что касается данных. Модели удобно выносить в отдельный проект, т. к. в больших расширениях (да и вообще, приложениях) ссылки на них могут быть нужны в различных проектах. Кроме того, иногда проекту нужны только описания моделей и не нужна работа с базой. Мне больше нравится, когда добавив ссылку на проект с моделями я не получу ничего лишнего (вроде реализации работы с БД). Абстракции репозиториев лежат также в отдельном проекте, т. к. именно через них производится вся работа с данными, без знания о конкретных реализациях для конкретных хранилищ. Ну и, соответственно, конкретные реализации лежат каждая в своем проекте, чтобы можно было использовать независимо ту или иную реализацию для того или иного хранилища. Также можно в любой момент добавить проек-реализацию нового хранилища и ничего не придется переделывать благодаря такой структуре.
Т. е. если вам необходимо подключить расширение, вы подключаете основной проект и выбранную конкретную реализацию репозиториев (например, для SQLite, если расширение вообще работает с хранилищем). Возможно, эту идею хорошо проиллюстрирует эта ссылка.
Буду рад идеям по улучшению этой структуры.
Благодарю за ответ. Становится понятнее. И хорошо было бы начать первую статью с подобного объяснения.
А еще ДО него описать ЦЕЛЬ — что вы хотите построить.
Ибо конечная цель определяет средства. И читателям неплохо бы сообщить вашу цель с самого начала. Тогда мы поймем почему вы делаете так и эдак.
И картинка весьма помогает. Например
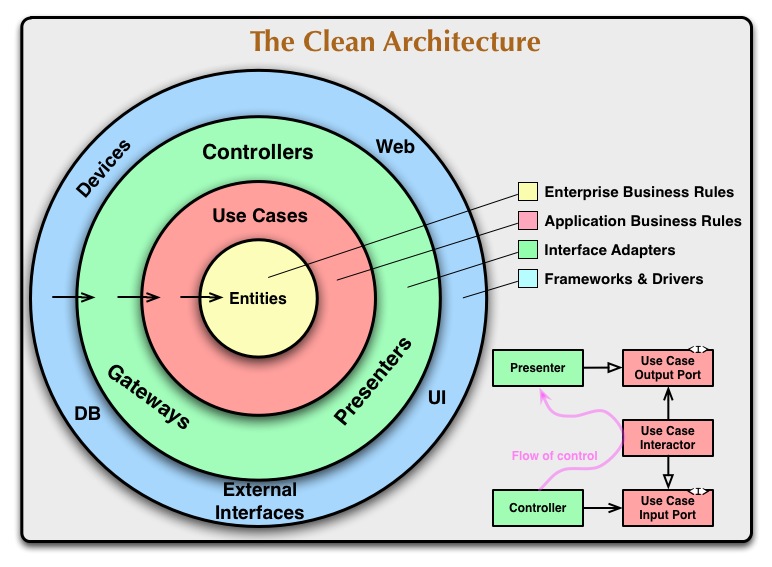
Моя идея: выделять сценарии использования — use cases — в отдельный проект. Я по возможности так делаю.
Получается структура похоже как на картинке.
Модель -> Репозетроий -> Сценарий -> Контроллер
Преимущество: одни и теже сценарии можно использовать из разных контроллеров и даже из разных приложений (web, mobil app).
На сценарии навешивать статистику, логи и т.д.
А контроллеры — очень тонкие, только готовят данные для представлений.
Я как-то писал пост в своем блоге про очень простую структуру MVC. Самый базовый минимум
http://blog.chudinov.net/how-to-create-a-minimal-asp-net-mvc-application/
А еще ДО него описать ЦЕЛЬ — что вы хотите построить.
Ибо конечная цель определяет средства. И читателям неплохо бы сообщить вашу цель с самого начала. Тогда мы поймем почему вы делаете так и эдак.
И картинка весьма помогает. Например
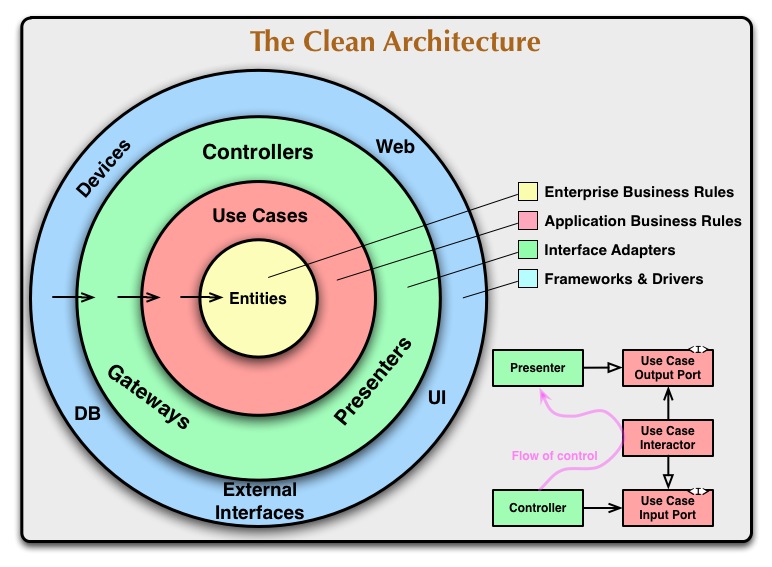
Моя идея: выделять сценарии использования — use cases — в отдельный проект. Я по возможности так делаю.
Получается структура похоже как на картинке.
Модель -> Репозетроий -> Сценарий -> Контроллер
Преимущество: одни и теже сценарии можно использовать из разных контроллеров и даже из разных приложений (web, mobil app).
На сценарии навешивать статистику, логи и т.д.
А контроллеры — очень тонкие, только готовят данные для представлений.
Я как-то писал пост в своем блоге про очень простую структуру MVC. Самый базовый минимум
http://blog.chudinov.net/how-to-create-a-minimal-asp-net-mvc-application/
Насчет выделения цели — согласен, это правильная мысль. И картинки тоже. Все приходит с опытом.
Насчет сценариев использования. Насколько я понимаю, это нечто вроде сервисного слоя? Т. е. контроллер обращается к сервису по какому-то методу предметной области, тот обращается к репозиториям (одному или нескольким), те, в свою очередь, уже к ORM и слою хранилища или источника данных. Правильно я понял? Если так, то я не использовал сервисный слой, чтобы не добавлять эту еще одну прослойку там, где в ней нет потребности. А объемные специфические задачи предметной области я обычно переношу на некие классы-хелперы, менеджеры и так далее.
Насчет сценариев использования. Насколько я понимаю, это нечто вроде сервисного слоя? Т. е. контроллер обращается к сервису по какому-то методу предметной области, тот обращается к репозиториям (одному или нескольким), те, в свою очередь, уже к ORM и слою хранилища или источника данных. Правильно я понял? Если так, то я не использовал сервисный слой, чтобы не добавлять эту еще одну прослойку там, где в ней нет потребности. А объемные специфические задачи предметной области я обычно переношу на некие классы-хелперы, менеджеры и так далее.
Вот здесь это хорошо описано chsakell.com/2015/02/15/asp-net-mvc-solution-architecture-best-practices
Да. Но я об этом и говорю, взгляните на слой сервисов в этом примере. Он практически полностью состоит из методов вроде:
Т. е. в большинстве случаев, где нет какой-то действительно сложной предметной области, слой сервисов это, как по мне, лишняя прослойка, идентичная слою единицы работы с репозиториями по функциональности, но находящаяся над ним. Еще одна параллельная иерархия интерфейсов/реализаций.
public Category GetCategory(int id)
{
var category = categorysRepository.GetById(id);
return category;
}Т. е. в большинстве случаев, где нет какой-то действительно сложной предметной области, слой сервисов это, как по мне, лишняя прослойка, идентичная слою единицы работы с репозиториями по функциональности, но находящаяся над ним. Еще одна параллельная иерархия интерфейсов/реализаций.
Да всё поняли правильно.
Хелпер-классы и менеджеры заменяют слой сервисов. Тоже сойдёт.
Хелпер-классы и менеджеры заменяют слой сервисов. Тоже сойдёт.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Готовим ASP.NET Core: подробнее про работу с модульным фреймворком