
Привет, Хабр! :-) Меня зовут Ильяс. В этой статье мы разберём известную идею — keepalive в межсервисном взаимодействии, которая спасла уже не одну компанию в трудное время :). Но чтобы добавить интереса, мы разберём, какие проблемы в keepalive принесли современные технологии (ведь что может пойти не так с этой простой идеей?). Поэтому в статье мы рассмотрим механизмы, которые позволяют проверять стабильность соединения между клиентом и сервером в случае, когда обычные TCP keepalive из-за сложности архитектуры не могут определить состояние сервера.

Вступление
В момент, когда вы принимаете решение о том, что стоит распилить ваш монолит на несколько частей (или закладываете новый проект с микросервисной архитектурой), вы принимаете ряд рисков, которые возникают при таком подходе относительно построения монолита. И один из таких рисков — возможность отказа какой-то из частей вашей системы. И, как показывает практика, история тут ровно такая же, как и с бэкапами баз данных — рано или поздно большинство систем наталкивается на такую проблему. В такой ситуации, когда вы будете видеть на ваших графиках кучу отмен запросов клиентами или Internal Server Error вместе с Context Deadline Exceeded (в лучшем случае) и недоумевать о том, что же происходит, ведь тот коллега, который уволился пару месяцев назад, конечно же, не настроил алерты на падение инстансов его сервиса, вы будете очень долго и больно раскапывать причину проблемы. И у нас такие ситуации случались. Так вот, статья про то, какие меры можно предпринять заранее, чтобы избежать этой боли и отработать сценарий отказа какой-либо части сервиса точнее и лучше.
Но всё же, прежде чем обсуждать всё самое интересное, надо всё-таки вспомнить, для чего эти keepalive вообще нужны. Под спойлером небольшой ликбез по этому поводу.
Ликбез про keepalive
Референсная документация тут.
Keepalive — это механизм определения состояния кого-то или чего-то на другой стороне неважно чего. В нашем контексте мы будем обсуждать межсервисное взаимодействие, поэтому у нас будет два компьютера, которые общаются между собой по сети. И через keepalive мы будем выяснять, жив ли компьютер на другом конце нашего провода.

Концепция keepalive в нашем контексте довольно простая. Когда мы установили соединение между двумя этими компьютерами, мы на каждом из них запускаем таймеры, по истечении заданного времени на которых эти компьютеры будут отправлять друг другу определённые сообщения, называемые keepalive probe. В случае получения такого сообщения каждый компьютер будет посылать ответное сообщение о том, что он жив (ACK — acknowledge). Ну и, соответственно, когда мы в ответ на свою keepalive probe получаем ACK, — мы делаем вывод о том, что компьютер на той стороне жив. Иначе, если после отправки keepalive probe мы за некоторое время не получаем этот ACK, — делаем вывод о том, что компьютер на той стороне уже недоступен. Для достоверности мы можем сделать несколько таких keepalive probe, чтобы с более высокой вероятностью сделать правильный вывод о недоступности компьютера на той стороне. Все настройки таймеров и количества проб конфигурируются. Подробнее про это можно прочитать в референсной документации.
Проблема TCP keepalive
Самым популярным и проверенным десятилетиями является механизм TCP keepalive, который работает на L4-уровне модели OSI. Данный механизм потрясающе работает при взаимодействии двух узлов между собой. Но в современной архитектуре виртуализаций, контейнеризаций, наличии проксей и прочих промежуточных систем, данный механизм имеет существенный недостаток, а именно — невозможность проверки состояния конечного узла при наличии посредника в таком взаимодействии. В случае, если вы совершаете запросы через посредника, TCP keepalive, настроенный на вашей стороне, будет проверять состояние этого посредника. Ну а этот посредник определяет уже состояние конечного узла. В таком случае вам необходимо настраивать параметры TCP keepalive сразу в 3 местах.
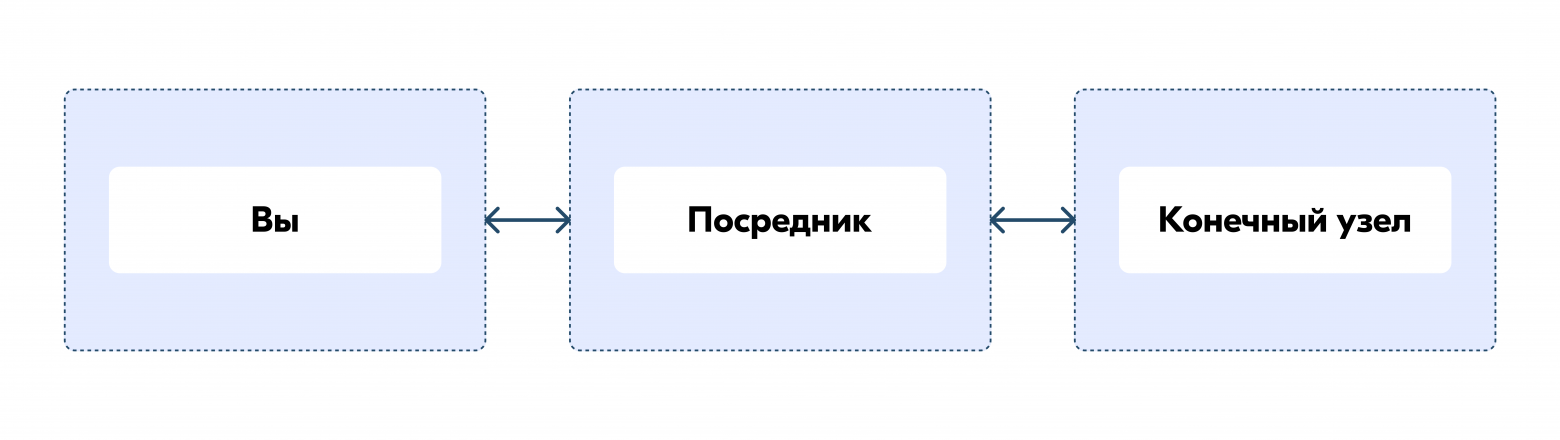

И, поскольку порой этот посредник настраивается кем-то другим, вы своими настройками не можете достоверно определить состояние конечного узла. В linux по умолчанию первый keepalive-запрос отправится спустя 2 часа простоя соединения, и потребуется совершить 9 keepalive probe раз в 75 секунд, только после этого соединение будет помечено как нерабочее. Итого, чтобы определить недоступность конечного узла при настройках по умолчанию, потребуется чуть больше 2 часов и 10 минут, что для более-менее нагруженных систем является крайне медленным результатом.
Небольшой оффтоп: помимо прочего, конкретно в гошке мы обнаружили некоторую особенность настройки L4 keepalive. По умолчанию net-пакет устанавливает параметры TCP keepalive, отличные от настроек linux. Для использования параметров ОС, требуется некоторым иным образом настраивать net.Transport. Более подробно можно почитать тут и тут. МР с добавлением возможности переопределить TCPKeepAliveIdle, TCPKeepAliveInterval и TCPKeepAliveCount тут.
И в таком случае на помощь приходят keepalive на более высоком уровне, а именно — на уровне L7.
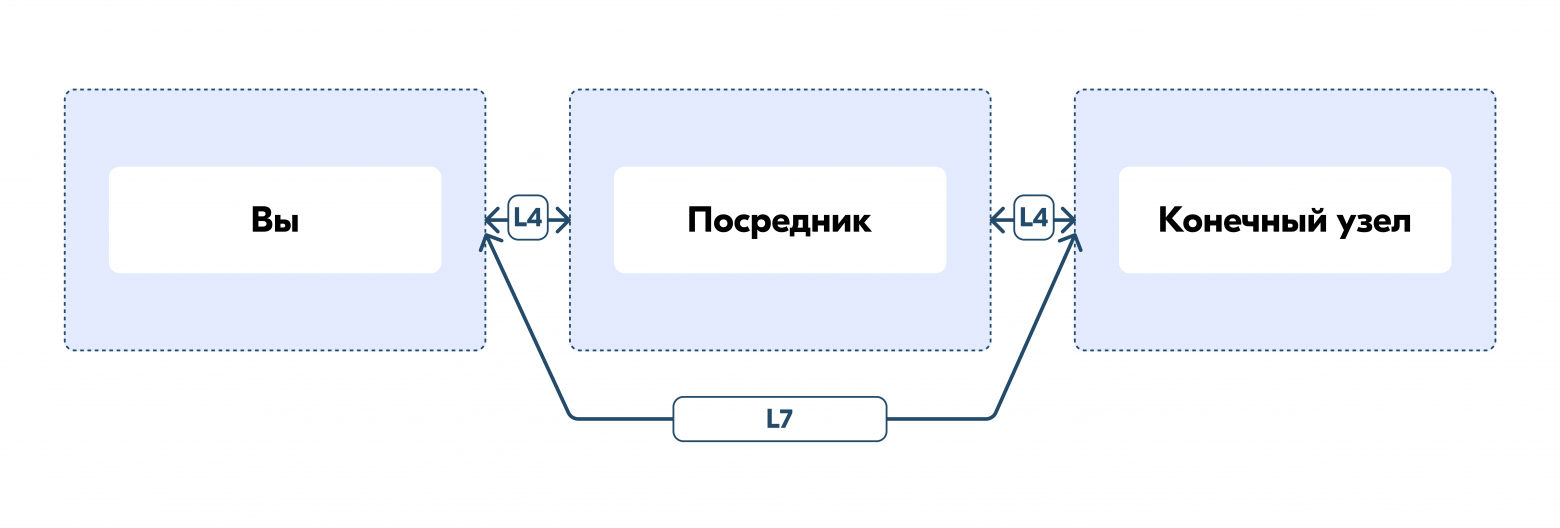
HTTP/2 ping
Данные механизмы реализованы в протоколе HTTP/2 и называются PING.
Такие механизмы позволяют при наличии посредника на L4-уровне проверять статус конечного узла в обход данного посредника.
Коль у нас статья feat. Go, поговорим про реализацию в ней.
Конфигурация ранее описанных параметров в гошке лежит тут. Есть два параметра — ReadIdleTimeout и PingTimeout. Первый параметр отвечает за то, через какое время мы пошлём Ping Frame с тех пор, как перестанем получать какие-либо данные от сервера. PingTimeout — время, через которое мы закроем соединение после отправки ping frame в случае, если не получим ответный ACK-пакет. Исходный код этого механизма можно посмотреть тут.
// ReadIdleTimeout is the timeout after which a health check using ping
// frame will be carried out if no frame is received on the connection.
// Note that a ping response will is considered a received frame, so if
// there is no other traffic on the connection, the health check will
// be performed every ReadIdleTimeout interval.
// If zero, no health check is performed.
ReadIdleTimeout time.Duration
// PingTimeout is the timeout after which the connection will be closed
// if a response to Ping is not received.
// Defaults to 15s.
PingTimeout time.DurationИ, казалось бы, всё хорошо, но реализация в гошке не предусматривает возможность отправки нескольких Ping Frame до закрытия соединения. Хорошо это или плохо — вопрос открытый. Подразумевается, что гарантия доставки пакетов обеспечивается на L4-уровне. На момент старта HTTP2 запускается time.AfterFunc, который через ReadIdleTimeout запустит механизм пинга. Далее в коде есть комментарий: “We don't need to periodically ping in the health check, because the readLoop of ClientConn will trigger the healthCheck again if there is no frame received.”, но тут, судя по всему, речь про то, что в функции healthcheck не требуется запускать пинги несколько раз, поскольку вышестоящий readloop делает это за неё (а в нем time.AfterFunc :) ).
В любом случае, корректная настройка данного механизма позволяет отправлять Ping на L7-уровне, не переживая о том, какая настройка TCP keepalive находится на прокси, через которую осуществляются запросы.

gRPC
Статья у нас также feat. gRPC-Go, поэтому поговорим чуть о нём.
gRPC-Go имеет собственную реализацию HTTP/2-клиента, в связи с чем имеет ряд особенностей и в механизме PING (cудя по всему, произошло это в связи с тем, что реализация в gRPC появилась несколькими месяцами ранее, чем в Go) На стороне конечного узла есть дополнительные настройки, которые могут ограничивать количество пингов со стороны клиента. Называются эти настройки Enforcement policy.
type EnforcementPolicy struct {
// MinTime is the minimum amount of time a client should wait before sending
// a keepalive ping.
MinTime time.Duration // The current default value is 5 minutes.
// If true, server allows keepalive pings even when there are no active
// streams(RPCs). If false, and client sends ping when there are no active
// streams, server will send GOAWAY and close the connection.
PermitWithoutStream bool // false by default.
}Определяются в этих настройках два параметра: минимальное время пинга и разрешение на отправку пингов в случае отсутствия параллельно происходящих запросов. В случае, если клиент нарушает эти настройки, gRPC-библиотека на стороне конечного узла может закрыть соединение с ошибкой too_many_pings. Поэтому для корректной реализации keepalive требуется согласовывать настройки клиента и сервера.
Под спойлером подробное описание
Минимальное время ограничивает то, как часто клиент может отправить пинг. Если клиент начинает слать пинги чаще, чем этот mintime, то сервер через 3 таких пинга закроет соединение с ошибкой too_many_pings. Аналогично с permitWithoutStream, которая разрешает отправку пингов в случае, если клиент в момент совершения пинга не совершает никаких запросов до этого бэкенда. Если у вас малое количество запросов совершается к этому бэкенду, то вы чаще будете попадать в ситуацию, когда пинг будет совершаться без наличия параллельно идущих запросов. Таким образом, если для вас важно быстро обрабатывать такие запросы, без дополнительных ретраев и задержек, следует разрешить keepalive пинги без параллельно идущих запросов. Тогда система будет постоянно опрашивать бэкенд, и когда придёт черёд совершать запрос, система отправит его на достоверно функционирующий бэкенд, не совершая заранее никаких накладных проверок.
НО! В gRPC-Go в случае, если коннект закрывается по ошибке too_many_pings, клиентская часть библиотеки заново откроет соединение, но будет отправлять ping-фреймы в 2 раза реже, чем делала до того, как получила ошибку. В итоге рано или поздно, система автоматически согласует настройки клиента и бэкенда и начнёт отправлять ping-фреймы в соответствии с Enforcement policy.
Выводы
Что касается технической части статьи, PING Frame в реализации HTTP/2 — крайне полезный механизм, но поскольку нет жёстких требований по его конфигурации, может быть реализован в разных системах по-разному. Но если же у вас в вашем соединении есть посредник, и вы не знаете о том, как на нем настроен L4 tcp keepalive (и его конфигурацией занимаетесь не вы), то есть смысл посмотреть в сторону HTTP2-пингов.
Ну, а что касается бизнесовой части — настраивайте keepalive на всех уровнях в ваших системах и не теряйте трафик. Поверьте — это очень неприятно :)
