
О создании системы мониторинга мы задумались на этапе формирования продуктовых команд. Стало понятно, что наше дело — эксплуатация — в эти команды никак не попадает. Почему так?
Дело в том, что все наши команды построены вокруг отдельных информационных систем, микросервисов и фронтов, поэтому общее состояние здоровья всей системы в целом команды не видят. Например, они могут не знать, как какая-то небольшая часть в глубоком бэкенде влияет на фронтовую часть. Круг их интересов ограничивается системами, с которыми интегрирована их система. Если же команда и её сервис А почти никак не связан с сервисом Б, то такой сервис для команды почти невидим.

Наша же команда, в свою очередь, работает с системами, которые очень сильно интегрированы между собой: между ними множество связей, это весьма большая инфраструктура. И от всех этих систем (которых у нас, к слову, огромное количество), зависит работа интернет-магазина.
Вот и получается, что наш отдел не относится ни к одной команде, а находится немного в стороне. Во всей этой истории наша задача — понимать в комплексе, как работают информационные системы, их функциональность, интеграции, ПО, сеть, железо, и как все это связано между собой.
Платформа, на которой функционируют наши интернет-магазины, выглядит так:
Как бы нам ни хотелось, но не бывает такого, чтобы все системы работали гладко и безукоризненно. Дело, опять же, в количестве систем и интеграций — при таком, как у нас, какие-то инциденты это неизбежность, несмотря на качество тестирования. Причем как внутри какой-то отдельной системы, так и в плане их интеграции. И нужно следить за состоянием всей платформы комплексно, а не какой-нибудь отдельной её части.
В идеале наблюдение за состоянием здоровья всей платформы нужно автоматизировать. И мы пришли к мониторингу как к неизбежной части этого процесса. Изначально он был построен только для фронтовой части, при этом собственные системы мониторинга по слоям были и есть у сетевиков, администраторов ПО и аппаратного обеспечения. Все эти люди следили за мониторингом только на своем уровне, комплексного понимания тоже ни у кого не было.
Например, если упала виртуальная машина, в большинстве случаев об этом знает только администратор, отвечающий за hardware и виртуальную машину. Команда фронта в таких случаях видела сам факт падения приложения, но данных о падении виртуальной машины у неё не было. А администратор может знать, кто заказчик, и примерно представлять, что именно сейчас на этой виртуальной машине крутится, при условии, что это какой-то большой проект. Про маленькие он, скорее всего, не знает. В любом случае, администратору нужно идти к владельцу, спрашивать, что же на этой машине было, что нужно восстанавливать и что поменять. А если ломалось что-то совсем серьезное, начиналась беготня по кругу — потому что никто не видел систему в целом.
В конечном счете такие разрозненные истории влияют на весь фронтенд, на пользователей и нашу основную бизнес-функцию — интернет-продажи. Так как мы не входим в команды, а занимаемся эксплуатацией всех ecommerce-приложений в составе интернет-магазина, мы взяли на себя задачу по созданию комплексной системы мониторинга ecommerce-платформы.
Мы начали с того, что выделили несколько слоёв мониторинга для наших систем, в разрезе которых нам потребуется собирать метрики. И все это нужно было объединить, что мы и сделали на первом этапе. Сейчас по этому этапу мы дорабатываем максимально качественный сбор метрик по всем нашим слоям, чтобы выстраивать корреляцию и понимать, как системы влияют друг на друга.
Отсутствие комплексного мониторинга на начальных этапах запуска приложений (так как мы начали строить его, когда большая часть систем была в эксплуатации) привело к тому, что у нас образовался значительный технический долг по настройке мониторинга всей платформы. Сосредотачиваться на настройке мониторинга какой-то одной ИС и детально прорабатывать мониторинг для неё мы не могли себе позволить, так как остальные системы остались бы на какое-то время без мониторинга. Для решения этой задачи мы определили список самых необходимых метрик оценки состояния информационной системы по слоям и начали его внедрять.
Поэтому слона решили есть по частям.
Наша система складывается из:

В центре этой системы — собственно мониторинг. Чтобы в общем понимать состояние всей системы, надо знать, что происходит с приложениями на всех этих слоях и в разрезе всего множества приложений.
Так вот, про стек.
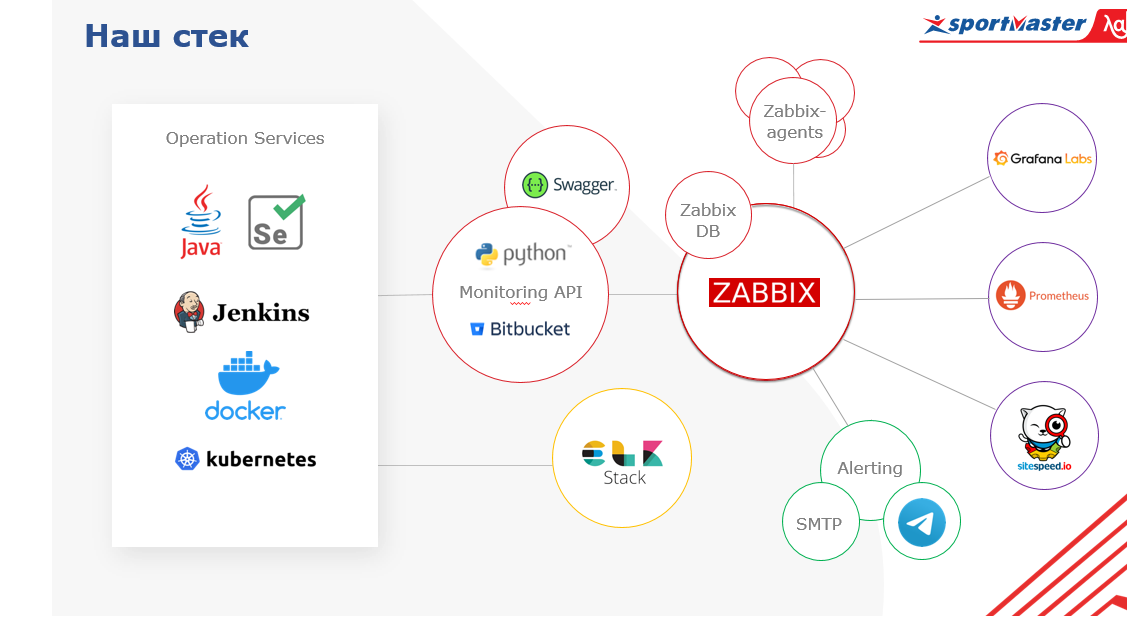
Используем ПО с открытым исходным кодом. В центре у нас Zabbix, который мы используем в первую очередь как систему алертинга. Всем известно, что он идеально подходит для мониторинга инфраструктуры. Что здесь имеется в виду? Как раз те низкоуровневые метрики, которые есть у каждой компании, которая содержит свой ЦОД (а у Спортмастера свои ЦОДы) — температура сервера, состояние памяти, рейда, метрики сетевых устройств.
Мы интегрировали Zabbix с мессенджером Telegram и Microsoft Teams, активно используемыми в командах. Zabbix покрывает слой фактической сети, железа и частично ПО, но это не панацея. Мы эти данные обогащаем из некоторых других сервисов. Например, по уровню аппаратного обеспечения мы напрямую по API коннектимся в нашей системе виртуализации и забираем данные.
Что ещё. Помимо Zabbix мы используем Prometheus, который позволяет мониторить метрики в приложении динамической среды. То есть, мы можем получать метрики приложения по HTTP endpoint и не переживать по поводу того, какие метрики в нее загружать, а какие нет. На основании этих данных можно прорабатывать аналитические запросы.
Источники данных для остальных слоев, например, бизнес-метрик, у нас делятся на три составляющие.
Во-первых, это внешние бизнесовые системы, Google Analytics, собираем метрики из логов. Из них мы получаем данные по активным пользователям, конверсии и всему прочему, связанному с бизнесом. Во-вторых, это система UI-мониторинга. О ней следует рассказать более подробно.
Когда-то мы начинали с мануального тестирования и оно перерасло в автотесты функционала и интеграций. Из него мы и сделали мониторинг, оставив только основной функционал, и завязались на маркеры, которые максимально стабильны и не часто меняются со временем.
Новая структура команд подразумевает, что вся деятельность по приложениям замыкается на продуктовых командах, поэтому чистым тестированием мы заниматься перестали. Вместо этого мы из тестов сделали UI-мониторинг, написанный на Java, Selenium и Jenkins (используется как система запуска и генерации отчетов).
У нас было много тестов, но в итоге мы решили выходить на главную дорогу, верхнеуровневую метрику. И если у нас будет много специфических тестов, то будет сложно поддерживать актуальность данных. Каждый последующий релиз будет значительно ломать всю систему, а мы только и будем заниматься ее починкой. Поэтому мы завязались на совсем фундаментальные вещи, которые редко меняются, и мониторим только их.
Наконец, в-третьих, источником данных является централизованная система логирования. Для логов используем Elastic Stack, а потом эти данные можем затягивать в нашу систему мониторинга по бизнес-метрикам. В дополнение ко всему этому работает наш собственный сервис Monitoring API, написанный на Python, который опрашивает по API любые сервисы и забирает в Zabbix данные из них.
Еще один незаменимый атрибут мониторинга — визуализация. У нас она строится на основе Grafana. Среди прочих систем визуализации она выделяется тем, что на дашборде можно визуализировать метрики из разных источников данных. Мы можем собрать верхнеуровневые метрики интернет-магазина, например, количество заказов, оформленных за последний час, из СУБД, метрики производительности ОС, на которой запущен этот интернет-магазин, из Zabbix, а метрики инстансов этого приложения — из Prometheus. И все это будет на одном дашборде. Наглядно и доступно.
Отмечу про безопасность — мы сейчас допиливаем систему, которую впоследствии будем интегрировать с глобальной системой мониторинга. На мой взгляд, основные проблемы, с которыми сталкивается e-commerce в сфере информационной безопасности, связаны с ботами, парсерами и брутфорсом. За этим нужно следить, потому что они все это может критично повлиять как на работу наших приложений, так и на репутацию с точки зрения бизнеса. И выбранным стеком мы эти задачи успешно покрываем.
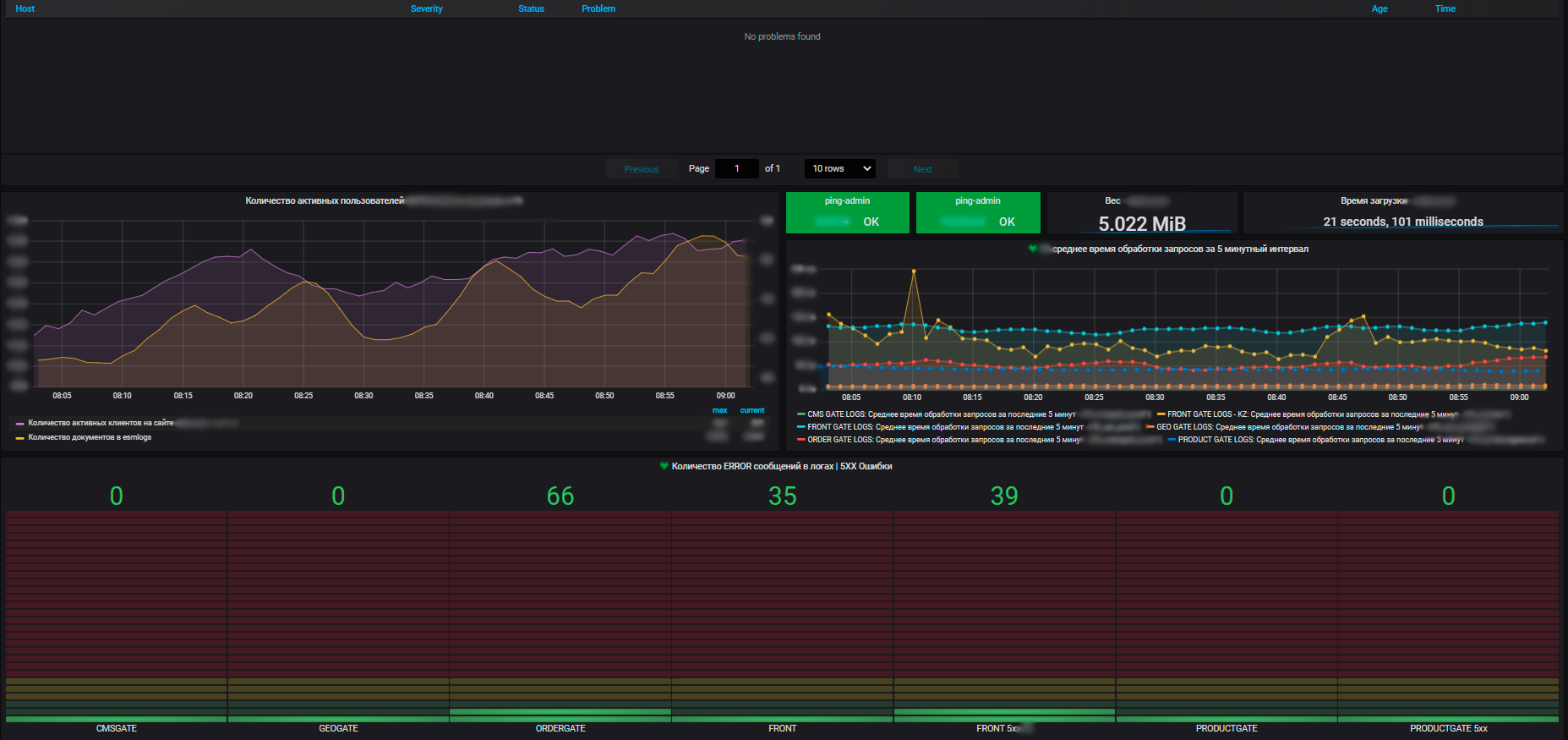
Ещё важный момент — уровень приложений собирается Prometheusом. Сам он он у нас тоже интегрирован с Zabbix. И ещё у нас есть sitespeed, сервис, который позволяет нам соответственно смотреть такие параметры, как скорость загрузки нашей страницы, боттлнеки, отрисовка страницы, загрузка скриптов и прочее, он тоже по API интегрирован. Так метрики у нас собираются в Zabbix, соответственно, алертим мы также оттуда. Все алерты пока уходят на основные способы отправки (пока это email и telegram, ещё подключили недавно MS Teams). В планах прокачать алертинг до такого состояния, чтобы умные боты работали как сервис и предоставляли информацию по мониторингу всем желающим продуктовым командам.
Для нас важны метрики не только отдельных информационных систем, но и общие метрики по всей инфраструктуре, которую используют приложения: кластеры физических серверов, на которых крутятся виртуалки, балансировщики трафика, Network Load Balancer-ы, сама сеть, утилизация каналов связи. Плюс метрики по нашим собственным цодам (у нас их несколько и инфраструктура довольно значительных размеров).
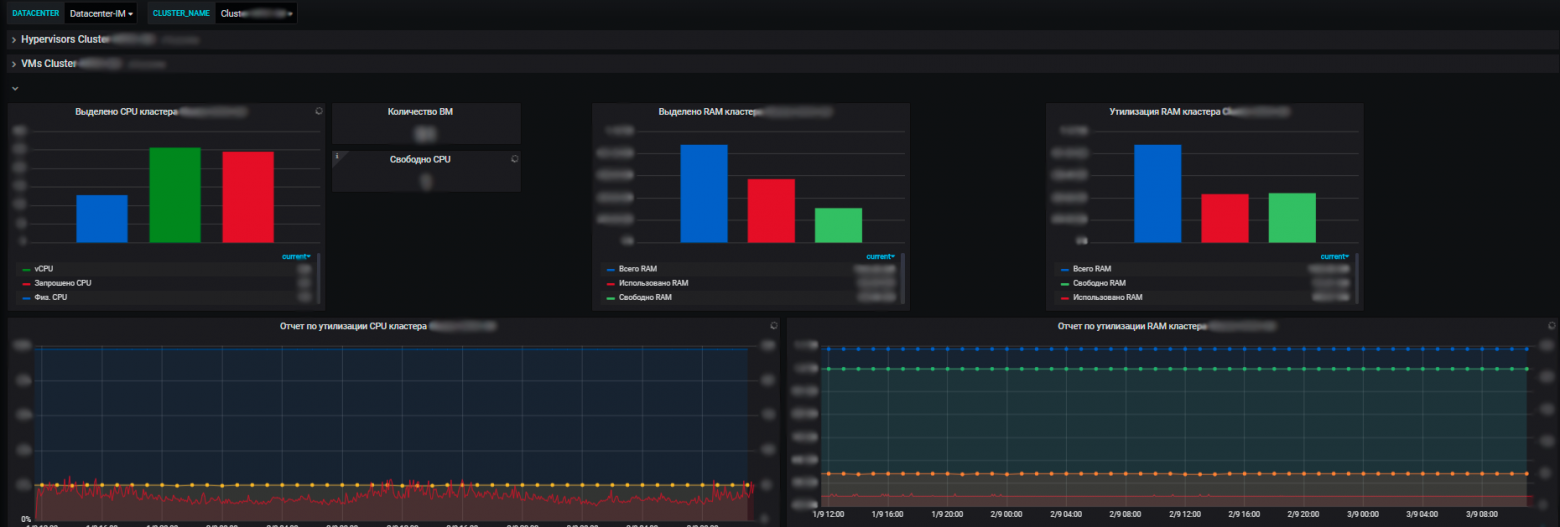
Плюсы нашей системы мониторинга в том, что с ее помощью мы видим состояние работоспособности всех систем, можем оценить их влияние друг на друга и на общие ресурсы. И в конечном счете она позволяет заниматься планированием ресурсов, что также входит в нашу зону ответственности. Мы управляем серверными ресурсами — пулом в рамках e-commerce, вводим-выводим из эксплуатации новое оборудование, докупаем новое, проводим аудит утилизации ресурсов и прочее. Каждый год команды планируют новые проекты, развивают свои системы, и нам важно обеспечить их ресурсами.
И с помощью метрик мы видим тенденцию потребления ресурсов нашими информационными системами. И уже на их основании можем что-то планировать. На уровне виртуализации мы собираем данные и видим информацию по доступному количеству ресурсов в разрезе ЦОДов. А уже внутри ЦОДа видна и утилизация, и фактическое распределение, потребление ресурсов. Причем как со standalone-серверами, так и виртуальными машинами и кластерами физических серверов, на которых все эти виртуалки бодро крутятся.
Сейчас у нас готово ядро системы в целом, но осталось достаточно моментов, над которыми еще предстоит работать. Как минимум это слой информационной безопасности, но важно также добраться до сети, развить алертинг и решить вопрос с корреляцией. Слоев и систем у нас много, на каждом слое еще множество метрик. Получается матрёшка в степени матрёшки.
Наша задача — в конечном счете сделать правильные алерты. Например, если случилась проблема с аппаратной частью, опять же, с виртуальной машиной, а там было важное приложение, и сервис был никак не зарезервирован. Мы узнаем, что виртуальная машина умерла. Затем будут алертить бизнес-метрики: пользователи куда-то пропали, конверсии нет, UI в интерфейсе недоступен, ПО и сервисы тоже умерли.
При таком раскладе мы получим спам из алертов, а это уже не укладывается в формат правильной системы мониторинга. Встает вопрос корреляции. Поэтому в идеале наша система мониторинга должна сказать: «Ребята, у вас физическая машина умерла, а вместе с ней вот это приложение и такие метрики», с помощью одного алерта вместо того, чтобы яростно засыпать нас сотней алертов. Она должна сообщить о главном — о причине, что способствует оперативности устранения проблемы за счёт её локализации.
Наша система оповещений и обработка алертов построена вокруг круглосуточной службы горячей линии. Все алерты, которые считаются у нас маст-хэвом и входят в чек-лист, передаются туда. Каждый алерт должен обязательно иметь описание: что произошло, что это, собственно, значит, на что влияет. А еще ссылку на дашборд и инструкцию, что же в этом случае нужно делать.
Это все, что касается требований к построению алертинга. Дальше ситуация может развиваться в двух направлениях — либо проблема есть и ее нужно решать, либо произошел сбой в системе мониторинга. Но в любом случае, нужно идти и разбираться.
В среднем сейчас за сутки нам падает около сотни алертов, это с учетом того, что корреляция алертов еще не настроена должным образом. И если нужно провести технические работы, и мы что-то принудительно отключаем, их число вырастает в разы.
Помимо мониторинга по системам, которые мы эксплуатируем, и сбора метрик, которые на нашей стороне расцениваются как важные, система мониторинга позволяет собирать данные для продуктовых команд. Они могут влиять на состав метрик в рамках информационных систем, которые мониторятся у нас.
Наш коллега может прийти и попросить добавить какую-нибудь метрику, которая окажется полезной и для нас, и для команды. Или, например, команде может быть недостаточно тех базовых метрик, которые у нас есть, им нужно отслеживать какую-то специфическую. В Grafana мы создаём пространство для каждой команды и выдаём права админа. Также, если команде нужны дашборды, а они сами не могут/не знают как это сделать, мы им помогаем.
Так как мы вне потока создания ценностей команды, их релизов и планирования, мы постепенно приходим к тому, что релизы всех систем бесшовные и их можно выкатывать ежедневно, не согласовывая при этом с нами. А нам важно отслеживать эти релизы, потому что потенциально они могут повлиять на работу приложения и что-то сломать, а это критично. Для управления релизами мы используем Bamboo, откуда по API получаем данные и можем видеть, какие релизы в каких информационных системах вышли и их статус. И самое важное — в какое время. Маркеры о релизах мы накладываем на основные критичные метрики, что визуально является весьма показательным в случае проблем.
Таким образом мы можем видеть корреляцию между новыми релизами и возникающими проблемами. Основная идея в том, чтобы понимать, как работает система на всех слоях, быстро локализовать проблему и так же быстро ее исправить. Ведь часто бывает так, что больше всего времени занимает не решение проблемы, а поиск причины.
И по этому направлению в будущем мы хотим сфокусироваться на проактивности. В идеале хотелось бы заранее узнавать о приближающейся проблеме, а не постфактум, чтобы заниматься ее предупреждением, а не решением. Порой случаются ложные срабатывания системы мониторинга, как из-за человеческой ошибки, так и из-за изменений в приложении.И мы работаем над этим, отлаживаем, и стараемся перед любыми манипуляциями над системой мониторинга предупреждать об этом пользователей, которые ее используют вместе с нами, либо проводить эти мероприятия в тех.окно.
Итак, система запущена и успешно работает с начала весны… и показывает вполне реальный профит. Конечно, это не ее финальная версия, мы будет внедрять еще множество полезностей. Но прямо сейчас, при таком большом количестве интеграций и приложений, без автоматизации мониторинга на самом деле не обойтись.
Если вы тоже мониторите большие проекты с серьезным количеством интеграций — напишите в комментариях, какую серебряную пулю нашли для этого.
Дело в том, что все наши команды построены вокруг отдельных информационных систем, микросервисов и фронтов, поэтому общее состояние здоровья всей системы в целом команды не видят. Например, они могут не знать, как какая-то небольшая часть в глубоком бэкенде влияет на фронтовую часть. Круг их интересов ограничивается системами, с которыми интегрирована их система. Если же команда и её сервис А почти никак не связан с сервисом Б, то такой сервис для команды почти невидим.
Наша же команда, в свою очередь, работает с системами, которые очень сильно интегрированы между собой: между ними множество связей, это весьма большая инфраструктура. И от всех этих систем (которых у нас, к слову, огромное количество), зависит работа интернет-магазина.
Вот и получается, что наш отдел не относится ни к одной команде, а находится немного в стороне. Во всей этой истории наша задача — понимать в комплексе, как работают информационные системы, их функциональность, интеграции, ПО, сеть, железо, и как все это связано между собой.
Платформа, на которой функционируют наши интернет-магазины, выглядит так:
- front
- middle-office
- back-office
Как бы нам ни хотелось, но не бывает такого, чтобы все системы работали гладко и безукоризненно. Дело, опять же, в количестве систем и интеграций — при таком, как у нас, какие-то инциденты это неизбежность, несмотря на качество тестирования. Причем как внутри какой-то отдельной системы, так и в плане их интеграции. И нужно следить за состоянием всей платформы комплексно, а не какой-нибудь отдельной её части.
В идеале наблюдение за состоянием здоровья всей платформы нужно автоматизировать. И мы пришли к мониторингу как к неизбежной части этого процесса. Изначально он был построен только для фронтовой части, при этом собственные системы мониторинга по слоям были и есть у сетевиков, администраторов ПО и аппаратного обеспечения. Все эти люди следили за мониторингом только на своем уровне, комплексного понимания тоже ни у кого не было.
Например, если упала виртуальная машина, в большинстве случаев об этом знает только администратор, отвечающий за hardware и виртуальную машину. Команда фронта в таких случаях видела сам факт падения приложения, но данных о падении виртуальной машины у неё не было. А администратор может знать, кто заказчик, и примерно представлять, что именно сейчас на этой виртуальной машине крутится, при условии, что это какой-то большой проект. Про маленькие он, скорее всего, не знает. В любом случае, администратору нужно идти к владельцу, спрашивать, что же на этой машине было, что нужно восстанавливать и что поменять. А если ломалось что-то совсем серьезное, начиналась беготня по кругу — потому что никто не видел систему в целом.
В конечном счете такие разрозненные истории влияют на весь фронтенд, на пользователей и нашу основную бизнес-функцию — интернет-продажи. Так как мы не входим в команды, а занимаемся эксплуатацией всех ecommerce-приложений в составе интернет-магазина, мы взяли на себя задачу по созданию комплексной системы мониторинга ecommerce-платформы.
Структура системы и стек
Мы начали с того, что выделили несколько слоёв мониторинга для наших систем, в разрезе которых нам потребуется собирать метрики. И все это нужно было объединить, что мы и сделали на первом этапе. Сейчас по этому этапу мы дорабатываем максимально качественный сбор метрик по всем нашим слоям, чтобы выстраивать корреляцию и понимать, как системы влияют друг на друга.
Отсутствие комплексного мониторинга на начальных этапах запуска приложений (так как мы начали строить его, когда большая часть систем была в эксплуатации) привело к тому, что у нас образовался значительный технический долг по настройке мониторинга всей платформы. Сосредотачиваться на настройке мониторинга какой-то одной ИС и детально прорабатывать мониторинг для неё мы не могли себе позволить, так как остальные системы остались бы на какое-то время без мониторинга. Для решения этой задачи мы определили список самых необходимых метрик оценки состояния информационной системы по слоям и начали его внедрять.
Поэтому слона решили есть по частям.
Наша система складывается из:
- hardware;
- операционной системы;
- software;
- UI-части в приложении мониторинга;
- бизнес-метрики;
- приложения интеграции;
- информационной безопасности;
- сети;
- балансировщика трафика.
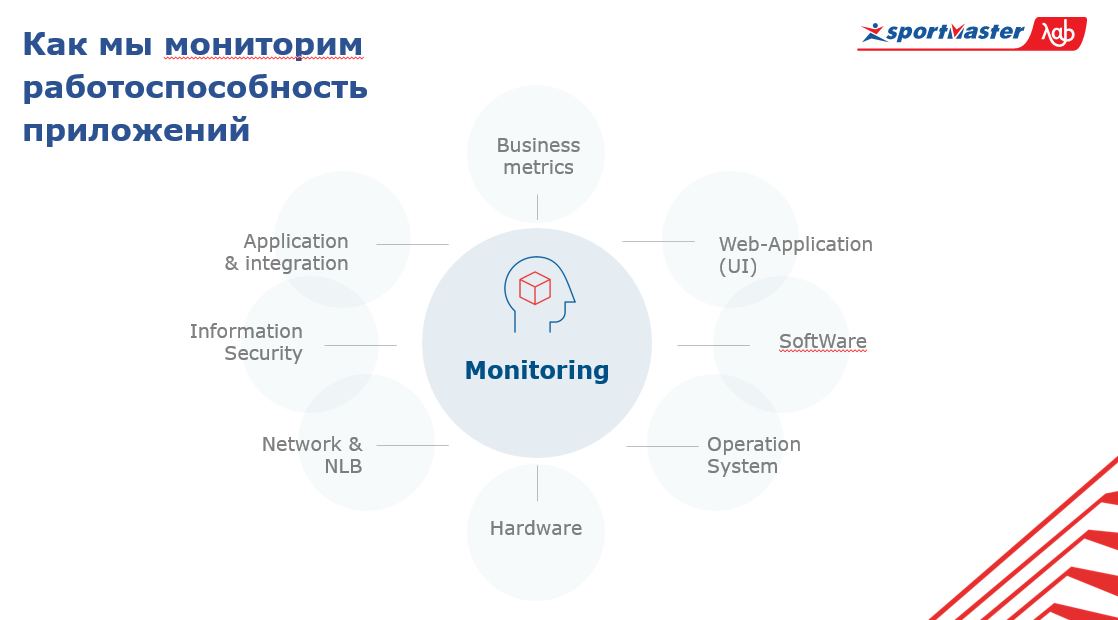
В центре этой системы — собственно мониторинг. Чтобы в общем понимать состояние всей системы, надо знать, что происходит с приложениями на всех этих слоях и в разрезе всего множества приложений.
Так вот, про стек.

Используем ПО с открытым исходным кодом. В центре у нас Zabbix, который мы используем в первую очередь как систему алертинга. Всем известно, что он идеально подходит для мониторинга инфраструктуры. Что здесь имеется в виду? Как раз те низкоуровневые метрики, которые есть у каждой компании, которая содержит свой ЦОД (а у Спортмастера свои ЦОДы) — температура сервера, состояние памяти, рейда, метрики сетевых устройств.
Мы интегрировали Zabbix с мессенджером Telegram и Microsoft Teams, активно используемыми в командах. Zabbix покрывает слой фактической сети, железа и частично ПО, но это не панацея. Мы эти данные обогащаем из некоторых других сервисов. Например, по уровню аппаратного обеспечения мы напрямую по API коннектимся в нашей системе виртуализации и забираем данные.
Что ещё. Помимо Zabbix мы используем Prometheus, который позволяет мониторить метрики в приложении динамической среды. То есть, мы можем получать метрики приложения по HTTP endpoint и не переживать по поводу того, какие метрики в нее загружать, а какие нет. На основании этих данных можно прорабатывать аналитические запросы.
Источники данных для остальных слоев, например, бизнес-метрик, у нас делятся на три составляющие.
Во-первых, это внешние бизнесовые системы, Google Analytics, собираем метрики из логов. Из них мы получаем данные по активным пользователям, конверсии и всему прочему, связанному с бизнесом. Во-вторых, это система UI-мониторинга. О ней следует рассказать более подробно.
Когда-то мы начинали с мануального тестирования и оно перерасло в автотесты функционала и интеграций. Из него мы и сделали мониторинг, оставив только основной функционал, и завязались на маркеры, которые максимально стабильны и не часто меняются со временем.
Новая структура команд подразумевает, что вся деятельность по приложениям замыкается на продуктовых командах, поэтому чистым тестированием мы заниматься перестали. Вместо этого мы из тестов сделали UI-мониторинг, написанный на Java, Selenium и Jenkins (используется как система запуска и генерации отчетов).
У нас было много тестов, но в итоге мы решили выходить на главную дорогу, верхнеуровневую метрику. И если у нас будет много специфических тестов, то будет сложно поддерживать актуальность данных. Каждый последующий релиз будет значительно ломать всю систему, а мы только и будем заниматься ее починкой. Поэтому мы завязались на совсем фундаментальные вещи, которые редко меняются, и мониторим только их.
Наконец, в-третьих, источником данных является централизованная система логирования. Для логов используем Elastic Stack, а потом эти данные можем затягивать в нашу систему мониторинга по бизнес-метрикам. В дополнение ко всему этому работает наш собственный сервис Monitoring API, написанный на Python, который опрашивает по API любые сервисы и забирает в Zabbix данные из них.
Еще один незаменимый атрибут мониторинга — визуализация. У нас она строится на основе Grafana. Среди прочих систем визуализации она выделяется тем, что на дашборде можно визуализировать метрики из разных источников данных. Мы можем собрать верхнеуровневые метрики интернет-магазина, например, количество заказов, оформленных за последний час, из СУБД, метрики производительности ОС, на которой запущен этот интернет-магазин, из Zabbix, а метрики инстансов этого приложения — из Prometheus. И все это будет на одном дашборде. Наглядно и доступно.
Отмечу про безопасность — мы сейчас допиливаем систему, которую впоследствии будем интегрировать с глобальной системой мониторинга. На мой взгляд, основные проблемы, с которыми сталкивается e-commerce в сфере информационной безопасности, связаны с ботами, парсерами и брутфорсом. За этим нужно следить, потому что они все это может критично повлиять как на работу наших приложений, так и на репутацию с точки зрения бизнеса. И выбранным стеком мы эти задачи успешно покрываем.
Ещё важный момент — уровень приложений собирается Prometheusом. Сам он он у нас тоже интегрирован с Zabbix. И ещё у нас есть sitespeed, сервис, который позволяет нам соответственно смотреть такие параметры, как скорость загрузки нашей страницы, боттлнеки, отрисовка страницы, загрузка скриптов и прочее, он тоже по API интегрирован. Так метрики у нас собираются в Zabbix, соответственно, алертим мы также оттуда. Все алерты пока уходят на основные способы отправки (пока это email и telegram, ещё подключили недавно MS Teams). В планах прокачать алертинг до такого состояния, чтобы умные боты работали как сервис и предоставляли информацию по мониторингу всем желающим продуктовым командам.
Для нас важны метрики не только отдельных информационных систем, но и общие метрики по всей инфраструктуре, которую используют приложения: кластеры физических серверов, на которых крутятся виртуалки, балансировщики трафика, Network Load Balancer-ы, сама сеть, утилизация каналов связи. Плюс метрики по нашим собственным цодам (у нас их несколько и инфраструктура довольно значительных размеров).
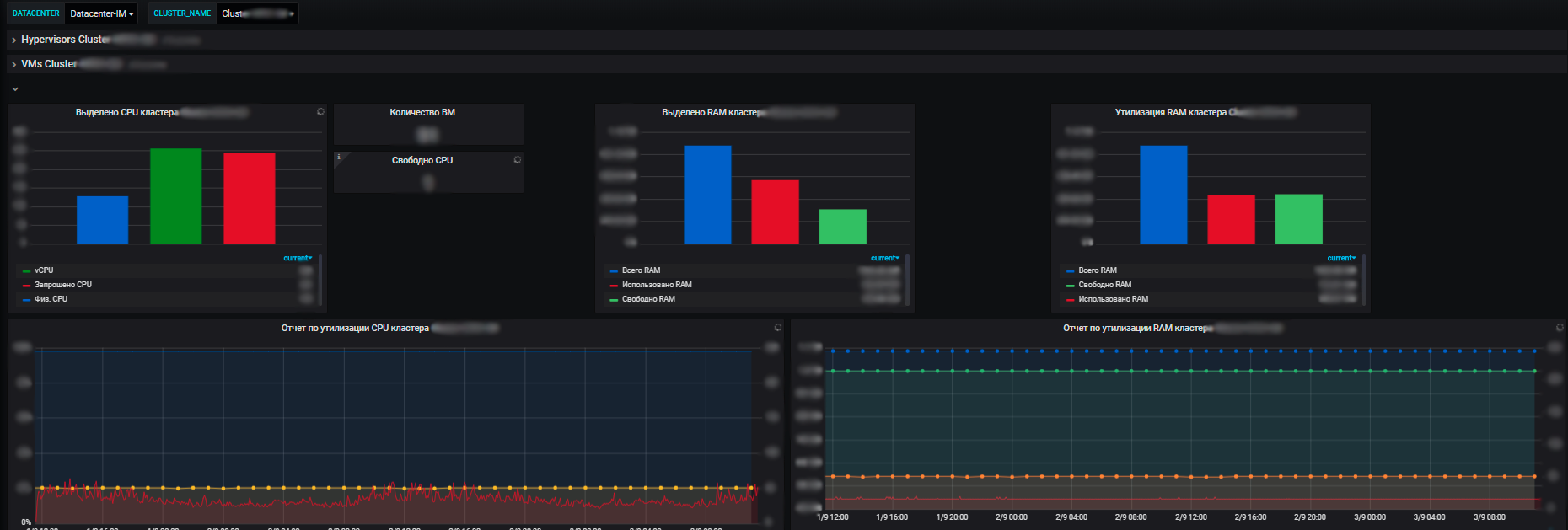
Плюсы нашей системы мониторинга в том, что с ее помощью мы видим состояние работоспособности всех систем, можем оценить их влияние друг на друга и на общие ресурсы. И в конечном счете она позволяет заниматься планированием ресурсов, что также входит в нашу зону ответственности. Мы управляем серверными ресурсами — пулом в рамках e-commerce, вводим-выводим из эксплуатации новое оборудование, докупаем новое, проводим аудит утилизации ресурсов и прочее. Каждый год команды планируют новые проекты, развивают свои системы, и нам важно обеспечить их ресурсами.
И с помощью метрик мы видим тенденцию потребления ресурсов нашими информационными системами. И уже на их основании можем что-то планировать. На уровне виртуализации мы собираем данные и видим информацию по доступному количеству ресурсов в разрезе ЦОДов. А уже внутри ЦОДа видна и утилизация, и фактическое распределение, потребление ресурсов. Причем как со standalone-серверами, так и виртуальными машинами и кластерами физических серверов, на которых все эти виртуалки бодро крутятся.
Перспективы
Сейчас у нас готово ядро системы в целом, но осталось достаточно моментов, над которыми еще предстоит работать. Как минимум это слой информационной безопасности, но важно также добраться до сети, развить алертинг и решить вопрос с корреляцией. Слоев и систем у нас много, на каждом слое еще множество метрик. Получается матрёшка в степени матрёшки.
Наша задача — в конечном счете сделать правильные алерты. Например, если случилась проблема с аппаратной частью, опять же, с виртуальной машиной, а там было важное приложение, и сервис был никак не зарезервирован. Мы узнаем, что виртуальная машина умерла. Затем будут алертить бизнес-метрики: пользователи куда-то пропали, конверсии нет, UI в интерфейсе недоступен, ПО и сервисы тоже умерли.
При таком раскладе мы получим спам из алертов, а это уже не укладывается в формат правильной системы мониторинга. Встает вопрос корреляции. Поэтому в идеале наша система мониторинга должна сказать: «Ребята, у вас физическая машина умерла, а вместе с ней вот это приложение и такие метрики», с помощью одного алерта вместо того, чтобы яростно засыпать нас сотней алертов. Она должна сообщить о главном — о причине, что способствует оперативности устранения проблемы за счёт её локализации.
Наша система оповещений и обработка алертов построена вокруг круглосуточной службы горячей линии. Все алерты, которые считаются у нас маст-хэвом и входят в чек-лист, передаются туда. Каждый алерт должен обязательно иметь описание: что произошло, что это, собственно, значит, на что влияет. А еще ссылку на дашборд и инструкцию, что же в этом случае нужно делать.
Это все, что касается требований к построению алертинга. Дальше ситуация может развиваться в двух направлениях — либо проблема есть и ее нужно решать, либо произошел сбой в системе мониторинга. Но в любом случае, нужно идти и разбираться.
В среднем сейчас за сутки нам падает около сотни алертов, это с учетом того, что корреляция алертов еще не настроена должным образом. И если нужно провести технические работы, и мы что-то принудительно отключаем, их число вырастает в разы.
Помимо мониторинга по системам, которые мы эксплуатируем, и сбора метрик, которые на нашей стороне расцениваются как важные, система мониторинга позволяет собирать данные для продуктовых команд. Они могут влиять на состав метрик в рамках информационных систем, которые мониторятся у нас.
Наш коллега может прийти и попросить добавить какую-нибудь метрику, которая окажется полезной и для нас, и для команды. Или, например, команде может быть недостаточно тех базовых метрик, которые у нас есть, им нужно отслеживать какую-то специфическую. В Grafana мы создаём пространство для каждой команды и выдаём права админа. Также, если команде нужны дашборды, а они сами не могут/не знают как это сделать, мы им помогаем.
Так как мы вне потока создания ценностей команды, их релизов и планирования, мы постепенно приходим к тому, что релизы всех систем бесшовные и их можно выкатывать ежедневно, не согласовывая при этом с нами. А нам важно отслеживать эти релизы, потому что потенциально они могут повлиять на работу приложения и что-то сломать, а это критично. Для управления релизами мы используем Bamboo, откуда по API получаем данные и можем видеть, какие релизы в каких информационных системах вышли и их статус. И самое важное — в какое время. Маркеры о релизах мы накладываем на основные критичные метрики, что визуально является весьма показательным в случае проблем.
Таким образом мы можем видеть корреляцию между новыми релизами и возникающими проблемами. Основная идея в том, чтобы понимать, как работает система на всех слоях, быстро локализовать проблему и так же быстро ее исправить. Ведь часто бывает так, что больше всего времени занимает не решение проблемы, а поиск причины.
И по этому направлению в будущем мы хотим сфокусироваться на проактивности. В идеале хотелось бы заранее узнавать о приближающейся проблеме, а не постфактум, чтобы заниматься ее предупреждением, а не решением. Порой случаются ложные срабатывания системы мониторинга, как из-за человеческой ошибки, так и из-за изменений в приложении.И мы работаем над этим, отлаживаем, и стараемся перед любыми манипуляциями над системой мониторинга предупреждать об этом пользователей, которые ее используют вместе с нами, либо проводить эти мероприятия в тех.окно.
Итак, система запущена и успешно работает с начала весны… и показывает вполне реальный профит. Конечно, это не ее финальная версия, мы будет внедрять еще множество полезностей. Но прямо сейчас, при таком большом количестве интеграций и приложений, без автоматизации мониторинга на самом деле не обойтись.
Если вы тоже мониторите большие проекты с серьезным количеством интеграций — напишите в комментариях, какую серебряную пулю нашли для этого.
