В преддверии старта курса "Machine Learning. Professional" делимся традиционным переводом полезного материала.
Из этой статьи вы узнаете то, что можно узнать, только потратив множество часов на изучение и практику.

Об этом проекте
Kaggle — прекрасное место. Это золотая жила для дата-сайентистов и инженеров машинного обучения. Не так много платформ, на которых вы можете найти высококачественные, эффективные, воспроизводимые, отобранные экспертами, потрясающие примеры коды в одном месте.
С момента запуска она провела более 164 соревнований. Эти соревнования привлекают на платформу экспертов и профессионалов со всего мира. В результате на каждом соревновании появляется множество высококачественных блокнотов и скриптов, а также огромное количество опенсорсных наборов данных, которые предоставляет Kaggle.
В начале своего пути в data science я приходил на Kaggle, чтобы найти наборы данных и оттачивать свои навыки. Когда бы я ни пытался разбираться с другими примерами и фрагментами кода, меня поражала сложность, и я сразу же терял мотивацию.
Но теперь я обнаружил, что провожу много времени за чтением чужих блокнотов и отправкой заявок на соревнования. Иногда там есть вещи, на которые стоит потратить все выходные. А иногда я нахожу простые, но невероятно эффективные приемы и передовой опыт, которые можно изучить, только наблюдая за другими профессионалами.
А в остальном дело за малым, мое ОКР практически вынуждает меня выкладывать все имеющиеся у меня знания в области науки о данных. Таким образом я представляю вам первый выпуск моего еженедельника «Полезные приемы и лучшие практики от Kaggle». На протяжении всей серии я буду писать обо всем, что может быть полезно во время типичного рабочего процесса в области data science, включая фрагменты кода распространенных библиотек, передовые практики, которым следуют ведущие эксперты в области с Kaggle, и т. д. - все, что я узнал за прошедшую неделю. Наслаждайтесь!
1. Отображение только нижней части корреляционной матрицы
Хорошая корреляционная матрица может многое сказать о вашем наборе данных. Обычно его строят, чтобы увидеть попарную корреляцию между вашими признаками (features) и целевой переменной. В соответствии с вашими потребностями вы можете решить, какие признаки сохранить и включить в свой алгоритм машинного обучения.
Но сегодня наборы данных содержат так много признаков, что разбираться с корреляционной матрицей, подобные этой, может оказаться непосильной задачей:
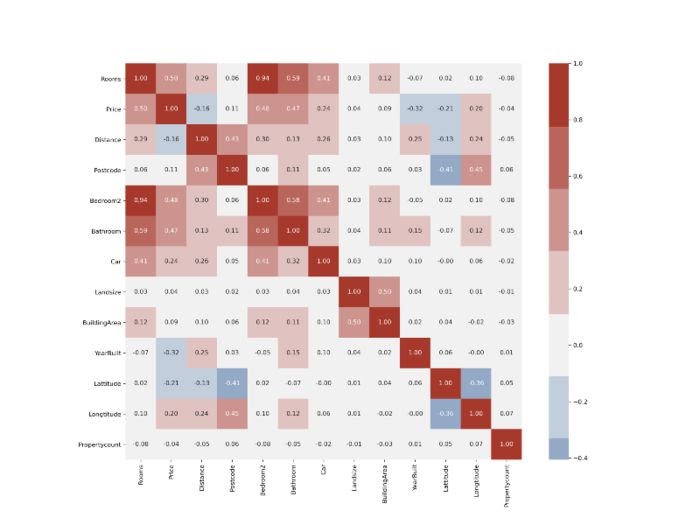
Как бы хороша она ни была, этой информации слишком много для восприятия. Корреляционные матрицы в основном симметричны по главной диагонали, поэтому они содержат повторяющиеся данные. Также бесполезна сама диагональ. Посмотрим, как можно построить только полезную половину:
houses = pd.read_csv('data/melb_data.csv')
# Calculate pairwise-correlation
matrix = houses.corr()
# Create a mask
mask = np.triu(np.ones_like(matrix, dtype=bool))
# Create a custom diverging palette
cmap = sns.diverging_palette(250, 15, s=75, l=40,
n=9, center="light", as_cmap=True)
plt.figure(figsize=(16, 12))
sns.heatmap(matrix, mask=mask, center=0, annot=True,
fmt='.2f', square=True, cmap=cmap)
plt.show();
Полученный в результате график намного легче интерпретировать, и он не так отвлекает избыточными данными. Сначала мы строим корреляционную матрицу, используя метод DataFrame .corr. Затем мы используем функцию np.ones_like с dtype, установленным в bool, чтобы создать матрицу значений True с той же формой, что и наш DataFrame:
>>> np.ones_like(matrix, dtype=bool)[:5]
array([[ True, True, True, True, True, True, True, True, True,
True, True, True, True],
[ True, True, True, True, True, True, True, True, True,
True, True, True, True],
[ True, True, True, True, True, True, True, True, True,
True, True, True, True],
[ True, True, True, True, True, True, True, True, True,
True, True, True, True],
[ True, True, True, True, True, True, True, True, True,
True, True, True, True]])Затем мы передаем его в функцию Numpy .triu, которая возвращает двумерную логическую маску, которая содержит значения False для нижнего треугольника матрицы. Затем мы можем передать его функции Seaborn heatmap для построения подмножества матрицы в соответствии с этой маской:
sns.heatmap(matrix, mask=mask, center=0, annot=True,
fmt='.2f', square=True, cmap=cmap)Я также сделал несколько дополнений, чтобы график получился немного лучше, например, добавление собственной цветовой палитры.
2. Добавление отсутствующих значений в value_counts
Небольшой удобный трюк с value_counts заключается в том, что вы можете увидеть долю пропущенных значений в любом столбце, установив dropna в False:
>>> houses.CouncilArea.value_counts(dropna=False, normalize=True).head()
NaN 0.100810
Moreland 0.085641
Boroondara 0.085420
Moonee Valley 0.073417
Darebin 0.068778
Name: CouncilArea, dtype: float64Определив долю значений, которые отсутствуют, вы можете принять решение относительно того, следует ли отбросить или перезаписать их. Однако, если вы хотите посмотреть долю отсутствующих значений во всех столбцах, value_counts - не лучший вариант. Вместо этого вы можете сделать:
>>> missing_props = houses.isna().sum() / len(houses)
>>> missing_props[missing_props > 0].sort_values(ascending=False
BuildingArea 0.474963
YearBuilt 0.395803
CouncilArea 0.100810
Car 0.004566
dtype: float64Сначала найдите пропорции, разделив количество отсутствующих значений на длину DataFrame. Затем вы можете отфильтровать столбцы с 0%, т.е. выбирать только столбцы с пропущенными значениями.
3. Использование Pandas DataFrame Styler
Многие из нас никогда не осознают огромный неиспользованный потенциал pandas. Недооцененной и часто упускаемой из виду особенностью pandas является ее способность стилизовать свои DataFrame’ы. Используя атрибут .style для DataFrame’ов pandas, вы можете применять к ним условные конструкции и стили. В качестве первого примера давайте посмотрим, как можно изменить цвет фона в зависимости от значения каждой ячейки:
>>> diamonds = sns.load_dataset('diamonds')
>>> pd.crosstab(diamonds.cut, diamonds.clarity).\
style.background_gradient(cmap='rocket_r')
Это практически тепловая карта без использования функции Seaborn heatmap. Здесь мы подсчитываем каждую комбинацию огранки и чистоты алмаза с помощью pd.crosstab. Используя .style.background_gradient с цветовой палитрой, вы можете легко определить, какие комбинации встречаются чаще всего. Только из приведенного выше DataFrame мы можем видеть, что большинство алмазов имеют идеальную огранку, а самая распространенная комбинация - с типом чистоты VS2.
Мы даже можем пойти дальше, найдя среднюю цену каждой комбинации огранки и чистоты бриллианта в перекрестной таблице:
>>> pd.crosstab(diamonds.cut, diamonds.clarity,
aggfunc=np.mean, values=diamonds.price).\
style.background_gradient(cmap='flare')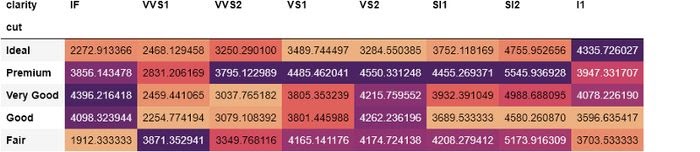
На этот раз мы агрегируем цены на бриллианты для каждой комбинации огранки и чистоты. Из стилизованного DataFrame мы видим, что самые дорогие бриллианты имеют чистоту VS2 или премиальную огранку. Но было бы лучше, если бы мы могли отображать агрегированные цены, округляя их. Мы также можем изменить это с помощью .style:
>>> agg_prices = pd.crosstab(diamonds.cut, diamonds.clarity,
aggfunc=np.mean, values=diamonds.price).\
style.background_gradient(cmap='flare')
>>> agg_prices.format('{:.2f}')
Изменив в методе .format строку формата {:.2f} мы указываем точность в 2 числа после запятой.
С .style предел - ваше воображение. Имея базовые познания в CSS, вы можете создавать собственные функции стилизации под свои нужды. Ознакомьтесь с официальным руководством pandas для получения дополнительной информации.
4. Настройка глобальных конфигураций графиков с помощью Matplotlib
При выполнении EDA (Exploratory Data Analysis) вы обнаружите, что сохраняете некоторые настройки Matplotlib одинаковыми для всех ваших графиков. Например, вы можете захотеть применить настраиваемую палитру для всех графиков, использовать более крупные шрифты для меток, изменить расположение легенды, использовать фиксированные размеры фигур и т. д.
Указание каждого настраиваемого изменения графиков может быть довольно скучной, повторяющейся и длительной задачей. К счастью, вы можете использовать rcParams из Matplotlib для установки глобальных конфигураций для ваших графиков:
from matplotlib import rcParams
rcParams - это просто старый словарь Python, содержащий настройки по умолчанию для Matplotlib:

Вы можете настроить практически все возможные аспекты каждого отдельного графика. Что я обычно делаю и видел, как делали другие, так это установка фиксированного размера фигур, размер шрифта меток и некоторые другие изменения:
# Remove top and right spines
rcParams['axes.spines.top'] = False
rcParams['axes.spines.right'] = False
# Set fixed figure size
rcParams['figure.figsize'] = [12, 9]
# Set dots per inch to 300, very high quality images
rcParams['figure.dpi'] = 300
# Enable autolayout
rcParams['figure.autolayout'] = True
# Set global fontsize
rcParams['font.style'] = 16
# Fontsize of ticklabels
rcParams['xtick.labelsize'] = 10
rcParams['ytick.labelsize'] = 10Вы можете избежать большого количества повторяющейся работы, установив все сразу после импорта Matplotlib. Просмотреть все другие доступные настройки можно, вызвав rcParams.keys().
5. Настройка глобальных конфигураций Pandas
Как и в Matplotlib, у pandas есть глобальные конфигурации, с которыми вы можете поиграть. Конечно, большинство из них связано с опциями отображения. В официальном руководстве пользователя говорится, что всей системой опций pandas можно управлять с помощью 5 функций, доступных непосредственно из пространства имен pandas:
get_option()/set_option()- получить/установить значение одного параметра.reset_option()- сбросить один или несколько параметров до значений по умолчанию.description_option()- вывести описание одного или нескольких параметров.option_context()- выполнить блок кода с набором параметров, которые после выполнения возвращаются к предыдущим настройкам.
Все параметры имеют имена без учета регистра и находятся с помощью регулярного выражения из под капота. Вы можете использовать pd.get_option, чтобы узнать, какое поведение используется по умолчанию, и изменить его по своему вкусу с помощью set_option:
>>> pd.get_option(‘display.max_columns’)
20Например, указанный выше параметр управляет количеством столбцов, которые должны отображаться, когда в DataFrame очень много столбцов. Сегодня большинство наборов данных содержит более 20 переменных, и всякий раз, когда вы вызываете .head или другие функции отображения, pandas ставит раздражающее многоточие, чтобы обрезать результат:
>>> houses.head()

Я бы предпочел видеть все столбцы, прокручивая их. Давайте изменим это поведение:
>>> pd.set_option(‘display.max_columns’, None)
Выше я полностью убираю ограничение:
>>> houses.head()

Вы можете вернуться к настройке по умолчанию с помощью:
pd.reset_option(‘display.max_columns’)
Как и в столбцах, вы можете настроить количество отображаемых строк по умолчанию. Если вы установите для display.max_rows значение 5, вам не придется все время вызывать .head():
>>> pd.set_option(‘display.max_rows’, 5)>>> houses

В настоящее время plotly становится очень популярным, поэтому было бы неплохо установить его как график по умолчанию для pandas. Поступая таким образом, вы будете получать интерактивные графические диаграммы всякий раз, когда вы вызываете .plot для DataFrame’ов pandas:
pd.set_option(‘plotting.backend’, ‘plotly’)
Обратите внимание, что для этого вам необходимо установить plotly.
Если вы не хотите испортить поведение по умолчанию или просто хотите временно изменить определенные настройки, вы можете использовать pd.option_context в качестве диспетчера контекста. Временное изменение поведения будет применено только к блоку кода, который следует за оператором. Например, если есть большие числа, у pandas есть раздражающая привычка преобразовывать их в стандартную нотацию. Вы можете временно избежать этого, используя:
>>> df = pd.DataFrame(np.random.randn(5, 5))
>>> pd.reset_option('display.max_rows')
>>> with pd.option_context('float_format', '{:f}'.format):
df.describe()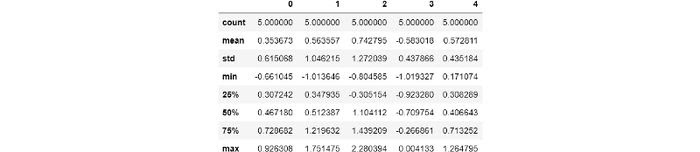
Вы можете увидеть список доступных параметров в официальном руководстве пользователя pandas.
Узнать подробнее о курсе "Machine Learning. Professional"
