
Многие Golang-разработчики пробовали работать с БД в Go, и у каждого — свои боли. В этой статье поисследуем библиотеку database/sql для работы с абстрактной СУБД и нашу имплементацию database/sql драйвера под СУБД YDB. Рассмотрим трудности эксплуатации при использовании драйвера database/sql на проде. А также расскажем, что мы делали для решения проблем.
Меня зовут Алексей Мясников, я — руководитель Application Team в команде разработки YDB. Я очень люблю git blame за то, что с его помощью можно проследить, как развивалась инженерная мысль с течением времени и немножко побыть в шкуре разработчика той или иной классной штуки. В статье я расскажу, как реализовать драйвер database/sql для распределённой базы данных, такой как YDB, какие проблемы при этом придётся преодолеть и как менялся подход с выходом новых версий Go.

Краткий экскурс: что такое YDB?
Зачем тут про YDB?
Можете рассматривать экскурс в YDB как рекламную вставку, но основная цель этого раздела — дать дорогому читателю необходимый минимум информации о работе распределенной СУБД и работе YDB в частности. Если часть про YDB не интересна — переходите сразу к ретроспективе database/sql.
Изначально YDB был задуман, спроектирован для решения задач надёжного хранения больших объёмов данных и транзакционных нагрузок с горизонтальным масштабированием и высокой отказоустойчивостью. То есть четыре волшебных буквы ACID — это про YDB. По состоянию на 2023 год YDB — платформа данных, потому что в дополнение к транзакционным нагрузкам поддерживает аналитические (OLAP) сценарии, доставку сообщений, координацию распределённых систем и ряд других фич.
YDB в Яндексе работает с внушительными цифрами:
Самый большой кластер ~10К узлов
Самая большая база данных — 1.5M транзакций в секунду, 1.5ПБ данных
Самая большая таблица — 35К шардов, 370 млрд. строк, 66ТБ данных
Compute и Storage
Кластер YDB логически разделён на вычислительный слой и слой хранения:

Наша самая отказоустойчивая конфигурация подразумевает развёртывание в трёх датацентрах и называется mirror-3-dc. Слой хранения мы считаем единой сущностью — это трёхдатацентровый Storage-слой. Пользователи же взаимодействуют только с Compute-слоем. Он выполняет планирование запросов, управление распределёнными транзакциями и, в том числе, принимает запросы от пользователей или клиентских приложений.
YDB с точки зрения клиентского приложения
Клиентское приложение для того, чтобы начать корректно взаимодействовать с YDB, первым делом должно выяснить конфигурацию кластера. У нас есть специальный сервис Discovery, который возвращает конфигурацию кластера конкретной БД, выделенной в этом кластере. Далее все запросы направляются непосредственно к вычислительным динамическим нодам в YDB.
Клиентское приложение должно реализовывать клиентскую балансировку и равномерно распределять нагрузку по узлам YDB. У меня в команде используется 8 языков программирования, соответственно, есть 8 SDK на этих языках. Первоначальный Discovery и клиентскую балансировку во всех наших официальных SDK мы предоставляем автоматически «из коробки».

Если случается, что один или несколько узлов в YDB перегружены, то включаются механизмы серверной балансировки: кластер предоставляет обратную связь клиенту и нагрузка уводится на менее загруженные узлы.

Иерархии таблиц YDB
В отличие от традиционных СУБД, где таблицы располагаются в иерархии фиксированной глубины и каждый уровень имеет особую роль, логическая организация объектов внутри кластера YDB больше похожа на виртуальную файловую систему: каждый объект (база данных, таблица, топик, и пр.) идентифицируется путём произвольной глубины. Физическое значение имеет только база данных в начале пути, а внутри неё пользователи сами решают, как организовывать свои данные по директориям.

Таким образом, вы можете создать таблицу как в корне БД, так и в некоторых директориях и поддиректориях.
YQL — диалект SQL для YDB
В YDB используется собственный диалект SQL, который называется YQL, со своими особенностями:
строгая типизация;
именованные подзапросы и значения;
явная параметризация;
богатый набор встроенных функций.
Люди, которые привыкли к SQL стандарту, встретят знакомые слова:
Стандартные DQL-конструкции внутри
SELECT, включая:JOINGROUP BYORDER BYLIMITWINDOW
Стандартные DML-конструкции, включая:
INSERT INTOUPDATEDELETE
Стандартные DDL-конструкции, включая:
CREATE TABLEALTER TABLEDROP TABLE
Если нужно продвинутое использование, стоит погрузиться в документацию по YQL и по YDB.
Данные упорядочены по первичному ключу
В YDB нельзя создать таблицу без первичного ключа. Типом первичного ключа может быть число, строка, UUID, timestamp и другие сравнимые типы данных, а также он может быть составным, как в примере:
CREATE TABLE account_history (
account_id Text NOT NULL,
operation_id Text NOT NULL,
name Text NOT NULL,
amount Int64 NOT NULL,
PRIMARY KEY (account_id, operation_id)
)Почему нельзя создать таблицу без первичного ключа? Потому что первичный ключ — это необходимое условие для того, чтобы автоматически шардировать таблицы в процессе эксплуатации.
YDB поддерживает следующие виды шардирования:
Шардирование таблиц по объёму.


Шардирование таблиц по нагрузке.


Автомёрдж таблиц после шардирования (после того, как нагрузка спала или часть данных была удалена).


Ручное шардирование.
CREATE TABLE account_history ( account_id Text, operation_id Text, PRIMARY KEY (account_id, operation_id) ) WITH ( AUTO_PARTITIONING_MIN_PARTITIONS_COUNT=50, AUTO_PARTITIONING_MAX_PARTITIONS_COUNT=100 )
Итак, вы знаете всё необходимое про YDB и теперь можно перейти к ретроспективе развития SQL, database/sql и YDB.

В языке Go произошло множество улучшений, начиная с пре-релизных времен. В данной статье мы коснемся только тех изменений Go, которые так или иначе отразились на работе с СУБД.
2011 — Пререлизный эксперимент exp/sql
В 2011 для работы с БД был:
Стандарт ODBC — это C-подобный интерфейс, который продвигал Microsoft.
Стандарт JDBC для экосистемы Java.
Я вижу много общего между database/sql и JDBC API. Вот пример работы с транзакциями:
Connection connection = dataSource.getConnection();
try (connection) {
connection.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement(
"UPDATE employees SET position=? WHERE emp_id=?");
pstmt.setString(1, "lead developer");
pstmt.setInt(2, 1);
pstmt.executeUpdate();
connection.commit();
} catch (SQLException e) {
connection.rollback();
}Cчитаю, что в Go сделано удачнее, потому что там транзакция — это объект, а в JDBC — некое состояние connection. В отличие от JDBC, в Go нам не приходится держать в уме, в каком состоянии находится соединение (в состоянии транзакции или нет, закоммичена эта транзакция или нет) — у нас просто есть объект транзакции, который порождается на соединении и дальше мы работает только с ним. А как мы помним — кошелек Миллера у нас ограничен.
В 2011 году Brad Fitzpatrick написал экспериментальный пакет SQL для Go. В нём объявил интерфейсы, которые нужно заимплементить в каждом конкретном драйвере для конкретной СУБД:
type Driver interface {
Open(name string) (Conn, error)
}
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}
type Stmt interface {
Close() error
NumInput() int
Exec(args []Value) (Result, error)
Query(args []Value) (Rows, error)
}
type Tx interface {
Commit() error
Rollback() error
}Интерфейсы на самом деле простые. Их несложно реализовать, но в них нет ничего про SQL. SQL появляется лишь когда мы в строковом параметре query передаем сам текст SQL-запроса. Но это совсем не обязательно. Как то я со студентами Практикума за 1 час написал database/sql драйвер для key-value хранилища с синтаксисом запросов, похожим на Redis (GET, SET, LIST). В общем, хоть пакет и называется database/sql, но по факту SQL’ем в нем и не пахнет.
db, err := sql.Open("webinar", "")
if err != nil { /*fallback*/ }
_, err = db.Exec("SET key1=$1", 1)
if err != nil { /*fallback*/ }
rows, err := db.Query("GET key1")
if err != nil { /*fallback*/ }
var value int
if !rows.Next() { panic("no rows") }
if err = rows.Scan(&value); err != nil { /*fallback*/ }driver.Result
Также в фундамент database/sql был заложен интерфейс Result, который подразумевает, что идентификатор строки — всегда число.
// Result is the result of a query execution.
type Result interface {
// LastInsertId returns the database's auto-generated ID
// after, for example, an INSERT into a table with primary
// key.
LastInsertId() (int64, error)
// RowsAffected returns the number of rows affected by the
// query.
RowsAffected() (int64, error)
}Это хорошо, если у вас традиционная одноинстансовая БД и есть автоинкремент, serial тип и т.д. Но в распределёнке автоинкремент — это, скорее, антипаттерн. У нас в YDB рекомендуется использовать UUID, чтобы нагрузка автоматически размазывалась по различным шардам. Или рекомендуем использовать составные первичные ключи, за счет которых также можно добиться хорошего шардирования таблицы.
Также интерфейс Result подразумевает, что все операции работы с БД сопровождаются статистикой. Но в распределённых БД рекомендуется использовать «слепые» вставки, изменения, удаления, чтобы всё работало быстро. В YDB можно и так и так, но если отдавать статистику, то пользователь будет создавать повышенную нагрузку на базу.
Благо, в этом интерфейсе есть второй результат — error, где можно сообщить, что запрос не сопровождается статистикой.
Если заглянуть в database/sql/driver, то найдётся ещё масса интерфейсов:
type DriverContext interface {...}
type Connector interface {...}
type Pinger interface {...}
type Execer interface {...}
type ExecerContext interface {...}
type Queryer interface {...}
type QueryerContext interface {...}
type ConnPrepareContext interface {...}
type ConnBeginTx interface {...}
type SessionResetter interface {...}
type Validator interface {...}
type StmtExecContext interface {...}
type StmtQueryContext interface {...}
type NamedValueChecker interface {...}
type ColumnConverter interface {...}
type RowsNextResultSet interface {...}
type RowsColumnTypeScanType interface {...}
type RowsColumnTypeDatabaseTypeName interface {...}
type RowsColumnTypeLength interface {...}
type RowsColumnTypeNullable interface {...}
type RowsColumnTypePrecisionScale interface {...}
...Как это работает? Оказывается, внутри database/sql во многих местах (порядка 25) происходит каст имплементации некой сущности к требуемому опциональному интерфейсу. Если каст успешный — используется продвинутое API. Если нет, то некое дефолтное поведение.
if driverCtx, ok := driveri.(driver.DriverContext); ok {
connector, err := driverCtx.OpenConnector(dataSourceName)
if err != nil {
return nil, err
}
return OpenDB(connector), nil
}Prepared statements
В мире баз данных prepared statements выполняют две важных функции:
Эффективность.
Клиентское приложение обменивает длинный SQL-запрос на короткий QueryID. При этом серверная сторона компилирует запрос и хранит у себя мапу QueryID⇒программа выполнения запроса. Это значит, что вы экономите на повторных компиляциях этого запроса и на сети. То есть при повторном выполнении вам не нужно передавать серверу весь этот жирный SQL, а можно ограничиться коротеньким QueryID.
Безопасность.
Когда мы отделяем тело запроса от передаваемых извне аргументов, то исключаем SQL-инъекции. Идея классная, но это немножко обман (или ненужный оверхед). Потому что когда мы начинаем пользоваться
database/sqlдрайвером, то можем написать хоть литеральный запрос:_, err := db.Exec("INSERT INTO tbl (id, value) VALUES (1, 2)")хоть параметризировать запрос и передать аргументы запроса отдельно:
_, err := db.Exec("INSERT INTO tbl (id, value) VALUES (?, ?)", 1, 2)
Если заглянуть в документацию database/sql драйверов в pgx и посмотреть в протокол работы с PostgreSQL, то там требуется передать идентификаторы типов параметров.
func (p *Pipeline) SendPrepare(
name, sql string, paramOIDs []uint32,
) {
if p.closed {
return
}
p.pendingSync = true
p.conn.frontend.SendParse(&pgproto3.Parse{Name: name, Query: sql, ParameterOIDs: paramOIDs})
p.conn.frontend.SendDescribe(&pgproto3.Describe{ObjectType: 'S', Name: name})
}При вызове prepare, мы передаем только текст запросов, а типы параметров появляются чуть позже. То есть в момент вызова prepare в pgx-драйвере вместо типов параметров передается nil
sd, err = c.pgConn.Prepare(ctx, psName, sql, nil)
if err != nil {
return nil, err
}Мы надеемся, что сервер БД каким-то волшебным образом вычислит, что вместо этих вопросиков или $1, $2, $3 появится что-то, что можно хотя бы скомпилировать.
Если заглянуть в pgjdbc драйвер для Postgres, то там в момент вызова prepare на сервер не отправляется никакого запроса. Сам запрос кэшируется на стороне драйвера, и как только мы передаём первые аргументы, тогда и происходит запрос, потому что типы уже известны.
Пул соединений
Создание соединения к базе данных — это дорогостоящая операция, особенно если используется шифрование типа TLS. Для того, чтобы сделать запрос к БД, недальновидно создавать соединение, выполнять запрос и закрывать соединение. Конечно же стоит кэшировать соединения. И в database/sql такой механизм имеется.

Но удивительно, что дефолтный размер пула составляет 2. То есть, как только concurrency запросов становится больше 2, всё начинает тормозить. Поэтому нужно настроить пул соединения через соответствующие методы:
db.SetConnMaxLifetime(time.Minute)
db.SetMaxIdleConns(10)
db.SetMaxOpenConns(10)2012 — Ретраеры и driver.ErrBadConn
В 2012 году появляется релиз-кандидат Go, и экспериментальный пакет exp/sql был переименован в известный нам database/sql. Именно в таком виде он докатился до наших дней.
Во многих местах database/sql были вставлены ретраеры со счётчиками:
func (db *DB) Prepare(query string) (*Stmt, error) {
var stmt *Stmt
var err error
for i := 0; i < 10; i++ {
stmt, err = db.prepare(query)
if err != driver.ErrBadConn {
break
}
}
return stmt, err
}Я подразумеваю, что цифра 10 здесь взята с потолка. Зато появился некий признак того, что имплементация драйвера может рассказать, что текущее соединение уже плохое (испортилось, сломалось) — имплементация может вернуть специальную ошибку driver.ErrBadConn, которая является признаком, что нужно повторить попытку на другом соединении.
2016 — Ретраеры с connReuseStrategy
В 2016 году вышла очередная версия Go — 1.5. Там заменили сомнительное место со счётчиком на connReuseStrategy.
Цикл из 10 попыток заменили на цикл из 3 попыток: 2 попытки на существующем или новом соединениях в пуле, и 1 попытка строго на новом.
const maxBadConnRetries = 2
func (db *DB) retry(fn func(strategy connReuseStrategy) error) error {
for i := int64(0); i < maxBadConnRetries; i++ {
err := fn(cachedOrNewConn)
// retry if err is driver.ErrBadConn
if err == nil || !errors.Is(err, driver.ErrBadConn) {
return err
}
}
return fn(alwaysNewConn)
}Представьте, у вас в пуле 50 соединений, и все они "протухли". Когда мы так работаем с БД, то выбрасываем 2 испорченных соединения, создаём одно новое и кладём его в пул. Так мы освежаем пул. Идея вообще суперская, и она докатилась до сегодняшних дней.
Классно, что встроили такой ретраер. Но он работает не всегда, а только в момент, когда мы делаем Query, но потом, когда итерируемся по строкам результата запроса, он не работает.
rows, err := db.QueryContext(ctx, "SELECT * FROM tbl;") // retry
if err != nil {
// fallback
}
defer rows.Close()
for rows.Next() { // no retry
// scan row
}
if err := rows.Err(); err != nil { // no retry
// fallback
}Дело в том, что database/sql вернул управление в клиентский код, и дальше это становится болью пользователя. То есть программист клиентского приложения сам должен написать некий ретраер или воспользоваться готовым. Если у вас СУБД работает по unary-протоколу (request-response), то ничего страшного и странного не ожидается (результаты запроса мы уже получили, материализовали в виде строк и ретраев не требуется). Поэтому маловероятно, что что-то пойдёт не так.
Но если мы работаем в потоковом протоколе или с неким cursor’ом, то возникает риск, что при вычитывании очередной строки из результатов может разорваться соединение и нужно поретраить весь запрос.
С интерактивной транзакцией аналогичная проблема — на момент вызова Begin у нас работает встроенный в database/sql ретраер (по сути выбирает «живое» соединение из пула и вызывает на нем Begin). Далее объект интерактивной транзакции отдаётся в клиентский код, то есть автоматическое управление ретраями становится невозможным. Подразумевается, что если после успешного Begin что-то пошло не так — клиентский код поретраит всю транзакцию целиком. То есть забота о неком механизме повторов перекладывается на программиста клиентского приложения.
tx, err := db.BeginTx(ctx,&sql.TxOptions{}) // retry
if err != nil {
// fallback
}
rows, err := tx.QueryContext(ctx, "SELECT * FROM tbl;") // no retry
if err != nil {
// fallback
}
defer rows.Close()
for rows.Next() { // no retry
// scan row
}
if err := rows.Err(); err != nil { // no retry
// fallback
}2016 — context.Context
Вскоре появляется Go 1.7, в котором завезли классную штуку — контекст. Это особая фича языка Go. И как мне кажется, мы (гошники, гоферы) находимся в существенно более выигрышном положении относительно разработчиков на других языках программирования, потому что имеем контекст как часть стандартной библиотеки Go.
Контекст в Go позволяет делать две вещи:
Приделывать значения для некого стека вызовов. Не самый правильный подход к передаче аргументов, но иногда без него просто не обойтись.
Cancellation/Deadline Propagation, то есть возможность отменить выполнение тяжеловесных или долгих операций по всему стеку вызовов после того, как отдали управление в некий библиотечный код или отправили задачу по сети.
Контекст появился в стандартной библиотеке Go, а в пакет стандартной библиотеки database/sql контекст не завезли. Упс =(
2017 — Именованные параметры запросов
Напомним, что в мире существует несколько распространённых стилей параметризации запросов:
-- Литералы
SELECT * FROM tbl WHERE id=100500 AND year>2012;
-- Позиционные параметры (поддержка зависит от СУБД)
SELECT * FROM tbl WHERE id=? AND year>?;
-- Нумерованные параметры (поддержка зависит от СУБД)
SELECT * FROM tbl WHERE id=$1 AND year>$2;Многие базы данных стали поддерживать именованные параметры запроса, в том числе YDB:
MS SQL
Oracle
MySQL
SQLite3
IBM DB2
YDB
-- Именованные параметры (поддержка и синтаксис зависит от СУБД)
SELECT * FROM tbl WHERE id=:id AND year>:year;
SELECT * FROM tbl WHERE id=$id AND year>$year;Более того, YDB поддерживает только именованные параметры запроса (например, $id, $year), никаких позиционных плейсхолдеров типа ? или $1 и $2.
Чуть позже в Go 1.8 также завезли именованные параметры запроса:
rows, err := db.Query(
"SELECT $name, $age",
sql.Named("$age", 2),
sql.Named("$name", "Bob"),
)Замечу, что в JDBC в 2023 году до сих пор нет именованных параметров запроса. Когда ребята в Java мире хотят работать с БД с именованными параметрами, им приходится использовать разные хитрости, чтобы достичь желаемого.
Но именованные параметры гораздо удобнее позиционных. Например, если написать $age, мы понимаем, что речь про возраст, а если $name — про имя. Так параметры становятся не безликими, а говорящими, и у нас снижаются шансы ошибиться в самом SQL.
2017 — rows.NextResultSet()
В Go 1.8 также завезли возможность итераций по множественным ResultSet:
for rows.NextResultSet() {
for rows.Next() {
// scan row
}
}Это может понадобиться, когда в одном SQL запросе используется более одного SELECT statement верхнего уровня. Тогда вам нужно на клиентской стороне уметь отличать ResultSet одной таблички от другой.
Когда вы читаете данные из большой таблицы, то вместо материализации всех данных в режиме unary (request-response) в рантайме Go, можно закономерно получить OOM Killed. Дальше вы можете переписать это на пагинацию, стримовую обработку или получать парты (чанки) данных согласно протоколу конкретной СУБД. Это такой trade-off, чтобы не создавать нагрузку на сеть, рантайм и память своего приложения.
Работает итерация по ResultSet'ам также через неявные интерфейсы:
type RowsNextResultSet interface {
Rows
HasNextResultSet() bool
NextResultSet() error
}
...
nextResultSet, ok := rs.rowsi.(driver.RowsNextResultSet)
if !ok {
return false
}
rs.lasterr = nextResultSet.NextResultSet()
if rs.lasterr != nil {
return false
}
return trueЕсли сущность из имплементации драйвера поддерживает этот интерфейс, то работаем с RowsNextResultSet. Если кастовать не удается, значит выполняется некое дефолтное поведение.
2017 — sql.*Context
В go 1.8 в пакет database/sql наконец довезли контекст. Появились парные методы для Exec, Query, Prepare и создания интерактивных транзакций:
db.Exec(query, args...)
db.ExecContext(ctx, query, args...)
db.Query(query, args...)
db.QueryContext(ctx, query, args...)
db.Prepare(query)
db.PrepareContext(ctx, query)
db.Begin()
db.BeginTx(ctx, txOptions)А старые, конечно, остались — потому что legacy. Если их выпилить, сломается обратная совместимость. По идее, это прямой повод для Go 2.0. Но этого не делают, потому что множество приложений уже используют старые методы без контекста. Пользователи Go будут сильно разочарованы, если их код сломается, когда они заиспользуют новую версию Go.
Поддержка контекста при работе с БД обеспечило cancel propagation (context cancellation) — cигнал о том, что результат запроса уже не интересен. Этот сигнал распространяется как в рантайме своего приложения, так и в распределённой микросервисной системе:

В классическом трёхзвенном приложении бывает так:

Есть некий UI — фронтенд, где пользователь нажимает кнопку, бэкенд принимает запрос, оформляет в виде SQL и отправляет в БД. Но представим, что на этом этапе у клиента порвалась сеть. Например, это произошло при перезагрузке страницы. В результате все результаты будут выброшены, потому что их некому отдавать. Когда программисты ходят в БД без контекста, то бэкенд продолжает выполнять тяжёлую работу, например тяжёлые запросы типа SELECT * FROM big_table. Получается, что даже если клиенту не интересен результат запроса или клиент пропал как абонент, то сервер БД продолжает работать. Эта неприятность возникает не только при работе с СУБД, но и при любых тяжеловесных операциях хоть в рамках рантайма единого приложения, хоть в распределенной системе.
Не все СУБД поддерживают возможность отменить запрос. А те, которые поддерживают эту возможность сегодня, не сразу такими стали. Например, Postgres стал поддерживать отмену запроса, начиная с версии 8.0. В YDB тоже всё случилось не сразу и у нас до сих пор есть legacy API, в котором мы не можем с клиентской стороны сказать: «Мистер сервер, отмени, пожалуйста, работу».
Опытные Go-программисты, конечно, уже знают, что в БД нужно ходить с контекстом.
2019 — Изменения в Go по работе с ошибками
Появляется Go 1.13, в котором изменяется подход к работе с ошибками.
Напомню, до Go 1.13 мы обрабатывали ошибки путём сравнения через ==. Начиная с Go 1.13 рекомендованный путь — проверять ошибки через errors.{Is,As}.
// до go1.13
if err != driver.ErrBadConn {
// do
}
// начиная с go1.13
// https://go.dev/wiki/ErrorValueFAQ
if errors.Is(err, driver.ErrBadConn) {
// do
}Это появилось потому, что ошибка перестала быть переменной. Она может оборачивать в себе другие ошибки. Стандартный fmt.Errorf() с плейсхолдером %w оборачивает какую-то исходную ошибку в новую. Подход через errors.{Is,As} позволяет проверить, что же там было в самом начале.
Однако в database/sql ничего не изменилось. Опять упc =(
Когда исходная ошибка замалчивается
Когда у нас есть исходная ошибка, мы вынуждены для совместимости с database/sql возвращать специальную ошибку driver.ErrBadConn. В этом случае на клиентских графиках выглядит как какой-то фон ошибок driver.ErrBadConn, а что там было на самом деле — непонятно. Можно ошибки рассматривать в черно-белом представлении мира как маркеры неудач.

Но на самом деле ошибки — это наши помощники, они разговаривают с нами, рассказывают что пошло не так и несут дополнительную семантическую нагрузку о том, что можно сделать для исправления проблемы. Зная семантику конкретной ошибки можно подобрать хороший fallback, чтобы добиться успеха.
Транспортные и серверные ошибки YDB
В YDB есть два крупных класса ошибок: транспортные и операционные (логические, серверные) ошибки.

Для одних ошибок мы рекомендуем ретраиться с медленной экспоненциальной задержкой. Для других — с быстрой экспоненциальной задержкой. Одни ошибки являются ретраибельными, безопасными, т.к. при их возникновении есть гарантии, что состояние базы данных не изменилось. Другие можно ретраить, только если пользователь явно указал специальный флажок идемпотентности. Это важно, чтобы при повторе тех же операций с БД мы пришли к тому же конечному состоянию.
В ответ на часть ошибок нужно удалить сессию, а в терминах database/sql — соединение к БД. На отдельных типах ошибок следует полностью закрыть соединение к одному из узлов YDB и удалить все сессии, которые на этом узле YDB созданы.
Реакция на все виды ошибок закреплена в соответствующих тестах.
Однако, соблюдая контракт database/sql об ошибках, все многообразие ошибок YDB превращается в примитивное:

Если бы driver.ErrBadConn не замалчивал исходные ошибки, на графиках можно было бы понять, что, например, часть сессий инвалидирована или сервер отменил транзакцию.

Дальше инженер технической поддержки, как минимум, мог бы понять, что нужно докинуть ресурсы, расширить кластер, ещё что-то сделать. Когда все спрятано за безликим driver.ErrBadConn, непонятно, как из этого выходить.
2021 — нативный драйвер YDB
В Яндексе к этому моменту уже были экспериментальный нативный Go-драйвер и database/sql драйвер, а также сотни тикетов с фидбеком его пользователей. Пришлось поискать корневые причины и понять, как сделать хорошо.
В YDB используют оптимистичные блокировки — конкурентные транзакции не блокируются в ожидании лока, но при Commit’е возникает риск того, что конкурентная транзакция уже изменила потроганные строчки данных — в YDB в этом случае в ответ на Commit вернётся специальная ошибка «Transaction Locks Invalidated». Для таких ошибок нужно повторить запрос с экспоненциальным backoff. В теории такие ретраи конкурентных транзакции сходятся.
Также в YDB используется подход fail fast. То есть в любой непонятной ситуации прерывается выполнение работы запроса и возвращается ошибка, чтобы не допустить некорректного результата. Это неприятное усугубляющее обстоятельство для пользователей распределённой СУБД и одновременно преимущество, т.к. при большом количестве конкурирующих клиентов одной базы минимизируются шансы на corrupt данных, странное поведение и т.п.
В общем, проанализировав всё, что есть, мы начали искать решения. Главное, что придумали — запретить работать с БД без ретраеров. Конечно же не директивно (неким постановлением ЦК КПСС), а за счет специального API, который не позволит работать с YDB неправильно (без ретраеров) .
err := db.Table().Do(ctx, func(ctx context.Context, s table.Session) error {
tx, result, err := s.Execute(ctx, txControl, query,
table.NewQueryParameters(params...))
if err != nil {
return err
}
var title, content string
for result.NextResultSet(ctx) {
for result.NextRow() {
if err := result.Scan(&title, &content); err != nil {
return err
}
log.Println(title, content)
}
}
return result.Err()
}, table.WithIdempotent())Здесь ретраер обозначен Do. В него нужно передавать лямбду (анонимную функцию), можно указать опциональный флаг идемпотентности (table.WithIdempotent()). Мы управляем временем жизни ретраера через контекст. И обязательно лямбда должна возвращать ошибку. return err — это способ из лямбды сообщить ретраеру об успехе или неудаче всей лямбды. В случае nil ошибки повторы будут прекращены. В случае не nil ретраер попытается классифицировать ошибку, выяснить, что там произошло, какую экспоненциальную задержку (быструю, медленную) вставить, нужно ли удалять сессию, и прочее.
2022 — database/sql-драйвер для YDB
Спустя примерно год мы написали официальный database/sql-драйвер для YDB. Там мы заложили, что с YDB нужно работать с помощью ретраеров:
err = retry.Do(ctx, db,
func(ctx context.Context, cc *sql.Conn) error {
...
},
retry.WithIdempotent(true),
)
err := retry.DoTx(ctx, db,
func(ctx context.Context, tx *sql.Tx) error {
...
},
retry.WithIdempotent(true),
retry.WithTxOptions(&sql.TxOptions{
Isolation: sql.LevelSnapshot,
ReadOnly: true,
}),
)Здесь два ретраера: Do — про работу с БД на SQL соединении, DoTx — про ретраи на на транзакции. Точно также мы передаём лямбды и можем обозначить флаг идемпотентности. Мы управляем временем жизни ретраера через контекст, и обязательно нужно возвращать ошибку. Это способ общения клиентской лямбды с ретраером.
2022 — database/sql: долгожданная обработка ошибок через errors.Is
Наконец, в Go 1.18 работу с ошибками заменили на error.Is (вместо проверки на ==):
const maxBadConnRetries = 2
func (db *DB) retry(fn func(strategy connReuseStrategy) error) error {
for i := int64(0); i < maxBadConnRetries; i++ {
err := fn(cachedOrNewConn)
// retry if err is driver.ErrBadConn
if err == nil || !errors.Is(err, driver.ErrBadConn) {
return err
}
}
return fn(alwaysNewConn)
}Благодаря этому мы перестали терять информацию об исходной ошибке.
До Go 1.18 было так:
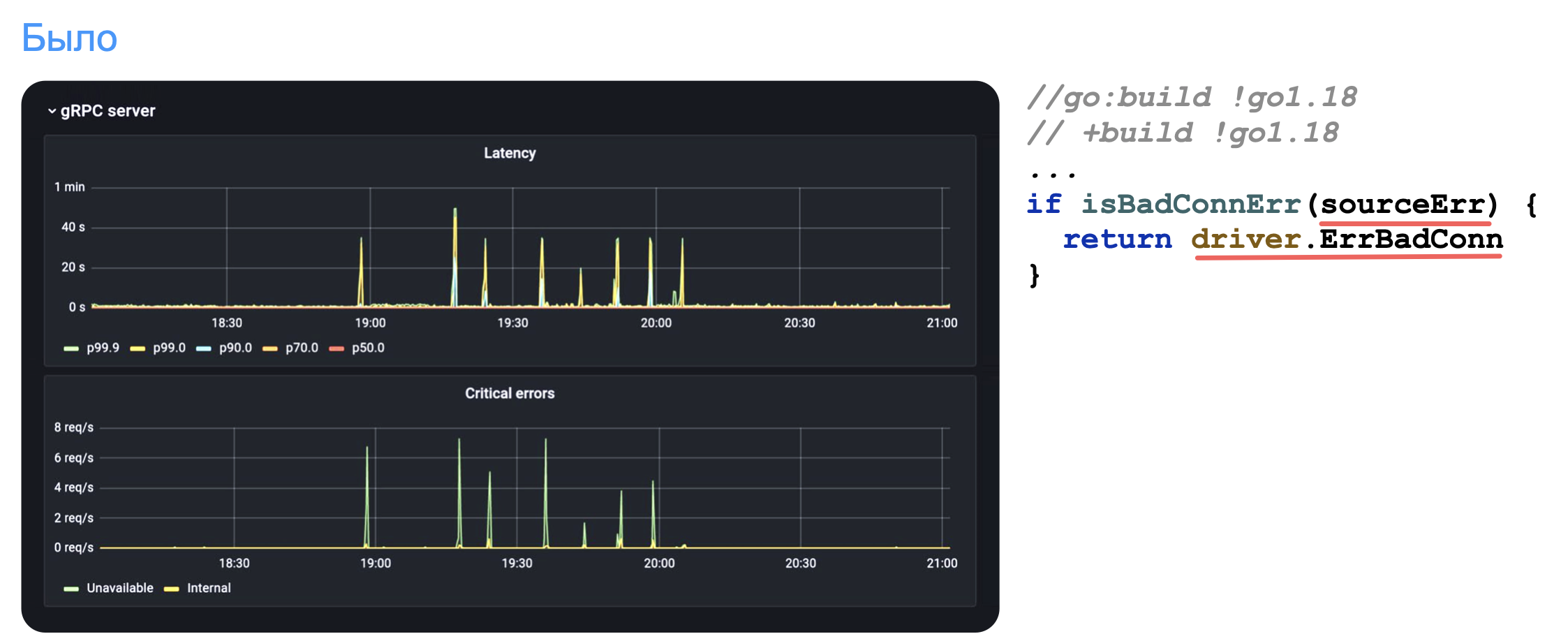
Это абсолютно честный график одного из клиентов YDB, работающего через database/sql. На графике исходная информация об ошибке теряется и видны нелепые задержки до минуты.
За счёт нехитрого трюка можно сохранить исходную информацию об ошибке и дальше её использовать в ретраере, чтобы оптимальным образом работать и выполнять повторные попытки:
//go:build go1.18
// +build go1.18
type badConnErr struct {
sourceErr error
}
func (e badConnErr) Is(err error) bool {
if err == driver.ErrBadConn {
return true
}
return errors.Is(e.sourceErr, err)
}Клиентские графики внезапно преобразились: latency запросов в высоких перцентилях кардинально улучшились, рэйт ошибок, докатывающихся до клиентского кода через ретраеры, существенно снизился.

2023 — биндинги запросов к YDB
Уже в 2023 году мы написали биндинги запросов к YDB — это некие функции-обогатители пользовательских SQL-запросов. YDB имеет довольно высокий порог входа. Люди, привыкшие работать с другими диалектами SQL, часто не хотят писать всякие PRAGMA, DECLARE. Биндинги решают эту задачку, автоматически превращая привычный пользователям SQL с другими видами плэйсхолдеров в корректный YQL.
Например, исходный запрос:
SELECT id, name, salary
FROM staff
WHERE
department_id = ? AND
salary > ?;с помощью биндингов превращается в YQL, понятный YDB:
-- bind TablePathPrefix
PRAGMA TablePathPrefix("/local/path/to/my/folder");
-- bind declares
DECLARE $p0 AS Int32;
DECLARE $p1 AS Double;
-- original query with positional args replacement
SELECT id, name, salary
FROM staff
WHERE
department_id = $p0 AND
salary > $p1;Поддержка debug tooling в Go-драйвере YDB
У нас написан debug-tooling для того, чтобы профилировать происходящее внутри драйвера. У нас есть встроенный логгер, который задаётся через переменные окружения, а ещё есть адаптеры для популярных логгеров (zap, zerolog, logrus). Есть метрики для Prometheus и внутри-яндексовой системы мониторинга. Есть адаптеры для трассировки в формате opentelemetry и opentracing.
Это must-have. Мы даём драйвер и говорим, что есть плагины (адаптеры) которые позволяют в случае проблем принести чуть больше, чем «Не работает, помогите!».
По дефолту драйвер YDB ничего не логирует, не считает и не отправляет никакие метрики, никуда не постит свои спаны. Таким образом, "ванильный" драйвер YDB не имеет лишних "странных" зависимостей. Представьте, что подключаете себе в проект драйвер для работы с YDB, используете у себя логгер zap, а по зависимостям к вам в проект приезжают логгеры zerolog и logrus. И еще какие-то зависимости на yandex-cloud. Мне бы как мэйнтейнеру некоего проекта показалось странным такое или даже опасным ("мои данные передаются в Яндекс.Облако???"). Поэтому подключение плагинов (адаптеров) — дело добровольное.
Ну вот, казалось бы, всё написано — берите, пользуйтесь, радуйтесь жизни и YDB. Можно уходить на пенсию? Но это только начало пути…
Когда у базы есть свой database/sql драйвер
Как только появился database/sql драйвер, начали рождаться проекты, основанные на нём. Например, моя коллега @Raubzeug написала ydb-grafana-datasource-plugin для работы с YDB. Также мы завезли поддержку YDB в утилиту миграции goose.
Есть ещё несколько проектов в состоянии work in progress:
У нас есть список issue в GitHub, помеченных специальной меткой student-projects, чтобы можно было прийти и нанести добро: покодить, повзаимодействовать со штатной командой или как-то отметиться на просторах опенсорса.
Вместо выводов
Статья в целом должна показаться увлекательной и бесполезной одновременно. Увлекательная — потому что ретроспективно мы поведали, как менялись стандартная библиотека Go, пакет database/sql, язык SQL и сама база данных YDB. А бесполезная — потому что на данный момент озвученные «нюансы» работы с СУБД через database/sql драйвер остались в прошлом, а следующие «нюансы» ещё не фигурируют на повестке дня. Тем не менее, можно попробовать сделать мета-вывод:
Язык
Go,SQLи СУБД (конкретноYDB) органично менялись вместе с изменением подходов к работе с базами данных, идеальных «первых блинов» не было, но инженерная мысль не стоит на месте и даёт свой отпор возникающим трудностям!
