
Генеративные языковые модели уверенно обосновались в практике Natural Language Processing (NLP). Большие предобученные трансформеры двигаются сразу в трёх направлениях: мультимодальность, мультизадачность и мультиязычность. Сегодня мы расскажем про последнюю — о том, как учили модель на основе GPT-3 на 61 языке мира.
Это — самая многоязычная авторегрессионная модель на сегодня. Такую модель можно использовать, например, чтобы создать вопросно-ответную систему, обрабатывающую тексты на многих языках, научить диалогового ассистента говорить на разных языках, а также сделать более универсальные решения для парсинга текста, извлечения информации.
Этим релизом мы хотим привлечь внимание к развитию NLP для языков стран СНГ, а также народов России. Для многих из представленных языков эта модель стала первой авторегрессионной языковой моделью.
Модель доступна в двух вариантах размеров: mGPT XL на 1,3 миллиарда параметров — в открытом доступе, а mGPT 13B — будет доступна в ML Space SberCloud.
Генерация на разных языках зависит от многих факторов. Обучение на всех языках сразу должно давать неоспоримое преимущество в вопросах задач, связанных с информационным поиском, но что при этом происходит с качеством генерации, классификации объектов реального мира и повседневной жизни? Насколько на него влияют культурные особенности? Мы попробуем ответить на вопрос в этой статье.
(Здесь и далее все затравки выделяем курсивом, дальше — генерация модели.)
Русский | В мае мы празднуем Первомай!!! Уважаемые наши студенты и жители города, придём вместе сегодня на площадь! |
Английский | In May we celebrate the First Friday Special Mother’s Day (В мае мы отмечаем особенный День матери в первую пятницу.) |
Хинди | मई में हम मनाते हैं साल फूल और पुरानी यादों को ताजा करते हैं। कन्या नवरात्र के अंतर्गत नारियल की पूजा का त्यौहार कन्यादान है, इसके कारण नारियल को राजाओं की पूजा के तौर पर भी माना गया है (В мае мы встречаем год цветами и переживаем старые воспоминания. Фестиваль поклонения кокосу под Канья Наваратри называется Каньядан, из-за которого кокос также считается объектом поклонения королей.) |
Китайский | 五月我们庆祝五一儿童节活动 (В мае мы отмечаем День защиты детей) |
Армянский | Մայիսին մենք նշում ենք Արարատի մարզի հայ գրողների և մանկավարժների օր (В мае мы отмечаем день армянских писателей и педагогов Араратской области.) |
Дальше мы расскажем, как собирали данные, как обучали модели, а также посмотрим на сценарии применения модели.
Датасет
Что делать с корпусами, когда языков реально много? Балансировать по языкам и источникам.
Интернет-корпуса: Большие encoder-decoder архитектуры, например, mBart (25 языков) и mT5 (101 язык), используют корпус MC4 — он же Multilingual Colossal Cleaned Common Crawl. По сути это открытый поисковый индекс, где автоматически определены языки + произведена чистка от спама, рекламы, html-разметки различными эвристиками. В прошлом году HuggingFace разместили датасет у себя, чем сильно облегчили работу с ним. MC4 уже даёт определённое разнообразие языков и относительную чистоту данных, поэтому мы использовали его.
Однако список языков MC4 совсем не включает многие языки народов России, причём даже популярные.
Больше языков: чтобы расширить список доступных модели языков, мы привлекли дополнительные данные, а именно веб-корпуса языков России, собранные школой лингвистики НИУ ВШЭ: как-то на Хабре уже была дискуссия о том, почему языки нужны, и не только лингвистам, но и разработчикам ИТ-продуктов и сервисов.
Для отбора языков в нашу модель мы использовали такой принцип:
1) взять основные языки, для которых данных достаточно (самые ресурсные);
2) к ним добавить языки, для которых сделано мало, так называемые малоресурсные языки (low-resource languages), желательно, чтобы для каждого такого языка был его многоресурсный родственник в той же семье;
3) к этим языкам дополнительно добавляем языки СНГ и народов России, для которых есть достаточно данных;
4) немного балансируем полученные корпуса за счёт самых крупных языков, чтобы сгладить неравенство в объёме данных: модель, обученная на 80% английских текстов, скорее всего, не будет слишком многоязычной.
Фактология: ну и, конечно, мы добавили все доступные статьи Википедии для языков из нашего списка, чтобы добавить фактических знаний модели, а не только обсуждений из интернета.
Все языки модели: азербайджанский, английский, арабский, армянский, африкаанс, баскский, башкирский, белорусский, бенгальский, бирманский, болгарский, бурятский, венгерский язык, вьетнамский, голландский, греческий (современный), грузинский, датский, иврит (современный), индонезийский, испанский (кастильский), итальянский, йоруба, казахский, калмыцкий, киргизский, китайский, корейский, латышский, литовский, малайский, малаялам, маратхи, молдавский, монгольский, немецкий, осетинский, персидский, польский, португальский, румынский, русский, суахили, таджикский, тайский, тамильский, татарский, телугу, тувинский, турецкий, туркменский, узбекский, украинский, урду, финский, французский, хинди, чувашский, шведский, якутский, японский.
Фильтрация:
И Википедия, и MC4 нуждаются в очистке, прежде чем будут использованы для обучения модели. И если у веб-корпусов основные усилия по очистке приходятся на удаление спама, рекламы, ключевых слов, то в случае с Википедией проблемы бывают совсем другие: например, для родственных языков случается копирование статей, а ещё — их автоматический перевод.
Чтобы избежать такого шума, мы использовали следующий набор эвристик:
Дедупликация: мы провели дедупликацию с помощью 64-битного хеширования каждого текста, сохраняя в выборке только тексты с уникальными хешами.
Фильтрация: затем документы были отфильтрованы — из MC4 были удалены тексты, коэффициент сжатия которых не попадал в подобранный интервал. Таким образом из выборки были удалены тексты со слишком высокой (например, случайные последовательности символов — пароли, хеши и т. п.) или слишком низкой (например, множественные повторы символов) энтропией. Оставшиеся документы были отфильтрованы небольшим бинарным классификатором, обученным отделять вики-тексты (положительные образцы) от интернет-текстов (отрицательный пример). Таким образом в выборке остались наиболее содержательные тексты.
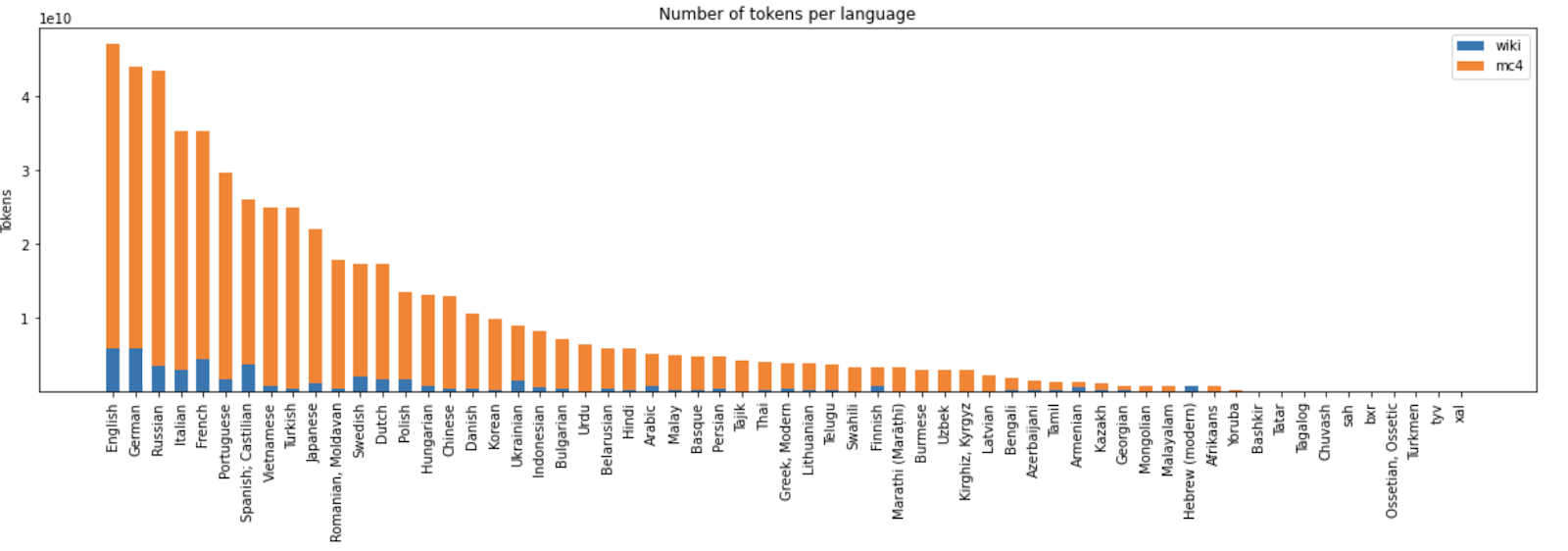
Общий датасет после фильтрации составил 488 миллиардов UTF-8 символов.
Итоговое соотношение языков в обучающем корпусе:
Архитектура
В 2022 году исследователям доступна широкая палитра трансформерных архитектур. Большинство из них объединяет принадлежность к трём классам:
GPT-подобные (или авторегрессионные трансформеры).
BERT-подобные (энкодеры).
BART/T5-подобные (sequence-to-sequence трансформеры).
Все они являются языковыми моделями, однако, подходят для разных задач и обучаются кодировать последовательность разными способами (masked language modelling, permutation masking и др.)
Архитектура, которую мы берём за основу — ruGPT-3. Она же воссозданная по научным статьям архитектура GPT-3: это декодерная модель, предсказывающая следующий элемент последовательности, с длиной контекста 2048 и количеством слоёв в 24 шт. Для воссоздания и обучения модели мы используем библиотеку Megatron-LM и DeepSpeed для реализации разреженного внимания [sparse attention]. Веса модели затем портируются в формат, совместимый с HuggingFace Transformers. Итоговую модель загрузить очень просто:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("sberbank-ai/mGPT")
model = GPT2LMHeadModel.from_pretrained("sberbank-ai/mGPT")Модели в 2 вариантах имеют 1.3 и 13 миллиардов параметров. Размер словаря у моделей одинаковый: 100 тысяч токенов в словаре, собранном при обучении bype-level byte-pair encoding (BBPE tokenization).
Обучение
Мы учили модели, используя размер батча 2048 и контекстное окно размером 512 токенов для первых 400 000 шагов. После этого мы дополнительно доучили модель на обновлённой очищенной версии датасета на ещё 200 000 шагах.
Всего за время обучения модели просмотрели 440 миллиардов токенов.
Вся процедура обучения модели на Christofari заняла 14 дней на 256 GPU NVidia V100 для модели mGPT XL и 22 дня на 512 GPU для модели mGPT 13B.

Падающий лосс обучения mGPT XL
Оценка модели
Как оценивать генеративные модели? Как обычно, есть простой способ и способ с подковыркой. И мы использовали оба.
Простой способ: измерить перплексию модели на некоторой отложенной тестовой выборке, которая не участвовала в обучении. Перплексия модели суть экспонента от лосса модели, нормированная на число токенов в тексте. Посмотрим на формулу:
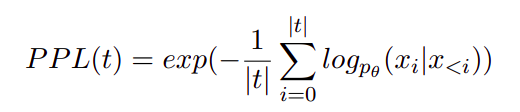
Тут t — входной текст, |t| длина текста в токенах, а log p θ (x i |x <i) — логарифмическая вероятность i-го токена в t, обусловленная предыдущими.
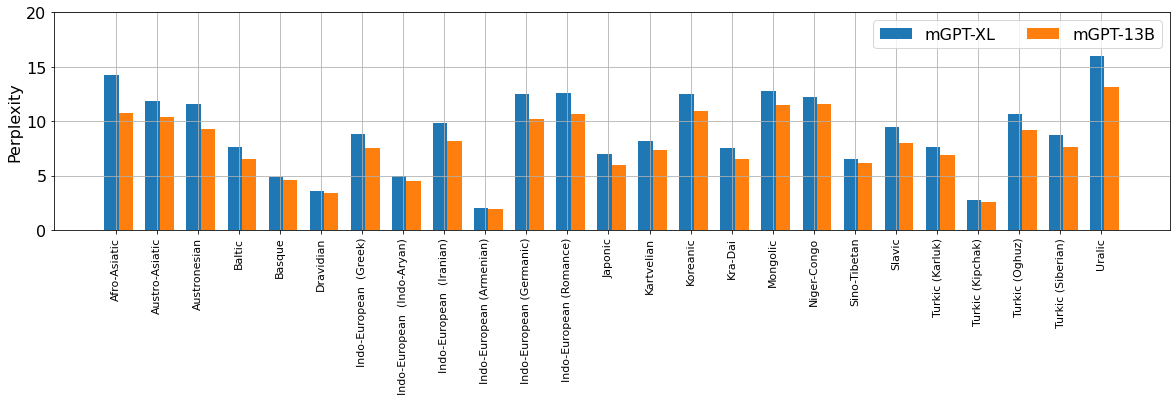
Наша модель для многих языков стала первой генеративной или первой, на которой измерена хоть какая-то перплексия для этого языка.
Перплексии модели в среднем по языковым семьям:
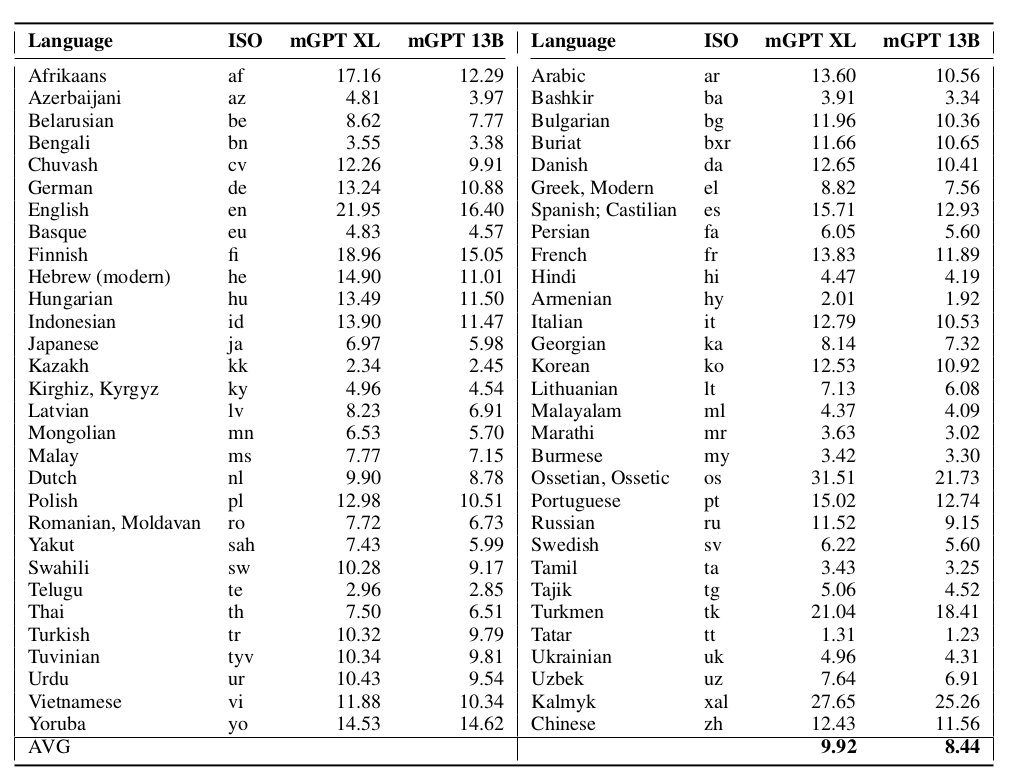
Перплексия моделей на каждом отдельном языке:
Ещё эксперименты!
А как же способ с подковыркой?
Он заключается в том, чтобы измерить вполне себе привычные метрики качества модели на самых разных задачах: классификации, генерации, разметке последовательности.
Так как авторегрессионные модели тяжёлые, но при этом обладают хорошей обобщающей способностью, то делать мы это будем без дообучения, с помощью few-shot и zero-shot подхода.
Zero-shot подход подразумевает, что мы стремимся решить данную нам задачу, обрабатывая исключительно вывод инференса модели по входному примеру или его модификациям (например, посмотрим на logits, loss, перплексию текста).
Few-shot даёт чуть больше свободы: в такой постановке мы можем использовать несколько хороших примеров из обучающей выборки, склеить их вместе и включить их в затравку модели. Затем, точно так же, посмотреть на loss, перплексию текста и т.д.
Так, в случае с zero-shot, мы делаем генерацию с затравки: ''Интересные факты о лягушках”:
mGPT 13B: Интересные факты о лягушках:
Лягушки едят еду человека, не жалея пальцев.
Первые лягушки появились в Сантьяго-де-Кубе незадолго до основания мексиканской столицы в 1517 году.
Первые лягушки появились во времена Крестовых походов, как ездовые животные.
Поговаривают, что первые лягушки появились в царской России.
Первый раз ел лягушку царский новорожденный сын Алексей Романов.
Первый лягушонок был наделен вейром, и его носил Петр I.
А в случае с Few-shot, берём подстроку с примером:
mGPT 13B: Интересные факты о лягушках:
Самая крупная лягушка — голиаф, вес которого может достигать 3 кг.
В естественных условиях бизон может жить около 50 лет, в закрытых зоопарках — до 80 лет.
В зоопарке города Виттенберге, Германия, живёт самая высокая лягушка в мире: необычные соотношения строения позвоночника (верхние ребра срастаются с ножками — в детстве)) и веса (бизон весит в среднем около 4,5 кг. без хвоста).
Чтобы провести полноценную оценку, мы взяли популярные бенчмарки, включающие задания как разных форматов, так и данные на разных языках. Для задач классификации получилось, в общем-то, неплохо!
Средняя точность (accuracy) по всем языкам на 5 задачах классификации:
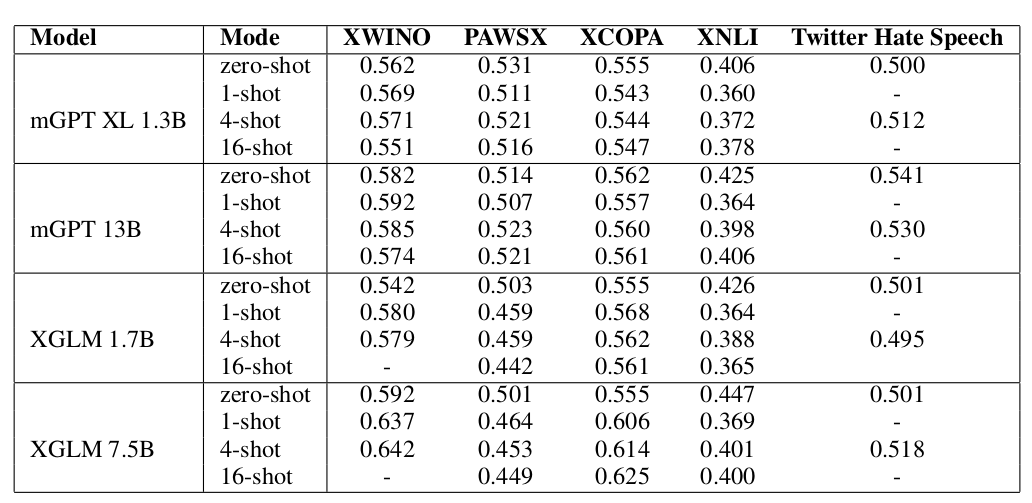
(Сравниваемся с моделью XGLM, обученной на 30 языках.)
Все проведенные тесты можно посмотреть в статье.
Мультиязычный пробинг знаний о мире
Мы рассчитали чисто статистические метрики и рассмотрели некоторые конкретные применения. А как быть со знаниями модели? Не отличаются ли версии Википедии на разных языках друг от друга настолько, что модель не сможет обобщить полученную информацию?
Так как модель обучалась на большом корпусе, стоит проверить, насколько её «картина мира» соответствует объективной реальности. Бенчмарк, проверяющий эту способность модели, называется mLAMA: multilingual LAnguage Model Analysis. Этот бенчмарк использует пробинг знаний моделей, чтобы оценить их способность отличать корректную фактологическую информацию от некорректной на разных языках.
Пробинг знаний — методология, которая предлагает тестирование предобученной модели на способность отличить фактологически корректные примеры от специально подобранных некорректных. Такой пробинг чаще всего формулируется как задача выбора верного факта из нескольких доступных. В нашем случае модель выбирала один из трёх вариантов.
Результаты пробинга знаний по доступным языкам: точность, среднее значение в районе 53%. Случайный выбор даёт 33%. Лучше всего модель работает с английским, хуже всего — с бенгальским.
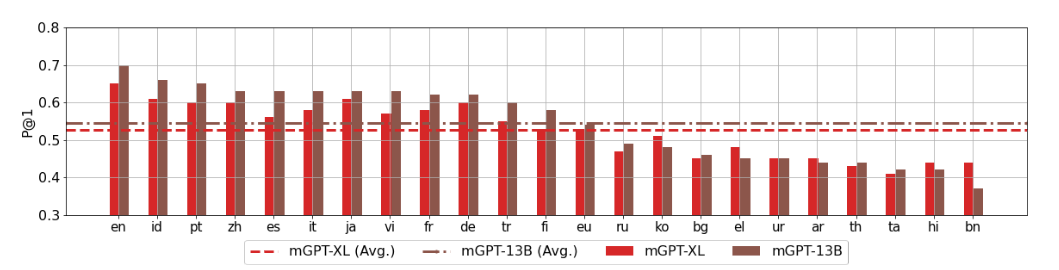
Конечно, итоговое знание, хранящееся в модели на разных языках, немного разное.
Культурные особенности находят своё явное отражение в примерах вида “счастье — это”:
Русский: Счастье — это когда сбывается то, о чем можно и мечтать!
Английский: Happiness is simply this: in every moment of your life, this image of yourself—to be sure it exists—is presented to the universe in a reflection of the one whose presence you experience.
(Счастье просто в следующем: в каждый момент вашей жизни этот ваш образ — чтобы быть уверенным, что он существует — представляется Вселенной в отражении того, чье присутствие вы ощущаете.)
Хинди: खुशी है प्रधानमंत्री की ट्रोलिंग के बाद
Счастливый после троллинга в личке
Узбекский: Baxt bu yerda - sog'lik
(Счастье здесь — это здоровье)
Китайский: 幸福就是有人照顾你
(Счастье — это когда кто-то заботится о тебе)
У кого больше зарплата?
Русский: Моя зарплата составляет 50000 руб, поэтому я выбираю сразу трех работодателей и начинаю искать работу, желая выбрать ту, которая удобна мне.
Английский: My salary is about $400.
Хинди: मेरा वेतन है तो मेरा वेतन बढाएगी मोदी सरकार, नाम लेने से नहीं मिला फोन, रिश्वत मांगी गई डॉ
(Правительство Моди повысит мою зарплату, если там будет моя зарплата.)
Узбекский: Mening maoshim bilan oyiga 5 litr benzin olib o‘tirishim shartmi?
Maktab o‘quvchilari mehnat yarmarkasida bir ishchiga 800 ming so‘m maosh undirdi
(Должен ли я платить за 5 литров бензина в месяц?
На ярмарке вакансий студенты заработали по 800 000 сумов на одного работника)
Китайский: 我的工資是4800塊,你說自己的工資多少比較合理。你記住,你家底薪每月8000塊
(Моя зарплата 4800 юаней, вы сказали, что моя зарплата более приемлемая. Помните, что ваша базовая зарплата составляет 8000 юаней в месяц.)
Где и как потрогать модель
Потенциально наиболее простыми в реализации нам видятся следующие применения модели:
Если обучающих данных нет:
zero-shot генерация для создания контента на новых языках
few-shot генерация для baseline-решения прикладных задач (классификация, sequence labelling, генерация) на разных языках.
Если обучающих данных мало:
используем техники с заморозкой слоёв (layer freezing) или тюнингом затравки (prompt tuning, prefix tuning, p-tuning). Также модель можно ансамблировать, чтобы комбинировать распределения: выходы большой модели с выходами небольшой модели, обученной решению целевой задачи или на целевом языке.
Если обучающие данные есть: fine-tuning на конкретной задаче с переносом навыка на новые языки. Например, болталки в диалоговых системах для языков России, вопросно-ответные системы (модель видела всю Википедию), автоматический перевод.
Как и всегда, будем рады вашим идеям, вопросам и применению моделей!
Напоследок, наш любимый тестовый пример — “классификация животных” Борхеса (как объяснял сам автор, его таксономия животных нужна, чтобы показать невозможность классифицировать реальность):
Оригинал | животные делятся на: а) принадлежащих Императору, б) набальзамированных, в) прирученных, г) молочных поросят, д) сирен, е) сказочных, ж) бродячих собак, |
Russian | Животные делятся на: а) принадлежащих Императору, б) имеющих доходы от частной собственности, в) принадлежащих гражданам. |
English | animals are classified into: (a) belonging to the Emperor, (b) being raw materials (valuables), (c) belonging to the merchant, (d) belonging to the masons (miners). |
Spanish | los animales se clasifican en: (a) pertenecientes al Emperador, (b) asociados con procesos y problemas diversos al comportamiento de los mismos animales, (c) pertenecientes a razas peligrosas, (d) asociadas con la investigación biológica y tecnológica |
French | les animaux sont classés en : (a) appartenant à l'Empereur, (b) appartenant aux autres personnages, (c) cherchant à progresser, (d) sous l'emprise de métaux toxiques. |
Hindi | जानवरों में वर्गीकृत किया गया है: (ए) सम्राट से संबंधित, (बी) दंतेवाड़ा से संबंधित, (सी) बाँकुरा से संबंधित, (दी) कुड़िया से संबंधित, |
Thai | สัตว์แบ่งออกเป็น: (ก) เป็นของจักรพรรดิ (ข) การแบ่งย่อย "ภูมิหลัง" ที่ชี้ไปที่รุ่น (ด) รุ่น หรือไซส์ นิยาม อุปกรณ์พิเศษของสัตว์นั้นประกอบด้วย: (ร) ผู้ใหญ่, เต่าทะเล (คา) เต่าสกุล, (ร) ซุปเปอร์เทิร์น, ลึกสัตว์น้ำมัน (ก) ราชวงศ์สัตว์ (ฉ) อธิราชร์รุ่น, อุปุยตตรี |
