
Стремясь к повышению производительности базы данных, вы можете столкнуться с ситуацией, когда оптимизации и настройки уже недостаточно. Если вы не можете заменить движок БД, а для настройки параметры рабочей нагрузки больше нет возможностей — базу данных придется масштабировать. Делать это руками долго и нецелесообразно, но и у автоматизации процессов масштабирования есть свои подводные камни.
Это перевод статьи Дмитрия Костика и Миколы Моржан из Percona. С их помощью посмотрим, в какой степени можно автоматизировать горизонтальное масштабирование баз данных MongoDB, MySQL и PostgreSQL в Kubernetes и как это сделать?

Как известно, масштабирование может быть вертикальным или горизонтальным. При вертикальном масштабировании к одному узлу добавляются дополнительные ресурсы. Обычно это никак не связано с архитектурой базы данных. Вы просто используете более быстрое хранилище, добавляя диски с большей пропускной способностью ввода-вывода или используете разные хранилища для разных разделов.
С горизонтальным масштабированием (добавлением и удалением узлов), дело обстоит иначе — оно, в первую очередь, касается распределенных баз данных. То есть, если говорить упрощенно, то вертикальное масштабирование в основном специфично для узлов, а горизонтальное — для архитектуры баз данных Вот почему в этой статье мы рассмотрим именно горизонтальное масштабирование.
Горизонтальное масштабирование особенно проблематично для самых распространенных систем управления базами данных, изначально предназначенных для работы с одним узлом. Хранилище и вычислительная нагрузка в этих системах не разделены, а кластеры поддерживаются за счет нескольких полных копий одних и тех же данных. Автоматизация этих процессов вызывает еще больше сложностей, поскольку ваша база данных должна быть расширена до фактического увеличения нагрузки и уменьшена при ее снижении.
Прежде чем перейти к практическому решению, вспомним немного теории. Природа баз данных разделяет масштабирование на две совершенно разные части: масштабирование записи (write) и масштабирование чтения (read). Как мы можем масштабировать запросы на чтение и запись в рассмотренных базах данных, и почему их нужно масштабировать отдельно? Каковы возможности автоматизации такого масштабирования?
Масштабирование запросов на запись
Как правило, когда изменение движка и настройка уже не рассматриваются, запросы на запись в реляционной БД сильно масштабировать не получится. Вам все равно придется записывать данные на каждый узел в кластере, поэтому единственный способ масштабировать write-запросы горизонтально — это использовать сегменты базы данных. В этой ситуации данные распределены по нескольким узлам БД и есть дополнительный компонент, перенаправляющий запросы на нужные.
Если вам все же нужно масштабировать write, но изменение, настройка и сегментирование (шардинг) ядра базы данных не рассматриваются, то вы ограничены вертикальным масштабированием ресурсов вашего узла. Тогда шардинг можно выполнить несколькими способами (если нет дополнительных ограничений, выбирайте самый простой):
Шардинг может изначально поддерживаться конкретной системой управления базами данных.
Если встроенной поддержки нет, можно использовать стороннее расширение.
Реализовать сегментирование вручную на уровне приложения, разделяя части данных и используя различные конечные точки/соединения.
Посмотрим на возможности сегментирования для перечисленных в названии баз данных:
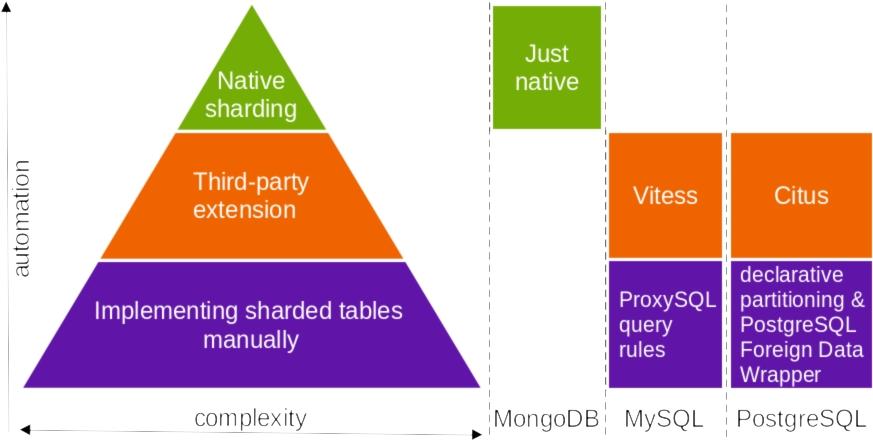
Шардинг в MongoDB самый простой, потому что встроен в эту БД. Для Kubernetes шардинг MongoDB поддерживается операторами Percona Kubernetes в среде Percona Distribution для MongoDB. Подробную информацию об этой функции можно найти здесь.
Шардинг в MySQL можно выполнить автоматически с помощью Vitess или MySQL NDB Cluster от Oracle. Вручную это делается по правилам запросов ProxySQL (этот пост в блоге Percona объясняет, как создать своего рода примитивный шардинг с несколькими таблицами и на пользовательском уровне угадать, какую из них использовать для write).
Шардинг в PostgreSQL также может быть реализован автоматически или вручную. Автоматически его можно реализовать с помощью расширения Citus PostgreSQL (пост о том, как с его помощью сегментировать базу данных). Создать сегментированную базу данных вручную можно, используя этот способ. Он объединяет в себе декларативное разделение и адаптер внешних данных от PostgreSQL.
Масштабирование запросов на чтение
Конечно, сегментирование также очень помогает при масштабировании запросов на чтение, но во многих случаях он не обязателен, если у вас задача масштабировать только такие запросы, без запросов на запись. Read-запросы можно масштабировать с помощью различных методов кэширования, но еще проще это сделать за счет увеличения количества реплик и разделения запросов чтения и записи. Давайте разберем, как это делается для конкретных баз данных.
Разделение запросов read / write в MongoDB выполняется драйвером базы данных, если отключен шардинг. Или с помощью Mongos, если он включен. Если вы используете стандартный драйвер MongoDB, то разделение у вас уже есть. Просто выбирайте по умолчанию secondary, secondaryPreferred или ближайший предпочтительный вариант read вместо основного. Вы даже можете контролировать функциональность write.
Разделение запросов read / write в MySQL можно выполнить с помощью ProxySQL или на уровне приложения. Для последнего используйте две конечные точки: одну для записи и вторую — для чтения с HAProxy перед базой данных.
Разделение запросов read / write в PostgreSQL производится с помощью драйвера базы данных, но надо иметь ввиду, что не все драйверы PostgreSQL поддерживают это разделение. Например, встроенный драйвер PostgreSQL libpq может это делать а драйвер приложений NodeJS node-postgres — нет, поэтому, если это ваш случай, то разделяйте запросы с помощью прокси Pgpool. Также вы можете создавать разные соединения для чтения и записи в вашем приложении.
Автоматическое масштабирование запросов на чтение
Когда вы увеличиваете количество участников в кластере, то один из существующих должен создать резервную копию, отправить ее новому и восстановить эту резервную копию. По крайней мере, так в настоящее время делают базы данных в Kubernetes.
Например, вы настроили разделение запросов на чтение и запись, и у вас есть кластер из двух участников. В тот самый момент, когда вы расширяете его до трех участника, производительность операций чтения существенно снижается (до двух раз при выполнении операторами Kubernetes, поскольку соединения от донора будут маршрутизироваться наружу), пока вы не завершите процесс сохранения резервной копии. И только после этого вы получите фактический прирост производительности чтения.
Например, вы настроили разделение чтения / записи, и у вас есть кластер из двух участников. В тот самый момент, когда вы масштабируете его для трех участников, производительность read существенно падает. Иногда даже в два раза — при выполнении операторами Kubernetes — пока вы не закончите процесс сохранения резервной копии. Потому что в этом случае соединения от донора будут маршрутизироваться наружу, а после завершения резервного копирования вы получите реальный прирост производительности чтения.
Конечно, вы можете настроить соединения, чтобы производительность снижалась не так сильно, но в этом случае вашей базе данных потребуется больше времени на достижение целевой производительности, а она обычно нужна как можно скорее.
Исходя из всего этого — нельзя масштабировать кластер автоматически на основе превышения текущей производительности двух изначальных участников. Мы должны масштабировать кластер заранее. Но это можно сделать только в том случае, если вы знаете, что в какие-то определенные часы будет пиковая нагрузка — и провести масштабирование до этого момента.
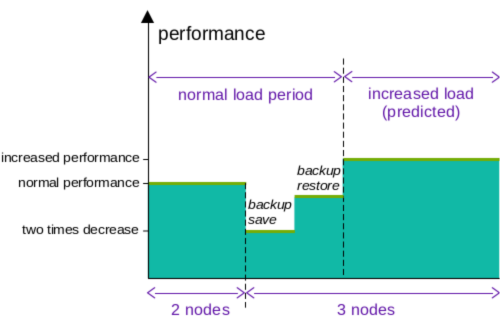
Поэтому имеет смысл только плановое масштабирование.
Горизонтальное автомасштабирование – реализация в Kubernetes
При использовании специального оператора для работы с кластерами базы данных, такого как Percona Kubernetes Operator для Percona XtraDB Cluster, вы можете сделать масштабирование еще проще. Рассмотрим пример таких действий для кластера MySQL, управляемого Percona XtraDB Cluster Operator.
Вы можете добавить или удалить узлы кластера, используя следующую команду:
kubectl scale --replicas=5 pxc/cluster1
Только заранее убедитесь, что команда масштабирования kubectl поддерживается используемым оператором, если таковой имеется. Например, Percona XtraDB Cluster Operator поддерживает ее только в режиме per-namespace/non-clusterwide, начиная с версии 1.8.0. У других операторов эта функция может и вовсе отсутствовать.
Кроме того, рекомендуется изучить документацию вашего оператора на предмет любых особенностей, связанных с масштабированием, которые способны повлиять на автомасштабирование. Например, у Percona XtraDB Cluster Operator и у Percona Operator для Percona Server для MongoDB есть параметр allowUnsafeConfigurations. Его необходимо включить, чтобы оператор не изменил количество экземпляров на безопасные значения по умолчанию. Операторы старательно предотвращают все потенциально небезопасные комбинации, такие как нечетное или четное количество экземпляров, и это может конфликтовать с автомасштабированием.
Наконец, если в вашем случае временное снижение производительности не является проблемой, то можно попробовать Horizontal Pod Autoscaler, чтобы динамически масштабировать кластер базы данных. Это будет на основе определенных показателей, таких как загрузка ЦП вместо того, чтобы делать запланированные масштабирования. Percona XtraDB Cluster Operator позволяет делать это с помощью такой конфигурации:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: cluster1
spec:
minReplicas: 3
maxReplicas: 5
metrics:
- resource:
name: cpu
targetAverageUtilization: 2
type: Resource
scaleTargetRef:
apiVersion: pxc.percona.com/v1
kind: PerconaXtraDBCluster
name: cluster1Итоги
Горизонтальное масштабирование традиционных баз данных состоит из двух очень разных задач: масштабирование операций чтения и операций записи. Единственный способ масштабировать запросы на запись по горизонтали — использовать шардинг базы данных. Горизонтальное масштабирование запросов на чтение связано с разделением операций read/write.
Шардинг и разделение read/write для рассмотренных баз данных можно выполнять по-разному. Как правило, чем менее встраиваемый способ вы используете, тем больше усилий потребуется для его реализации.
Что касается горизонтального автомасштабирования, то это возможный вариант, но вы получите хоть и временное, но довольно большое падением производительности. Поэтому имеет смысл его использовать по расписанию, зная планируемое изменение нагрузки.
Наконец, Kubernetes может еще сильнее автоматизировать масштабирование. Надо только проверять операторы на совместимость с его встроенными возможностями масштабирования для конкретной базы данных.
Сегодня — последний день «Черной пятницы», когда вы можете со скидкой 30% купить билет на участие в конференции TestDriven Conf 2022.
TestDriven Conf 2022, конференция для senior тестировщиков и QA-инженеров пройдет 27-28 июня в Москве и будет посвящена всем вопросам автоматизации в тестировании и рядом с ним. Расписание и тезисы докладов уже на сайте.
