
Вас когда-нибудь будили по алерту в 2 часа ночи, и вы бежали поднимать упавший сервер, полчаса дебажили, подняли, а потом выяснялось, что это был не тот сервер? Потому что тот, который нужно, стоял рядом, а вы подняли старый, который выключили специально, и всё окончательно сломали…Или вы послали инженера в ДЦ переткнуть патчкорд, диск поменять... А он смотрел не в ту табличку и менял не тот диск? Или ваш сетевой инженер ошибался IP-адресом и обнулял не ту стойку? Или вообще выключал не тот ДЦ?
Все эти случаи, помимо чисто человеческого фактора, происходят, когда вокруг нас либо недостаточно правды, либо слишком много информации. У нас есть Вики, Git, эксельки, блокнот, а еще инженер Вася, который знает то, чего не знает никто другой. Чтобы избавиться от этой боли, расскажу, как навести порядок в описании инфраструктуры и создать свой Источник Правды (Source of Truth), достоверный и актуальный.

В ECOMMPAY я слежу за тем, чтобы купить что-нибудь нужное, привезти это в правильное место, правильно установить и подключить. (В процессе ещё неплохо бы заплатить поставщику, но тут возможны варианты). Ещё помогаю коллегам отвечать на вопросы, что где лежит, и когда все это кончится. Можно сказать, что моя самая главная задача — знать всё и обо всём.
Что такое ECOMMPAY? Мы делаем так, чтобы платить за товары и услуги в Интернете было удобно, быстро и безопасно. У нас сотни IT-специалистов: разработка и эксплуатация, аналитики, QA, и платформа собственной разработки. Пять ДЦ по всему миру, «четыре девятки» SLA перед нашими заказчиками и совершенно неприличная стоимость минуты простоя.
Мне не просто надо знать всё и обо всём. Информация должна быть актуальной и достоверной, иначе от нее не будет никакого толку. С данными должно быть легко и просто работать, иначе коллеги начнут плодить те самые записки в блокноте, эксельки, гугл-доки и прочие тайные знания. Удобство снизится, время на поиск нужной информации — наоборот. Кому охота просидеть все выходные за отчётом, который, как обычно, нужен «ещё вчера»?
Давайте посмотрим, что мешает нам в поиске Правды.
Устаревшая документация
Она же «документация Шрёдингера». Может устареть примерно сразу после написания, и пока вы не начнёте сверять её с действительностью, не сможете понять, насколько она актуальна. Обновлялись данные или нет, и если нет, то почему? Может быть, все так стабильно работало, что за год ничего не изменилось. А может быть у вас не дошли руки внести правки в документацию. В любом случае доверять ей, к сожалению, нельзя (точнее, можно, но очень избирательно и аккуратно).
Автоматические discovery
Их очень любят программисты и админы. У вас есть какой-нибудь Zabbix или Prometheus, в него автоматически заезжают триггеры, метрики, появляются новые items — все круто, но возникает слишком много информационного шума. Например, в вашем Zabbix’е появился новый триггер, а вы не знаете, этот триггер появился легитимно или что-то случилось и пошло не так?
Разные источники информации с разной степенью доверия
Часть информации лежит в вашей вики-системе, часть — в Git, а ещё что-нибудь только в голове у админа Васи. Одно и тоже описано в разных местах с разной степенью актуальности и достоверности.
Всё это снижает видимость и уменьшает количество правды вокруг нас. Мы не знаем, чему можно верить, а чему — нет.
Источник Правды
Чтобы избежать всех этих проблем, я использую концепцию Источника Правды. Это место, где мы храним достоверные сведения о том, как должна выглядеть наша система.
Ключевое качество источника — достоверность. Когда вы к нему обращаетесь, то априори должны быть уверены, что данные в нем правильные. Второе качество, тоже немаловажное — в источнике описывается, как должна выглядеть система, а не как она выглядит на самом деле. Позже объясню, почему.
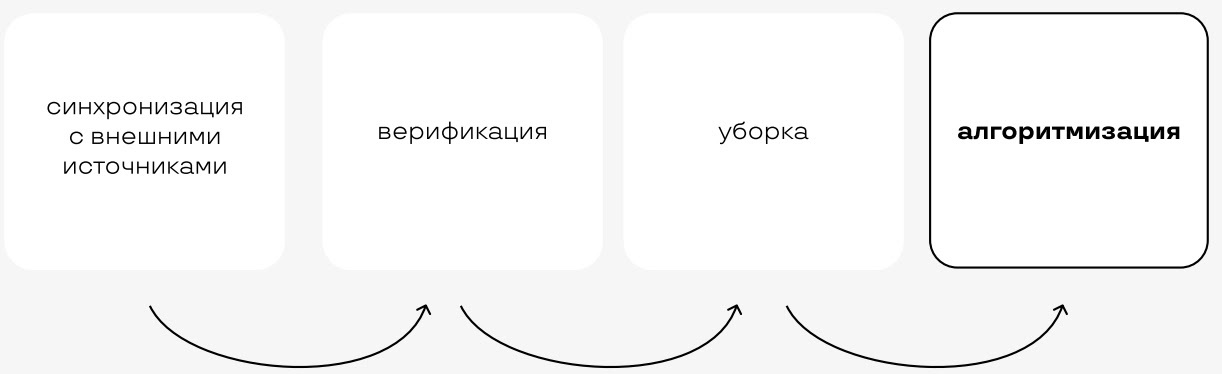
Перед тем, как начать работать с Источником Правды, стоит настроить синхронизацию данных с внешним миром, например, с хостинг-провайдером или с DNS-провайдером. Нам нужно получать информацию о том, за что мы платим и как «выглядим» снаружи. Поэтому сверяем то, что нашли, с тем, что у нас есть.
В случае хостинга, если серверов или виртуалок много, на этом шаге можно совершить какое-нибудь интересное открытие в виде пары (или пары десятков) серверов, которые давно уже никому не нужны, и про которые все забыли (кроме вашего хостинг-провайдера, разумеется).
Потом делаем уборку. Проходим по нашей системе и «наводим порядок». Например, пишем плейбуки, чтобы все сервера настраивались по шаблону, и причесываем description на портах сетевого оборудования. Избавляемся (ок, стараемся избавиться) от «уникальных решений предков», которые никак не документированы.
После уборки вы можете увидеть, что некоторые вещи можно алгоритмизировать и не запоминать. Например, генерировать по ID дата-центра IP-адреса для него, автономную систему и еще много чего. Алгоритмизация поможет не складировать в Источнике Правды информацию, которую там можно не хранить, а значит, не заботиться о ее достоверности и актуальности.
Знание закономерностей заменяет знание многих фактов.
Не источник Правды
Что не является Источником Правды? Нельзя доверять «живым» конфигам на оборудовании. Они не могут быть Источником Правды потому, что мы не знаем, почему этот конфиг выглядит именно так. Потому, что так правильно или потому, что тот самый админ Вася последний раз накостылил решение, поднял его и забыл.
Не стоит путать источник правды и AssetDB, ведь с точки зрения эксплуатации нам не нужна информация об оборудовании, которое лежит на складе. Зато этот список будет очень интересен, например, вашей бухгалтерии, потому что по нему она формирует перечень основных средств.
CMDB тоже не годится на роль Источника Правды. Для ITIL/ITSM это основная система хранения информации обо всех сущностях в организации, которыми управляет IT. Но я ни разу не видел, чтобы CMDB была наполнена актуальными данными. Там много лишней информации с точки зрения эксплуатации, и не всегда есть то, что нужно. Попытка впихнуть все данные обо всем в один источник, делает работу с CMDB неудобной.
А ещё, как правило, за все эти системы, если они есть, отвечают разные люди.
Пример (всё ещё не Источник Правды)
Например, у вас есть флот в 2-3 сотни серверов. И когда месячный счет от провайдера за их аренду составляет шестизначную сумму в валюте, бизнес спрашивает: «А а за что мы платим?»
Мы ж программисты, поэтому пишем скрипт, который получает данные от провайдера и загружает в базу. Потом пишем вокруг этой базы некоторую обвязку: интерфейс, логику, систему агентов для наших серверов и виртуальных машин, чтобы получать с них актуальную информацию. Раскатываем везде и начинаем получать информацию об IP-адресах, ОС, ЦПУ, памяти и обо всем, что можем собрать. Складываем это в ту же базу, удивляемся и выкидываем пачку ненужных серверов, на которые 2 года никто не заходил (их просто забыли сдать). Экономим кучу денег и отчитываемся перед бизнесом, заодно наведя порядок в том, что мы считаем Источником Правды.
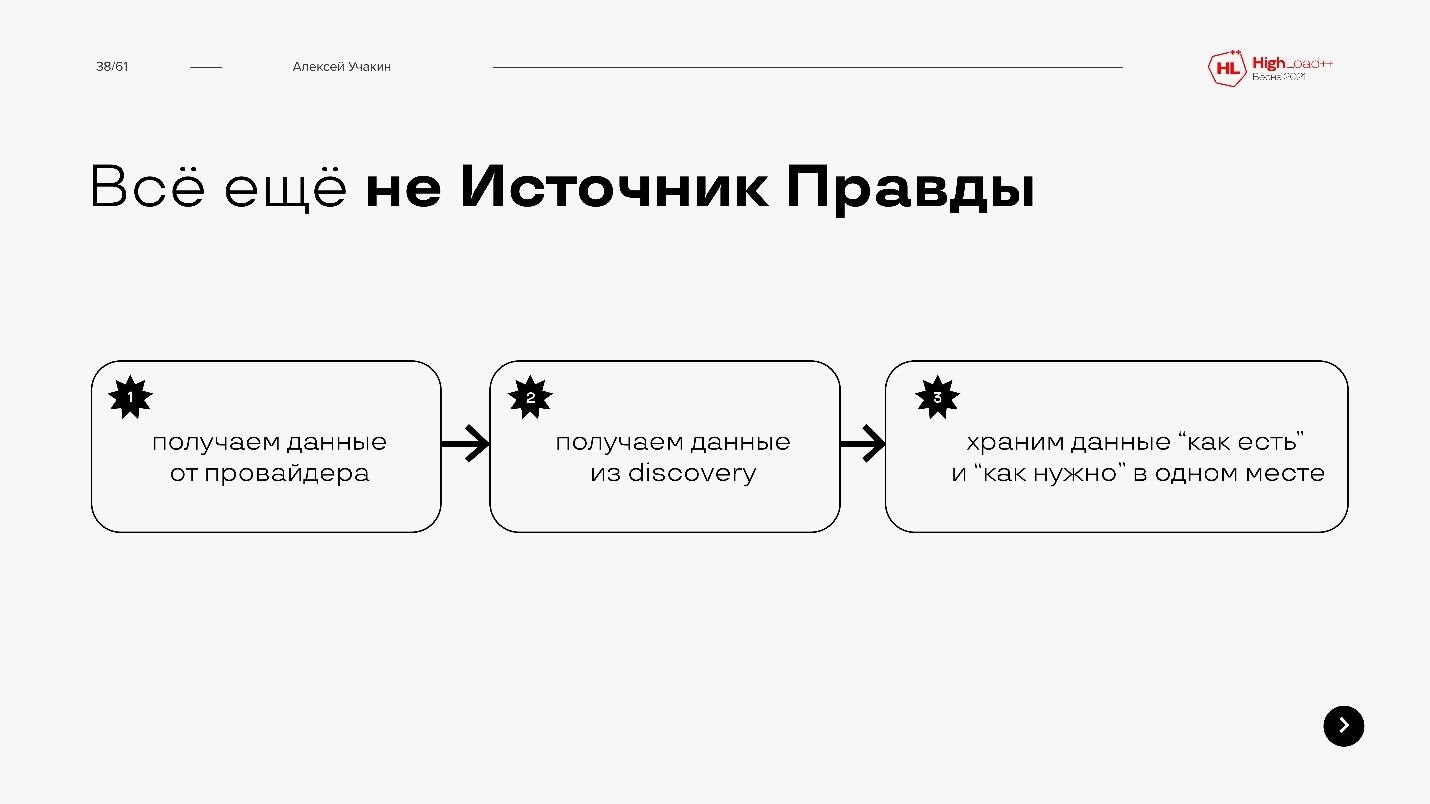
Наступают будни эксплуатации.
После того, как админ Вася поиграется с Докером с одного из серверов прилетает пачка «неправильных» айпишников. А вот тут отъехал API провайдера, и данные о стойках «потерялись». И ещё раз. Постоянно что-нибудь случается. Вы латаете систему, делаете фильтры и откаты, но всё равно просачиваются недостоверные данные, а значит, падает уровень доверия.
Не смотря на это, подход «собрать в одном месте все данные, до которых сможем дотянуться» очень популярен. Потому что кажется, что если собрать все-все данные, до которых можно дотянуться, они автоматом станут актуальными, а если грамотно настроить фильтры, то и достоверными. Я считаю такой подход в корне ошибочным, и вот почему

Данные от провайдера — это не ваши данные (что кажется очевидным). Он их может потерять, поломать и в результате прислать не то, что нужно. В случае с Discovery — с хоста могут прилететь ненужные или невалидные данные по разным причинам. Наконец, может прийти ООМ Killer, убить агента, и вы потеряете данные с этого сервера.
Попытка хранить в одном месте данные «как есть» и «как надо» вообще приводит к лёгкой шизофрении, потому что трудно разобраться: данные вроде есть, но насколько они достоверны? А вот эта информация, она должна быть, или просто так на хосте сейчас настроено?.
На одной из моих прошлых работ у нас был случай, когда от провайдера по API прилетел неправильный адрес управления коммутатором и записался в базу. И когда инженер мониторинга попытался снять метрики с помощью этого IP и модели коммутатора, выяснилось, что метрики оборудованию не соответствуют. Так мы поняли, что железка «немного не та», и информация, которая прилетела от провайдера, некорректная. Провайдер это пофиксил, но, если бы это был не мониторинг, а скрипт управления, мы бы просто положили стойку.
Создаем Источник Правды
Многие из вас знакомы с подходами GitOPS и IaC (Infrastructure as Code). В них Git выступает как Источник Правды, в котором хранится информация о том, как должна выглядеть ваша система. Сетевики очень любят Netbox — это, по сути, база данных с веб-интерфейсом и API, в которой хранятся связанные объекты: ДЦ, стойки, оборудование, IP-адреса, VLAN и все остальное, а также описание связей между ними. В конце концов, если у вас небольшая инфраструктура, вы можете описать все это в Excel-табличках. Просто используйте подходящий ситуации инструмент. Я видел таблицу, которая занимала пару мегабайт, со списком VLAN и IP-адресов. Это была целая простыня, и редактировать её было чрезвычайно трудно, но «все к ней привыкли». Пришлось показывать, что уже давно есть более удобные инструменты и внедрять IPAM-систему.
Обновление данных
После проведения верификации, уборки и алгоритмизации, мы получаем набор данных, которые считаем корректными, и заносим в наш Источник Правды через импорт или руками, кому как удобнее. Это наш «нулевой километр», от которого мы считаем изменения.
Далее сравниваем нашу реальную систему («живые» конфиги, информацию от провайдеров, discovery) с Источником правды. Почти сразу у вас начнут появляться расхождения, но не торопитесь вносить изменения.
Обогащаем наши данные с помощью сканеров, берем информацию из мониторинга. Все это мы постоянно сравниваем с нашим Источником Правды и алертим, если что-то не совпадает.
Когда понятно, что данные в Источнике Правды действительно нужно изменить или дополнить, готовим пулл-реквест. Здесь все, как в обычной выкатке кода на прод — должен быть code style, ревью и ограниченное число человек, которые могут мержить в мастер. Можно даже прикрутить к этому CI/CD и запускать автотесты, которые после изменения данных в Источнике Правды будут еще раз проверять, насколько он соответствует вашей реальной системе.
Популяризация
Обязательно популяризируйте ваш Источник Правды, чтобы им могли пользоваться не только вы, но и ваши коллеги. Иначе вы зашьетесь и будете целый день смотреть в источник Правды и принимать патчи для поддержки актуальности.
Единый Источник Правды
Источников Правды может быть больше одного. Я считаю хранение всех данных в одном месте некорректным потому, что поддерживать актуальность и правильность множества разношерстных данных очень сложно.
Хороший пример, когда у вас есть, допустим, LDAP, где хранятся учетные записи пользователей, а еще есть DNS-сервер, Netbox или Git — и в каждом из них лежит разная информация. При этом, когда нужно авторизовать пользователя, мне надо идти в LDAP. А если нужно получить актуальный список доменных имен, которые закреплены за организацией, я пойду в админку DNS-сервера. То есть данные могут быть разной природы, хоть и связанными друг с другом. Главное, не дублировать одно и то же в разных источниках, иначе вы получите совершенно ненужную проблему актуализации данных в разных местах.
Резервирование
Достоверные данные ценнее всего, когда все сломалось, прод лежит и в 3 часа ночи команда админов пытается разобраться в том, что происходит. Для Git это доступно из коробки — у каждого разработчика и админа есть более-менее свежая локальная копия репозитория. В случае других систем нужно подумать о том, как сохранить доступ к тому же Netbox или Excel-табличке, когда всё сломалось.
Заключение
Лучшая документация — та, которой нет. Чем меньше данных в вашей системе, тем лучше. В Источнике Правды должно быть настолько мало информации, насколько это возможно, но не меньше. Алгоритмизируйте все, что можно и используйте автоматическую генерацию ip-адресов, ID или других данных. Один раз напишите шаблон, положите его в Источник Правды или даже в вашу Вики, или Git, и следуйте ему, потому что шаблон будет априори меняться гораздо реже.
Тогда у вас всегда будут самые свежие и достоверные данные. Удобство их использования — это залог того, что вы не превратитесь в раба своего инструмента, а Источником Правды будут пользоваться все.
Но помните, что Источник Правды — это не самоцель. Это, скорее, идеология, подход, благодаря которому все видят одни и те же данные, доверяют им, и одинаково на них смотрят. Видео моего выступления на HighLoad++ Весна 2021 можно посмотреть здесь.
Да пребудет с вами Правда, потому что у кого правда, тот и сильней!
В этом году нас ждёт ещё два HighLoad++: 20-21 сентября в Санкт-Петербурге и 25-26 ноября — в Москве. Питерское расписание уже готово.
Билеты на конференцию в Санкт-Петербурге можно купить здесь, а на московскую — тут. С 1 сентября цены на Saint HighLoad++ 2021 вырастут. Вы можете забронировать билет, зафиксировать цену ещё на несколько дней и оплатить позже.
