Memory on demand — автоматическое выделение памяти виртуальной машине по необходимости.
Я уже чуть раньше писал об этой идее: Управление памятью гостевой машины в облаке. Тогда это была теория и некоторые наброски с доказательствами, что эта идея сработает.
Сейчас, когда эта технология обрела практическое воплощение, и клиентская и серверная часть готовы и (вроде бы) отлажены, можно поговорить уже не про идею, а про то, как это работает. Как с пользовательской, так и с серверной части. Заодно, поговорим и о том, что получилось не так идеально, как хотелось бы.
Суть технологии memory on demand заключается в предоставлении гостю того количества памяти, которое ему нужно в каждый конкретный момент времени. Изменение объёма памяти происходит автоматически (без необходимости что-то менять в панели управления), на ходу (без перезагрузки) и в очень короткие сроки (порядка секунды и меньше). Если быть точным, выделяется объём памяти, который заняли приложения и ядро гостевой ОС, плюс небольшой объём на кеш.
Технически, для Xen Cloud Platform это организовано очень просто: в гостевой машине у нас агент (самописный, ибо штатные утилиты слишком прожорливы и неудобны), написанный на Си. Я выбирал на чём его писать — шелл, питон или Си. За шелл говорила простота реализации (5 строк), за питон — надёжность и красота кода. Но победил Си (около 150 строк кода) по двум причинам: информацию о состоянии машины нужно отправлять часто — и было бы нечестно «проедать» чужое машинное время и чужую память на удобном и красивом коде (вместо не очень изящного, но очень быстрого кода на Си).
Против питона, помимо всего прочего, говорило ещё то, что его нет в минимальной установке Debian'а.
Серверная часть (собственно, решающая сколько нужно памяти и выделяющая её) всё же на питоне — математики там не очень много, зато масса занудных для Си операций, связанных с конвертацией из строк в числа, работы со списками, словарями и т.д. Кроме того, эта машина потребляет служебные ресурсы и не сказывается на затратах клиентов.
Серверная часть принимает данные из гостевой системы и меняет размер памяти у гостей согласно политике управления памятью. Политику определяет пользователь (из панели управления или через API гостевой системы).
Идеальных вещей не бывает. У memory on demand тоже есть свои проблемы — и я думаю, что рассказывать о них заранее лучше, чем ошарашивать клиента пост-фактум.
Скрипты, регулирующие память, не следят за запросами к ОС, они следят лишь за показателями в самой ОС. Другими словами, если кто-то попросит у ОС пару гигабайт памяти за раз, то ему могут и отказать. А вот если он с интервалами попросит 10 раз по 200 — то вполне дадут. Как показали тесты, в серверной среде именно так — потребление памяти растёт по мере форков демонов и роста нагрузки, причём растёт с вполне конечной скоростью (так, что mod-server вполне успевает накинуть памяти до следующего крупного запроса).
Ещё одна страховка от этого — своп. Те, кто привык работать на VDS'ах на базе openVZ, наверное, удивятся. Те, кто привык к Xen'у или к обычным машинам, даже не обратят на это внимание. Да, в виртуальных машинах есть своп. И он даже используется! Спустя некоторое время работы машины (в реальных условиях, а не в лабораторном ничегонеделании) в свопе оказывается несколько сотен мегабайт данных.
К счастью, линукс весьма и весьма аккуратен со свопом, и выкидывает туда только неиспользующиеся данные (да и регулировать это поведение можно с помощью vm.swapiness).
Так вот, основная задача свопа в условиях Memory on demand — в страховке от слишком быстрых/толстых запросов. Такие запросы будут успешно обработаны без oom_killer'а, хоть и ценой некоторых тормозов. У пользователя же есть возможность повлиять на это поведение с помощью политик.
Есличеловек программа в гостевой системе попросила сильно много памяти за раз и часть малоиспользуемого кода оказалась выкинута в своп, то снова срабатывает mod-server (MOD=Memory On Demand), который накидывает памяти. Достаточно, чтобы очистить своп, но линукс существо ленивое, и выгружать из свопа неиспользуемые данные не торопится. Благодаря этому, бОльший объём памяти оказывается отдан под дисковый кеш (увеличение производительности). Если же линуксу потребуется что-то из свопа, то память готова принять эти данные.
Второй недостаток более фундаментальный. Динамическое управление памятью требует… памяти. Да, и довольно много. Для 256Мб это около 12Мб оверхеда, для 512 — около 20, для 2Гб — около 38, для 6Гб — около 60Мб оверхеда. Оверхед «съедается» то ли гипервизором, то ли ядром гостевой системы… Он даже не показывается в 'free' в TotalMem.
Можно подумать, что этот оверхед не очень большой. Однако, если у вас запас 5Гб, а реальное потребление 200, то вы будете иметь оверхед 50Мб (т.е. платить за +25% памяти за право расти до 5Гб). Если потолок спустить до 2 Гб, то оверхед снизится до 10% памяти при 256 базы.
Таким образом, оверхед является платой за готовность получить от гипервизора много памяти. С нашей же стороны (меркантильной, корыстной и т.д.) это является небольшой страховкой, что человек не станет просто так резервировать под себя 64 Гб памяти (ему придётся иметь оверхед около 6Гб, что довольно накладно для машины с потреблением в 200Мб). А вот сделать себе машинку с интервалом 300-2Гб — самое то. Оверхед маленький, запас по памяти есть.
Ещё одним недостатком является то, что менять верхний лимит памяти можно менять только с перезагрузкой.
Анлима (любого количества памяти по первому запросу — упор на слова «любого») нет и не будет. Причин несколько.
Во-первых, у нас физически не найдётся для вас 500 Гб памяти прямо-здесь-и-сейчас для одной-единственной виртуальной машины. Даже если попросите. Столько планок памяти в сервер не влазит. Во-вторых, сама технология требует (на настоящий момент) наличия потолка, причём, желательно, не сильно выше среднего потребления (не более, чем на полтора порядка, при больших цифрах сильно растёт оверхед, о нём было выше, запас до 500Гб сожрёт у вас этак гигабайт 30 памяти «в никуда» — дороговатое удовольствие получается).
Обещали анлим. Но не сделали. Точнее, формально его можно сделать в пределах возможности хоста облака, но такие диапазоны (128-48Гб) экономически не целесообразны.
Увы, красивой картинки с полным отсутствием верхней планки памяти не получилось. Зато удалось реализовать технологию оплаты по потреблению. Если вы (ваша ВМ) потребляет мало памяти — то денег платится мало. А запас на случай «шального хабра-эффекта» с пухнущими апачами есть.
Особый разговор с кешем. Мы не можем выставить объём памяти виртуальной машины строго по потреблению, потому что кеш всё-таки нужен. Не смотря на то, что до физических винтов там два уровня кеширования и десятки гигабайт памяти с кешем (общего назначения). Свой местный кеш позволяет уменьшить число дисковых операций (а они, между прочим, оплачиваются отдельно).
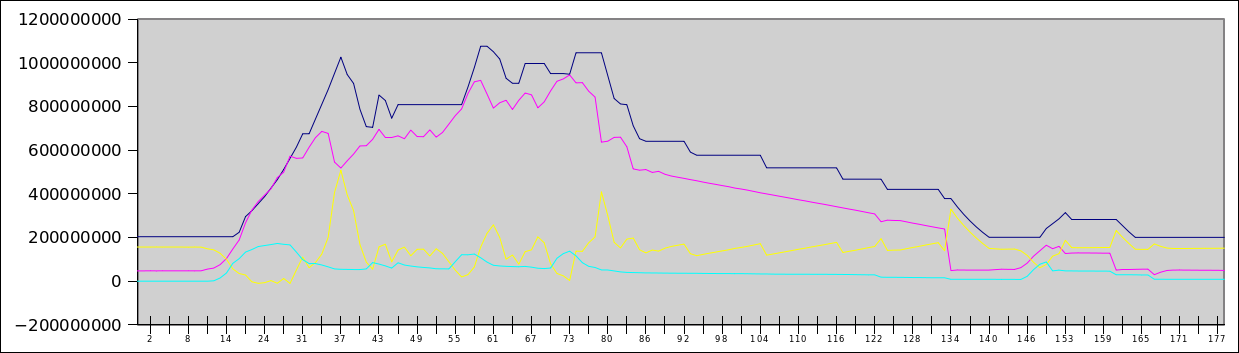
Таким образом, мы можем резервировать небольшой запас памяти в машине, который с одной стороны обслуживает запросы новой памяти внутри виртуальной машины (т.е. уменьшает число операций изменения квоты памяти у машины), а с другой стороны используется как дисковый кеш. Так как мы следим за объёмом памяти в госте, то память для кеша есть практически всегда, кроме моментов острого пикового потребления памяти (на графике это видно).
Не получится. Современные ядра хотят много памяти, так, что даже цифра в 64Мб их не устроит. Как показал тест, имеет смысл говорить о цифрах от 96Мб, или, с небольшой поправкой на кеш, от 128Мб. Если попытаться урезать память ниже этой величины (для пользователей этой возможности мы не предоставляем, а в лаборатории я пробовал), то получается очень плохо — ядро начинает паниковать, начинать делать глупости. Таким образом, разумный лимит, зафиксированный у нас в интерфейсе — это осознанное решение после тестов, а не запрет на экономию.
Ещё одной потенциальной проблемой могут быть приложения, стратегия которых состоит в использовании всего доступного объёма памяти. В этой ситуации включается дурная рекурсия:
Эта рекурсия закончится в тот момент, когда MOD-сервер не сможет увеличить объём памяти (из-за верхнего лимита).
Я знаю, что так себя ведёт Exchange 2007 и выше, некоторые версии SQL-серверов. Что делать в такой ситуации?
Я не знаю, какой подход будет лучше, практика покажет.
Ну, секрета тут особого нет.
В настоящий момент управление памятью осуществляется по очень топорному алгоритму с тремя режимами (init/run/stop) и простым гистерезисом, в ближайших перспективах написание алгоритма с оглядкой на статистику предыдущих запросов и подстройкой уровня оптимистичности выделения памяти.
P.S. В эту статью планировалось добавитьсисе.. графиков потребления и выделения памяти, однако, изготовление стенда, где бы это была не совсем синтетика, оказалось сложнее, чем я думал, так что графики будут через несколько дней.
PPS В качестве тизера — график хабраэффекта на 140 пользователей, одновременно гуляющих по сайту. Синяя линия — выделенная память, красная — занятая память, жёлтая — свободная, циан — своп-файл. По Y — байты (т.е. верх — 1.2Гб), по X — секунды с момента начала теста.
Я уже чуть раньше писал об этой идее: Управление памятью гостевой машины в облаке. Тогда это была теория и некоторые наброски с доказательствами, что эта идея сработает.
Сейчас, когда эта технология обрела практическое воплощение, и клиентская и серверная часть готовы и (вроде бы) отлажены, можно поговорить уже не про идею, а про то, как это работает. Как с пользовательской, так и с серверной части. Заодно, поговорим и о том, что получилось не так идеально, как хотелось бы.
Суть технологии memory on demand заключается в предоставлении гостю того количества памяти, которое ему нужно в каждый конкретный момент времени. Изменение объёма памяти происходит автоматически (без необходимости что-то менять в панели управления), на ходу (без перезагрузки) и в очень короткие сроки (порядка секунды и меньше). Если быть точным, выделяется объём памяти, который заняли приложения и ядро гостевой ОС, плюс небольшой объём на кеш.
Технически, для Xen Cloud Platform это организовано очень просто: в гостевой машине у нас агент (самописный, ибо штатные утилиты слишком прожорливы и неудобны), написанный на Си. Я выбирал на чём его писать — шелл, питон или Си. За шелл говорила простота реализации (5 строк), за питон — надёжность и красота кода. Но победил Си (около 150 строк кода) по двум причинам: информацию о состоянии машины нужно отправлять часто — и было бы нечестно «проедать» чужое машинное время и чужую память на удобном и красивом коде (вместо не очень изящного, но очень быстрого кода на Си).
Против питона, помимо всего прочего, говорило ещё то, что его нет в минимальной установке Debian'а.
Серверная часть (собственно, решающая сколько нужно памяти и выделяющая её) всё же на питоне — математики там не очень много, зато масса занудных для Си операций, связанных с конвертацией из строк в числа, работы со списками, словарями и т.д. Кроме того, эта машина потребляет служебные ресурсы и не сказывается на затратах клиентов.
Серверная часть принимает данные из гостевой системы и меняет размер памяти у гостей согласно политике управления памятью. Политику определяет пользователь (из панели управления или через API гостевой системы).
Идеальных вещей не бывает. У memory on demand тоже есть свои проблемы — и я думаю, что рассказывать о них заранее лучше, чем ошарашивать клиента пост-фактум.
Недостатки
Асинхронное выделение памяти
Скрипты, регулирующие память, не следят за запросами к ОС, они следят лишь за показателями в самой ОС. Другими словами, если кто-то попросит у ОС пару гигабайт памяти за раз, то ему могут и отказать. А вот если он с интервалами попросит 10 раз по 200 — то вполне дадут. Как показали тесты, в серверной среде именно так — потребление памяти растёт по мере форков демонов и роста нагрузки, причём растёт с вполне конечной скоростью (так, что mod-server вполне успевает накинуть памяти до следующего крупного запроса).
Ещё одна страховка от этого — своп. Те, кто привык работать на VDS'ах на базе openVZ, наверное, удивятся. Те, кто привык к Xen'у или к обычным машинам, даже не обратят на это внимание. Да, в виртуальных машинах есть своп. И он даже используется! Спустя некоторое время работы машины (в реальных условиях, а не в лабораторном ничегонеделании) в свопе оказывается несколько сотен мегабайт данных.
К счастью, линукс весьма и весьма аккуратен со свопом, и выкидывает туда только неиспользующиеся данные (да и регулировать это поведение можно с помощью vm.swapiness).
Так вот, основная задача свопа в условиях Memory on demand — в страховке от слишком быстрых/толстых запросов. Такие запросы будут успешно обработаны без oom_killer'а, хоть и ценой некоторых тормозов. У пользователя же есть возможность повлиять на это поведение с помощью политик.
Если
Оверхед
Второй недостаток более фундаментальный. Динамическое управление памятью требует… памяти. Да, и довольно много. Для 256Мб это около 12Мб оверхеда, для 512 — около 20, для 2Гб — около 38, для 6Гб — около 60Мб оверхеда. Оверхед «съедается» то ли гипервизором, то ли ядром гостевой системы… Он даже не показывается в 'free' в TotalMem.
Можно подумать, что этот оверхед не очень большой. Однако, если у вас запас 5Гб, а реальное потребление 200, то вы будете иметь оверхед 50Мб (т.е. платить за +25% памяти за право расти до 5Гб). Если потолок спустить до 2 Гб, то оверхед снизится до 10% памяти при 256 базы.
Таким образом, оверхед является платой за готовность получить от гипервизора много памяти. С нашей же стороны (меркантильной, корыстной и т.д.) это является небольшой страховкой, что человек не станет просто так резервировать под себя 64 Гб памяти (ему придётся иметь оверхед около 6Гб, что довольно накладно для машины с потреблением в 200Мб). А вот сделать себе машинку с интервалом 300-2Гб — самое то. Оверхед маленький, запас по памяти есть.
Ещё одним недостатком является то, что менять верхний лимит памяти можно менять только с перезагрузкой.
Анлим
Анлима (любого количества памяти по первому запросу — упор на слова «любого») нет и не будет. Причин несколько.
Во-первых, у нас физически не найдётся для вас 500 Гб памяти прямо-здесь-и-сейчас для одной-единственной виртуальной машины. Даже если попросите. Столько планок памяти в сервер не влазит. Во-вторых, сама технология требует (на настоящий момент) наличия потолка, причём, желательно, не сильно выше среднего потребления (не более, чем на полтора порядка, при больших цифрах сильно растёт оверхед, о нём было выше, запас до 500Гб сожрёт у вас этак гигабайт 30 памяти «в никуда» — дороговатое удовольствие получается).
Обещали анлим. Но не сделали. Точнее, формально его можно сделать в пределах возможности хоста облака, но такие диапазоны (128-48Гб) экономически не целесообразны.
Увы, красивой картинки с полным отсутствием верхней планки памяти не получилось. Зато удалось реализовать технологию оплаты по потреблению. Если вы (ваша ВМ) потребляет мало памяти — то денег платится мало. А запас на случай «шального хабра-эффекта» с пухнущими апачами есть.
Дисковый кеш
Особый разговор с кешем. Мы не можем выставить объём памяти виртуальной машины строго по потреблению, потому что кеш всё-таки нужен. Не смотря на то, что до физических винтов там два уровня кеширования и десятки гигабайт памяти с кешем (общего назначения). Свой местный кеш позволяет уменьшить число дисковых операций (а они, между прочим, оплачиваются отдельно).
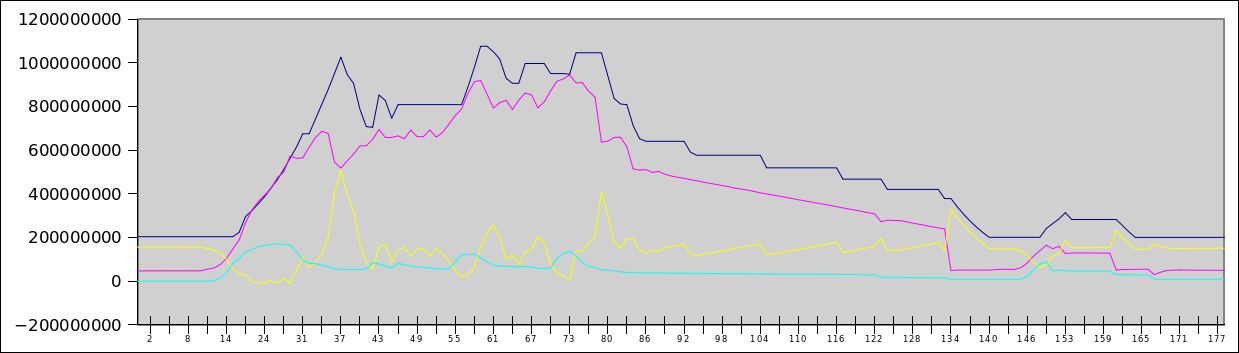
Таким образом, мы можем резервировать небольшой запас памяти в машине, который с одной стороны обслуживает запросы новой памяти внутри виртуальной машины (т.е. уменьшает число операций изменения квоты памяти у машины), а с другой стороны используется как дисковый кеш. Так как мы следим за объёмом памяти в госте, то память для кеша есть практически всегда, кроме моментов острого пикового потребления памяти (на графике это видно).
Сделайте мне сервер с 8Мб оперативной памяти
Не получится. Современные ядра хотят много памяти, так, что даже цифра в 64Мб их не устроит. Как показал тест, имеет смысл говорить о цифрах от 96Мб, или, с небольшой поправкой на кеш, от 128Мб. Если попытаться урезать память ниже этой величины (для пользователей этой возможности мы не предоставляем, а в лаборатории я пробовал), то получается очень плохо — ядро начинает паниковать, начинать делать глупости. Таким образом, разумный лимит, зафиксированный у нас в интерфейсе — это осознанное решение после тестов, а не запрет на экономию.
Я оглянулся посмотреть не оглянулась ли ты, посмоstack overflow
Ещё одной потенциальной проблемой могут быть приложения, стратегия которых состоит в использовании всего доступного объёма памяти. В этой ситуации включается дурная рекурсия:
- Программа видит, что свободно 32Мб
- Программа запрашивает у ОС 30 Мб
- MOD-агент сообщает серверу, что у ОС осталось свободно 2Мб памяти
- MOD-сервер накидывает гостевой ОС ещё 64Мб памяти
- Программа видит, что свободно ещё 66 Мб памяти
- Программа запрашивает у ОС ещё 64Мб памяти
Эта рекурсия закончится в тот момент, когда MOD-сервер не сможет увеличить объём памяти (из-за верхнего лимита).
Я знаю, что так себя ведёт Exchange 2007 и выше, некоторые версии SQL-серверов. Что делать в такой ситуации?
- Отключать возможность выделять память. Памяти столько, сколько поставили в панельке. Скучное решение
- Отключить автоматическое выделение памяти, перейти на API (нужна память, попросил). Основная проблема состоит в том, что такой подход противоречит идее memory on demand — автоматическому выделению памяти
- Изменить настройки программ (все подобные программы позволяют изменять поведение)
- Изменить настройку политики выделения памяти (например, сделать так, чтобы память выделение памяти происходило в тот момент, когда начинает использоваться своп).
Я не знаю, какой подход будет лучше, практика покажет.
Как это реализовано?
Ну, секрета тут особого нет.
xe vm-memory-dyniamic-range-set max=XXX min=YYY uuid=... — и дело в шляпе. Сама возможность менять на ходу память у виртуальной машины присутствует в зене давным давно. Однако, существовавшая реализация (xenballoond) была слишком оптимистичной (т.е. резервировала для виртуальной машины объём памяти много больше необходимого) и медлительной — не отрабатывала всплески и пики потребления. Кроме того, она сильно полагалась на своп, что в условиях платных дисковых операций не очень хорошая идея. Не говоря уже о том, что сам демон был написан на шелле.Перспективы
В настоящий момент управление памятью осуществляется по очень топорному алгоритму с тремя режимами (init/run/stop) и простым гистерезисом, в ближайших перспективах написание алгоритма с оглядкой на статистику предыдущих запросов и подстройкой уровня оптимистичности выделения памяти.
P.S. В эту статью планировалось добавить
PPS В качестве тизера — график хабраэффекта на 140 пользователей, одновременно гуляющих по сайту. Синяя линия — выделенная память, красная — занятая память, жёлтая — свободная, циан — своп-файл. По Y — байты (т.е. верх — 1.2Гб), по X — секунды с момента начала теста.