
В последнее время новостные ленты заполонили статьи о машинном обучении (ML; Machine Learning) и глубинном обучении (Deep Learning).
Действительно, за несколько лет исследователи существенно продвинулись в этом направлении – и, что важнее, общество стало готово к новым технологиям.
К сожалению, спекулируя на популярной теме машинного обучения, многие сосредоточились на совершенно ненужных человечеству областях его применения: генерации текстов и сценариев для безумных фильмов, написании картин в стиле известных художников и т.д. Часть подобных статей и вовсе скатывается до панических настроений вроде «скоро мы все останемся без работы».
Такой подход создает в обществе неверное представление о машинном обучении и сценариях его использования в реальных задачах. На практике ML позволяет нам автоматизировать тот или иной вид умственной деятельности. Машина способна принимать решения так же, как человек, и даже быстрее или точнее, чем человек, — за счет обработки большего количество данных. Тем не менее важно понимать, что алгоритм способен хорошо выполнять только одну определенную задачу.
Мы не можем заменить компьютером полицейского, но мы можем научить компьютер распознавать в потоке людей лица, похожие на лицо преступника. Вся мощь алгоритмов иссякает тогда, когда имеющихся данных становится недостаточно или происходит событие, не похоже на предыдущие — известные системе. Машина не способна на творчество в незнакомой ситуации.
Machine learning в системах хранения
Применительно к теме систем хранения данных, зададимся вопросом: как подходы ML могут применяться в мире жестких и твердотельных дисков? Приведем несколько примеров использования машинного обучения в СХД.
1. Изменение параметров работы всей системы в целом и ее отдельных компонентов
Алгоритм, изучая множество данных и следя за характеристиками устройств, может изменять параметры поведения системы хранения.
Были попытки реализации подобного «автопилота» для flash-накопителей. Следует отметить, что разработчикам устройств на основе NAND Flash всегда приходится идти на компромиссы, выбирая между объемом, надежностью и максимальным количеством перезаписей. В данном случае возможно изменять параметры устройства, настраивая поведение контроллера через выставление параметров регистров. Таких регистров может быть 50–100 в планарной памяти и более 1000 в 3D NAND.
Яркий пример машинного обучения для изменения параметров различных регистров демонстрирует стартап NVMdurance. Подробности о том, как ML может быть применено в сфере SSD-накопителей, читайте в whitepaper от Coughlin Associates.
2. Анализ поведения СХД и предиктивная аналитика
Алгоритм может анализировать журналы и историю событий и предсказывать потенциальные проблемы c кластером хранения. Так, большую работу на пути к “умному датацентру” проделали ребята из Nimble Storage. Рассказ об их продукте InfoSight вы можете найти по ссылке.
Развитие мобильных технологий и поведенческие характеристики нового поколения пользователей приведут к тому, что через 5-7 лет средства, используемые для управления инфраструктурой, будут понимать естественный язык. Уже сейчас появляются аналоги Microsoft IFTTT, которые понимают задачи вроде “Создать ссылку в Twitter для всех моих обновлений в Facebook”.
Рано или поздно системы на предприятиях смогут по простому запросу предоставить информацию о состоянии инфраструктуры, выделить нужные ресурсы или провести анализ нагрузки.
Ясно одно — подход к управлению инфраструктурой предприятия изменится и изменится кардинально.
3. QoS (качество обслуживания) на уровне приложений
Третий важный случай применения ML — обеспечение QoS для определенных приложений. Очевидно, что старый подход “одно приложение – один LUN” больше не работает. Мы неоднократно сталкивались с ситуацией, когда с одним и тем же томом с одного и того же хоста работают различные приложения. При этом многие из них совершенно не критичны для бизнеса, но очень требовательны к ресурсам.
Для решения этой проблемы мы реализовали проект QoSmic. Фактически, ПО RAIDIX научило СХД распознавать приложения и нагрузки по характерным признакам IO. О нем мы поговорим немного подробнее.
Разработка «умной» технологии QoS
Основной задачей большинства современных систем хранения данных является одновременное предоставление ресурсов хранения нескольким клиентским станциям (инициаторам).
Следует разделять задачи, требующие ресурсов хранения, на критичные и некритичные для бизнеса компании. Невозможность выполнения критичных для бизнеса задач в связи с тем, что все необходимые ресурсы были захвачены приложениями, выполняющими некритичные задачи, может привести к серьезным финансовым потерям.
Достаточно часто предоставление уровня обслуживания по запросам различных инициаторов формируется вручную системным администратором. Администратор может предоставить приоритет одному или нескольким инициаторам, тогда запросам от них будет предоставлена гарантированная пропускная способность. Однако такой способ управления в системах хранения данных не может обеспечить уровень обслуживания с оптимальной производительностью и надежностью.
В RAIDIX мы создали свою уникальную технологию автоматического представления приоритета QoSmic, основанную на идентификации работающих приложений в СХД “на лету”. С помощью алгоритма QoSmic распознаются критически важные бизнес-приложения, и именно им выставляется наивысший приоритет. Приоритет автоматически снимается, когда критически важное приложение перестает работать. Данный алгоритм может быть включен или выключен по желанию клиента.
Система хранения данных с встроенной технологией QoSmic представлена на Рисунке 1.
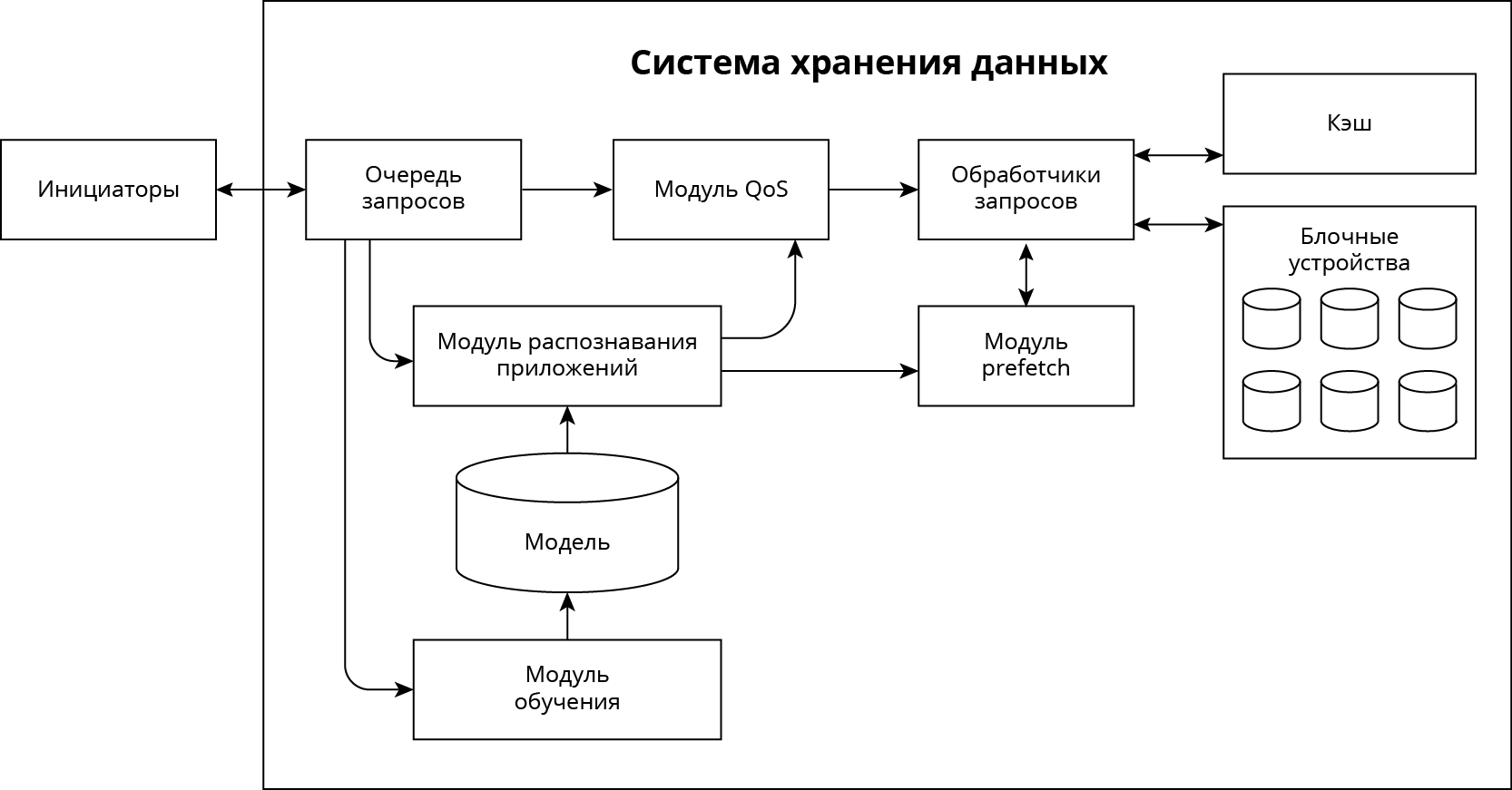
Рисунок 1. Система хранения данных с встроенной технологий QoSmic
Принцип работы QoSmic
Алгоритм идентификации приложений состоит из двух модулей: обучение и распознавание
- Модуль обучения: мы «знакомим» нашу систему хранения с новым приложением, которое планируется распознавать в целях работы QoS или упреждающего чтения
- Модуль распознавания: приложения для модуля QoS или упреждающего чтения идентифицируются в режиме реального времени.
Запросы в течении t секунд (например, 20 сек.) собираются в модули распознавания, далее данный лог анализируются, и по нему строятся I/O сигнатуры. Для идентификации приложения нам достаточно знать четыре характеристики: длину запроса, тип запроса (чтение или запись), оффсет (адресное пространство), время прихода запроса. В режиме обучения сигнатуры помечаются именем приложения, в режиме распознавания подаются в модуль для идентификации.
В качестве алгоритма классификации («Модель» на рис. 1) используется Random Forest.
Данный алгоритм довольно часто применяется в промышленной индустрии, так как обычно дает хорошие результаты и “понятен” для заказчика. И обладает рядом преимуществ такими как, высокая скорость обучения, неитеративное обучение (алгоритм завершается за фиксированное число операций), масштабируемость (способность обрабатывать большие объемы данных), высокое качество получаемых моделей (сравнимое с нейронными сетями и ансамблями нейронных сетей), малое количество настраиваемых параметров.
Далее с помощью алгоритма Random Forest и модели, полученной в режиме обучения, идентифицируются приложения, работающие на клиенте, или выдается ответ “не удалось определить” в случае:
- если на инициаторе работает неизвестное приложение;
- времени для идентификации недостаточно, обычно это происходит из-за низкой интенсивности I/O запросов, что не позволяет сформировать “надежные” I/O сигнатуры.
Потом имена приложений поступают в модуль QoS, который и выставляет приоритеты.
Нас часто спрашивают о том, как администратору понять, что пора выполнить переобучение? Переобучение стоит выполнить, если часто выдается вопрос “не удалось определить” или неправильно определяются приложения. В процессе обучения сам алгоритм может подсказать, что полученных сигнатур недостаточно для точной идентификации.
Функциональные особенности алгоритма QoSmic
Алгоритм точно идентифицирует приложения
Вероятность ошибок первого рода (когда важное приложение посчитали неважным) или второго рода (когда одно критически важное приложение было принято за другое) пренебрежимо мала и представлена в таблице 1.
Высокий уровень точности, достигнутый благодаря выбранным параметрам в I/O сигнатуре, позволяет формировать достаточно точный статистический профиль приложений и, следовательно, с высокой точностью обнаруживать работающее критически важное приложение и отличать его от низкоприоритетного.
Таблица 1. Точность идентификации
| Ошибки первого рода | Ошибки второго рода | |
|---|---|---|
| Apple Final Cut Pro/X | 0.1% | 0.5% |
| Adobe Premiere Pro | 0.15% | 0.8% |
| Autodesk Smoke | 0.12% | 0.7% |
| Antivirus Kaspersky Small Business Security | 0.01% | 0.01% |
| SQL база данных | 0.005% | 0.01% |
| Неважные приложения | 0.1% | -- |
Для сравнения выбраны три медийных приложения, которые генерят довольно-похожий последовательный траффик. Под неважными приложениями подразумевается работа браузера, служебные утилиты, простое копирование, бэкапы и т.п.
Алгоритм распознавания не требователен к ресурсам и не влияет на производительность системы
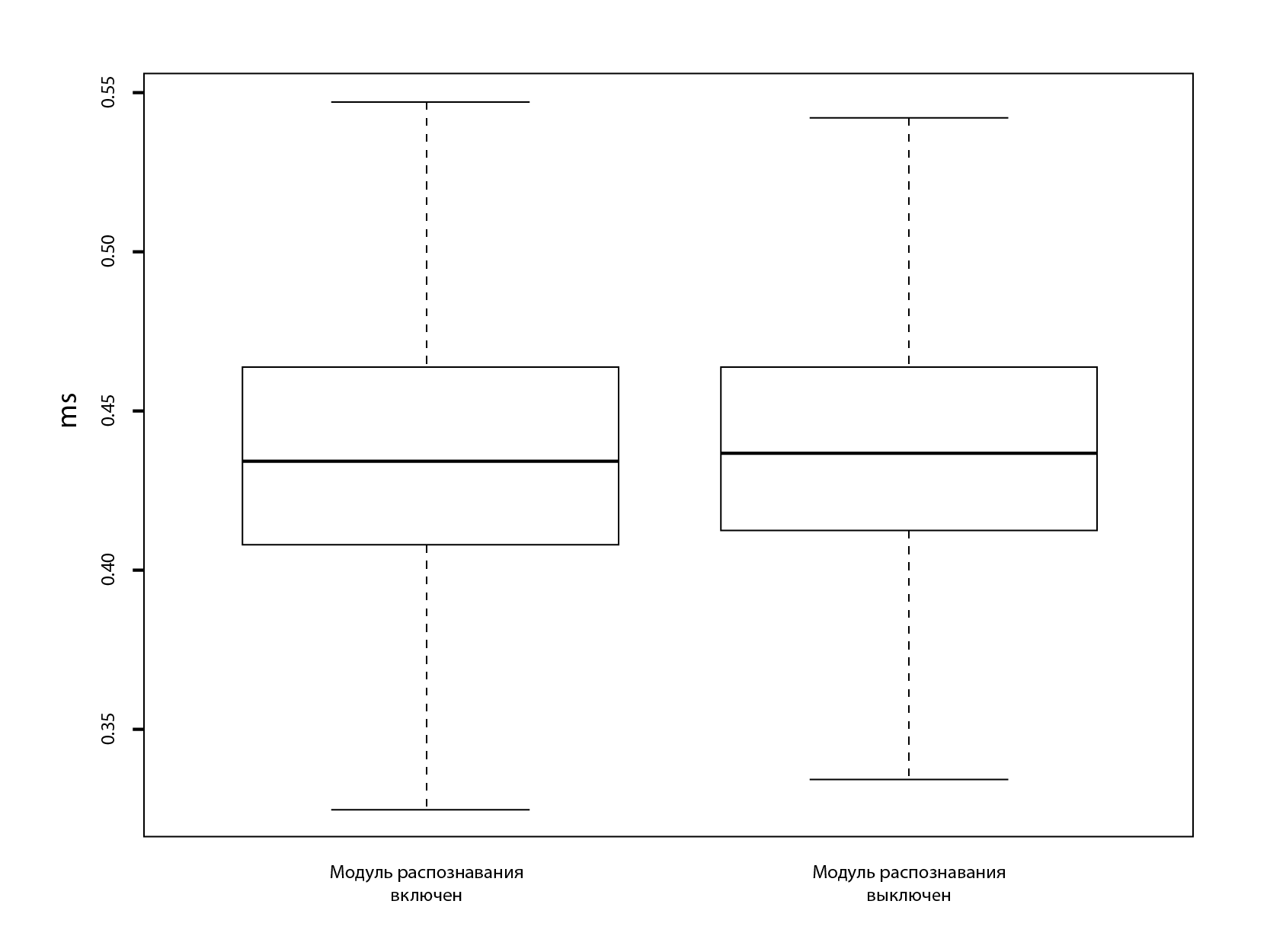
Рисунок 2. Диаграмма размаха распределения latency СХД
При максимальной по интенсивности нагрузке на систему хранения данных с маломощным процессором и недорогими HDD потребительского класса производительность системы практически не меняется, то есть конечный пользователь не ощущает никаких задержек в работе системы как при включенном, так и при выключенном режиме QoSmic (см. рисунок 2 и таблицу 2).
Таблица 2. Тестирование производительности с помощью Iometer
| Workload | Length of request, KB | Read % | Decrease in bandwidth |
|---|---|---|---|
| Sequential read | 4, 32, 256, 1024 | 100% | 1.3% |
| Sequential write | 4, 32, 256, 1024 | 0% | <1% |
| Sequential read/write | 4, 32, 256, 1024 | 50% | 1.5% |
| Random read | 4, 32, 256, 1024 | 100% | 1.4% |
| Random write | 4, 32, 256, 1024 | 0% | < 1% |
| Random read/write | 4, 32, 256, 1024 | 50% | 2 % |
Заключение
Подводя итог, стоит выделить главные преимущества технологии QoSmic:
- высокая скорость и точность идентификации приложений;
- возможность распознавать различные паттерны в одном и том же приложении;
- возможность распознавать важные и неважные задачи на одном и том же инициаторе;
- низкие затраты ресурсов модуля (light weight).
Стоит также отметить, что модуль распознавания приложений может быть использован для упреждающего чтения.
Применение методов машинного обучения в СХД вполне реально и дает неплохие результаты. Такие технологии перестают быть фантастикой — они успешно работают и эффективно применяются. Сейчас пока рано говорить о том, заменит ли machine learning системного администратора или станет его лучшим помощником, но можно с уверенностью заявить, что эти методы окажут существенное влияние на работу отрасли в обозримом будущем.
