Мы выложили парсер OOXML форматов на Ruby в open-source. Он доступен на GitHub'е и RubyGems.org, бесплатен и распространяется под лицензией AGPLv3. Всё как у модненьких Ruby-разработчиков.

Не секрет, что наш парсер не первый парсер OOXML на Ruby. Мы могли бы взять продукт сторонних разработчиков, но решили не брать. У тех решений, которые нам удалось найти, есть ряд проблем:
а) они давно заброшены разработчиками;
б) они поддерживают только базовую функциональность;
в) они, как правило, распространяются как три отдельные библиотеки. Зачастую парсер docx и парсер xlsx делали разные люди, поэтому их интерфейсы могут кардинально отличаться. Согласитесь, это неудобно.
Мы писали его под себя и свои задачи (тестирование редакторов документов), но потом поняли, что, возможно, он может помочь и другим Ruby-разработчикам, потому что он:
а) активно развивается;
б) поддерживает всю функциональность наших редакторов, а это очень много. Вот тут можно почитать;
в) называется OOXML парсер, так как работает и с docx, и xlsx, и pptx.
Отдельно остановимся на пункте б) — функциональность. Реализованы ли у нас все возможные фичи стандарта? Не-а. Стандарт ECMA-376 это четыре тома и в сумме over 9000 страниц (нет). На самом деле, около 7 тысяч. Можно выдыхать.

В общем, сами понимаете: реализовано у нас не всё. Но есть всё самое необходимое и более того: распознаются параграфы, таблицы, автофигуры. Есть поддержка таких комплексных вещей как
Спойлер — Зачем нам вообще нужны парсеры?
Он появился на свет в отделе тестирования.
С самого начала автоматизированного тестирования у нас был принят единый концепт функциональных тестов.
Возьмем простейший тест:
1. Создаем новый документ.
2. Печатаем текст и выставляем у него свойство Bold.
3. Проверяем, что Bold выставлен.
Редактор ONLYOFFICE написан на Canvas, то есть, текст в документе представляет собой картинку. Проверифицировать толщину шрифта по картинке чрезвычайно сложно. А ведь применить Bold можно к любому шрифту!

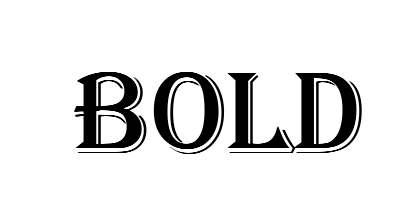
В некоторых шрифтах (таких как Arial Black) Bold может вообще визуально никак не проявиться. Согласитесь, что сравнивать картинки imagemagick-ом — не самый оптимальный вариант.
Поэтому шаг верификации теста был выделен в отдельный пункт, а именно:
4. Скачиваем полученный файл в формате docx и проверяем, что у текста выставлен параметр Bold.
Таких параметров сотни. При этом ни одно из существующих решений не поддерживало ничего, кроме простейшего выхватывания текста, таблиц и еще пары вещей. Так мы и решили создавать свою библиотеку.
Постойте, спросите вы, вы же разрабатываете редактор документов, который умеет открывать все эти форматы на редактирование! Почему бы не использовать уже готовое решение из редактора и верифицировать тесты через него?
Почему нет?
1. В серверной части редакторов парсер написан на C++, а весь процесс автоматизированного тестирования построен на Ruby. С ходу было не совсем понятно, как это всё завязать друг с другом.
2. Сейчас у нас есть версия для Linux (и она основная), но в момент начала интеграции всей инфраструктуры для тестирования серверная часть документов поддерживала в качестве платформы только Windows. При этом в тестировании мы всегда использовали Ubuntu и производные. Чтобы склеить вот это всё, пришлось бы придумывать хитрые схемы.
3. А можно ли вообще серверный парсер считать эталоном? Верифицировать результаты работы продукта, используя сам продукт? Сомнительная идея.
Если вы когда-либо пытались заархивировать docx-файл, то могли заметить, что степень сжатия очень мала. Почему так? Всё просто: ooxml-файлы — это всего лишь заархивированный набор xml-файлов. Их структура достаточно тривиальна.
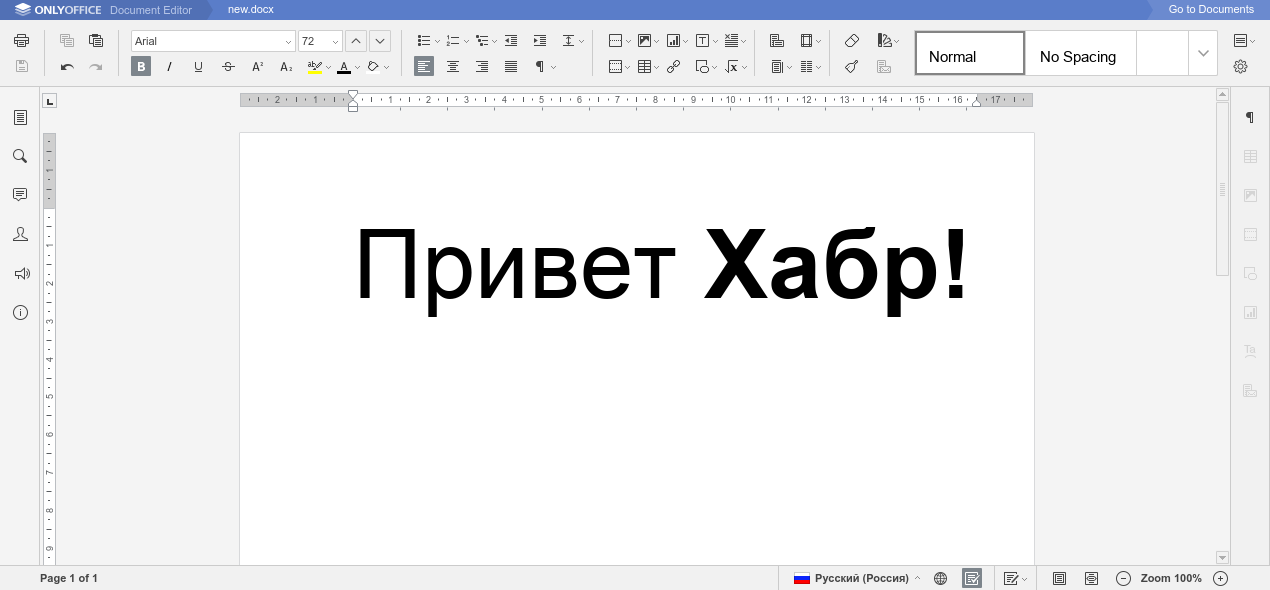
Для примера создадим простой файл с приветствием в нашем редакторе ONLYOFFICE и скачаем его в docx. Затем разархивируем как zip файл и посмотрим, где же хранится интересное нам мясцо этого документа.
Мы увидим такую структуру:
Начинаем копаться во внутренностях. По порядку.
[Content_Types].xml — список mime-типов в документе. Холодно.
app.xml — метадата документа, приложение-создатель, статистика. Уже тепло, информация интересная, пригодится.
core.xml — метадата о последних модификациях.
document.xml — Ohh, that's a bingo. В этом файле и прячется контент нашего документа, рассмотрим его позднее.
fontTable.xml — таблица шрифтов в документе. Пригодится.
document.xml.rels — список всех файлов в архиве, этот список будет нам очень полезен для комплексных документов, с картинками и графиками.
settings.xml — из названия понятно, что там хранятся разнообразные параметры документа, такие как дефолтный зум, разделители чисел и прочее.
styles.xml, theme1.xml и theme1.xml.rels — очень громоздкие, очень детальные файлы, содержащие параметры стилей и тем документа. Возможность понимать эти документы — одна из ключевых особенностей продукта.
webSettings.xml — настройка касаемо web-версии документа. Не самая популярная функциональность для docx, опустим.
Итак, оказалось, что в простом документе интересен именно word/document.xml.

Простая xml. Благо с парсингом xml на Ruby проблем никаких нет. Берем Nokogiri и получаем DOM-дерево. Ну а дальше уже дело техники, почитаем стандарт (если не лень, документ же очень большой), или же просто старым добрым реверс-инжинирингом поймем, где в документе запрятан нужный параметр.
В начале работы мы допустили ряд ошибок, которые по мере возрастания осознанности сами поправили. Две самые значимые ошибки описаны ниже — благо они в прошлом, и нам уже не стыдно. Надеемся, наш опыт поможет другим не пробежаться по тем же граблям.
Огромные файлы
Итак, у нас есть задача обработать три разных формата документов. Как же мы организуем код для этого? Конечно, три файла по 4000 строчек кода (на самом деле, даже 4 файла по 4000 строчек кода, потому что были еще и общие методы для форматов).
Решение проблемы заняло больше всего времени. Пришлось приводить всё это хозяйство в аккуратный вид (хотя до сих пор иногда всплывает файлик на 300 строчек), выделять методы в аккуратные классы и т.д. Сейчас у нас более 200 файлов исходников вместо четырех. Править баги стало легче.
Отсутствие тестов
Логика была такая: мы пишем парсер, чтобы тестировать наш основной продукт ONLYOFFICE Document Server, зачем нам тестировать сам парсер?
НЕТ. НЕТ. НЕТ!!!
Сцена из жизни:
— Надо бы поправить вот тут кое-что, у нас цвет фигуры неправильно определяется.
— Да, сейчас, опечатка там была, одну букву исправил, закоммитил.
Итог:
Всё упало. Парсер, редактор, курс доллара, шалтай-болтай, самооценка.
А всего лишь надо было создать папочку `spec`, положить туда пару сотен файлов, проверить кучу параметров, чтобы спать ночами спокойно и знать, что тот коммит, который ты сделал перед уходом с работы, не сломает верификацию той опции, которая выставляется в меню 3-его уровня вложенности. Как мы это называем «в третьей звезде налево».
Но мы не только косячили. Здравые мысли у нас тоже были. Самые классные из них:
Использование RuboCop
RuboCop — это статический анализатор кода для Ruby, и мы его любим. Очень-очень. И всегда прислушиваемся к его мнению. Он помогает держать код в тонусе, не допускать глупых ошибок и строго следить, чтобы код не стал грязнее и хуже после очередного коммита (благодаря интеграции через overcommit).
Его работа выглядит так: после тяжелого рабочего дня ты забыл, что переменные в Ruby принято называть с маленькой буквы и пытаешься закоммитить код вида
В этом случае произойдет ошибка:
Закоммитить этот код без дополнительных манипуляций (`SKIP=RuboCop git commit -av`) не получится. Это отличная защита от дурака.
Ориентация на open-source проекты
Практически с самого начала разработки парсера мы ориентировались на другие open-source проекты. Хотя мы не были уверены, что наш код будет выложен в open source, но всегда были к этому готовы. Когда поступила команда «Выкладывайте», мы просто нажали кнопочку «make public» в GitHub'e и всё, никаких дополнительных причесываний и прочего.
В этом большая заслуга того же RuboCop: мы часто подглядывали в их код, думая как лучше организовать ту или иную тему, например Changelog, структуру гема. Кроме того, вся разработка, коммиты, история изменений и прочего изначально велись на английском.
Использование базы документов
При тестировании парсеров нам пригодились наши предыдущие наработки — крупная база со всякими странными, огромными и непонятными файлами трех форматов.
Когда-то давным-давно, на ранней стадии разработки редакторов ONLYOFFICE мы собрали эти файлы на просторах интернета — на них проверялся рендеринг сложных и нестандартных документов. Спустя несколько лет по этой же базе документов прогнался парсер. В результате нашлось достаточно много проблем разного уровня сложности и, потратив пару недель на их устранение, мы получили отличный продукт.

Итак, все доступно, берете, добавляете в своё Ruby-приложение, парсите docx, строите по ним статистику, анализируете, как работает ваша бухгалтерия по xlsx файлам, узнаете, какой мемасик спрятал ваш PM на презентации продукта в четвертом слайде. И все это бесплатно.
А еще можете находить проблемные файлы и создавать issue на GitHub'e, будем это разруливать. Можете даже править сами и слать Pull Requests.
Почему мы не использовали сторонние парсеры
Не секрет, что наш парсер не первый парсер OOXML на Ruby. Мы могли бы взять продукт сторонних разработчиков, но решили не брать. У тех решений, которые нам удалось найти, есть ряд проблем:
а) они давно заброшены разработчиками;
б) они поддерживают только базовую функциональность;
в) они, как правило, распространяются как три отдельные библиотеки. Зачастую парсер docx и парсер xlsx делали разные люди, поэтому их интерфейсы могут кардинально отличаться. Согласитесь, это неудобно.
Чем отличается наш парсер
Мы писали его под себя и свои задачи (тестирование редакторов документов), но потом поняли, что, возможно, он может помочь и другим Ruby-разработчикам, потому что он:
а) активно развивается;
б) поддерживает всю функциональность наших редакторов, а это очень много. Вот тут можно почитать;
в) называется OOXML парсер, так как работает и с docx, и xlsx, и pptx.
Отдельно остановимся на пункте б) — функциональность. Реализованы ли у нас все возможные фичи стандарта? Не-а. Стандарт ECMA-376 это четыре тома и в сумме over 9000 страниц (нет). На самом деле, около 7 тысяч. Можно выдыхать.
В общем, сами понимаете: реализовано у нас не всё. Но есть всё самое необходимое и более того: распознаются параграфы, таблицы, автофигуры. Есть поддержка таких комплексных вещей как
- Цветовые схемы;
- Стили параграфов и таблиц;
- Встроенные диаграммы;
- Свойства автофигур;
- Колонки;
- Списки.
Зачем нужен был парсер
Спойлер — Зачем нам вообще нужны парсеры?
Он появился на свет в отделе тестирования.
С самого начала автоматизированного тестирования у нас был принят единый концепт функциональных тестов.
Возьмем простейший тест:
1. Создаем новый документ.
2. Печатаем текст и выставляем у него свойство Bold.
3. Проверяем, что Bold выставлен.
Редактор ONLYOFFICE написан на Canvas, то есть, текст в документе представляет собой картинку. Проверифицировать толщину шрифта по картинке чрезвычайно сложно. А ведь применить Bold можно к любому шрифту!
В некоторых шрифтах (таких как Arial Black) Bold может вообще визуально никак не проявиться. Согласитесь, что сравнивать картинки imagemagick-ом — не самый оптимальный вариант.
Поэтому шаг верификации теста был выделен в отдельный пункт, а именно:
4. Скачиваем полученный файл в формате docx и проверяем, что у текста выставлен параметр Bold.
Таких параметров сотни. При этом ни одно из существующих решений не поддерживало ничего, кроме простейшего выхватывания текста, таблиц и еще пары вещей. Так мы и решили создавать свою библиотеку.
Постойте, спросите вы, вы же разрабатываете редактор документов, который умеет открывать все эти форматы на редактирование! Почему бы не использовать уже готовое решение из редактора и верифицировать тесты через него?
Почему нет?
1. В серверной части редакторов парсер написан на C++, а весь процесс автоматизированного тестирования построен на Ruby. С ходу было не совсем понятно, как это всё завязать друг с другом.
2. Сейчас у нас есть версия для Linux (и она основная), но в момент начала интеграции всей инфраструктуры для тестирования серверная часть документов поддерживала в качестве платформы только Windows. При этом в тестировании мы всегда использовали Ubuntu и производные. Чтобы склеить вот это всё, пришлось бы придумывать хитрые схемы.
3. А можно ли вообще серверный парсер считать эталоном? Верифицировать результаты работы продукта, используя сам продукт? Сомнительная идея.
Как работает парсер
Если вы когда-либо пытались заархивировать docx-файл, то могли заметить, что степень сжатия очень мала. Почему так? Всё просто: ooxml-файлы — это всего лишь заархивированный набор xml-файлов. Их структура достаточно тривиальна.
Для примера создадим простой файл с приветствием в нашем редакторе ONLYOFFICE и скачаем его в docx. Затем разархивируем как zip файл и посмотрим, где же хранится интересное нам мясцо этого документа.
Мы увидим такую структуру:
#tree
├── [Content_Types].xml
├── docProps
│ ├── app.xml
│ └── core.xml
├── _rels
└── word
├── document.xml
├── fontTable.xml
├── _rels
│ └── document.xml.rels
├── settings.xml
├── styles.xml
├── theme
│ ├── _rels
│ │ └── theme1.xml.rels
│ └── theme1.xml
└── webSettings.xml
Начинаем копаться во внутренностях. По порядку.
[Content_Types].xml — список mime-типов в документе. Холодно.
app.xml — метадата документа, приложение-создатель, статистика. Уже тепло, информация интересная, пригодится.
core.xml — метадата о последних модификациях.
document.xml — Ohh, that's a bingo. В этом файле и прячется контент нашего документа, рассмотрим его позднее.
fontTable.xml — таблица шрифтов в документе. Пригодится.
document.xml.rels — список всех файлов в архиве, этот список будет нам очень полезен для комплексных документов, с картинками и графиками.
settings.xml — из названия понятно, что там хранятся разнообразные параметры документа, такие как дефолтный зум, разделители чисел и прочее.
styles.xml, theme1.xml и theme1.xml.rels — очень громоздкие, очень детальные файлы, содержащие параметры стилей и тем документа. Возможность понимать эти документы — одна из ключевых особенностей продукта.
webSettings.xml — настройка касаемо web-версии документа. Не самая популярная функциональность для docx, опустим.
Итак, оказалось, что в простом документе интересен именно word/document.xml.
Простая xml. Благо с парсингом xml на Ruby проблем никаких нет. Берем Nokogiri и получаем DOM-дерево. Ну а дальше уже дело техники, почитаем стандарт (если не лень, документ же очень большой), или же просто старым добрым реверс-инжинирингом поймем, где в документе запрятан нужный параметр.
Как писался парсер
В начале работы мы допустили ряд ошибок, которые по мере возрастания осознанности сами поправили. Две самые значимые ошибки описаны ниже — благо они в прошлом, и нам уже не стыдно. Надеемся, наш опыт поможет другим не пробежаться по тем же граблям.
Огромные файлы
Итак, у нас есть задача обработать три разных формата документов. Как же мы организуем код для этого? Конечно, три файла по 4000 строчек кода (на самом деле, даже 4 файла по 4000 строчек кода, потому что были еще и общие методы для форматов).
Решение проблемы заняло больше всего времени. Пришлось приводить всё это хозяйство в аккуратный вид (хотя до сих пор иногда всплывает файлик на 300 строчек), выделять методы в аккуратные классы и т.д. Сейчас у нас более 200 файлов исходников вместо четырех. Править баги стало легче.
Отсутствие тестов
Логика была такая: мы пишем парсер, чтобы тестировать наш основной продукт ONLYOFFICE Document Server, зачем нам тестировать сам парсер?
НЕТ. НЕТ. НЕТ!!!
Сцена из жизни:
— Надо бы поправить вот тут кое-что, у нас цвет фигуры неправильно определяется.
— Да, сейчас, опечатка там была, одну букву исправил, закоммитил.
Итог:
Всё упало. Парсер, редактор, курс доллара, шалтай-болтай, самооценка.
А всего лишь надо было создать папочку `spec`, положить туда пару сотен файлов, проверить кучу параметров, чтобы спать ночами спокойно и знать, что тот коммит, который ты сделал перед уходом с работы, не сломает верификацию той опции, которая выставляется в меню 3-его уровня вложенности. Как мы это называем «в третьей звезде налево».
Но мы не только косячили. Здравые мысли у нас тоже были. Самые классные из них:
Использование RuboCop
RuboCop — это статический анализатор кода для Ruby, и мы его любим. Очень-очень. И всегда прислушиваемся к его мнению. Он помогает держать код в тонусе, не допускать глупых ошибок и строго следить, чтобы код не стал грязнее и хуже после очередного коммита (благодаря интеграции через overcommit).
Его работа выглядит так: после тяжелого рабочего дня ты забыл, что переменные в Ruby принято называть с маленькой буквы и пытаешься закоммитить код вида
— path_to_zip_file = copy_file_and_rename_to_zip(path_to_file)
+ ZIP_file = copy_file_and_rename_to_zip(path_to_file)
В этом случае произойдет ошибка:
Analyze with RuboCop........................................[RuboCop] FAILED
Errors on modified lines:
ooxml_parser/lib/ooxml_parser/common_parser/parser.rb:8:7: E: dynamic constant assignment
Закоммитить этот код без дополнительных манипуляций (`SKIP=RuboCop git commit -av`) не получится. Это отличная защита от дурака.
Ориентация на open-source проекты
Практически с самого начала разработки парсера мы ориентировались на другие open-source проекты. Хотя мы не были уверены, что наш код будет выложен в open source, но всегда были к этому готовы. Когда поступила команда «Выкладывайте», мы просто нажали кнопочку «make public» в GitHub'e и всё, никаких дополнительных причесываний и прочего.
В этом большая заслуга того же RuboCop: мы часто подглядывали в их код, думая как лучше организовать ту или иную тему, например Changelog, структуру гема. Кроме того, вся разработка, коммиты, история изменений и прочего изначально велись на английском.
Использование базы документов
При тестировании парсеров нам пригодились наши предыдущие наработки — крупная база со всякими странными, огромными и непонятными файлами трех форматов.
Когда-то давным-давно, на ранней стадии разработки редакторов ONLYOFFICE мы собрали эти файлы на просторах интернета — на них проверялся рендеринг сложных и нестандартных документов. Спустя несколько лет по этой же базе документов прогнался парсер. В результате нашлось достаточно много проблем разного уровня сложности и, потратив пару недель на их устранение, мы получили отличный продукт.
Итого
Итак, все доступно, берете, добавляете в своё Ruby-приложение, парсите docx, строите по ним статистику, анализируете, как работает ваша бухгалтерия по xlsx файлам, узнаете, какой мемасик спрятал ваш PM на презентации продукта в четвертом слайде. И все это бесплатно.
А еще можете находить проблемные файлы и создавать issue на GitHub'e, будем это разруливать. Можете даже править сами и слать Pull Requests.
