
Attack detection has been a part of information security for decades. The first known intrusion detection system (IDS) implementations date back to the early 1980s.
Nowadays, an entire attack detection industry exists. There are a number of kinds of products—such as IDS, IPS, WAF, and firewall solutions—most of which offer rule-based attack detection. The idea of using some kind of statistical anomaly detection to identify attacks in production doesn’t seem as realistic as it used to. But is that assumption justified?
Detection of anomalies in Web Applications
The first firewalls tailored to detect web application attacks appeared on the market in the early 1990s. Both attack techniques and protection mechanisms have evolved dramatically since then, with attackers racing to get one step ahead.
Most current web application firewalls (WAFs) attempt to detect attacks in a similar fashion, with a rule-based engine embedded in a reverse proxy of some type. The most prominent example is mod_security, a WAF module for the Apache web server, which was created in 2002. Rule-based detection has some disadvantages: for instance, it fails to detect novel attacks (zero-days), even though these same attacks might easily be detected by a human expert. This fact is not surprising, since the human brain works very differently than a set of regular expressions.
From the perspective of a WAF, attacks can be divided into sequentially-based ones (time series) and those consisting of a single HTTP request or response. Our research focused on detecting the latter type of attacks, which include:
- SQL Injection
- Cross-Site Scripting
- XML External Entity Injection
- Path Traversal
- OS Commanding
- Object Injection
But first let’s ask ourselves: how would a human do it?
What would a human do when seeing a single request
Take a look at a sample regular HTTP request to some application:
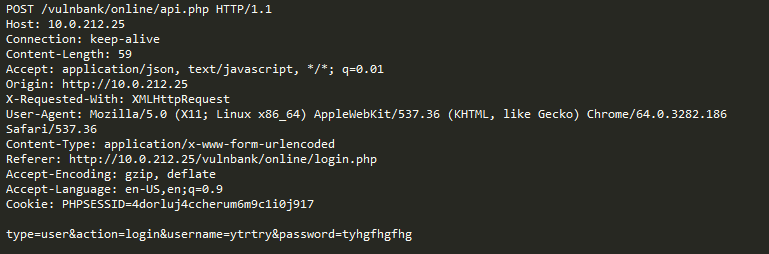
If you had to detect malicious requests sent to an application, most likely you would want to observe benign requests for a while. After looking at requests for a number of application execution endpoints, you would have a general idea of how safe requests are structured and what they contain.
Now you are presented with the following request:

You immediately intuit that something is wrong. It takes some more time to understand what exactly, and as soon as you locate the exact piece of the request that is anomalous, you can start thinking about what type of attack it is. Essentially, our goal is to make our attack detection AI approach the problem in a way that resembles this human reasoning.
Complicating our task is that some traffic, even though it may seem malicious at first sight, might actually be normal for a particular website.
For instance, let’s look at the following request:
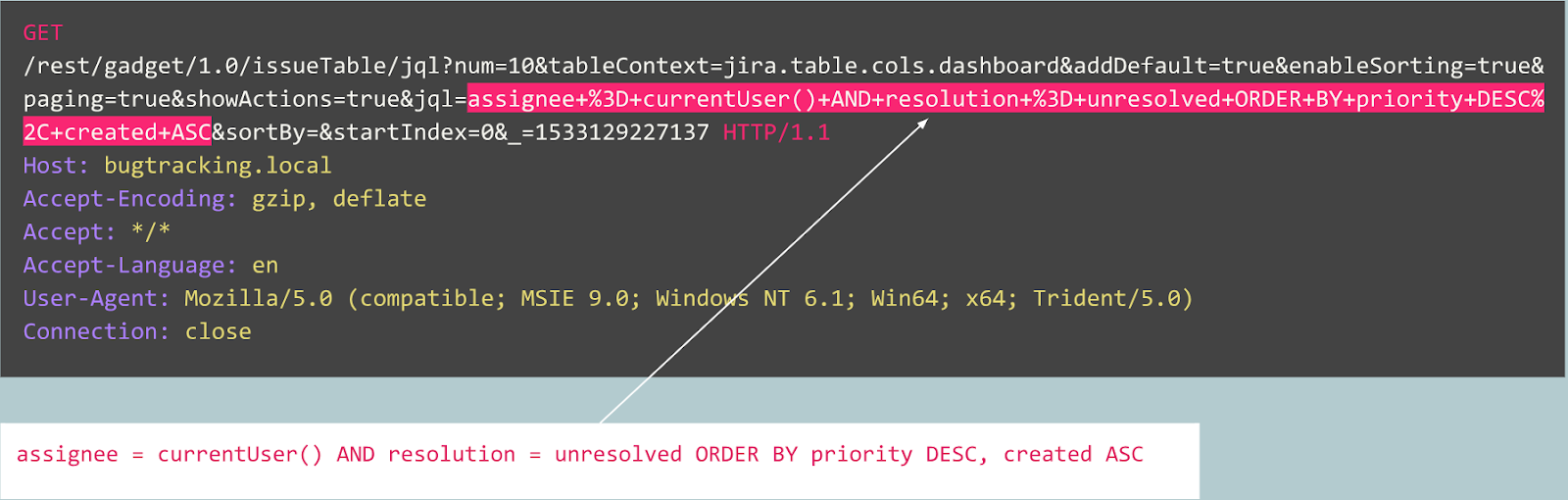
Is it an anomaly? Actually, this request is benign: it is a typical request related to bug publication on the Jira bug tracker.
Now let’s take a look at another case:

At first the request looks like typical user signup on a website powered by the Joomla CMS. However, the requested operation is “user.register” instead of the normal “registration.register”. The former option is deprecated and contains a vulnerability allowing anybody to sign up as an administrator.
This exploit is known as “Joomla < 3.6.4 Account Creation / Privilege Escalation” (CVE-2016-8869, CVE-2016-8870).

How we started
We first took a look at previous research, since many attempts to create different statistical or machine learning algorithms to detect attacks have been made throughout the decades. One of the most frequent approaches is to solve the task of assignment to a class (“benign request,” “SQL Injection,” “XSS,” “CSRF,” and so forth). While one may achieve decent accuracy with classification for a given dataset, this approach fails to solve some very important problems:
- The choice of class set. What if your model during learning is presented with three classes (“benign,“ “SQLi,” “XSS”) but in production it encounters a CSRF attack or even a brand-new attack technique?
- The meaning of these classes. Suppose you need to protect 10 customers, each of them running completely different web applications. For most of them, you would have no idea what a single “SQL Injection” attack against their application really looks like. This means you would have to somehow artificially construct your learning datasets—which is a bad idea, because you will end up learning from data with a completely different distribution than your real data.
- Interpretability of the results of your model. Great, so the model came up with the “SQL Injection” label—now what? You and most importantly your customer, who is the first one to see the alert and typically is not an expert in web attacks, have to guess which part of the request the model considers malicious.
Keeping that in mind, we decided to give classification a try anyway.
Since the HTTP protocol is text-based, it was obvious that we had to take a look at modern text classifiers. One of the well-known examples is sentiment analysis of the IMDB movie review dataset. Some solutions use recurrent neural networks (RNNs) to classify these reviews. We decided to use a similar RNN classification model with some slight differences. For instance, natural language classification RNNs use word embeddings, but it is not clear what words there are in a non-natural language like HTTP. That’s why we decided to use character embeddings in our model.
Ready-made embeddings are irrelevant for solving the problem, which is why we used simple mappings of characters to numeric codes with several internal markers such as GO and EOS.
After we finished development and testing of the model, all the problems predicted earlier came to pass, but at least our team had moved from idle musing to something productive.
How we proceeded
From there, we decided to try making the results of our model more interpretable. At some point we came across the mechanism of “attention” and started to integrate it into our model. And that yielded some promising results: finally, everything came together and we got some human-interpretable results. Now our model started to output not only the labels but also the attention coefficients for every character of the input.
If that could be visualized, say, in a web interface, we could color the exact place where a “SQL Injection” attack has been found. That was a promising result, but the other problems still remained unsolved.
We began to see that we could benefit by going in the direction of the attention mechanism, and away from classification. After reading a lot of related research (for instance, “Attention is all you need,” Word2Vec, and encoder–decoder architectures) on sequence models and by experimenting with our data, we were able to create an anomaly detection model that would work in more or less the same way as a human expert.
Autoencoders
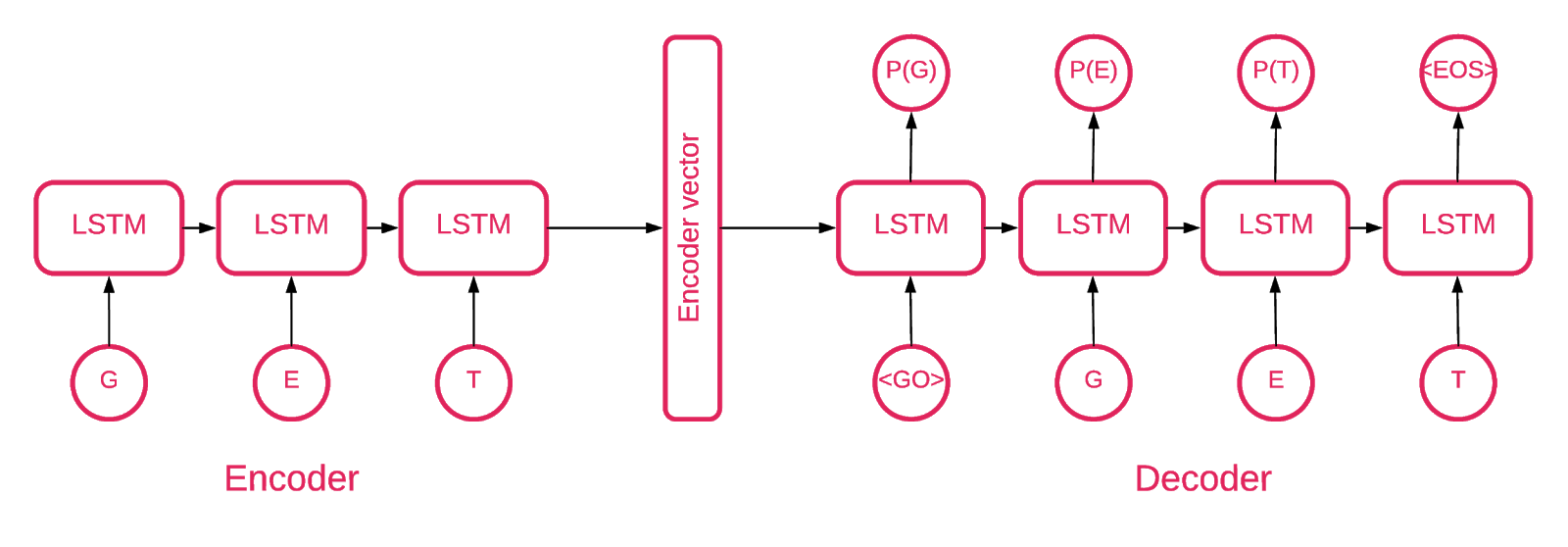
At some point it became clear that a sequence-to-sequence autoencoder fit our purpose best.
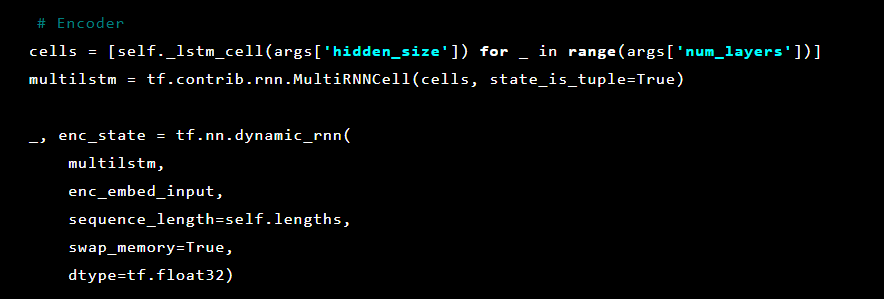
A sequence-to-sequence model consists of two multilayered long short-term memory (LSTM) models: an encoder and a decoder. The encoder maps the input sequence to a vector of fixed dimensionality. The decoder decodes the target vector using this output of the encoder.
So an autoencoder is a sequence-to-sequence model that sets its target values equal to its input values. The idea is to teach the network to re-create things it has seen, or, in other words, approximate an identity function. If the trained autoencoder is given an anomalous sample it is likely to re-create it with a high degree of error because of never having seen such a sample previously.
The code
Our solution is made up of several parts: model initialization, training, prediction, and validation.
Most of the code located in the repository is self-explanatory, we will focus on important parts only.
The model is initialized as an instance of the Seq2Seq class, which has the following constructor arguments:
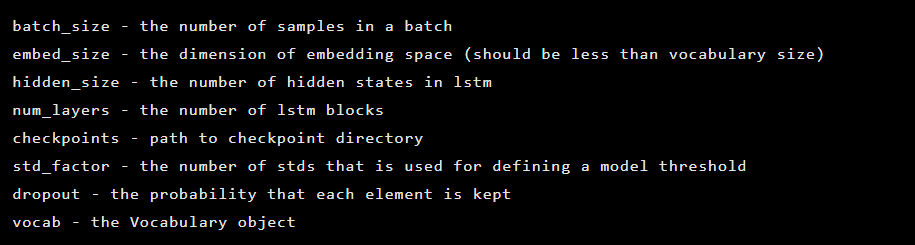
After that, the autoencoder layers are initialized. First, the encoder:
And then the decoder:
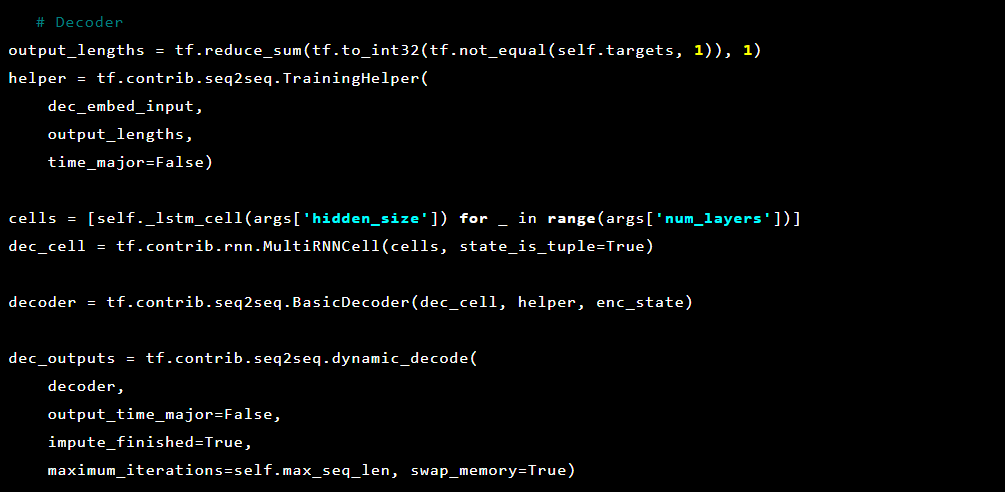
Since we are trying to solve anomaly detection, the targets and inputs are the same. Thus our feed_dict looks as follows:
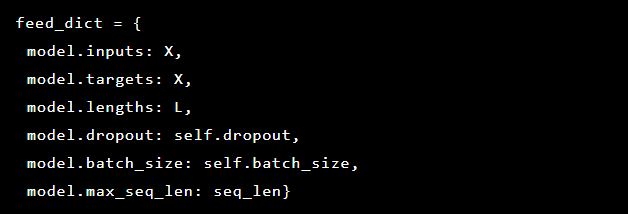
After each epoch the best model is saved as a checkpoint, which can be later loaded to do predictions. For testing purposes a live web application was set up and protected by the model so that it was possible to test if real attacks were successful or not.
Being inspired by the attention mechanism, we tried to apply it to the autoencoder but noticed that probabilities output from the last layer works better at marking the anomalous parts of a request.

At the testing stage with our samples we got very good results: precision and recall were close to 0.99. And the ROC curve was around 1. Definitely a nice sight!
The results
Our described Seq2Seq autoencoder model proved to be able to detect anomalies in HTTP requests with high accuracy.
This model acts like a human does: it learns only the “normal” user requests sent to a web application. It detects anomalies in requests and highlights the exact place in the request considered anomalous. We evaluated this model against attacks on the test application and the results appear promising. For instance, the previous screenshot depicts how our model detected SQL injection split across two web form parameters. Such SQL injections are fragmented, since the attack payload is delivered in several HTTP parameters. Classic rule-based WAFs do poorly at detecting fragmented SQL injection attempts because they usually inspect each parameter on its own.
The code of the model and the train/test data have been released as a Jupyter notebook so anyone can reproduce our results and suggest improvements.
Conclusion
We believe our task was quite non-trivial: to come up with a way of detecting attacks with minimal effort. On the one hand, we sought to avoid overcomplicating the solution and create a way of detecting attacks that, as if by magic, learns to decide by itself what is good and what is bad. At the same time, we wanted to avoid problems with the human factor when a (fallible) expert is deciding what indicates an attack and what does not. And so overall the autoencoder with Seq2Seq architecture seems to solve our problem of detecting anomalies quite well.
We also wanted to solve the problem of data interpretability. When using complex neural network architectures, it is very difficult to explain a particular result. When a whole series of transformations is applied, identifying the most important data behind a decision becomes nearly impossible. However, after rethinking the approach to data interpretation by the model, we were able to get probabilities for each character from the last layer.
It's important to note this approach is not a production-ready version. We cannot disclose the details of how this approach might be implemented in a real product. But we will warn you that it's not possible to simply take this work and «plug it in.» We make this caveat because after publishing on GitHub, we began to see some users who attempted to simply implement our current solution wholesale in their own projects, with unsuccessful (and unsurprising) results.
Proof of concept is available here (github.com).
Authors: Alexandra Murzina (murzina_a), Irina Stepanyuk (GitHub), Fedor Sakharov (GitHub), Arseny Reutov (Raz0r)
