
До недавнего времени в Одноклассниках около 50 ТБ данных, обрабатываемых в реальном времени, хранилось в SQL Server. Для такого объема обеспечить быстрый и надежный, да еще и устойчивый к отказу ЦОД доступ, используя SQL СУБД, практически невозможно. Обычно в таких случаях используют одно из NoSQL-хранилищ, но не всё можно перенести в NoSQL: некоторые сущности требуют гарантий ACID-транзакций.
Это подвело нас к использованию NewSQL-хранилища, то есть СУБД, предоставляющей отказоустойчивость, масштабируемость и быстродействие NoSQL-систем, но при этом сохраняющей привычные для классических систем ACID-гарантии. Работающих промышленных систем этого нового класса немного, поэтому мы реализовали такую систему сами и запустили ее в промышленную эксплуатацию.
Как это работает и что получилось — читай под катом.
Сегодня ежемесячная аудитория «Одноклассников» составляет более 70 млн уникальных посетителей. Мы входим в пятерку крупнейших соцсетей мира, и в двадцатку сайтов, на которых пользователи проводят больше всего времени. Инфраструктура «ОК» обрабатывает очень высокие нагрузки: более миллиона HTTP-запросов/сек на фронты. Части парка серверов в количестве более 8000 штук расположены близко друг от друга — в четырех московских дата-центрах, что позволяет обеспечивать сетевую задержку менее 1 мс между ними.
Мы используем Cassandra с 2010 года, начиная с версии 0.6. Сегодня в эксплуатации несколько десятков кластеров. Самый быстрый кластер обрабатывает более 4 млн операций в секунду, а крупнейший хранит 260 Тб.
Однако всё это обычные NoSQL-кластеры, использующиеся для хранения слабо согласованных данных. Нам же хотелось заменить основное консистентное хранилище, Microsoft SQL Server, которое использовалось с момента основания «Одноклассников». Хранилище состояло из более чем 300 SQL Server Standard Edition машин, на которых содержалось 50 Тб данных — бизнес-сущностей. Эти данные модифицируются в рамках ACID-транзакций и требуют высокой согласованности.
Для распределения данных по нодам SQL Server мы использовали как вертикальное, так и горизонтальное партиционирование (шардирование). Исторически мы использовали простую схему шардирования данных: каждой сущности сопоставлялся токен — функция от ID сущности. Сущности с одинаковым токеном помещались на один SQL-сервер. Отношение типа master-detail реализовывалось так, чтобы токены основной и порожденной записи всегда совпадали и находились на одном сервере. В социальной сети почти все записи порождаются от имени пользователя — значит, все данные пользователя в пределах одной функциональной подсистемы хранятся на одном сервере. То есть в бизнес-транзакции почти всегда участвовали таблицы одного SQL-сервера, что позволяло обеспечивать согласованность данных с помощью локальных ACID-транзакций, без необходимости использования медленных и ненадежных распределенных ACID-транзакций.
Благодаря шардингу и для ускорения работы SQL:
- Не используем Foreign key constraints, так как при шардировании ID сущности может находиться на другом сервере.
- Не используем хранимые процедуры и триггеры из-за дополнительной нагрузки на ЦПУ СУБД.
- Не используем JOINs из-за всего вышеперечисленного и множества случайных чтений с диска.
- Вне транзакции для уменьшения взаимоблокировок используем уровень изоляции Read Uncommitted.
- Выполняем только короткие транзакции (в среднем короче 100 мс).
- Не используем многорядные UPDATE и DELETE из-за большого количества взаимоблокировок — обновляем только по одной записи.
- Запросы всегда выполняем только по индексам — запрос с планом полного просмотра таблицы для нас означает перегрузку БД и ее отказ.
Эти шаги позволили выжать из SQL-серверов почти максимум производительности. Однако проблем становилось всё больше и больше. Давайте их рассмотрим.
Проблемы с SQL
- Поскольку мы использовали самописный шардинг, добавление новых шардов выполнялось администраторами вручную. Всё это время масштабируемые реплики данных не обслуживали запросы.
- По мере роста количества записей в таблице снижается скорость вставки и модификации, при добавлении индексов к существующей таблице скорость падает кратно, создание и пересоздание индексов идёт с даунтаймом.
- Наличие в production небольшого количества Windows для SQL Server затрудняет управление инфраструктурой
Но главная проблема —
Отказоустойчивость
У классического SQL-сервера плохая отказоустойчивость. Допустим, у вас всего один сервер базы данных, и он отказывает раз в три года. В это время сайт не работает 20 минут, это приемлемо. Если у вас 64 сервера, то сайт не работает уже раз в три недели. А если у вас 200 серверов, то сайт не работает каждую неделю. Это проблема.
Что можно сделать для повышения отказоустойчивости SQL-сервера? Википедия предлагает нам построить высокодоступный кластер: где в случае отказа любого из компонентов есть дублирующий.
Это требует парка дорогостоящего оборудования: многочисленное дублирование, оптоволокно, хранилища общего доступа, да и включение резерва работает ненадежно: около 10% включений заканчиваются отказом резервной ноды паровозиком за основной нодой.
Но главный недостаток такого высокодоступного кластера — нулевая доступность при отказе дата-центра, в котором он стоит. У «Одноклассников» четыре дата-центра, и нам необходимо обеспечивать работу при полной аварии в одном из них.
Для этого можно было бы применить Multi-Master репликацию, встроенную в SQL Server. Это решение сильно дороже за счет стоимости софта и страдает от хорошо известных проблем с репликацией — непредсказуемых задержек транзакций при синхронной репликации и задержек в применении репликаций (и, как следствие, потерянных модификаций) при асинхронной. Подразумевающееся же ручное разрешение конфликтов делает этот вариант полностью неприменимым для нас.
Все эти проблемы требовали кардинального решения и мы приступили к их детальному анализу. Здесь нам нужно познакомиться с тем, что в основном делает SQL Server — транзакциями.
Простая транзакция
Рассмотрим простейшую, с точки зрения прикладного SQL-программиста, транзакцию: добавление фотографии в альбом. Альбомы и фотографии хранятся в разных табличках. У альбома есть счетчик публичных фотографий. Тогда такая транзакция разбивается на следующие шаги:
- Блокируем альбом по ключу.
- Создаем запись в таблице фотографий.
- Если у фотографии публичный статус, то накручиваем в альбоме счетчик публичных фотографий, обновляем запись и коммитим транзакцию.
Или в виде псевдокода:
TX.start("Albums", id);
Album album = albums.lock(id);
Photo photo = photos.create(…);
if (photo.status == PUBLIC ) {
album.incPublicPhotosCount();
}
album.update();
TX.commit();Мы видим, что самый распространённый сценарий бизнес транзакции — прочитать данные из БД в память сервера приложений, что-то изменить и сохранить новые значения обратно в БД. Обычно в такой транзакции мы обновляем несколько сущностей, несколько таблиц.
При выполнении транзакции может произойти конкурентное модифицирование тех же самых данных из другой системы. Например, Антиспам может решить, что пользователь какой-то подозрительный и поэтому все фотографии у пользователя более не должны быть публичными, их нужно отправить на модерацию, а значит поменять photo.status на какое-то другое значение и открутить соответствующие счетчики. Очевидно, что если данная операция будет происходить без гарантий атомарности применения и изоляции конкурирующих модификаций, как в ACID, то результат будет не тем, что необходимо — или счетчик фото будет показывать неправильное значение, или не все фото отправятся на модерацию.
Подобного кода, манипулирующего с различными бизнес-сущностями в рамках одной транзакции, за всё время существования Одноклассников написано очень много. По опыту же миграций на NoSQL с Eventual Consistency мы знаем, что самые большие сложности (и временные затраты) вызывает необходимость разрабатывать код, направленный на поддержание согласованности данных. Поэтому главным требованием к новому хранилищу мы считали обеспечение для прикладной логики настоящих ACID-транзакций.
Другими, не менее важными, требованиями были:
- При отказе дата-центра должны быть доступны и чтение, и запись в новое хранилище.
- Сохранение текущей скорости разработки. То есть при работе с новым хранилищем количество кода должно быть приблизительно тем же самым, не должно появляться необходимости дописывать что-то в хранилище, разрабатывать алгоритмы разрешения конфликтов, поддержания вторичных индексов и т.п.
- Скорость работы нового хранилища должна быть достаточно высокой, как при чтении данных, так и при обработке транзакций, что эффективно означало неприменимость академически строгих, универсальных, но медленных решений, как, например, двухфазных коммитов.
- Автоматическое масштабирование на лету.
- Использование обычных дешёвых серверов, без необходимости покупки экзотических железяк.
- Возможность развития хранилища силами разработчиков компании. Иными словами, приоритет отдавался своим или основанным на открытом коде решениям, желательно на Java.
Решения, решения
Анализируя возможные решения, мы пришли к двум возможным выборам архитектуры:
Первый — взять любой SQL-сервер и реализовать нужную отказоустойчивость, механизм масштабирования, отказоустойчивый кластер, разрешение конфликтов и распределенные, надежные и быстрые ACID-транзакции. Мы оценили этот вариант как весьма нетривиальный и трудоемкий.
Второй вариант — взять готовое NoSQL-хранилище с реализованным масштабированием, отказоустойчивым кластером, разрешением конфликтов и реализовать транзакции и SQL самим. На первый взгляд даже задача реализации SQL, не говоря уж об ACID транзакциях, выглядит задачкой на года. Но потом мы поняли, что набор возможностей SQL, который мы используем на практике, далек от ANSI SQL так же далеко, как Cassandra CQL далек от ANSI SQL. Приглядевшись еще повнимательнее к CQL, мы поняли, что он достаточно близок к тому, что нам нужно.
Cassandra и CQL
Итак, чем же интересна Cassandra, какими возможностями она обладает?
Во-первых, здесь можно создавать таблицы с поддержкой различных типов данных, можно делать SELECT или UPDATE по первичному ключу.
CREATE TABLE photos (id bigint KEY, owner bigint,…);
SELECT * FROM photos WHERE id=?;
UPDATE photos SET … WHERE id=?;Для обеспечения согласованности данных реплик, Cassandra использует кворумный подход. В простейшем случае это означает, что при размещении трех реплик одного и того же ряда на разных нодах кластера, запись считается успешной, если большинство нод (т.е две из трех) подтвердили успешность этой операции записи. Данные ряда считаются согласованными, если при чтении большинство нод были опрошены и подтвердили их. Таким образом, при наличии трёх реплик гарантируется полная и мгновенная согласованность данных при отказе одной ноды. Такой подход позволил нам реализовать еще более надёжную схему: всегда отправлять запросы на все три реплики, дожидаясь ответа от двух самых быстрых. Запоздавший ответ третьей реплики в таком случае отбрасывается. У запоздавшей с ответом ноды при этом могут быть серьезные проблемы — тормоза, сборка мусора в JVM, direct memory reclaim в linux kernel, сбой железа, отключение от сети. Однако на операции клиента и на данные это никак не влияет.
Подход, когда мы обращаемся к трём нодам, а получаем ответ от двух, называется спекуляцией: запрос на лишние реплики отправляется еще до того, как «отвалиться».
Ещё одним из преимуществ Cassandra является Batchlog — механизм, гарантирующий либо полное применение, либо полное неприменение пакета вносимых вами изменений. Это позволяет нам решить A в ACID — атомарность из коробки.
Самое близкое к транзакциям в Cassandra — это так называемые "lightweight transactions". Но от «настоящих» ACID-транзакций они далеки: на самом деле, это возможность сделать CAS на данных только одной записи, используя консенсус по тяжеловесному протоколу Paxos. Поэтому скорость таких транзакций невелика.
Чего нам не хватило в Cassandra
Итак, нам предстояло реализовать в Cassandra настоящие ACID-транзакции. С использованием которых мы могли бы легко реализовать две других удобных возможности классических DBMS: консистентные быстрые индексы, что позволило бы нам выполнять выборки данных не только по первичному ключу и обычный генератор монотонных автоинкрементных ID.
C*One
Так родилась новая СУБД C*One, состоящая из трех типов серверных нод:
- Хранилища — (почти) стандартные серверы Cassandra, отвечающие за хранение данных на локальных дисках. По мере роста нагрузки и объема данных их количество можно легко масштабировать до десятков и сотен.
- Координаторы транзакций — обеспечивают исполнение транзакций.
- Клиенты — серверы приложений, реализующие бизнес-операции и инициирующие транзакции. Таких клиентов могут быть тысячи.
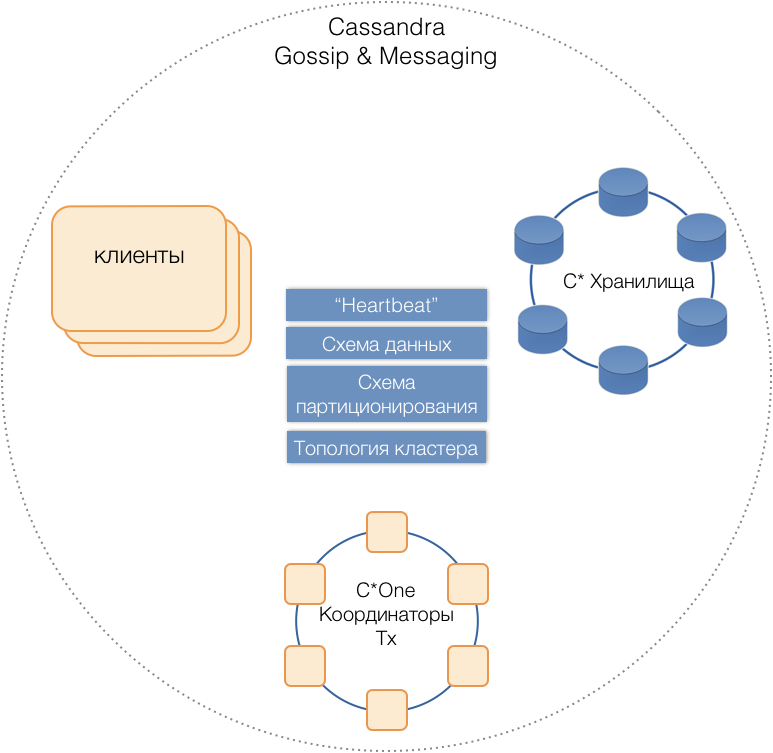
Серверы всех типов состоят в общем кластере, используют внутренний протокол сообщений Cassandra для общения друг с другом и gossip для обмена кластерной информацией. С помощью Heartbeat серверы узнают о взаимных отказах, поддерживают единую схему данных — таблицы, их структуру и репликацию; схему партиционирования, топологию кластера, и т.п.
Клиенты
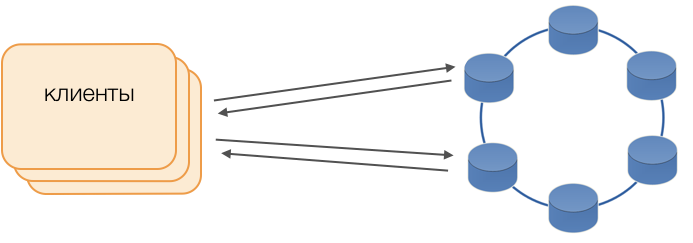
Вместо стандартных драйверов используется режим Fat Сlient. Такая нода не хранит данных, но может выступать в роли координатора исполнения запросов, то есть Клиент сам выполняет функцию координатора своих запросов: опрашивает реплики хранилища и разрешает конфликты. Это не только надежнее и быстрее стандартного драйвера, требующего коммуникации с удаленным координатором, но и позволяет управлять передачей запросов. Вне открытой на клиенте транзакции запросы направляются в хранилища. Если же клиент открыл транзакцию, то все запросы в рамках транзакции направляются в координатор транзакций.
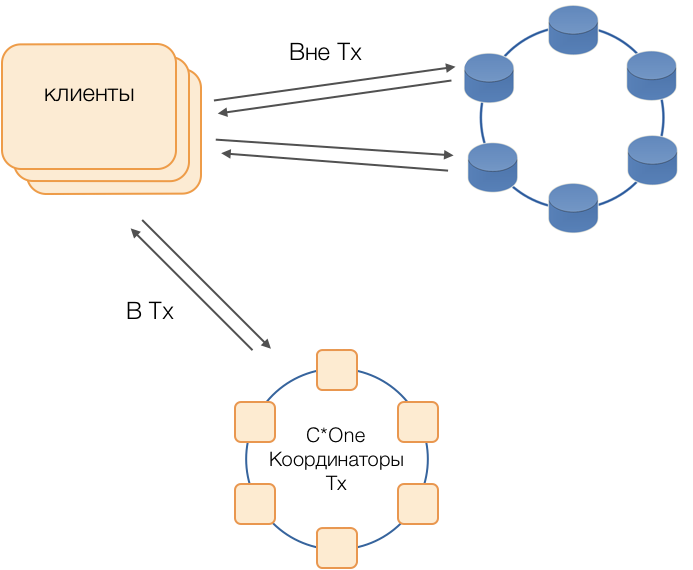
Координатор транзакций C*One
Координатор — то, что мы реализовали для C*One с нуля. Он отвечает за управление транзакциями, блокировками и порядком применения транзакций.
Для каждой обслуживаемой транзакции координатор генерирует временную метку: каждая последующая больше, чем у предыдущей транзакции. Поскольку в Cassandra система разрешения конфликтов основана на временных метках (из двух конфликтных записей актуальной считается с позднейшей временной меткой), то конфликт будет всегда разрешен в пользу последующей транзакции. Таким образом мы реализовали часы Лэмпорта — дешевый способ разрешения конфликтов в распределенной системе.
Блокировки
Для обеспечения изоляции мы решили использовать самый простой способ — пессимистичные блокировки по первичному ключу записи. Другими словами, в транзакции запись необходимо сначала заблокировать, только затем прочитать, модифицировать и сохранить. Только после успешного коммита запись может быть разблокирована, чтобы конкурирующие транзакции могли ее использовать.
Реализация такой блокировки проста в нераспределенной среде. В распределенной системе есть два основных пути: либо реализовать распределенную блокировку на кластере, или распределить транзакции так, чтобы транзакции с участием одной записи всегда обслуживались одним и тем же координатором.
Поскольку в нашем случае данные уже распределены по группам локальных транзакций в SQL, было решено закрепить за координаторами группы локальных транзакций: один координатор выполняет все транзакции с токеном от 0 до 9, второй — с токеном от 10 до 19, и так далее. В результате каждый из экземпляров координатора становится мастером группы транзакций.
Тогда блокировки могут быть реализованы в виде банального HashMap в памяти координатора.
Отказы координаторов
Поскольку один координатор исключительно обслуживает группу транзакций, очень важно быстро определить факт его отказа, чтобы повторная попытка исполнения транзакции уложилась в таймаут. Чтобы это было быстро и надежно, мы применили полносвязный кворумный hearbeat протокол:
В каждом дата-центре размещается минимум по две ноды координатора. Периодически каждый координатор рассылает heartbeat-сообщение остальным координаторам и сообщает им о своём функционировании, а также о том, heartbeat-сообщения от каких координаторов в кластере он получал в последний раз.

Получая аналогичную информацию от остальных в составе их heartbeat-сообщений, каждый координатор решает для себя, какие ноды кластера функционируют, а какие нет, руководствуясь принципом кворума: если нода Х получила от большинства нод в кластере информацию о нормальном получении сообщений с ноды Y, значит, Y работает. И наоборот, как только большинство сообщит о пропаже сообщений с ноды Y, значит, Y отказал. Любопытно, что если кворум сообщит ноде Х, что не получает от нее более сообщений, значит сама нода X будет считать себя отказавшей.
Heartbeat-сообщения рассылаются с большой частотой, около 20 раз в сек, с периодом 50 мс. В Java сложно гарантировать отклик приложения в течение 50 мс из-за сравнимой продолжительности пауз, вызванных сборщиком мусора. Нам удалось добиться такого времени отклика с использованием сборщика мусора G1, позволяющего указать цель по продолжительности пауз GC. Однако, иногда, достаточно редко, паузы сборщика выходят за рамки 50 мс, что может привести к ложному обнаружению отказа. Чтобы такого не было, координатор не сообщает об отказе удаленной ноды при пропаже первого же heartbeat-сообщения от нее, только если пропало несколько подряд.Так нам удалось добиться обнаружения отказа ноды координатора за 200 мс.
Но мало быстро понять, какая нода перестала функционировать. Нужно что-то с этим делать.
Резервирование
Классическая схема предполагает в случае отказа мастера запускать выборы нового с помощью одного из модных универсальных алгоритмов. Однако, у подобных алгоритмов есть хорошо известные проблемы со сходимостью во времени и длительностью самого процесса выборов. Подобных дополнительных задержек нам удалось избежать с помощью схемы замещения координаторов в полносвязной сети:
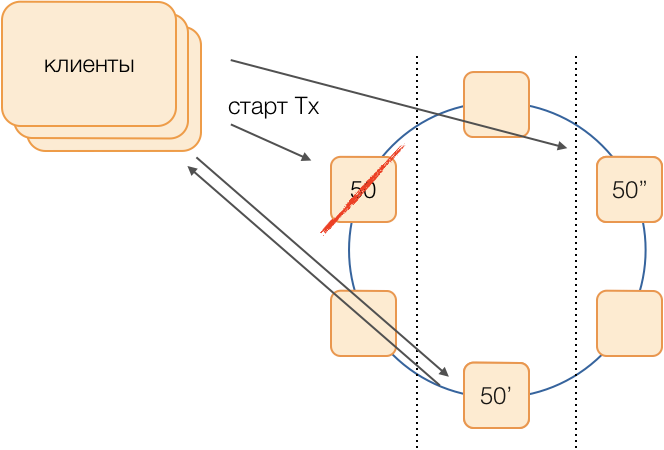
Допустим, мы хотим выполнить транзакцию в группе 50. Заранее определим схему замещения, то есть какие ноды будут исполнять транзакции 50 группы в случае отказа основного координатора. Наша цель — сохранить работоспособность системы при отказе дата-центра. Определим, что первым резервом будет нода из другого дата-центра, а вторым резервом — нода из третьего. Эта схема выбирается один раз и не меняется до тех пор, пока не поменяется топология кластера, то есть пока в него не войдут новые ноды (что случается очень редко). Порядок выбора нового активного мастера при отказе старого будет всегда таким: активным мастером станет первый резерв, а если и он перестал функционировать — второй резерв.
Такая схема надёжнее универсального алгоритма, так как для активации нового мастера достаточно определения факта отказа старого.
Но как клиенты поймут, какой из мастеров сейчас работает? За 50 мс невозможно разослать информацию на тысячи клиентов. Возможна ситуация, когда клиент отправляет запрос на открытие транзакции, ещё не зная, что этот мастер уже не функционирует, и запрос зависнет на таймауте. Чтобы этого не случилось, клиенты спекулятивно посылают запрос на открытие транзакции сразу мастеру группы и обоим его резервам, но ответит на этот запрос только тот, кто является активным мастером в данный момент. Всю последующую коммуникацию в рамках транзакции клиент будет производить только с активным мастером.
Резервные мастеры полученные запросы на не свои транзакции помещают в очередь нерожденных транзакций, где они хранятся некоторое время. Если активный мастер умирает, то новый мастер отрабатывает запросы на открытие транзакций из своей очереди и отвечает клиенту. Если клиент уже успел открыть транзакцию со старым мастером, то второй ответ игнорируется (и, очевидно, такая транзакция не завершится и будет повторена клиентом).
Как работает транзакция
Допустим, клиент прислал координатору запрос на открытие транзакции для такой-то сущности с таким-то первичным ключом. Координатор эту сущность блокирует и помещает в таблицу блокировок в памяти. Если необходимо, координатор считывает эту сущность из хранилища и сохраняет полученные данные в состояние транзакции в памяти координатора.
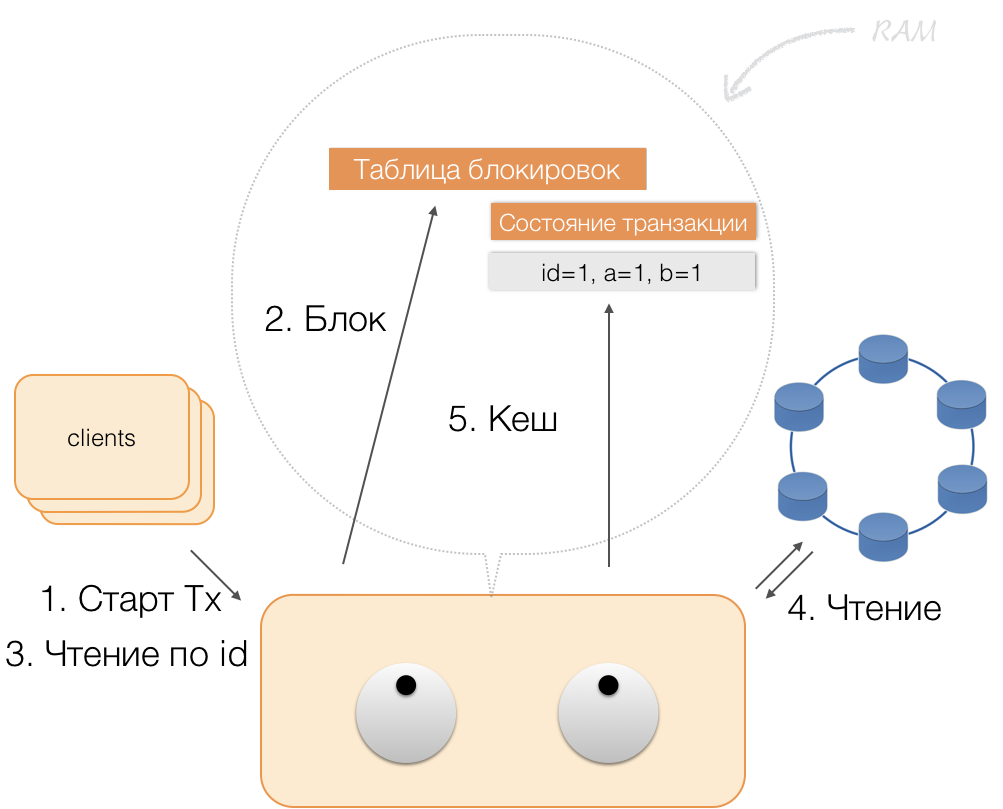
Когда клиент хочет изменить данные в транзакции, то присылает координатору запрос на модификацию сущности, а тот помещает новые данные в таблицу состояния транзакций в памяти. На этом запись завершена — запись в хранилище не производится.
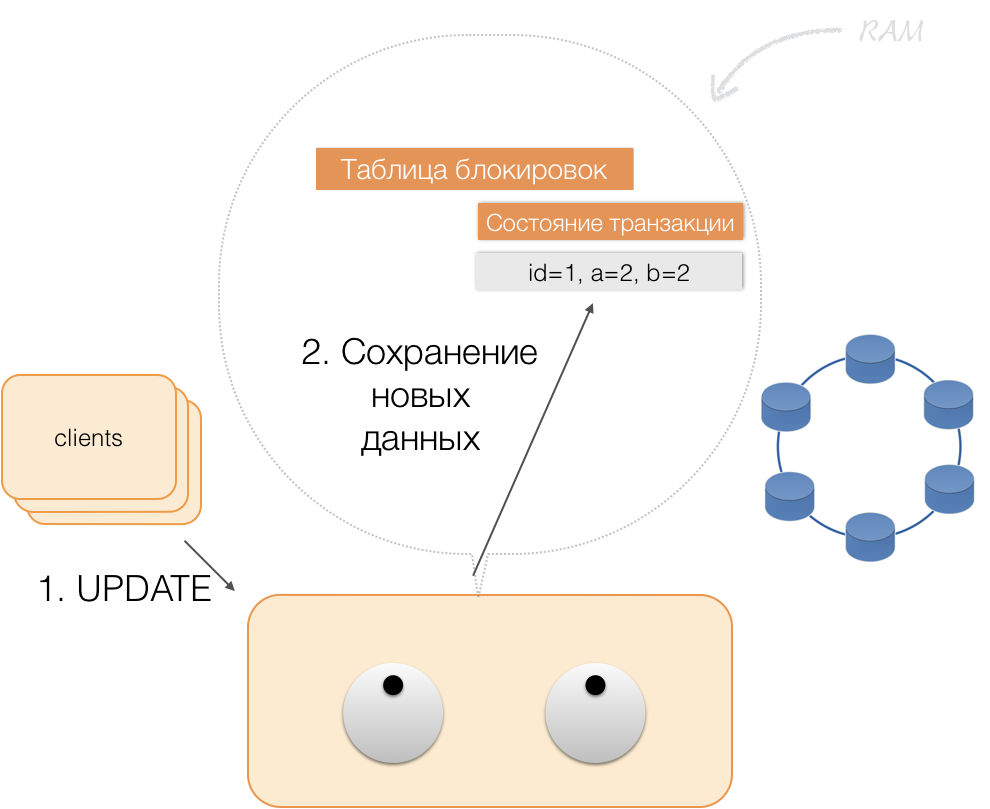
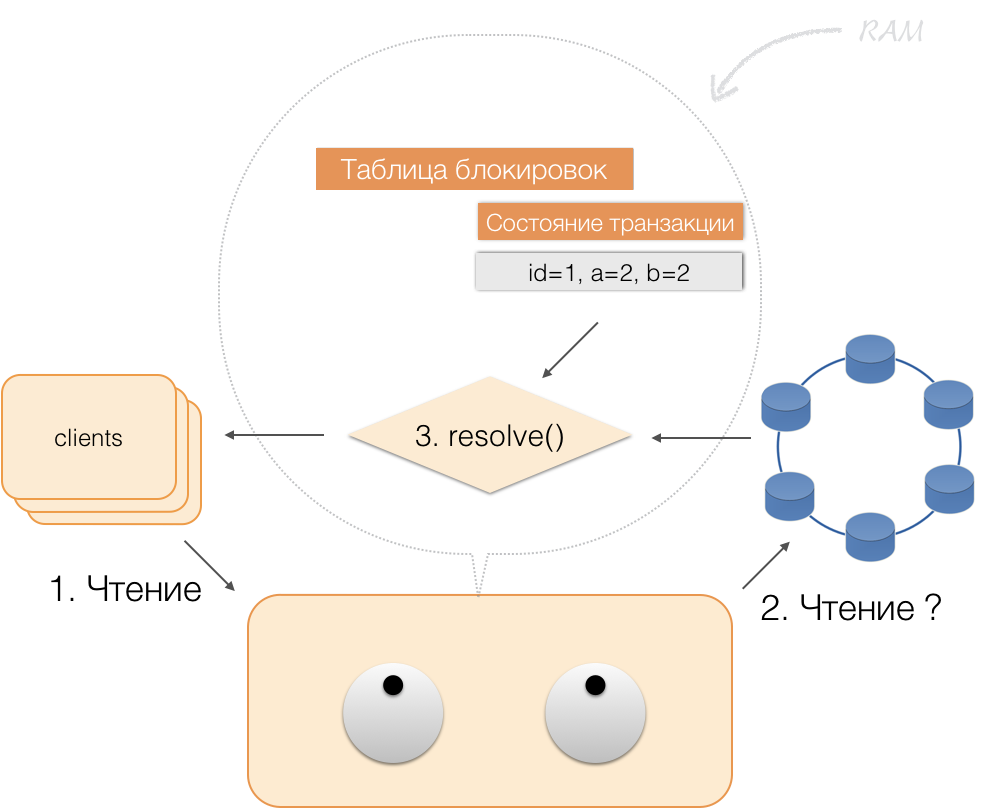
Когда клиент запрашивает в рамках активной транзакции собственные измененные данные, то координатор действует так:
- если ID уже есть в транзакции, то данные берутся из памяти;
- если ID в памяти нет, то недостающие данные считываются из нод-хранилищ, объединяются с уже имеющимися в памяти, и результат отдается клиенту.
Таким образом, клиент может прочитать собственные изменения, а другие клиенты эти изменения не видят, потому что хранятся они только в памяти координатора, в нодах Cassandra их еще нет.
Когда клиент присылает commit, состояние, имевшееся в памяти у сервиса, сохраняется координатором в logged batch, и уже в виде logged batch отправляется в хранилища Cassandra. Хранилища делают всё необходимое, чтобы этот пакет был атомарно (полностью) применен, и возвращают ответ координатору, а тот освобождает блокировки и подтверждает успешность транзакции клиенту.
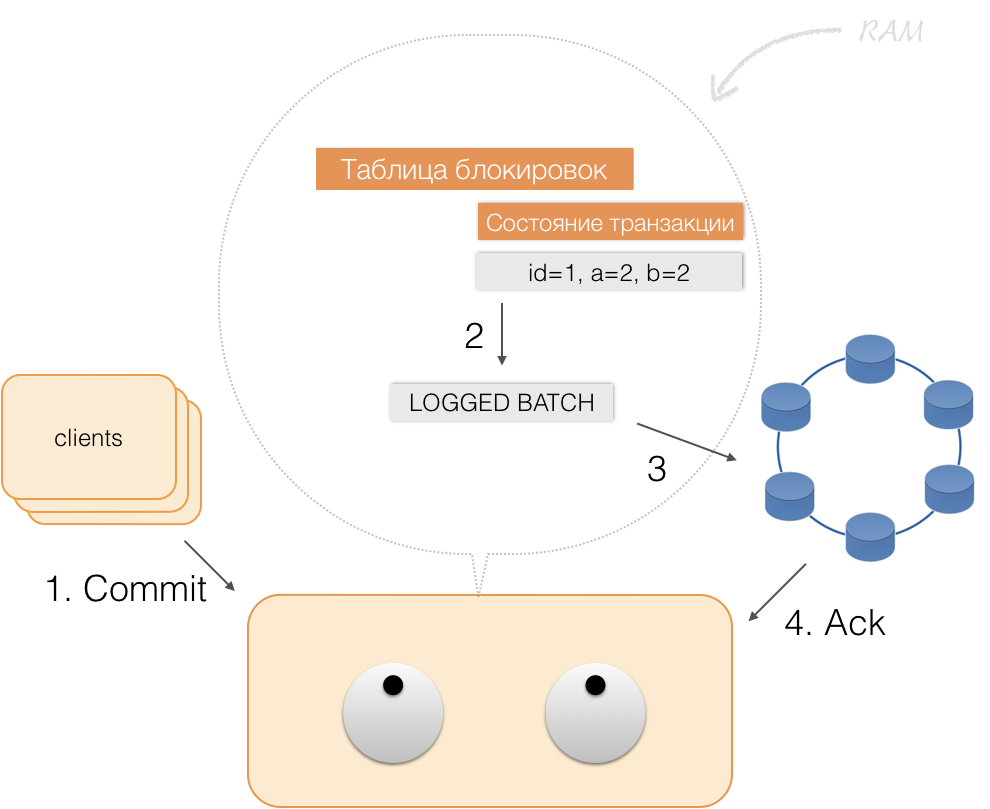
А для отката координатору достаточно лишь освободить память, занятую состоянием транзакции.
В результате вышеописанных доработок мы реализовали принципы ACID:
- Атомарность. Это гарантия того, что никакая транзакция не будет зафиксирована в системе частично, будут либо выполнены все её подоперации, либо не выполнено ни одной. У нас этот принцип соблюдается за счёт logged batch в Cassandra.
- Согласованность. Каждая успешная транзакция по определению фиксирует только допустимые результаты. Если после открытия транзакции и выполнения части операций обнаруживается, что результат недопустим, выполняется откат.
- Изолированность. При выполнении транзакции параллельные транзакции не должны влиять на её результат. Конкурирующие транзакции изолированы с помощью пессимистических блокировок на координаторе. Для чтений вне транзакции соблюдается принцип изолированности на уровне Read Committed.
- Устойчивость. Независимо от проблем на нижних уровнях — обесточивание системы, сбой в оборудовании, — изменения, сделанные успешно завершённой транзакцией, должны остаться сохраненными после возобновления функционирования.
Чтение по индексам
Возьмём простую таблицу:
CREATE TABLE photos (
id bigint primary key,
owner bigint,
modified timestamp,
…)У нее есть ID (первичный ключ), владелец и дата изменения. Нужно сделать очень простой запрос — выбрать данные по владельцу с датой изменения «за последние сутки».
SELECT *
WHERE owner=?
AND modified>?Чтобы подобный запрос отрабатывал быстро, в классической SQL СУБД надо построить индекс по колонкам (owner, modified). Подобное мы можем сделать достаточно просто, так как теперь у нас есть гарантии ACID!
Индексы в C*One
Есть исходная таблица c фотографиями, в которой ID записи является первичным ключом.

Для индекса C*One создает новую таблицу, которая является копией исходной. Ключ совпадает с индексным выражением, при этом в него входит еще и первичный ключ записи из исходной таблицы:

Теперь запрос по «владельцу за последние сутки» можно переписать как select из другой таблицы:
SELECT * FROM i1_test
WHERE owner=?
AND modified>?Согласованность данных исходной таблицы photos и индексной i1 поддерживается координатором автоматически. На основании одной только схемы данных при получении изменения координатор генерирует и запоминает изменение не только основной таблицы, но и изменения копий. Никаких дополнительных действий с таблицей индекса не выполняется, логи не считываются, блокировки не используются. То есть добавление индексов почти не потребляет ресурсы и практически не влияет на скорость применения модификаций.
C помощью ACID нам удалось реализовать индексы «как в SQL». Они обладают согласованностью, могут масштабироваться, быстро работают, могут быть составными и встроены в язык запросов CQL. Для поддержки индексов не нужно вносить изменения в прикладной код. Всё просто, как в SQL. И что самое важное, индексы не влияют на скорость исполнения модификаций исходной таблицы транзакций.
Что получилось
Мы разработали C*One три года назад и запустили в промышленную эксплуатацию.
Что же мы получили в итоге? Давайте оценим это на примере подсистемы обработки и хранения фотографий, одного из важнейших типов данных в социальной сети. Речь не о самих телах фотографий, а о всевозможной метаинформации. Сейчас в «Одноклассниках» около 20 млрд таких записей, система обрабатывает 80 тыс. запросов на чтение в секунду, до 8 тыс. ACID-транзакций в секунду, связанных с модификацией данных.
Когда мы использовали SQL с replication factor = 1 (но в RAID 10), метаинформация фотографий хранилась на высокодоступном кластере из 32 машин с Microsoft SQL Server (плюс 11 резервных). Также было выделено 10 серверов для хранения бэкапов. Итого 50 дорогостоящих машин. При этом система работала на номинальной нагрузке, без запаса.
После мигрирования на новую систему мы получили replication factor = 3 — по копии в каждом дата-центре. Система состоит из 63 нод хранилища Cassandra и 6 машин координаторов, итого 69 серверов. Но эти машины значительно дешевле, их общая стоимость составляет около 30 % стоимости системы на SQL. При этом нагрузка держится на уровне 30 %.
С внедрением C*One снизились и задержки: в SQL операция записи занимала около 4,5 мс. В C*One — около 1,6 мс. Длительность транзакции в среднем меньше 40 мс, коммит выполняется за 2 мс, длительность чтения и записи — в среднем 2 мс. 99-й перцентиль — всего 3-3,1 мс, количество таймаутов снизилось в 100 раз — всё за счет широкого применения спекуляций.
К текущему моменту из эксплуатации выведена большая часть нод SQL Server, новые продукты разрабатываются только c использованием C*One. Мы адаптировали C*One для работы в нашем облаке one-cloud, что позволило ускорить развертывание новых кластеров, упростить конфигурацию и автоматизировать эксплуатацию. Без исходного кода это сделать было бы значительно сложнее и костыльнее.
Сейчас мы работаем над переводом других наших хранилищ в облако — но это уже совсем другая история.
