
Привет, Хабр.
На недавнем митапе в офисе Tutu я рассказывал о том, как мы в рамках редизайна superjob.ru совершали переход от монолитного приложения к api-based архитектуре с красивыми single page applications на ReactJS на фронте и шустрым PHP-приложением на бэке. В этой статье я бы хотел подробнее рассказать о том, как мы оптимизировали наше бэкенд-приложение, чтобы оно действительно стало шустрым.
Заинтересовавшихся — прошу под кат.
Изначальный сетап
У нас было монолитное приложение на Yii1. К Yii были добавлены некоторые компоненты Symfony: например, DI, Doctrine, EventDispatcher и прочая магия. Всё это добро крутилось под PHP 7.1.
В рамках редизайна сайта мы решили разделить монолит на два приложения: одно должно было отвечать за бизнес-логику и API, а другое — исключительно за рендеринг. Поскольку объем кодовой базы Superjob опытным бойцам внушает уважение, а неопытным — страх, крамольные мысли переписать всё с нуля/на go/ещё раз с нуля были отвергнуты. В качестве хранителя бизнес-логики и провайдера API было решено использовать часть монолита на Yii, а за рендеринг должно было отвечать новое приложение на ReactJS. Общаться между собой приложения должны были посредством JSON API. Таким образом мы хотели получить следующий сетап:

Чтобы научить приложение на Yii разговаривать на JSON API, мы после долгих раздумий реализовали свое решение с исключительно оригинальным названием Mapper, о котором уже была статья на Хабре.
Mapper позволял описывать преобразования моделей в сущности JSON API при помощи yaml-конфигов, которые затем компилировались в php-код. Выглядело это примерно так:

Это позволило нам писать существенно меньше кода руками, а также гарантировало единообразие сущностей определённого типа в API.
Кроме этого Mapper взял на себя автоматизацию многих вещей, среди которых:
- работа с транспортным слоем JSON API,
- взаимодействие с БД (ActiveRecord, Doctrine),
- общение с сервисами и DI,
- проверка прав доступа,
- валидация моделей,
- генерация документации,
- что-нибудь ещё, что очень лениво делать руками.
Благодаря Mapper’у мы смогли максимально оперативно внедрять новые эндпойнты, которые тут же подхватывало фронтовое приложение, разработка которого шла параллельно.
Оптимизация
Проанализировав первые результаты работы фронтового приложения, мы выяснили, что оно генерирует в среднем около 10 запросов к API на страницу, а значит, нам следовало всерьёз задуматься об оптимизации бэкенда: чем медленнее работает API, тем сильнее страдает UX приложения, особенно если фронт вынужден выполнять запросы последовательно.
Оптимизация Mapper’а
Мы решили начать с самого очевидного — с ядра нашего API.
Первым делом мы позаботились о том, чтобы Mapper не выполнял одну и ту же работу несколько раз. Часто в ответе API одна и та же сущность может упоминаться несколько раз (например, несколько вакансий со связью на одну компанию, несколько резюме, принадлежащих одному человеку, и так далее), но нам совершенно ни к чему несколько раз обрабатывать одно и то же. Поэтому мы научили Mapper быстро понимать, с какими моделями в рамках текущего запроса он уже работал, и отсеивать дубли. Казалось бы, что тут сложного? Если мы знаем, что нам могут быть переданы модели определённого типа, имеющие уникальное значение в определённом свойстве/геттере, задача решается тривиально. Но в более общем случае, когда ни тип, ни уникальный признак нам не гарантированы, а переданная нам структура может быть древовидной, всё становится куда сложнее. В случае с Mapper’ом задачу поиска дубликатов мы решили при помощи комбинации spl_object_hash и дополнительных проверок, специфичных для наших моделей. Однако хочется предостеречь юных падаванов, пожелавших повторить наш путь: не стоит недооценивать
Для отсеивания дубликатов мы предприняли и другой шаг: поскольку JSON API позволяет клиенту запрашивать иерархические связи сущностей, вполне легитимным будет, например, такой запрос связей: user.resume.user.resume.user.resume. Обработка таких связей — настоящая боль, поэтому мы научили Mapper обрабатывать такие кейсы. Связи, ссылающиеся друг на друга, помечались в конфиге специальным атрибутом, и при разборе запроса Mappper выполнял нормализацию списка связей, удаляя дубли.

В ходе работы над Mapper’ом мы придумали два типа сервисов, которые позволяли влиять на итоговый ответ API: это правила доступа и модификаторы. Первые разрешали или запрещали доступ к конкретной сущности, а вторые могли выполнять различные преобразования над атрибутами и связями сущностей. Передавать в такие сервисы каждую сущность по отдельности было довольно дорогим удовольствием, поэтому мы научили Mapper объединять сущности, требующие дополнительной обработки, в коллекции, которые затем передавались в сервисы. По своей сути механизм формирования таких коллекций был похож на транзакции в БД: при проходе по дереву моделей простые сущности мы рендерили сразу, а сложные отправлялись в коллекции, где ждали окончания обхода дерева. Затем наступал момент коммита — и обработанные сервисами сущности занимали свои места в дереве ответа.
Поскольку для своей работы Mapper использует компиляцию конфигов сущностей в php-код (а на данный момент в нашем API свыше 220 сущностей), мы позаботились о том, чтобы скомпилированный код был максимально компактным:
- повторяющиеся куски кода мы выносим в общие функции и трейты;
- откладываем инстанцирование объектов, а если объекты уже инстанцированы, то стараемся их переиспользовать;
- на этапе компиляции мы стараемся выполнить все проверки, не зависящие от рантайма, чтобы сократить количество действий при обработке запросов.
Оптимизация бутстрапа
После оптимизации Mapper’а мы приступили к оптимизации бутстрапа нашего приложения.
Чтобы определить, что же выполняется при каждом запросе, мы создали пустой эндпойнт, который не выполнял абсолютно никакой полезной работы, и натравили на него профайлер (мы используем связку tideways + blackfire).
Одной из проблем нашего бутстрапа оказалось слишком большое количество инстанцируемых при старте приложения сервисов и, как следствие, большое количество подключаемых файлов. Это следовало исправить.
Мы проанализировали сервисы, которые инстанцировал сам бутстрап, и отказались от части из них. Часть сервисов мы стали инстанцировать в зависимости от текущего контекста: например, мы не инстанцировали сервис, отвечающий за авторизацию пользователя, если в запросе не было авторизационного заголовка. Для сервисов, чьё инстанцирование занимало существенное время, мы стали использовать расширение для Symfony DI — Lazy Services. Это расширение заменяет инстанс сервиса на легковесную пустышку, а сам сервис не инстанцируется вплоть до первого обращения к нему.
Затем мы решили оптимизировать работу EventDispatcher. Дело в том, что по умолчанию EventDispatcher инстанцирует всех своих слушателей, а это создаёт ощутимый оверхед, если таких слушателей много. Чтобы решить эту проблему, мы написали свой CompilerPass для DI, который, исходя из особенностей нашего приложения, либо не инстанцировал слушателей вовсе, либо инстанцировал какую-то их часть.
Наконец, чтобы ещё сильнее сократить количество подключаемых файлов, мы выполнили небольшую оптимизацию самого DI. По умолчанию DI складывает кеш рефлексии одного класса в несколько ключей (в нашем случае — файлов), что приводит к существенному увеличению операций чтения и десериализации. Мы переписали класс, ответственный за сбор и кеширование рефлексии так, чтобы кеш по одному классу хранился в одном ключе. Это, несмотря на слегка возросший размер кеша, дало нам выигрыш по времени за счёт сокращения количества операций чтения.
В конечном итоге все наши оптимизации позволили нам сократить потребление cpu на 40% и немного сэкономить память.
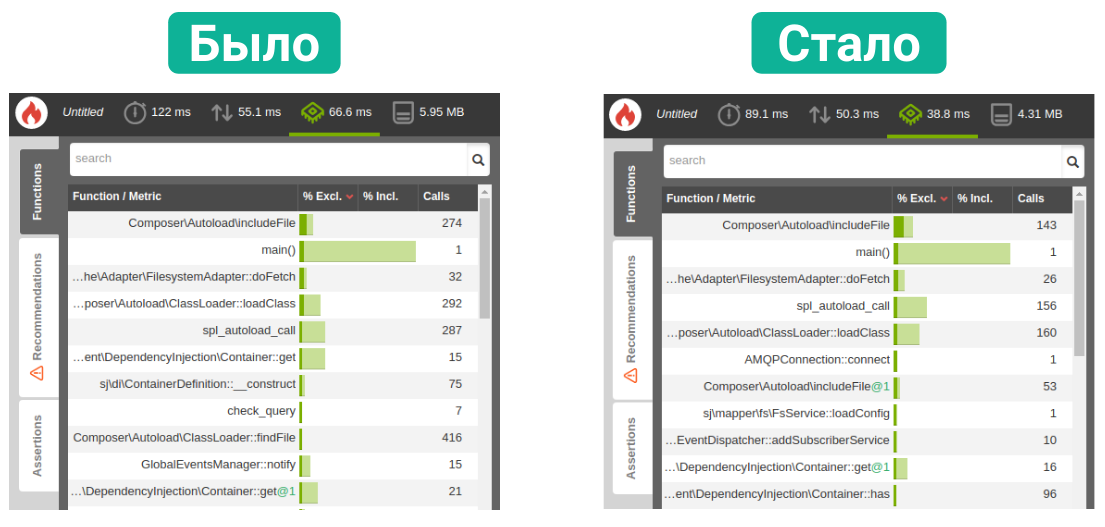
Оптимизация эндпойнтов
Наконец, последним этапом оптимизации бэкенда стала оптимизация конкретных эндпойнтов.
Поскольку единственным источником информации для фронтового приложения был наш API, у нас было некоторое количество эндпойнтов со справочниками, словарями, конфигами и прочими редкоизменяемыми данными. Специально для таких эндпойнтов мы добавили поддержку серверного кеширования: словарный эндпойнт при помощи комбинации заголовков Cache-Control и Expires мог попросить nginx закешировать тело ответа на определённое количество времени.
Для остальных эндпойнтов мы вооружились специальным инструментарием. Мы интегрировали наш API с debug-панелью: с каждым ответом API приходила ссылка на панель, по которой можно было перейти и посмотреть, что происходило внутри эндпойнта:

Данные из панели попадали в сводную таблицу, из которой можно было получить сведения о времени работы эндпойнтов, а также взглянуть на профайлинг в blackfire.
Благодаря такому набору инструментов проблемные эндпойнты были видны в буквальном смысле невооружённым взглядом, но мы все равно вооружались скриптами, которые анализировали таблицу и выискивали там аномалии. Последние делились, как правило, на два типа: либо эндпойнт начинал тормозить при определённой комбинации фильтров, либо — при больших объёмах запрошенных данных. По каждому проблемному кейсу мы проводили расследование и вносили исправления.
Итоги
По сравнению со старым сайтом скорость первоначальной загрузки страницы в редизайне, несмотря на возросшую нагрузку на бэкенд, практически не изменилась, а все последующие переходы стали ощутимо быстрее благодаря архитектуре фронтового приложения, которое не требует полной перерисовки страницы при каждом переходе.
Помимо выигрыша в скорости, мы получили более чистый код как на бэке, так и на фронте: бэк не думает об отображении, а фронт не хранит у себя бизнес-логику.
Разделение монолита на отдельные приложения повлияло также на скорость разработки и доставки фич до конечных пользователей. Автоматизация рутины в бэкенд-приложении позволила нам реализовывать эндпойнты для новых фич быстрее, а чёткая спецификация дала возможность нашим коллегам из команды фронта вести разработку параллельно, используя вместо эндпойнтов моки.
Мы надеемся, что наш опыт оказался кому-то полезен, и всегда рады ответить на ваши вопросы в комментариях.
