 Привет, Хаброжители!
Привет, Хаброжители! А мы издали второе издание книги Сэма Ньюмена
По мере того как организации переходят от монолитных приложений к небольшим автономным микросервисам, распределенные системы становятся все более детализированными. Второе дополненное издание предлагает целостный взгляд на самые актуальные темы, в которых необходимо разбираться при создании и масштабировании архитектуры микросервисов, а также управлении ею.
Вы познакомитесь с современными решениями для моделирования, интеграции, тестирования, развертывания и мониторинга собственных автономных сервисов. Примеры из реальной жизни показывают, как получить максимальную отдачу от этих архитектур. Книга будет полезна всем: от архитекторов и разработчиков до тестировщиков и специалистов по эксплуатации.
Кому стоит прочитать эту книгу
Область применения данной книги широка, как и возможности микросервисных архитектур. Таким образом, это издание должно понравиться людям, интересующимся аспектами проектирования, разработки, развертывания, тестирования и обслуживания систем. Те из вас, кто уже вступил на путь создания мелкомодульных архитектур для использования в новых проектах или в рамках декомпозиции существующей монолитной системы, найдут здесь множество практических рекомендаций. Это руководство также поможет тем, кто хочет тщательнее разобраться в микросервисах и наконец определиться в необходимости их применения.
Что изменилось с момента выхода первого издания
Первое издание я писал примерно год, на протяжении 2014 года, а выпущено оно было уже в феврале 2015-го. Это было в самом начале истории микросервисов, по крайней мере с точки зрения понимания этого термина широкими кругами в отрасли. С тех пор микросервисы стали популярны настолько, что я и предположить не мог. Чем популярнее становилась данная отрасль, тем больше появлялось возможностей и технологий для ее реализации.
По мере того как я работал с большим количеством команд после выхода первого издания, я совершенствовал свои знания о микросервисах. Иногда это означало, что идеи, существовавшие только на периферии моего сознания (например, скрытие информации), становились более ясными как основополагающие концепции, требующие более широкого освещения. Иногда новые технологии предоставляют не только новые решения, но и дополнительные сложности. Видя, как много людей стекаются в Kubernetes в надежде, что эта платформа поможет решить все их проблемы с микросервисными архитектурами, я, безусловно, задумался.
Кроме того, я написал первое издание книги «Создание микросервисов», чтобы не только рассказать о микросервисах, но и продемонстрировать, как этот архитектурный подход меняет суть разработки программного обеспечения (ПО). Поэтому, более глубоко изучив вопросы, связанные с безопасностью и отказоустойчивостью, я обнаружил, что хочу подробнее остановиться на тех темах, которые становятся все более важными для современной разработки программного обеспечения.
Таким образом, в этом, втором издании я потратил больше времени на подготовку наглядных примеров. Каждая глава была пересмотрена, и каждое предложение проанализировано. От первого издания осталось не так уж много с точки зрения непосредственно текста, но все идеи сохранились. Я старался излагать свои мысли более ясно, в то же время признавая существование нескольких способов решения проблемы. Это привело к более широкому описанию межпроцессной коммуникации, которое теперь занимает три главы. Я также потратил больше времени на изучение влияния применения таких технологий, как контейнеры, Kubernetes и бессерверные вычисления. В результате теперь есть отдельные главы о сборке и развертывании.
Я надеялся написать книгу примерно того же объема, что и первое издание, и при этом найти способ привести больше деталей. Как видно, мне не удалось достичь своей цели — это издание стало больше! Но я думаю, что смог более четко сформулировать свои идеи.
По мере того как я работал с большим количеством команд после выхода первого издания, я совершенствовал свои знания о микросервисах. Иногда это означало, что идеи, существовавшие только на периферии моего сознания (например, скрытие информации), становились более ясными как основополагающие концепции, требующие более широкого освещения. Иногда новые технологии предоставляют не только новые решения, но и дополнительные сложности. Видя, как много людей стекаются в Kubernetes в надежде, что эта платформа поможет решить все их проблемы с микросервисными архитектурами, я, безусловно, задумался.
Кроме того, я написал первое издание книги «Создание микросервисов», чтобы не только рассказать о микросервисах, но и продемонстрировать, как этот архитектурный подход меняет суть разработки программного обеспечения (ПО). Поэтому, более глубоко изучив вопросы, связанные с безопасностью и отказоустойчивостью, я обнаружил, что хочу подробнее остановиться на тех темах, которые становятся все более важными для современной разработки программного обеспечения.
Таким образом, в этом, втором издании я потратил больше времени на подготовку наглядных примеров. Каждая глава была пересмотрена, и каждое предложение проанализировано. От первого издания осталось не так уж много с точки зрения непосредственно текста, но все идеи сохранились. Я старался излагать свои мысли более ясно, в то же время признавая существование нескольких способов решения проблемы. Это привело к более широкому описанию межпроцессной коммуникации, которое теперь занимает три главы. Я также потратил больше времени на изучение влияния применения таких технологий, как контейнеры, Kubernetes и бессерверные вычисления. В результате теперь есть отдельные главы о сборке и развертывании.
Я надеялся написать книгу примерно того же объема, что и первое издание, и при этом найти способ привести больше деталей. Как видно, мне не удалось достичь своей цели — это издание стало больше! Но я думаю, что смог более четко сформулировать свои идеи.
Реализация коммуникации микросервисов
В поисках идеальной технологии
Существует огромное множество вариантов взаимодействия микросервисов. Но какой из них правильный: SOAP, XML-RPC, REST, gRPC? И всегда появляются новые. Поэтому, прежде чем мы обсудим конкретную технологию, давайте подумаем, чего мы хотим от нее.
Упростите обратную совместимость
При внесении изменений в микросервисы необходимо убедиться, что мы не нарушаем совместимость с любыми потребляющими микросервисами. Таким образом, мы гарантируем, что любая выбираемая технология позволит легко вносить обратно совместимые изменения. Простые операции, вроде добавления новых полей, не должны нарушать работу клиентов. В идеале мы хотим получить возможность проверять внесенные изменения на предмет обратной совместимости и иметь возможность получить эту обратную связь до того, как запустим микросервис в эксплуатацию.
Сделайте свой интерфейс выразительным
Важно, чтобы интерфейс, который микросервис предоставляет внешнему миру, был выразительным, то есть понятным для потребителя. Но это также означает, что разработчику микросервиса должно быть ясно, какая функциональность останется неизменной для внешних потребителей, ведь мы хотим избежать ситуации, в которой изменение микросервиса приводит к случайному нарушению совместимости.
Подобные схемы могут иметь большое значение для обеспечения выразительности интерфейса, предоставляемого микросервисом. Некоторые из рассматриваемых технологий требуют использования схемы, для остальных это необязательно. В любом случае я настоятельно рекомендую использовать выразительную схему, а также подтверждающую документацию, чтобы было ясно, какую функциональность потребитель может ожидать от микросервиса.
Следите за тем, чтобы ваши API не зависели от технологий
Если вы долго работаете в ИТ-индустрии, вам не нужно объяснять, что это быстро меняющаяся сфера. Единственная имеющаяся уверенность — это наличие перемен. Постоянно появляются новые инструменты, фреймворки и языки, реализующие новые идеи, способные помочь работать быстрее и эффективнее. Прямо сейчас у вас может быть магазин, написанный на платформе .NET. Но что будет через год или через пять лет? Что, если вы захотите поэкспериментировать с альтернативным технологическим стеком, который может повысить производительность?
Я думаю, что надо всегда оставаться открытыми для новых возможностей, вот почему я такой поклонник микросервисов. Очень важно сделать так, чтобы API, используемые для связи между микросервисами, не зависели от технологий. Это означает отказ от технологии интеграции, диктующей, какие технологические стеки можно применять для реализации микросервисов.
Сделайте свой сервис простым для потребителей
Необходимо упростить потребителям использование нашего микросервиса. Прекрасно оформленный микросервис не представляет большого значения, если его стоимость заоблачная! Итак, давайте подумаем, что позволит клиентам легко пользоваться нашим замечательным новым сервисом. Было бы идеальным предоставить клиентам полную свободу в выборе технологий. С другой стороны, предоставление клиентской библиотеки может облегчить внедрение. Однако часто такие библиотеки несовместимы с другими функциями, которые мы хотим получить. Например, мы могли бы использовать клиентские библиотеки, чтобы упростить работу для потребителей, но это может усилить связанность.
Скройте детали внутренней реализации
Необходимо, чтобы наши потребители не были привязаны к внутренней реализации, поскольку это приводит к усилению связанности. При попытке что-то преобразовать внутри микросервиса мы рискуем нарушить работу потребителей, ожидая от них внесения изменений. Это увеличивает стоимость, чего мы и пытаемся избежать. Нам с меньшей вероятностью захочется вносить изменения из-за страха обновления потребителей, что может привести к увеличению технического долга в рамках сервиса. Поэтому следует избегать любых технологий, подталкивающих нас к раскрытию внутренних деталей представления.
Выбор технологий
Существует целый ряд технологий, которые можно использовать, но вместо того, чтобы целиком рассматривать длинный список вариантов, я выделю некоторые из наиболее популярных и интересных.
Удаленный вызов процедур
Фреймворки, позволяющие применять локальные вызовы методов в удаленном процессе. Распространенные варианты включают SOAP и gRPC.
REST
Архитектурный стиль, где вы предоставляете ресурсы (Клиент, Заказ и т. д.), к которым можно получить доступ с помощью общего набора команд (GET, POST). В REST немного больше возможностей, и мы скоро вернемся к этой теме.
GraphQL
Относительно новый протокол, позволяющий потребителям определять пользовательские запросы, которые будут извлекать информацию из нескольких нижестоящих микросервисов, фильтруя результаты, чтобы возвращать только требующиеся данные.
Брокеры сообщений
Промежуточное ПО, позволяющее осуществлять асинхронную связь через очереди или топики.
Удаленные вызовы процедур
Удаленный вызов процедур (remote procedure call, RPC) относится к технике реализации локального вызова и его выполнения где-то на удаленном сервисе. Существует несколько различных реализаций RPC. Большая часть технологий в этой области требует явной схемы, применяемой, например, в системах SOAP или gRPC. В контексте RPC схема часто упоминается как язык описания интерфейса (interface definition language, IDL), а SOAP ссылается на свой формат схемы как на язык описания веб-сервисов (web service definition language, WSDL). Использование отдельной схемы упрощает создание клиентских и серверных заглушек для разных технологических стеков. Так, например, у меня мог бы быть сервер Java, предоставляющий интерфейс SOAP, и клиент .NET, созданный на основе одного и того же определения интерфейса WSDL. Другие технологии, такие как Java RMI, требуют более тесной связи между клиентом и сервером, где нужно, чтобы оба использовали одну и ту же базовую технологию, но избегали необходимости в явном определении сервиса, поскольку неявное определение предоставляется определениями типов Java. Однако все эти технологии имеют общую особенность: они делают удаленный вызов похожим на локальный.
Как правило, использование технологии RPC означает, что вы приобретаете протокол сериализации. Фреймворк RPC определяет, как данные сериализуются и десериализуются. Например, gRPC использует для этой цели формат сериализации Protocol buffers. Некоторые реализации привязаны к определенному сетевому протоколу (например, SOAP, номинально использующий HTTP), в то время как другие могут позволить вам применить различные типы сетевых протоколов, предоставляющих дополнительные функции. Например, TCP предлагает гарантии доставки, а UDP — нет, хотя требует гораздо меньших накладных расходов. Таким образом, вы можете выбирать разные сетевые технологии для различных сценариев.
RPC-фреймворки с явной схемой очень упрощают генерацию клиентского кода, что позволяет избежать необходимости в клиентских библиотеках, поскольку любой клиент может запросто сгенерировать свой собственный код в соответствии со спецификацией сервиса. Однако для того, чтобы генерация кода на стороне клиента работала, ему нужен какой-то способ вывести схему. Другими словами, потребитель должен иметь доступ к схеме, прежде чем планировать совершить вызов. Платформа Avro RPC является исключением, поскольку она дает возможность отправлять полную схему вместе с полезной нагрузкой, позволяя клиентам динамически интерпретировать схему.
Простота генерации клиентского кода — одно из основных преимуществ RPC. Возможность вызвать обычный метод и теоретически проигнорировать все остальное — настоящая находка.
Проблемы
Как вы уже поняли, у технологии RPC есть ряд преимуществ, но она не лишена и недостатков. И некоторые реализации RPC могут быть более проблематичными, чем другие. Многие из проблем вполне возможно решить, но они заслуживают дальнейшего изучения.
Технологическая связанность. Некоторые механизмы RPC, такие как Java RMI, сильно привязаны к конкретной платформе, что может ограничить использование технологии на стороне клиента и сервера. Системы Thrift и gRPCобладают впечатляющей поддержкой альтернативных языков, что несколько уменьшает озвученный недостаток. Тем не менее технология RPC иногда имеет ограничения по совместимости.
В некотором смысле эта технологическая связанность может быть формой раскрытия внутренних технических деталей реализации. Например, использование RMI связывает с JVM не только клиент, но и сервер.
Однако стоит отметить, что существует ряд реализаций RPC, не имеющих подобного ограничения, — gRPC, SOAP и Thrift. Все это примеры, обеспечивающие совместимость между различными стеками технологий.
Локальные и удаленные вызовы различаются. Основная идея RPC — скрыть сложность удаленного вызова. Однако не стоит переусердствовать. Необходимо помнить, что удаленные и локальные вызовы методов — это разные вещи, хоть и некоторые формы RPC стремятся их уравнять и скрыть этот факт. Можно совершать большое количество локальных вызовов в процессе, не слишком беспокоясь о производительности. При использовании RPC затраты на маршалинг и анмаршалинг полезных нагрузок могут быть значительными, не говоря уже о времени, необходимом на отправку данных по сети. Это означает, что разработка API для удаленных интерфейсов потребует подхода, отличного от разработки локальных версий. Если вы просто возьмете локальный API и не задумываясь попытаетесь сделать его границей сервиса, скорее всего, у вас возникнут проблемы. В некоторых случаях, если абстракция слишком непрозрачна, разработчики могут использовать удаленные вызовы, даже не подозревая об этом.
Вам нужно подумать о самой сети. Одно из заблуждений о распределенных вычислениях — «Сеть надежна» (https://oreil.ly/8J4Vh). Сети ненадежны. Они могут не сработать, даже если общающиеся клиент и сервер работоспособны. Ожидать стоит чего угодно: моментального выхода из строя, постепенной деградации, даже искажения ваших пакетов. Исходите из того, что ваши сети кишат злонамеренными сущностями, готовыми в любой момент все сломать. В итоге вы столкнетесь с такими типами сбоев, с которыми, возможно, никогда не имели дело в более простом монолитном ПО. Вызвать сбой может как возвращенное удаленным сервером сообщение об ошибке, так и неправильно совершенный вызов. И как в таком случае поступить? А что вы будете делать, если удаленный сервер просто начнет медленно отвечать? Мы рассмотрим эту тему, когда будем говорить об отказоустойчивости в главе 12.
Уязвимость. Некоторые из самых популярных реализаций RPC могут привести к отдельным неприятным формам уязвимости. Java RMI является очень хорошим примером. Давайте рассмотрим довольно простой Java-интерфейс, который мы решили сделать удаленным API для нашего сервиса Покупатель. В примере 5.1 объявлены методы, которые мы собираемся использовать удаленно. Затем Java RMI генерирует клиентские и серверные заглушки для нашего метода.
Пример 5.1. Определение конечной точки сервиса с помощью Java RMI
import java.rmi.Remote;
import java.rmi.RemoteException;
public interface CustomerRemote extends Remote {
public Customer findCustomer(String id) throws RemoteException;
public Customer createCustomer(
String firstname, String surname, String emailAddress)
throws RemoteException;
}В этом интерфейсе функция
createCustomer принимает имя, фамилию и адрес электронной почты. Что произойдет, если мы разрешим создание объекта Customer (Покупатель), используя только адрес электронной почты? На этом этапе можно довольно легко добавить новый метод, например:...
public Customer createCustomer(String emailAddress) throws RemoteException;
...Проблема в том, что теперь клиентам, желающим использовать новый метод, понадобятся новые серверные заглушки. И в зависимости от характера изменений в спецификации, потребителям, которым новый метод не нужен, также придется их использовать. Конечно, с этим можно справиться, но только до определенного момента. Подобные изменения происходят довольно часто. Конечные точки RPC нередко содержат большое количество методов для различных способов создания объектов или взаимодействия с ними. Отчасти это связано с тем, что мы все еще думаем об этих удаленных вызовах как о локальных.
Однако есть и другой вид уязвимости. Давайте посмотрим, как выглядит объект
Customer:public class Customer implements Serializable {
private String firstName;
private String surname;
private String emailAddress;
private String age;
}Что, если поле
age (возраст) в наших объектах Customer окажется невостребованным ни одним из наших потребителей? Логично было бы удалить его. Но если в серверной реализации убрать поле age из определения этого типа, и не сделать то же самое для всех потребителей, то даже если они никогда не использовали это поле, код, связанный с десериализацией объекта Customer на стороне потребителя, будет нарушен. Чтобы внедрить данное изменение, нам потребуется преобразовать код клиента для поддержки нового определения и развернуть эти обновленные клиенты одновременно с развертыванием новой версии сервера. Это ключевая проблема любого механизма RPC, который поощряет использование двоичной генерации заглушек: вы не можете разделить развертывание клиента и сервера. Если вы используете эту технологию, в будущем станете заложником жестко регламентированного порядка выпуска релизов.Похожие проблемы возникают при необходимости перестроить объект
Customer, даже если поля не удалялись. Например, если мы хотим инкапсулировать поля firstName и surname в новый тип naming для упрощения управления. Мы могли бы, конечно, передать типы словарей в качестве параметров наших вызовов, но на данном этапе теряются многие преимущества сгенерированных заглушек, потому что нам все равно придется вручную сопоставлять и извлекать нужные поля.На практике объекты, используемые как часть двоичной сериализации при передаче данных по сети, стоит рассматривать как типы «только для расширения». Эта уязвимость приводит к тому, что типы подвергаются воздействию процесса передачи по сети и превращаются в массу полей, часть из которых больше не используются, но и не могут быть безопасно удалены.
Где использовать
Несмотря на недостатки, мне все равно очень нравится RPC, а его более современные реализации, такие как gRPC, превосходны, в то время как у аналогов имеются существенные проблемы. У Java RMI, например, есть ряд проблем, связанных с уязвимостью и ограниченным выбором технологий, а SOAP довольно тяжеловесен с точки зрения разработчика, особенно по сравнению с более современными вариантами.
Просто имейте в виду некоторые потенциальные подводные камни, связанные с RPC, если собираетесь выбрать эту модель. Не абстрагируйте свои удаленные вызовы до такой степени, чтобы сеть была полностью скрыта, и убедитесь, что сохраняется возможность развивать интерфейс сервера без необходимости настаивать на поэтапном обновлении для клиентов. Например, важно найти правильный баланс для вашего клиентского кода. Убедитесь, что клиенты не забывают о сетевом вызове. Клиентские библиотеки часто используются в контексте RPC, и при неправильном структурировании они могут вызвать проблемы. Вскоре мы поговорим о них подробнее.
Если бы я рассматривал варианты из этой области, gRPC был бы в топе моего списка. Он позволяет использовать преимущества HTTP/2, обладает некоторыми впечатляющими характеристиками производительности и в целом прост в работе. Я также ценю gRPC за выстроенную экосистему, включая такие инструменты, как Protolock (https://protolock.dev). Их мы обсудим позже в этой главе, когда будем говорить о схемах.
Платформа gRPC хорошо подходит для синхронной модели «запрос — ответ», но также в состоянии работать с реактивными расширениями. Она занимает первое место в моем списке во всех случаях, когда у меня выстроен грамотный контроль как над клиентскими, так и над серверными конечными точками. Если появляется необходимость поддерживать широкий спектр других приложений, которым может потребоваться взаимодействие с вашими микросервисами, компиляция клиентского кода в соответствии со схемой на стороне сервера может стать проблемой. В этом случае, скорее всего, лучше подойдет какая-либо форма REST API через HTTP.
REST
Передача репрезентативного состояния (representational state transfer, REST) — это архитектурный стиль, вдохновленный Интернетом. В основе REST лежит множество принципов и ограничений, но мы сосредоточимся на том, что действительно помогает в решении проблем интеграции микросервисов и при поиске альтернативы RPC для интерфейсов сервисов.
Самое важное в REST — это концепция ресурсов. Представьте себе ресурсы как что-то, что знает сам сервис, например объект
Customer. Сервер создает различные представления Customer по запросу. Внешнее отображение ресурса полностью отделено от способа его хранения внутри системы. Например, клиент может запросить JSON-представление объекта Customer, даже если оно хранится в совершенно другом формате. Как только клиент получает представление Customer, он может отправлять запросы на его изменение, а сервер может выполнять их или нет.Существует много различных стилей REST, и я лишь вкратце коснусь их здесь. Настоятельно рекомендую вам взглянуть на модель зрелости Ричардсона (https://oreil.ly/AlDzu), где сравниваются различные стили REST.
REST чаще всего он работает через HTTP. Некоторые функции, предоставляемые протоколом HTTP как часть спецификации, упрощают реализацию REST, в то время как с другими протоколами вам придется обрабатывать эти функции самостоятельно.
REST и HTTP
Сам HTTP определяет ряд полезных возможностей, которые очень хорошо сочетаются с REST. Например, методы HTTP-запросов (такие как GET, POST и PUT) уже содержат хорошо понятные значения в спецификации HTTP относительно того, как они должны работать с ресурсами. Архитектурный стиль REST на самом деле позволяет этим методам вести себя одинаково на всех ресурсах, а спецификация HTTP определяет набор доступных для использования команд. Например, GET извлекает ресурс идемпотентным способом, а POST создает новый ресурс. Это означает, что нам удастся избежать множества различных методов createCustomer или editCustomer. Теперь мы можем с помощью метода POST просто отправить представление клиента, чтобы запросить у сервера создание нового ресурса, а затем инициировать запрос GET для получения представления ресурса. Концептуально в этих случаях существует одна конечная точка в виде ресурса Customer, и операции, которые мы можем выполнять с ним, записываются в протокол HTTP.
HTTP также предоставляет обширную экосистему вспомогательных инструментов и технологий. Имеется возможность применять прокси-серверы кэширования HTTP, например Varnish, балансировщики нагрузки mod_proxy и многие инструменты мониторинга, уже с поддержкой HTTP. Эти инструменты позволяют обрабатывать большие объемы HTTP-трафика и маршрутизировать их разумно и довольно прозрачно. Допускается также использовать все доступные средства контроля безопасности с помощью HTTP для защиты способов коммуникации. Начиная с базовой аутентификации и заканчивая сертификатами клиентов, экосистема HTTP предоставляет множество инструментов для упрощения процесса обеспечения безопасности (подробнее рассмотрим эту тему в главе 11). Тем не менее, чтобы получить эти преимущества, необходимо эффективно использовать протокол HTTP. В противном случае он может быть таким же небезопасным и трудным для масштабирования, как и любая другая существующая технология.
Обратите внимание, что HTTP может применяться и для реализации RPC. Протокол SOAP, например, маршрутизируется по HTTP, но, к сожалению, он использует очень мало спецификаций. Команды игнорируются, как и коды ошибок HTTP. С другой стороны, gRPC был разработан специально для раскрытия потенциала HTTP/2, например для отправки нескольких потоков «запрос — ответ» по одному соединению. Однако при использовании gRPC вам недоступен REST из-за применения HTTP!
Гипермедиа как движок состояния приложения
Еще один принцип REST, способный помочь избежать связанности между клиентом и сервером, — это концепция гипермедиа как двигатель состояния приложения (часто сокращается как HATEOAS — от hypermedia as the engine of application state). Это довольно сложная формулировка, но сама концепция интересная, поэтому давайте немного разберем ее.
Гипермедиа — это расширение так называемого гипертекста или возможность открывать новые веб-страницы через ссылки на другие данные в различных форматах (например, текст, изображения, звуки). Идея, лежащая в основе HATEOAS, заключается во взаимодействии клиентов с сервером (потенциально приводящим к переходам состояний) через ссылки на другие ресурсы. Клиенту не нужно знать, где именно на сервере содержится необходимая информация. Вместо этого он использует ссылки и перемещается по ним, чтобы найти то, что ему нужно.
Это не совсем обычная концепция, поэтому сделаем шаг назад и рассмотрим, как люди взаимодействуют с веб-страницей с элементами управления гипермедиа.
Вспомните сайт Amazon.com. Расположение корзины покупок менялось с течением времени. Изменилась графика, ссылка. Тем не менее мы понимаем, что такое корзина, и по-прежнему можем взаимодействовать с ней, даже если точная форма и основной элемент управления, используемый для ее представления, изменились. Вот как веб-страницы могут постепенно меняться с течением времени. До тех пор пока этот негласный договор между клиентом и веб-сайтом по-прежнему соблюдается, изменения не обязательно должны быть критическими.
С помощью средств управления гипермедиа мы пытаемся достичь такого же уровня понятности для наших электронных потребителей. Рассмотрим элемент управления гипермедиа, который мы могли бы использовать для MusicCorp. В нашем распоряжении имеется доступ к ресурсу, представляющему запись каталога для заданного альбома в примере 5.2. Наряду с информацией об альбоме мы видим ряд элементов управления гипермедиа.
Пример 5.2. Элементы управления гипермедиа, используемые в списке альбомов
<album>
<name>Give Blood</name>
<link rel="/artist" href="/artist/theBrakes" /> (1)
<description>
Awesome, short, brutish, funny and loud. Must buy!
</description>
<link rel="/instantpurchase" href="/instantPurchase/1234" /> (2)
</album>(1) Данный элемент управления гипермедиа показывает, где находится информация об исполнителе.
(2) Если мы хотим купить альбом, теперь известно, где искать.
В этом примере есть два элемента управления гипермедиа. Клиент должен знать, что для получения информации об исполнителе ему необходимо перейти к элементу управления, связанному с artist, и что
instantpurchase (мгновенная покупка) представляет собой часть протокола, используемого для покупки альбома. В данном случае семантика API во многом похожа на корзину с сайта покупок — это место хранения приобретаемых товаров.Как клиенту, мне не обязательно знать, к какой схеме URI получить доступ, чтобы купить альбом. Мне всего лишь нужно зайти на сайт, найти элемент управления покупкой и перейти к нему. Местоположение элемента управления покупкой может измениться, как и сам URI, а сайт вообще может направить меня на другой сервис, но мне как покупателю должно быть все равно. Это дает нам огромное снижение связанности между клиентом и сервером.
Здесь мы сильно абстрагируемся от базовых деталей. Допустимо было бы полностью изменить представление элемента управления, пока он все еще соответствует пониманию клиента, точно так же, как элемент управления корзиной покупок может превратиться из простой ссылки в более сложный элемент. Можно также свободно добавлять дополнительные элементы управления, возможно представляющие новые переходы состояний, которые мы способны выполнять на рассматриваемом ресурсе. Если бы мы коренным образом изменили семантику одного из элементов управления, чтобы он вел себя совсем по-другому, или если бы вообще его удалили, то в итоге нарушили бы работу наших потребителей.
Теоретически, используя эти элементы управления для разделения клиента и сервера, мы получаем значительные преимущества, компенсирующие увеличение времени, которое необходимо для запуска и начала эксплуатации этих протоколов. В теории все эти идеи кажутся разумными, однако на практике оказывается, что такая форма REST редко используется. Поэтому концепцию HATEOAS гораздо сложнее популяризировать среди тех, кто уже привержен использованию REST. По сути, многие идеи в REST основаны на создании распределенных гиперпространственных систем, а это не то, чем занимается большинство людей.
Проблемы
С точки зрения простоты использования исторически сложилось так, что нельзя генерировать код на стороне клиента для вашего REST через HTTP протокола приложения, в отличие от RPC. Это часто приводило к тому, что люди создавали REST API, предоставляющие пользователям клиентские библиотеки для использования. Эти клиентские библиотеки осуществляют привязку к API, чтобы упростить интеграцию с клиентом. Проблема заключается в том, что клиентские библиотеки могут вызывать определенные трудности во взаимодействии между клиентом и сервером. Мы обсудим это в разделе «DRY и опасности повторного использования кода в мире микросервисов» этой главы.
В последние годы эта проблема была отчасти решена. Спецификация OpenAPI (https://oreil.ly/Idr1p), выросшая из проекта Swagger, теперь предоставляет возможность определять достаточно информации о конечной точке REST, чтобы обеспечить генерацию клиентского кода на различных языках. Я лично не встречал команды, которые действительно бы использовали эту функциональность, даже если они уже применяли Swagger для документации. Мне кажется, что это связано с трудностями его адаптации к текущим API. У меня также есть опасения по поводу спецификации, которая ранее использовалась только для документации, а теперь применяется для определения более явного контракта.
Это может привести к гораздо более сложной спецификации: например, сравнение схемы OpenAPI со схемой Protocol buffers представляет собой довольно резкий контраст. Однако, несмотря на мои сомнения, хорошо, что этот вариант в принципе существует.
Производительность также может оказаться слабым звеном. Полезные нагрузки REST через HTTP на самом деле могут быть более компактными, чем SOAP, так как REST поддерживает альтернативные форматы, такие как JSON или даже бинарный, но он все равно далеко не такой экономичный, каким мог бы быть Thrift. Накладные расходы HTTP для каждого запроса также могут быть проблемой из-за требований к низкой задержке. Все основные протоколы HTTP, используемые в настоящее время, требуют применения протокола передачи данных (Transmission Control Protocol, TCP), который неэффективен по сравнению с другими сетевыми протоколами, а некоторые реализации RPC позволяют применять альтернативные TCP сетевые протоколы, такие как протокол пользовательских датаграмм (User Datagram Protocol, UDP).
Ограничения, накладываемые на HTTP из-за требования использовать TCP, устраняются. Протокол HTTP/3, который в настоящее время находится в процессе доработки, стремится перейти на использование более нового протокола QUIC. QUIC предоставляет те же возможности, что и TCP (например, улучшенные гарантии по сравнению с UDP), но с некоторыми существенными доработками, обеспечивающими снижение задержки и сокращение пропускной способности. Вероятно, пройдет несколько лет, прежде чем HTTP/3 окажет обширное влияние на Всемирную сеть, но, скорее всего, организации извлекут из этого выгоду раньше, чем HTTP/3 появится в их собственных сетях.
Что касается конкретно HATEOAS, вы гарантированно столкнетесь с дополнительными проблемами производительности. Поскольку клиентам необходимо переходить от одного элемента управления к другому, чтобы найти правильные конечные точки для совершаемой операции, это может привести к появлению очень сложных протоколов — для каждой операции потребуется несколько проходов по всем элементам управления. В конечном счете это компромисс. Если вы решите использовать REST в стиле HATEOAS, я бы посоветовал начать с того, чтобы ваши клиенты в первую очередь переходили по этим элементам управления, а при необходимости позже их можно оптимизировать. Помните, что HTTP предоставляет нам большой инструментарий «из коробки», о чем мы говорили выше. Недостатки преждевременной оптимизации были хорошо задокументированы ранее, поэтому не стоит подробно останавливаться на них здесь. Обратите также внимание, что не все из этих методов подойдут, так как большинство из них было разработано для создания распределенных гипертекстовых систем. Иногда вы можете поймать себя на мысли, что вам просто нужен старый добрый RPC.
Несмотря на эти минусы, REST через HTTP представляется разумным стандартным выбором для взаимодействия между сервисами. Если вы хотите узнать больше, я рекомендую книгу REST in Practice: Hypermedia and Systems Architecture (O’Reilly) от Джима Веббера, Саваса Парастатидиса и Иэна Робинсона, в которой подробно рассматривается тема REST по протоколу HTTP.
Где использовать
API на основе REST через HTTP представляется очевидным выбором для синхронного интерфейса по модели «запрос — ответ», если вы хотите разрешить доступ как можно большему количеству клиентов. Было бы ошибкой представлять себе REST API просто как выбор, «достаточно хороший для большинства ситуаций», однако в этом что-то есть. Это понятный стиль интерфейса, с которым многие знакомы, и он гарантирует совместимость с огромным разнообразием технологий.
Благодаря возможностям HTTP и степени, в которой REST использует эти возможности (а не скрывает их), API на основе REST превосходны в ситуациях, требующих крупномасштабного и эффективного кэширования запросов. Именно по этой причине они стали очевидным выбором для предоставления API внешним потребителям или клиентским интерфейсам. Однако они могут проигрывать по сравнению с более эффективными протоколами связи, и, хотя допустимо создавать протоколы асинхронного взаимодействия поверх API на основе REST, это не совсем подходящий вариант по сравнению с альтернативами для общего взаимодействия между микросервисами.
Несмотря на ясность целей HATEOAS, я не видел достаточно доказательств того, что дополнительная работа по внедрению этого стиля REST приносит ощутимые выгоды в долгосрочной перспективе. И не могу вспомнить, чтобы за последние несколько лет я разговаривал с какими-либо специалистами, внедряющими микросервисную архитектуру, которые сообщили бы о целесообразности использования HATEOAS. Очевидно, что мой собственный опыт — это нерепрезентативная выборка, и я не сомневаюсь, что для некоторых людей HATEOAS, возможно, стал очень подходящим вариантом. Но эта концепция не особо прижилась. Возможно, идеи, лежащие в основе HATEOAS, слишком чужды для нашего понимания, а может быть, роль сыграло отсутствие инструментов или стандартов в этой области, или, вероятно, модель просто не работает для созданных нами в итоге систем. Конечно, также возможно, что концепции, лежащие в основе HATEOAS, на самом деле плохо сочетаются с методами создания микросервисов.
Так что в узкоспециализированном использовании эта концепция работает фантастически хорошо, и для синхронной связи по модели «запрос — ответ» между микросервисами она великолепна.
GraphQL
В последние годы язык GraphQL (https://graphql.org) приобрел большую популярность во многом благодаря тому, что он позволяет устройству на стороне клиента определять вызовы, способные избежать выполнения нескольких запросов для получения одной и той же информации. Это может значительно улучшить производительность ограниченных по производительности клиентских устройств, а также поможет избежать необходимости внедрять индивидуальную агрегацию на стороне сервера.
В качестве простого примера представьте мобильное устройство, которому нужно отобразить страницу с обзором последних заказов клиента. Страница должна содержать некоторую информацию о клиенте, а также информацию о его пяти последних заказах. На экране требуется показать всего несколько полей из записи клиента: дату, стоимость и статус доставки каждого заказа. Мобильное устройство может отправлять вызовы двум нижестоящим микросервисам для получения необходимой информации, но для этого понадобится выполнить несколько вызовов, включая извлечение информации, которая на самом деле необязательна. Это может быть расточительно: на такие операции расходуется больше средств тарифного плана мобильного устройства, чем необходимо, и может занять больше времени.
GraphQL позволяет выдавать один запрос, способный извлекать всю необходимую информацию. Чтобы это сработало, нужен микросервис, предоставляющий конечную точку GraphQL клиентскому устройству. Эта точка GraphQL служит входом для всех клиентских запросов и предлагает схему для использования клиентскими устройствами. Такая схема предоставляет типы, доступные клиенту, а также удобный графический конструктор запросов, упрощающий их создание. Уменьшая количество вызовов и объем данных, извлекаемых клиентским устройством, вы можете аккуратно решать некоторые проблемы, возникающие при создании пользовательских интерфейсов с микросервисными архитектурами.
Проблемы
На раннем этапе одной из проблем было отсутствие языковой поддержки спецификации GraphQL, и единственным выбором изначально был JavaScript. В этом плане произошел серьезный рывок, поскольку все основные технологии теперь поддерживают эту спецификацию. На самом деле произошли значительные улучшения в GraphQL и различных реализациях по всем направлениям, что сделало применение GraphQL гораздо менее рискованной перспективой, чем это было несколько лет назад. Тем не менее вам стоит знать об оставшихся проблемах.
Для начала клиентское устройство может выдавать динамически изменяющиеся запросы, и бывают команды, у которых возникают проблемы с запросами GraphQL, вызывающими значительную нагрузку на серверную часть. При сравнении GraphQL с чем-то вроде SQL мы видим аналогичную проблему. Ресурсоемкий SQL-запрос может вызвать значительные проблемы для базы данных и потенциально оказать серьезное влияние на систему в целом. Та же проблема возникает и с GraphQL. Разница в том, что при использовании SQL применяются такие инструменты, как планировщики запросов для БД, которые помогают диагностировать проблемные запросы, в то время как аналогичный недостаток с GraphQL сложнее отследить. Регулирование запросов на стороне сервера — одно из потенциальных, но непростых решений, поскольку выполнение вызова может быть распределено между несколькими микросервисами.
Кэширование оказывается более сложным по сравнению с обычными HTTP-API на основе REST. При использовании API на основе REST можно задать один из множества ответов заголовков, чтобы помочь клиентским устройствам или промежуточным кэшам, таким как сети доставки контента (content delivery networks, CDNs), кэшировать ответы, чтобы их не нужно было запрашивать снова. При использовании GraphQL организовать процесс таким же образом невозможно. Советы по этому вопросу сводятся к тому, чтобы просто связать идентификатор с каждым возвращаемым ресурсом (и помните: запрос GraphQL может содержать несколько ресурсов), а затем заставить клиентское устройство кэшировать запрос по этому идентификатору. Насколько я могу судить, без лишней работы это делает использование CDN или кэширование обратных прокси невероятно сложным.
Хотя я видел некоторые решения данной проблемы, зависящие от конкретной реализации (например, обнаруженные в JavaScript Apollo), кэширование, похоже, было сознательно или бессознательно проигнорировано на этапе первоначальной разработки GraphQL. Если отправляемые вами запросы очень специфичны по своей природе для конкретного пользователя, то отсутствие кэширования на уровне запроса не может стать препятствием для контракта, поскольку коэффициент попадания в кэш, скорее всего, будет низким. Однако мне интересно, означает ли это ограничение, что вы все равно получите гибридное решение для клиентских устройств, где одни (более общие) запросы будут выполняться через обычные HTTP-API на основе REST, а другие — через GraphQL.
Еще одна проблема заключается в том, что, хотя GraphQL теоретически способен обрабатывать процесс записи, он подходит для этого не так хорошо, как для чтения. Это приводит к ситуациям, в которых команды используют GraphQL для чтения, а REST — для записи.
Последний вопрос может показаться совершенно субъективным, но я все же думаю, что его стоит поднять. GraphQL дарит вам ощущение, что вы просто работаете с данными. Это может укрепить мнение о том, что микросервисы, с которыми вы взаимодействуете, представляют собой всего лишь оболочки баз данных. Я видел, как несколько человек сравнивали GraphQL с Odata — технологией, разработанной как универсальный API для доступа к данным из БД. Идея рассматривать микросервисы просто как оболочку баз данных может иметь негативные последствия. Микросервисы предоставляют функциональные возможности через сетевые интерфейсы. Некоторые из этих функций могут привести к раскрытию данных или потребовать сделать это, но они все равно должны содержать свою собственную внутреннюю логику и поведение. Не стоит думать, что ваши микросервисы — это не более чем API для базы данных, только потому, что вы используете GraphQL. Очень важно, чтобы GraphQL API не был связан с базовыми хранилищами данных ваших микросервисов.
Где использовать
Лучшее место для использования GraphQL — по периметру системы, где предоставляется функциональность внешним клиентам. Эти клиенты, как правило, представляют собой графические интерфейсы, и такое решение подходит для мобильных устройств, учитывая их ограниченные возможности по передаче данных конечному пользователю и характер мобильных сетей. Но GraphQL также используется для внешних API, и сервис GitHub стал одним из первых последователей GraphQL. Если у вас есть внешний API, который часто требует от внешних клиентов совершать множество вызовов для получения необходимой им информации, то GraphQL поможет сделать API намного более эффективным и удобным.
По сути, GraphQL — это механизм агрегации и фильтрации вызовов, поэтому в контексте микросервисной архитектуры он будет использоваться для агрегирования вызовов нескольких нижестоящих микросервисов. Сам по себе он не может служить заменителем общей коммуникации между микросервисами.
Альтернативой использованию GraphQL может стать шаблон «Бэкенд для фронтенда» (Backend for Frontend, BFF), который мы рассмотрим, а также сравним с GraphQL и другими методами агрегации в главе 14.
Брокеры сообщений
Брокеры сообщений — это посредники, часто называемые промежуточным ПО, находящиеся между процессами для управления связью между ними. Они стали популярным вариантом выбора для реализации асинхронной связи, поскольку предлагают множество мощных возможностей.
Как обсуждалось ранее, сообщение — это общее понятие, определяющее то, что отправляет брокер. Сообщение может содержать запрос, ответ или событие. Вместо того чтобы напрямую связываться с другим микросервисом сервис передает брокеру сообщение с информацией о том, как оно должно быть отправлено.
Топики и очереди
Брокеры, как правило, предоставляют либо очереди, либо топики, либо и то и другое. Очереди обычно бывают точечными. Отправитель помещает сообщение в очередь, а потребитель считывает его из этой очереди. В топик-ориентированной системе несколько пользователей могут подписаться на топик, чтобы получить копию этого сообщения.
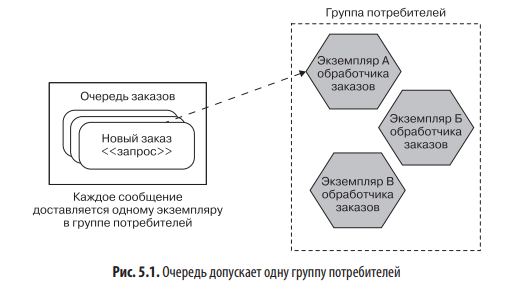
Потребитель может представлять собой один или несколько микросервисов, обычно моделируемых как группа потребителей. Это может быть полезно, если у вас имеется несколько экземпляров микросервиса и вы хотите, чтобы любой из них мог получить сообщение. На рис. 5.1 показан пример, в котором у сервиса Обработчик заказов есть три развернутых экземпляра, входящих в одну группу потребителей. Когда сообщение помещается в очередь, только один член группы получит его. Это означает, что очередь работает как механизм распределения нагрузки. Это пример модели конкурирующих потребителей, мы кратко затронули ее в главе 4.
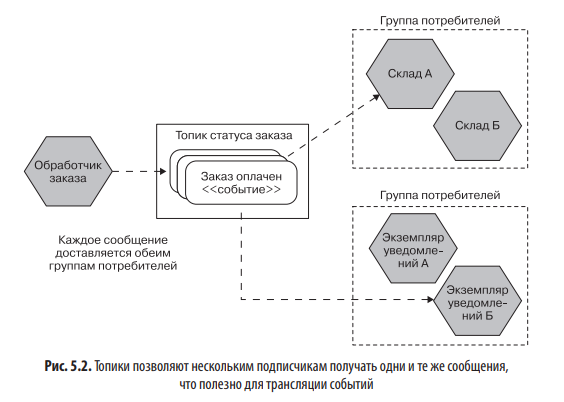
С помощью топиков можно создать несколько групп потребителей. На рис. 5.2 событие, представляющее оплачиваемый заказ, помещается в топик Статус заказа. Копия этого события принимается как микросервисом Склад, так и сервисом Уведомления, которые находятся в отдельных группах потребителей. Только один экземпляр каждой группы потребителей увидит это событие.
На первый взгляд очередь выглядит просто как топик с одной группой потребителей. Основное различие между ними заключается в том, что, когда сообщение отправляется через очередь, сохраняется информация, кому оно предназначено. В случае с топиком эта информация скрыта от отправителя — он не знает, кто (если таковой блок вообще будет) в конечном счете получит сообщение.
Топики хорошо подходят для событийного сотрудничества, в то время как очереди больше для коммуникации в стиле «запрос — ответ». Однако это следует рассматривать как общее руководство, а не как строгое правило.
Гарантированная доставка
Так зачем же использовать брокеры? По сути, они предоставляют некоторые возможности, которые могут быть очень полезны для асинхронной связи. Предоставляемые ими свойства различаются, но наиболее интересной особенностью для нас будет гарантированная доставка, которую так или иначе поддерживают все широко используемые брокеры. Гарантированная доставка описывает обязательство брокера обеспечить доставку сообщения.
С точки зрения микросервиса, отправляющего сообщение, это может быть очень полезно. Если нижестоящий адресат недоступен, брокер будет удерживать сообщение до тех пор, пока доставка не осуществится, что уменьшит количество проблем для вышестоящего микросервиса. Сравните этот процесс с синхронным прямым вызовом. Например, с HTTP-запросом: если нижестоящий адресат недоступен, вышестоящему микросервису необходимо решить, что делать с запросом: повторить вызов или отказаться?
Чтобы гарантированная доставка работала, брокер должен обеспечить хранение всех еще не доставленных сообщений в надежном месте до тех пор, пока они не будут доставлены. Чтобы выполнить это обязательство, брокер обычно работает как своего рода кластерная система, гарантируя, что потеря одного компьютера не приведет к потере сообщения. Как правило, для стабильной работы брокера требуется выполнить большой объем работ, отчасти из-за проблем с управлением программным обеспечением на основе кластеров. Часто обязательство гарантированной доставки может быть нарушено, если брокер настроен неправильно. Например, для RabbitMQ необходимо, чтобы экземпляры в кластере обменивались данными по сетям с относительно низкой задержкой. В противном случае экземпляры могут начать путаться в текущем состоянии обрабатываемых сообщений, что приведет к потере данных. Я не говорю, что RabbitMQ из-за этого плох, у всех брокеров есть ограничения относительно того, как их нужно запускать, чтобы обеспечить гарантированную доставку. Если вы планируете запустить собственный брокер, обязательно изучите документацию.
Стоит также отметить, что понятие гарантированной доставки у каждого конкретного брокера может варьироваться. Опять же, чтение документации — отличная отправная точка в изучении этой особенности.
Доверие
Гарантированная доставка — одно из главных преимуществ брокера. Но для того, чтобы это свойство работало, вам нужно доверять не только людям, которые создали брокер, но и тому, как этот брокер работает. Если вы разработали систему, основанную на предположении, что доставка гарантирована, а это оказывается не так из-за проблемы с базовым брокером, то могут возникнуть серьезные проблемы. Остается надеяться, что вы перекладываете эту работу на ПО, созданное людьми, которые могут решать эту задачу лучше вас. В конечном счете вы должны решить, насколько доверять используемому брокеру.
Другие характеристики
Брокеры полезны не только благодаря гарантированной доставке.
Большинство из них могут гарантировать порядок доставки сообщений, но даже в этом случае объем подобной гарантии ограничен. Например, в Kafka порядок гарантируется только в пределах одного раздела. Если нет уверенности, что сообщения будут получены по порядку, вашему потребителю может потребоваться компенсация, возможно, путем отсрочки обработки сообщений, полученных не по порядку, до тех пор, пока не поступят все пропущенные сообщения.
Некоторые брокеры предоставляют транзакции при записи. Например, Kafka позволяет записывать сообщения в несколько топиков за одну транзакцию. Многие брокеры также могут обеспечивать транзакцию чтения, чем я воспользовался при применении ряда брокеров через API Java Message Service (JMS). Это полезно, если вы хотите убедиться, что сообщение может быть обработано потребителем, прежде чем удалять его у брокера.
Еще одна, несколько спорная, функция, обещанная некоторыми брокерами, — однократная доставка. Один из самых простых способов обеспечить гарантированную доставку — разрешить повторную отправку сообщения. Это может привести к тому, что потребитель увидит одно и то же сообщение несколько раз (даже если это редкая ситуация). Большинство брокеров сделают все возможное, чтобы уменьшить такую вероятность или скрыть этот факт от потребителя, но некоторые брокеры продвинуты настолько, что гарантируют доставку сообщения только один раз. Это сложная тема. Я общался с некоторыми экспертами, которые утверждают, что гарантировать подобную функцию во всех случаях невозможно. В то же время другие эксперты утверждают, что в принципе это можно реализовать с помощью нескольких простых обходных путей. В любом случае, если выбранный вами брокер утверждает, что способен на однократную доставку, обратите пристальное внимание на то, как это реализовано. А еще лучше построить свои потребители таким образом, чтобы они были готовы к получению сообщения более одного раза и могли справиться с этой ситуацией. Очень простой пример: каждому сообщению присваивается идентификатор, который потребитель проверяет при каждом получении сообщения. Если сообщение с таким идентификатором уже было обработано, то новое может быть проигнорировано.
Варианты выбора
Существует множество брокеров сообщений. К популярным примерам относятся RabbitMQ, ActiveMQ и Kafka (который мы вскоре рассмотрим подробнее). Основные поставщики публичных облачных сервисов также предоставляют множество продуктов, выполняющих функции брокера: от управляемых версий этих брокеров, которые вы можете установить в своей собственной инфраструктуре, до индивидуальных реализаций, специфичных для конкретной платформы. Например, в AWS есть Simple Queue Service (SQS), Simple Notification Service (SNS) и Kinesis, предоставляющие различные варианты полностью управляемых брокеров. Фактически SQS был вторым в истории продуктом, выпущенным AWS, который был запущен еще в 2006 году.
Kafka
Kafka стоит выделить в качестве особого брокера, учитывая его популярность в последнее время. Отчасти она объясняется возможностью Kafka перемещать большие объемы данных в рамках реализации конвейеров потоковой обработки. Это может помочь перейти от пакетной обработки к обработке в режиме реального времени.
Отдельного внимания заслуживают некоторые особенности Kafka. Во-первых, этот инструмент рассчитан на очень большие масштабы — он был разработан в LinkedIn, чтобы заменить несколько существующих кластеров сообщений единой платформой. Kafka позволяет работать с множеством потребителей и производителей. Я общался с одним экспертом из крупной технологической компании, у которого более 50 000 производителей и потребителей работали в одном кластере. Честно говоря, очень немногие организации сталкиваются с проблемами при таком масштабе, но для некоторых компаний возможность легко масштабировать Kafka (условно говоря) может быть очень полезной.
Во-вторых, Kafka — это постоянство сообщений. Обычный брокер сообщений не хранит сообщение, как только последний потребитель получил его. С Kafka сообщения могут храниться в течение настраиваемого периода или вообще вечно. Такой подход дает возможность потребителям повторно отправлять уже обработанные ими сообщения или разрешает вновь развернутым потребителям обрабатывать отправленные ранее сообщения.
Наконец, Kafka внедряет встроенную поддержку потоковой обработки. Вместо того чтобы использовать Kafka для отправки сообщений в специальный инструмент обработки потоков, такой как Apache Flink, теперь появилась возможность некоторые задачи выполнять внутри Kafka. Используя потоки KSQL, можно определить SQL-подобные инструкции, которые обрабатывают один или несколько топиков на лету. Это дает что-то похожее на динамически обновляемое материализованное представление базы данных, при этом источником данных будут топики Kafka, а не БД. Такой потенциал открывает некоторые очень интересные возможности для управления данными в распределенных системах. Если вы хотите изучить эти идеи более подробно, рекомендую книгу «Проектирование событийно-ориентированных систем» от Бена Стопфорда (я должен рекомендовать книгу Бена, поскольку я написал к ней предисловие!). Для более глубокого погружения в Kafka в целом я бы предложил книгу «Apache Kafka. Потоковая обработка и анализ данных».
Об авторе
Сэм Ньюмен — независимый консультант, автор и докладчик. За более чем 20 лет работы в отрасли он имел дело с различными технологическими стеками в разных областях и компаниях по всему миру. В основном он помогает организациям быстрее и безопаснее внедрять ПО в эксплуатацию, а также ориентироваться в сложностях микросервисов. Автор книги «От монолита к микросервисам».
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Микросервисы
