

Мы в компании любим и уважаем Apache Kafka, и в ознаменование выхода ее недавнего обновления я решил подготовить статью про ее производительность. А еще рассказать немного про то, как выжать из нее максимум.
Зачем нам это?
Дело в том, что нам повезло иногда заниматься высоконагруженными внутренними системами, автоматизирующими набор в нашу компанию. Например, одна из них собирает все отклики с большинства самых известных работных сайтов страны, обрабатывает и отправляет это все рекрутерам. А это довольно большие потоки данных.
Чтобы все работало, нам необходимо осуществлять обмен данными между разными приложениями. Причем обмен должен происходить достаточно быстро и без потерь, ведь, в конечном счете, это выливается в эффективность подбора персонала.
Для решения этой задачи нам предстояло выбрать среди нескольких доступных на рынке брокеров сообщений, и мы остановились на Apache Kafka. Почему? Потому что она быстрая и поддерживает семантику гарантированно единственной доставки сообщения (exactly-once semantic). В нашей системе важно, чтобы в случае отказа сообщения все равно доставлялись, и при этом не дублировали бы друг друга.
Как все устроено
Все в Apache Kafka построено вокруг концепции логов. Не тех логов, что вы выводите куда-либо для чтения человеком, а других, абстрактных логов. Логи, если взглянуть шире, это наиболее простая абстракция для хранения информации. Это очередь данных, которая отсортирована по времени, и куда данные можно только добавлять.
Для Apache Kafka все сообщения – это логи. Они передаются от производителей (producer) к потребителям (consumer) через кластер Apache Kafka. Вы можете адаптировать кластер Apache Kafka под свои задачи для повышения производительности. Помимо изменения настроек брокеров (машин в кластере), настройки можно менять у производителей и потребителей. В статье пойдет речь об оптимизации только производителей.
Есть несколько важных концепций, которые нужно понять, чтобы знать, что и зачем “тюнить”:
Нет потребителей — скорость падает
Если новые сообщения тут же никто не забирает, они сохраняются на диск. А это очень дорогая операция. Поэтому если потребители внезапно отключились или “залагали”, пропускная скорость упадет.
Чем больше размер сообщения, тем выше пропускная способность
Факт, что гораздо “легче” записать на диск 1 файл размером в 100 байт, чем 100 файлов в 1 байт. А ведь Apache Kafka при необходимости скидывает сообщения на диск. Интересный график с сайта Linkedin:
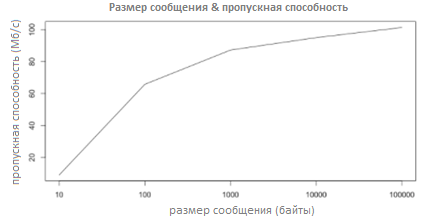
Новые производители/потребители почти линейно увеличивают производительность
Но не забываем о пункте №1.
Асинхронное реплицирование может потерять ваши данные
В отличие от синхронного механизма реплицирования, при асинхронном главная нода Apache Kafka не дожидается подтверждения получения сообщения от дочерних нод. И при сбое мастер-ноды данные могут быть утеряны. Так что надо решать – или скорость, или живучесть.
Про параметры производителей
Вот основные параметры конфигурации производителей, которые влияют на их работу:
- Batch.size
Размер пакета сообщений, который отправляется от производителя к брокеру. Производители умеют собирать эти “паки“, чтобы не отправлять сообщения по одному, т.к. они могут быть достаточно маленькими. В общем случае, чем больше этот параметр, тем:
- (Плюс) Больше степень сжатия, а значит выше пропускная способность.
- (Минус) Больше задержка в общем случае.
- Linger.ms
По умолчанию равно 0. Обычно продюсер начинает собирать следующий пакет сообщений сразу после того, как отправляет предыдущий. Параметр linger.ms говорит продюсеру, сколько нужно подождать времени, начиная с предыдущей отправки пакета и до следующего момента комплектации нового пакета (batch) сообщений.
- Compression.type
Алгоритм для сжатия сообщений (lzip, gzip, и т.д). Этот параметр сильно влияет на задержку.
- Max.in.flight.requests.per.connection
Если этот параметр больше 1, то мы находимся в так называемом режиме “трубы” (“pipeline”). Вот к чему это ведет в общем случае
- (Плюс) Более хорошую пропускную способность.
- (Минус) Возможность нарушения порядка сообщений в случае отказа.
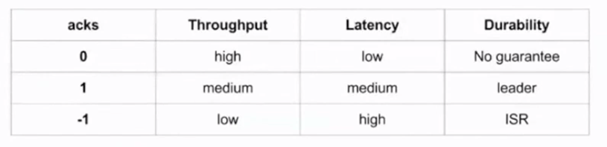
- Acks
Влияет на “живучесть” сообщений в случае отказа чего-либо. Может принимать четыре параметра: -1, 0, 1, all (то же самое, что -1). В таблице ниже сведения о том, как и на что он влияет:
Как выжать максимум
Итак, вы хотите подкрутить параметры производителя и тем самым ускорить систему. Под ускорением понимается увеличение пропускной способности и уменьшение задержки. При этом должна сохраниться “живучесть” и порядок сообщений в случае отказа.
Возьмем за данность то, что у вас уже определен тип сообщений, которые вы отправляете от производителя к потребителю. А значит, примерно известен его размер. Мы в качестве примера возьмем сообщения размером в 100 байт.
Понять в чем “затык” можно с помощью файла bin\windows\kafka-producer-perf-test.bat. Это достаточно гибкий инструмент для профилирования Apache Kafka, и для построения графиков я использовал именно его. А если его пропатчить (git pull github.com/becketqin/kafka KAFKA-3554), в нем можно выставлять два дополнительных параметра: --num-threads (кол-во потоков производителей) и --value-bound (диапазон случайных чисел для нагрузки компрессора).
Есть два варианта того, что можно изменить в производителях, чтобы все ускорить:
- Найти оптимальный размер пакета (batch.size).
- Увеличить кол-во производителей и кол-во разделов в топике (partitions).
Мы воспроизвели это все у себя. И вот что получилось:
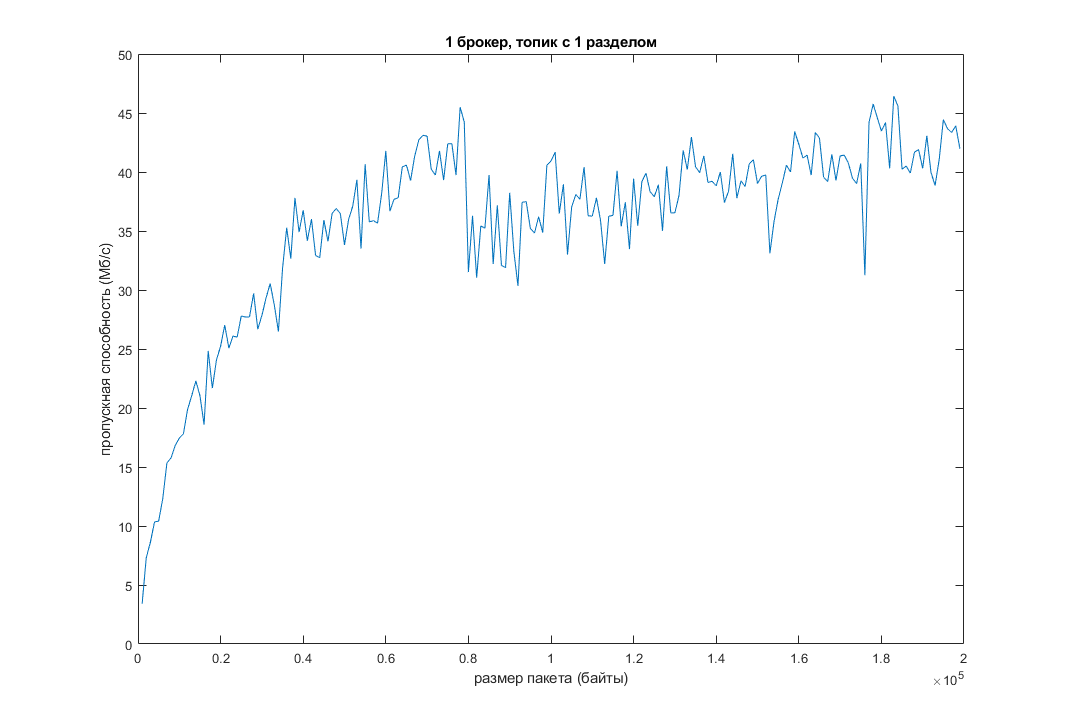
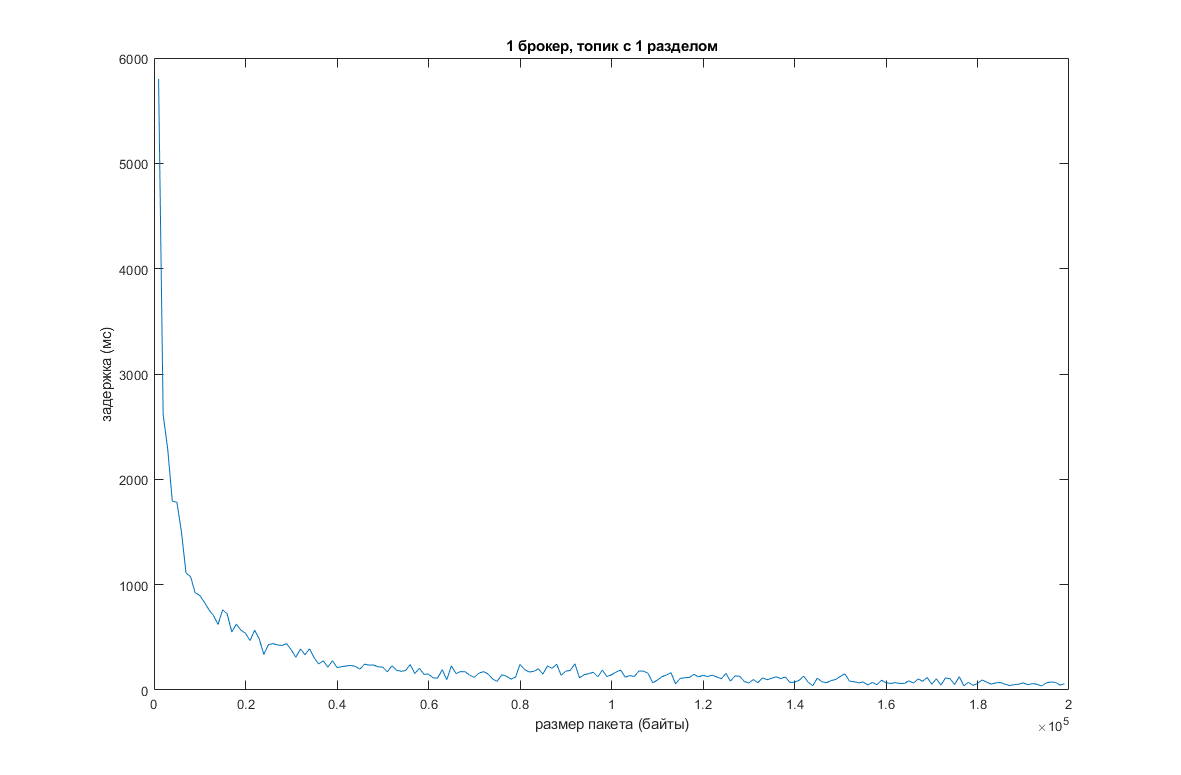
Как видно, при увеличении дефолтного размера пакета сообщений, увеличивается пропускная способность и уменьшается задержка. Но всему есть предел. В моем случае, когда размер пакета перевалил за 200 КБ, функция почти “легла”:
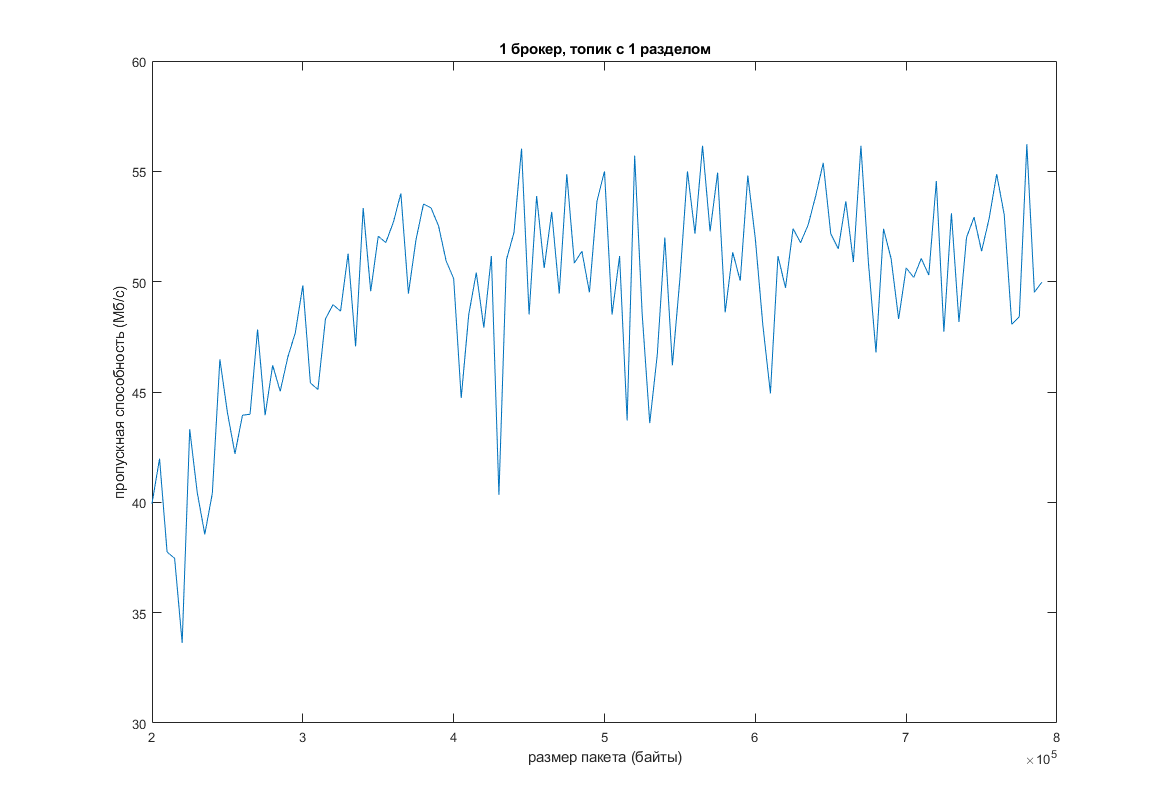
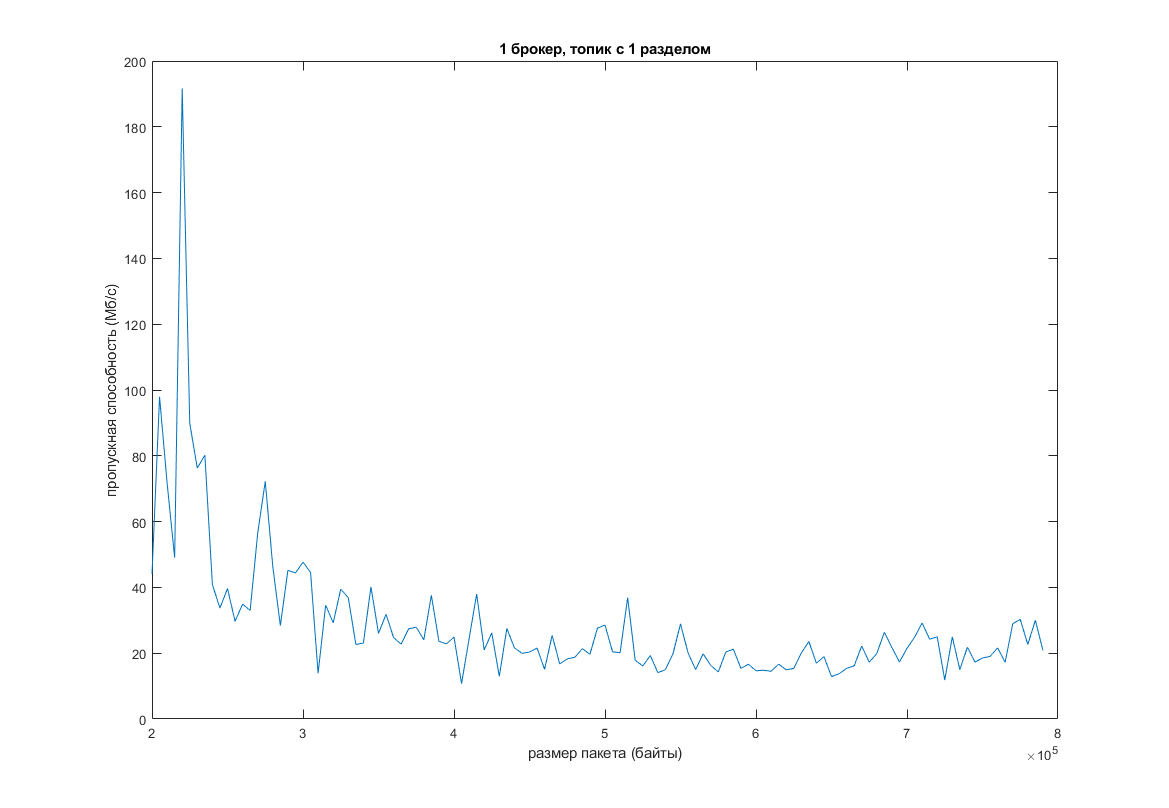
Другим вариантом является увеличение количества разделов в топике при одновременном увеличении количества потоков. Проведем те же тесты, но с уже 16 разделами в топике и 3-мя разными величинами –num-threads (теоретически это должно повысить эффективность):
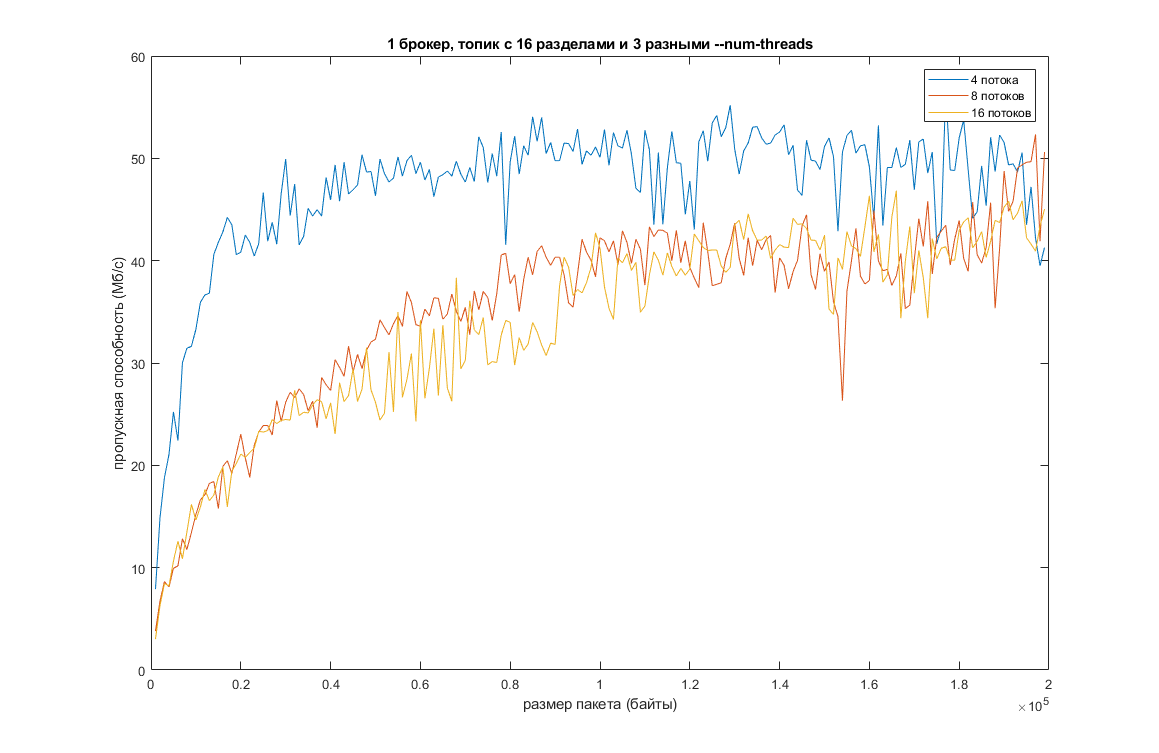
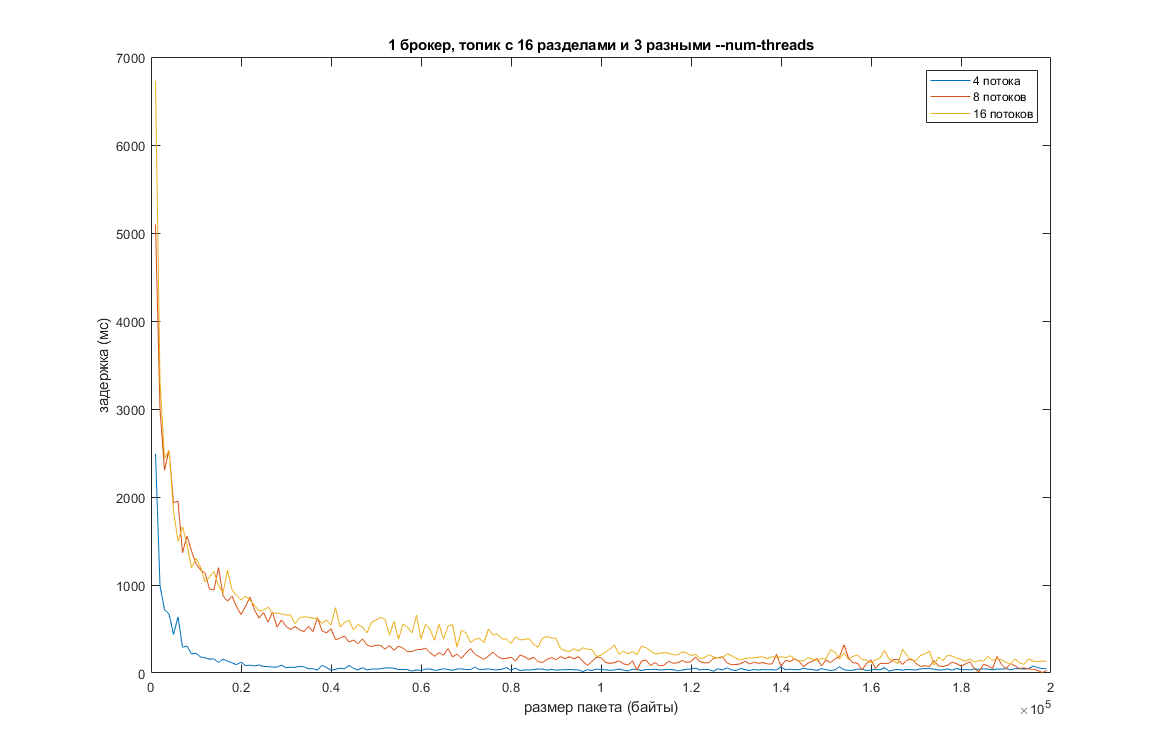
Пропускную способность это немного подняло, а задержку немного уменьшило. Видно, что при дальнейшем увеличении количества потоков производительность падает из-за издержек на время переключения контекста между потоками. На другой машине график, естественно, будет немного иным, но общая картина скорее всего не изменится.
Заключение
В данной статье были рассмотрены основные настройки производителей, изменив которые можно добиться увеличения производительности. Также было продемонстрировано, как изменение этих параметров влияет на пропускную способность и задержку. Надеюсь, мои небольшие изыскания в этом вопросе вам помогут и спасибо за внимание.
