
Продолжаем делиться последними анонсами с AWS re:Invent 2021. Смело можно назвать третий день re:Invent днем машинного обучения и баз данных, внушительный список обновлений и новых релизов разберем в этой статье. Если вы пропустили первую часть анонсов, то вчера solution архитекторы из AWS на стриме обсудили все события первых дней - по ссылке можно посмотреть запись. Приходите на следующие стримы. Регистрация здесь

Amazon SageMaker Studio Lab (предварительный доступ)
Одна из миссий AWS — сделать машинное обучение более доступным. Существующие среды машинного обучения часто слишком сложны для новичков или слишком ограничены для поддержки современных экспериментов с машинным обучением. Новички хотят быстро начать обучение и не беспокоиться о развертывании инфраструктуры, настройке сервисов или о превышении бюджета. Есть еще один барьер для многих людей: необходимость предоставления платежной информации и информации о кредитной карте при регистрации.
Что, если бы у вас была предсказуемая и контролируемая среда запуска ноутбуков Jupyter, в которой вы не сможете случайно получить большой счет? Та, которая при регистрации вообще не требует данных о кредитной карте?
Сегодня AWS объявляет о запуске предварительно публичной версии Amazon SageMaker Studio Lab — бесплатного сервиса для разработчиков, ученых и дата-саентистов, где они могут экспериментировать и изучать машинное обучение, и который не требует знаний об настройке облаков или кредитную карту.
С помощью Amazon SageMaker Studio Lab пользователи смогут экспериментировать с данными и машинным обучением без необходимости настраивать или запускать какую-либо инфраструктуру. Он основан на опенсорсном веб-приложении JupyterLab, благодаря чему пользователи получают полностью открытое окружение с возможностью использования любого фреймворка, такого как Pytorch, TensorFlow, MxNet, или Hugging Face, и библиотек, таких как SciKitLearn, NumPy, и Pandas. В Studio Lab есть авто-сохранение, благодаря чему сессии пользователей сохраняются и они могут продолжить с того же места, на котором остановились, когда зайдут в следующий раз.
Чтобы начать работать со Studio Lab, перейдите по этой ссылке и запросите учетную запись. Вам понадобится только ваш адрес электронной почты, чтобы зарегистрироваться. Когда ваш запрос будет одобрен, вы получите электронное письмо со ссылкой на страницу регистрации учетной записи Studio Lab. Теперь вы можете создать свою учетную запись с подтвержденным адресом электронной почты, задать пароль и имя пользователя. Этот аккаунт не зависит от аккаунта AWS и не требует предоставления платежной информации. Вскоре после этого вы сможете начать изучать машинное обучение и экспериментировать с Jupyter ноутбуками. Также там доступны такие примеры, как AWS Machine Learning University, Dive into DeepLearning, и ноутбуки Hugging Face.
Studio Lab проста в настройке. На самом деле, единственное, что вам нужно сделать — это выбрать, нужен ли вам инстанс CPU или GPU для вашего проекта.
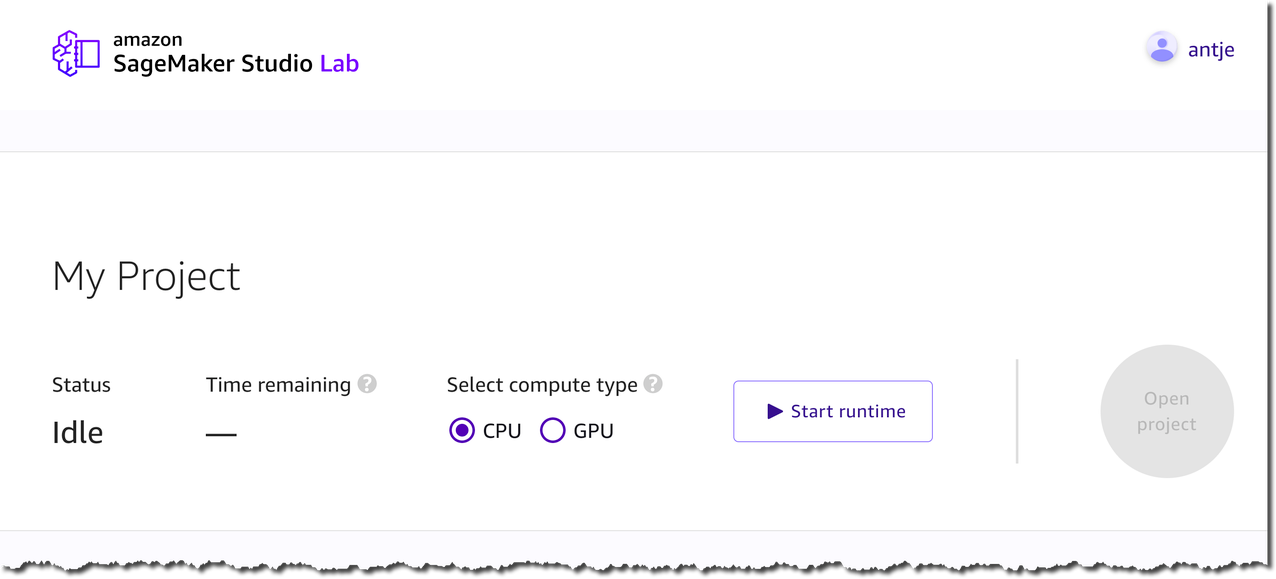
Вы можете выбрать между 12 часами работы CPU или 4 часами GPU за одну сессию, при этом вам доступно неограниченное количество сессий. Кроме того, вы получаете не менее 15 ГБ постоянного хранилища на проект. По истечении сеанса Studio Lab сделает сохранение. Это позволяет вам продолжить с того места, где вы остановились.
Studio Lab поставляется с базовым образом Python, с которым вы можете начать работать. В образе предустановлено всего несколько библиотек, чтобы сэкономить доступное пространство для нужных фреймворков и библиотек.

Studio Lab тесно интегрирована с GitHub и предлагает полную поддержку командной строки Git. Это позволяет легко клонировать, копировать и сохранять проекты. Кроме того, вы можете добавить значок Open in Studio Lab в файл Readme.md или сохранять блокноты в общедоступном репозитории GitHub, чтобы поделиться своей работой с другими.

Вы можете запросить бесплатную учетную запись Amazon SageMaker Studio Lab уже сегодня. Количество регистраций новых учетных записей будет ограничено, чтобы обеспечить высокое качество обслуживания для всех пользователей. Образцы блокнотов можно найти в репозитории Studio Lab на GitHub.
Amazon SageMaker Canvas
Amazon SageMaker Canvas - это новый функционал Amazon SageMaker, который позволяет бизнес-аналитикам создавать точные модели машинного обучения и генерировать прогнозы с помощью графического интерфейса без необходимости писать код.
Amazon SageMaker Canvas предоставляет пользовательский интерфейс для быстрого подключения и доступа к данным из различных источников, а также для подготовки данных для построения моделей машинного обучения. SageMaker Canvas использует технологию AutoML, которая автоматически обучает и строит модели на основе ваших данных. Это позволяет SageMaker Canvas определять лучшую модель на основе этих данных, чтобы вы могли создавать единичные или групповые прогнозы. SageMaker Canvas интегрирован с SageMaker Studio, что позволяет бизнес-аналитикам легко делиться моделями со специалистами по анализу данных.

Amazon SageMaker Canvas уже доступен в регионах AWS в США (Огайо, Северная Вирджиния и Орегон) и Европе (Франкфурт и Ирландия). Подробнее вы можете прочитать в блоге, а для начала работы можете перейти на страницу продукта.
Amazon SageMaker Serverless Inference
Amazon SageMaker Serverless Inference (Preview) - это новый бессерверный (serverless) способ развертывания ML моделей. При использовании Serverless Inference больше не надо думать о виртуальных машинах. Amazon SageMaker сам развернет модель и выполнит автоматическое масштабирование. Оплачивается только фактическое время работы моделей и объем обработанных данных, а не время простоя. Такая схема идеальна для моделей, работающих не всегда, или имеющих непредсказуемый паттерн использования.

Например вы строите чат бот, помогающий сотрудникам компании получить сервисы от бухгалтерии. Такой чат бот будет наиболее активно использоваться несколько дней в месяц - в дни выплаты зарплаты. Amazon SageMaker Serverless Inference будет идеальным способом развернуть ML модель для такого чат бота и не платить за время, когда модель не используется.
С появлением SageMaker Serverless Inference, SageMaker теперь предоставляет четыре способа развертывания ML моделей. Помимо Serverless Inference это SageMaker Real-Time Inference для моделей, требующих низких (миллисекундных) задержек при работе. SageMaker Batch Transform для пакетной обработки больших объемов данных, а также SageMaker Asynchronous Inference для моделей, требующих асинхронной обработки из-за долгой работы или большого размера входных данных.
В GitHub репозитории примеров работы с SageMaker доступен Jupyter ноутбук, демонстрирующий работу с SageMaker Serverless Inference с начала и до конца.
Serverless Inference доступен в US East (N. Virginia), US East (Ohio), US West (Oregon), EU (Ireland), Asia Pacific (Tokyo) и Asia Pacific (Sydney).
Интеграция Amazon SageMaker Studio с Amazon EMR - Hadoop и Spark
Теперь Amazon SageMaker Studio может напрямую работать с Amazon EMR кластерами. Вы можете создавать, удалять, запускать и останавливать Amazon EMR кластеры прямо из SageMaker Studio, а также использовать SparkUI для мониторинга задач, запущенных на кластере. Доступны шаблоны EMR кластеров, оптимизированные под разные задачи.
Больше не надо покидать SageMaker Studio для конфигурации EMR кластера и думать о том как выполнить подключение к нему. А для мониторинга Spark задач не требуется настраивать прокси и туннели. Теперь это можно сделать в один клик прямо из ноутбука.
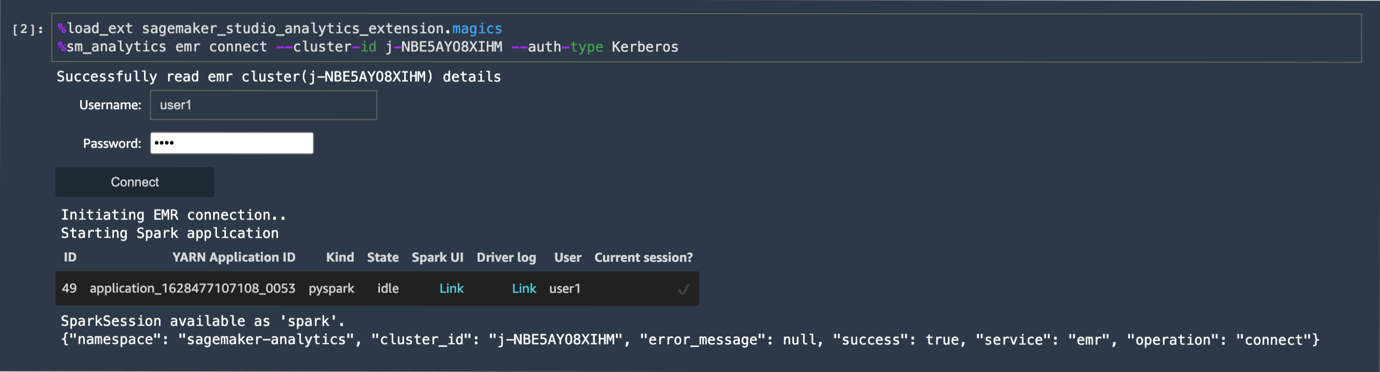
Подробней о работе с Amazon EMR и Spark в SageMaker Studio можно прочитать в статьях:
Amazon SageMaker Training Compiler
Amazon SageMaker Training Compiler - новая возможность SageMaker, помогающая ускорить обучение deep learning моделей (нейронных сетей) до 50%.
Обучение нейронных сетей может занимать очень много времени. Например обучение популярной NLP модели RoBERTa на одной видеокарте длится 25 000 часов. Оптимизировать время обучения сейчас могут только профессионалы с большим опытом, что препятствует внедрению и использованию машинного обучения. Дата-саентисты обычно пишут код на Python используя TensorFlow или PyTorch или другие фреймворки. Эти фреймворки конвертируют Python код в математические функции, работающие на видеокартах. Обычно используется стандартный код, не заточенный под конкретную ML модель, обучаемую в данный момент. SageMaker Training Compiler генерирует код для видеокарт, заточенный под обучение вашей конкретной модели. Благодаря этому обучение происходит быстрее и требуется меньше памяти.
Hugging Face GPT-2 модель с использованием SageMaker Training Compiler обучается всего 90 минут вместо 3 часов. При этом включение SageMaker Training Compiler требует добавления всего двух строк кода на Python.

Не каждая модель может быть оптимизирована. Сейчас SageMaker Training Compiler поддерживает работу с Hugging Face трансформерами в TensorFlow и PyTorch.
Доступны Jupyter ноутбуки, показывающие работу с SageMaker Training Compiler, а также документация. Training Compiler уже доступен в EU (Ireland), US East (N. Virginia), US East (Ohio) и US West (Oregon).
Amazon SageMaker Inference Recommender
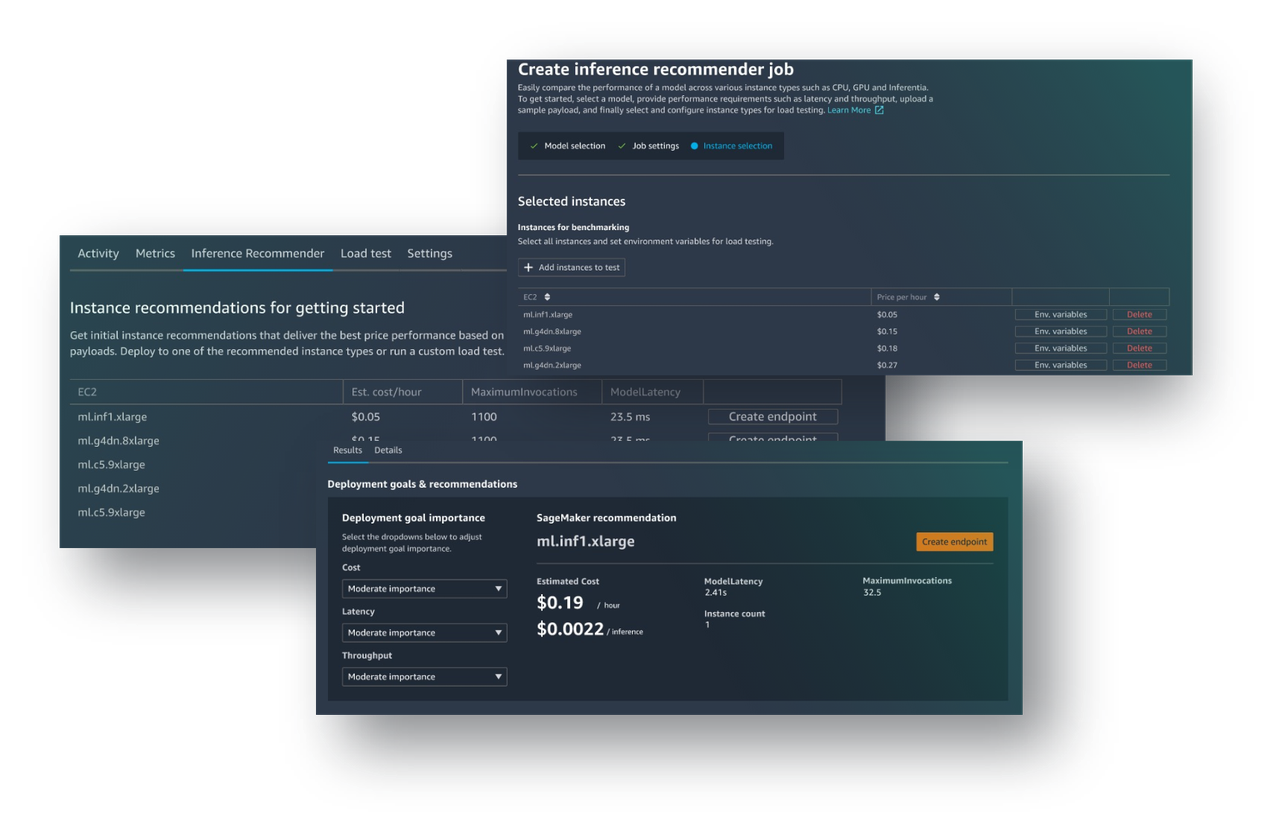
Amazon SageMaker Inference Recommender - новая возможность Amazon SageMaker Studio, позволяющая проводить нагрузочное тестирование ML моделей и оптимизировать выделяемые для их работы ресурсы.
До появления SageMaker Inference Recommender MLOps инженерам было трудно выбирать оптимальные по соотношению цены и утилизации EC2 инстансы с учетом особенностей работы каждой конкретной ML модели. Это делалось методом проб и ошибок.
Теперь можно быстро провести нагрузочное тестирование, оценить производительность, пропускную способность и задержки, и развернуть ML модель на оптимальном типе инстансов. Благодаря этому MLOps инженеры могут быть уверены, что их ML модели ведут себя предсказуемым образом под рабочей нагрузкой.
Более подробная информация доступна в документации. Пример работы с Inference Recommender из кода доступен в Jupyter ноутбуке.
Amazon RDS Custom for SQL Server and Oracle
26 октября 2021 года AWS запустил Amazon RDS Custom for Oracle — управляемый сервис баз данных для приложений, требующих настройки операционной системы и самой среды управления базами данных. RDS Custom позволяет получить доступ и настроить хост сервера баз данных и операционную систему, например, путем применения специальных патчей и изменения настроек самого программного обеспечения базы данных для поддержки сторонних приложений, требующих привилегированного доступа.
Сегодня объявлено об общей доступности Amazon RDS Custom for SQL Server для поддержки приложений, которым нужная конкретная конфигурация, и для поддержки сторонних приложений, требующих особой настройки в корпоративных системах, системах электронной коммерции и управления контентом, таких как Microsoft SharePoint.
С помощью RDS Custom for SQL Server можно включить функции, требующие повышенных привилегий, такие как среда выполнения SQL Common Language Runtime (CLR), установить определенные драйверы для включения разнородных связанных серверов или иметь более 100 баз данных на инстанс.
Благодаря тому, что это управляемый сервис, RDS Custom for SQL Server позволяет вам сосредоточиться на основной деятельности, которая важна для бизнеса. Наличие автоматизировации бэкапов и других операционных задач позволяет вам быть спокойными, зная, что ваши данные в безопасности и готовы к восстановлению в случае необходимости.
Amazon RDS Custom for SQL Server уже доступен в регионах US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), EU (Frankfurt), EU (Ireland), и EU (Stockholm).
Больше узнать можно на странице продукта и в документации Amazon RDS Custom. Оставляйте нам отзывы на форуме AWS для Amazon RDS или через обычные контакты службы поддержки AWS.
Amazon DynamoDB Standard-Infrequent access table class

Одним из интересных релизов на re:Invent 2021 стал Amazon DynamoDB Standard-Infrequent Access (DynamoDB Standard-IA). Новый класс таблиц для DynamoDB, который снижает на 60% затраты на хранение по сравнению с существующим классом таблиц DynamoDB Standard, но при этом обеспечивает такую же производительность, надежность и масштабируемость.
В настоящее время многие клиенты перемещают свои редко используемые данные между DynamoDB и Amazon Simple Storage Service (Amazon S3). Это означает, что заказчики разрабатывают процесс миграции данных и довольно сложные приложения, которым необходимо поддерживать два абсолютно разных API - один для DynamoDB, а другой для Amazon S3. Новый класс таблиц DynamoDB Standard-IA решает эту проблему. Он разработан, чтобы удовлетворить требования клиентов, которым требуется экономически выгодное решение для хранения редко используемых данных в DynamoDB без изменения кода своих приложений. Используя новый класс таблиц вы получаете высокую производительность чтения и записи от DynamoDB и используете все те же API.
При использовании класса таблиц DynamoDB Standard-IA вы сэкономите до 60% затрат на хранение по сравнению со стандартным классом таблиц DynamoDB. Однако операции чтения и записи DynamoDB для нового класса имеют более высокую стоимость, чем стандартные таблицы. Поэтому важно продумать варианты использования, прежде чем изменять на новый класс ваши таблицы.
DynamoDB Standard-IA - отличное решение, если вам необходимо хранить терабайты данных в течение нескольких лет, когда данные должны быть высокодоступными, но при этом к ним не часто обращаются. Примером может служить приложение социальной сети, в котором конечные пользователи редко получают доступ к своим старым сообщениям. Однако, эти сообщения хранятся потому, что если кто-то будет прокручивать профиль, чтобы увидеть фотографию 10-ти летней давности, он захочет получить ее так же быстро, как если бы это была более новая запись.
Сайты электронной коммерции - еще один хороший вариант использования. На этих сайтах может быть много продуктов, к которым нечасто обращаются, но администраторы сайта по-прежнему хотят, чтобы они были доступны в магазине для покупки. Кроме того, это хорошее решение для хранения предыдущих заказов клиента. Таблица DynamoDB Standard-IA предлагает возможность сохранять историю заказов с меньшими затратами.
Вы можете изменить класс существующей таблицы на Standard-IA или Standard два раза каждые 30 дней без потери производительности или доступности. Все функции DynamoDB так же доступны при использовании таблицы нового класса. Кроме того, вы также можете создать новую таблицу с классом DynamoDB Standard-IA.
DynamoDB Standard-IA доступен во всех регионах AWS, кроме регионов Китая и AWS GovCloud. Стоимость хранилища DynamoDB Standard-IA, например, на Востоке США (Северная Вирджиния) составляет $0,10 за ГБ (на 60% меньше, чем DynamoDB Standard), а операции чтения и записи будут на 25% выше.
Дополнительные сведения об этой функции и ее ценах см. на странице DynamoDB Standard-IA и на странице цен DynamoDB.
Amazon DevOps Guru for RDS to Detect, Diagnose, and Resolve Amazon Aurora-Related Issues using ML

Вчера AWS представили Amazon DevOps Guru для RDS, новую функциональность Amazon DevOps Guru. Это позволяет разработчикам легко обнаруживать, диагностировать и решать проблемы производительности и эксплуатации в Amazon Aurora.
Сотни тысяч клиентов в настоящее время используют Amazon Aurora, потому что она отличается высокой доступностью, масштабируемостью и надежностью. Но по мере роста размера и сложности приложений этим клиентам становится все сложнее быстро обнаруживать и устранять проблемы в эксплуатации и с производительностью. Теперь у разработчиков будет достаточно информации, чтобы определить точную причину проблемы производительности базы данных.
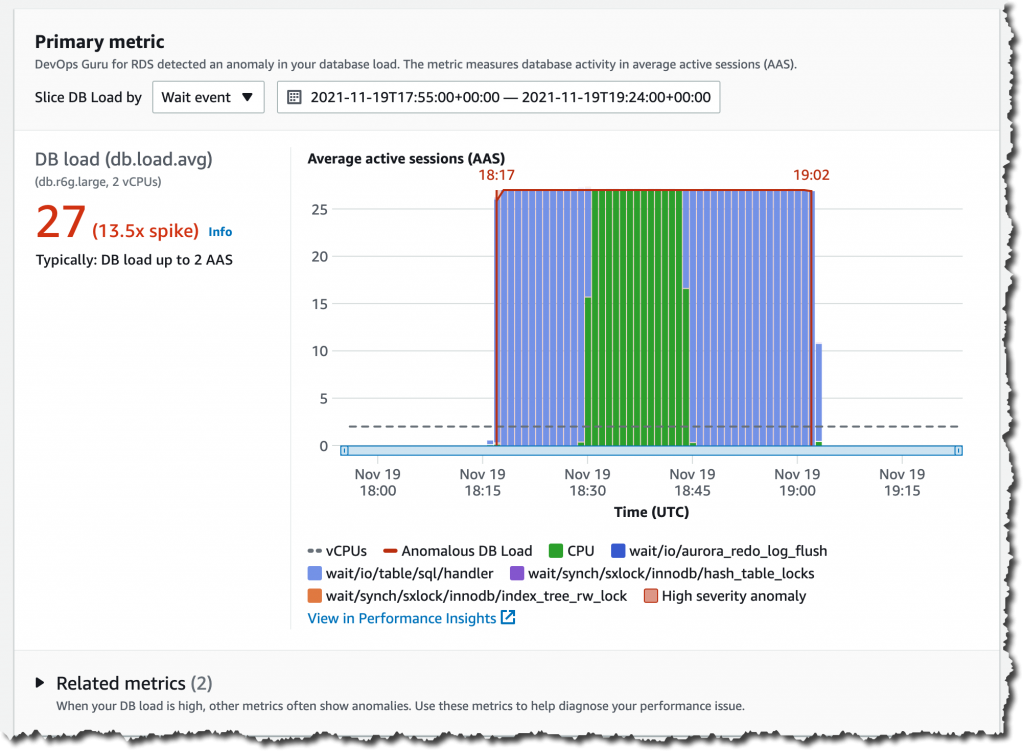
DevOps Guru для RDS использует машинное обучение для автоматического выявления и анализа широкого спектра проблем, связанных с производительностью баз данных, таких как чрезмерное использование ресурсов хоста, узкие места базы данных или неправильное поведение SQL-запросов. Он также рекомендует решения для устранения обнаруженных проблем. Чтобы использовать эту возможность, вам не нужно быть экспертом по базам данных или машинному обучению.

При обнаружении проблемы DevOps Guru для RDS отображает результаты в консоли DevOps Guru и отправляет уведомления с помощью Amazon EventBridge или Amazon Simple Notification Service (SNS). Это позволяет разработчикам автоматически управлять проблемами и принимать меры в режиме реального времени.
Использовать DevOps Guru для RDS можно без дополнительной оплаты, в рамках существующей стоимости, которую DevOps Guru взимает за ресурсы RDS.
DevOps Guru для RDS доступен во всех регионах, где доступен DevOps Guru: Восток США (Огайо и Северная Вирджиния), Запад США (Орегон), Азиатско-Тихоокеанский регион (Сингапур, Сидней и Токио), Европе (Франкфурт, Ирландия и Стокгольм).
Возникли вопросы по новым продуктам и обновлениям? Лучший способ разобраться в этом - обсудить с коллегами за чашечкой кофе или подключиться на второй стрим результатов AWS re:Invent 2021, где смело можно задавать ваши вопросы архитекторам из AWS, которые будут рады на них ответить. Регистрация на стрим по ссылке
Если вы не можете подключиться на стрим или у вас остались вопросы, вы можете напрямую обратиться к архитекторам Softline, которые помогут разобраться с как с традиционными решениями AWS, так и с новыми продуктами.
