Комментарии 38
Тут как бы не жёлтая пресса. С такими заголовками читать хабр противно.
С точки зрения машинного обучения всё сложно. Если что-то подобное было в истории — модель всё поймет. Но это уже не черный лебедь, раз в истории было. Если не было — тут сложно, но некоторые алгоритмы (и это не random forest) могут всё разгадать.
Алгоритмы, которые могут разгадать, это нейросети, изредка градиентный бустинг над деревьями, и… линейные (с нелинейными фичами, преобразованным таргетом). На пальцах, они выучивают зависимость, поверхность управления (как в теории катастроф), а не сами данные (исключаем оверфит, меморайз и всё такое).
Хорошо генерализовавшая данные модель — может (и я сам с таким сталкивался, что не верил модели, а она предсказывала резкие изменения верно) говорить о серьезных поворотах в жизни системы.
Другое дело что запихать экономику США и глобальные взаимосвязи всё в одну модель — ну да вот так просто не сделать, тупо из-за тех же данных, хоть весь quandl купи.
Вот так я всё это вижу.
я сам с таким сталкивался, что не верил модели, а она предсказывала резкие изменения верно
Вот это то, что лично меня серьёзно пугает во всей этой отрасли. Мы, по сути, движемся к ситуации, когда есть система, которая функционирует, но никто (реально ни единый человек, включая её создателей) не может ответить на вопросы:
— почему она функционирует именно так?
— правильно ли она это делает (для сложных случаев, разумеется)?
— всегда ли она делает это правильно?
— как отличить «правильно» от «неправильно»?
— как она будет вести себя при заданных условиях?
и т.д. и т.п.
Она ведёт себя правильнее моих представлений о системе. Вы когда интеграл считаете, тоже конкретное число не знаете. А потом исходя из него действуете. Я могу в уме интеграл подсчитать, но неточно :)
Интеграл понятно как вычисляется. К тому же интеграл от одной и той же функции всегда будет один и тот же. А тут — далеко не факт.
Так в том и прикол весь. На самом деле модели можно верить в пределах её ошибки, а проверять A/B-тестами. Всё конечно признают, что глубокое обучение — когда фичи за тебя сеть извлекла — и когда веса не интерпретируются — это до некоторой степени чёрный ящик, да. Но в среднем оно кошку от собаки отличит, в своём проценте точности.
Это статистика же в обратную сторону. Найти функцию от данных, да ещё и чтобы вероятность параметров была максимальной. Это тупо работает — в пределах допущений в виде исходных данных — как и интеграл работает в прямую сторону.
Местами это уже давно так, и без МашОб. Например у меня в продакшне есть сервис с большим графом данных. Он ищет короткие пути встроенными в neo4j средствами, но никто не может проконтролировать реально ли это оптимальные пути или нет. Куда деваться?
Алгоритм в ТЗ это одно, а реализация совсем другое. Некий баг может и в ПО без МашОБ сидеть годами и портить результаты. Это даже на безопасных языках.
А в си и плюсах есть ещё приколы с undefined behaviour. Тоже никакого ML не надо, чтобы результат зависел от погоды на Марсе.
en.wikipedia.org/wiki/Undefined_behavior#Examples_in_C_and_C++
boolean start_war = false;
Ну и классика:
if (start_war = true)
kill_all_humans();
Или всерьёз полагаете что кто-то пишет код, работоспособность которого зависит исключительно от undefined behaviour?
Может вы не в курсе, что есть UB? Прогеры (разной квалификации) пишут код, а он потом делает совсем не то, что они думали, причём в зависимости от «погоды на Марсе». И безо всякого МО.
С багами аналогично. Можно сколько угодно теоретизировать на тему «спецификацию и реализацию можно верифицировать», на практике баги есть во всем ПО. Даже которое летает в космос на стоящем миллиарды баксов железе.
Проблема с нейронными сетями в том, что в принципе непонятно почему они работают именно так.
Алгоритмы машинного обучения имеют так скажем два режима — обучение (train) и предсказание (inference).
В режиме обучения сетка представляет собой функцию F(xi1, ..., xiN, theta_1, ..., theta_M) = y_hat_i, и некоторым оптимизационным алгоритмом (например можно даже Ньютоном) ищутся такие theta_j такие, что невязка (sum(abs(y_i — y_hat_i))) минимальная (или какая другая функция ошибки, в зависимости от задачи). Локальных оптимумов может быть много, поэтому применяются всякие ухищрения, чтобы попасть в оптимум поглубже… но это не суть.
Никакой магии, правда же?
При инференсе, просто берут найденные theta_j, и подставляют в F. Качество оценивают на таких x, которые при обучении не использовались.
Так что всё понятно как они работают. theta_j не интерпретируются, да. Но так когда сплайнами интерполируют, коэффициенты тоже не особо поддаются интерпретации. Нейросетка — упрощая — тот же сплайн.
Они работают тупо потому, что есть теоремы о сходимости. Невязка ненулевая потому что данные имеют шум, и потому что в глобальный оптимум сетка может и не попасть (поверхность ошибки уж больно многомерная, часто с протяженными желобами-оврагами). И никакая сетка реальный мусор не развяжет на отложенном множестве, как её ни обучай, если там мешанина.
TLDR — нейросетки работают именно так, как их настроили и на каких данных. Это просто функция от данных* и их настроек (гиперпараметров) — как и другие алгоритмы машинного обучения.
* — это не (всегда) значит что она знает все данные, что и проверяется отложенным множеством.
Вот я сегодня взял тот алгоритм, который сам как-то придумал, и решил прогнать на датасете рукописных цифр (MNIST). Он по построению запоминает датасет, но при инференсе наоборот… делает предположение о таргете. SVM, с которым я сравниваю, при обучении ищет прямые, которые разделяют классы так, чтобы они были разнесены прямой как можно дальше.
Нейросетка тоже разделяет классы преобразованиями, запутанные данные распутывает до той степени, чтобы они были линейно разделимы (если принципиально может), и делает это при обучении, а при инференсе повторяет всё распутывание для каждого входящего примера — и относит его в итоге куда-то.
Короче я тут что-то разошелся…
Моё резюме (номера два:)).
Алгоритм и нейросетка (в режиме инференса) — одно и то же. Просто коэффициенты в алгоритм и в сетку добываются различными способами. Либо на бумаге, либо подгонкой под известные данные с последующей проверкой на неизвестных.
Вот тут уместна картинка про Карлсона-датасайнтиста и «Ты чо, пёс? Я математик!» :)
Я на самом деле соврал про функционал, который минимизируют, но там все чутьчуть эквивалентно. На самом деле нынче максисизируют вероятность получить theta при условии имеющихся данных. То есть находят наиболее вероятные параметры.
Что касается Карлсона, это самоирония. Дата сайентист и аналитик, и математик, и программист. Все вместе, но у разных сайнтистов разные пропорции. Это не столько от конторы, сколько от его бэкграунда зависит.
Я больше на инструменты полагаюсь, ищу там где светло чаще всего, а не где потерял. Увеличивая радиус освещения, пока не найду :) потому что я не математик уже лет 12, программист в основном. Поэтому Карлсон тот был немного про меня.
Однако я знаю свои слабые стороны, и постоянно качаю скиллы в разведочном анализе, байесе, по мере наличия времени. Нынче много инструментов в дата сайенсе, что матан можно и не знать, казалось бы. Проблема в том что толком их можно будет, эти инструменты, применять только для задач из примеров. В реальной практике действительно математика нужна. Очень сложно получить первую рабочую модель, но зато потом её можно тюнить и катать кроссвалидации уже до посинения. И без знания устройства моделей, матана того же, не выйдет и это кстати тоже.
Сложно разобрать сезонность.
Например, как здесь:

Если есть понимание бизнеса, от каких параметров зависит спрос, то затоваривание и убытки с применением прогнозирования уменьшаются.
Достаточно определить наклон продаж каждой номенклатурной группы, выделить параметры влияющие на продажи, определить их корреляцию с продажами(порой и в течение года влияние/взаимосвязь параметра на продажи менялась) и строить прогноз на основе модели.
Если у кого во время учёбы в универа был вопрос «зачем в жизни эконометрика?», то вот ответ.
В итоге решение было реализовано в продакшене?
Интересно, на основание чего принималось решение об эффективности новой системы прогнозирования для бизнеса. Как WAPE переводили в деньги?
В деньги переводится не само изменение WAPE, а изменение запасов и продаж на магазинах.
Если немного упростить, то бизнес-кейс рассчитывался двумя путями:
— на основании «benchmark» с предыдущих проектов
— на основании out-of-stock и упущенных продаж. Несмотря на то, что при построении модели использовалось предположение, что дефицита нет (т.к. нам не успели выдать остатки), при расчете бизнес-кейса мы рассчитали «вторичный» дефицит из данных продаж и оценили упущенные продажи
Цифры оказались одного порядка
На каком уровне оценивалась ошибка, для всей сети?
WAPE оценивался понедельно двумя способами:
— ошибка прогноза товаров на всю сеть (цифры из статьи)
— ошибка прогноза товаров на каждом магазине — здесь улучшение еще лучше
Отслеживали ли, что происходило в конкретных магазинах?
Конкретные магазины отслеживали — это один из шагов процесса, необходимый для понимания, что вносит наибольший вклад в ошибку прогнозирования.
В итоге решение было реализовано в продакшене?
Смотря что иметь ввиду под продакшн:
— в текущем процессе используется простой прогноз продаж, мы предложили заменить его на чуть более сложный, это практически не изменяет работу аналитиков
— если рассматривать целевую картину, то TO-BE процесс предложен, но еще не реализован, так что про этот конкретный кейс сможем рассказать чуть позже
— Если под продакшн имеется ввиду scheduling ETL и запуска моделей, то на SAS это делается довольно просто, но это тема отдельной статьи
В деньги переводится не само изменение WAPE, а изменение запасов и продаж на магазинах.
Как оценивалось изменение запасов и продаж, если прогноз не шел в магазин и не исполнялся?
на основании «benchmark» с предыдущих проектов
А вы можете поделиться бенчмарками или это закрытая информация? :)
Если вы подразумеваете, что на запасы и продажи влияют также процессы исполнения/пополнения, то да, их вклад можно оценить только после того как прогноз пройдет всю цепочку от аналитика до выставления товара на полку.
Если прогнозы описанной в статье модели будут 1:1 выполнены то конечно издержки на остатки сократятся но каковы будут упущенные продажи и денежные потери? Так же не известно на какой горизонт вы прогнозируете и к чему это занижение приведет.
Хорошо, если есть понимание что нужно немного перепрогнозить то насколько? Немного понятие относительное, и в добавок это же не будет достигнуто если под те же метрики отпимизироваться, а если корректировать вручную то это уже не совсем аналитическое решение.
Хорошо, если есть понимание что нужно немного перепрогнозить то насколько?
Для точного ответа на этот вопрос надо понимать все косты на всем сквозном процессе предприятия — ФОТ, закупка, логистика, хранение, списания и сотни других факторов, влияющих на себестоимость конкретного товара в конкретном магазине. Отсюда можно сделать свою функцию потерь и ее оптимизировать. Или Reinforcement Learning в помощь:). WAPE, MAPE, SMAPE — это некоторые приближения, которые выбираются под задачу. Определить баланс между BIAS и WAPE можно, например, экспериментально (если вам дадут это сделать КМ'ы).
Тогда это просто дескриптивная статистика которая не помогает мне решить проблему недопрогноза.
Дескриптивная статистика не так плохо, если у вас есть фабрика моделей и вы выбираете наилучшую с точки зрения бизнеса.
а если корректировать вручную то это уже не совсем аналитическое решение
Смотря что считать аналитическим решением. Конечно голубая мечта многих, что весь процесс будет работать без участия людей. Но конкретно в ритейле до этого пока далеко. Поэтому часто аналитика рассматривается как инструмент поддержки принятия решений, а не инструмент принятия решений
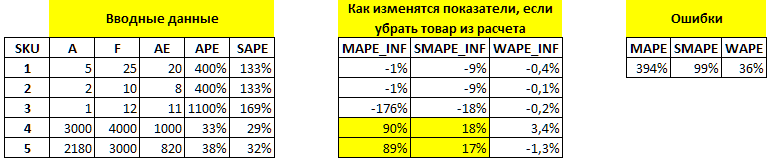
"Заказчик измерял текущую точность прогнозирования, используя метрику MAPE. Метрика популярна и проста, но обладает определенными недостатками"
я ожидал дальше по тексту увидеть про SMAPE как серебряную пулю против низкой базы....
посчитан лаг 4 средних продаж категории товара
я правильно понял что в итоге в качестве предикторов получили средние продажи по текущему магазину-товару за 4 недели относительно текущей (которая является откликом)?
Если да, то может быть лучше было бы в качестве предиктора использовать наклон линейной регрессии по этим 4 предыдущим неделям или это в вашем случае давало результаты хуже чем средние продажи за неделю?
К сожалению каждый отдельный товар больше 6 недель не продается. А основная сложность была спрогнозировать именно первые недели, поэтому рассчитать лаг за 4 недели на уровне магазин-товар не получится. Мы смотрели лаги средних продаж категории.
Можно попробовать использовать производные продаж (кроме среднего значения) на уровне категории. Это хорошая гипотеза на дальнейшее развитие. Основная задача здесь была максимально быстро показать применимый результат с минимальными усилиями, так называемый Quick-Win.
Использовать машинное обучение не сложно. Для этого достаточно в течение недели…