
Вступление
Google Dorks или Google Hacking — техника, используемая СМИ, следственными органами, инженерами по безопасности и любыми пользователями для создания запросов в различных поисковых системах для обнаружения скрытой информации и уязвимостях, которые можно обнаружить на общедоступных серверах. Это метод, в котором обычные запросы на поиск веб-сайтов используются в полную меру для определения информации, скрытой на поверхности.
Как работает Google Dorking?
Данный пример сбора и анализа информации, выступающий как инструмент OSINT, является не уязвимостью Google и не устройством для взлома хостинга сайтов. Напротив, он выступает в роли обычного поискового процесса данных с расширенными возможностями. И это не в новинку, так как существует огромное количество веб-сайтов, которым уже более десятка лет и они служат как хранилища для изучения и использования Google Hacking.
В то время как поисковые системы индексируют, сохраняют хедеры и содержимое страниц, и связывают их между собой для оптимальных поисковых запросов. Но к сожалению, сетевые пауки любых поисковиков настроены индексировать абсолютно всю найденную информацию. Даже несмотря на то, что у администраторов веб ресурсов не было никаких намерений публиковать этот материал.
Однако самое интересное в Google Dorking, так это огромный объем информации, который может помочь каждому в процессе изучения поискового процесса Google. Может помочь новичкам в поиске пропавших родственников, а может научить каким образом можно извлечь информацию для собственной выгоды. В общем, каждый ресурс интересен и удивителен по своему и может помочь каждому в том, что именно он ищет.
Какую информацию можно найти через Dorks?
Начиная, от контроллеров удаленного доступа различных заводских механизмов до конфигурационных интерфейсов важных систем. Есть предположение о том, что огромное количество информации, выложенной в сети, никто и никогда не найдет.
Однако, давайте разберемся по порядку. Представьте себе новую камеру видеонаблюдения, позволяющая просматривать ее трансляцию на телефоне в любое время. Вы настраиваете и подключаетесь к ней через Wi-Fi, и загружаете приложение, для аутентификации входа в систему камеры наблюдения. После этого можно получить доступ к этой же камере из любой точки мира.
На заднем плане не все выглядит таким простым. Камера посылает запрос на китайский сервер и воспроизводит видео в режиме реального времени, позволяя войти в систему и открыть видеотрансляцию, размещенную на сервере в Китае, с вашего телефона. Этот сервер может не требовать пароля для доступа к каналу с вашей веб-камеры, что делает ее общедоступной для всех, кто ищет текст, содержащийся на странице просмотра камеры.
И к сожалению, Google безжалостно эффективен в поиске любых устройств в Интернете, работающих на серверах HTTP и HTTPS. И поскольку большинство этих устройств содержат определенную веб платформу для их настройки, это означает, что многие вещи, не предназначенные быть в Google, в конечном итоге оказываются там.
Безусловно, самый серьезный тип файлов, это тот, который несет в себе учетные данные пользователей или же всей компании. Обычно это происходит двумя способами. В первом, сервер настроен неправильно и выставляет свои административные логи или журналы в открытом доступе в Интернете. Когда пароли меняются или пользователь не может войти в систему, эти архивы могут утечь вместе с учетными данными.
Второй вариант происходит тогда, когда конфигурационные файлы, содержащие ту же информацию (логины, пароли, наименования баз данных и т.д.), становятся общедоступными. Это файлы должны быть обязательно скрыты от любого публичного доступа, так как в них часто оставляют важную информацию. Любая из этих ошибок может привести к тому, что злоумышленник найдет данные лазейки и получит всю нужную информацию.
Данная статья иллюстрирует использование Google Dorks, для того чтобы показать не только как находить все эти файлы, но и насколько бывают уязвимы платформы, содержащие информацию в виде списка адресов, электронной почты, картинок и даже перечня веб-камер в открытом доступе.
Разбор операторов поиска
Dorking можно использовать в различных поисковых системах, не только в Google. В повседневном использовании поисковые системы, такие как Google, Bing, Yahoo и DuckDuckGo, принимают поисковый запрос или строку поисковых запросов и возвращают соответствующие результаты. Также эти же системы запрограммированы принимать более продвинутые и сложные операторы, которые значительно сужают эти условия поиска. Оператор — это ключевое слово или фраза, несущее особое значение для поисковой системы. Вот примеры часто используемых операторов: «inurl», «intext», «site», «feed», «language». За каждым оператором следует двоеточие, за которым следует соответствующий ключевая фраза или фразы.
Эти операторы позволяют выполнять поиск более конкретной информации, например: определенные строки текста внутри страниц веб-сайта или файлы, размещенные по конкретному URL-адресу. Помимо прочего, Google Dorking может также находить скрытые страницы для входа в систему, сообщения об ошибках, выдающие информации о доступных уязвимостях и файлы общего доступа. В основном причина заключается в том, что администратор веб-сайта мог просто забыть исключить из открытого доступа.
Наиболее практичным и в то же время интересным сервисом Google, является возможность поиска удаленных или архивных страниц. Это можно сделать с помощью оператора «cache:». Оператор работает таким образом, что показывает сохраненную (удаленную) версию веб-страницы, хранящейся в кеше Google. Синтаксис данного оператора показан здесь:

cache:www.youtube.com
После произведения вышеуказанного запроса в Google, предоставляется доступ к предыдущей или устаревшей версии веб-страницы Youtube. Команда позволяет вызвать полную версию страницы, текстовую версию или сам источник страницы (целостный код). Также указывается точное время (дата, час, минута, секунда) индексации, сделанной пауком Google. Страница отображается в виде графического файла, хоть и поиск по самой странице осуществляется точно так же как в обычной странице HTML (сочетание клавиш CTRL + F). Результаты выполнения команды «cache:» зависят от того, как часто веб-страница индексировалась роботом Google. Если разработчик сам устанавливает индикатор с определенной частотой посещений в заголовке HTML-документа, то Google распознает страницу как второстепенную и обычно игнорирует ее в пользу коэффициента PageRank, являющийся основным фактором частоты индексации страницы. Поэтому, если конкретная веб-страница была изменена, между посещениями робота Google, она не будет проиндексирована и не будет прочитана с помощью команды «cache:». Примеры, которые особенно хорошо работают при тестировании данной функции, являются часто обновляемые блоги, учетные записи социальных сетей и интернет-порталы.
Удаленную информацию или данные, которые были размещены по ошибке или требуют удаления в определенный момент, можно очень легко восстановить. Небрежность администратора веб — платформ может поставить его под угрозу распространения нежелательной информации.
Информация о пользователях
Поиск информации о пользователях используется при помощи расширенных операторов, которые делают результаты поиска точными и подробными. Оператор «@» используется для поиска индексации пользователей в социальных сетях: Twitter, Facebook, Instagram. На примере того же самого польского вуза, можно найти его официального представителя, на одной из социальных платформ, при помощи этого оператора следующим образом:

inurl: twitter @minregion_ua
Данный запрос в Twitter находит пользователя «minregion_ua». Предполагая, что место или наименование работы пользователя, которого ищем (Министерство по развитию общин и территорий Украины) и его имя известны, можно задать более конкретный запрос. И вместо утомительного поиска по всей веб-странице учреждения, можно задать правильный запрос на основе адреса электронной почты и предположить, что в названии адреса должно быть указано хотя бы имя запрашиваемого пользователя или учреждения. Например:

site: www.minregion.gov.ua «@minregion.ua»
Можно также использовать менее сложный метод и отправить запрос только по адресам электронной почты, как показано ниже, в надежде на удачу и недостаток профессионализма администратора веб ресурса.

email.xlsx
filetype: xls + email
Вдобавок можно попытаться получить адреса электронных почт с веб-страницы по следующему запросу:

site:www.minregion.gov.ua intext:e-mail
Показанный выше запрос, будет производить поиск по ключевому слову «email» на веб-странице Министерства по развитию общин и территорий Украины. Поиск адресов электронной почты имеет ограниченное использование и в основном требует небольшой подготовки и сборе информации о пользователях заранее.
К сожалению, поиск индексированных телефонных номеров через «phonebook» Google ограничен только на территории США. Например:

phonebook:Arthur Mobile AL
Поиск информации о пользователях также возможен через Google «image search» или обратного поиска изображений. Это позволяет находить идентичные или похожие фотографии на сайтах, проиндексированными Google.
Информация веб-ресурсов
Google имеет несколько полезных операторов, в частности «related:», который отображает список «похожих» веб-сайтов на нужный. Сходство основано на функциональных ссылках, а не на логических или содержательных связях.
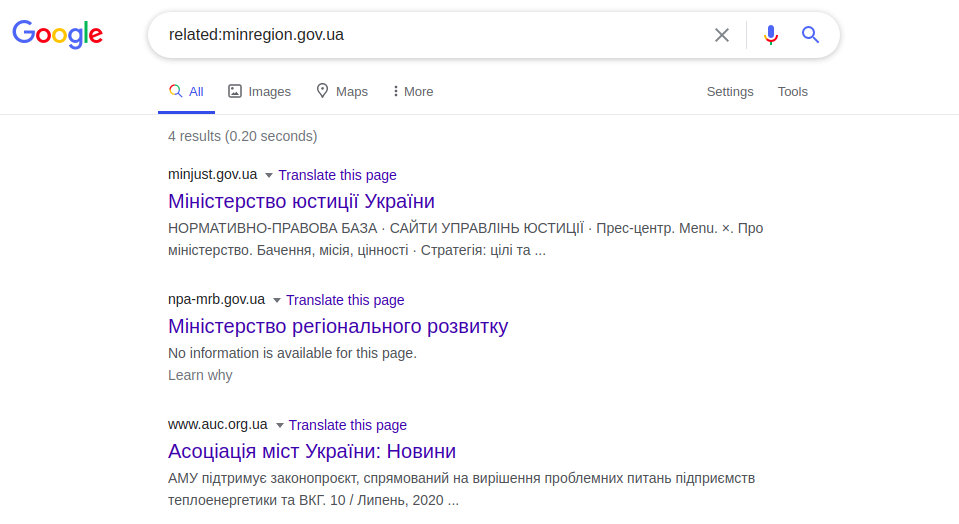
related:minregion.gov.ua
В этом примере отображаются страницы других Министерств Украины. Этот оператор работает как кнопка “Похожие страницы” в расширенном поиске Google. Точно таким же образом работает запрос “info:”, который отображает информацию на определенной веб-странице. Это конкретная информация веб-страницы, представленная в заголовке веб-сайта (), а именно в мета-тегах описания (<meta name = “Description”). Пример:

info:minregion.gov.ua
Другой запрос, «define:» весьма полезен в поиске научной работе. Он позволяет получить определения слов из таких источников, как энциклопедий и онлайн-словарей. Пример его применения:

define:ukraine territories
Универсальный оператор — тильда (»~»), позволяет искать похожие слова или слова синонимы:

~громад ~розвитку
Приведенный выше запрос отображает, как веб-сайты со словами «громад» (территорий) и «розвитку» (развитие), так и сайты с синонимом «общины». Оператор «link:», модифицирующий запрос, ограничивает диапазон поиска ссылками, указанными для определенной страницы.

link:www.minregion.gov.ua
Однако этот оператор не отображает все результаты и не расширяет критерии поиска.
Хештеги являются своего рода идентификационными номерами, позволяющие группировать информацию. В настоящее время они используются в Instagram, VK, Facebook, Tumblr и TikTok. Google позволяет выполнять поиск во многих социальных сетях одновременно или только в рекомендуемых. Пример типичного запроса к любой поисковой системе является:

#політикавукраїні
Оператор «AROUND(n)» позволяет искать два слова, расположенные на расстоянии определенного количества слов, друг от друга. Пример:

Міністерство AROUND(4) України
Результатом вышеупомянутого запроса является отображение веб-сайтов, которые содержат эти два слова (»министерство» и «Украины»), но они отделены друг от друга четырьмя другими словами.
Поиск по типам файлов также чрезвычайно полезен, поскольку Google индексирует материалы в соответствии с их форматами, в котором они были записаны. Для этого используется оператор «filetype:». В настоящее время используется очень широкий диапазон поиска файлов. Среди всех доступных поисковых систем, Google предоставляет самый сложный набор операторов для поиска открытых исходных кодов.
В качестве альтернативы вышеупомянутых операторов, рекомендуются такие инструменты, как Maltego и Oryon OSINT Browser. Они обеспечивают автоматический поиск данных и не требуют знания специальных операторов. Механизм программ очень прост: с помощью правильного запроса, направленного в Google или Bing, находятся документы, опубликованные интересующим вас учреждением и анализируются метаданные из этих документов. Потенциальным информационным ресурсом для таких программ является каждый файл с любым расширением, к примеру: «.doc», «.pdf», «.ppt», «.odt», «.xls» или «.jpg».
В дополнении, следует сказать о том как правильно позаботиться об «очистке своих метаданных», прежде чем делать файлы общедоступными. В некоторых веб-руководствах предусмотрено как минимум несколько способов избавления от мета информации. Однако невозможно вывести самый лучший способ, потому что это все зависит от индивидуальных предпочтений самого администратора. В основном рекомендуется записать файлы в формате, в котором изначально не хранятся метаданные, а затем сделать файлы доступным. В Интернете присутствует многочисленное количество бесплатных программ очистки метаданных, главным образом, в отношении изображений. ExifCleaner может рассматриваться как один из самых желательных. В случае текстовых файлов, настоятельно рекомендуется выполнять очистку вручную.
Информация, неосознанно оставленная владельцами сайтов
Ресурсы, индексируемые Google, остаются публичными (например внутренние документы и материалы компании, оставшиеся на сервере), или они оставляются для удобства использования теми же людьми (например музыкальные файлы или файлы фильмов). Поиск такого контента может быть сделан при помощи Google через множество различных способов и самый простой из них, это просто угадать. Если например в определенном каталоге есть файлы 5.jpg, 8.jpg и 9.jpg, можно предугадать, что есть и файлы от 1 до 4, от 6 до 7 и даже более 9. Поэтому можно получить доступ к материалам, которые не должны были быть в публичном виде. Другой способ — поиск по определенным типам контента на веб-сайтах. Можно искать музыкальные файлы, фотографии, фильмы и книги (электронные книги, аудиокниги).
В другом случае это могут быть файлы, которые пользователь оставил бессознательно в публичном доступе (например — музыка на FTP сервере для собственного использования). Такую информацию можно получить двумя способами: используя оператор «filetype:» или оператор «inurl:». Например:

filetype:doc site:gov.ua
site:www.minregion.gov.ua filetype:pdf
site:www.minregion.gov.ua inurl:doc
Также можно искать программные файлы, используя поисковый запрос и фильтруя искомый файл по его расширению:
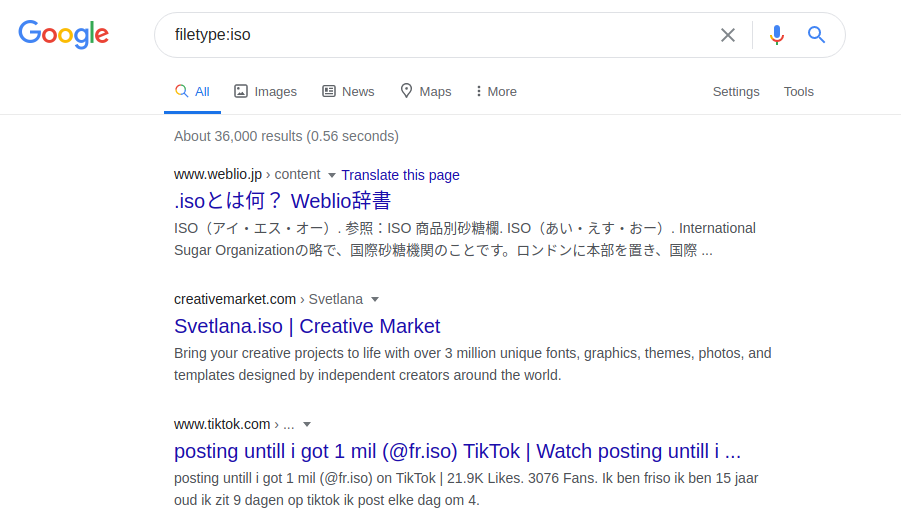
filetype:iso
Информация о структуре веб-страниц
Для того чтобы просмотреть структуру определенной веб-страницы и раскрыть всю ее конструкцию, которая поможет в дальнейшем сервера и его уязвимостей, можно проделать это, используя только оператор «site:». Давайте проанализируем следующую фразу:

site: www.minregion.gov.ua minregion
Мы начинаем поиск слова «minregion» в домене «www.minregion.gov.ua». Каждый сайт из этого домена (Google ищет как в тексте, в заголовках и в заголовке сайта) содержит данное слово. Таким образом, получая полную структуру всех сайтов этого конкретного домена. Как только структура каталогов станет доступной, более точный результат (хотя это не всегда может произойти) можно получить с помощью следующего запроса:
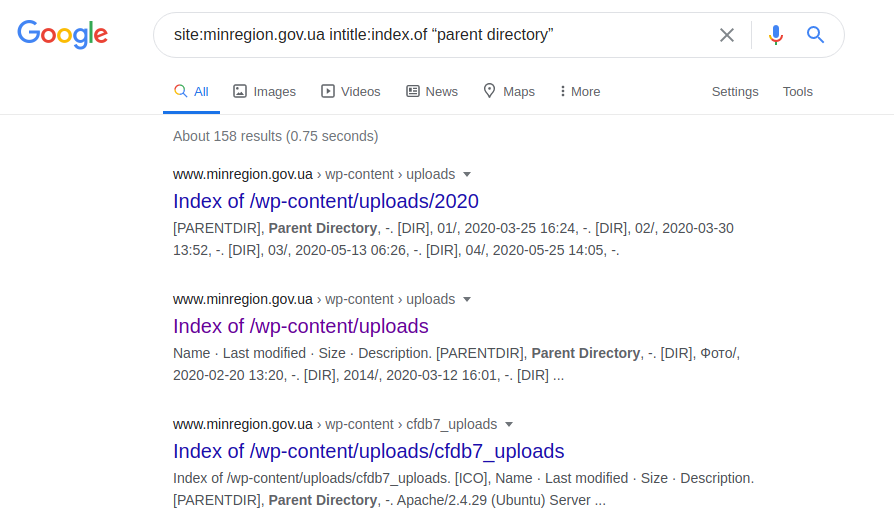
site:minregion.gov.ua intitle:index.of «parent directory»
Он показывает наименее защищенные субдомены «minregion.gov.ua», иногда с возможностью поиска по всему каталога, вместе с возможной загрузкой файлов. Поэтому, естественно, такой запрос не применим ко всем доменам, поскольку они могут быть защищены или работать под управлением какого-либо другого сервера.


site:gov inurl:robots.txt intext:Disallow: /web.config
Данный оператор позволяет получить доступ к параметрам конфигураций различных серверов. После проведения запроса, переходим в файл robots.txt, ищем путь к «web.config» и переход по заданному пути файла. Чтобы получить имя сервера, его версию и другие параметры (например, порты), делается следующий запрос:

site:gosstandart.gov.by intitle:index.of server.at
Каждый сервер имеет какие-то свои уникальные фразы на заглавных страницах, например, Internet Information Service (IIS):

intitle:welcome.to intitle:internet IIS
Определение самого сервера и используемых в нем технологий зависит только от изобретательности задаваемого запроса. Можно, например, попытаться сделать это с помощью уточнения технической спецификации, руководства или так называемых страниц справок. Чтобы продемонстрировать данную возможность, можно воспользоваться следующим запросом:

site:gov.ua inurl:manual apache directives modules (Apache)
Доступ может быть более расширенным, например, благодаря файлу с ошибками SQL:

«#mysql dump» filetype:SQL
Ошибки в базе данных SQL могут в частности, предоставить информацию о структуре и содержании баз данных. В свою очередь, вся веб-страница, ее оригинал и (или) ее обновленные версии могут быть доступны по следующему запросу:

site:gov.ua inurl:backup
site:gov.ua inurl:backup intitle:index.of inurl:admin
В настоящее время использование вышеупомянутых операторов довольно редко дает ожидаемые результаты, поскольку они могут быть заранее заблокированы осведомленными пользователями.
Также с помощью программы FOCA можно найти такой же контент, как и при поиске вышеупомянутых операторов. Для начала работы, программе нужно название доменного имени, после чего она проанализирует структуру всего домена и всех других поддоменов, подключенных к серверам конкретного учреждения. Такую информацию можно найти в диалоговом окне на вкладке «Сеть»:

Таким образом, потенциальный злоумышленник может перехватить данные, оставленные веб-администраторами, внутренние документы и материалы компании, оставленные даже на скрытом сервере.
Если вы захотите узнать еще больше информации о всех возможных операторов индексирования вы можете ознакомиться с целевой базой данных всех операторов Google Dorking вот здесь. Также можно ознакомиться с одним интересным проектом на GitHub, который собрал в себя все самые распространенные и уязвимые URL ссылки и попробовать поискать для себя что-то интересное, его можно посмотреть вот по этой ссылке.
Комбинируем и получаем результаты
Для более конкретных примеров, ниже представлена небольшая сборка из часто используемых операторов Google. В комбинации различной дополнительной информации и тех же самых команд, результаты поиска показывают более подробный взгляд на процесс получения конфиденциальной информации. Ведь как-никак, для обычной поисковой системы Google, такой процесс сбора информации может оказаться довольно интересным.
Поиск бюджетов на веб-сайте Министерства национальной безопасности и кибербезопасности США.
Следующая комбинация предоставляет все общедоступные проиндексированные таблицы Excel, содержащие слово «бюджет»:

budget filetype:xls
Так как оператор «filetype:» автоматически не распознает различные версии одинаковых форматов файлов (например, doc против odt или xlsx против csv), каждый из этих форматов должен быть разбит отдельно:

budget filetype:xlsx OR budget filetype:csv
Последующий dork вернет файлы PDF на веб-сайте NASA:

site:nasa.gov filetype:pdf
Еще один интересный пример использования дорка с ключевым словом «бюджет» — это поиск документов по кибербезопасности США в формате «pdf» на официальной сайте Министерства внутренней обороны.

budget cybersecurity site:dhs.gov filetype:pdf
То же самое применение дорка, но в этот раз поисковик вернет электронные таблицы .xlsx, содержащие слово «бюджет» на веб-сайте Министерства внутренней безопасности США:

budget site: dhs.gov filetype: xls
Поиск паролей
Поиск информации по логину и паролю может быть полезен в качестве поиска уязвимостей на собственном ресурсе. В остальных случаях пароли хранятся в документах общего доступа на веб-серверах. Можно попробовать применить следующие комбинации в различных поисковых системах:

password filetype:doc / docx / pdf / xls
password filetype:doc / docx / pdf / xls site:[Наименование сайта]
Если попробовать ввести такой запрос в другой поисковой системе, то можно получить совершенно разные результаты. Например, если выполнить этот запрос без термина «site: [Наименование сайта]«, Google вернет результаты документов, содержащие реальные имена пользователей и пароли некоторых американских средних школ. Другие поисковые системы не показывают эту информацию на первых страницах результатов. Как это можно увидеть ниже, Yahoo и DuckDuckGo являются таковыми примерами.


Цены на жилье в Лондоне
Другой интересный пример касается информации о цене на жилье в Лондоне. Ниже приведены результаты запроса, который был введен в четырех разных поисковых системах:
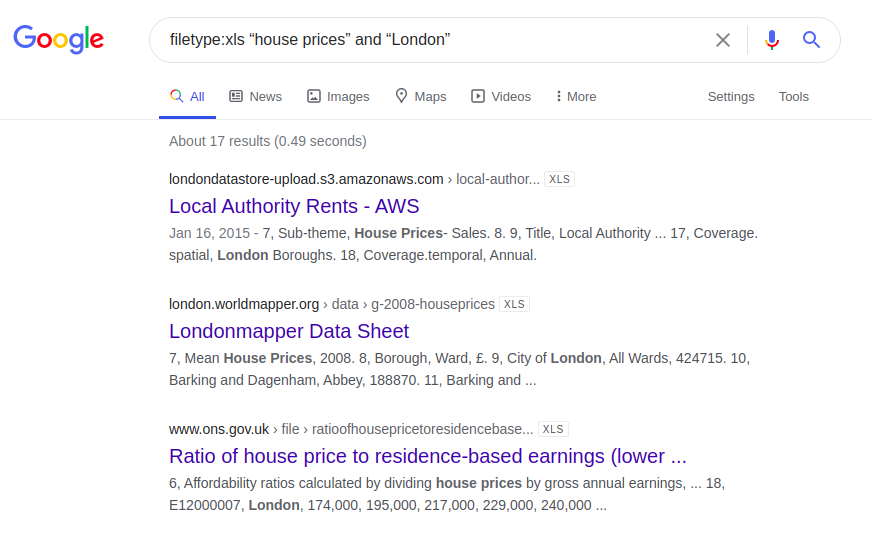
filetype:xls «house prices» and «London»
Возможно, теперь у вас есть собственные идеи и представления о том, на каких веб-сайтах вы хотели бы сосредоточиться в своем собственном поиске информации или же как правильно проверять свой собственный ресурс на определение возможных уязвимостей.
Альтернативные инструменты поиска индексаций
Существуют также и другие методы сбора информации при помощи Google Dorking. Все они являются альтернативой и выступают в качестве автоматизации поисковых процессов. Ниже предлагаем взглянуть на одни из самых популярных проектов, которыми не грех поделиться.
Google Hacking Online
Google Hacking Online — это онлайн интеграция поиска Google Dorking различных данных через веб страницу при помощи установленных операторов, с которыми вы можете ознакомиться здесь. Инструмент представляет из себя обычное поле ввода для поиска желаемого IP адреса или URL ссылки на интересующий ресурс, вместе с предлагаемыми опциями поиска.

Как видно из картинки выше, поиск по нескольким параметрам предоставляется в виде нескольких вариантов:
- Поиск публичных и уязвимых каталогов
- Файлы конфигурации
- Файлы баз данных
- Логи
- Старые данные и данные резервного копирования
- Страницы аутентификации
- Ошибки SQL
- Документы, хранящиеся в общем доступе
- Информация о конфигурации php на сервере («phpinfo»)
- Файлы общего интерфейса шлюза (CGI)
Все работает на ванильном JS, который прописан в самом файл веб страницы. В начале берется введенная информация пользователя, а именно наименование хоста или IP адрес веб страницы. И потом составляется запрос с операторами на введенную информацию. Ссылка на поиск определенного ресурса, открывается в новом всплывающем окне, с предоставленными результатами.
BinGoo
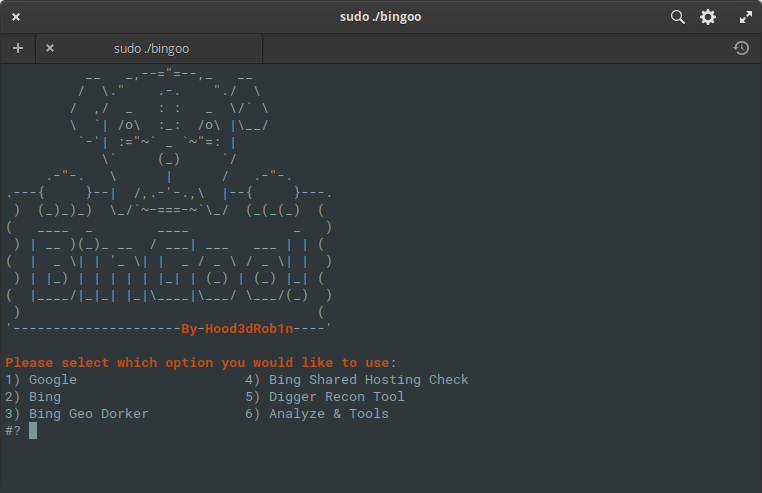
BinGoo — это универсальной инструмент, написанный на чистом bash. Он использует поисковые операторы Google и Bing для фильтрации большого количества ссылок на основе приведенных поисковых терминов. Можно выбрать поиск по одному оператору за раз или составить списки по одному оператору на строку и выполнить массовое сканирование. Как только заканчивается процесс с изначальным сбором информации или у вас появятся ссылки, собранные другими способами, можно перейти к инструментам анализа, чтобы проверить общие признаки уязвимостей.
Результаты аккуратно отсортированы в соответствующих файлах на основе полученных результатов. Но и здесь анализ не останавливается, можно пойти еще дальше и запустить их с помощью дополнительных функционалов SQL или LFI или можно использовать инструменты-оболочки SQLMAP и FIMAP, которые работают намного лучше, с точными результатами.
Также включено несколько удобных функций, чтобы упростить жизнь, таких как «геодоркинг» на основе типа домена, кодов стран в домене и проверка общего хостинга, которая использует предварительно сконфигурированный поиск Bing и список дорков для поиска возможных уязвимостей на других сайтах. Также включен простой поиск страниц администраторов, работающий на основе предоставленного списка и кодов ответа сервера для подтверждения. В целом — это очень интересный и компактный пакет инструментов, осуществляющий основной сбор и анализ заданной информации! Ознакомиться с ним можно вот здесь.
Pagodo
Цель инструмента Pagodo — это пассивное индексирование операторов Google Dorking для сбора потенциально уязвимых веб-страниц и приложений через Интернет. Программа состоит из двух частей. Первая — это ghdb_scraper.py, которая запрашивает и собирает операторы Google Dorks, а вторая — pagodo.py, использует операторы и информацию, собранную через ghdb_scraper.py и анализирует ее через запросы Google.
Для начала файлу pagodo.py требуется список операторов Google Dorks. Подобный файл предоставляется либо в репозитории самого проекта или можно просто запросить всю базу данных через один GET-запрос, используя ghdb_scraper.py. А затем просто скопировать отдельные операторы dorks в текстовый файл или поместить в json, если требуются дополнительные контекстные данные.
Для того чтобы произвести данную операцию, нужно ввести следующую команду:
python3 ghdb_scraper.py -j -sТеперь, когда есть файл со всеми нужными операторами, его можно перенаправить в pagodo.py с помощью опции «-g», для того чтобы начать сбор потенциально уязвимых и общедоступных приложений. Файл pagodo.py использует библиотеку «google» для поиска таких сайтов с помощью подобных операторов:
intitle: «ListMail Login» admin -demo
site: example.com
К сожалению, процесс столь огромного количества запросов (а именно ~ 4600) через Google, просто не будет работать. Google сразу же определит вас как бота и заблокирует IP адрес на определенный период. Для того чтобы поисковые запросы выглядели более органичными, было добавлено несколько улучшений.
Для модуля Python «google» сделали специальные поправки, чтобы обеспечить рандомизацию агента пользователя через поисковые запросы Google. Эта функция доступна в версии модуля 1.9.3 и позволяет рандомизировать различные пользовательские агенты, используемые для каждого поискового запроса. Данная возможность позволяет эмулировать различные браузеры, используемые в большой корпоративной среде.
Второе усовершенствование фокусируется на рандомизации времени между поисковыми запросами. Минимальная задержка указывается с помощью параметра «-e», а коэффициент джиттера используется для добавления времени к минимальному числу задержек. Создается список из 50 джиттеров и один из них случайным образом добавляется к минимальному времени задержки для каждого процесса поиска в Google.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))Далее в скрипте выбирается случайное время из массива джиттера и добавляется к задержке создания запросов:
pause_time = self.delay + random.choice (self.jitter)Можно самостоятельно поэкспериментировать со значениями, но настройки по умолчанию работают итак успешно. Обратите внимание, что процесс работы инструмента может занять несколько дней (в среднем 3; в зависимости от количества заданных операторов и интервала запроса), поэтому убедитесь, что у вас есть на это время.
Чтобы запустить сам инструмент, достаточно следующей команды, где «example.com» это ссылка на интересуемый веб сайт, а «dorks.txt» это текстовый файл который создал ghdb_scraper.py:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1А сам инструмент вы можете пощупать и ознакомиться перейдя вот по этой ссылочке.
Методы защиты от Google Dorking
Основные рекомендации
Google Dorking, как и любой другой инструмент свободного доступа, имеет свои техники для защиты и предотвращения сбора конфиденциальной информации злоумышленниками. Последующие рекомендации пяти протоколов следует придерживаться администраторам любых веб платформ и серверов, чтобы избежать угроз от «Google Dorking»:
- Систематическое обновление операционных систем, сервисов и приложений.
- Внедрение и обслуживание анти-хакерских систем.
- Осведомленность о Google роботах и различных процедурах поисковых систем, а также способы проверки таких процессов.
- Удаление конфиденциального содержимого из общедоступных источников.
- Разделение общедоступного контента, частного контента и блокировка доступа к контенту для пользователей общего доступа.
Конфигурация файлов .htaccess и robots.txt
В основном все уязвимости и угрозы, связанные с «Dorking», генерируются из-за невнимательности или небрежности пользователей различных программ, серверов или других веб-устройств. Поэтому правила самозащиты и защиты данных не вызывают каких-либо затруднений или осложнений.
Для того чтобы тщательно подойти к предотвращению индексаций со стороны любых поисковых систем стоит обратить внимание на два основных файла конфигураций любого сетевого ресурса: «.htaccess» и «robots.txt». Первый — защищает обозначенные пути и директории при помощи паролей. Второй — исключает директории из индексирования поисковиков.
В случае, если на вашем собственном ресурсе содержатся определенные виды данных или директорий, которым не следует быть индексированным на Google, то в первую очередь следует настроить доступ к папкам через пароли. На примере ниже, можно наглядно посмотреть как правильно и что именно следует прописать в файл «.htaccess», находящийся в корневой директории любого веб сайта.
Для начала следует добавить несколько строк, показанные ниже:
AuthUserFile /your/directory/here/.htpasswd
AuthGroupFile /dev/null
AuthName «Secure Document»
AuthType Basic
require user username1
require user username2
require user username3
В строке AuthUserFile указываем путь к местоположению файла .htaccess, который находится в вашем каталоге. А в трех последних строках, нужно указать соответствующее имя пользователя, к которому будет предоставлен доступ. Затем нужно создать «.htpasswd» в той же самой папке, что и «.htaccess» и выполнив следующую команду:
htpasswd -c .htpasswd username1
Дважды ввести пароль для пользователя username1 и после этого, будет создан абсолютно чистый файл «.htpasswd» в текущем каталоге и будет содержать зашифрованную версию пароля.
Если есть несколько пользователей, следует назначить каждому из них пароль. Чтобы добавить дополнительных пользователей, не нужно создавать новый файл, можно просто добавить их в существующий файл, не используя опцию -c, при помощи этой команды:
htpasswd .htpasswd username2
В остальных случаях рекомендуется настраивать файл robots.txt, который отвечает за индексацию страниц любого веб ресурса. Он служит проводником для любой поисковой системы, которая ссылается на определенные адреса страниц. И прежде чем перейти непосредственно к искомому источнику, robots.txt будет либо блокировать подобные запросы, либо пропускать их.
Сам файл расположен в корневом каталоге любой веб платформы, запущенной в Интернете. Конфигурация осуществляется всего лишь изменением двух главных параметров: «User-agent» и «Disallow». Первый выделяет и отмечает либо все, либо какие-то определенные поисковые системы. В то время как второй отмечает, что именно нужно заблокировать (файлы, каталоги, файлы с определенными расширениями и т.д.). Ниже приведено несколько примеров: исключения каталога, файла и определенной поисковой системы, исключенные из процесса индексирования.
User-agent: *
Disallow: /cgi-bin/
User-agent: *
Disallow: /~joe/junk.html
User-agent: Bing
Disallow: /
Использование мета-тегов
Также ограничения для сетевых пауков могут быть введены на отдельных веб страницах. Они могут располагаться как на типичных веб-сайтах, блогах, так и страницах конфигураций. В заголовке HTML они должны сопровождаться одной из следующих фраз:
<meta name=“Robots” content=“none” \>
<meta name=“Robots” content=“noindex, nofollow” \>
При добавлении такой записи в хедере страницы, роботы Google не будут индексировать ни второстепенные, ни главную страницу. Данная строка может быть введена на страницах, которым не следуют индексироваться. Однако это решение, основано на обоюдном соглашении между поисковыми системами и самим пользователем. Хоть Google и другие сетевые пауки соблюдают вышеупомянутые ограничения, есть определенные сетевые роботы «охотятся» за такими фразами для получения данных, изначально настроенных без индексации.
Из более продвинутых вариантов по безопасности индексирования, можно воспользоваться системой CAPTCHA. Это компьютерный тест, позволяющий получить доступ к контенту страницы только людям, а не автоматическим ботам. Однако этот вариант имеет, небольшой недостаток. Он не слишком удобен для самих пользователей.
Другим простым защитным методом от Google Dorks может быть, например, кодирование знаков в административных файлах кодировкой ASCII, затрудняющий использование Google Dorking.
Практика пентестинга
Практика пентестинга — это тесты на выявления уязвимостей в сети и на веб платформах. Они важны по своему, потому что такие тесты однозначно определяют уровень уязвимости веб-страниц или серверов, включая Google Dorking. Существуют специальные инструменты для пентестов, которые можно найти в Интернете. Одним из них является Site Digger, сайт, позволяющий автоматически проверять базу данных Google Hacking на любой выбранной веб-странице. Также, есть еще такие инструменты, как сканер Wikto, SUCURI и различные другие онлайн-сканеры. Они работают аналогичным образом.
Есть более серьезные инструменты, имитирующие среду веб-страницы, вместе с ошибками и уязвимостями для того, чтобы заманить злоумышленника, а затем получить конфиденциальную информацию о нем, как например Google Hack Honeypot. Стандартному пользователю, у которого мало знаний и недостаточно опыта в защите от Google Dorking, следует в первую очередь проверить свой сетевой ресурс на выявление уязвимостей Google Dorking и проверить какие конфиденциальные данные являются общедоступными. Стоит регулярно проверять такие базы данных, haveibeenpwned.com и dehashed.com, чтобы выяснить, не была ли нарушена и опубликована безопасность ваших учетных записей в сети.

https://haveibeenpwned.com/, касается плохо защищенных веб-страниц, где были собраны данные учетных записей (адреса электронных почт, логины, пароли и другие данные). В настоящее время база данных содержит более 5 миллиардов учетных записей. Более продвинутый инструмент доступен на https://dehashed.com, позволяющий искать информацию по именам пользователей, адресов электронных почт, паролей и их хешу, IP адресам, именам и номерам телефонов. В дополнении, счета, по которым произошла утечка данных, можно купить в сети. Стоимость однодневного доступа составляет всего 2 доллара США.
Заключение
Google Dorking является неотъемлемой частью процесса сбора конфиденциальной информации и процесса ее анализа. Его по праву можно считать одним из самых корневых и главных инструментов OSINT. Операторы Google Dorking помогают как в тестировании своего собственного сервера, так и в поиске всей возможной информации о потенциальной жертве. Это действительно очень яркий пример корректного использования поисковых механизмов в целях разведки конкретной информации. Однако являются ли намерения использования данной технологии благими (проверка уязвимостей собственного интернет ресурса) или недобрыми (поиск и сбор информации с разнообразных ресурсов и использование ее в незаконных целях), остается решать только самим пользователям.
Альтернативные методы и инструменты автоматизации дают еще больше возможностей и удобств для проведения анализа веб ресурсов. Некоторые из них, как например BinGoo, расширяет обычный индексированный поиск на Bing и анализирует всю полученную информацию через дополнительные инструменты (SqlMap, Fimap). Они в свою очередь преподносят более точную и конкретную информацию о безопасности выбранного веб ресурса.
В то же самое время, важно знать и помнить как правильно обезопасить и предотвратить свои онлайн платформы от процессов индексирования, там где они не должны быть. А также придерживаться основных положений, предусмотренных для каждого веб администратора. Ведь незнание и неосознание того, что по собственной ошибке, твою информацию заполучили другие люди, еще не означает то, что все можно вернуть как было прежде.
