
Моя основная работа — это, по большей части, развертывание систем ПО, то есть уйму времени я трачу, пытаясь ответить на такие вот вопросы:
- У разработчика это ПО работает, а у меня нет. Почему?
- Вчера это ПО у меня работало, а сегодня нет. Почему?
Это — своего рода отладка, которая немного отличается от обычной отладки ПО. Обычная отладка — это про логику кода, а вот отладка развертывания — это про взаимодействие кода и среды. Даже если корень проблемы — логическая ошибка, тот факт, что на одной машине все работает, а на другой — нет, означает, что дело неким образом в среде.
Поэтому вместо обычных инструментов для отладки вроде gdb у меня есть другой набор инструментов для отладки развертывания. И мой любимый инструмент для борьбы с проблемой типа "Почему это ПО у меня не пашет?" называется strace.
Что же такое strace?
strace — это инструмент для "трассировки системного вызова". Изначально создавался под Linux, но те же фишки по отладке можно проворачивать и с инструментами для других систем (DTrace или ktrace).
Основное применение очень просто. Надо лишь запустить strace c любой командой и он отправит в дамп все системные вызовы (правда, сперва, наверное, придется установить сам strace):
$ strace echo Hello
...Snip lots of stuff...
write(1, "Hello\n", 6) = 6
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++Что это за системные вызовы? Это нечто вроде API для ядра операционной системы. Давным-давно у ПО был прямой доступ к "железу", на котором оно работало. Если, например, нужно было отобразить что-нибудь на экране, оно играло с портами и\или отображаемыми в память регистрами для видео-устройств. Когда стали популярны многозадачные компьютерные системы, воцарился хаос, потому что различные приложения дрались за "железо". Ошибки в одном приложении могли обрушить работу прочих, если не всю систему целиком. Тогда в ЦПУ появились режимы привилегий (или "кольцевая защита"). Самым привилегированным становилось ядро: оно получало полный доступ к "железу", плодя менее привилегированные приложения, которым уже приходилось запрашивать доступ у ядра для взаимодействия с "железом" — через системные вызовы.
На бинарном уровне системный вызов немного отличается от простого вызова функции, однако большинство программ используют обертку в стандартной библиотеке. Т.е. стандартная библиотека POSIX C содержит вызов функции write(), которая содержит весь зависящий от архитектуры код для системного вызова write.
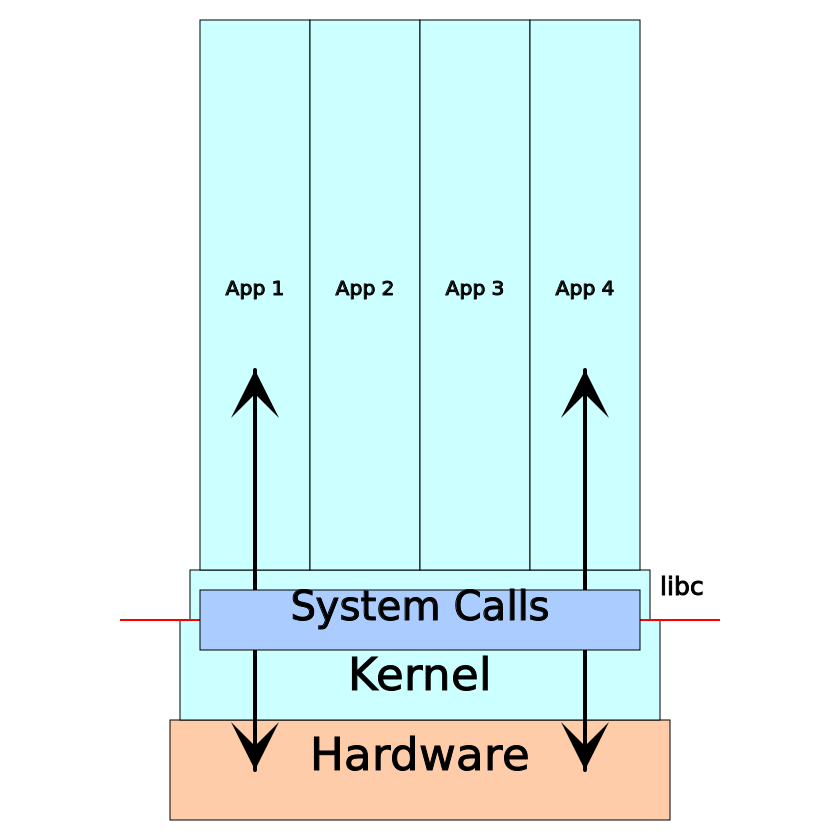
Если вкратце, то любое взаимодействие приложения со своей средой (компьютерными системами) осуществляется через системные вызовы. Поэтому когда ПО на одно машине работает, а на другой нет, хорошо бы заглянуть в результаты трассировки системных вызовов. Если же конкретнее, то вот вам список типичных моментов, которые можно проанализировать при помощи трассировки системного вызова:
- Консольный ввод-вывод
- Сетевой ввод-вывод
- Доступ к файловой системе и файловый ввод-вывод
- Управление сроком жизни процесса\потока
- Низкоуровневое управление памятью
- Доступ к драйверам особых устройств
Когда использовать strace?
В теории, strace используется с любыми программами в пользовательском пространстве, ведь любая программа в пользовательском пространстве должна делать системные вызовы. Он эффективнее работает с компилируемыми, низкоуровневыми программами, но и с высокоуровневыми языками вроде Python тоже работает, если получится продраться через дополнительный шум от среды исполнения и интерпретатора.
Во всем блеске strace проявляет себя во время отладки ПО, которое хорошо работает на одной машине, а на другой вдруг перестает работать, выдавая невнятные сообщения о файлах, разрешениях или неудачных попытках выполнить какие-то команды или еще что… Жаль, но не так хорошо он сочетается с высокоуровневыми проблемами типа ошибки проверки сертификата. Обычно тут требуется комбинация strace, иногда ltrace и инструментов более высокго уровня (вроде инструмента командной строки openssl для отладки сертификата).
Для примера берем работу на изолированном сервере, но трассировку системных вызовов зачастую можно выполнить и на более сложных платформах развертывания. Просто надо подобрать подходящий инструментарий.
Пример простой отладки
Скажем, хотите вы запустить потрясающее серверное приложение foo, а получается вот что:
$ foo
Error opening configuration file: No such file or directoryОчевидно, у него не получилось найти написанный вами конфигурационный файл. Так происходит, потому что иногда, когда менеджеры пакетов, компилируя приложение, переопределяют ожидаемое расположение файлов. И если следовать руководству по установке для одного дистрибутива, в другом находишь файлы совершенно не там, где ожидал. Решить проблему можно было бы за пару секунд, если бы сообщение об ошибке говорило, где следует искать конфигурационный файл, но ведь оно же не говорит. Так где искать?
Если есть доступ к исходному коду, можно прочесть его и все выяснить. Хороший запасной план, но не самое быстрое решение. Можно прибегнуть к пошаговому отладчику вроде gdb и посмотреть, что делает программа, но куда эффективнее использовать инструмент, который специально спроектирован показывать взаимодействие со средой: strace.
Вывод strace может показаться избыточным, но хорошие новости в том, что большую его часть можно смело игнорировать. Часто полезно использовать оператор -o, чтобы сохранять результаты трассировки в отдельный файл:
$ strace -o /tmp/trace foo
Error opening configuration file: No such file or directory
$ cat /tmp/trace
execve("foo", ["foo"], 0x7ffce98dc010 /* 16 vars */) = 0
brk(NULL) = 0x56363b3fb000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=25186, ...}) = 0
mmap(NULL, 25186, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f2f12cf1000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\260A\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1824496, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2f12cef000
mmap(NULL, 1837056, PROT_READ, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f2f12b2e000
mprotect(0x7f2f12b50000, 1658880, PROT_NONE) = 0
mmap(0x7f2f12b50000, 1343488, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x22000) = 0x7f2f12b50000
mmap(0x7f2f12c98000, 311296, PROT_READ, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x16a000) = 0x7f2f12c98000
mmap(0x7f2f12ce5000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1b6000) = 0x7f2f12ce5000
mmap(0x7f2f12ceb000, 14336, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f2f12ceb000
close(3) = 0
arch_prctl(ARCH_SET_FS, 0x7f2f12cf0500) = 0
mprotect(0x7f2f12ce5000, 16384, PROT_READ) = 0
mprotect(0x56363b08b000, 4096, PROT_READ) = 0
mprotect(0x7f2f12d1f000, 4096, PROT_READ) = 0
munmap(0x7f2f12cf1000, 25186) = 0
openat(AT_FDCWD, "/etc/foo/config.json", O_RDONLY) = -1 ENOENT (No such file or directory)
dup(2) = 3
fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
brk(NULL) = 0x56363b3fb000
brk(0x56363b41c000) = 0x56363b41c000
fstat(3, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x8), ...}) = 0
write(3, "Error opening configuration file"..., 60) = 60
close(3) = 0
exit_group(1) = ?
+++ exited with 1 +++Примерно вся первая страница вывода strace — это обычно низкоуровневая подготовка к запуску. (Много вызовов mmap, mprotect, brk для вещей типа обнаружения низкоуровневой памяти и отображение динамических библиотек.) Вообще-то, во время отладки выводы strace лучше читать с самого конца. Внизу будет вызов write, выводящий сообщение об ошибке. Смотрим выше, и видим первый ошибочный системный вызов — вызов openat, выдающий ошибку ENOENT ("файл или каталог не найдены"), пытавшийся открыть /etc/foo/config.json. Вот, здесь и должен лежать конфигурационный файл.
Это был просто пример, но я бы сказал, что 90% времени, что я пользуюсь strace, ничего сильно сложнее этого выполнять и не приходится. Ниже — полное пошаговое руководство по отладке:
- Расстроиться из-за невнятного сообщения о system-y ошибке от программы
- Заново запустить программу со strace
- Найти в результатах трассировки сообщение об ошибке
- Идти выше, пока не уткнетесь в первый неудачный системный вызов
Весьма вероятно, что системный вызов в 4-м шаге покажет, что пошло не так.
Подсказки
Прежде чем показать пример более сложной отладки, открою вам несколько приемов для эффективного использования strace:
man — ваш друг
На многих *nix системах полный список системных вызовов к ядру можно получить, запустив man syscalls. Вы увидите вещи вроде brk(2), а значит, больше информации можно получить, запустив man 2 brk.
Небольшие грабли: man 2 fork показывает мне страницу для оболочки fork() в GNU libc, которая, оказывается, которая реализована с помощью вызова clone(). Семантика вызова fork остается той же, если написать программу, использующую fork(), и запустить трассировку — я не найду вызовов fork, вместо них будут clone(). Такие вот грабли только путают, если начать сравнивать исходник с выводом strace.
Используйте -о, чтобы сохранить вывод в файл
strace может сгенерировать обширный вывод, так что зачастую полезно хранить результаты трассировки в отдельных файлах (как в приведенном выше примере). А еще это помогает не спутать программный вывод с выводом strace в консоли.
Используйте -s, чтобы просмотреть больше данных аргумента
Вы наверняка заметили, что вторая половина сообщения об ошибке не показана в приведенном выше примере трассировки. Это потому, что strace по умолчанию показывает только первые 32 байта аргумента строки. Если хотите видеть больше, добавьте что-нибудь вроде -s 128 к вызову strace.
-у облегчает отслеживание файлов\сокетов\и проч.
"Все — файл" означает, что *nix системы выполняют все вводы-выводы, используя файловые дескрипторы, применимо ли именно к файлу или сети, или межпроцессным каналам. Это удобно для программирования, но мешает следить за тем, что происходит на самом деле, когда видите общие read и write в результатах трассировки системного вызова.
Добавив оператор -у, вы заставите strace аннотировать каждый файловый дескриптор в выводе с примечанием, на что он указывает.
Прикрепите к уже запущенному процессу с -p**
Как будет видно из приведенного ниже примера, иногда нужно производить трассировку программы, которая уже запущена. Если известно, что она запущена как процесс 1337 (скажем, из выводов ps), то можно осуществить трассировку ее вот так:
$ strace -p 1337
...system call trace output...Возможно, вам нужны root-права.
Используйте -f, чтобы следить за дочерними процессами
strace по умолчанию трассирует всего один процесс. Если же этот процесс порождает дочерние процессы, то можно увидеть системный вызов для порождения дочернего процесса, но системные вызовы дочернего процесса не будут отображены.
Если считаете, что ошибка — в дочернем процессе, используйте оператор -f, это включит его трассировку. Минус этого в том, что вывод еще больше собьет вас с толку. Когда strace трассирует один процесс или одну ветку, он показывает единый поток событий вызовов. Когда он трассирует сразу несколько процессов, то, вы, возможно, увидите начало вызова, прерванного сообщением <unfinished ...>, затем — кучку вызовов для других веток исполнения, и только потом — окончание первого с <… foocall resumed>. Или разделите все результаты трассировки по разным файлам, используя также оператор -ff (детали — в руководстве по strace).
Фильтруйте трассировку при помощи -e
Как видите, результат трассировки — реальная куча всех возможных системных вызовов. Флагом -e можно отфильтровать трассировку (см. руководство по strace). Главное преимущество в том, что запускать трассировку с фильтрацией быстрее, чем делать полную трассировку, а потом grep`ать. Если честно, то мне почти всегда пофиг.
Не все ошибки плохи
Простой и распространенный пример — программа, ищущая файл сразу в нескольких местах, вроде оболочки, ищущей, в которой корзине\каталоге содержится исполняемый файл:
$ strace sh -c uname
...
stat("/home/user/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory)
stat("/usr/local/bin/uname", 0x7ffceb817820) = -1 ENOENT (No such file or directory)
stat("/usr/bin/uname", {st_mode=S_IFREG|0755, st_size=39584, ...}) = 0
...Эвристика типа "последний неудачный запрос перед сообщением об ошибке" хороша в поиске релевантных ошибок. Как бы там ни было, логично начинать с самого конца.
Понять системные вызовы хорошо помогают руководства по программированию на языке С
Стандартные вызовы к библиотекам С — не системные вызовы, но лишь тонкий поверхностный слой. Так что, если вы хоть немного понимаете, как и что делать в С, вам будет легче разобраться в результатах трассировки системного вызова. Например, у вас беда с отладкой вызовов к сетевым системам, просмотрите то же классическое "Руководство по сетевому программированию" Биджа.
Пример отладки посложнее
Я уже говорил, что пример простой отладки — это пример того, с чем мне, по большей части, приходится иметь дело в работе со strace. Однако порой требуется настоящее расследование, так что вот вам реальный пример отладки посложнее.
bcron — планировщик обработки задач, еще одна реализация демона *nix cron. Он установлен на сервере, но когда кто-то пытается редактировать расписание, происходит вот что:
# crontab -e -u logs
bcrontab: Fatal: Could not create temporary fileЛадненько, значит, bcron попытался написать некий файл, но у него не вышло, и он не признается почему. Расчехляем strace:
# strace -o /tmp/trace crontab -e -u logs
bcrontab: Fatal: Could not create temporary file
# cat /tmp/trace
...
openat(AT_FDCWD, "bcrontab.14779.1573691864.847933", O_RDONLY) = 3
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000
read(3, "#Ansible: logsagg\n20 14 * * * lo"..., 8192) = 150
read(3, "", 8192) = 0
munmap(0x7f82049b4000, 8192) = 0
close(3) = 0
socket(AF_UNIX, SOCK_STREAM, 0) = 3
connect(3, {sa_family=AF_UNIX, sun_path="/var/run/bcron-spool"}, 110) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f82049b4000
write(3, "156:Slogs\0#Ansible: logsagg\n20 1"..., 161) = 161
read(3, "32:ZCould not create temporary f"..., 8192) = 36
munmap(0x7f82049b4000, 8192) = 0
close(3) = 0
write(2, "bcrontab: Fatal: Could not creat"..., 49) = 49
unlink("bcrontab.14779.1573691864.847933") = 0
exit_group(111) = ?
+++ exited with 111 +++Примерно в самом конце есть сообщение об ошибке write, но на этот раз кое-что отличается. Во-первых, нет релевантной ошибки системного вызова, которая обычно перед этим происходит. Во-вторых, видно, что где-то кто-то уже прочел сообщение об ошибке. Похоже на то, что настоящая проблема — где-то в другом месте, а bcrontab просто воспроизводит сообщение.
Если посмотреть на man 2 read, то можно увидеть, что первый аргумент (3) — это файловый дескриптор, который *nix и использует для всех обработок ввода-вывода. Как узнать, что представляет файловый дескриптор 3? В данном конкретном случае можно запустить strace с оператором -у (см. выше), и он автоматически расскажет, однако, чтобы вычислять подобные штуки, полезно знать, как читать и анализировать результаты трассировки.
Источником файлового дескриптора может быть один из многих системных вызовов (все зависит от того, для чего дескриптор — для консоли, сетевого сокета, собственно файла или чего-то иного), но как бы там ни было, вызовы мы ищем, возвращая 3 (т.е. ищем "= 3" в результатах трассировки). В этом результате их 2: openat в самом верху и socket в середине. openat открывает файл, но close(3) после этого покажет, что он закрывается снова. (Грабли: файловые дескрипторы могут использоваться заново, когда их открывают и закрывают). Вызов socket() подходит, поскольку он последний перед read(), и получается, что bcrontab работает с чем-то через сокет. Следующая строка показывает, что файловый дескриптор связан с unix domain socket по пути /var/run/bcron-spool.
Итак, надо найти процесс, привязанный к unix socket с другой стороны. Для этой цели есть парочка изящных трюков, и оба пригодятся для отладки серверных развертываний. Первый — использовать netstat или более новый ss (socket status). Обе команды показывают активные сетевые соединения системы и берут оператор -l для описания слушающих сокетов, а также оператор -p для отображения программ, подключенных к сокету в качестве клиента. (Полезных опций намного больше, но для этой задачи достаточно и этих двух.)
# ss -pl | grep /var/run/bcron-spool
u_str LISTEN 0 128 /var/run/bcron-spool 1466637 * 0 users:(("unixserver",pid=20629,fd=3))Это говорит о том, что слушающий — это команда inixserver, работающая с ID процесса 20629. (И, по совпадению, она использует файловый дескриптор 3 в качестве сокета.)
Второй реально полезный инструмент для нахождения той же информации называется lsof. Он перечисляет все октрытые файлы (или файловые дескрипторы) в системе. Или же можно получить информацию об одном конкретном файле:
# lsof /var/run/bcron-spool
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
unixserve 20629 cron 3u unix 0x000000005ac4bd83 0t0 1466637 /var/run/bcron-spool type=STREAMПроцесс 20629 — это долгоживущий сервер, так что можно прикрепить к нему strace при помощи чего-то вроде strace -o /tmp/trace -p 20629. Если редактировать задание cron в другом терминале — получим вывод результатов трассировки с возникающей ошибкой. А вот и результат:
accept(3, NULL, NULL) = 4
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21181
close(4) = 0
accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21181, si_uid=998, si_status=0, si_utime=0, si_stime=0} ---
wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 0}], WNOHANG|WSTOPPED, NULL) = 21181
wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes)
rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0
rt_sigreturn({mask=[]}) = 43
accept(3, NULL, NULL) = 4
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21200
close(4) = 0
accept(3, NULL, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=21200, si_uid=998, si_status=111, si_utime=0, si_stime=0} ---
wait4(0, [{WIFEXITED(s) && WEXITSTATUS(s) == 111}], WNOHANG|WSTOPPED, NULL) = 21200
wait4(0, 0x7ffe6bc36764, WNOHANG|WSTOPPED, NULL) = -1 ECHILD (No child processes)
rt_sigaction(SIGCHLD, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, {sa_handler=0x55d244bdb690, sa_mask=[CHLD], sa_flags=SA_RESTORER|SA_RESTART, sa_restorer=0x7faa47ab9840}, 8) = 0
rt_sigreturn({mask=[]}) = 43
accept(3, NULL, NULL(Последний accept() не будет завершен при трассировке.) И снова, как ни жаль, но данный результат не содержит ошибки, которую мы ищем. Мы не видим ни одного сообщения, которые бы bcrontag посылал сокету или принимал от него. Вместо них сплошное управление процессом (clone, wait4, SIGCHLD и проч.) Этот процесс порождает дочерний процесс, который, как можно догадаться, и выполняет настоящую работу. И если надо поймать ее след, добавьте к вызову strace -f. Вот что мы найдем, поискав сообщение об ошибке в новом результате со strace -f -o /tmp/trace -p 20629:
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
21470 write(1, "32:ZCould not create temporary f"..., 36) = 36
21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84
21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory)
21470 exit_group(111) = ?
21470 +++ exited with 111 +++Вот, это уже кое-что. Процесс 21470 получает ошибку "отказано в доступе" при попытке создать файл по пути tmp/spool.21470.1573692319.854640 (относящийся к текущему рабочему каталогу). Если бы мы просто знали текущий рабочий каталог, мы бы знали и полный путь и смогли выяснили, почему процесс не может создать в нем свой временный файл. К несчастью, процесс уже вышел, поэтому не получится просто использовать lsof -p 21470 для того, чтобы найти текущий каталог, но можно поработать в обратную сторону — поискать системные вызовы PID 21470, меняющие каталог. (Если таких нет, PID 21470, должно быть, унаследовали их от родителя, и это уже через lsof -p не выяснить.) Этот системный вызов — chdir (что несложно выяснить при помощи современных сетевых поисковых движков). А вот и результат обратных поисков по результатам трассировки, до самого сервера PID 20629:
20629 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7faa47c44810) = 21470
...
21470 execve("/usr/sbin/bcron-spool", ["bcron-spool"], 0x55d2460807e0 /* 27 vars */) = 0
...
21470 chdir("/var/spool/cron") = 0
...
21470 openat(AT_FDCWD, "tmp/spool.21470.1573692319.854640", O_RDWR|O_CREAT|O_EXCL, 0600) = -1 EACCES (Permission denied)
21470 write(1, "32:ZCould not create temporary f"..., 36) = 36
21470 write(2, "bcron-spool[21470]: Fatal: logs:"..., 84) = 84
21470 unlink("tmp/spool.21470.1573692319.854640") = -1 ENOENT (No such file or directory)
21470 exit_group(111) = ?
21470 +++ exited with 111 +++(Если теряетесь, то вам, возможно, стоит прочесть мой предыдущий пост об управлении процессом *nix и оболочках.) Итак, сервер PID 20629 не получил разрешения создать файл по пути /var/spool/cron/tmp/spool.21470.1573692319.854640. Вероятнее всего, причиной тому — классические настройки разрешений файловой системы. Проверим:
# ls -ld /var/spool/cron/tmp/
drwxr-xr-x 2 root root 4096 Nov 6 05:33 /var/spool/cron/tmp/
# ps u -p 20629
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
cron 20629 0.0 0.0 2276 752 ? Ss Nov14 0:00 unixserver -U /var/run/bcron-spool -- bcron-spoolВот где собака зарыта! Сервер работает как пользовательский cron, но только у root есть разрешение записывать в каталог /var/spool/cron/tmp/. Простая команда chown cron /var/spool/cron/tmp/ заставит bcron работать правильно. (Если проблема заключалась не в этом, то следующий наиболее вероятный подозреваемый — модуль безопасности ядра типа SELinux или AppArmor, так что я бы проверил журнал сообщений ядра с помощью dmesg.)
Итого
Начинающему в результатах трассировки системных вызовов можно утонуть, но я, надеюсь, показал, что они — быстрый способ отладки целого класса распространенных проблем с развертыванием. Представьте, как пытаетесь отладить многопроцессный bcron, используя пошаговый отладчик.
Разбор результатов трассировки в обратном порядке вдоль цепочки системных вызовов требует навыка, но как я уже говорил, почти всегда, пользуясь strace, я просто получаю результат трассировки и ищу ошибки, начиная с конца. В любом случае, strace помогает мне сэкономить уйму времени на отладке. Надеюсь, и вам он тоже будет полезен.
