
Привет, я Антон Маслов, ведущий разработчик в MTS AI.
В предыдущих статьях я рассказывал о том, как работает распознавание изображений на чипе KL520 с помощью нейросети Tiny YOLOv3, а так же о том, как устроена, из чего состоит и как собирается прошивка чипов KL520. И вот теперь, когда мы познакомились с технологией Edge AI в общих чертах, мы можем отправиться в самое увлекательное путешествие и создать на базе KL520 собственный оригинальный девайс!
Распознавание изображений — это всего лишь одна из множества задач, решаемых методами искусственного интеллекта. Нейросетевые технологии открывают возможности для создания умных устройств, использующих сложные алгоритмы работы с временными последовательностями. Одной из таких задач является распознавание голосовых команд в режиме реального времени. На эту тему существует множество решений. Поисковики в смартфонах, умные колонки, голосовое управление в автомобилях, и даже голосовые боты. Но все они требуют связи с Интернетом. С одной стороны, это связано с вычислительной сложностью процесса распознавания и размерами сетей, которые для этого используются. Мощности обычных смартфонов может просто не хватить для комфортной работы в реальном времени. С другой стороны, крупные компании часто используют результаты распознавания для сбора данных о потребительских запросах пользователей, усовершенствования механизмов рекламы и маркетинга.
Реализация же механизма распознавания звука на конечных устройствах позволила бы создавать системы голосового управления любыми внешними объектами без внешних серверов, без задержек, а также без передачи данных через потенциально небезопасные соединения.
А теперь представьте, что распознавание нескольких десятков голосовых команд можно сделать на устройстве по цене среднего микроконтроллера, работающем от батарейки. Причем голосовые команды распознаются независимо от тембра голоса, скорости речи и других особенностей произношения. Скажете, невозможно? Ну, тогда, добро пожаловать в мир нейрозвука!
Математические основы
Итак, для распознавания голосовых команд надо сначала разобраться, что эти команды из себя представляют с точки зрения данных.
Как известно, звук в цифровом формате можно представить в виде последовательности значений, записанных со определенной частотой. В нашем случае это массив чисел в 16-битном или 24-битном двоичном формате. Частота дискретизации может быть любой, но для наших задач будет достаточно 16 КГц. Нетрудно догадаться, что в исходном формате, во временной области, такой массив данных нам не подойдет. Звуковые сигналы, как и любые другие временные последовательности плохо подходят для анализа и обработки в сыром виде. Нам придется их преобразовать.
Для этой цели используется способ представления звука в виде набора так называемых мел-спектральных коэффициентов. Этот метод широко используется в алгоритмах сжатия звука, например MP3, и берет свое начало из теории музыки. Идея состоит в следующем. Еще в XVIII веке в эпоху И. С. Баха музыканты заметили, что наш слух устроен таким образом, что мы слышим в унисон звуки, которые расположены на частотной шкале не в линейном, а в логарифмическом масштабе. То есть расстояние в герцах между одинаковыми нотами октав тем больше, чем выше звук.

Это обусловлено физиологическим строением нашего слухового аппарата. Чем выше частота, тем труднее почувствовать разницу между звуками. Эту идею подхватили математики, и, еще до развития технологий искусственного интеллекта, появились способы опознавания музыкальных инструментов как раз по набору мел-спектральных коэффициентов. А в дальнейшем оказалось, что этот метод крайне удачно подходит и для распознавания вообще любых звуков.
Что же это за коэффициенты такие? Все просто. Сначала выясним что такое «мел». Мел это, на самом, деле просто название единицы измерения частоты или высоты звука. Если герц это линейная единица измерения, то мел — логарифмическая, и она пропорциональна звуковому давлению. Каждую частоту можно представить в мелах. А само слово «мел» происходит от «мелодия».

Теперь разберемся, что такое «мел-спектральные коэффициенты». Группа американских ученых еще в 60-х годах прошлого века проводила исследования сейсмической активности. И они предложили теорию представления сигналов в особом формате. Если не вдаваться в детали, на практике это означает формирование спектра мощности сигнала в особом логарифмическом масштабе в сжатом виде. Более подробно об теории мел-спектральных коэффициентов можно почитать, например, тут.
Теперь пока временно забудем про загадочные коэффициенты и представим наш сигнал в мел-спектральном виде.
Для начала нарежем исходный сигнал на участки. Для этого нам понадобится оконное преобразование. Для корректного отображения, исходный сигнал необходимо предварительно дополнить в начале и в конце небольшими зеркальными участками в половину длины окна. А само окно будет применяться с наложением. Это необходимо для того, чтобы при оконном преобразовании не потерять данные в самом начале и в самом конце звуковой дорожки. Максимум оконной функции находится в ее центре. А форма в виде косинусоиды позволяет нарезать сигнал без добавления паразитных высокочастотных гармоник, которые неизбежно возникнут при резком появлении или пропадании звука. В итоге получим двумерный массив данных.

Затем выполним преобразование Фурье каждого из участков. Получим частотное представление сигнала в комплексном виде. После этого вычислим квадраты абсолютных значений комплексных чисел и таким образом получим спектральную картину мощности. Легко заметить, что в таком представлении данные выражены незаметно.

На следующем шаге получим мел-частотный спектр. Для этого наложим на спектр мощности серию треугольных фильтров. Каждый фильтр соответствует определенному мелу, то есть определенной частоте. Наложение таких фильтров позволит определить какие частоты исходного сигнала и в каком объеме присутствуют в каждом меле. Нетрудно догадаться, что существует предельное количество мелов, в которых можно выразить частоты, полученные из преобразования Фурье.
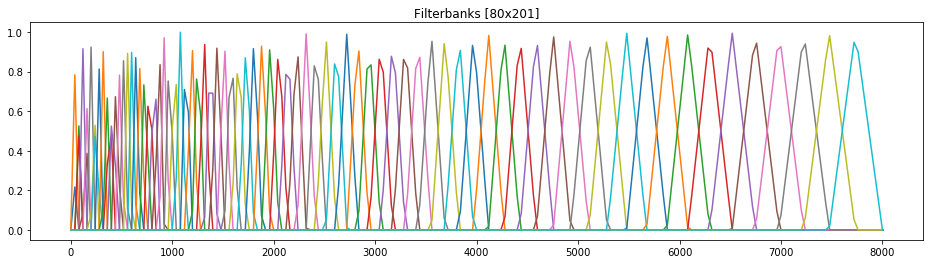
Затем, переведем значения мощностей в децибелы. То есть еще раз логарифмируем, но по другой оси. Таким образом получим мел-частотный спектр в децибелах. По сравнению со исходным спектром мощности тут данные выражены уже гораздо более явно.

В итоге, нам остается последний шаг. Получение тех самых мел-спектральных коэффициентов (далее — MFCC). Фактически, мы выполним сжатие данных. А для этого применим дискретно-косинусное преобразование. Про теорию самого преобразования можно подробнее почитать, например, тут.
На практике это означает, что мы вычленим из исходного набора самые значимые данные. В качестве бонуса мы уберем и шум. Нас мало интересуют мелкие колебания вокруг интересующих звуков, нам важно выделить из сигнала сами звуки. После чего полученные значения необходимо нормализовать, так как абсолютные величины могут вылезать за границы диапазона. Нормализованные коэффициенты в виде картинки и будут служить основой для распознавания и в дальнейшем будут подаваться на вход нейросети.

К примеру, сигнал длительностью 4 секунды, записанный с частотой дискретизации 16 КГц, преобразуется в набор MFCC в виде матрицы размером 40×320 чисел в формате float32, где 40 — количество коэффициентов, а 320 — количество участков. Если звук представлен в 24-битном формате, получается, что его исходный размер 192000 байт. А размер матрицы коэффициентов — уже 51200 байт. То есть, мы сжимаем сырые данные почти в 4 раза с несущественными потерями. А если учитывать, что для работы на KL520 используются квантизованные данные в формате int8, то размер входа получается 12800 байт. А это сжатие уже в 15 раз!
Нейросеть
Нетрудно заметить, что аудио данные, представленные с помощью набора MFCC, по внешнему виду очень напоминают изображения. Более того, диапазон значений, при котором получается создать хорошую систему распознавания, как раз укладывается в формат RGB, причем в один канал. Так получилось, что системы распознавания изображений получили свое развитие несколько раньше других приложений искусственного интеллекта. В настоящее время множество инструментов для обучения нейросетей очень хорошо оптимизированы именно для работы с картинками в разных стандартных форматах. Это же касается и утилит от Kneron. Мы воспользуемся этим преимуществом, но для решения задачи работы со звуком.
Несмотря на то, что нам, в принципе, хватает одного канала, многочисленные исследования методов распознавания голоса показали, что наилучшие результаты достигаются в случае, когда в качестве входных данных используются не только сами значения MFCC, но также их первая и вторая производные. Это позволяет учитывать динамические характеристики звукового спектра и наилучшим образам вычленить признаки из данных. А для передачи этих значений как раз очень удобно использовать два других канала из тройки RGB.
Не существует единой универсальной структуры нейросети, наилучшим образом адаптированной для работы с MFCC и производными от них. В конце концов, и количество коэффициентов, и параметры шагов вычисления производных сильно зависят от условий и параметров записи звука. Однако, некоторые популярные архитектуры, например ResNet, вполне подходят для решения задачи. В данной работе использовалась нейросеть ResNet18, доработанная путем приведения размера последнего полносвязного слоя к количеству обучаемых команд. На практике это означает, что мы выкидываем изначальный полносвязный слой и добавляем вместо него новый. Размерность его входа будет совпадать с размерностью выхода предыдущего сверточного слоя, каким бы он ни был. А выход — это одномерный вектор. Его длина равна количеству команд, а каждое значение — это предсказание нейросети по каждой команде. Для получения вероятностей во float32 от 0 до 1 нам также понадобится слой softmax, который в нашем случае будет реализован уже программно. Остается только подготовить немалое количество записанных команд, пропустить их через механизм предобработки (получить MFCC), собрать таким образом данные для обучения и, в конечном итоге, обучить новую нейросеть. Подробнее о самом процессе обучения можно почитать, например, тут.

Квантизация нейросети и получение кода запуска на нейроускорителе выполняем с использованием набора инструментов от Kneron. Подробнее об этом механизме можно почитать в первой статье из настоящего цикла.
Аппаратная часть
Возвращаясь из мира математики, нейросетей и высоких материй в мир железа, стоит в первую очередь рассказать о том, как же получить изначальные аудио данные. Записывать звук с микрофона придется на достаточно низком уровне. Для этой цели понадобится миниатюрный встраиваемый микрофон с интерфейсом I2S. Наподобие тех, что стоят в сотовых телефонах. В чипе KL520 как раз для такого устройства есть соответствующий вход.

При подаче питания данные с микрофона начинают передаваться автоматически в формате 24 бита с частотой 16 КГц. Причем, передается только один канал, в данном случае, левый.
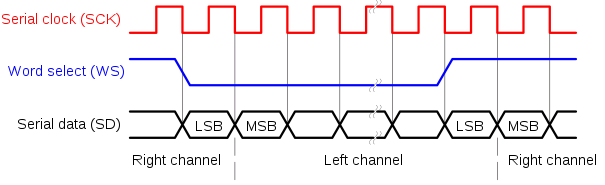
Настройка принимающей части, а именно интерфейса I2S на KL520 — это отдельная тема. К сожалению, ввиду отсутствия описания периферии, приходится использовать готовые примеры работы с драйверами I2S, из которых не до конца ясны возможности на аппаратном уровне. В настройках выбирается моно-режим и разрешается работа через DMA. В этом случае требуется настройка размера одной DMA передачи и выбора реакции системы при обработке прерываний от DMA, но не будем заострять на внимание на этих деталях.
Предобработка
Прежде чем погрузиться в вопросы реализации следует пояснить один важный момент. Из всех шагов алгоритма предварительной обработки сигналов наибольшую вычислительную сложность представляет именно преобразование Фурье. И так уж получается, что единственный работоспособный вариант, это так называемое быстрое преобразование Фурье (БПФ). Не вдаваясь в подробное описание этого метода, вспомним, что мы ограничены в размере подаваемого сигнала для БПФ степенью двойки. Это накладывает некоторые ограничения на размер и шаг оконного преобразования. Но это еще не самое интересное. Дело в том, что достаточно эффективная реализация алгоритма БПФ есть в стандарте CMSIS, но для каждого варианта БПФ существует свой набор коэффициентов и части исполняемого кода. Все варианты сразу использовать нельзя, так как такой объем логики просто не влезет в SRAM контроллера. Поэтому для каждого размера необходимо включать специальные определения, например, для выбора размера БПФ 1024 отсчета.
ARM_DSP_CONFIG_TABLES
ARM_FFT_ALLOW_TABLES
ARM_TABLE_TWIDDLECOEF_F32_512
ARM_TABLE_BITREVIDX_FLT_512
ARM_TABLE_TWIDDLECOEF_RFFT_F32_1024Весь алгоритм предварительной обработки запускается на вспомогательном ядре. Это позволяет максимально распараллелить процессы, так как вся обработка занимает достаточно много времени. Основное ядро занимается только чтением данных с микрофона в сыром виде и отдает команды остальным узлам.
Так как вычисление параметров треугольных фильтров для мел-преобразования — это однократная операция, ее имеет смысл разместить в части кода, выполняемой только при загрузке. То же касается и операций по выделению памяти для всех нужных массивов на каждом шаге алгоритма. Их лучше выделить все заранее в какую-нибудь обособленную область DDR.
Для запуска непосредственно нейроускорителя используется набор API функции внутри прошивки. Причем, в SDK от Kneron для KL520 нам уже доступен набор различных вариантов работы, например с Yolo. Для каждой известной нейросети в системе предусмотрен свой уникальный идентификатор. Также заготовлен большой запас идентификаторов для пользовательских нейросетей. Помимо этого, для одной нейросети может существовать несколько вариантов запуска или применения определенных алгоритмов пред- и постобработки. Вариант запуска выбирается через указание jobid в управляющей структуре. Таким образом для нашей собственной нейросети с особой предобработкой требуется использовать один из резервных идентификаторов сети и для него определить в системе уникальный jobid.
Реализация
Так как все процессы в систем работают под управлением RTOS, чтение данных с микрофона, а также вывод результатов, например на внешний экран, это отдельные таски RTOS. Создание этих тасков и инициализация параметров периферии осуществляется однократно сразу после запуска.
Так как разработка нейросети и отладка механизмов предобработки сигналов это довольно сложный итеративный процесс, было реализовано два режима работы системы. Основной режим — автономный, при котором вся логика реализована и запускается на кристалле.

Другой режим — это режим компаньона, когда на чипе остается только запуск нейросети, а вся подготовка данных происходит наверху. Идя заключается в том, что на практике намного проще отлаживать алгоритм на большом компьютере, чем на контроллере через отладчик. В режиме компаньона на вход чипа подаются уже пред-обработанные данные, то есть просто матрица чисел. Причем, в данном случае мы уже не ограничены ни размером БПФ, ни быстродействием вычислений. В этом режиме можно провести серию экспериментов и вывести оптимальные параметры всех шагов алгоритма. А затем уже портировать их во встраиваемую систему.

Эти два режима, в конечном итоге, легко объединяются в один, что позволяет получить универсальную прошивку, подходящую как для автономной работы, так и для экспериментов.
Для экспериментов нейросеть была обучена на команды длительностью 4 секунды. Испытания показали, что вся предобработка сырых данных, запуск нейроускорителя и получения результатов занимают немного меньше 4 секунд. А это навело на мысль о возможности реализации распознавания в реальном времени. Быстродействия должно было хватить.
Оптимизация
Итак, для работы в реальном времени, по сути, требуется обеспечить выдачу результатов распознавания за время реакции человека. По разным исследованиям, психологический порог восприятия события как условно мгновенного составляет порядка 200 мс. Но нельзя просто нарезать по 200 мс звука и распознавать. Ведь нейросеть всегда принимает на вход данные одного и того же размера. В нашем случае, всегда 4 секунды, преобразованные в матрицу чисел. Значит, единственный вариант, это обновлять небольшие фрагменты аудио записи, сдвигать предыдущие данные во времени и отправлять всегда 4 секунды звука на предобработку и распознавание.
Но, как показала практика, предобработка всего массива данных занимает времени даже больше, чем работа нейроускорителя. Это связано с высокой математической сложностью алгоритма и реализацией вычислений на обычном процессоре. Для подобных вычислений можно было бы применить DSP процессор, если бы он был. Но такой возможности нет, аппаратное умножение чисел в формате float32 на Cortex-M4 ситуацию облегчает не сильно. Хороший вариант — это хранить предыдущие данные не в сыром виде, а в пред-обработанном в формате столбцов матрицы чисел уже после мел-спектрального преобразования. Причем, в этом случае возможная длительность обновляемого интервала кратна шагу окна. От получения мел-спектральных коэффициентов, кстати, пришлось отказаться в пользу быстродействия. Это привело к увеличению размера входа нейросети. Но, при этом, вся предобработка стала занимать меньше времени, чем вычисления на нейроускорителе.
Испытания показали, что при заданном размере входа наиболее оптимальным вариантом является обновление приблизительно 280 мс за шаг. В этом случае около 100 мс уходит на предобработку и получение части столбцов матрицы, а 180 мс занимает запуск нейросети и получение результата. Суммарно это немного выше психологического порога, но все равно оказалось не сильно заметным.

В работе системы, кстати, было замечено несколько любопытных моментов. Несмотря на ощутимое время работы, а следовательно, ожидаемой задержки реакции, быстродействие реального прототипа иногда казалось даже лучше, чем оно есть на самом деле. Задержка в нашем случае, это же время получение достоверного результата работы нейросети. А такой результат может быть получен и не при полном объеме входных данных. Например, какое-то слово, произнесенное в микрофон, будучи поделенным на интервалы в реальном времени, отправляется на распознавание. И, например, оказывается, что в окончании слова не содержится признаков, существенных для его идентификации с хорошей достоверностью. Тогда, последний участок, фактически, не нужен. А в этом случае, пока в микрофон будет произносится этот последний участок, пройдут все необходимые процессы со всем предыдущим массивом данных, и ответ будет получен практически мгновенно. Более того, если в списке присутствует какое-то очень длинное слово или длинная команда, признаки которой наилучшим образом проявляются задолго до окончания, может произойти еще один очень забавный эффект. Результат в системе может появиться еще до того, как слово будет до конца произнесено. То есть, как-бы, заранее. Наблюдение подобных эффектов, кстати, может произвести сильное эмоциональное впечатление на неподготовленную публику. Машина начинает догадываться, что мы говорим, еще не дослушав нас до конца. Жуть!
Заключение
Все описанные механизмы были проверены в реальном мире на прототипе. Одно из применений технологии, кстати, это серия устройств для умного дома. Голосовыми командами можно управлять, например, яркостью света в помещении.
На сегодняшний день в разработке микропрограмм нам доступен весь арсенал цифровой обработки сигналов. И мы совершенно не ограничены работой только с акустическим диапазоном. Ничто не мешает на базе технологии Edge AI разрабатывать системы для любых других временных последовательностей. Данные ультразвука, сейсмограммы, вибродиагностика, радиолокация и еще много чего другого. Все эти сигналы можно попробовать как-то преобразовать, найти или создать подходящую архитектуру нейросети, обучить ее, и разработать на базе всего этого системы искусственного интеллекта нового поколения.
Технологии нам сегодня доступны. Уже скоро мы не будем удивляться, если найдем виртуального ассистента в каждом утюге. Всегда будет, с кем поговорить, а может, даже поспорить. Забавный это будет мир, где тебе может аргументированно возразить собственный чайник. А еще можно вместе с голосовым ассистентом отправиться в далекие путешествия.
Для фантазии и творчества не существует границ!
